目录
一、CNN概述
二、卷积层
1、卷积核
2、卷积计算
3、边缘填充
4、步长
5、多通道卷积计算
6、多卷积核卷积计算
7、特征图大小
8、卷积参数共享
9、局部特征提取
10、卷积层API
三、池化层
1、池化层概述
1.池化层的作用
2.池化层类型
2、池化层计算
3、步长
4、边缘填充
5、多通道池化计算
6、池化API
1. 最大池化 (MaxPooling)
2. 平均池化 (AvgPooling)
3. 自适应池化 (Adaptive Pooling)
四、综合
一、CNN概述
视觉处理三大任务:图像分类、目标检测、图像分割
上游:提取特征,CNN
下游:分类、目标、分割等,具体的业务
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低运算量并特征增强;全连接层类似神经网络的部分,用来输出想要的结果。
卷积操作是CNN的核心特征提取机制,包含两个关键过程:
-
卷:卷积核在输入数据上按顺序滑动(从左到右,从上到下)
-
积:卷积核与局部区域进行逐元素乘积并求和
-
局部连接
-
局部连接可以更好地利用图像中的结构信息,空间距离越相近的像素其相互影响越大。
-
根据局部特征完成目标的可辨识性。
-
-
权重共享
-
图像从一个局部区域学习到的信息应用到其他区域。
-
减少参数,降低学习难度。
-
import torch from matplotlib import pyplot as plt import torch.nn as nn import os image_path = os.path.relpath(os.path.join(os.path.dirname(__file__), 'data', '彩色.png')) # img_data (H, W, C)------>转变为(C, H, W)------>转变为(N, C, H, W) img_data = plt.imread(image_path) print(img_data.shape) img_data = torch.tensor(img_data.transpose(2, 0, 