一、K8S介绍及部署
1 应用的部署方式演变
部署应用程序的方式上,主要经历了三个阶段:
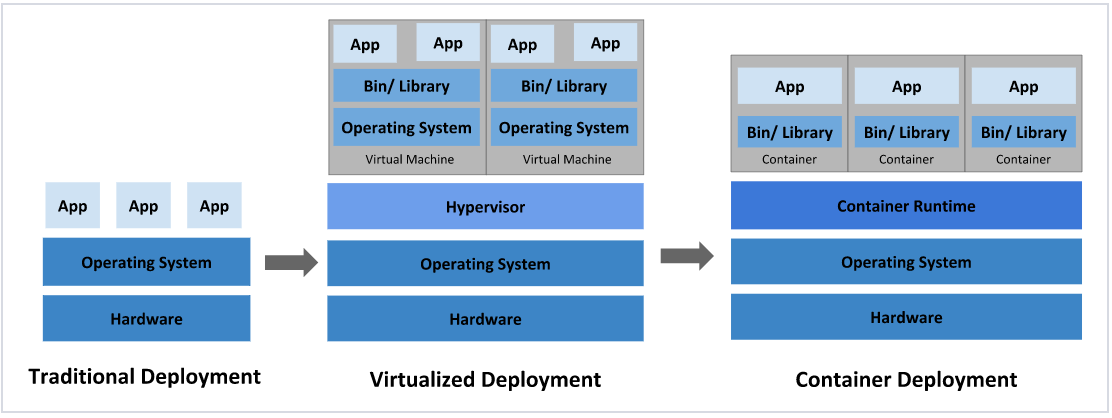
传统部署:互联网早期,会直接将应用程序部署在物理机上
-
优点:简单,不需要其它技术的参与
-
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
-
优点:程序环境不会相互产生影响,提供了一定程度的安全性
-
缺点:增加了操作系统,浪费了部分资源
容器化部署:与虚拟化类似,但是共享了操作系统
[!NOTE]
容器化部署方式给带来很多的便利,但是也会出现一些问题,比如说:
- 一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器
- 当并发访问量变大的时候,怎么样做到横向扩展容器数量
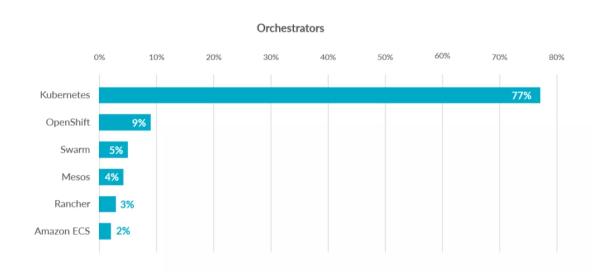
2 容器编排应用
为了解决这些容器编排问题,就产生了一些容器编排的软件:
- Swarm:Docker自己的容器编排工具
- Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
- Kubernetes:Google开源的的容器编排工具
3 kubernetes 简介

- 在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年
- Borg系统运行管理着成千上万的容器应用。
- Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
- Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户。
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
4 K8S的设计架构
1.4.1 K8S各个组件用途
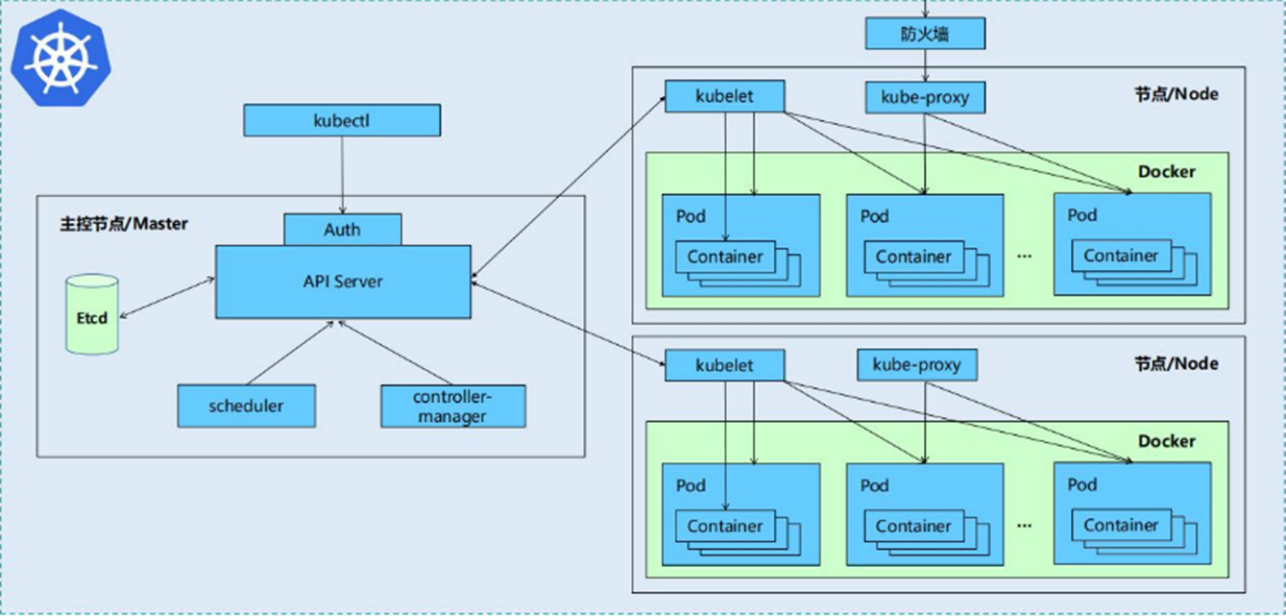
一个kubernetes集群主要是由控制节点(master)、**工作节点(node)**构成,每个节点上都会安装不同的组件
1 master:集群的控制平面,负责集群的决策
-
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
-
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
-
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
-
Etcd :负责存储集群中各种资源对象的信息
2 node:集群的数据平面,负责为容器提供运行环境
- kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
- Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
- kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
1.4.2 K8S 各组件之间的调用关系
当我们要运行一个web服务时
-
kubernetes环境启动之后,
master和node都会将自身的信息存储到etcd数据库中 -
web服务的安装请求会首先被发送到master节点的apiServer组件
-
apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上
在此时,它会从
etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer -
apiServer调用controller-manager去调度Node节点安装web服务
-
kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
-
如果需要访问web服务,就需要通过
kube-proxy来对pod产生访问的代理
1.4.3 K8S 的常用名词
-
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
-
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
-
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
-
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
-
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
-
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
-
NameSpace:命名空间,用来隔离pod的运行环境
1.4.4 k8S的分层架构
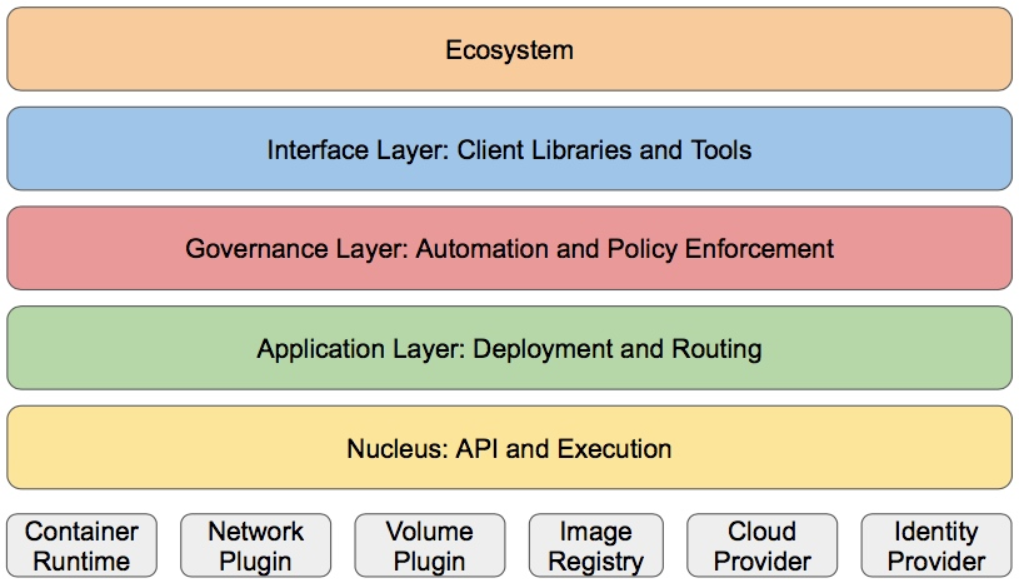
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
二 K8S集群环境搭建
2.1 k8s中容器的管理方式
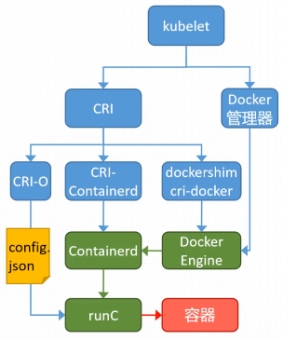
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建。
[!NOTE]
docker 和cri-o 这两种方式要对kubelet程序的启动参数进行设置
2.2 k8s 集群部署
1. 前置任务部署
- 全部主机都要设置
- 把swap给禁用掉
]# systemctl mask swap.target
]# swapoff -a
]#重启主机,无输出即可
#swapon -s]# vim /etc/fstab
#
# /etc/fstab
# Created by anaconda on Sun Feb 19 17:38:40 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/rhel-root / xfs defaults 0 0
UUID=ddb06c77-c9da-4e92-afd7-53cd76e6a94a /boot xfs defaults 0 0
#/dev/mapper/rhel-swap swap swap defaults 0 0
/dev/cdrom /media iso9660 defaults 0 0]# systemctl daemon-reload[root@k8s-master ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.147.10 K8s_slave1.zym.org
192.168.147.20 K8s_slave2.zym.org
192.168.147.100 K8s_master.zym.org
192.168.147.200 reg.zym.org
harbor配置
mkdir -p packages
cd packages
scp docker.tar.gz root@192.168.147.100:/root/packages
scp docker.tar.gz root@192.168.147.10:/root/packages
scp docker.tar.gz root@192.168.147.20:/root/packagestar zxf docker.tar.gz
dnf install *.rpm -yvim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --iptables=true
#########################systemctl enable --now docker.service#安装harbor
tar zxf harbor-offline-installer-v2.5.4.tgz
mkdir -p /data/certscd /root/packages/harbor/
cp harbor.yml.tmpl harbor.ymlvim harbor.yml
hostname: reg.zym.org
certificate: /data/certs/zym.org.crt
private_key: /data/certs/zym.org.key
harbor_admin_password: 123456
######################################./install.sh --with-chartmuseum#证书
mkdir -p /data/certs
openssl req -newkey rsa:4096 \
> -nodes -sha256 -keyout /data/certs/zym.org.key \
> -addext "subjectAltName = DNS:reg.zym.org" \
> -x509 -days 365 -out /data/certs/zym.org.crtCountry Name (2 letter code) [XX]:CN
State or Province Name (full name) []:guangxi
Locality Name (eg, city) [Default City]:cenxi
Organization Name (eg, company) [Default Company Ltd]:youeryuan
Organizational Unit Name (eg, section) []:harbor
Common Name (eg, your name or your server's hostname) []:reg.zym.org
Email Address []:admin.zym@zym.org
K8s节点
#检测SELinux是否为该状态
[root@K8smaster ~]# getenforce
Disabledtar zxf docker.tar.gz
dnf install *.rpm -yvim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --iptables=true
###########################在Harbor传输密钥
[root@Harbor ~]# for i in 100 10 20; do ssh -l root 192.168.147.$i mkdir -p /etc/docker/certs.d; scp /data/certs/zym.org.crt root@192.168.147.$i:/etc/docker/certs.d/ca.crt; done#继续配置节点
vim /etc/docker/daemon.json
{"registry-mirrors" : ["https://reg.zym.org"]
}
#指定的是Harbor仓库的主机地址systemctl enable --now docker.service
登录进Harbor仓库
[root@K8smaster ~]# cd /etc/docker/certs.d
[root@K8smaster certs.d]# mkdir -p reg.zym.org
[root@K8smaster certs.d]# mv ca.crt reg.zym.org/
[root@K8smaster certs.d]# ls
reg.zym.org
[root@K8smaster certs.d]# docker login reg.zym.org
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-storesLogin Succeeded
2. 安装K8s
三台主机均安装
#此为源码安装
[root@K8smaster ~]# mkdir -p mnt
[root@K8smaster ~]# cd mnt/
[root@K8smaster mnt]# ls
cri-dockerd-0.3.14-3.el8.x86_64.rpm k8s-1.30.tar.gz libcgroup-0.41-19.el8.x86_64.rpm
[root@K8smaster mnt]# dnf install *.rpm -y[root@K8smaster ~]# vim /lib/systemd/system/cri-docker.service
#指定网络插件名称及基础容器镜像
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.zym.org/k8s/pause:3.9[root@K8smaster ~]# systemctl daemon-reload
[root@K8smaster ~]# systemctl enable --now cri-docker.service[root@K8smaster mnt]# tar zxf k8s-1.30.tar.gz
[root@K8smaster mnt]# dnf install *.rpm -y#设置kubectl命令补齐功能---仅需在主机上配置
[root@k8s-master ~]# dnf install bash-completion -y
[root@k8s-master ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
[root@k8s-master ~]# source ~/.bashrc
或者使用软件仓库安装
#部署软件仓库,添加K8S源
[root@k8s-master ~]# vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0#安装软件
[root@k8s-master ~]# dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -y3. 在master节点拉取K8S所需镜像
[root@K8smaster mnt]# docker load -i k8s_docker_images-1.30.tardocker images | awk '/google/{print $1":"$2}' | awk -F / '{system("docker tag "$0" reg.zym.org/k8s/"$3)}'[root@K8smaster ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
reg.zym.org/k8s/kube-apiserver v1.30.0 c42f13656d0b 15 months ago 117MB
registry.aliyuncs.com/google_containers/kube-apiserver v1.30.0 c42f13656d0b 15 months ago 117MB
reg.zym.org/k8s/kube-controller-manager v1.30.0 c7aad43836fa 15 months ago 111MB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.30.0 c7aad43836fa 15 months ago 111MB
reg.zym.org/k8s/kube-scheduler v1.30.0 259c8277fcbb 15 months ago 62MB
registry.aliyuncs.com/google_containers/kube-scheduler v1.30.0 259c8277fcbb 15 months ago 62MB
reg.zym.org/k8s/kube-proxy v1.30.0 a0bf559e280c 15 months ago 84.7MB
registry.aliyuncs.com/google_containers/kube-proxy v1.30.0 a0bf559e280c 15 months ago 84.7MB
reg.zym.org/k8s/etcd 3.5.12-0 3861cfcd7c04 18 months ago 149MB
registry.aliyuncs.com/google_containers/etcd 3.5.12-0 3861cfcd7c04 18 months ago 149MB
reg.zym.org/k8s/coredns v1.11.1 cbb01a7bd410 24 months ago 59.8MB
registry.aliyuncs.com/google_containers/coredns v1.11.1 cbb01a7bd410 24 months ago 59.8MB
reg.zym.org/k8s/pause 3.9 e6f181688397 2 years ago 744kB
registry.aliyuncs.com/google_containers/pause 3.9 e6f181688397 2 years ago 744kB#镜像上传
