上篇我们从0开始构建了基本的环境,这篇我们继续后续的标定,遥操作,录制数据,上传,训练。
环境:显卡技嘉的5060,cpui5-13490f,主板技嘉b760m gaming,双系统ubuntu2204,win10专业版。
主要参考的教程,链接:https://huggingface.co/docs/lerobot/so101?example=Linux
环境就绪后,我们需要连接硬件,如果你还没有硬件,tb上搜soarm101可买,当然也可以自己打印,github上有开源图纸。包括硬件的连接方式组装方式这里都暂时不讲,如果你从tb买的,可以找tb客服问。这里假设你已经装好硬件,连接到主机上。
Configure the motors
1. Find the USB ports associated with each arm
python lerobot/find_port.py官方提供了找端口的py脚本,但是我没用过,linux下基本就是ttyACM0,ttyACM1,ttyACM2这几个端口,原始的方法你拔掉一个电源看哪个口没了那他就是哪个口。注意!不要热插拔,先断电源,再把数据线拔掉,后面调试的过程中始终记住,不然可能会导致电机出问题。
给予权限:
sudo chmod 666 /dev/ttyACM0
sudo chmod 666 /dev/ttyACM12. Set the motors ids and baudrates
俺找官网的视频中,逐个电机接上,然后设置id号,当然还有一种更简单的,不用动手的。如果你有一台win的电脑,下一个飞特的电机调式软件。可以参考这篇文章中更新固件部分,有下载链接。参考:lerobot-soarm100标定报错:ConnectionError: Read failed due to communication error on port /dev/ttyACM0 _lerobot机械臂校准报错-CSDN博客文章浏览阅读1k次,点赞24次,收藏29次。可能原因二:feetech舵机的固件版本需要更新,找fd的调试软件里更新。波特率最大然后开始,搜索,给每个舵机都升。升级完后再执行lerobot下标定脚本,即可成功标定。可能原因一:线缆没接好,检查控制板和电机之间的接线。每个舵机都检测更新一遍。我的是1.9.8.3。_lerobot机械臂校准报错https://blog.csdn.net/Jzzzzzzzzzzzzzz/article/details/148081567?spm=1001.2014.3001.5501
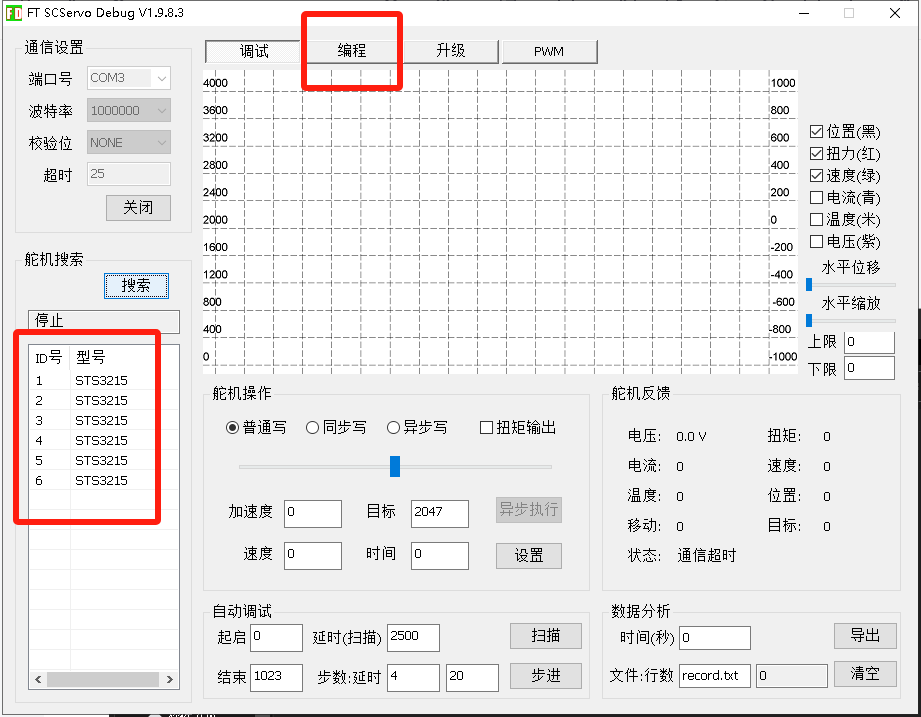
就是在编程中,逐个设置id,我这里给出b站的视频链接,可以直接照着操作。
【全球首发】LeRobot SO-ARM101 具身智能机械臂 - 组装和配置教程_哔哩哔哩_bilibiliLeRobot SO-ARM101 具身智能机械臂 - 组装和配置教程, 视频播放量 7922、弹幕量 0、点赞数 107、投硬币枚数 35、收藏人数 210、转发人数 33, 视频作者 WowRobo机器人, 作者简介 WowRobo机器人专注具身智能领域软硬件开发和应用。淘宝:WowRobo机器人企业店铺,交流Q群:517472861,相关视频:LeRobot具身智能机械臂实操入门课程-01:软件环境配置和双臂标定,30分钟装好SO-ARM100-保姆级视频组装教程-从臂,全网最低成本lerobot机械臂,机械臂运动学优秀学员作品展示第一期来啦 感谢@高质量用户 胡同学的精彩毕设分享,具身智能+机械臂创造无限可能💪💪 后面还有更多精彩等你一起来~,便宜没好货?SO100机械臂重复定位精度测试,让我们看看它能完成挑战吗?,具身智能基础技术路线,2-不到一千七百元,搭出自己的lerobot-aloha真实机械臂材料清单,Lerobot机械臂:新版本so101&虚拟舵机硬件组装,LeRobot具身智能机械臂实操入门课程-02:相机选型、接线与代码调试,LeRobot具身智能机械臂实操入门课程-03:机械臂的数据集录制与模型训练![]() https://www.bilibili.com/video/BV13bLyzKES8?t=3244.6当然也可以就按照教程中的,但是那种可能会一些朋友热插拔,而且需要逐个拔掉电机连接线,我觉得有点麻烦。
https://www.bilibili.com/video/BV13bLyzKES8?t=3244.6当然也可以就按照教程中的,但是那种可能会一些朋友热插拔,而且需要逐个拔掉电机连接线,我觉得有点麻烦。
Follower
Connect the usb cable from your computer and the power supply to the follower arm’s controller board. Then, run the following command or run the API example with the port you got from the previous step. You’ll also need to give your leader arm a name with the id parameter.
记得换成自己的端口号。
python -m lerobot.setup_motors \--robot.type=so101_follower \--robot.port=/dev/tty.usbmodem585A0076841 # <- paste here the port found at previous stepYou should see the following instruction
Connect the controller board to the 'gripper' motor only and press enter.As instructed, plug the gripper’s motor. Make sure it’s the only motor connected to the board, and that the motor itself is not yet daisy-chained to any other motor. As you press [Enter], the script will automatically set the id and baudrate for that motor.
Leader
Do the same steps for the leader arm.
