引言
在当今数据驱动的商业环境中,企业业务数据通常存储在MySQL等关系型数据库中,但当数据量增长到千万级甚至更高时,直接在MySQL中进行复杂分析会导致性能瓶颈。本文将详细介绍如何将MySQL业务数据迁移到大数据平台,并通过Spark等工具实现高效的离线分析流程。
一、整体架构设计
1.1 技术栈选择
核心组件:
数据抽取:Sqoop、Flink CDC
数据存储:HDFS、Hive
计算引擎:Spark、Hive
调度系统:Airflow
可视化:Superset
1.2 流程概览

二、数据抽取实战
2.1 Sqoop全量导入最佳实践
#!/bin/bash
# sqoop_full_import.shDB_URL="jdbc:mysql://mysql-host:3306/prod_db"
USERNAME="etl_user"
PASSWORD="secure_password"
TABLE_NAME="orders"
HDFS_PATH="/data/raw/${TABLE_NAME}_$(date +%Y%m%d)"sqoop import \--connect $DB_URL \--username $USERNAME \--password $PASSWORD \--table $TABLE_NAME \--target-dir $HDFS_PATH \--compress \--compression-codec org.apache.hadoop.io.compress.SnappyCodec \--fields-terminated-by '\001' \--null-string '\\N' \--null-non-string '\\N' \--m 8关键参数说明:
--compress:启用压缩--fields-terminated-by '\001':使用不可见字符作为分隔符--m 8:设置8个并行任务
2.2 增量同步方案对比
| 方案 | 适用场景 | 优缺点 |
|---|---|---|
| Sqoop增量 | T+1批处理 | 简单但需要维护last-value |
| Flink CDC | 近实时同步 | 复杂但支持精确一次语义 |
| 时间戳触发器 | 业务系统有更新时间字段 | 依赖业务表设计 |
三、数据清洗与转换
3.1 Spark清洗标准化流程
import org.apache.spark.sql.*;public class DataCleaningJob {public static void main(String[] args) {// 初始化SparkSessionSparkSession spark = SparkSession.builder().appName("JavaDataCleaning").config("spark.sql.parquet.writeLegacyFormat", "true").getOrCreate();// 1. 读取原始数据Dataset<Row> rawDF = spark.read().format("parquet").load("/data/raw/orders");// 2. 数据清洗转换Dataset<Row> cleanedDF = rawDF// 处理空值.na().fill(0.0, new String[]{"discount"}).na().fill(-1, new String[]{"user_id"})// 过滤无效记录.filter(functions.col("order_amount").gt(0))// 日期转换.withColumn("order_date", functions.to_date(functions.from_unixtime(functions.col("create_timestamp")), "yyyy-MM-dd"))// 数据脱敏.withColumn("user_name", functions.when(functions.length(functions.col("user_name")).gt(0),functions.expr("mask(user_name)")).otherwise("Anonymous"));// 3. 分区写入cleanedDF.write().partitionBy("order_date").mode(SaveMode.Overwrite).parquet("/data/cleaned/orders");spark.stop();}
}数据质量检查工具类
import org.apache.spark.sql.*;public class DataQualityChecker {public static void checkNullValues(Dataset<Row> df) {System.out.println("=== Null Value Check ===");for (String colName : df.columns()) {long nullCount = df.filter(functions.col(colName).isNull()).count();System.out.printf("Column %s has %d null values%n", colName, nullCount);}}public static void checkValueRange(Dataset<Row> df, String colName) {Row stats = df.select(functions.mean(colName).alias("mean"),functions.stddev(colName).alias("stddev")).first();double mean = stats.getDouble(0);double stddev = stats.getDouble(1);double upperBound = mean + 3 * stddev;double lowerBound = mean - 3 * stddev;System.out.printf("Column %s statistics:%n", colName);System.out.printf("Mean: %.2f, StdDev: %.2f%n", mean, stddev);System.out.printf("Normal range: %.2f ~ %.2f%n", lowerBound, upperBound);long outliers = df.filter(functions.col(colName).lt(lowerBound).or(functions.col(colName).gt(upperBound))).count();System.out.printf("Found %d outliers%n", outliers);}