[root@K8smaster ~]# docker images | awk '/zym/{system("docker push " $1":"$2)}'
4. 集群初始化
#启动kubelet服务
[root@K8smaster ~]# systemctl enable --now kubelet.service[root@K8smaster ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 --image-repository reg.zym.org/k8s --kubernetes-version v1.30.0 --cri-socket=unix:///var/run/cri-dockerd.sock#指定集群配置文件变量
[root@k8s-master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@K8smaster ~]# source ~/.bash_profile#当前节点没有就绪,因为还没有安装网络插件,容器没有运行
[root@K8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster.zym.org NotReady control-plane 66s v1.30.0

[root@K8smaster mnt]# docker load -i flannel-0.25.5.tag.gz
[root@K8smaster mnt]# docker tag flannel/flannel:v0.25.5 reg.zym.org/flannel/flannel:v0.25.5
#在Harbor仓库中创建flannel仓库,权限需为公开
[root@K8smaster mnt]# docker push reg.zym.org/flannel/flannel:v0.25.5[root@K8smaster mnt]# docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 reg.zym.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
[root@K8smaster mnt]# docker push reg.zym.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
查看仓库
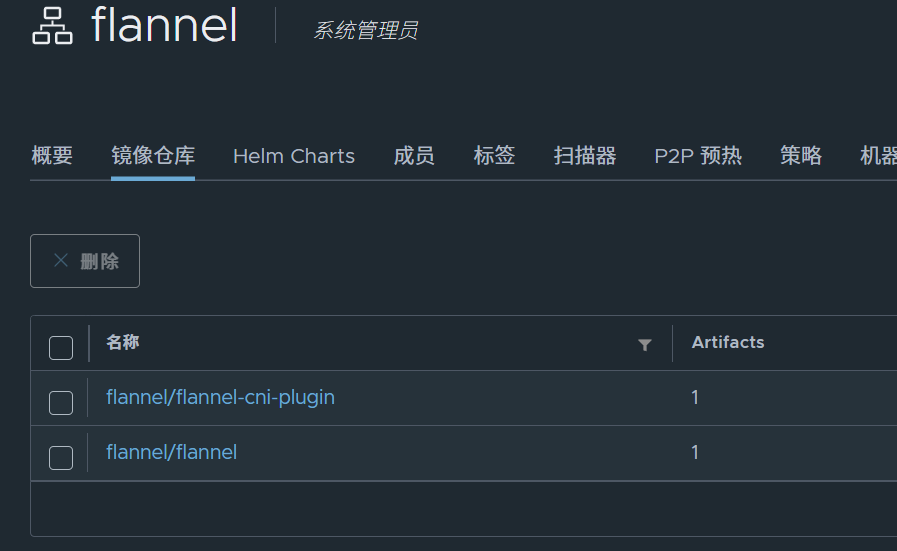
[root@K8smaster mnt]# vim kube-flannel.yml146: image: flannel/flannel:v0.25.5
173: image: flannel/flannel-cni-plugin:v1.5.1-flannel1
184: image: flannel/flannel:v0.25.5[root@K8smaster mnt]# kubectl apply -f kube-flannel.yml
namespace/kube-flannel created
serviceaccount/flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created[root@K8smaster mnt]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster.zym.org Ready control-plane 19m v1.30.0

查看
kubectl get namespaces
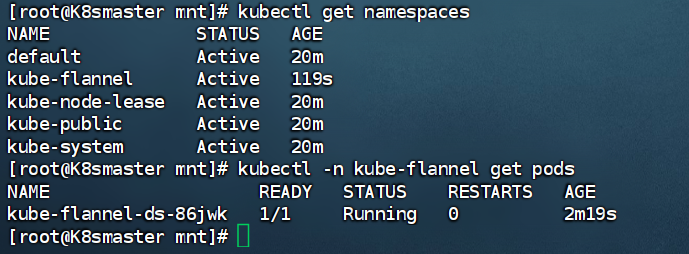
5. 添加工作节点
[root@K8smaster mnt]# kubeadm token create --print-join-command
kubeadm join 192.168.147.100:6443 --token cqu5z7.42608w7amd9v3tyg --discovery-token-ca-cert-hash sha256:2fe2b3cdf1c4ee177ce102e6ce2d8ec54322f23609e2c506e62c0b2576bab069#在slave上运行该命令
kubeadm join 192.168.147.100:6443 --token cqu5z7.42608w7amd9v3tyg --discovery-token-ca-cert-hash sha256:2fe2b3cdf1c4ee177ce102e6ce2d8ec54322f23609e2c506e62c0b2576bab069 --cri-socket=unix:///var/run/cri-dockerd.sock#在最后查看节点,状态均为Ready,安装成功
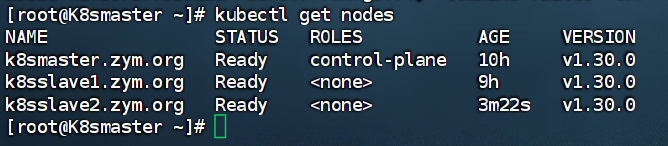
[root@K8smaster ~]# kubectl get nodes
一个为控制器节点,两个工作节点
6.镜像上传Harbor仓库
上传后,集群中可以获取镜像
#上传busyboxplus镜像
[root@Harbor docker-images]# docker load -i busyboxplus.tar.gz
[root@Harbor docker-images]# docker tag busyboxplus:latest reg.zym.org/library/busyboxplus:latest
[root@Harbor docker-images]# docker push reg.zym.org/library/busyboxplus:latest
二、K8s中的pod管理以及优化
(一)K8s的资源
2.1 资源管理介绍
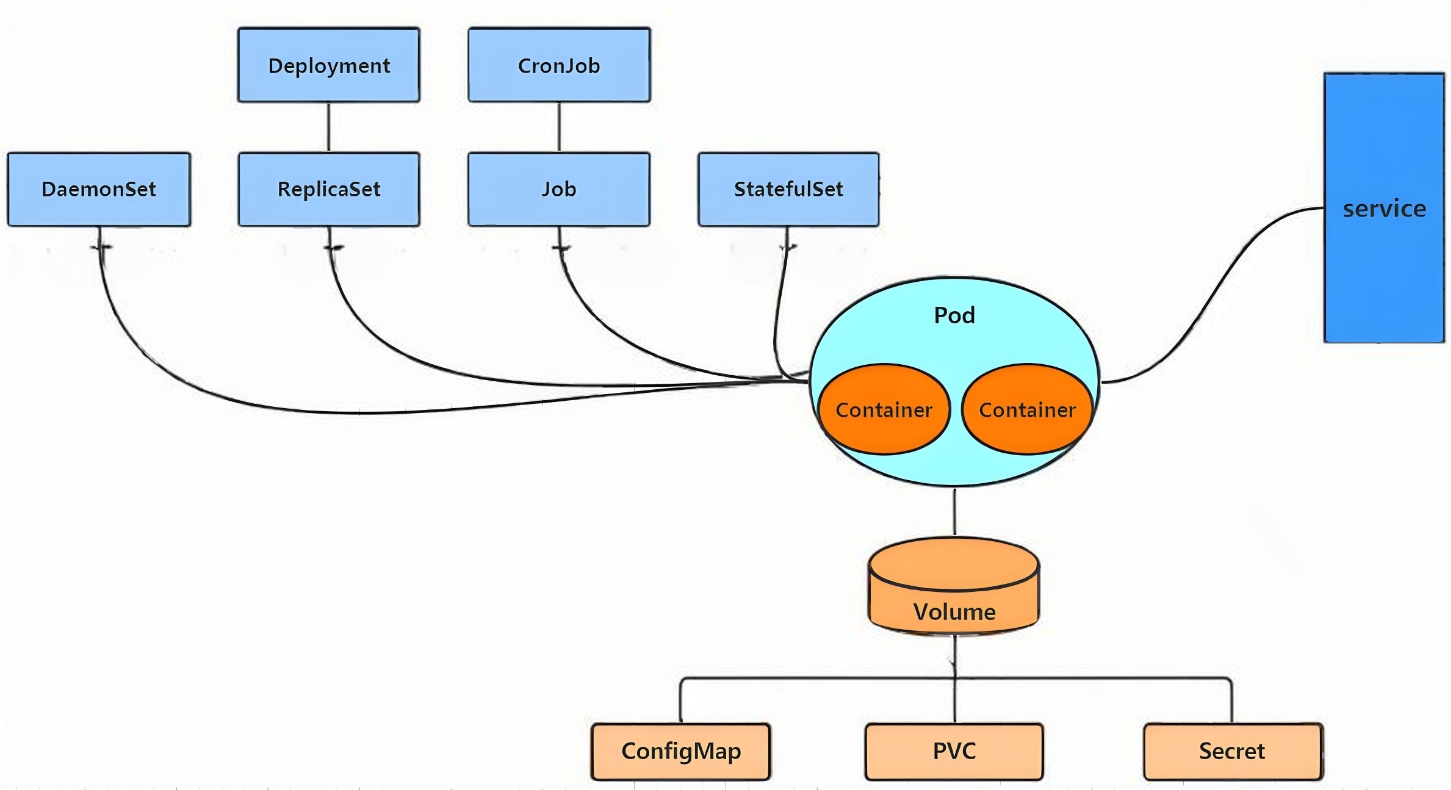
- K8s为一个集群系统,可以在集群中部署各种服务
- 在K8s中可以理解为资源,通过操作资源管理运行K8s
- 部署服务为,在集群中运行容器,将指定的程序在容器中运行
- pod为最小的管理单元,pod相当于进程,容器为线程;容器要在pod中运行
- 要通过pod控制器进行管理容器,服务的访问是由kubernetes提供的
Service资源来实现
2.2资源的运行方式
-
命令操作K8s资源—命令式对象管理
kubectl run nginx-pod --image=nginx:latest --port=80 -
apply命令和配置文件操作资源—声明式对象配置
kubectl apply -f nginx-pod.yaml -
命令配置和配置文件操作资源—命令式对象配置
- 创建之后,不可以覆盖更新
kubectl create/patch -f nginx-pod.yaml
各方式区别
| 类型 | 适用环境 | 优点 | 缺点 |
|---|---|---|---|
| 命令式对象管理 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
| 命令式对象配置 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 声明式对象配置 | 开发 | 支持目录操作 | 意外情况下难以调试 |
2.2.1 命令式对象管理
kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]
comand:指定要对资源执行的操作,例如create、get、delete
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
# 查看所有pod
kubectl get pods# 查看某个pod
kubectl get pod <pod_name># 查看某个pod,以yaml格式展示结果
kubectl get pod <pod_name> -o yaml
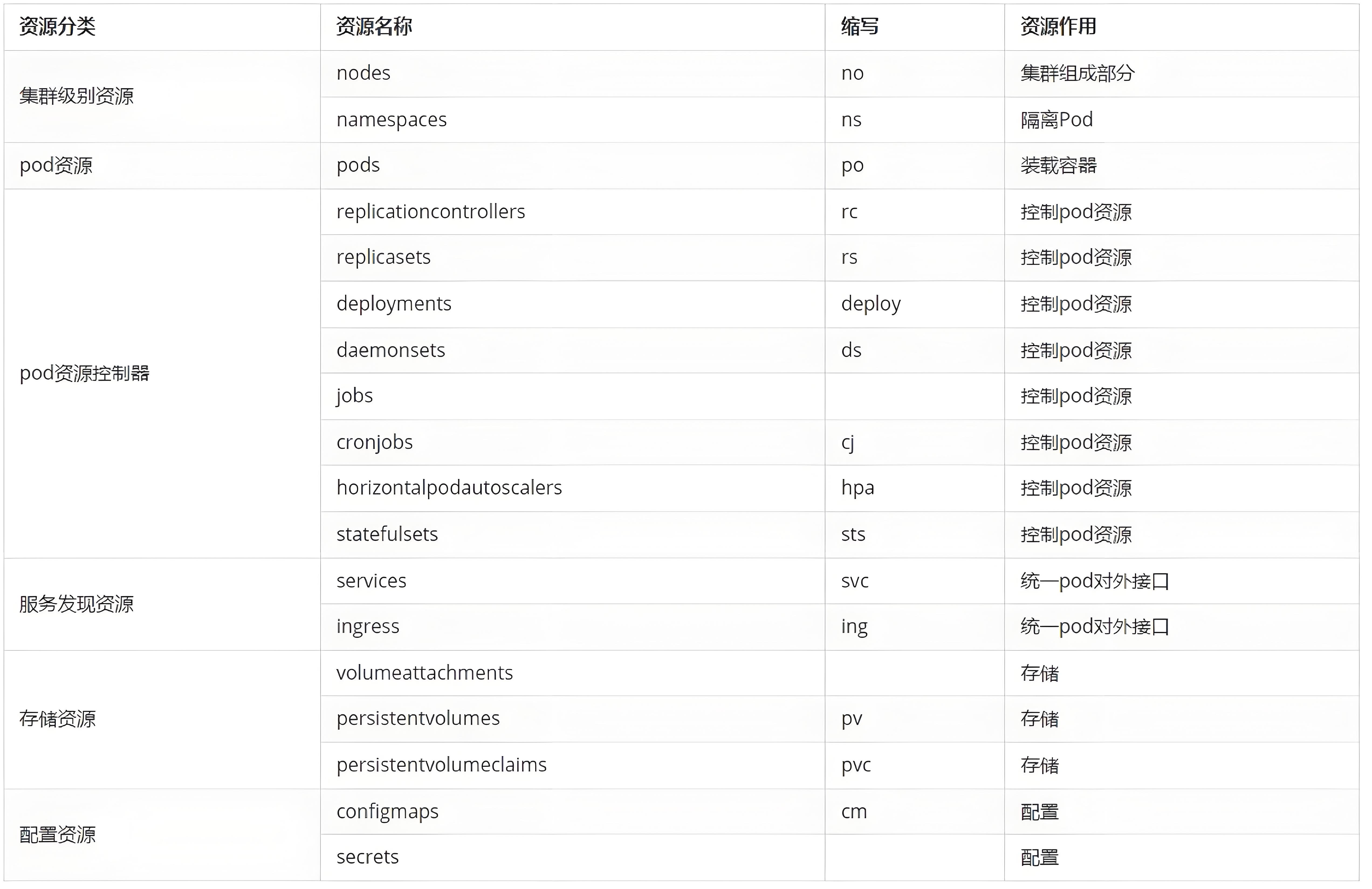
2.2.2 资源的类型
kubernetes中所有的内容都抽象为资源
kubectl api-resources
常用资源类型
kubect 常见命令操作
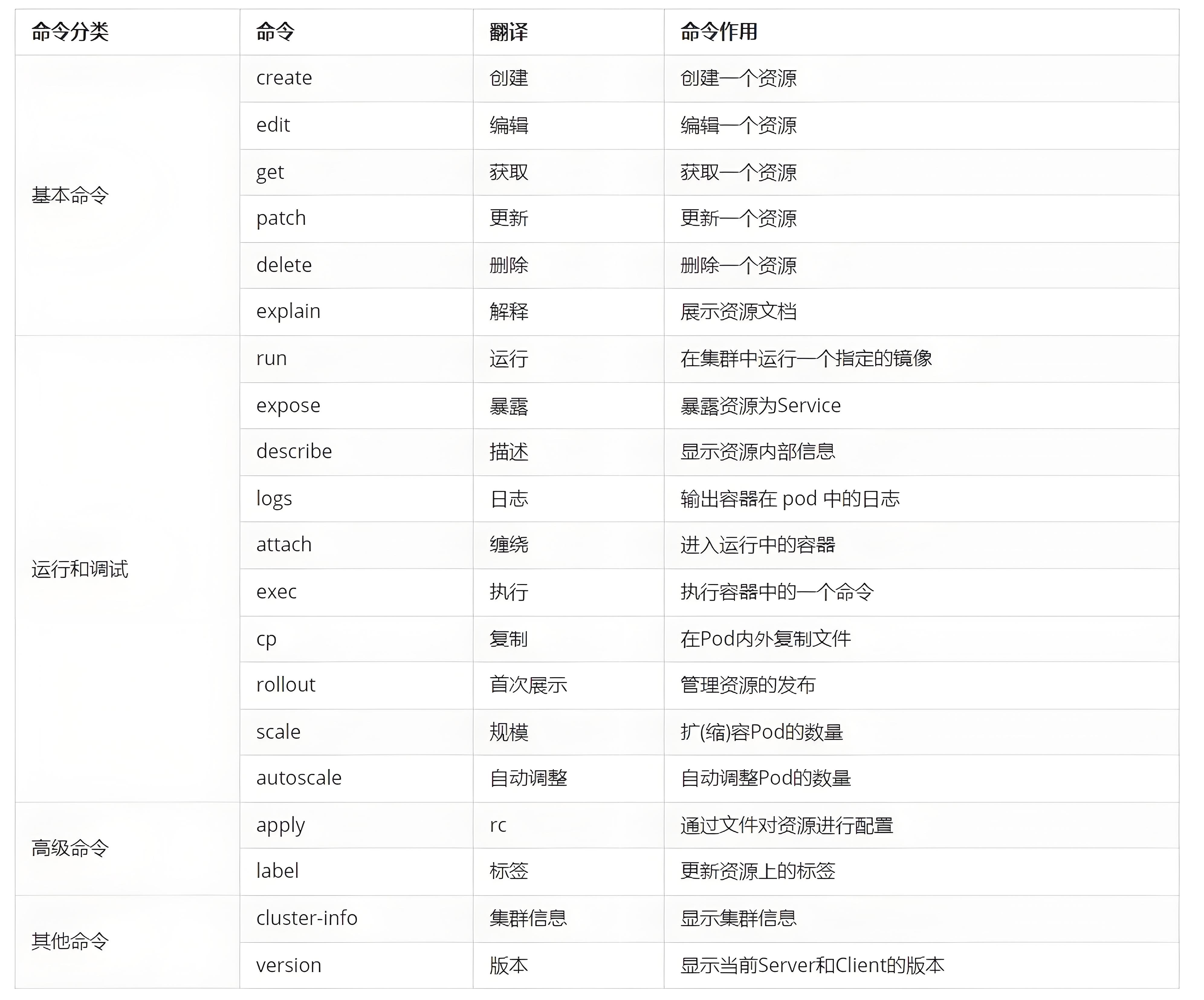
2.2.3 基本命令的示例
kubectl的官方详细说明:https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
显示集群版本和信息
#显示集群版本
[root@k8s-master ~]# kubectl version
Client Version: v1.30.0
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.30.0#显示集群信息
[root@k8s-master ~]# kubectl cluster-info
Kubernetes control plane is running at https://172.25.254.100:6443
CoreDNS is running at https://172.25.254.100:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
2.2.4 运行和调试命令示例
pod基本使用
#运行pod
[root@k8s-master ~]# kubectl run testpod --image nginx:1.23 #需要与仓库的版本一致,默认是为latest
pod/testpod created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
testpod 1/1 Running 0 7s#进入pod
[root@K8smaster ~]# kubectl attach testpod -it#删除pod
[root@K8smaster ~]# kubectl delete pod liveness#查看pod详细信息
[root@k8s-master ~]# kubectl describe pods -o wide#删除多个pod
[root@k8s-master ~]# kubectl delete deployments.apps zym
暴露端口,使得可以直接访问容器
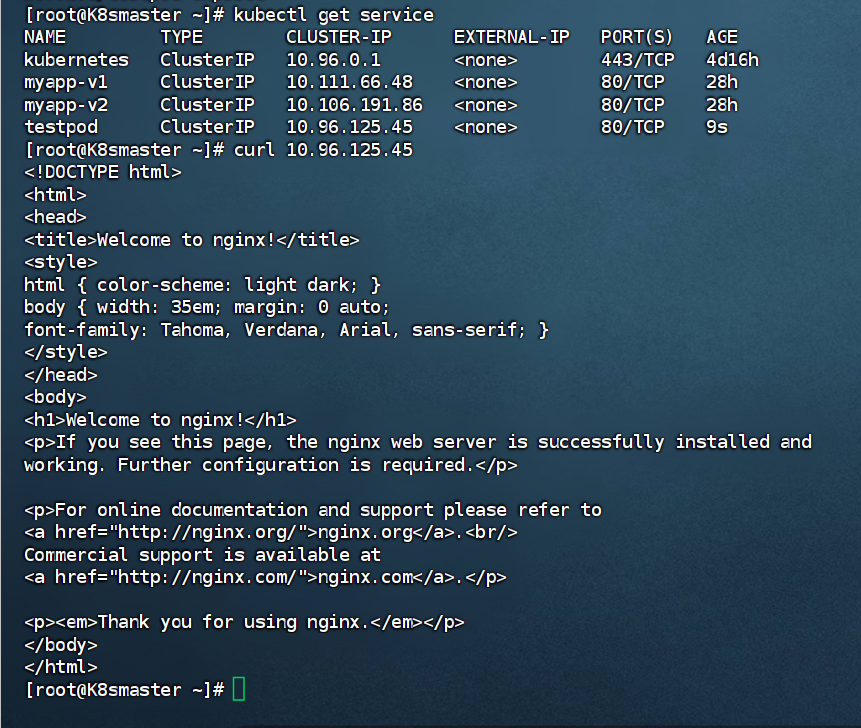
#端口暴漏
[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d14h[root@k8s-master ~]# kubectl expose pod testpod --port 80 --target-port 80
service/testpod exposed[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d14h
testpod ClusterIP 10.106.78.42 <none> 80/TCP 18s
[root@k8s-master ~]# curl 10.106.78.42
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
结果截图:
*查看报错资源日志
#查看资源日志
[root@k8s-master ~]# kubectl logs pods/testpod#testpod为开启pod的名称
pod交互运行
#运行交互pod
[root@k8s-master ~]# kubectl run -it testpod --image busyboxIf you don't see a command prompt, try pressing enter.
/ #
/ # #ctrl+pq退出不停止pod#运行非交互pod
[root@k8s-master ~]# kubectl run nginx --image nginx
pod/nginx created#进入到已经运行的容器,且容器有交互环境
[root@k8s-master ~]# kubectl attach pods/testpod -it
If you don't see a command prompt, try pressing enter.
/ #
/ ##在已经运行的pod中运行指定命令
[root@k8s-master ~]# kubectl exec -it pods/nginx /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx:/#
控制器创建
#创建一个webcluster控制器,控制器中pod数量为2
[root@k8s-master ~]# kubectl create deployment webcluseter --image nginx --replicas 2
#查看控制器
[root@k8s-master ~]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web 3/3 3 3 69m
#编辑控制器配置
[root@k8s-master ~]# kubectl edit deployments.apps web
@@@@省略内容@@@@@@
spec:progressDeadlineSeconds: 600replicas: 2[root@k8s-master ~]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web 2/2 2 2 73m
#利用补丁更改控制器配置
[root@k8s-master ~]# kubectl patch deployments.apps web -p '{"spec":{"replicas":4}}'
deployment.apps/web patched
[root@k8s-master ~]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web 4/4 4 4 74m
*资源删除
#删除资源
[root@k8s-master ~]# kubectl delete deployments.apps web
deployment.apps "web" deleted
2.3 高级命令示例
#管理资源标签
[root@k8s-master ~]# kubectl run nginx --image nginx
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 12s run=nginx[root@k8s-master ~]# kubectl label pods nginx app=lee
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 57s app=lee,run=nginx#更改标签
[root@k8s-master ~]# kubectl label pods nginx app=webcluster --overwrite#删除标签
[root@k8s-master ~]# kubectl label pods nginx app-
pod/nginx unlabeled
[root@k8s-master ~]# kubectl get pods nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 7m56s run=nginx#标签时控制器识别pod示例的标识
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 11m run=nginx
webcluster-7c584f774b-66zbd 1/1 Running 0 2m10s app=webcluster,pod-template-hash=7c584f774b
webcluster-7c584f774b-9x2x2 1/1 Running 0 35m app=webcluster,pod-template-hash=7c584f774b#删除pod上的标签
root@k8s-master ~]# kubectl label pods webcluster-7c584f774b-66zbd app-
pod/webcluster-7c584f774b-66zbd unlabeled#控制器会重新启动新pod
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 11m run=nginx
webcluster-7c584f774b-66zbd 1/1 Running 0 2m39s pod-template-hash=7c584f774b
webcluster-7c584f774b-9x2x2 1/1 Running 0 36m app=webcluster,pod-template-hash=7c584f774b
webcluster-7c584f774b-hgprn 1/1 Running 0 2s app=webcluster,pod-template-hash=7c584f774b
(二)pod是什么?