python -m lerobot.setup_motors \--teleop.type=so101_leader \--teleop.port=/dev/tty.usbmodem575E0031751 # <- paste here the port found at previous stepCalibrate标定
python -m lerobot.calibrate \--robot.type=so101_follower \--robot.port=/dev/tty.usbmodem58760431551 \ # <- The port of your robot--robot.id=my_awesome_follower_arm # <- Give the robot a unique name同样记得换自己的端口号,名字改不改都行。
然后先把机械臂转至中立位,然年吧每个关节电机都动一遍,最大角度和最小角度都动到,他会一直遍历当下角度值,取最大最小,实现标定。
参考视频:https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/lerobot/calibrate_so101_2.mp4![]() https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/lerobot/calibrate_so101_2.mp4
https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/lerobot/calibrate_so101_2.mp4
Leader
Do the same steps to calibrate the leader arm, run the following command or API example:
从臂做相同的事情。
python -m lerobot.calibrate \--teleop.type=so101_leader \--teleop.port=/dev/tty.usbmodem58760431551 \ # <- The port of your robot--teleop.id=my_awesome_leader_arm # <- Give the robot a unique nameTeleoperate遥操作
完成标定后我们就可以尝试遥操作,即主臂控制从臂。后面的训练需要我们通过遥操作录制训练数据。依旧修改端口号。
python -m lerobot.teleoperate \--robot.type=so101_follower \--robot.port=/dev/tty.usbmodem58760431541 \--robot.id=my_awesome_follower_arm \--teleop.type=so101_leader \--teleop.port=/dev/tty.usbmodem58760431551 \--teleop.id=my_awesome_leader_armTeleoperate with cameras 带摄像头的遥操
相同的命令再加上摄像头的使能,注意,官网给的教程有点小问题,给的是koch机械臂,我们要换位我们的so101
python -m lerobot.teleoperate \--robot.type=so101_follower \--robot.port=/dev/tty.usbmodem58760431541 \--robot.id=my_awesome_follower_arm \--teleop.type=so101_leader \--teleop.port=/dev/tty.usbmodem58760431551 \--teleop.id=my_awesome_leader_arm--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \--teleop.type=koch_leader \--display_data=trueAdd your token to the CLI by running this command:在这里把token换成自己的api key,获得方式同样是上huggingface官网注册,创建自己的数据仓库,然后获取key。
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential检查下输出是否是自己的huggingface的用户名。
HF_USER=$(huggingface-cli whoami | head -n 1)
echo $HF_USER一切都就绪后,可以开始录制数据。
python -m lerobot.record \--robot.type=so101_follower \--robot.port=/dev/tty.usbmodem585A0076841 \ --robot.id=my_awesome_follower_arm \--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \--teleop.type=so101_leader \--teleop.port=/dev/tty.usbmodem58760431551 \--teleop.id=my_awesome_leader_arm \--display_data=true \--dataset.repo_id=${HF_USER}/record-test \--dataset.num_episodes=2 \--dataset.single_task="Grab the black cube"注意换端口号,会有语音提示,录如episodes0,1等,或者看rerun界面,当无法遥操时录制结束。
接下来,又能会有的问题来了。报错如下:
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ python -m lerobot.teleoperate --robot.type=so101_follower --robot.port=/dev/ttyACM1 --robot.id=my_awesome_follower_arm --teleop.type=so101_leader --teleop.port=/dev/ttyACM2 --teleop.id=my_awesome_leader_arm --display_data=true --robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \ > [2025-06-23T08:26:10Z INFO re_grpc_server] Listening for gRPC connections on 0.0.0.0:9876. Connect by running `rerun --connect rerun+http://127.0.0.1:9876/proxy` [2025-06-23T08:26:10Z WARN wgpu_hal::gles::egl] Re-initializing Gles context due to Wayland window [2025-06-23T08:26:10Z INFO egui_wgpu] There were 2 available wgpu adapters: {backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver: "llvmpipe", driver_info: "Mesa 23.2.1-1ubuntu3.1~22.04.3 (LLVM 15.0.7)", vendor: Mesa (0x10005)}, {backend: Gl, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver_info: "4.5 (Core Profile) Mesa 23.2.1-1ubuntu3.1~22.04.3", vendor: Mesa (0x10005)} [2025-06-23T08:26:10Z WARN re_renderer::context] Software rasterizer detected - expect poor performance. See: https://www.rerun.io/docs/getting-started/troubleshooting#graphics-issues [2025-06-23T08:26:10Z INFO re_renderer::context] wgpu adapter backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver: "llvmpipe", driver_info: "Mesa 23.2.1-1ubuntu3.1~22.04.3 (LLVM 15.0.7)" /home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py:87: DeprecationWarning: since 0.23.0: Use `Scalars` instead. rr.log(f"observation_{obs}", rr.Scalar(val)) /home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py:92: DeprecationWarning: since 0.23.0: Use `Scalars` instead. rr.log(f"action_{act}", rr.Scalar(val)) --------------------------- NAME | NORM shoulder_pan.pos | 13.38 shoulder_lift.pos | -98.73 elbow_flex.pos | 99.46 wrist_flex.pos | 46.98 wrist_roll.pos | 0.88 gripper.pos | 5.88 time: 67.44ms (15 Hz) Traceback (most recent call last): File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 196, in _run_module_as_main return _run_code(code, main_globals, None, File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 86, in _run_code exec(code, run_globals) File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 137, in <module> teleoperate() (lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ 10/site-packages/draccus/argparsing.py", line 225, in wrapper_inner (lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 126, in teleoperate teleop_loop(teleop, robot, cfg.fps, display_data=cfg.display_data, duration=cfg.teleop_time_s) File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 84, in teleop_loop observation = robot.get_observation() File "/home/dora/dora_ws/lerobot_v2/lerobot/common/robots/so101_follower/so101_follower.py", line 167, in get_observation obs_dict[cam_key] = cam.async_read() File "/home/dora/dora_ws/lerobot_v2/lerobot/common/cameras/opencv/camera_opencv.py", line 448, in async_read raise TimeoutError( TimeoutError: Timed out waiting for frame from camera OpenCVCamera(0) after 200 ms. Read thread alive: True.