1)).unsqueeze(0) print(img_data.shape) conv1 = nn.Conv2d(in_channels=4, # 输入通道数(RGBA图像为4)out_channels=16,# 输出通道数(16个卷积核)kernel_size=3,# 卷积核大小3x3stride=1, # 步长为1 ) # conv1 ----->(1,16,499,498) conv2 = nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1, ) # conv2 ----->(1,32,497,496) conv3 = nn.Conv2d(in_channels=32,out_channels=2,kernel_size=3,stride=1, ) # conv3 ----->(1,2,495,494) # out = conv1(img_data) out = conv2(out) out = conv3(out) out_ = out.squeeze(0)[1] print(out_.shape) # out = out.squeeze(0).detach().numpy().transpose(1, 2, 0) # # plt.imshow(out) # plt.show()
二、卷积层
1、卷积核
卷积核是卷积运算过程中必不可少的一个“工具”,在卷积神经网络中,卷积核是非常重要的,它们被用来提取图像中的特征。
卷积核其实是一个小矩阵,在定义时需要考虑以下几方面的内容:
-
卷积核的个数:卷积核(过滤器)的个数决定了其输出特征矩阵的通道数。
-
卷积核的值:卷积核的值是初始化好的,后续进行更新。
-
卷积核的大小:常见的卷积核有1×1、3×3、5×5等,一般都是奇数 × 奇数。
2、卷积计算
卷积的重要性在于它可以将图像中的特征与卷积核进行卷积操作,从而提取出图像中的特征。
可以通过不断调整卷积核的大小、卷积核的值和卷积操作的步长,可以提取出不同尺度和位置的特征。
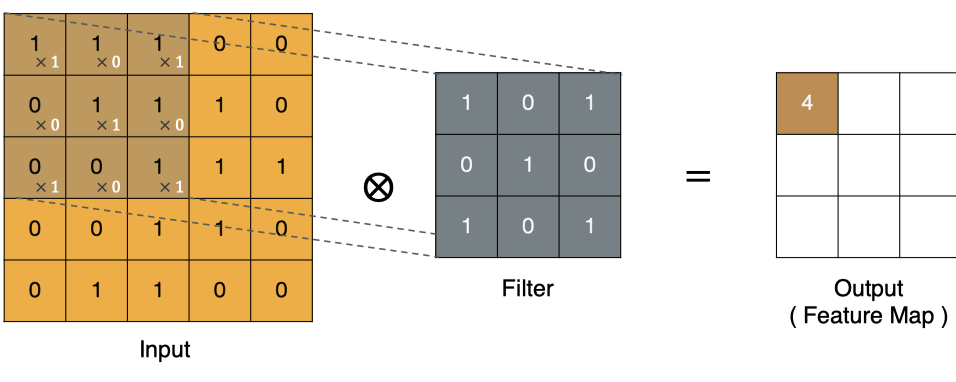
-
input 表示输入的图像
-
filter 表示卷积核, 也叫做滤波器
-