- Pod是可以创建和管理Kubernetes计算的最小可部署单元
- 一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip
- 一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
- 多个容器间共享IPC、Network和UTC namespace
2.1 创建自主式pod
在生产中不推荐
| 优点 | 缺点 |
|---|---|
| 灵活性高—可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求 | 管理复杂—如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作 |
| 学习和调试方便—于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置 | 缺乏高级功能—无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下 |
| 适用于特殊场景—在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式 | 可维护性差—动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新 |
#查看所有pods
[root@k8s-master ~]# kubectl get pods
No resources found in default namespace.#建立一个名为zym的pod
[root@k8s-master ~]# kubectl run zym --image nginx
pod/timinglee created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
zym 1/1 Running 0 6s#显示pod的较为详细的信息
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
zym 1/1 Running 0 11s 10.244.1.17 k8s-node1.zym.org <none> <none>
2.2 利用控制器管理pod(推荐)
高可用性和可靠性:
- 自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
- 健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
- 轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
- 水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化
版本管理和更新:
- 滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响
- 回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性
声明式配置:
- 简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作
- 期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率
服务发现和负载均衡:
- 自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器
- 流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率
示例:
#建立控制器并自动运行pod
[root@k8s-master ~]# kubectl create deployment timinglee --image nginx
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-mrjvx 1/1 Running 0 37m#为pod扩容
[root@k8s-master ~]# kubectl scale deployment timinglee --replicas 6
deployment.apps/timinglee scaled[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-8rgkz 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-ddndl 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-m4r9l 0/1 ContainerCreating 0 1s
timinglee-859fbf84d6-mrjvx 1/1 Running 0 37m
timinglee-859fbf84d6-tsn97 1/1 Running 0 20s
timinglee-859fbf84d6-xgskk 0/1 ContainerCreating 0 1s#为timinglee缩容
root@k8s-master ~]# kubectl scale deployment timinglee --replicas 2
deployment.apps/timinglee scaled[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-mrjvx 1/1 Running 0 38m
timinglee-859fbf84d6-tsn97 1/1 Running 0 73s
2.3 应用版本的更新
#利用控制器建立pod
[root@k8s-master ~]# kubectl create deployment timinglee --image myapp:v1 --replicas 2
deployment.apps/timinglee created#暴漏端口
[root@k8s-master ~]# kubectl expose deployment timinglee --port 80 --target-port 80
service/timinglee exposed
[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h
timinglee ClusterIP 10.110.195.120 <none> 80/TCP 8s#访问服务
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120#查看历史版本
[root@k8s-master ~]# kubectl rollout history deployment timinglee
deployment.apps/timinglee
REVISION CHANGE-CAUSE
1 <none>#更新控制器镜像版本
[root@k8s-master ~]# kubectl set image deployments/timinglee myapp=myapp:v2
deployment.apps/timinglee image updated#查看历史版本
[root@k8s-master ~]# kubectl rollout history deployment timinglee
deployment.apps/timinglee
REVISION CHANGE-CAUSE
1 <none>
2 <none>#访问内容测试
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# curl 10.110.195.120#版本回滚
[root@k8s-master ~]# kubectl rollout undo deployment timinglee --to-revision 1
deployment.apps/timinglee rolled back
[root@k8s-master ~]# curl 10.110.195.120
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
2.4 用yaml文件部署应用
yaml文件优点
| 优点 | 声明式的配置 | 灵活性和可扩展性 | 能与工具集成 |
|---|---|---|---|
| 清晰表达期望状态 | 丰富的配置选项 | 与 CI/CD 流程集成 | |
| 可重复性和版本控制 | 组合和扩展 | 命令行工具支持 |
- 声明式配置
- 以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等,得配置易于理解和维护
- 配置文件可以被版本控制,确保在不同环境中的部署一致性,也可以回滚到之前版本
2.4.1 配置参数说明
| 参数名称 | 类型 | 参数说明 |
|---|---|---|
| version | String | 这里是指的是K8S API的版本,目前基本上是v1,可以用kubectl api-versions命令查询 |
| kind | String | 这里指的是yaml文件定义的资源类型和角色,比如:Pod |
| metadata | Object | 元数据对象,固定值就写metadata |
| metadata.name | String | 元数据对象的名字,这里由我们编写,比如命名Pod的名字 |
| metadata.namespace | String | 元数据对象的命名空间,由我们自身定义 |
| Spec | Object | 详细定义对象,固定值写Spec |
参数名称 类型 参数说明
Spec #Object #详细定义对象,固定值就写Specspec.containers[] #list #这里是Spec对象的容器列表定义,是个列表spec.containers[].name #String #这里定义容器的名字spec.containers[].image #string #这里定义要用到的镜像名称spec.containers[].imagePullPolicy #String #定义镜像拉取策略,有三个值可选:#a.Always: 每次都尝试重新#b. IfNotPresent:如果本地有镜像就使用本地镜像#c.Never:表示仅使用本地镜像spec.containers[].command[] #list #指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令 |spec.containers[].args[] #list #指定容器运行参数,可以指定多个spec.containers[].workingDir#String #指定容器工作目录
spec.containers[].volumeMounts[]#list #指定容器内部的存储卷配置
spec.containers[].volumeMounts[].name#String #指定可以被容器挂载的存储卷的名称
spec.containers[].volumeMounts[].mountPath#String #指定可以被容器挂载的存储卷的路径
spec.containers[].volumeMounts[].readOnly#String #设置存储卷路径的读写模式,ture或false,默认为读写模式
spec.containers[].ports[]#list #指定容器需要用到的端口列表
spec.containers[].ports[].name#String #指定端口名称
spec.containers[].ports[].containerPort#String #指定容器需要监听的端口号
spec.containers[] ports[].hostPort#String #指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突)| spec.containers[].ports[].protocol | String | 指定端口协议,支持TCP和UDP,默认值为TCP
| spec.containers[].env[] | list | 指定容器运行前需设置的环境变量列表
| spec.containers[].env[].name | String | 指定环境变量名称
| spec.containers[].env[].value | String | 指定环境变量值
| spec.containers[].resources | Object | 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限)
| spec.containers[].resources.limits | Object | 指定设置容器运行时资源的运行上限
| spec.containers[].resources.limits.cpu | String | 指定CPU的限制,单位为核心数,1=1000m
| spec.containers[].resources.limits.memory | String | 指定MEM内存的限制,单位为MIB、GiB
| spec.containers[].resources.requests | Object | 指定容器启动和调度时的限制设置
| spec.containers[].resources.requests.cpu | String | CPU请求,单位为core数,容器启动时初始化可用数量
| spec.containers[].resources.requests.memory | String | 内存请求,单位为MIB、GIB,容器启动的初始化可用数量| spec.restartPolicy | string | 定义Pod的重启策略,默认值为Always.(1)Always: Pod-旦终止运行,无论容器是如何 终止的,kubelet服务都将重启它 (2)OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它(3) Never: Pod终止后,kubelet将退出码报告给Master,不会重启该
spec.nodeSelector | Object | 定义Node的Label过滤标签,以key:value格式指定spec.imagePullSecrets | Object | 定义pull镜像时使用secret名称,以name:secretkey格式指定
pec.hostNetwork | Boolean | 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机 上启动第二个副本
2.5 yaml编写示例
用命令获取yaml模板,以下均编写yaml配置文件
kubectl run zym --image myapp:v1 --dry-run=client -o yaml > pod.yml
示例1:运行简单的单个容器pod
apiVersion: v1
kind: Pod
metadata:labels:run: timing #pod标签name: timinglee #pod名称
spec:containers:- image: myapp:v1 #pod镜像name: timinglee #容器名称
示例2:运行多个容器pod
!注意:如果多个容器运行在一个pod中,资源共享的同时在使用相同资源时也会干扰,比如端口占用
apiVersion: v1
kind: Pod
metadata:labels:run: timingname: timinglee
spec:containers:- image: nginx:latestname: web1- image: nginx:latestname: web2
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created#有一台启动失败
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/2 Error 1 (14s ago) 18s
#查看日志
[root@k8s-master ~]# kubectl logs timinglee web2
2024/08/31 12:43:20 [emerg] 1#1: bind() to [::]:80 failed (98: Address already in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address already in use)
2024/08/31 12:43:20 [notice] 1#1: try again to bind() after 500ms
2024/08/31 12:43:20 [emerg] 1#1: still could not bind()
nginx: [emerg] still could not bind()
[!NOTE]
在一个pod中开启多个容器时一定要确保容器彼此不能互相干扰
apiVersion: v1
kind: Pod
metadata:labels:run: timingname: timinglee
spec:containers:- image: nginx:latestname: web1- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","sleep 1000000"][root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 2/2 Running 0 19s
示例3:端口映射
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: myapp:v1name: myapp1ports:- name: httpcontainerPort: 80 #映射端口hostPort: 80protocol: TCP#测试
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 12s 10.244.1.2 k8s-node1.zym.org <none> <none>
示例4:设定环境变量
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","echo $NAME;sleep 3000000"]env:- name: NAMEvalue: timinglee #环境变量设定[root@k8s-master ~]# kubectl logs pods/test busybox
timinglee
示例5:资源限制
!注意
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
QoS(Quality of Service)即服务质量
资源设定 优先级类型 资源限定未设定 BestEffort 资源限定设定且最大和最小不一致 Burstable-次敏感型 资源限定设定且最大和最小一致,内存和CPU均要设定 Guaranteed-敏感型
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:containers:- image: myapp:v1name: myappresources:limits: #pod使用资源的最高限制 cpu: 500mmemory: 100Mrequests: #pod期望使用资源量,不能大于limitscpu: 500mmemory: 100M
root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 3s[root@k8s-master ~]# kubectl describe pods testLimits:cpu: 500mmemory: 100MRequests:cpu: 500mmemory: 100M
QoS Class: Guaranteed
示例6:容器启动管理
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:restartPolicy: Always #启动管理containers:- image: myapp:v1name: myapp
Always: 要确保运行,掉了要重新运行
Never:不管该Pod还能否运行
示例7:选择运行节点
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:nodeSelector:kubernetes.io/hostname: k8s-node1 #选择运行节点restartPolicy: Alwayscontainers:- image: myapp:v1name: myapp
示例8:共享宿主机网络
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:run: timingleename: test
spec:hostNetwork: truerestartPolicy: Alwayscontainers:- image: busybox:latestname: busyboxcommand: ["/bin/sh","-c","sleep 100000"][root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created[root@k8s-master ~]# kubectl exec -it pods/test -c busybox -- /bin/sh
/ #ipconfig
三、K8S的管理
(一)POD的生命周期
3.1 init容器
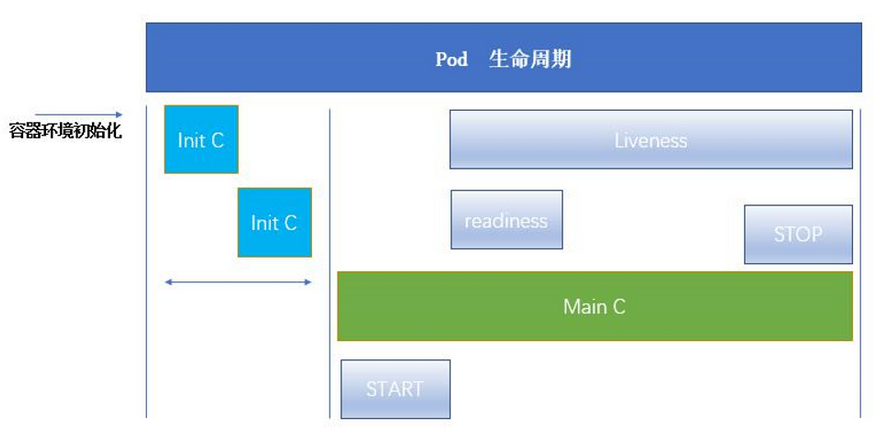
- pod中是先于应用容器的启动
- 与普通容器区别
- 每个均要运行到完成
- 不支持
Readiness,init容器需要在pod容器运行之前运行完成 - 每一个容器需要运行成功后,再运行下一个
- 如果pod里的init容器启动失败,k8s会不断进行重启,直到init容器启动成功
3.1.1 容器的功能
- Init 容器可以包含安装过程中应用容器中不存在的实用工具或个性化代码
- Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低
- 应用镜像的创建者和部署者可以各自独立工作
- Init 容器能以不同于Pod内应用容器的文件系统视图运行;init容器可具有访问 Secrets 的权限,而应用容器不能够访问
- 由于 Init 容器必须在应用容器启动之前运行完成;因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动
3.1.2 INIT 容器示例
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: initpodname: initpod
spec:containers:- image: myapp:v1name: myappinitContainers:- name: init-myserviceimage: busyboxcommand: ["sh","-c","until test -e /testfile;do echo wating for myservice; sleep 2;done"] #检测/testfile下的test文件是否存在#测试
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/initpod created
[root@k8s-master ~]# kubectl get pods
显示init容器正在运行中,因为该容器中没有目标文件,会处于该状态

#每两秒刷新启动
[root@k8s-master ~]# kubectl logs pods/initpod init-myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice#添加所需的目标文件
[root@k8s-master ~]# kubectl exec pods/initpod -c init-myservice -- /bin/sh -c "touch /testfile"[root@k8s-master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE
initpod 1/1 Running 0 62s

3.2 三种探针
选择执行在容器上运行的三种探针执行
-
存活探针–livenessProbe:会持续检测该容器是否正常运行,启动不了的话,会把之前启动的给删了,然后受到重启策略影响,重新开一个新的容器
如果容器不设定存活探针话,会默认状态为success
-
就绪探针–readinessProbe:容器是否准备好服务请求,就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为失败
-
启动探针–startupProbe:容器中的应用是否已经启动,提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止;启动探测失败的话,会将容器删除,重新启动容器
ReadinessProbe 与 LivenessProbe 的区别
- 当检测失败后,将 Pod 的
IP:Port从对应的 EndPoint 列表中删除 - 当检测失败后,将杀死容器并根据
Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
- 当三个探针同时存在,
先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod满足启动探针配置的条件,其他 2 个探针启动;不满足按照规则重启容器。 - 另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
3.2.1 探针示例
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:labels:name: livenessname: liveness
spec:containers:- image: myapp:v1name: myapplivenessProbe:tcpSocket: #检测端口存在性port: 8080initialDelaySeconds: 3 #容器启动后要等待多少秒后就探针开始工作,默认是 0speriodSeconds: 1 #执行探测的时间间隔,默认为 10stimeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间,默认为 1s#测试:
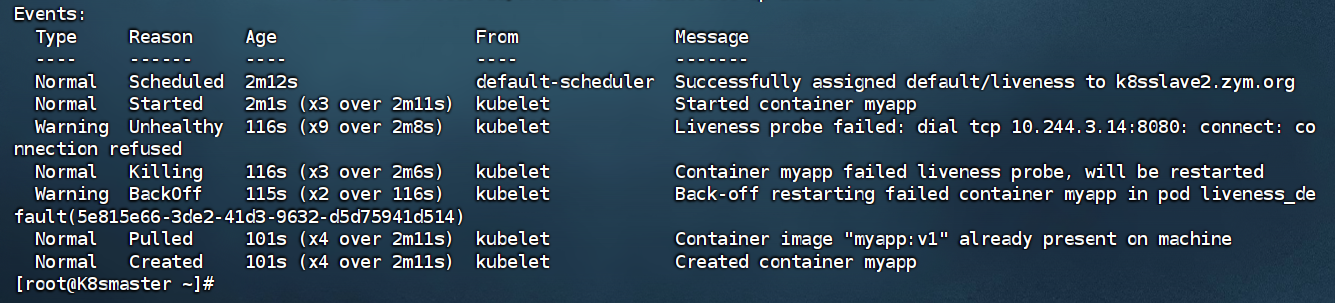
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/liveness created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
liveness 0/1 CrashLoopBackOff 2 (7s ago) 22s[root@k8s-master ~]# kubectl describe pods
可以看到因为无法连接该8080端口,在持续的删除重启
四、k8s中的控制器
(一)控制器的说明
控制器是管理pod的一种手段
- 自主Pod—pod退出或意外关闭后不会被重新创建
- 控制器管理的Pod—在控制器的生命周期里,始终维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
(二)常用控制器的类型
| 控制器名称 | 控制器用途 |
|---|---|
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象。 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
(三)replicaset控制器
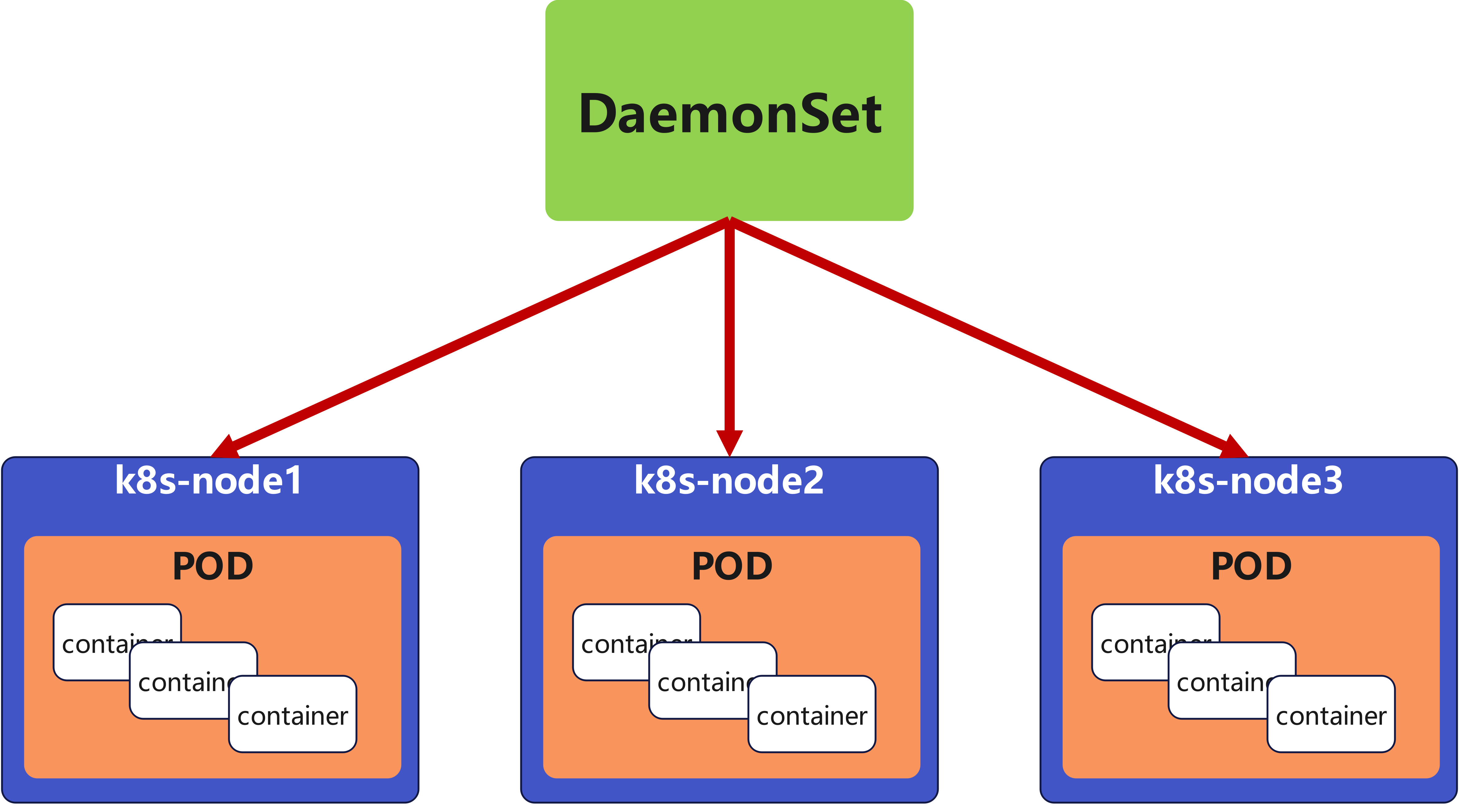
replicaset功能
- ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
- 协助Deployments 用作协调 Pod 创建、删除和更新的机制
replicaset解释
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:replicas: 2 #指定维护pod数量为2selector: #指定检测匹配方式matchLabels: #指定匹配方式为匹配标签app: myapp #指定匹配的标签为app=myapptemplate: #模板,当副本数量不足时,会根据下面的模板创建pod副本metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp
replicaset 示例
创建测试容器
#生成yml文件
[root@k8s-master ~]# kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > replicaset.yml[root@k8s-master ~]# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:replicas: 2 #指定维护pod数量为2selector: #指定检测匹配方式matchLabels: #指定匹配方式为匹配标签app: myapp #指定匹配的标签为app=myapptemplate: #模板,当副本数量不足时,会根据下面的模板创建pod副本metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp[root@k8s-master ~]# kubectl apply -f replicaset.yml
replicaset.apps/replicaset created
测试:通过标签匹配pod,标签不同,会重新启动一个标签相同的容器
[root@k8s-master ~]# kubectl label pod replicaset-l4xnr app=timinglee --overwrite
pod/replicaset-l4xnr labeled
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-gd5fh 1/1 Running 0 2s app=myapp #会开启新的pod
replicaset-l4xnr 1/1 Running 0 3m19s app=timinglee