}四、高效存储策略
4.1 存储格式对比测试
我们对10GB订单数据进行了基准测试:
| 格式 | 存储大小 | 查询耗时 | 写入耗时 |
|---|---|---|---|
| Text | 10.0GB | 78s | 65s |
| Parquet | 1.2GB | 12s | 32s |
| ORC | 1.0GB | 9s | 28s |
4.2 分区优化实践
动态分区配置:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=1000;CREATE TABLE orders_partitioned (order_id BIGINT,user_id INT,amount DECIMAL(10,2)
) PARTITIONED BY (dt STRING, region STRING)
STORED AS PARQUET;五、离线计算模式
5.1 典型分析场景实现
场景1:RFM用户分群
import org.apache.spark.sql.*;
import org.apache.spark.sql.expressions.Window;
import static org.apache.spark.sql.functions.*;public class RFMAnalysis {public static void main(String[] args) {SparkSession spark = SparkSession.builder().appName("JavaRFMAnalysis").enableHiveSupport().getOrCreate();// 计算RFM基础指标Dataset<Row> rfmDF = spark.sql("SELECT user_id, " +"DATEDIFF(CURRENT_DATE, MAX(order_date)) AS recency, " +"COUNT(DISTINCT order_id) AS frequency, " +"SUM(amount) AS monetary " +"FROM orders_cleaned " +"WHERE order_date >= DATE_SUB(CURRENT_DATE, 365) " +"GROUP BY user_id");// 使用窗口函数计算分位数WindowSpec recencyWindow = Window.orderBy(col("recency").desc());WindowSpec frequencyWindow = Window.orderBy(col("frequency").desc());WindowSpec monetaryWindow = Window.orderBy(col("monetary").desc());Dataset<Row> result = rfmDF.withColumn("r_score", ntile(5).over(recencyWindow)).withColumn("f_score", ntile(5).over(frequencyWindow)).withColumn("m_score", ntile(5).over(monetaryWindow)).withColumn("rfm", concat(col("r_score"), col("f_score"), col("m_score")));// 保存结果result.write().saveAsTable("user_rfm_analysis");spark.stop();}
}5.2 漏斗分析
import org.apache.spark.sql.*;
import static org.apache.spark.sql.functions.*;public class FunnelAnalysis {public static void main(String[] args) {SparkSession spark = SparkSession.builder().appName("JavaFunnelAnalysis").getOrCreate();String[] stages = {"view", "cart", "payment"};Dataset<Row> funnelDF = null;// 构建漏斗各阶段数据集for (int i = 0; i < stages.length; i++) {String stage = stages[i];Dataset<Row> stageDF = spark.table("user_behavior").filter(col("action").equalTo(stage)).groupBy("user_id").agg(countDistinct("session_id").alias(stage + "_count"));if (i == 0) {funnelDF = stageDF;} else {funnelDF = funnelDF.join(stageDF, "user_id", "left_outer");}}// 计算转化率for (int i = 0; i < stages.length - 1; i++) {String fromStage = stages[i];String toStage = stages[i+1];double conversionRate = funnelDF.filter(col(fromStage + "_count").gt(0)).select(avg(when(col(toStage + "_count").gt(0), 1).otherwise(0))).first().getDouble(0);System.out.printf("Conversion rate from %s to %s: %.2f%%%n", fromStage, toStage, conversionRate * 100);}spark.stop();}