output 经过 filter 的得到输出为最右侧的图像,该图叫做特征图
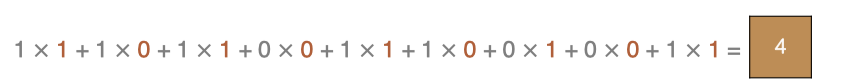
3、边缘填充
边缘填充还更好的保护了图像边缘数据的特征。
通过上面的卷积计算,我们发现最终的特征图比原始图像要小,如果想要保持图像大小不变, 可在原图周围添加padding来实现。
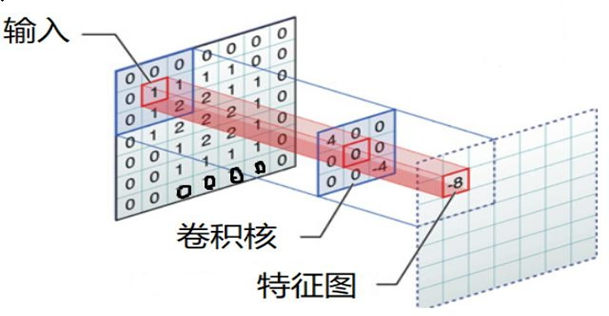
4、步长
按照步长为1来移动卷积核,计算特征图如下所示:

如果我们把 Stride 增大为2,也是可以提取特征图的,如下图所示:

stride太小:重复计算较多,计算量大,训练效率降低; stride太大:会造成信息遗漏,无法有效提炼数据背后的特征;
示例:
import torch.nn as nn import torch def test1(input):conv = nn.Conv2d(in_channels=3, #输入通道数out_channels=128, #输出通道数kernel_size=3, #卷积核大小stride=1,#步长bias=True #使用偏置顶padding #)name_par=conv.named_parameters() #for name, param in name_par:print(name, param.size())out = conv(input)return out if __name__ == '__main__':input_data = torch.randn(5,3,224,224)out = test1(input_data)print(out.shape)
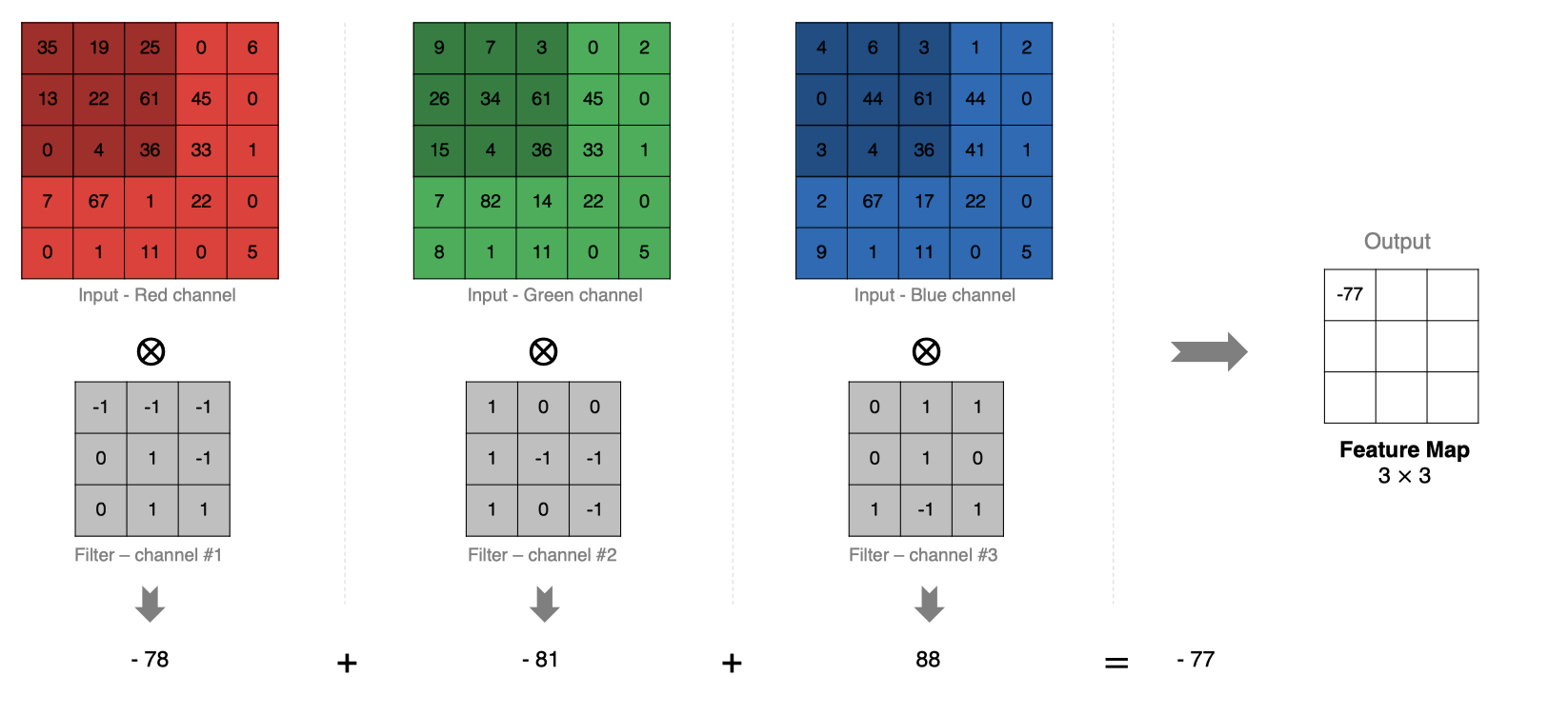
5、多通道卷积计算
计算方法如下:
-
当输入有多个通道(Channel), 例如RGB三通道, 此时要求卷积核需要有相同的通道数。
-
卷积核通道与对应的输入图像通道进行卷积。
-
将每个通道的卷积结果按位相加得到最终的特征图。
6、多卷积核卷积计算
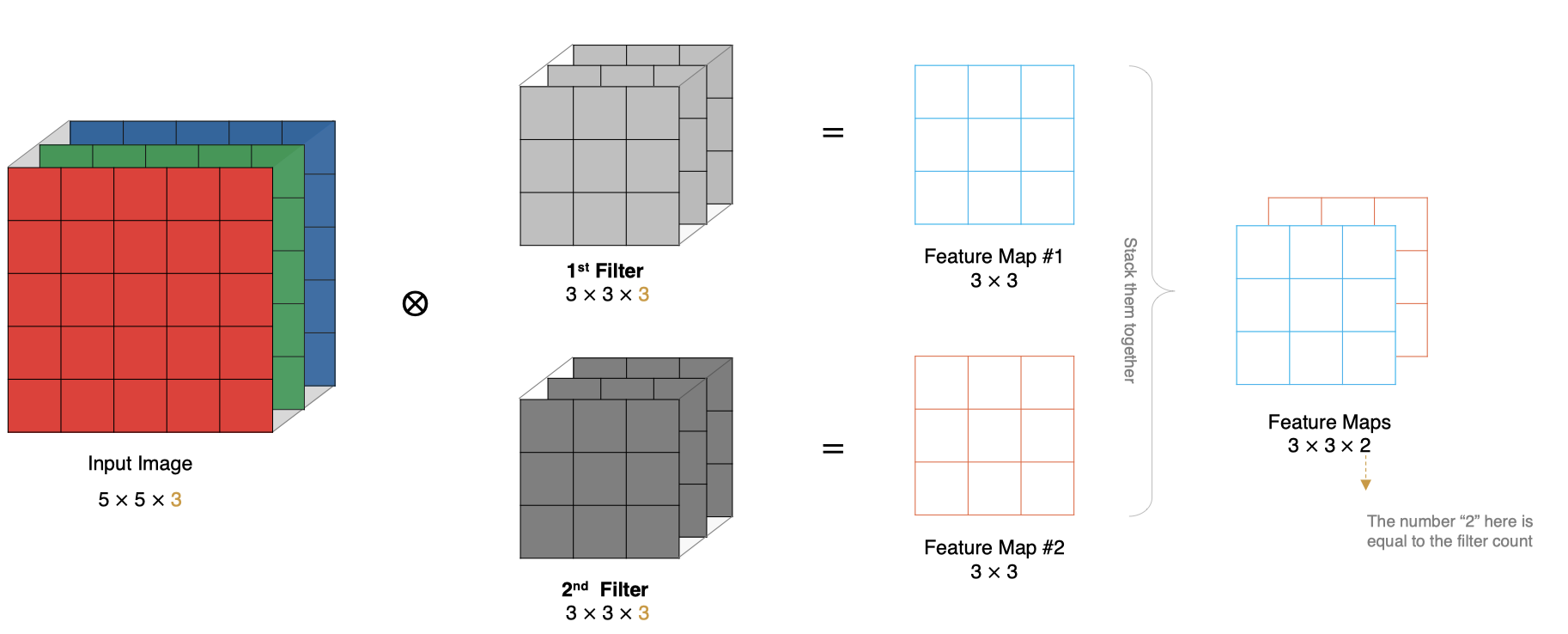
7、特征图大小