replicaset-t2s5p 1/1 Running 0 3m19s app=myapp
测试:控制容器的数量
#删除其中一个pod,会自动重新生成新的pod,保证数量
[root@k8s-master ~]# kubectl delete pods replicaset-t2s5p
pod "replicaset-t2s5p" deleted[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-l4xnr 1/1 Running 0 5m43s app=myapp
replicaset-nxmr9 1/1 Running 0 15s app=myapp
(四)deployment 控制器
4.1 deployment控制器说明
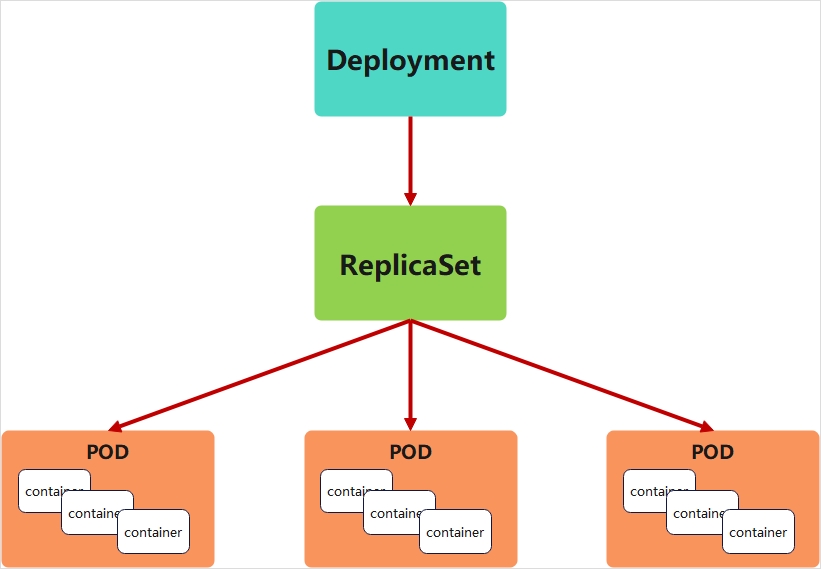
- Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
- Deployment管理ReplicaSet,ReplicaSet管理Pod
- Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
- 在Deployment中ReplicaSet相当于一个版本
典型的应用场景:
- 用来创建Pod和ReplicaSet
- 滚动更新和回滚
- 扩容和缩容
- 暂停与恢复
pod控制器—deployment
kubectl create deployment webcluster --imagge myapp:v1 - replicas 4#deployment---为实时和系统进行命令的对比,查看是否符合命令操作
#replicas---为期望,设定期望pod开启的数量为4个
4.2 deployment控制器示例
#生成yaml文件
[root@k8s-master ~]# kubectl create deployment deployment --image myapp:v1 --dry-run=client -o yaml > deployment.yml[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp
#建立pod
root@k8s-master ~]# kubectl apply -f deployment.yml
deployment.apps/deployment created#查看pod信息
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
deployment-5d886954d4-2ckqw 1/1 Running 0 23s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-m8gpd 1/1 Running 0 23s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-s7pws 1/1 Running 0 23s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-wqnvv 1/1 Running 0 23s app=myapp,pod-template-hash=5d886954d4
4.2.1 版本迭代
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-2ckqw 1/1 Running 0 2m40s 10.244.2.14 k8s-node2 <none> <none>
deployment-5d886954d4-m8gpd 1/1 Running 0 2m40s 10.244.1.17 k8s-node1 <none> <none>
deployment-5d886954d4-s7pws 1/1 Running 0 2m40s 10.244.1.16 k8s-node1 <none> <none>
deployment-5d886954d4-wqnvv 1/1 Running 0 2m40s 10.244.2.15 k8s-node2 <none> <none>#pod运行容器版本为v1
[root@k8s-master ~]# curl 10.244.2.14
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>[root@k8s-master ~]# kubectl describe deployments.apps deployment
Name: deployment
Namespace: default
CreationTimestamp: Sun, 01 Sep 2024 23:19:10 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=myapp
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge #默认每次更新25%#更新容器运行版本
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:minReadySeconds: 5 #最小就绪时间5秒replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v2 #更新为版本2name: myapp[root@k8s2 pod]# kubectl apply -f deployment-example.yaml#更新过程
[root@k8s-master ~]# watch - n1 kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE
deployment-5d886954d4-8kb28 1/1 Running 0 48s
deployment-5d886954d4-8s4h8 1/1 Running 0 49s
deployment-5d886954d4-rclkp 1/1 Running 0 50s
deployment-5d886954d4-tt2hz 1/1 Running 0 50s
deployment-7f4786db9c-g796x 0/1 Pending 0 0s#测试更新效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-7f4786db9c-967fk 1/1 Running 0 10s 10.244.1.26 k8s-node1 <none> <none>
deployment-7f4786db9c-cvb9k 1/1 Running 0 10s 10.244.2.24 k8s-node2 <none> <none>
deployment-7f4786db9c-kgss4 1/1 Running 0 9s 10.244.1.27 k8s-node1 <none> <none>
deployment-7f4786db9c-qts8c 1/1 Running 0 9s 10.244.2.25 k8s-node2 <none> <none>[root@k8s-master ~]# curl 10.244.1.26
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
[!NOTE]
更新的过程是重新建立一个版本的RS,新版本的RS会把pod 重建,然后把老版本的RS回收
4.2.2 版本回滚
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:replicas: 4selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1 #回滚到之前版本name: myapp[root@k8s-master ~]# kubectl apply -f deployment.yml
deployment.apps/deployment configured#测试回滚效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-dr74h 1/1 Running 0 8s 10.244.2.26 k8s-node2 <none> <none>
deployment-5d886954d4-thpf9 1/1 Running 0 7s 10.244.1.29 k8s-node1 <none> <none>
deployment-5d886954d4-vmwl9 1/1 Running 0 8s 10.244.1.28 k8s-node1 <none> <none>
deployment-5d886954d4-wprpd 1/1 Running 0 6s 10.244.2.27 k8s-node2 <none> <none>[root@k8s-master ~]# curl 10.244.2.26
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
4.2.3 滚动更新策略
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment
spec:minReadySeconds: 5 #最小就绪时间,指定pod每隔多久更新一次replicas: 4strategy: #指定更新策略rollingUpdate:maxSurge: 1 #比定义pod数量多几个maxUnavailable: 0 #比定义pod个数少几个selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- image: myapp:v1name: myapp
[root@k8s2 pod]# kubectl apply -f deployment-example.yaml
4.2.4 暂停及恢复
在实际生产环境中我们做的变更可能不止一处,当修改了一处后,如果执行变更就直接触发了
我们期望的触发时当我们把所有修改都搞定后一次触发
暂停,避免触发不必要的线上更新
[root@k8s2 pod]# kubectl rollout pause deployment deployment-example[root@k8s2 pod]# vim deployment-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deployment-example
spec:minReadySeconds: 5strategy:rollingUpdate:maxSurge: 1maxUnavailable: 0replicas: 6 selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:containers:- name: myappimage: nginxresources:limits:cpu: 0.5memory: 200Mirequests:cpu: 0.5memory: 200Mi[root@k8s2 pod]# kubectl apply -f deployment-example.yaml#调整副本数,不受影响
[root@k8s-master ~]# kubectl describe pods deployment-7f4786db9c-8jw22
Name: deployment-7f4786db9c-8jw22
Namespace: default
Priority: 0
Service Account: default
Node: k8s-node1/172.25.254.10
Start Time: Mon, 02 Sep 2024 00:27:20 +0800
Labels: app=myapppod-template-hash=7f4786db9c
Annotations: <none>
Status: Running
IP: 10.244.1.31
IPs:IP: 10.244.1.31
Controlled By: ReplicaSet/deployment-7f4786db9c
Containers:myapp:Container ID: docker://01ad7216e0a8c2674bf17adcc9b071e9bfb951eb294cafa2b8482bb8b4940c1dImage: myapp:v2Image ID: docker-pullable://myapp@sha256:5f4afc8302ade316fc47c99ee1d41f8ba94dbe7e3e7747dd87215a15429b9102Port: <none>Host Port: <none>State: RunningStarted: Mon, 02 Sep 2024 00:27:21 +0800Ready: TrueRestart Count: 0Environment: <none>Mounts:/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mfjjp (ro)
Conditions:Type StatusPodReadyToStartContainers TrueInitialized TrueReady TrueContainersReady TruePodScheduled True
Volumes:kube-api-access-mfjjp:Type: Projected (a volume that contains injected data from multiple sources)TokenExpirationSeconds: 3607ConfigMapName: kube-root-ca.crtConfigMapOptional: <nil>DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300snode.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Scheduled 6m22s default-scheduler Successfully assigned default/deployment-7f4786db9c-8jw22 to k8s-node1Normal Pulled 6m22s kubelet Container image "myapp:v2" already present on machineNormal Created 6m21s kubelet Created container myappNormal Started 6m21s kubelet Started container myapp#但是更新镜像和修改资源并没有触发更新
[root@k8s2 pod]# kubectl rollout history deployment deployment-example
deployment.apps/deployment-example
REVISION CHANGE-CAUSE
3 <none>
4 <none>#恢复后开始触发更新
[root@k8s2 pod]# kubectl rollout resume deployment deployment-example[root@k8s2 pod]# kubectl rollout history deployment deployment-example
deployment.apps/deployment-example
REVISION CHANGE-CAUSE
3 <none>
4 <none>
5 <none>#回收
[root@k8s2 pod]# kubectl delete -f deployment-example.yaml
(五) daemonset控制器
5.1 daemonset功能
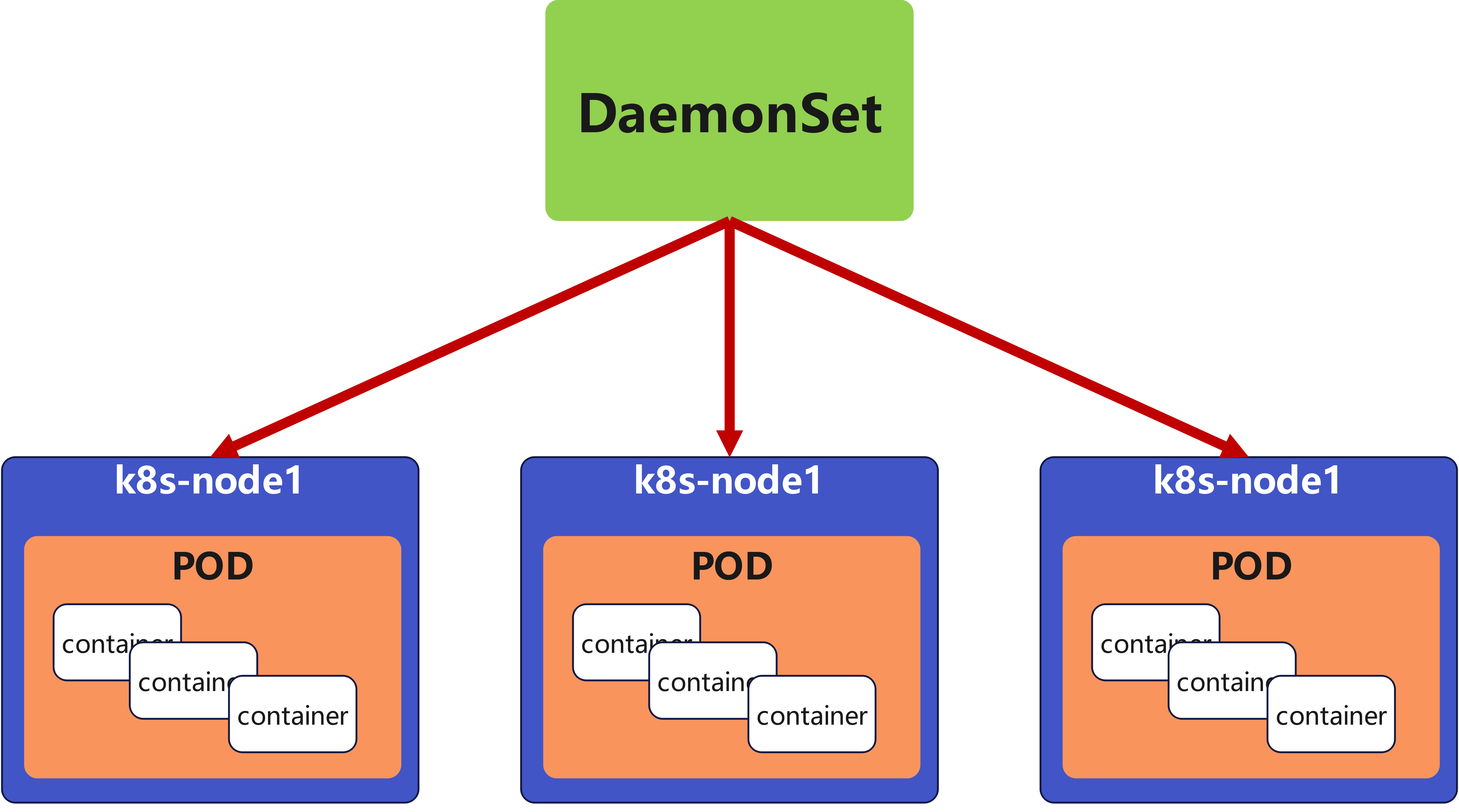
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
DaemonSet 的典型用法:
- 在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
- 在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
- 在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
- 一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
- 一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
5.2 daemonset 示例
[root@k8s2 pod]# cat daemonset-example.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:name: daemonset-example
spec:selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:tolerations: #对于污点节点的容忍- effect: NoScheduleoperator: Existscontainers:- name: nginximage: nginx[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
daemonset-87h6s 1/1 Running 0 47s 10.244.0.8 k8s-master <none> <none>
daemonset-n4vs4 1/1 Running 0 47s 10.244.2.38 k8s-node2 <none> <none>
daemonset-vhxmq 1/1 Running 0 47s 10.244.1.40 k8s-node1 <none> <none>#回收
[root@k8s2 pod]# kubectl delete -f daemonset-example.yml
(六)job 控制器
6.1 job控制器说明
- 可以进行批量处理的短暂一次运行
[root@k8s2 pod]# vim job.yml
apiVersion: batch/v1
kind: Job
metadata:name: pi
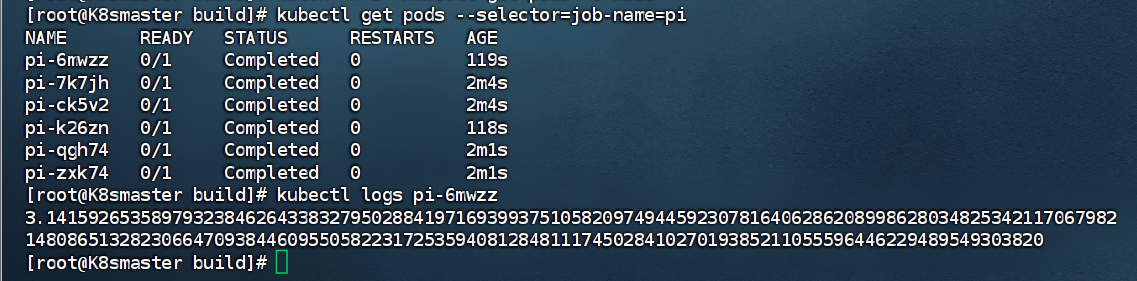
spec:completions: 6 #一共完成任务数为6 parallelism: 2 #每次并行完成2个backoffLimit: 4 #尝试运行失败4次后重新运行template:spec:containers:- name: piimage: perl:5.34.0command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] #计算圆周率3.14的后2000位restartPolicy: Never #关闭后不自动重启[root@k8s2 pod]# kubectl apply -f job.yml#监控
[root@K8smaster ~]# watch -n 1 "kubectl get pods -o wide"
#删除
[root@K8smaster build]# kubectl delete jobs.batch pi
[!NOTE]
关于重启策略**
restartPolicy**设置的说明:
如果指定为OnFailure,则job会在pod出现故障时重启容器
而不是创建pod,failed次数不变
如果指定为Never,则job会在pod出现故障时创建新的pod
并且故障pod不会消失,也不会重启,failed次数加1
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了
结果查看:可以看到状态为completed状态
(七)cronjob控制器
7.1 cronjob说明
- Cron Job 创建基于时间调度的 Jobs
- CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象
- CronJob可以进行周期性任务作业,控制其运行时间点及重复运行的方式
- CronJob可以在特定的时间点(反复的)去运行job任务
7.2 cronjob示例
[root@k8s2 pod]# vim cronjob.yml
apiVersion: batch/v1
kind: CronJob
metadata:name: hello
spec:schedule: "* * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busyboximagePullPolicy: IfNotPresentcommand:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure #当失败后,重新启动pod,但不记录失败次数[root@k8s2 pod]# kubectl apply -f cronjob.yml
五、微服务
微服务相当于主机中的网卡,实现服务发现
编写配置文件时,需要注意格式,保证配置正常运行
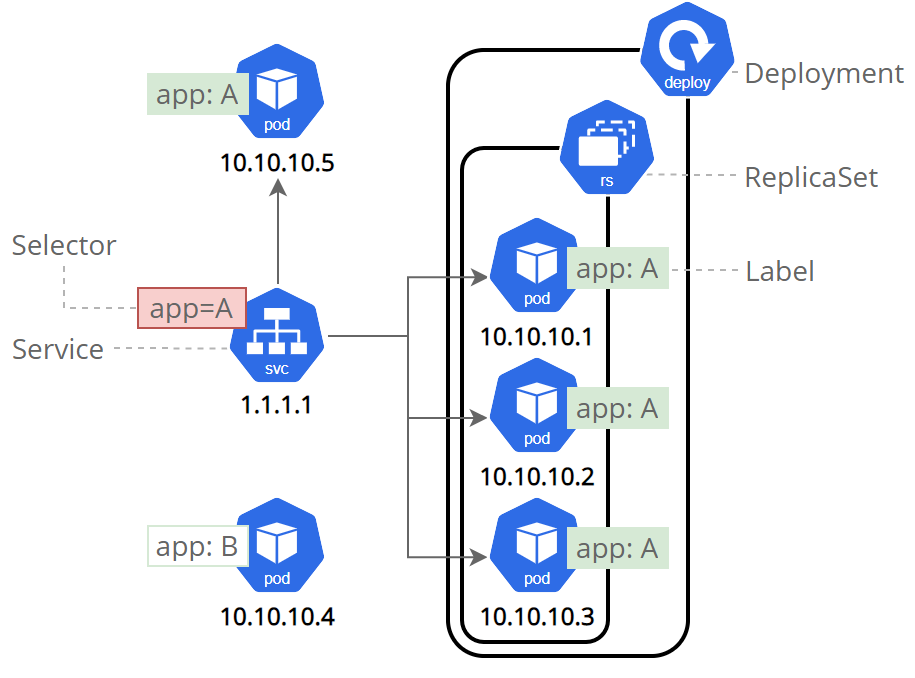
- Service是一组提供相同服务的Pod对外开放的接口
- service默认只支持4层负载均衡能力,没有7层功能(可以通过Ingress实现)
结构图:
(一)微服务的类型
| 微服务类型 | 作用描述 |
|---|---|
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 进行设定) |
前三个类型都是,集群外部访问到集群内部;另一个是,集群内访问集群外部
(二)IPVS模式
- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
- kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源
- IPVS模式的service,可以使K8s集群支持更多量级的Pod
3.1 ipvs模式配置方式
- 在所有节点中安装ipvsadm
[root@k8s-所有节点 pod]dnf install ipvsadm –y
- 修改master节点的代理配置
[root@k8s-master ~]# kubectl -n kube-system edit cm kube-proxymetricsBindAddress: ""mode: "ipvs" #设置kube-proxy使用ipvs模式nftables:
- 配置yml文件
[root@K8smaster build]# vim myappv1.yml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: myappv1name: myappv1
spec:replicas: 2selector:matchLabels:app: myappv1template:metadata:labels:app: myappv1spec:containers:- image: myapp:v1name: myapp
---
apiVersion: v1
kind: Service
metadata:labels:app: myappv1name: myappv1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myappv1type: ClusterIP
- 需重启pod,才能生效
[root@k8s-master ~]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'[root@k8s-master ~]# ipvsadm -Ln


注意:
当切换ipvs模式后,kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0,并分配所有service IP
(三)微服务类型详情
3.1 ClusterIP
- 用于在集群的内部暴露控制器的,在集群内访问,并对集群内的pod提供健康检测和自动发现功能
对于微服务的域名解析
#service创建后集群DNS提供解析[root@K8smaster build]# dig myappv1.default.svc.cluster.local @10.96.0.10; <<>> DiG 9.16.23-RH <<>> myappv1.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28306
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: fa143f2b1d9b817f (echoed)
;; QUESTION SECTION:
;myappv1.default.svc.cluster.local. IN A;; ANSWER SECTION:
myappv1.default.svc.cluster.local. 30 IN A 10.103.231.139;; Query time: 0 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Mon Aug 18 00:03:33 CST 2025
;; MSG SIZE rcvd: 123
3.2 ClusterIP中的特殊模式headless
headless(无头服务)
对于无头 Services 并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度由 dns 单独完成
[root@K8smaster build]# vim myappv1.yml
---
apiVersion: v1
kind: Service
metadata:labels:app: myappv1name: myappv1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myappv1type: ClusterIPclusterIP: "None" #添加此代码
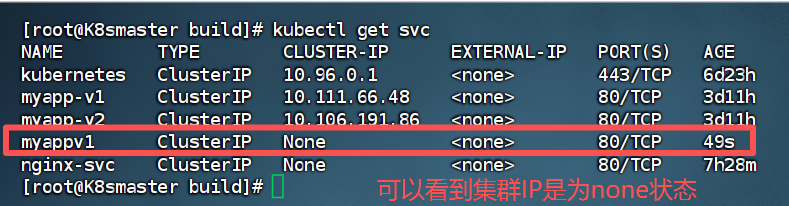
进行域名的解析可以看到
3.3 nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip,来访问pod业务
- 其访问过程为:

---
apiVersion: v1
kind: Service
metadata:labels:app: myappv1name: myappv1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myappv1type: NodePoort #改为NodePort模式
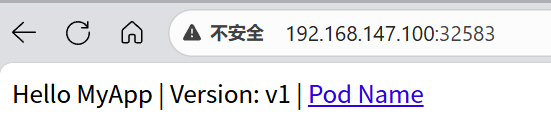
可以看到会生成一个对外的访问端口—32583
[root@K8smaster build]# kubectl get service myappv1
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myappv1 NodePort 10.104.59.217 <none> 80:32583/TCP 22s
通过访问主机的IP+端口就可以访问到pod上
!注意
nodeport默认端口
nodeport默认端口是30000-32767,超出会报错
3.3.1 端口的固定优化
---
apiVersion: v1
kind: Service
metadata:labels:app: myappv1name: myappv1
spec:ports:- port: 80protocol: TCPtargetPort: 80nodePort: 36666 #设置固定的对外端口selector:app: myappv1type: NodePoort
如果需要使用这个范围以外的端口就需要特殊设定
root@k8s-master ~]# vim /etc/kubernetes/manifests/kube-apiserver.yaml- --service-node-port-range=30000-40000
[!NOTE]
添加“–service-node-port-range=“ 参数,端口范围可以自定义
修改后api-server会自动重启,等apiserver正常启动后才能操作集群
集群重启自动完成在修改完参数后全程不需要人为干预
3.4 loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配

[root@k8s-master ~]# vim myappv1.yaml---
apiVersion: v1
kind: Service
metadata:labels:app: myappv1name: myappv1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myappv1type: LoadBalancer[root@k8s2 service]# kubectl apply -f myappv1.yml默认无法分配外部访问IP
[root@k8s2 service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d1h
myappv1 LoadBalancer 10.107.23.134 <pending> 80:32537/TCP 4s
LoadBalancer模式适用云平台,裸金属环境需要安装metallb提供支持
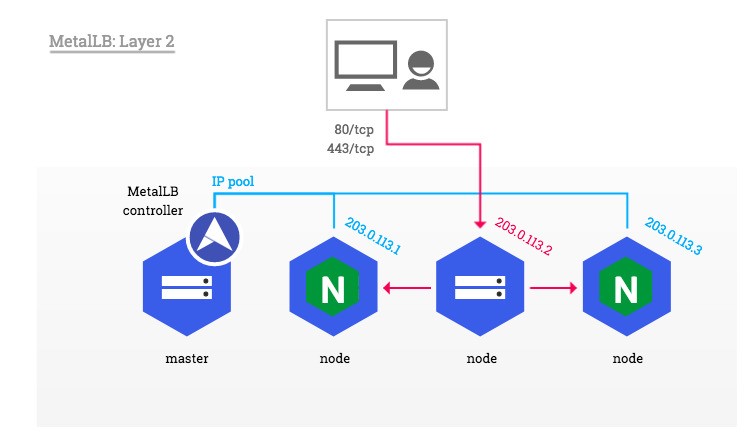
3.5 metalLB
相当于网络中的DHCP,为LoadBalancer分配vip
官网:https://metallb.universe.tf/installation/
部署方式
1.设置ipvs模式
[root@k8s-master ~]# kubectl edit cm -n kube-system kube-proxy
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:strictARP: true[root@k8s-master ~]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'2.下载部署文件
[root@k8s2 metallb]# wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml3.修改文件中镜像地址,与harbor仓库路径保持一致
[root@k8s-master ~]# vim metallb-native.yaml
...