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ python -m lerobot.teleoperate --robot.type=so101_follower --robot.port=/dev/ttyACM1 --robot.id=my_awesome_follower_arm --teleop.type=so101_leader --teleop.port=/dev/ttyACM2 --teleop.id=my_awesome_leader_arm --display_data=true --robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \
> [2025-06-23T08:26:10Z INFO re_grpc_server] Listening for gRPC connections on 0.0.0.0:9876. Connect by running `rerun --connect rerun+http://127.0.0.1:9876/proxy`
[2025-06-23T08:26:10Z WARN wgpu_hal::gles::egl] Re-initializing Gles context due to Wayland window
[2025-06-23T08:26:10Z INFO egui_wgpu] There were 2 available wgpu adapters: {backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver: "llvmpipe", driver_info: "Mesa 23.2.1-1ubuntu3.1~22.04.3 (LLVM 15.0.7)", vendor: Mesa (0x10005)}, {backend: Gl, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver_info: "4.5 (Core Profile) Mesa 23.2.1-1ubuntu3.1~22.04.3", vendor: Mesa (0x10005)}
[2025-06-23T08:26:10Z WARN re_renderer::context] Software rasterizer detected - expect poor performance. See: https://www.rerun.io/docs/getting-started/troubleshooting#graphics-issues
[2025-06-23T08:26:10Z INFO re_renderer::context] wgpu adapter backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver: "llvmpipe", driver_info: "Mesa 23.2.1-1ubuntu3.1~22.04.3 (LLVM 15.0.7)"
/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py:87: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"observation_{obs}", rr.Scalar(val))
/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py:92: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"action_{act}", rr.Scalar(val))---------------------------
NAME | NORM
shoulder_pan.pos | 13.38
shoulder_lift.pos | -98.73
elbow_flex.pos | 99.46
wrist_flex.pos | 46.98
wrist_roll.pos | 0.88
gripper.pos | 5.88time: 67.44ms (15 Hz)
Traceback (most recent call last):File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 196, in _run_module_as_mainreturn _run_code(code, main_globals, None,File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 86, in _run_codeexec(code, run_globals)File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 137, in <module>teleoperate()
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ 10/site-packages/draccus/argparsing.py", line 225, in wrapper_inner
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 126, in teleoperateteleop_loop(teleop, robot, cfg.fps, display_data=cfg.display_data, duration=cfg.teleop_time_s)File "/home/dora/dora_ws/lerobot_v2/lerobot/teleoperate.py", line 84, in teleop_loopobservation = robot.get_observation()File "/home/dora/dora_ws/lerobot_v2/lerobot/common/robots/so101_follower/so101_follower.py", line 167, in get_observationobs_dict[cam_key] = cam.async_read()File "/home/dora/dora_ws/lerobot_v2/lerobot/common/cameras/opencv/camera_opencv.py", line 448, in async_readraise TimeoutError(
TimeoutError: Timed out waiting for frame from camera OpenCVCamera(0) after 200 ms. Read thread alive: True.开始时成功启动的,但是立马就终止了。
TimeoutError: Timed out waiting for frame from camera OpenCVCamera(0) after 200 ms. Read thread alive: True.问题来自于这里,超时了。报错给出了警告。
[2025-06-23T08:26:10Z WARN re_renderer::context] Software rasterizer detected - expect poor performance. See: https://www.rerun.io/docs/getting-started/troubleshooting#graphics-issues
[2025-06-23T08:26:10Z INFO re_renderer::context] wgpu adapter backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)"
[2025-06-23T08:26:10Z WARN re_renderer::context] Software rasterizer detected - expect poor performance. See: https://www.rerun.io/docs/getting-started/troubleshooting#graphics-issues
[2025-06-23T08:26:10Z INFO re_renderer::context] wgpu adapter backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)"说明我的系统没有使用硬件GPU进行图形渲染。device_type: Cpu, name: "llvmpipe": 而是正在使用 llvmpipe,这是一个基于CPU的软件渲染器。所以性能极差,且超时。所以解决办法就是装驱动。实测现在570.144这般驱动已经进去22.04及以后的版本,20.04的ppa仓库也已添加,这版以支持50系GPU,所以只需要在nvidia-driver-570后加open。
sudo apt install nvidia-driver-570-openNVIDIA Proprietary:表示是nvidia专有模块。
GPL/MIT:这个是使用GPL/MIT协议的开源模块。
在nvidia官方发布的帖子中,有一篇专门的说明,详见:
NVIDIA 全面转向开源 GPU 内核模块 - NVIDIA 技术博客
有一段内容是这个:
支持的 GPU
并不是每个 GPU 都能与开源 GPU 内核模块兼容。
对于 NVIDIA Grace Hopper 或 NVIDIA Blackwell 等尖端平台,您必须使用开源的 GPU 内核模块,因为这些平台不支持专有的驱动程序。
对于来自 Turing、Ampere、Ada Lovelace 或 Hopper 架构的较新 GPU,NVIDIA 建议将其切换到开源的 GPU 内核模块。
对于 Maxwell、Pascal 或 Volta 架构中的旧版 GPU,其开源 GPU 内核模块不兼容您的平台。因此,请继续使用 NVIDIA 专有驱动。
对于在同一系统中混合部署较旧和较新 GPU,请继续使用专有驱动程序。
因为50系列是Blackwell架构,所以需要选择gpl的开源内核模块。
参考的文章: https://minetest.top/archives/zai-linuxxia-wei-nvidia-50xi-an-zhuang-xian-qia-qu-dong![]() https://minetest.top/archives/zai-linuxxia-wei-nvidia-50xi-an-zhuang-xian-qia-qu-dong
https://minetest.top/archives/zai-linuxxia-wei-nvidia-50xi-an-zhuang-xian-qia-qu-dong
安装完后,输入下面命令检查,并看自己的cuda版本,后面还需要装pytorch的环境,需要和cuda版本对应。我这里是cuda=12.8
nvidia-smiok那我们继续。再次运行上面的命令。写到这里才发现,上面报错的命令其实执行的其实是带摄像头的遥操,不过不要紧,总归是要装显卡驱动的。下面才执行的是录制的命令,但是报错一致,仍然是超时,我们来查看错误信息。
(lerobot) dora@dora-B760M-GAMING:~/dora_ws$ python -m lerobot.record \--robot.type=so101_follower \--robot.port=/dev/ttyACM1 \--robot.id=my_awesome_follower_arm \--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 1920, height: 1080, fps: 30}}" \--teleop.type=so101_leader \--teleop.port=/dev/ttyACM2 \--teleop.id=my_awesome_leader_arm \--display_data=true \--dataset.repo_id=${HF_USER}/record-test \--dataset.num_episodes=2 \--dataset.single_task="Grab the blue cube"
[2025-06-23T09:01:57Z INFO re_grpc_server] Listening for gRPC connections on 0.0.0.0:9876. Connect by running `rerun --connect rerun+http://127.0.0.1:9876/proxy`
[2025-06-23T09:01:57Z INFO winit::platform_impl::linux::x11::window] Guessed window scale factor: 1
[2025-06-23T09:01:57Z WARN wgpu_hal::gles::egl] No config found!