输出特征图的大小与以下参数息息相关:
-
size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1×1, 3×3, 5×5
-
Padding: 零填充的方式
-
Stride: 步长
那计算方法如下图所示:
-
输入图像大小: W x W
-
卷积核大小: F x F
-
Stride: S
-
Padding: P
-
输出图像大小: N x N
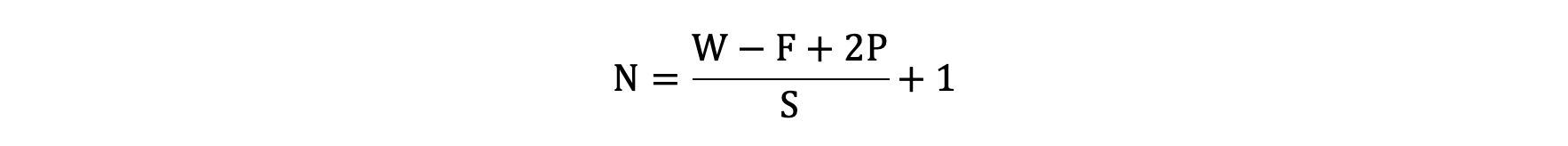
8、卷积参数共享
-
减少参数量 同一卷积核在整个输入图像上滑动使用,避免每个位置学习独立权重。 示例:
1000×1000输入图像 + 全连接层 → 需10^6权重/神经元 同场景3×3卷积核 → 仅需 9个权重(减少 > 10万倍!) -
保障平移不变性(Translation Invariance) 相同特征(如边缘)无论出现在图像何处,均由同一卷积核检测
9、局部特征提取
-
聚焦局部模式 卷积核仅连接输入的小局部区域(如
3×3),避免全连接对全局噪声敏感。 -
分层特征抽象: 浅层提取基础特征(边缘/纹理) → 中层组合局部结构 → 高层理解语义对象。
10、卷积层API
1. nn.Conv1d - 一维卷积
torch.nn.Conv1d(in_channels, # 输入通道数out_channels, # 输出通道数(卷积核数量)kernel_size, # 卷积核大小(整数或元组)stride=1, # 步长(默认1)padding=0, # 填充(默认0)dilation=1, # 空洞卷积率(默认1)groups=1, # 分组卷积设置(默认1)bias=True, # 是否使用偏置(默认True)padding_mode='zeros' # 填充模式(默认'zeros') )
应用场景:时序数据、文本处理、音频信号
2. nn.Conv2d - 二维卷积(最常用)