image: metallb/controller:v0.14.8
image: metallb/speaker:v0.14.84.上传镜像到harbor
[root@k8s-master ~]# docker pull quay.io/metallb/controller:v0.14.8
[root@k8s-master ~]# docker pull quay.io/metallb/speaker:v0.14.8[root@k8s-master ~]# docker tag quay.io/metallb/speaker:v0.14.8 reg.timinglee.org/metallb/speaker:v0.14.8
[root@k8s-master ~]# docker tag quay.io/metallb/controller:v0.14.8 reg.timinglee.org/metallb/controller:v0.14.8[root@k8s-master ~]# docker push reg.timinglee.org/metallb/speaker:v0.14.8
[root@k8s-master ~]# docker push reg.timinglee.org/metallb/controller:v0.14.8部署服务
[root@k8s2 metallb]# kubectl apply -f metallb-native.yaml
[root@k8s-master ~]# kubectl -n metallb-system get pods
NAME READY STATUS RESTARTS AGE
controller-65957f77c8-25nrw 1/1 Running 0 30s
speaker-p94xq 1/1 Running 0 29s
speaker-qmpct 1/1 Running 0 29s
speaker-xh4zh 1/1 Running 0 30s配置分配地址段
[root@k8s-master ~]# vim configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:name: first-pool #地址池名称namespace: metallb-system
spec:addresses:- 172.25.254.50-172.25.254.99 #修改为自己本地地址段--- #两个不同的kind中间必须加分割
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:name: examplenamespace: metallb-system
spec:ipAddressPools:- first-pool #使用地址池 [root@k8s-master ~]# kubectl apply -f configmap.yml
ipaddresspool.metallb.io/first-pool created
l2advertisement.metallb.io/example created[root@k8s-master ~]# kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h
timinglee-service LoadBalancer 10.109.36.123 172.25.254.50 80:31595/TCP 9m9s#通过分配地址从集群外访问服务
[root@reg ~]# curl 172.25.254.50
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>4.6 externalname
- 开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
- 一般应用于外部业务和pod沟通或外部业务迁移到pod内时
- 在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
- 集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
示例:
[root@k8s-master ~]# vim timinglee.yaml
---
apiVersion: v1
kind: Service
metadata:labels:app: timinglee-servicename: timinglee-service
spec:selector:app: timingleetype: ExternalNameexternalName: www.timinglee.org[root@k8s-master ~]# kubectl apply -f timinglee.yaml[root@k8s-master ~]# kubectl get services timinglee-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
timinglee-service ExternalName <none> www.timinglee.org <none> 2m58s#测试:
[root@master service]# kubectl run test --image busyboxplus -it
If you don't see a command prompt, try pressing enter./# ping [root@master service]# kubectl run test --image busyboxplus -it
If you don't see a command prompt, try pressing enter./# ping ext-service.default.svc.cluster.local
PING ext-service.default.svc.cluster.local (103.235.46.115): 56 data bytes64 bytes from 103.235.46.115:seq=0 tt1=127 time=331.212 ms
(五)ingress-nginx
5.1 部署ingress
ingress-nginx功能
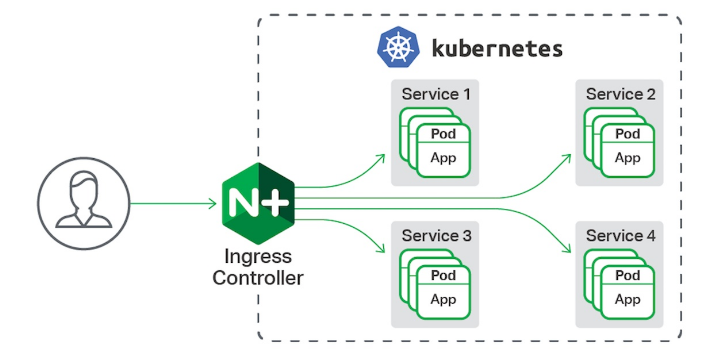
- 一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
- Ingress由两部分组成:Ingress controller和Ingress服务
- Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力
- 业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller
5.1.1 下载部署文件
在Harbor中创建项目ingress-nginx
#在Harbor仓库上传所需镜像
docker tag registry.k8s.io/ingress-nginx/controller:v1.13.1 reg.zym.org/ingress-nginx/controller:v1.13.1docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.1 reg.zym.org/ingress-nginx/kube-webhook-certgen:v1.6.1docker push reg.zym.org/ingress-nginx/kube-webhook-certgen:v1.6.1
docker push reg.zym.org/ingress-nginx/controller:v1.13.1
5.1.2 安装ingress
[root@k8s-master ~]# vim deploy.yaml
image: ingress-nginx/controller:v1.13.1
image: ingress-nginx/kube-webhook-certgen:v1.6.1
image: ingress-nginx/kube-webhook-certgen:v1.6.1[root@k8s-master ~]# kubectl -n ingress-nginx get pods
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-ggqm6 0/1 Completed 0 82s
ingress-nginx-admission-patch-q4wp2 0/1 Completed 0 82s
ingress-nginx-controller-7bf698f798-bkxq2 1/1 Running 0 82s[root@K8smaster build]# kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.104.155.231 172.25.254.50 80:31247/TCP,443:31269/TCP 4h33m
ingress-nginx-controller-admission ClusterIP 10.103.168.235 <none> 443/TCP
提示:
EXTERNAL-IP为对外开放的ip地址
5.1.3 测试ingress
#生成yaml文件
[root@k8s-master ~]# kubectl create ingress webcluster --rule '*/=timinglee-svc:80' --dry-run=client -o yaml > timinglee-ingress.yml
kubectl create ingress
- create表示创建资源,ingress指定要创建的资源类型是 Ingress
webcluster
- 创建的 Ingress 资源的名称,它在所属的命名空间内必须是唯一
--rule '*/=timinglee-svc:80'
-
–rule:参数用于定义 Ingress 的路由规则
*/=timinglee-svc:80表示: -
*:匹配所有的主机名
-
/:匹配所有的 URL 路径,即所有的 HTTP 请求路径都会被这个规则处理
timinglee-svc
- 指定后端要转发流量的 Service 名称
--dry-run=client
- 该参数表示以客户端模拟运行的方式执行命令,不会真正在集群中创建 Ingress 资源,仅在本地对命令进行语法检查,并按照命令执行后的结果生成相应的数据结构
-o yaml
- -o是–output的缩写,用于指定输出格式,yaml表示将命令执行后的结果以 YAML 格式输出
timinglee-ingress.yml
- 这是将命令输出的 YAML 内容重定向到名为timinglee-ingress.yml的文件中,后续可以通过编辑该文件,对 Ingress 配置进行调整
[root@k8s-master ~]# vim timinglee-ingress.yml
aapiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: test-ingress
spec:ingressClassName: nginxrules:- http:paths:- backend:service:name: timinglee-svcport:number: 80path: /pathType: Prefix #Exact(精确匹配),ImplementationSpecific(特定实现),Prefix(前缀匹配),Regular expression(正则表达式匹配)
#建立ingress控制器
[root@k8s-master ~]# kubectl apply -f timinglee-ingress.yml
ingress.networking.k8s.io/webserver created[root@k8s-master ~]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress nginx * 172.25.254.10 80 8m30s
5.2 ingress高级用法
5.2.1 基于路径进行访问
A. 测试配置yaml编写
[root@k8s-master app]# kubectl create deployment myapp-v1 --image myapp:v1 --dry-run=client -o yaml > myapp-v1.yaml[root@k8s-master app]# kubectl create deployment myapp-v2 --image myapp:v2 --dry-run=client -o yaml > myapp-v2.yaml[root@k8s-master app]# vim myapp-v1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: myapp-v1name: myapp-v1
spec:replicas: 1selector:matchLabels:app: myapp-v1strategy: {}template:metadata:labels:app: myapp-v1spec:containers:- image: myapp:v1name: myapp---apiVersion: v1
kind: Service
metadata:labels:app: myapp-v1name: myapp-v1
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myapp-v1[root@k8s-master app]# vim myapp-v2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: myapp-v2name: myapp-v2
spec:replicas: 1selector:matchLabels:app: myapp-v2template:metadata:labels:app: myapp-v2spec:containers:- image: myapp:v2name: myapp
---
apiVersion: v1
kind: Service
metadata:labels:app: myapp-v2name: myapp-v2
spec:ports:- port: 80protocol: TCPtargetPort: 80selector:app: myapp-v2
#将端口写到容器内
[root@k8s-master app]# kubectl expose deployment myapp-v1 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v1.yaml[root@k8s-master app]# kubectl expose deployment myapp-v2 --port 80 --target-port 80 --dry-run=client -o yaml >> myapp-v1.yaml
查看services
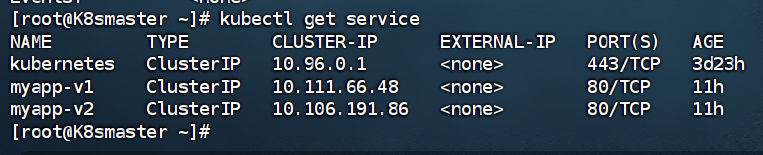
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d23h
myapp-v1 ClusterIP 10.111.66.48 <none> 80/TCP 11h
myapp-v2 ClusterIP 10.106.191.86 <none> 80/TCP 11h
B. 编写建立ingress的yaml文件
#vim ingress1.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/rewrite-target: /name: ingress1
spec:ingressClassName: nginxrules:- host: www.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /v1pathType: Prefix- backend:service:name: myapp-v2port:number: 80path: /v2pathType: Prefix
C. 效果测试:
#测试:
[root@reg ~]# echo 172.25.254.50 www.timinglee.org >> /etc/hosts[root@reg ~]# curl www.timinglee.org/v1
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl www.timinglee.org/v2
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>#nginx.ingress.kubernetes.io/rewrite-target: / 功能实现
[root@reg ~]# curl www.timinglee.org/v2/aaaa
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
5.2.4 建立auth认证
#建立认证文件
[root@k8s-master app]# dnf install httpd-tools -y
[root@k8s-master app]# htpasswd -cm auth lee
New password:
Re-type new password:
Adding password for user lee
[root@k8s-master app]# cat auth
lee:$apr1$BohBRkkI$hZzRDfpdtNzue98bFgcU10#建立认证类型资源
[root@k8s-master app]# kubectl create secret generic auth-web --from-file auth
root@k8s-master app]# kubectl describe secrets auth-web
Name: auth-web
Namespace: default
Labels: <none>
Annotations: <none>Type: OpaqueData
====
auth: 42 bytes
#建立ingress4基于用户认证的yaml文件
[root@k8s-master app]# vim ingress4.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/auth-type: basicnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-realm: "Please input username and password"name: ingress4
spec:tls:- hosts:- myapp-tls.timinglee.orgsecretName: web-tls-secretingressClassName: nginxrules:- host: myapp-tls.timinglee.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix#建立ingress4
[root@k8s-master app]# kubectl apply -f ingress4.yml
ingress.networking.k8s.io/ingress4 created
[root@k8s-master app]# kubectl describe ingress ingress4
Name: ingress4
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
TLS:web-tls-secret terminates myapp-tls.timinglee.org
Rules:Host Path Backends---- ---- --------myapp-tls.timinglee.org/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/auth-realm: Please input username and passwordnginx.ingress.kubernetes.io/auth-secret: auth-webnginx.ingress.kubernetes.io/auth-type: basic
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 14s nginx-ingress-controller Scheduled for sync
结果测试:测试前需要解析主机名
(六)Canary金丝雀发布
6.1 金丝雀发布介绍
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
6.2 Canary发布方式
其中header和weiht中的最多
6.2.1 基于header(http包头)灰度
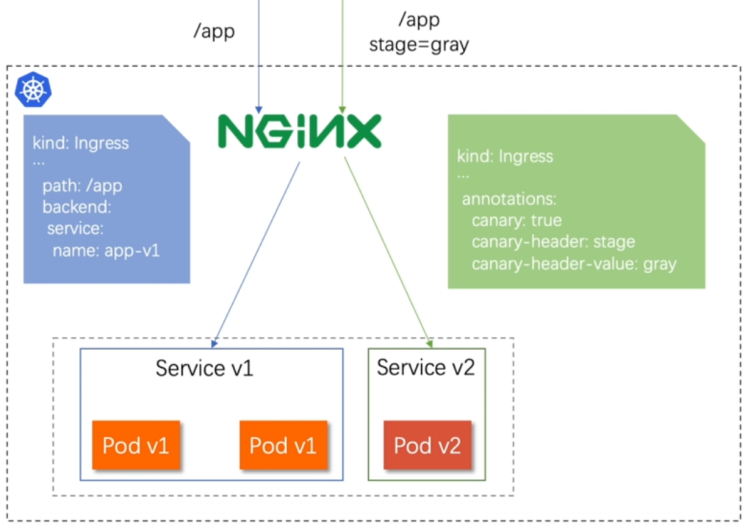
- 通过Annotaion扩展
- 创建灰度ingress,配置灰度头部key以及value
- 灰度流量验证完毕后,切换正式ingress到新版本
- 之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
配置示例:
#建立版本1的ingress
[root@k8s-master app]# vim ingress7.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:name: myapp-v1-ingress
spec:ingressClassName: nginxrules:- host: myapp.zym.orghttp:paths:- backend:service:name: myapp-v1port:number: 80path: /pathType: Prefix[root@k8s-master app]# kubectl apply -f ingress7.yml
如图配置查看
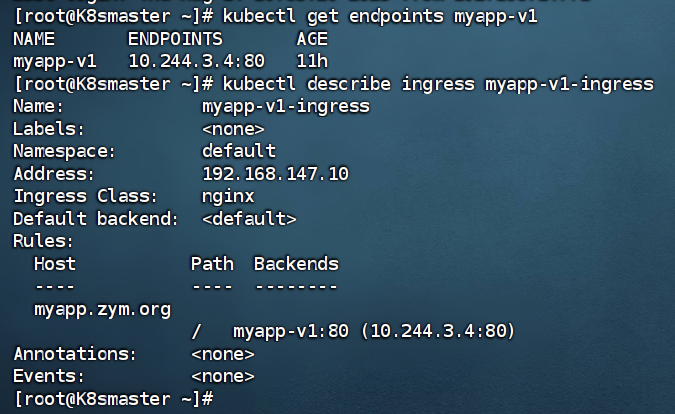
#建立基于版本2的ingress
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/canary: "true"nginx.ingress.kubernetes.io/canary-by-header: versionnginx.ingress.kubernetes.io/canary-by-header-value: "2"name: myapp-v2-ingress
spec:ingressClassName: nginxrules:- host: myapp.zym.orghttp:paths:- backend:service:name: myapp-v2port:number: 80path: /pathType: Prefix[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
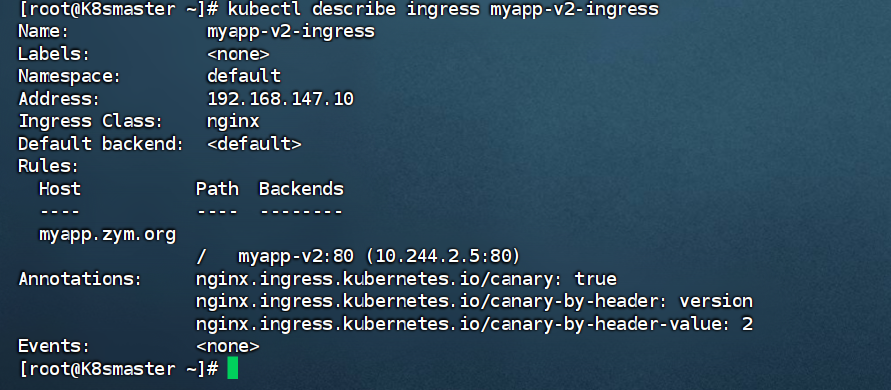
#测试:
[root@K8smaster build]# curl myapp.zym.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@K8smaster build]# curl -H "version: 2" myapp.zym.org
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
6.2.2 基于权重的灰度发布
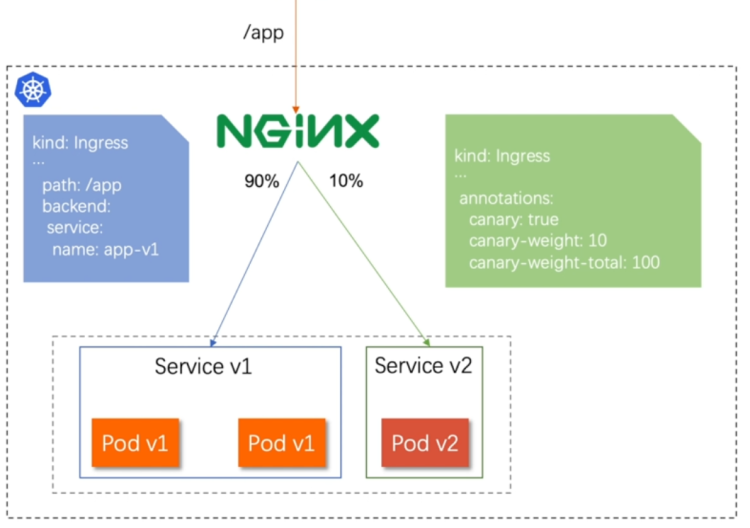
- 通过Annotaion拓展
- 创建灰度ingress,配置灰度权重以及总权重
- 灰度流量验证完毕后,切换正式ingress到新版本
配置示例
#基于权重的灰度发布
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:annotations:nginx.ingress.kubernetes.io/canary: "true"nginx.ingress.kubernetes.io/canary-weight: "10" #更改权重值nginx.ingress.kubernetes.io/canary-weight-total: "100"name: myapp-v2-ingress
spec:ingressClassName: nginxrules:- host: myapp.timinglee.orghttp:paths:- backend:service:name: myapp-v2port:number: 80path: /pathType: Prefix[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created#测试:
[root@reg ~]# vim check_ingress.sh
#!/bin/bash
v1=0
v2=0for (( i=0; i<100; i++))
doresponse=`curl -s myapp.timinglee.org |grep -c v1`v1=`expr $v1 + $response`v2=`expr $v2 + 1 - $response`done