[2025-06-23T09:01:57Z WARN wgpu_hal::gles::egl] EGL says it can present to the window but not natively
[2025-06-23T09:01:57Z WARN wgpu_hal::gles::adapter] Max vertex attribute stride unknown. Assuming it is 2048
[2025-06-23T09:01:57Z WARN wgpu_hal::gles::adapter] Max vertex attribute stride unknown. Assuming it is 2048
[2025-06-23T09:01:57Z INFO egui_wgpu] There were 3 available wgpu adapters: {backend: Vulkan, device_type: DiscreteGpu, name: "NVIDIA Graphics Device", driver: "NVIDIA", driver_info: "570.133.07", vendor: NVIDIA (0x10DE), device: 0x2D04}, {backend: Vulkan, device_type: Cpu, name: "llvmpipe (LLVM 15.0.7, 256 bits)", driver: "llvmpipe", driver_info: "Mesa 23.2.1-1ubuntu3.1~22.04.3 (LLVM 15.0.7)", vendor: Mesa (0x10005)}, {backend: Gl, device_type: Other, name: "NVIDIA Graphics Device/PCIe/SSE2", driver_info: "3.3.0 NVIDIA 570.133.07", vendor: NVIDIA (0x10DE)}
/home/dora/dora_ws/lerobot_v2/lerobot/record.py:226: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"observation.{obs}", rr.Scalar(val))
/home/dora/dora_ws/lerobot_v2/lerobot/record.py:231: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"action.{act}", rr.Scalar(val))
/home/dora/dora_ws/lerobot_v2/lerobot/record.py:226: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"observation.{obs}", rr.Scalar(val))
/home/dora/dora_ws/lerobot_v2/lerobot/record.py:231: DeprecationWarning: since 0.23.0: Use `Scalars` instead.rr.log(f"action.{act}", rr.Scalar(val))
Traceback (most recent call last):File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 196, in _run_module_as_mainreturn _run_code(code, main_globals, None,File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/runpy.py", line 86, in _run_codeexec(code, run_globals)File "/home/dora/dora_ws/lerobot_v2/lerobot/record.py", line 346, in <module>record()File "/home/dora/dora_ws/lerobot_v2/lerobot/configs/parser.py", line 226, in wrapper_innerresponse = fn(cfg, *args, **kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/record.py", line 308, in recordrecord_loop(File "/home/dora/dora_ws/lerobot_v2/lerobot/common/datasets/image_writer.py", line 36, in wrapperraise eFile "/home/dora/dora_ws/lerobot_v2/lerobot/common/datasets/image_writer.py", line 29, in wrapperreturn func(*args, **kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/record.py", line 189, in record_loopobservation = robot.get_observation()File "/home/dora/dora_ws/lerobot_v2/lerobot/common/robots/so101_follower/so101_follower.py", line 167, in get_observationobs_dict[cam_key] = cam.async_read()File "/home/dora/dora_ws/lerobot_v2/lerobot/common/cameras/opencv/camera_opencv.py", line 448, in async_readraise TimeoutError(
TimeoutError: Timed out waiting for frame from camera OpenCVCamera(0) after 200 ms. Read thread alive: True.