torch.nn.Conv2d(in_channels, # 输入通道数(如RGB图像为3)out_channels, # 输出通道数(特征图数量)kernel_size, # 卷积核大小(整数或元组,如3或(3,3))stride=1, # 步长(默认1)padding=0, # 填充(默认0,可设为整数或元组)dilation=1, # 空洞卷积(默认1)groups=1, # 分组卷积(默认1,groups=in_channels时为深度可分离卷积)bias=True, # 偏置项(默认True)padding_mode='zeros' # 填充模式('zeros', 'reflect', 'replicate', 'circular') )
应用场景:图像处理、计算机视觉任务
3. nn.Conv3d - 三维卷积
torch.nn.Conv3d(in_channels, # 输入通道数out_channels, # 输出通道数kernel_size, # 卷积核大小stride=1, # 步长padding=0, # 填充dilation=1, # 空洞卷积groups=1, # 分组卷积bias=True, # 偏置padding_mode='zeros' )
应用场景:视频处理、医学影像(3D体数据)
三、池化层
1、池化层概述
1.池化层的作用
-
降低空间维度:减小特征图尺寸
-
减少计算量:加速模型训练和推理
-
增强特征鲁棒性:提供平移/旋转不变性
-
防止过拟合:减少参数数量
-
特征提取:保留显著特征(最大池化)或整体特征(平均池化)
2.池化层类型
| 类型 | 计算方式 | 特点 | 适用场景 |
|---|---|---|---|
| 最大池化 | 取局部区域最大值 | 保留显著特征 | 纹理、边缘检测 |
| 平均池化 | 取局部区域平均值 | 平滑特征 | 背景特征提取 |
| 自适应池化 | 自动调整输出尺寸 | 固定输出大小 | 全连接层前 |
2、池化层计算
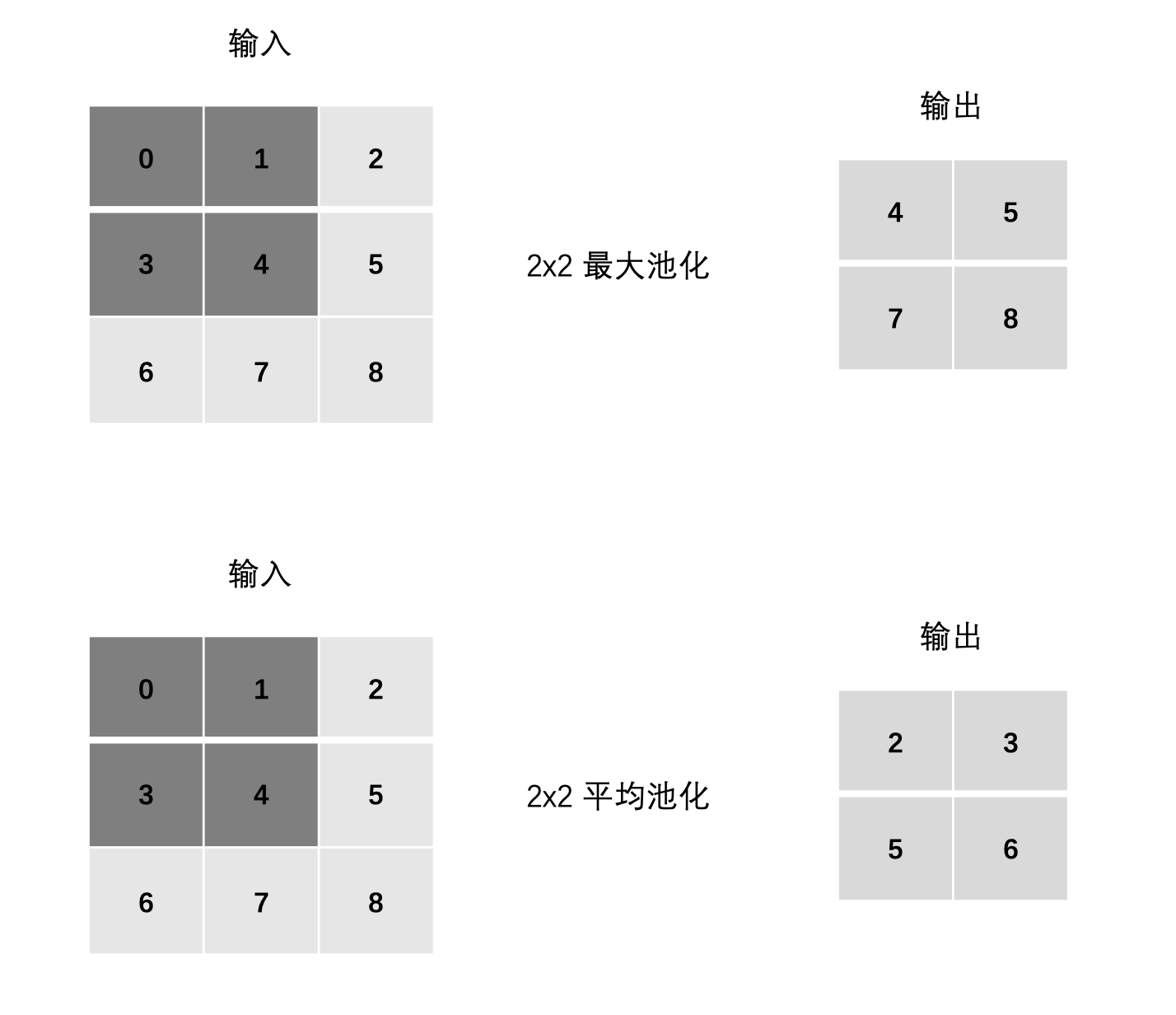
最大池化:
-
max(0, 1, 3, 4)
-
max(1, 2, 4, 5)
-
max(3, 4, 6, 7)
-
max(4, 5, 7, 8)
平均池化:
-
mean(0, 1, 3, 4)
-
mean(1, 2, 4, 5)
-
mean(3, 4, 6, 7)