echo "v1:$v1, v2:$v2"[root@reg ~]# sh check_ingress.sh
v1:90, v2:10#更改完毕权重后继续测试可观察变化
六、K8s储存管理
(一)configmap
1.1 configmap的功能
用于存储非敏感的配置数据,以键值对的形式存在,使得应用程序可以在不修改镜像的情况下读取不同的配置信息,进行pod的配置
- configMap用于保存配置数据,以键值对形式存储
- configMap 资源提供了向 Pod 注入配置数据的方法
- 镜像和配置文件解耦,以便实现镜像的可移植性和可复用性
- etcd限制了文件大小不能超过1M
1.2 configmap的使用场景
- 填充环境变量的值
- 设置容器内的命令行参数
- 填充卷的配置文件
1.3 configmap创建方式
1.3.1 字面值的创建
[root@K8smaster ~]# kubectl create cm zym-config --from-literal fname=liubailiushiliu --from-literal name=zym
configmap/zym-config created
[root@K8smaster ~]# kubectl describe cm zym-config
Name: zym-config
Namespace: default
Labels: <none>
Annotations: <none>Data
====
fname:
----
liubailiushiliu
name:
----
zymBinaryData
====Events: <none>
1.3.2 通过文件创建
[root@K8smaster ~]# kubectl create cm zym2-config --from-file /etc/resolv.conf
configmap/zym2-config created
[root@K8smaster ~]# kubectl describe cm zym2-config
Name: zym2-config
Namespace: default
Labels: <none>
Annotations: <none>Data
====
resolv.conf:
----
# Generated by NetworkManager
search zym.org
nameserver 8.8.8.8BinaryData
====Events: <none>
1.3.3 通过目录创建
[root@K8smaster ~]# kubectl create cm zym3-config --from-file zymconfig/
configmap/zym3-config created
[root@K8smaster ~]# kubectl describe cm zym3-config
Name: zym3-config
Namespace: default
Labels: <none>
Annotations: <none>Data
====
fstab:
----#
# /etc/fstab
# Created by anaconda on Fri Jul 11 02:10:59 2025
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
UUID=c37e3bfa-0b77-4e9a-9b23-880e9bd2dfab / xfs defaults 0 0
UUID=c2a71f8f-02fb-407f-94f0-91e81b201c49 /boot xfs defaults 0 0
#UUID=1d85bab1-7292-44e0-8c9f-cc996a24a9a2 none swap defaults 0 0rc.local:
----
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.touch /var/lock/subsys/local
mount /dev/cdrom /rhel9/
mount /dev/cdrom /rhel9/BinaryData
====Events: <none>
1.3.4 通过yaml文件创建
[root@K8smaster ~]# kubectl create cm zym4-config --from-literal db_host=192.168.147.100 --from-literal db_port=3306 --dry-run=client -o yaml > zym-config.yamlapiVersion: v1
data:db_host: 192.168.147.100db_port: "3306"
kind: ConfigMap
metadata:name: zym4-config#生成configmap
[root@K8smaster ~]# kubectl apply -f zym-config.yaml
[root@K8smaster ~]# kubectl describe cm zym4-config
Name: zym4-config
Namespace: default
Labels: <none>
Annotations: <none>Data
====
db_host:
----
192.168.147.100
db_port:
----
3306BinaryData
====Events: <none>
1.4 configmap使用方式
- 通过环境变量的方式直接传递,挂载到pod中
- 通过pod的命令行运行方式
1.4.1 使用configmap填充环境变量
注意:Kubectl apply只能在正在运行中的pod进行打补丁
#把cm中的内容映射为指定变量
[root@k8s-master ~]# vim testpod1.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:containers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- envenv:- name: key1valueFrom:configMapKeyRef:name: zym4-configkey: db_host- name: key2valueFrom:configMapKeyRef:name: zym4-configkey: db_portrestartPolicy: Never[root@k8s-master ~]# kubectl apply -f testpod.yml
pod/testpod created
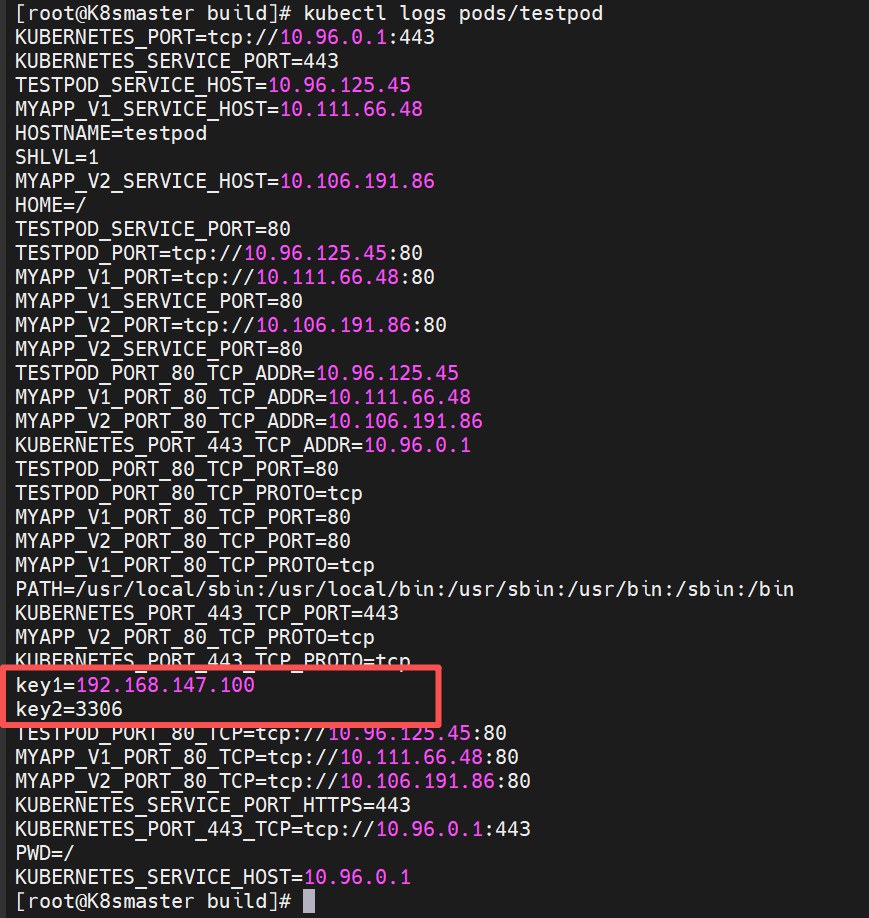
#把cm中的值直接映射为变量
[root@k8s-master ~]# vim testpod2.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:containers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- envenvFrom:- configMapRef:name: lee4-configrestartPolicy: Never#查看日志
[root@k8s-master ~]# kubectl logs pods/testpod
#在pod命令行中使用变量
[root@k8s-master ~]# vim testpod3.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:containers:- image: busyboxplus:latestname: testpodcommand:- /bin/sh- -c- echo ${db_host} ${db_port} #变量调用需envFrom:- configMapRef:name: lee4-configrestartPolicy: Never#查看日志
[root@k8s-master ~]# kubectl logs pods/testpod
172.25.254.100 3306
(二)secrets配置管理
2.1 功能介绍
在公有和私有的仓库中,均需要密钥信息才可以被使用
-
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
-
Pod 可以用两种方式使用 secret:
- 作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里
-
当 kubelet 为 pod 拉取镜像时使用
2.2 secret创建方法
[root@K8smaster ~]# mkdir -p secrets
[root@K8smaster ~]# echo -n zym > username.txt
[root@K8smaster ~]# echo -n 123456 > password.txt[root@K8smaster ~]# kubectl create secret generic userlist --from-file username.txt --from-file password.txt
查看信息:
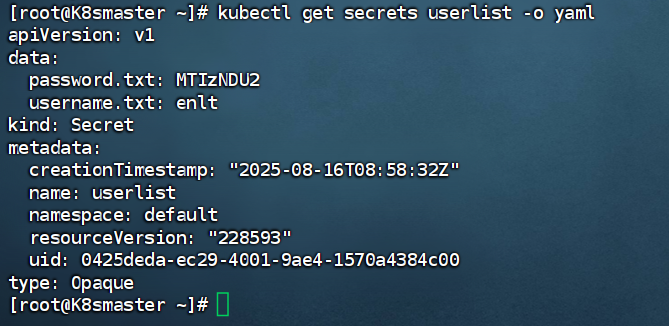
#查看密码编码
[root@K8smaster ~]# echo -n zym | base64
enlt
[root@K8smaster ~]# echo -n 123456 | base64
MTIzNDU2[root@k8s-master secrets]# kubectl create secret generic userlist --dry-run=client -o yaml > userlist.yml
编写yaml
apiVersion: v1
kind: Secret
metadata:creationTimestamp: nullname: userlist
type: Opaque
data:username: enlt #用户名password: MTIzNDU2 #密码
查看:
[root@K8smaster secrets]# kubectl apply -f userlist.yml
2.3 Secretss使用方法
2.3.4 存储docker registry的认证信息
建立私有仓库并上传镜像
成功上传,如上图所示
[root@Harbor packages]# docker load -i game2048.tar.gz
Loaded image: timinglee/game2048:latest[root@Harbor packages]# docker tag timinglee/game2048:latest reg.zym.org/zym/game2048:latest[root@Harbor packages]# docker push reg.zym.org/zym/game2048
创建Docker认证的secret
[root@K8smaster build]# kubectl create secret docker-registry my-registry-secret --docker-server=reg.zym.org --docker-username=admin --docker-password=123456
编写yaml文件
apiVersion: v1
kind: Pod
metadata:labels:name: game2048name: game2048
spec:imagePullSecrets: #镜像拉取密钥- name: my-registry-secret #密钥名称containers:- image: reg.zym.org/zym/game2048:latestname: game2048
运行:
[root@K8smaster build]# kubectl apply -f pod3.yml
pod/game2048 created
[root@K8smaster build]# kubectl get pods
NAME READY STATUS RESTARTS AGE
game2048 1/1 Running 0 12s
(三) volumes卷配置管理
卷的两点重要性
- 数据的持久化
- 共享存储
存储卷的区别
| 存储类型 | 生命周期 | 数据持久性 | 适用场景 |
|---|---|---|---|
| emptyDir | 与 Pod 绑定 | 临时(Pod 删除丢失) | 容器间临时共享数据 |
| hostPath | 与节点绑定 | 节点本地持久化 | 单节点测试(不适合生产) |
| PersistentVolume | 集群级独立生命周期 | 跨 Pod / 节点持久化 | 生产环境数据存储(如数据库) |
3.1 emptyDir卷
emptyDir 是 Kubernetes 中一种简单的临时存储卷,它的核心特点是生命周期与 Pod 绑定,主要用于 Pod 内部容器之间共享数据,或存储临时数据
- 无法进行数据的持久化
emptyDir 的使用场景:
- 缓存空间,例如基于磁盘的归并排序
- 耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行
- 在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件
示例配置:
[root@k8s-master volumes]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: busyboxplus:latestname: vm1command:- /bin/sh- -c- sleep 30000000volumeMounts:- mountPath: /cachename: cache-vol- image: nginx:latestname: vm2volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volemptyDir:medium: MemorysizeLimit: 100Mi[root@k8s-master volumes]# kubectl apply -f pod1.yml#查看pod中卷的使用情况
[root@k8s-master volumes]# kubectl describe pods vol1#测试效果[root@k8s-master volumes]# kubectl exec -it pods/vol1 -c vm1 -- /bin/sh
/ # cd /cache/
/cache # ls
/cache # curl localhost
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
/cache # echo timinglee > index.html
/cache # curl localhost
timinglee
/cache # dd if=/dev/zero of=bigfile bs=1M count=101
dd: writing 'bigfile': No space left on device
101+0 records in
99+1 records out
3.2 hostpath卷
在 Kubernetes 中,hostPath卷的核心功能是将节点(Node)的本地文件系统路径挂载到 Pod 的容器中,实现 Pod 与所在节点之间的文件共享
- 可以进行数据持久化保存
示例配置:
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: nginx:1.23name: vm1volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volhostPath:path: /datatype: DirectoryOrCreate #当/data目录不存在时自动建立
测试:
[root@K8smaster build]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
vol1 1/1 Running 0 5m33s 10.244.3.6 k8sslave2.zym.org
在node节点上
[root@k8s-node2 ~]# echo liubailiu > /data/index.html
[root@k8s-master volumes]# curl 10.244.3.6s
liubailiu#当pod被删除后hostPath不会被清理
[root@k8s-master volumes]# kubectl delete -f pod2.yml
pod "vol1" deleted
[root@k8s-node2 ~]# ls /data/
index.html
3.4 nfs卷
-
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中,意思是:在集群以外创建一个NFS的服务器,pod挂载在NFS卷上,实现数据的持久化
-
如果有多个容器需要访问相同的数据集,或者需要将容器中的数据持久保存到外部存储,NFS 卷可以提供一种方便的解决方案
3.4.1部署一台nfs共享主机
#举例用Harbor仓库作为nfs共享主机
[root@Harbor packages]# dnf install nfs-utils -y[root@Harbor ~]# vim /etc/exports
/nfsdata *(rw,sync,no_root_squash)[root@Harbor ~]# mkdir -p /nfsdata
[root@Harbor ~]# exportfs -rv
exporting *:/nfsdata[root@Harbor ~]# showmount -e
Export list for Harbor.zym.org:
/nfsdata *
K8s集群上的所有节点均需安装nfs-utils
[root@k8s-master & node1 & node2 ~]# dnf install nfs-utils -y
3.4.2 部署nfs卷
配置yaml文件–pod3.yml
apiVersion: v1
kind: Pod
metadata:name: vol1
spec:containers:- image: nginx:1.23name: vm1volumeMounts:- mountPath: /usr/share/nginx/htmlname: cache-volvolumes:- name: cache-volnfs:server: 192.168.147.200path: /nfsdata[root@K8smaster build]# kubectl apply -f pod3.yml
pod/vol1 created[root@K8smaster build]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
vol1 1/1 Running 0 20s 10.244.3.8 k8sslave2.zym.org
#访问该IP
curl 10.244.3.8
测试:
在nfs主机上创建内容文件
[root@Harbor ~]# echo liubailiushiliu > /nfsdata/index.html
集群中访问查看

3.5 PersistentVolume持久卷
PV 的核心是将存储资源(如 NFS、本地磁盘、云存储等)抽象为集群中的一种 “资源”,供 Pod 通过 PersistentVolumeClaim(PVC)申请使用,解决了 Pod 生命周期与数据持久化的矛盾(Pod 删除后,PV 中的数据仍可保留)
- pv和pod是相互独立的
- pv是集群中的一种资源,是一种Volume的插件
- pv的提供方式有两种方式:
- 静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
- 动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass;当pod要使用资源的时候,会调用一个class自动创建pv存储分配器,去到nfs主机中读取数据
PersistentVolumeClaim(持久卷声明,简称PVC)
-
是用户的一种存储请求
-
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
-
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
-
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes
-
容量(capacity):指定存储大小(如 10Gi)
-
访问模式(accessModes)
:支持的访问方式,包括:
ReadWriteOnce(RWO):仅允许单个节点读写ReadOnlyMany(ROX):允许多个节点只读ReadWriteMany(RWX):允许多个节点读写(需存储类型支持)
-
回收策略(persistentVolumeReclaimPolicy)
:PVC 释放后 PV 的处理方式:
Retain:保留数据,需手动清理(默认)Delete:自动删除 PV 及关联存储(适合云存储)Recycle:清空数据后可被重新申请(已废弃,推荐用 Retain)
-
存储类(storageClassName):关联到特定存储类(StorageClass),实现动态 PV 创建
注意:
[!NOTE]
只有NFS和HostPath支持回收利用
AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作
静态PV实例
#在nfs主机中建立实验目录
[root@reg ~]# mkdir /nfsdata/pv{1..3}
#编写创建pv的yml文件,pv是集群资源,不在任何namespace中
[root@k8s-master pvc]# vim pv.yml
apiVersion: v1
kind: PersistentVolume
metadata:name: pv1
spec:capacity:storage: 5GivolumeMode: FilesystemaccessModes:- ReadWriteOncepersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv1server: 192.168.147.200---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv2
spec:capacity:storage: 15GivolumeMode: FilesystemaccessModes:- ReadWriteManypersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv2server: 192.168.147.200
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv3
spec:capacity:storage: 25GivolumeMode: FilesystemaccessModes:- ReadOnlyManypersistentVolumeReclaimPolicy: RetainstorageClassName: nfsnfs:path: /nfsdata/pv3server: 192.168.1417.200
[root@K8smaster pvc]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pv1 5Gi RWO Retain Available nfs <unset> 5s
pv2 15Gi RWX Retain Available nfs <unset> 5s
pv3 25Gi ROX Retain Available nfs <unset> 5s
#建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
[root@k8s-master pvc]# vim pvc.ym
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc1
spec:storageClassName: nfsaccessModes:- ReadWriteOnceresources:requests:storage: 1Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc2
spec:storageClassName: nfsaccessModes:- ReadWriteManyresources:requests:storage: 10Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc3
spec:storageClassName: nfsaccessModes:- ReadOnlyManyresources:requests:storage: 15Gi
如图所示:为Bound状态

#在其他namespace中是无法应用
[root@k8s-master pvc]# kubectl -n kube-system get pvc
No resources found in kube-system namespace.