FATAL: exception not rethrown
已中止 (核心已转储)通过输出我们可以看到,显卡驱动已经装上
INFO egui_wgpu] There were 3 available wgpu adapters: {backend: Vulkan, device_type: DiscreteGpu, name: "NVIDIA Graphics Device", driver: "NVIDIA", driver_info: "570.133.07", vendor: NVIDIA (0x10DE), device: 0x2D04} ...让我们来分析一下 lerobot.teleoperate 和 lerobot.record 的区别:
teleoperate: 主要任务是 读取遥控臂数据 -> 发送给机器人 -> 读取摄像头 -> 在屏幕上显示。
它对性能的要求主要是实时显示。虽然卡卡的但是能显示。
record: 在 teleoperate 的基础上,增加了极其耗费资源的任务:将每一帧数据处理、编码并写入硬盘。
所以问题就是目前处理性能达到了极限,不够了:
与两个机器人进行低延迟USB串口通信。 从摄像头捕获1080p30fps的高带宽视频流。 对每一帧1080p的图像进行编码并写入硬盘。最关键的负载是:图像编码和磁盘I/O非常消耗CPU和系统资源。当主循环忙于处理和保存上一帧图像时,它就没空在200毫秒内去向摄像头请求下一帧了,从而导致超时。 尽管GPU现在可以帮助显示,但标准的OpenCV图像捕获和 lerobot 的数据保存逻辑主要是由CPU执行的(这一段话来自gemini2.5pro)。因此,即使GPU驱动好了,CPU和磁盘I/O仍然是瓶颈。
所以我们确定瓶颈是录制(写磁盘)而不是捕获(读摄像头)所以需要减小我们的负载,直接办法在 record 命令中降低摄像头的分辨率。命令如下:
python -m lerobot.record \--robot.type=so101_follower \--robot.port=/dev/ttyACM1 \--robot.id=my_awesome_follower_arm \--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}}" \--teleop.type=so101_leader \--teleop.port=/dev/ttyACM2 \--teleop.id=my_awesome_leader_arm \--display_data=true \--dataset.repo_id=${HF_USER}/record-test \--dataset.num_episodes=2 \--dataset.single_task="Grab the blue cube"将分辨率从 1920x1080 大幅降低到了 640x480。每一帧的数据量减小了约9倍。很好,现在不仅实时显示的很流畅,录制问题也解决了。
录制完成,我们现在可以去huggingface上看一眼我们录制的数据。
如何管理 Hugging Face 上的数据集?
刚刚的命令: --dataset.repo_id=${HF_USER}/record-test1 实际上已经创建并上传到了一个全新的仓库。
假设你的Hugging Face用户名($HF_USER)是 dora,那么现在可以https://huggingface.co/dora/record-test1 查看刚刚上传的数据集。
每次录制时,都给它起一个有意义的名字。 例如
今天录制抓蓝色方块: --dataset.repo_id=${HF_USER}/so101_grab_blue_cube
明天录制推红色球: --dataset.repo_id=${HF_USER}/so101_push_red_ball
这样做你的所有实验数据都独立保存,不会互相干扰,管理起来非常清晰。不然就像我的一开始仓库里全是只变了一个字母的数据集,自己都分不清了。
Train a policy训练
To train a policy to control your robot, use the python lerobot/scripts/train.py script. A few arguments are required. Here is an example command:执行训练命令。
这里的
--output_dir=outputs/train/act_so101_test \ 是你之前上传的数据集
--job_name=act_so101_test \是你wandb上管理的项目名字。都需要对应好,不然管理起来有些麻烦,做好名称管理后,wandb还会有多此训练的对比,会很清晰看到训练效果。
python lerobot/scripts/train.py \--dataset.repo_id=${HF_USER}/record-test1 \--policy.type=act \--output_dir=outputs/train/act_so101_test \--job_name=act_so101_test \--policy.device=cuda \--wandb.enable=trueLet’s explain the command:
- We provided the dataset as argument with
--dataset.repo_id=${HF_USER}/so101_test. - We provided the policy with
policy.type=act. This loads configurations from configuration_act.py. Importantly, this policy will automatically adapt to the number of motor states, motor actions and cameras of your robot (e.g.laptopandphone) which have been saved in your dataset. - We provided
policy.device=cudasince we are training on a Nvidia GPU, but you could usepolicy.device=mpsto train on Apple silicon. - We provided
wandb.enable=trueto use Weights and Biases for visualizing training plots. This is optional but if you use it, make sure you are logged in by runningwandb login
官方给的命令
新的问题,报错如下:
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$ python lerobot/scripts/train.py --dataset.repo_id=${HF_USER}/record-test1 --policy.type=act --output_dir=outputs/train/act_so101_test --job_name=act_so101_test --policy.device=cuda --wandb.enable=true
INFO 2025-06-23 17:37:48 ts/train.py:111 {'batch_size': 8,'dataset': {'episodes': None,Logs will be synced with wandb.