-
mean(4, 5, 7, 8)
3、步长
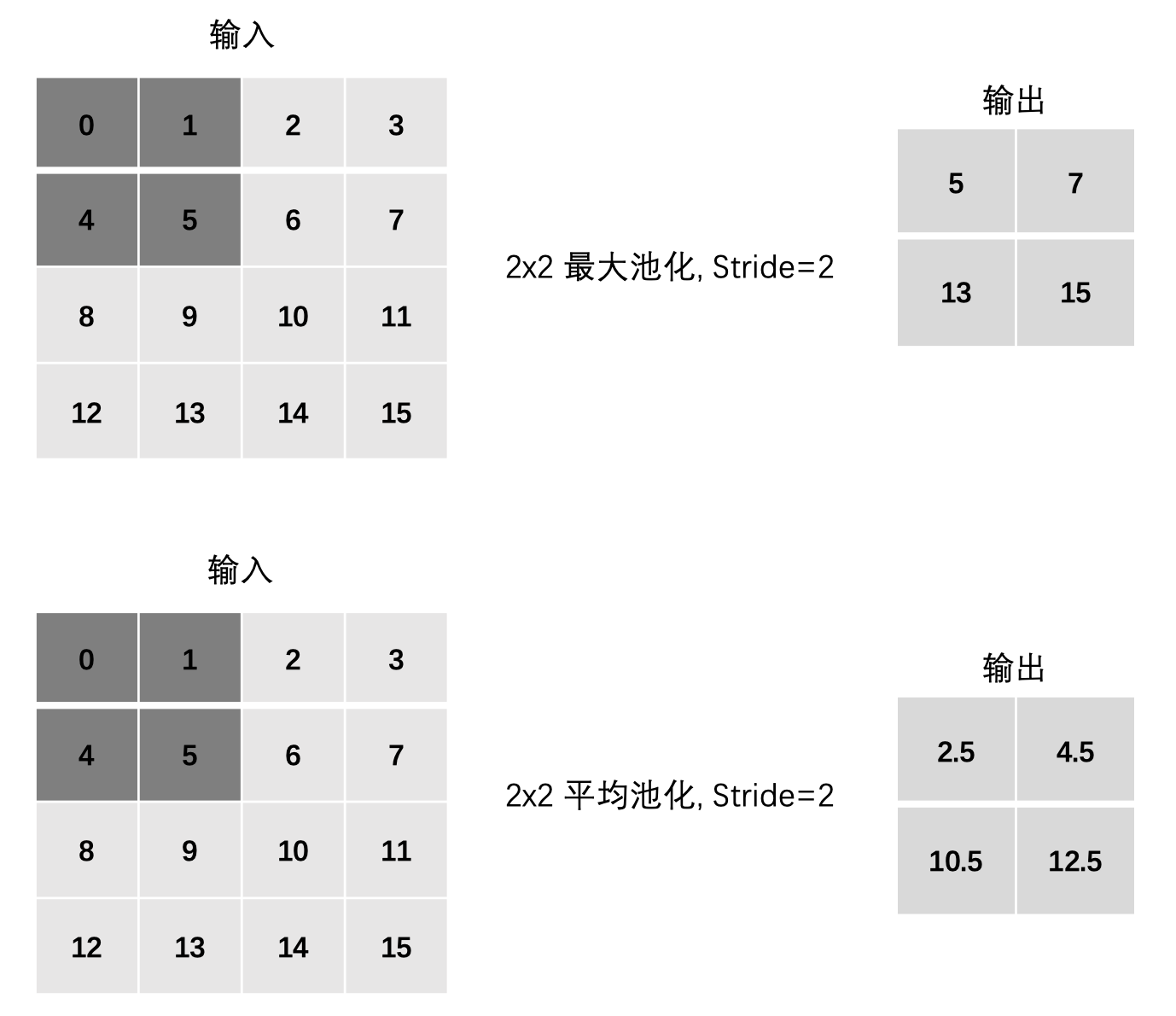
最大池化:
-
max(0, 1, 4, 5)
-
max(2, 3, 6, 7)
-
max(8, 9, 12, 13)
-
max(10, 11, 14, 15)
平均池化:
-
mean(0, 1, 4, 5)
-
mean(2, 3, 6, 7)
-
mean(8, 9, 12, 13)
-
mean(10, 11, 14, 15)
4、边缘填充
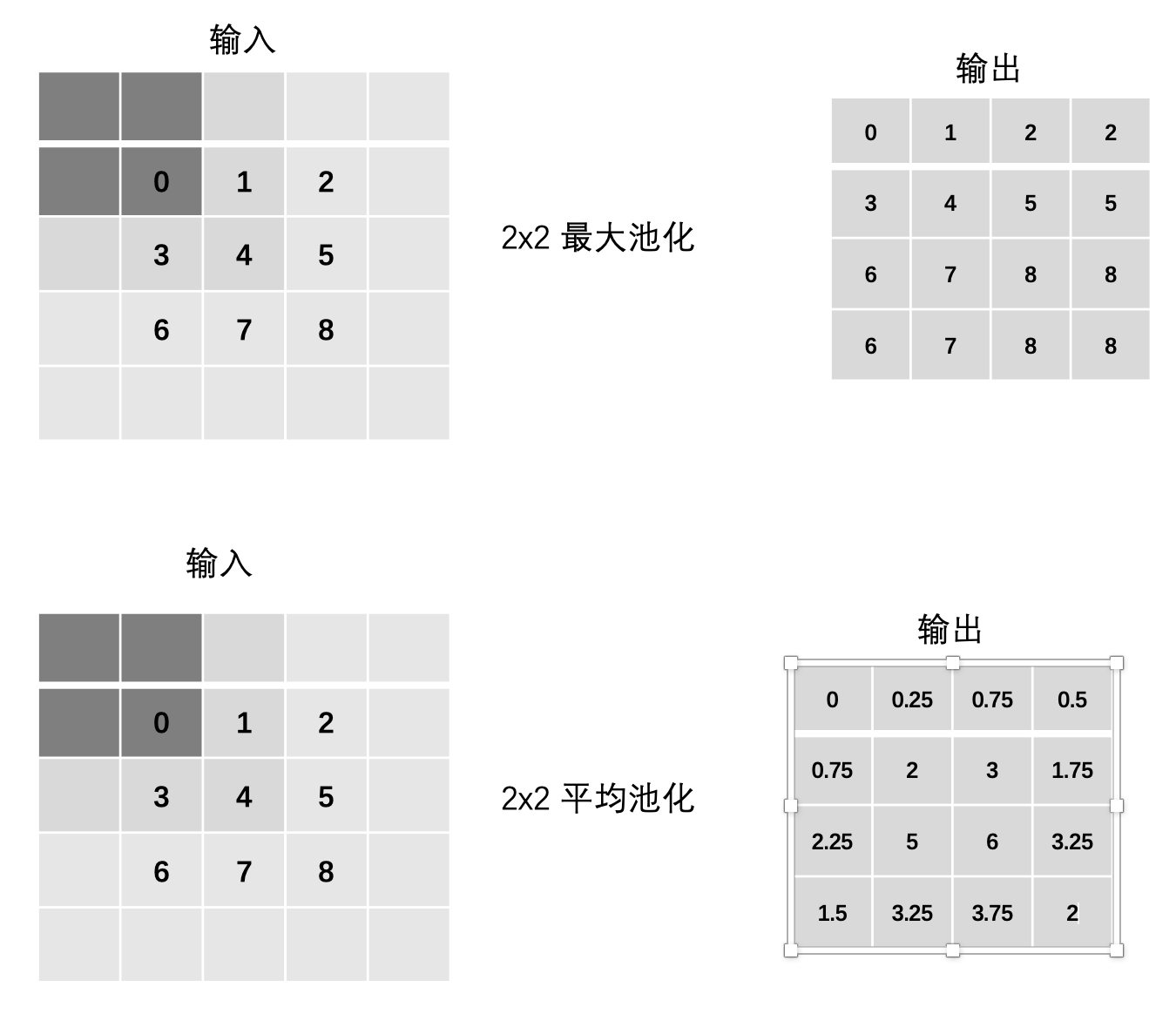
最大池化:
-
max(0, 0, 0, 0)
-
max(0, 0, 0, 1)
-
max(0, 0, 1, 2)
-
max(0, 0, 2, 0)
-
... 以此类推
平均池化:
-
mean(0, 0, 0, 0)
-
mean(0, 0, 0, 1)
-
mean(0, 0, 1, 2)
-
mean(0, 0, 2, 0)
-
... 以此类推
5、多通道池化计算
-
每个通道独立进行池化
-
输出通道数与输入通道数相同
输入 (3通道): 通道1: [[0,1,2], [3,4,5], [6,7,8]] 通道2: [[10,20,30], [40,50,60], [70,80,90]] 通道3: [[11,22,33], [44,55,66], [77,88,99]] # 2x2 最大池化 输出: 通道1: [[4,5], [7,8]] 通道2: [[50,60], [80,90]] 通道3: [[55,66], [88,99]]
6、池化API
1. 最大池化 (MaxPooling)
torch.nn.MaxPool2d(kernel_size, # 池化窗口大小 (int或tuple)stride=None, # 步长 (默认为kernel_size)padding=0, # 填充dilation=1, # 窗口间距return_indices=False, # 是否返回最大值位置ceil_mode=False # 尺寸计算模式 (True向上取整/False向下取整) )