在pod中使用pvc
[root@k8s-master pvc]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:name: timinglee
spec:containers:- image: nginxname: nginxvolumeMounts:- mountPath: /usr/share/nginx/htmlname: vol1volumes:- name: vol1persistentVolumeClaim:claimName: pvc1[root@k8s-master pvc]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
timinglee 1/1 Running 0 83s 10.244.2.54 k8s-node2 <none> <none>
[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# curl localhost
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.27.1</center>
</body>
</html>
root@timinglee:/# cd /usr/share/nginx/
root@timinglee:/usr/share/nginx# ls
html
root@timinglee:/usr/share/nginx# cd html/
root@timinglee:/usr/share/nginx/html# ls[root@reg ~]# echo timinglee > /data/pv1/index.html[root@k8s-master pvc]# kubectl exec -it pods/timinglee -- /bin/bash
root@timinglee:/# cd /usr/share/nginx/html/
root@timinglee:/usr/share/nginx/html# ls
index.html
排错方法:
kubectl -n nfs-client-provisioner get pods
kubectl -n nfs-client-provisioner describe pod <pod名称> # 替换为上一步获取的Pod名称
(四)存储类storageclass
StorageClass(存储类) 是用于动态管理持久化存储的 API 资源,它为管理员提供了一种定义 “存储类型” 的方式,能够自动创建满足特定需求的持久卷(PersistentVolume,PV),从而简化存储管理流程
- StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务
- 每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
4.1 StorageClass的属性
属性说明:https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
**Provisioner(存储分配器):**用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
**Reclaim Policy(回收策略):**通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
4.2 存储分配器NFS Client Provisioner
源码地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
-
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
-
PV以
${namespace}-${pvcName}-${pvName}的命名格式提供(在NFS服务器上) -
PV回收的时候以
archieved-${namespace}-${pvcName}-${pvName}的命名格式(在NFS服务器上)
4.3 部署NFS Client Provisioner
4.3.1 创建sa并授权
[root@k8s-master storageclass]# vim rbac.yml
apiVersion: v1
kind: Namespace
metadata:name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisionernamespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runner
rules:- apiGroups: [""]resources: ["nodes"]verbs: ["get", "list", "watch"] #设置可以“显示,列出,监控”的动作- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: nfs-client-provisioner
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-client-provisioner
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: nfs-client-provisioner
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io#查看rbac信息
[root@k8s-master storageclass]# kubectl apply -f rbac.yml
namespace/nfs-client-provisioner created
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
[root@k8s-master storageclass]# kubectl -n nfs-client-provisioner get sa
NAME SECRETS AGE
default 0 14s
nfs-client-provisioner 0 14s
4.4.2 部署应用
[root@k8s-master storageclass]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nfs-client-provisionerlabels:app: nfs-client-provisionernamespace: nfs-client-provisioner
spec:replicas: 1strategy:type: Recreateselector:matchLabels:app: nfs-client-provisionertemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisionercontainers:- name: nfs-client-provisionerimage: sig-storage/nfs-subdir-external-provisioner:v4.0.2volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: k8s-sigs.io/nfs-subdir-external-provisioner- name: NFS_SERVERvalue: 172.25.254.250- name: NFS_PATHvalue: /nfsdatavolumes:- name: nfs-client-rootnfs:server: 172.25.254.250path: /nfsdata[root@k8s-master storageclass]# kubectl -n nfs-client-provisioner get deployments.apps nfs-client-provisioner
NAME READY UP-TO-DATE AVAILABLE AGE
nfs-client-provisioner 1/1 1 1 86s
4.4.3 创建存储类
[root@k8s-master storageclass]# vim class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:archiveOnDelete: "false"[root@k8s-master storageclass]# kubectl apply -f class.yaml
storageclass.storage.k8s.io/nfs-client created
[root@k8s-master storageclass]# kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 9s
4.4.4 创建pvc
[root@k8s-master storageclass]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claim
spec:storageClassName: nfs-clientaccessModes:- ReadWriteManyresources:requests:storage: 1G
[root@k8s-master storageclass]# kubectl apply -f pvc.yml
persistentvolumeclaim/test-claim created[root@k8s-master storageclass]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
test-claim Bound pvc-7782a006-381a-440a-addb-e9d659b8fe0b 1Gi RWX nfs-client <unset> 21m4.4.5 创建测试pod
[root@k8s-master storageclass]# vim pod.yml
kind: Pod
apiVersion: v1
metadata:name: test-pod
spec:containers:- name: test-podimage: busyboxcommand:- "/bin/sh"args:- "-c"- "touch /mnt/SUCCESS && exit 0 || exit 1"volumeMounts:- name: nfs-pvcmountPath: "/mnt"restartPolicy: "Never"volumes:- name: nfs-pvcpersistentVolumeClaim:claimName: test-claim[root@k8s-master storageclass]# kubectl apply -f pod.yml[root@reg ~]# ls /data/default-test-claim-pvc-b1aef9cc-4be9-4d2a-8c5e-0fe7716247e2/
SUCCESS
4.4.6 设置默认存储类
-
在未设定默认存储类时pvc必须指定使用类的名称
-
在设定存储类后创建pvc时可以不用指定storageClassName
#一次性指定多个pvc
[root@k8s-master pvc]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc1
spec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:requests:storage: 1Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc2
spec:storageClassName: nfs-clientaccessModes:- ReadWriteManyresources:requests:storage: 10Gi---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc3
spec:storageClassName: nfs-clientaccessModes:- ReadOnlyManyresources:requests:storage: 15Giroot@k8s-master pvc]# kubectl apply -f pvc.yml
persistentvolumeclaim/pvc1 created
persistentvolumeclaim/pvc2 created
persistentvolumeclaim/pvc3 created
[root@k8s-master pvc]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc1 Bound pvc-25a3c8c5-2797-4240-9270-5c51caa211b8 1Gi RWO nfs-client <unset> 4s
pvc2 Bound pvc-c7f34d1c-c8d3-4e7f-b255-e29297865353 10Gi RWX nfs-client <unset> 4s
pvc3 Bound pvc-5f1086ad-2999-487d-88d2-7104e3e9b221 15Gi ROX nfs-client <unset> 4s
test-claim Bound pvc-b1aef9cc-4be9-4d2a-8c5e-0fe7716247e2 1Gi RWX nfs-client <unset> 9m9s设定默认存储类
[root@k8s-master storageclass]# kubectl edit sc nfs-client
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"nfs-client"},"parameters":{"archiveOnDelete":"false"},"provisioner":"k8s-sigs.io/nfs-subdir-external-provisioner"}storageclass.kubernetes.io/is-default-class: "true" #设定默认存储类creationTimestamp: "2024-09-07T13:49:10Z"name: nfs-clientresourceVersion: "218198"uid: 9eb1e144-3051-4f16-bdec-30c472358028
parameters:archiveOnDelete: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
reclaimPolicy: Delete
volumeBindingMode: Immediate#测试,未指定storageClassName参数
[root@k8s-master storageclass]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: test-claim
spec:accessModes:- ReadWriteManyresources:requests:storage: 1Gi[root@k8s-master storageclass]# kubectl apply -f pvc.yml
persistentvolumeclaim/test-claim created
[root@k8s-master storageclass]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
test-claim Bound pvc-b96c6983-5a4f-440d-99ec-45c99637f9b5 1Gi RWX nfs-client <unset> 7s(五)StatefulSet控制器
用于管理有状态应用的工作负载控制器,专为需要稳定标识、持久存储和有序部署 / 扩展 / 更新的应用设计。与管理无状态应用的 Deployment 不同,StatefulSet 为每个 Pod 提供固定的身份和一致的部署顺序,确保有状态服务(如数据库、分布式系统、消息队列等)的可靠运行
StatefulSet 的工作依赖两个关键组件:
- Headless Service:为 Pod 提供稳定的网络标识(DNS 记录),不分配集群 IP
- StatefulSet 资源:定义 Pod 模板、扩缩容策略、更新策略等
5.1 构建方法
#建立无头服务
[root@k8s-master statefulset]# vim headless.yml
apiVersion: v1
kind: Service
metadata:name: nginx-svclabels:app: nginx
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
[root@k8s-master statefulset]# kubectl apply -f headless.yml#建立statefulset
[root@k8s-master statefulset]# vim statefulset.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:name: web
spec:serviceName: "nginx-svc"replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxvolumeMounts:- name: wwwmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: wwwspec:storageClassName: nfs-clientaccessModes:- ReadWriteOnceresources:kuberequests:storage: 1Gi
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web configured
root@k8s-master statefulset]# kubectl get pods
NAME READY STATUS RESTARTS kuh AGE
web-0 1/1 Running 0 3m26s
web-1 1/1 Running 0 3m22s
web-2 1/1 Running 0 3m18s[root@reg nfsdata]# ls /nfsdata/
default-test-claim-pvc-34b3d968-6c2b-42f9-bbc3-d7a7a02dcbac
default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f
default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c
default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854
5.2 测试:
#为每个pod建立index.html文件[root@reg nfsdata]# echo web-0 > default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f/index.html
[root@reg nfsdata]# echo web-1 > default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c/index.html
[root@reg nfsdata]# echo web-2 > default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854/index.html#建立测试pod访问web-0~2
[root@k8s-master statefulset]# kubectl run -it testpod --image busyboxplus
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2#删掉重新建立statefulset
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web created#访问依然不变
[root@k8s-master statefulset]# kubectl attach testpod -c testpod -i -t
If you don't see a command prompt, try pressing enter.
/ # cu
curl cut
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
测试截图:
5.3 statefulset的弹缩
首先,想要弹缩的StatefulSet. 需先清楚是否能弹缩该应用
用命令改变副本数
$ kubectl scale statefulsets <stateful-set-name> --replicas=<new-replicas>
通过编辑配置改变副本数
$ kubectl edit statefulsets.apps <stateful-set-name>
statefulset有序回收
[root@k8s-master statefulset]# kubectl scale statefulset web --replicas 0
statefulset.apps/web scaled
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl delete pvc --all
persistentvolumeclaim "test-claim" deleted
persistentvolumeclaim "www-web-0" deleted
persistentvolumeclaim "www-web-1" deleted
persistentvolumeclaim "www-web-2" deleted
persistentvolumeclaim "www-web-3" deleted
persistentvolumeclaim "www-web-4" deleted
persistentvolumeclaim "www-web-5" deleted
[root@k8s2 statefulset]# kubectl scale statefulsets web --replicas=0[root@k8s2 statefulset]# kubectl delete -f statefulset.yaml[root@k8s2 mysql]# kubectl delete pvc --all
七、K8s通信与调度
(一)网络通信
1.1 k8s的通信架构
- k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
- CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下:
a. 虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信
b. 多路复用:MacVLAN,多个容器共用一个物理网卡进行通信
c. 硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好
- 容器间通信:
- 同一个pod内的多个容器间的通信,通过lo回环接口即可实现pod之间的通信
- 同一节点的pod之间通过cni网桥转发数据包。
- 不同节点的pod之间的通信需要网络插件支持
- pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,做不了nat转换
- pod和外网通信:iptables的MASQUERADE
- Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
1.2 flannel网络插件
插件组成:
| 插件 | 功能 |
|---|---|
| VXLAN | 即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出覆盖网络(Overlay Network) |
| VTEP | VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因 |
| Cni0 | 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡) |
| Flannel.1 | TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端 |
| Flanneld | flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息 |
1.2.1 flannel跨主机通信原理
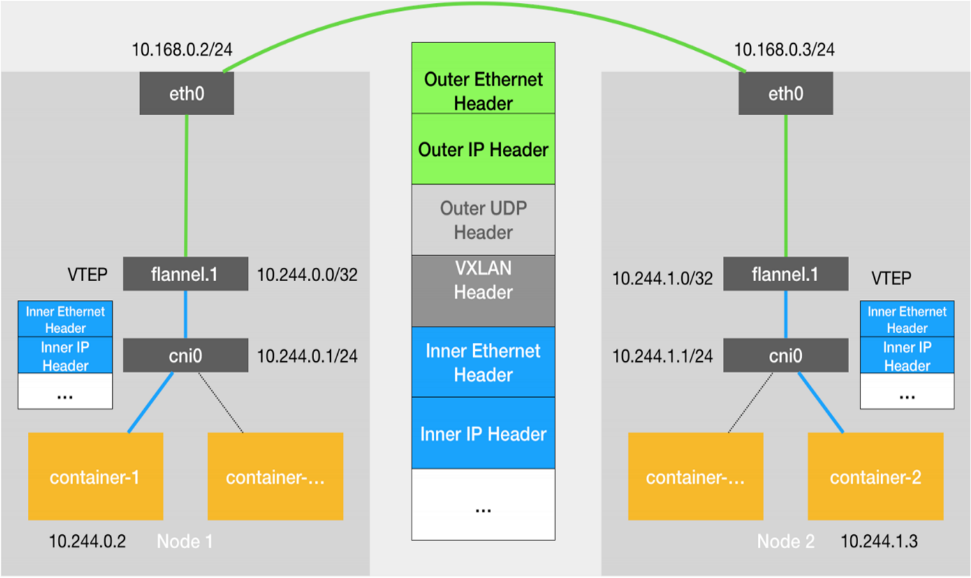
通信原理解析:
- 当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
- VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
- 内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输
- Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识
- flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的
- linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取
- 此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器
1.2.2 flannel支持的后端模式
| 网络模式 | 功能 |
|---|---|
| vxlan | 报文封装,默认模式 |
| Directrouting | 直接路由,跨网段使用vxlan,同网段使用host-gw模式 |
| host-gw | 主机网关,性能好,但只能在二层网络中,不支持跨网络 如果有成千上万的Pod,容易产生广播风暴,不推荐 |
| UDP | 性能差,不推荐 |
更改flannel的默认模式
[root@k8s-master ~]# kubectl -n kube-flannel edit cm kube-flannel-cfg
apiVersion: v1
data:cni-conf.json: |{"name": "cbr0","cniVersion": "0.3.1","plugins": [{"type": "flannel","delegate": {"hairpinMode": true,"isDefaultGateway": true}},{"type": "portmap","capabilities": {"portMappings": true}}]}net-conf.json: |{"Network": "10.244.0.0/16","EnableNFTables": false,"Backend": {"Type": "host-gw" #更改内容}}
#重启pod
[root@k8s-master ~]# kubectl -n kube-flannel delete pod --all
pod "kube-flannel-ds-bk8wp" deleted
pod "kube-flannel-ds-mmftf" deleted
pod "kube-flannel-ds-tmfdn" deleted[root@k8s-master ~]# ip r
default via 172.25.254.2 dev eth0 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 172.25.254.10 dev eth0
10.244.2.0/24 via 172.25.254.20 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.25.254.0/24 dev eth0 proto kernel scope link src 172.25.254.100 metric 100
1.3 calico网络插件
calico简介:
- 纯三层的
网络层转发,中间没有任何的NAT和overlay,转发效率最好 - Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景
calico网络架构:
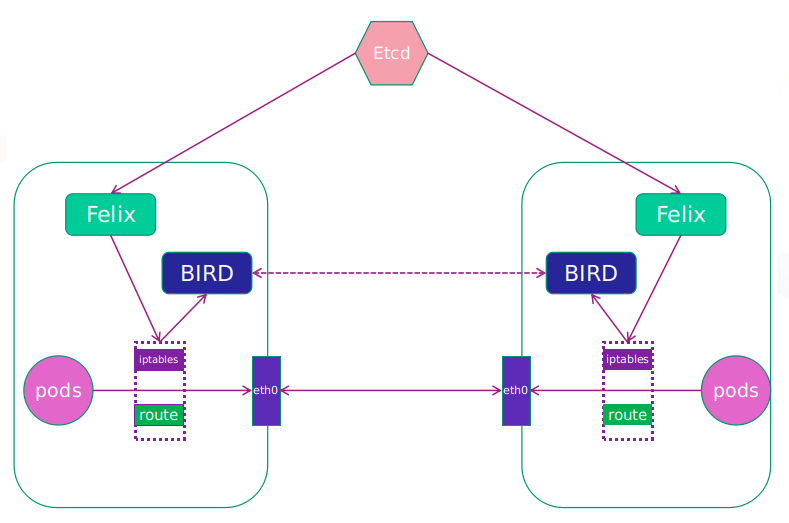
1.3.1 部署calico
删除flannel插件
[root@k8s-master ~]# kubectl delete -f kube-flannel.yml
删除所有节点上flannel配置文件,避免冲突
[root@k8s-master & node1-2 ~]# rm -rf /etc/cni/net.d/10-flannel.conflist
创建文件夹,将所需内容放进去
[root@K8smaster calico]# ls
calico.yaml
[root@Harbor network]# ls
calico-3.28.1.tar calico.yaml#在harbor中上传镜像到仓库中
更改calico.yaml文件
[root@k8s-master calico]# vim calico.yaml
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.14970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0"[root@k8s-master calico]# kubectl apply -f calico.yaml
[root@k8s-master calico]# kubectl -n kube-system get pods
部署完成测试:
[root@K8smaster calico]# kubectl run web --image myapp:v1
pod/web created
[root@K8smaster calico]# kubectl get pods web -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web 1/1 Running 0 24s 192.168.179.64 k8sslave1.zym.org <none> <none>
[root@K8smaster calico]# curl 192.168.179.64
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
(二)k8s调度
2.1 调度在Kubernetes中的作用
- 调度是指将未调度的Pod自动分配到集群中的节点的过程
- 调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
- 调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