}六、生产环境优化
6.1 数据倾斜处理工具类
import org.apache.spark.sql.*;
import static org.apache.spark.sql.functions.*;public class DataSkewHandler {public static Dataset<Row> handleSkew(Dataset<Row> df, String skewedColumn, Object skewedValue) {// 方法1:加盐处理Dataset<Row> saltedDF = df.withColumn("salt", when(col(skewedColumn).equalTo(skewedValue), floor(rand().multiply(10))).otherwise(0));return saltedDF.repartition(col("salt"));}public static Dataset<Row> separateProcessing(Dataset<Row> df, String skewedColumn, Object skewedValue) {// 方法2:分离处理Dataset<Row> normalData = df.filter(col(skewedColumn).notEqual(skewedValue));Dataset<Row> skewedData = df.filter(col(skewedColumn).equalTo(skewedValue));// 对skewedData进行特殊处理...// 例如增加并行度skewedData = skewedData.repartition(20);return normalData.union(skewedData);}
}七、完整案例:电商数据分析平台
7.1 数据流设计
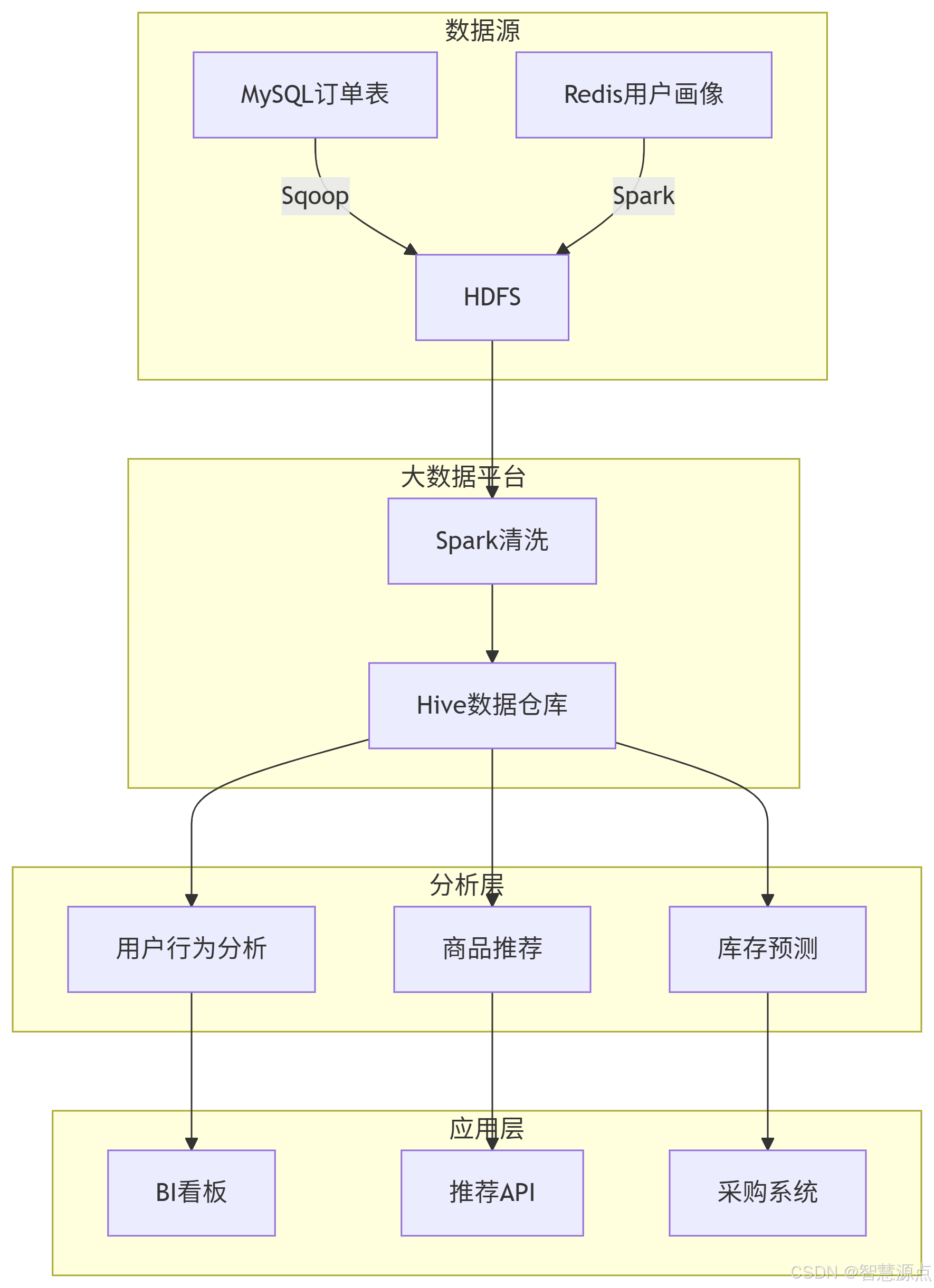
7.1 电商分析平台主程序
import org.apache.spark.sql.*;public class ECommerceAnalysisPlatform {public static void main(String[] args) {// 初始化SparkSparkSession spark = SparkSession.builder().appName("ECommerceAnalysis").config("spark.sql.warehouse.dir", "/user/hive/warehouse").enableHiveSupport().getOrCreate();// 1. 数据抽取MySQLToHDFSExporter.exportTable("orders", "/data/raw/orders");// 2. 数据清洗new DataCleaningJob().run(spark);// 3. 分析任务new RFMAnalysis().run(spark);new FunnelAnalysis().run(spark);// 4. 日报生成generateDailyReport(spark);spark.stop();}private static void generateDailyReport(SparkSession spark) {// GMV周同比计算Dataset<Row> reportDF = spark.sql("WITH current_week AS (" +" SELECT SUM(amount) AS gmv, COUNT(DISTINCT user_id) AS uv " +" FROM orders_cleaned " +" WHERE dt BETWEEN DATE_SUB(CURRENT_DATE, 7) AND CURRENT_DATE" +"), last_week AS (" +" SELECT SUM(amount) AS gmv, COUNT(DISTINCT user_id) AS uv " +" FROM orders_cleaned " +" WHERE dt BETWEEN DATE_SUB(CURRENT_DATE, 14) AND DATE_SUB(CURRENT_DATE, 7)" +") " +"SELECT " +" c.gmv AS current_gmv, " +" l.gmv AS last_gmv, " +" (c.gmv - l.gmv) / l.gmv AS gmv_yoy, " +" c.uv AS current_uv, " +" l.uv AS last_uv " +"FROM current_week c CROSS JOIN last_week l");// 保存到MySQLreportDF.write().format("jdbc").option("url", "jdbc:mysql://mysql-host:3306/report_db").option("dbtable", "daily_gmv_report").option("user", "report_user").option("password", "report_password").mode(SaveMode.Overwrite).save();}
}结语
构建完整的大数据离线分析管道需要综合考虑数据规模、时效性要求和业务需求。本文介绍的技术方案已在多个生产环境验证,可支持每日亿级数据的处理分析。随着业务发展,可逐步引入实时计算、特征仓库等更先进的架构组件。
最佳实践建议:
始终保留原始数据副本
建立完善的数据血缘追踪
监控关键指标:任务耗时、数据质量、资源利用率
定期优化分区和文件大小

![[论文阅读] 人工智能 + 软件工程 | LLM协作新突破:用多智能体强化学习实现高效协同——解析MAGRPO算法](http://pic.xiahunao.cn/[论文阅读] 人工智能 + 软件工程 | LLM协作新突破:用多智能体强化学习实现高效协同——解析MAGRPO算法)




)
把“可配置查询”装进 Mustache)
)


)

:I2C 总线上可以接多少个设备?如何保证数据的准确性?)

如何开发有监督神经网络系统?)