2. 平均池化 (AvgPooling)
torch.nn.AvgPool2d(kernel_size, # 池化窗口大小stride=None, # 步长padding=0, # 填充ceil_mode=False, # 尺寸计算模式count_include_pad=True, # 是否包含填充值计算divisor_override=None # 覆盖分母值 )
3. 自适应池化 (Adaptive Pooling)
# 自适应最大池化 torch.nn.AdaptiveMaxPool2d(output_size) # 自适应平均池化 torch.nn.AdaptiveAvgPool2d(output_size)
示例:
import torch.nn as nn import torch #最大池化 def test01():input_map = torch.randn(1, 1, 7, 7)pool1=nn.MaxPool2d(kernel_size=2,stride=1,padding=0,ceil_mode=False)out=pool1(input_map)print(out.shape) #平均池化 def test02():input_map = torch.randn(1, 1, 7, 7)pool1=nn.AvgPool2d(kernel_size=2,stride=1,padding=0,ceil_mode=False)out=pool1(input_map)print(out.shape) #自适最大池化 def test03():input_map = torch.randn(1, 1, 7, 7)pool1=torch.nn.AdaptiveMaxPool2d(output_size=5)out=pool1(input_map)print(out.shape) def test04():input_map = torch.randn(1, 1, 7, 7)pool1=torch.nn.AdaptiveAvgPool2d(output_size=5)out=pool1(input_map)print(out.shape) if __name__ == '__main__':# test01()# test02()# test03()test04()
四、综合
自定义网络示例:
import torch import torch.nn as nn class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.c1 = nn.Sequential(#nn.Sequential顺序执行nn.Conv2d(in_channels=1,#输入通道out_channels=16,#输出通道kernel_size=3,#卷积核stride=1,#步长),nn.ReLU(),) self.pool2 = nn.AdaptiveMaxPool2d(output_size=22)self.c3 = nn.Conv2d(in_channels=16,out_channels=32,kernel_size=3,stride=1,)self.pool4 = nn.AdaptiveMaxPool2d(output_size=16) self.l5 = nn.Linear(#全连接层 将三维特征图展平为一维向量in_features=16*16*32,out_features=10) def forward(self, x):# x(1,16,26,26)x = self.c1(x)# x(1,16,22,22)x = self.pool2(x)# x(1,32,20,20)x = self.c3(x)# x(1,32,16,16)x = self.pool4(x)# self.l5(x.view(-1, x.size(1)*x.size(2)*x.size(3)))out = self.l5(x.view(x.size(0), -1))return out if __name__ == '__main__':input_data = torch.randn(1, 1, 28, 28)model = MyModel()out = model(input_data)print(out.shape)


前端直传)










(模拟)(对各位进行拆解))




)
