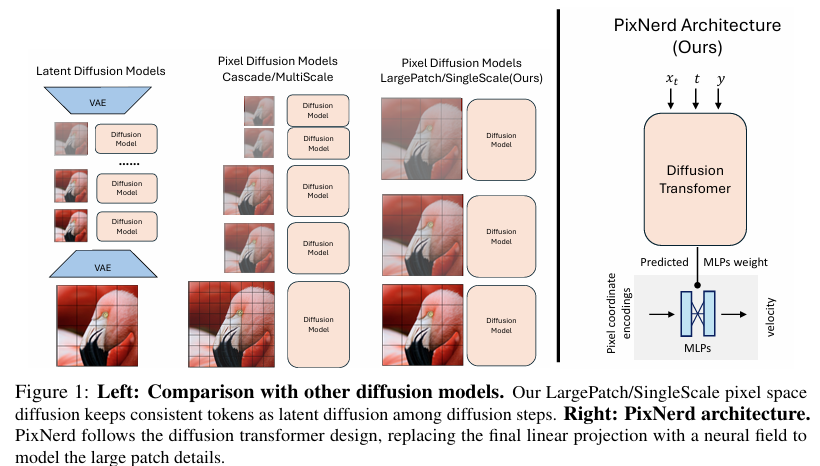
摘要:扩散变换器目前所取得的成功在很大程度上依赖于预训练变分自编码器(VAE)所塑造的压缩潜在空间。然而,这种两阶段训练模式不可避免地会引入累积误差和解码伪影。为解决上述问题,研究人员选择回归像素空间,但这需要付出构建复杂级联流水线和增加令牌复杂度的代价。与他们的努力不同,我们提出利用神经场对分块解码进行建模,并给出了一种单尺度、单阶段、高效且端到端的解决方案,称之为像素神经场扩散(PixelNerd)。得益于PixNerd中高效的神经场表示,我们在无需任何复杂级联流水线或VAE的情况下,直接在256×256分辨率的ImageNet数据集上实现了2.15的FID分数,在512×512分辨率的ImageNet数据集上实现了2.84的FID分数。此外,我们还将PixNerd框架拓展到了文本生成图像的应用领域。我们的PixNerd-XXL/16在GenEval基准测试中取得了0.73的综合得分,在DPG基准测试中取得了80.9的综合得分,表现极具竞争力。Huggingface链接:Paper page,论文链接:2507.23268
研究背景和目的
研究背景:
近年来,扩散模型(Diffusion Models)在图像生成领域取得了显著进展,尤其是基于潜在空间的扩散变换器(Diffusion Transformers)展现出了强大的生成能力。这些模型通常依赖于预训练的变分自编码器(VAE)来压缩图像空间,从而在低维潜在空间上进行学习和生成。VAE通过显著减少原始像素的空间维度,提供了一个紧凑且几乎无损的潜在表示,极大地简化了扩散变换器的学习难度。然而,这种两阶段训练方法(先训练VAE,再训练扩散模型)不可避免地引入了累积误差和解码伪影,限制了生成图像的质量和多样性。
与此同时,直接在像素空间上进行扩散学习的模型进展较为缓慢。由于像素空间的庞大维度,直接学习扩散过程面临巨大的计算挑战,且生成的图像细节和结构往往不如基于潜在空间的模型。为了解决这些问题,一些研究尝试了级联解决方案,通过在不同分辨率尺度上分割扩散过程来降低计算成本,但这些方法通常导致训练和推理过程的复杂化。
研究目的:
针对上述背景,本研究旨在提出一种新颖、优雅且高效的单尺度、单阶段端到端解决方案——像素神经场扩散(PixelNerd),以消除对VAE的依赖,并直接在像素空间上实现高质量的图像生成。具体目标包括:
- 消除累积误差和解码伪影:通过直接在像素空间上学习扩散过程,避免两阶段训练带来的累积误差和解码伪影。
- 简化模型架构:提出一种单尺度、单阶段的端到端模型,避免复杂的级联流水线和增加的令牌复杂度。
- 实现高质量图像生成:在ImageNet等大型数据集上实现与基于潜在空间的模型相当甚至更优的生成性能。
- 拓展应用场景:将模型框架拓展到文本生成图像等应用领域,验证其泛化能力。
研究方法
1. 模型架构设计:
PixNerd遵循扩散变换器的设计原则,但用神经场(Neural Field)替换了最终的线性投影层,以建模大块区域的细节。具体来说,PixNerd使用扩散变换器的最后隐藏状态来预测神经场的参数(MLP权重),这些参数随后用于解码每个像素块内的像素级扩散速度。
2. 神经场表示:
神经场通常采用多层感知机(MLP)将坐标编码映射到信号(如RGB值)。在PixNerd中,每个像素块内的局部坐标首先被转换为坐标编码,然后与对应的噪声像素值一起输入到神经场MLP中,以预测扩散速度。这种方法显著减轻了在大块配置下学习细节的挑战。
3. 扩散过程建模:
PixNerd采用与标准扩散模型相似的扩散过程,但通过神经场来预测每个像素块的扩散速度。在训练过程中,模型通过最小化预测扩散速度与真实扩散速度之间的差异来优化神经场参数。
4. 优化与训练策略:
为了提高模型的训练稳定性和生成质量,PixNerd采用了多种优化策略,包括:
- SwIGLU激活函数:增强模型的非线性表达能力。
- RMSNorm归一化:稳定训练过程,加速收敛。
- 对数域采样:提高采样效率,减少计算成本。
- 表示对齐:通过与DINOv2等预训练模型的中间特征进行对齐,增强模型的生成能力。
研究结果
1. 图像生成质量:
在ImageNet 256×256和512×512分辨率上,PixNerd-XL/16分别实现了2.15和2.84的FID分数,与基于潜在空间的模型相当甚至更优。特别是在空间结构方面(sFID),PixNerd-XL/16在ImageNet 256×256上实现了4.55的sFID分数,显著优于其他像素空间生成模型。
2. 文本生成图像应用:
将PixNerd框架拓展到文本生成图像领域后,PixNerd-XXL/16在GenEval基准测试中取得了0.73的综合得分,在DPG基准测试中取得了80.9的综合得分,表现极具竞争力。这表明PixNerd不仅限于图像生成任务,还能有效处理更复杂的文本到图像生成场景。
3. 计算效率与资源消耗:
与基于潜在空间的模型相比,PixNerd在训练和推理过程中消耗更少的内存和计算资源。特别是在推理阶段,PixNerd-L/16实现了近8倍于其他像素空间扩散模型的加速效果。
研究局限
尽管PixNerd在图像生成质量和计算效率方面取得了显著进展,但仍存在以下局限:
1. 细节表现不足:
在某些情况下,PixNerd生成的图像细节仍不够清晰,尤其是在处理复杂场景或精细结构时。这可能是由于神经场在建模极端细节方面的能力有限。
2. 多语言支持有限:
虽然PixNerd在英语提示下表现良好,但在处理其他语言(如中文、日语)时,生成图像的质量和多样性可能受到影响。这主要是由于训练数据中非英语提示的覆盖不足。
3. 分辨率适应性:
尽管PixNerd通过坐标插值实现了任意分辨率的图像生成,但在处理极高分辨率(如超过1024×1024)时,生成图像的质量和细节可能有所下降。这需要进一步优化神经场的表示能力和扩散过程的建模方法。
未来研究方向
针对上述局限,未来研究可以从以下几个方面展开:
1. 增强细节建模能力:
通过改进神经场的架构设计(如增加MLP层数或通道数)或引入更复杂的坐标编码方式,提升模型在建模极端细节方面的能力。此外,可以考虑结合超分辨率技术来进一步提升生成图像的细节表现。
2. 拓展多语言支持:
通过收集和标注更多非英语提示的图像数据,增强模型在处理多语言提示时的生成能力和多样性。同时,可以探索跨语言提示生成技术,实现不同语言提示下的高质量图像生成。
3. 提升高分辨率生成能力:
针对极高分辨率图像生成的需求,可以研究更高效的神经场表示方法和扩散过程建模技术。例如,可以尝试将神经场与多尺度建模方法相结合,或者引入分块生成和融合策略来提升高分辨率图像的生成质量和效率。
4. 探索更多应用场景:
除了文本生成图像外,还可以探索PixNerd在其他生成任务(如视频生成、3D物体生成)中的应用潜力。通过调整模型架构和训练策略,使其能够适应不同类型的数据和生成需求。
5. 优化训练和推理过程:
进一步优化模型的训练和推理过程,减少计算成本和内存消耗。例如,可以研究更高效的采样算法和参数优化策略,或者利用硬件加速技术(如GPU并行计算)来提升模型的训练和推理速度。













创建第一个Shader项目)

的组成详解)
)