INFO 2025-06-23 17:38:04 db_utils.py:103 Track this run --> https://wandb.ai/yiming_jz-nankai-university/lerobot/runs/nsyt0nci
INFO 2025-06-23 17:38:04 ts/train.py:127 Creating dataset
Generating train split: 3593 examples [00:00, 24028.44 examples/s]
INFO 2025-06-23 17:38:07 ts/train.py:138 Creating policy
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /home/dora/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉| 44.6M/44.7M [00:06<00:00, 6.89MB/s]
Traceback (most recent call last):File "/home/dora/dora_ws/lerobot_v2/lerobot/scripts/train.py", line 288, in <module>train()File "/home/dora/dora_ws/lerobot_v2/lerobot/configs/parser.py", line 226, in wrapper_innerresponse = fn(cfg, *args, **kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/scripts/train.py", line 139, in trainpolicy = make_policy(File "/home/dora/dora_ws/lerobot_v2/lerobot/common/policies/factory.py", line 171, in make_policypolicy = policy_cls(**kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/common/policies/act/modeling_act.py", line 74, in __init__self.model = ACT(config)File "/home/dora/dora_ws/lerobot_v2/lerobot/common/policies/act/modeling_act.py", line 335, in __init__backbone_model = getattr(torchvision.models, config.vision_backbone)(File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torchvision/models/_utils.py", line 142, in wrapperreturn fn(*args, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torchvision/models/_utils.py", line 228, in inner_wrapperreturn builder(*args, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torchvision/models/resnet.py", line 705, in resnet18return _resnet(BasicBlock, [2, 2, 2, 2], weights, progress, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torchvision/models/resnet.py", line 301, in _resnetmodel.load_state_dict(weights.get_state_dict(progress=progress, check_hash=True))File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torchvision/models/_api.py", line 90, in get_state_dictreturn load_state_dict_from_url(self.url, *args, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torch/hub.py", line 871, in load_state_dict_from_urldownload_url_to_file(url, cached_file, hash_prefix, progress=progress)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torch/hub.py", line 760, in download_url_to_fileraise RuntimeError(
RuntimeError: invalid hash value (expected "f37072fd", got "ab125a875db449ac29ade8b1523b786e6c2c91fe710e1ff41441f256095dd741")
(lerobot) dora@dora-B760M-GAMING:~/dora_ws/lerobot_v2$原因:由于文件校验失败,PyTorch 认定该文件已损坏或下载不完整,于是抛出了 RuntimeError,以防止使用这个坏掉的文件进行后续的训练。大概率是网络问题导致下载中出现问题,所以删了重下就可以解决。
rm -rf /home/dora/.cache/torch/hub/checkpoints在执行之前的训练命令。
又双报错了,内容如下:
INFO 2025-06-23 17:42:56 ts/train.py:202 Start offline training on a fixed dataset
Traceback (most recent call last):File "/home/dora/dora_ws/lerobot_v2/lerobot/scripts/train.py", line 288, in <module>train()File "/home/dora/dora_ws/lerobot_v2/lerobot/configs/parser.py", line 226, in wrapper_innerresponse = fn(cfg, *args, **kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/scripts/train.py", line 212, in traintrain_tracker, output_dict = update_policy(File "/home/dora/dora_ws/lerobot_v2/lerobot/scripts/train.py", line 71, in update_policyloss, output_dict = policy.forward(batch)File "/home/dora/dora_ws/lerobot_v2/lerobot/common/policies/act/modeling_act.py", line 147, in forwardbatch = self.normalize_inputs(batch)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1751, in _wrapped_call_implreturn self._call_impl(*args, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1762, in _call_implreturn forward_call(*args, **kwargs)File "/home/dora/miniconda3/envs/lerobot/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 116, in decorate_contextreturn func(*args, **kwargs)File "/home/dora/dora_ws/lerobot_v2/lerobot/common/policies/normalize.py", line 170, in forwardassert not torch.isinf(mean).any(), _no_stats_error_str("mean")
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.不过多解释了,想了解的大家可以自行ai一下,总归就是当前环境中安装的PyTorch预编译包不适用于当前的cuda,所以我们需要根据自己的cuda版本更新一下。
先卸载
pip uninstall torch torchvision torchaudio在查版本号
nvidia-smi然后去官网:Get Started
PyTorch Build: Stable (稳定版)
Your OS: Linux Package: Pip (因为你正在用pip)
Language: Python
cuda:你刚才找的版本号。
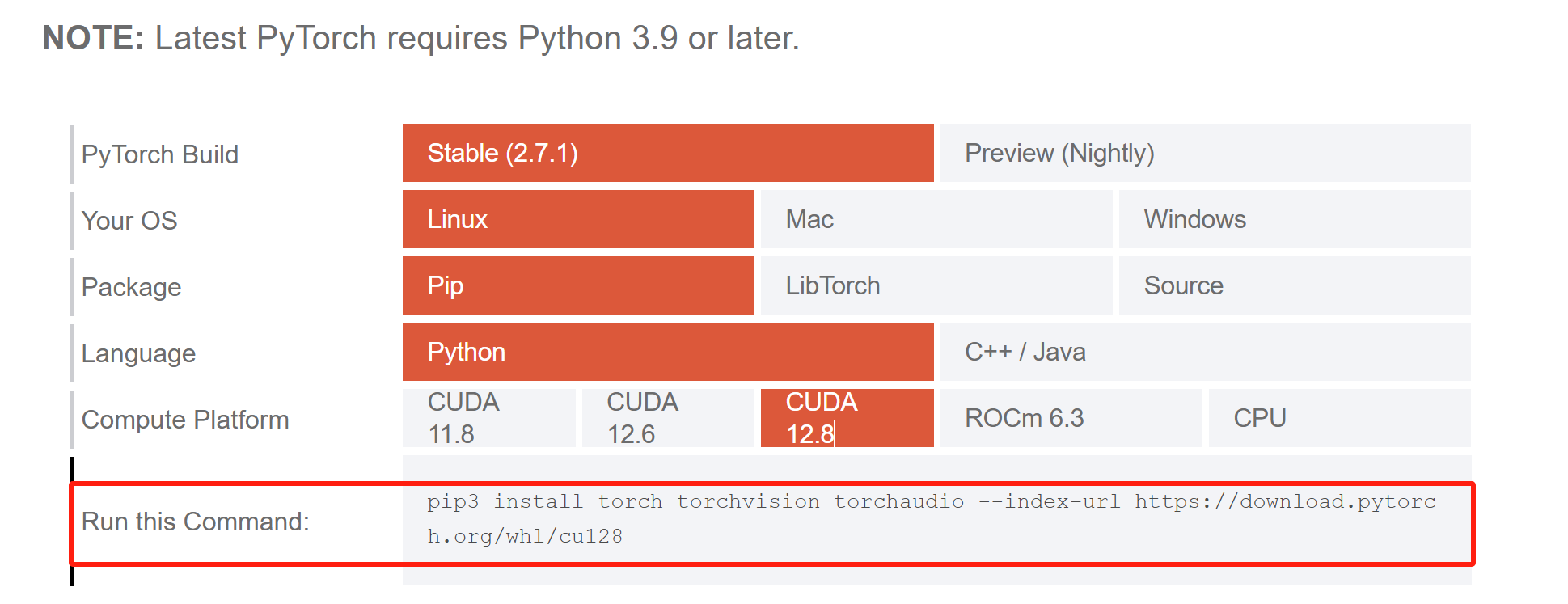
复制这整行命令,然后在你的 lerobot conda环境中执行它。
装完后验证一下:
在你的conda环境中输入python解释器:
然后输入以下代码:
import torchprint(f"PyTorch version: {torch.__version__}")print(f"CUDA available: {torch.cuda.is_available()}")如果一切正常,CUDA available 应该输出 True,并且你会看到PyTorch使用的CUDA版本和你的设备名称。
如果到这里一切就绪,再次训练,你会发现终端中开始输出一些信息表明正在训练了。同时你也可以去wandb查看训练的效果,状态。
但是,因为我们这次的目的是跑通流程,所以使用的录制训练集,只有两个episode,过少的数据集会导致过拟合,所以长时间训练没有什么意义。但是为了跑通后续的模型评估部分,我们需要一个效果很烂但是完整的模型。那么我们就需要设置好检查点,官方的教程没有设置,所以我也不知道默认会跑多久,那我们就自己设置,每2k步触发一个检查点。
python lerobot/scripts/train.py \--dataset.repo_id=${HF_USER}/record-test1 \--policy.type=act \--output_dir=outputs/train/act_so101_test \--job_name=act_soarm_2 \--policy.device=cuda \--wandb.enable=true \--save_freq=2000当训练步骤达到2000步时,脚本会自动在 outputs/train/act_so101_test/ 目录下创建一个名为 checkpoints 的文件夹。 然后它会在 checkpoints 文件夹里保存第一个模型文件,可能命名为 step_000002000.ckpt 或类似的名字。
那么到这里,基本的功能就已全部跑通,后续还会最后一个功能就是模型的评估,番外篇更新!
如果你喜欢这些机械臂小知识,或者想一起玩玩这些开源的机械臂控制,后续我们会发布更多相关优秀的指南教程,欢迎点赞关注,敬请期待~
预告预告~下一篇,lekiwi开源底座小车!!!



,鼠标绘制基本图形(直线、圆、矩形))






1.0.1 BETA》发布)



)



Leetcode155最小栈+739每日温度)
】NLP(自然语言处理)基础)