2.2 调度原理:
- 创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
- 调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
- 选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
- 绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
- 节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
2.3 调度器种类
- 默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
- 自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
- 扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
- kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
2.4 常用的调度方法
2.4.1 nodenam–指定节点
- nodeName 是节点选择约束的最简单方法,但一般不推荐
- 如果 nodeName 在 PodSpec 中指定了,它会优先于其他的节点选择方法
- 使用 nodeName 来选择节点的一些限制
- 如果指定的节点不存在。
- 如果指定的节点没有资源来容纳 pod,则pod 调度失败。
- 云环境中的节点名称并非总是可预测或稳定的
实例:
#建立pod文件
[[root@k8s-master scheduler]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml#设置调度
[root@k8s-master scheduler]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:nodeName: k8s-node2 #需要指定集群中的节点名称相同containers:- image: myapp:v1name: testpod#建立pod
[root@k8s-master scheduler]# kubectl apply -f pod1.yml
pod/testpod created[root@k8s-master scheduler]# kubectl get pods testpod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 18s 10.244.169.130 k8s-node2 <none> <none>
[! 注意]
找不到节点pod会出现pending状态,优先级最高,其他调度方式无效
可以使用
kubectl get nodes,该命令查看集群中节点名称
2.4.2 Nodeselector—通过标签控制节点
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
kubectl label nodes k8s-node1 lab=zym -
可以给多个节点设定相同标签,当运行pod会指定节点运行
spec:nodeSelector:lab: zym
示例:
#查看节点标签
[root@k8s-master scheduler]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8smaster.zym.org Ready control-plane 8d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8smaster.zym.org,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
k8sslave1.zym.org Ready <none> 8d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8sslave1.zym.org,kubernetes.io/os=linux
k8sslave2.zym.org Ready <none> 8d v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8sslave2.zym.org,kubernetes.io/os=linux#设定节点标签
[root@k8s-master scheduler]# kubectl label nodes k8s-node1 lab=zym
node/k8s-node1 labeled
[root@k8s-master scheduler]# kubectl get nodes k8s-node1 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node1 Ready <none> 5d3h v1.30.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,lab=zym#调度设置
[root@k8s-master scheduler]# vim pod2.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:nodeSelector:lab: zymcontainers:- image: myapp:v1name: testpod[root@k8s-master scheduler]# kubectl apply -f pod2.yml
pod/testpod created
[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 4s 10.244.36.65 k8s-node1 <none> <none>
2.5 affinity(亲和性)
官方文档 :
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node
2.5.1 亲和与反亲和
- nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
- 使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
2.5.2 nodeAffinity节点亲和
- 那个节点服务指定条件就在那个节点运行
requiredDuringSchedulingIgnoredDuringExecution必须满足,但不会影响已经调度的podpreferredDuringSchedulingIgnoredDuringExecution倾向满足,在无法满足情况下也会调度pod- IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
- nodeaffinity还支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
nodeAffinity示例
#示例1
[root@k8s-master scheduler]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:name: node-affinity
spec:containers:- name: nginximage: nginxaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: diskoperator: In | NotIn #两个结果相反values:- ssd2.5.3 Podaffinity(pod的亲和)
- 那个节点有符合条件的POD就在那个节点运行
- podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
- podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
- Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
- Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度
Podaffinity示例
[root@k8s-master scheduler]# vim example4.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-658496fff-d58bk 1/1 Running 0 39s 10.244.169.133 k8s-node2 <none> <none>
nginx-deployment-658496fff-g25nq 1/1 Running 0 39s 10.244.169.134 k8s-node2 <none> <none>
nginx-deployment-658496fff-vnlxz 1/1 Running 0 39s 10.244.169.135 k8s-node2 <none> <none>
2.5.4 Podantiaffinity(pod反亲和)
Podantiaffinity示例
[root@k8s-master scheduler]# vim example5.yml
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginxaffinity:podAntiAffinity: #反亲和requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- nginxtopologyKey: "kubernetes.io/hostname"[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-5f5fc7b8b9-hs9kz 1/1 Running 0 6s 10.244.169.136 k8s-node2 <none> <none>
nginx-deployment-5f5fc7b8b9-ktzsh 0/1 Pending 0 6s <none> <none> <none> <none>
nginx-deployment-5f5fc7b8b9-txdt9 1/1 Running 0 6s 10.244.36.67 k8s-node1 <none> <none>2.6 Taints—污点模式
- 禁止调度到该标记污点的节点上
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法
$ kubectl taint nodes node1 key=value:NoSchedule #创建
$ kubectl describe nodes server1 | grep Taints #查询
$ kubectl taint nodes node1 key- #删除
其中 effect 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点,就像贴了个 “禁止入内”,已经在这节点运行的也会继续运行 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点,如果实在没别的节点可用,也可以放在该节点进行运行 |
| NoExecute | 如该节点标为污点模式,不能调度上该节点上,并且节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被节点去掉 |
2.6.1 设定污点
#创建运行pod
[root@K8smaster calico]# vim example.yml
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec:replicas: 2selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginx:1.23name: nginx
设定污点标签
[root@K8smaster calico]# kubectl taint node k8sslave1.zym.org name=zym:NoSchedule
此时设定污点标签后,正在运行的节点还是会在该节点上运行

新添加的节点就不会,在标记污点的节点上运行
[root@K8smaster calico]# kubectl scale deployment web --replicas 6
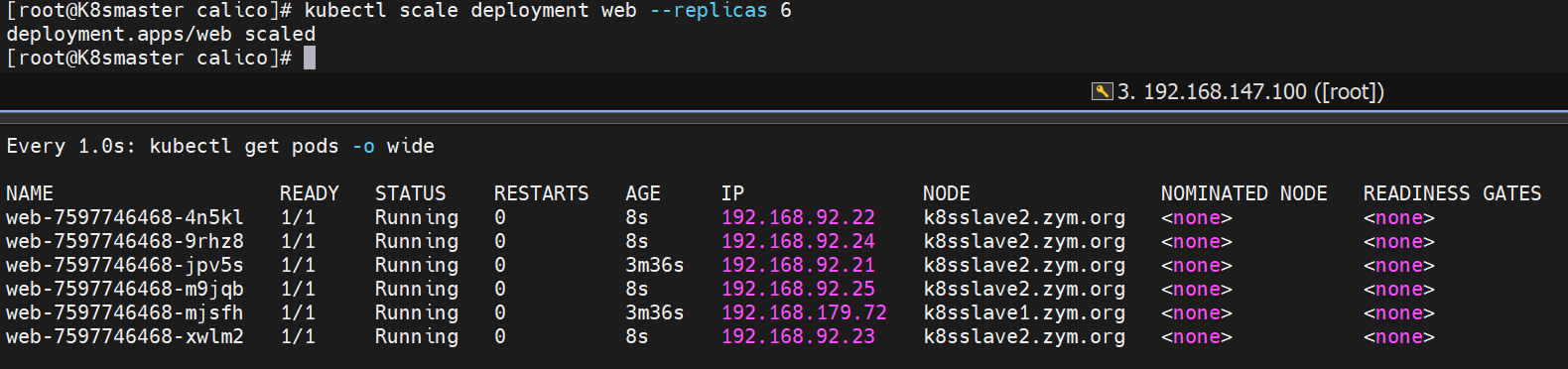
2.6.2 污点删除
[root@K8smaster calico]# kubectl taint node k8sslave1.zym.org name-[root@K8smaster calico]# kubectl describe nodes k8sslave1.zym.org k8sslave2.zym.org | grep Tain
Taints: <none>
Taints: <none>
2.6.3 污点容忍
$ kubectl taint nodes <nodename> key=value:effect
$ kubectl taint node k8sslave1.zym.org name=zym:NoSchedule
key 和 value 可以自定义
-
tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
- 如果 operator 是 Equal ,则key与value之间的关系必须相同
- 如果 operator 是 Exists ,value可以省略
- 如果不指定operator属性,则默认值为Equal
-
还有两个特殊值:
-
当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点
-
当不指定effect ,则匹配所有的effecttolerations中定义的key、value、effect,要与node上设置的taint保持一直
-
如果 operator 是 Equal ,则key与value之间的关系必须相等。如果 operator 是 Exists ,value可以省略如果不指定operator属性,则默认值为Equal。还有两个特殊值:当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。当不指定effect ,则匹配所有的effect
-
容忍实例:
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: webname: web
spec:replicas: 2selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: nginx:1.23name: nginxtolerations: #容忍所有污点- operator: Exists
容忍effect为Noschedule的污点
tolerations: #容忍effect为Noschedule的污点
- operator: Existseffect: NoSchedule
容忍指定key的NoSchedule污点
$ kubectl taint node k8s-node2 nodetype=bad:NoScheduletolerations: #容忍指定key和value的NoSchedule污点
- key: nodetypevalue: badeffect: NoSchedule
八、k8s中的认证授权
(一)kubernetes API 访问控制
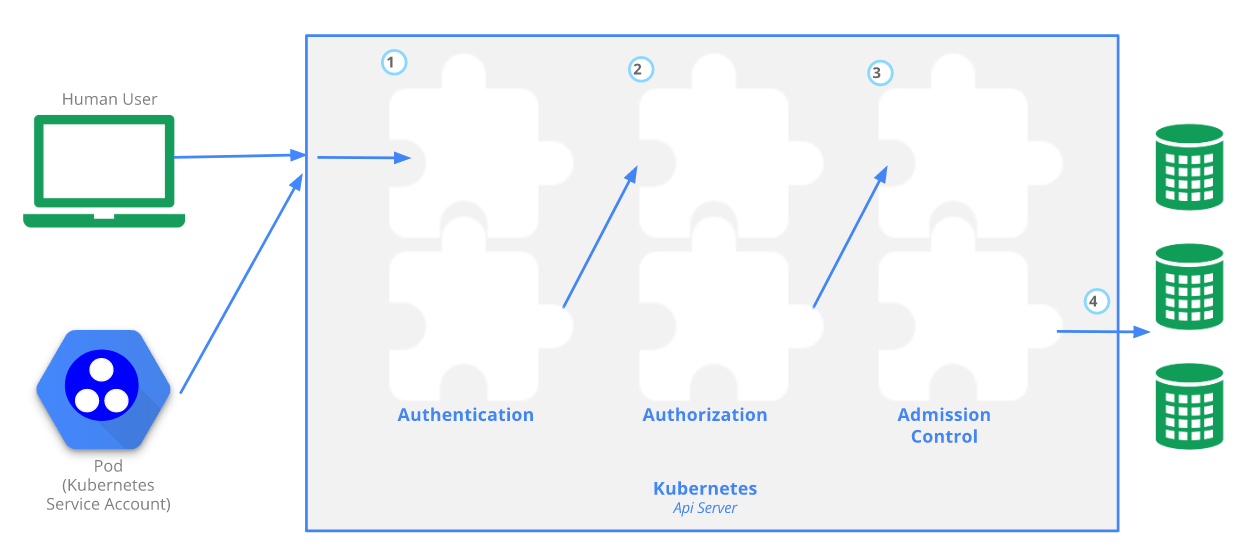
Authentication(认证)
-
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
-
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
Authorization(授权)
- 必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求。授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node。默认集群强制开启RBAC。
Admission Control(准入控制)
- 用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验。
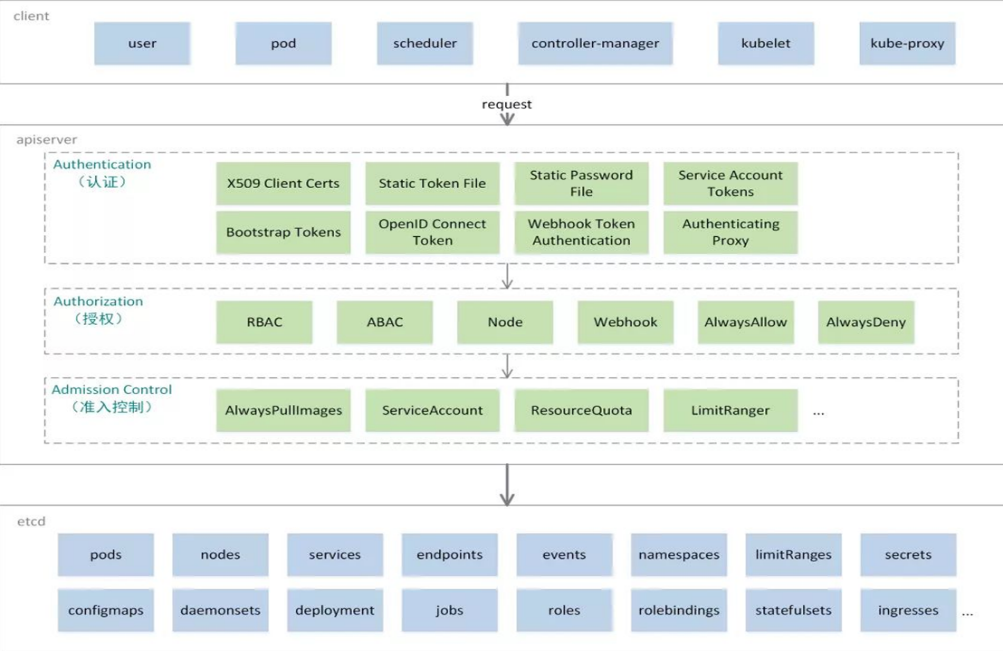
1.1 UserAccount与ServiceAccount
-
用户账户是针对人而言的。 服务账户是针对运行在 pod 中的进程而言的。
-
用户账户是全局性的。 其名称在集群各 namespace 中都是全局唯一的,未来的用户资源不会做 namespace 隔离, 服务账户是 namespace 隔离的。
-
集群的用户账户可能会从企业数据库进行同步,其创建需要特殊权限,并且涉及到复杂的业务流程。 服务账户创建的目的是为了更轻量,允许集群用户为了具体的任务创建服务账户 ( 即权限最小化原则 )。
1.1.1 ServiceAccount
-
服务账户控制器(Service account controller)
-
服务账户管理器管理各命名空间下的服务账户
-
每个活跃的命名空间下存在一个名为 “default” 的服务账户
-
-
服务账户准入控制器(Service account admission controller)
-
相似pod中 ServiceAccount默认设为 default。
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
-
如果pod不包含ImagePullSecrets设置那么ServiceAccount中的ImagePullSecrets 被添加到pod中
-
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中
-
1.1.2 ServiceAccount示例:
建立名字为zym的ServiceAccoun
kubectl create sa zym
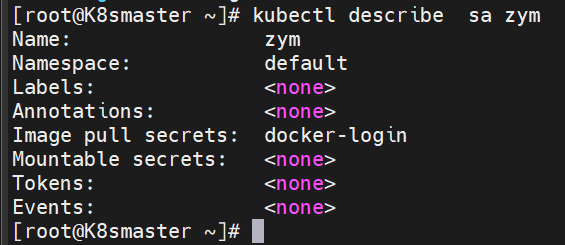
建立secrets
kubectl create secret docker-registry docker-login --docker-username admin --docker-password 123456 --docker-server reg.zym.org --docker-email zym@qq.org
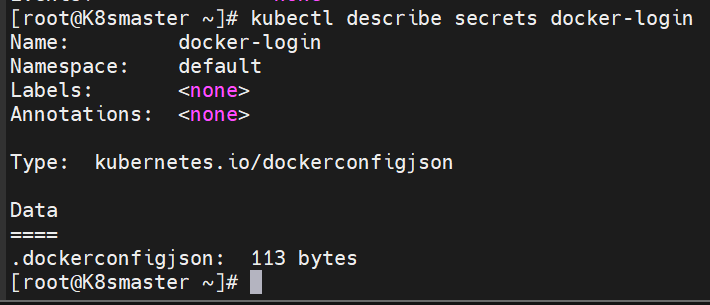
secrets注入到sa中
[root@k8s-master ~]# kubectl edit sa timinglee
apiVersion: v1
imagePullSecrets:
- name: docker-login
kind: ServiceAccount
metadata:creationTimestamp: "2025-08-19T07:49:26Z"name: zymnamespace: defaultresourceVersion: "355930"uid: 2601532b-7de8-4af2-a1fd-a9483bd59e5d
建立私有仓库并且利用pod访问私有仓库
[root@k8s-master auth]# vim example1.yml
[root@K8smaster calico]# kubectl run testpod --image reg.zym.org/zym/game2048 --dry-run=client -o yaml
apiVersion: v1
kind: Pod
metadata:creationTimestamp: nulllabels:run: testpodname: testpod
spec:containers:- image: reg.zym.org/zym/game2048name: testpodresources: {}dnsPolicy: ClusterFirstrestartPolicy: Always
status: {}
[root@K8smaster calico]# kubectl run testpod --image reg.zym.org/zym/game2048 --dry-run=client -o yaml > example1.yml[root@k8s-master auth]# kubectl apply -f example1.yml
pod/testpod created
[root@k8s-master auth]# kubectl describe pod testpodWarning Failed 5s kubelet Failed to pull image "reg.timinglee.org/lee/nginx:latest": Error response from daemon: unauthorized: unauthorized to access repository: lee/nginx, action: pull: unauthorized to access repository: lee/nginx, action: pullWarning Failed 5s kubelet Error: ErrImagePullNormal BackOff 3s (x2 over 4s) kubelet Back-off pulling image "reg.timinglee.org/lee/nginx:latest"Warning Failed 3s (x2 over 4s) kubelet Error: ImagePullBackOff
在创建pod时会镜像下载会受阻,因为docker私有仓库下载镜像需要认证
pod绑定sa
[root@k8s-master auth]# vim example1.yml
apiVersion: v1
kind: Pod
metadata:labels:run: testpodname: testpod
spec:serviceAccountName: zymcontainers:- image: reg.zym.org/zym/game2048:latestname: testpod
现在可以正常拉取镜像了
[root@k8s-master auth]# kubectl apply -f example1.yml
pod/testpod created
[root@k8s-master auth]# kubectl get pods
NAME READY STATUS RESTARTS AGE
testpod 1/1 Running 0 2s
二 认证(在k8s中建立认证用户)
2.1 创建UserAccount
建立证书
[root@K8smaster calico]# cd /etc/kubernetes/pki/
[root@K8smaster pki]# openssl genrsa -out zym.key 2048
[root@K8smaster pki]# openssl req -new -key zym.key -out zym.csr -subj "/CN=zym"
[root@K8smaster pki]# openssl x509 -req -in zym.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out zym.crt -days 365
Certificate request self-signature ok
subject=CN = zym
[root@K8smaster pki]# openssl x509 -in zym.crt -text -noout
Certificate:Data:Version: 1 (0x0)Serial Number:66:14:f2:95:f5:ab:f3:e4:da:d1:53:ae:5d:6f:14:bc:c7:7f:72:6aSignature Algorithm: sha256WithRSAEncryptionIssuer: CN = kubernetesValidityNot Before: Aug 19 08:22:34 2025 GMTNot After : Aug 19 08:22:34 2026 GMTSubject: CN = zymSubject Public Key Info:Public Key Algorithm: rsaEncryptionPublic-Key: (2048 bit)Modulus:00:9c:38:50:1e:53:2f:59:f5:7d:9f:06:c6:10:4c:2b:58:a3:aa:84:65:d4:7b:28:9c:17:e0:1c:e2:40:9e:ad:55:51:57:18:f5:53:25:b3:1c:2b:a9:85:fe:55:b1:d6:95:dc:85:97:0b:40:eb:a3:c4:51:2a:bf:ed:29:4f:89:81:81:37:70:04:25:bf:0f:97:ce:f3:23:61:1a:09:44:23:19:f4:bf:8d:d3:45:79:41:05:ed:a5:0e:29:29:59:db:94:56:e2:5a:f9:ad:88:29:da:36:73:78:67:98:12:9d:44:4c:33:f6:b6:da:d9:3d:e1:e9:f1:0a:3f:e9:6b:07:ae:06:dd:b6:12:8b:1f:af:c8:68:8b:c1:b6:41:42:95:9c:57:98:10:39:80:20:1a:63:01:54:72:64:b6:c8:13:bf:fa:e2:4a:b8:1e:4d:7d:3c:ca:ae:63:2c:b7:68:5c:74:c2:dd:07:7c:ae:9a:46:8d:b4:1f:79:a8:82:7a:e5:19:9f:ca:58:fd:1d:a6:40:da:03:d0:86:d9:8b:58:eb:7f:d5:b2:69:f1:b6:c4:d3:1f:bb:69:08:ff:15:81:08:69:57:f0:fb:f6:10:05:41:0b:d1:4c:2e:c4:95:11:da:2f:7f:40:58:a7:0c:17:e9:d9:46:52:d8:5b:dc:23:b1Exponent: 65537 (0x10001)Signature Algorithm: sha256WithRSAEncryptionSignature Value:ad:77:d8:17:fe:8e:f6:dd:79:7a:23:74:8f:62:22:af:9d:0c:39:e1:95:dc:81:da:e8:50:3a:c8:d3:aa:59:ae:30:11:be:d0:8d:3c:5c:d6:5d:44:d4:ef:ca:f4:99:9a:22:54:5b:04:bd:a8:ea:2f:cc:b8:c1:61:96:70:eb:c1:a5:b7:ac:a0:52:86:49:dd:94:b3:35:1f:4e:37:5b:0a:3f:04:36:39:6a:7a:32:49:23:75:7a:08:6e:c3:db:18:fb:11:91:c4:36:7f:bc:e5:b8:0c:2f:00:75:fe:66:69:9b:3b:6f:16:e7:bf:bf:fa:ed:54:13:79:8e:f8:68:8a:fa:87:53:b2:5a:a5:cb:63:93:09:22:64:6c:00:1d:25:e2:8a:d7:1a:4a:5b:f0:4e:51:ce:d3:51:d8:98:b6:92:6e:cb:b5:5b:25:f8:f2:e7:5f:b8:db:b4:89:01:7e:2f:27:d6:77:ff:15:7d:45:15:46:1f:7e:06:3e:3f:2d:e0:c9:31:87:43:20:ca:3d:35:5c:de:6f:75:22:ab:83:8c:9c:35:d3:2d:b2:fd:14:33:ce:10:37:35:1d:36:96:2f:bd:a4:07:3f:ad:82:df:6a:d1:aa:13:af:63:54:85:be:7a:6d:a5:a9:07:7e:d6:99:cb:6a:4e:a4:0f:95:46:a2
建立k8s中的用户
[root@K8smaster pki]# kubectl config set-credentials zym --client-certificate /etc/kubernetes/pki/zym.crt --client-key /etc/kubernetes/pki/zym.key --embed-certs=true
User "zym" set.
[root@k8s-master pki]# kubectl config view
apiVersion: v1
clusters:
- cluster:certificate-authority-data: DATA+OMITTEDserver: https://172.25.254.100:6443name: kubernetes
contexts:
- context:cluster: kubernetesuser: kubernetes-adminname: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-adminuser:client-certificate-data: DATA+OMITTEDclient-key-data: DATA+OMITTED
- name: timingleeuser:client-certificate-data: DATA+OMITTEDclient-key-data: DATA+OMITTED#为用户创建集群的安全上下文
root@k8s-master pki]# kubectl config set-context timinglee@kubernetes --cluster kubernetes --user timinglee
Context "timinglee@kubernetes" created.#切换用户,用户在集群中只有用户身份没有授权
[root@k8s-master ~]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".
[root@k8s-master ~]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "timinglee" cannot list resource "pods" in API group "" in the namespace "default"#切换会集群管理
[root@k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".#如果需要删除用户
[root@k8s-master pki]# kubectl config delete-user timinglee
deleted user timinglee from /etc/kubernetes/admin.conf
2.2 RBAC(Role Based Access Control)
2.2.1 基于角色访问控制授权:
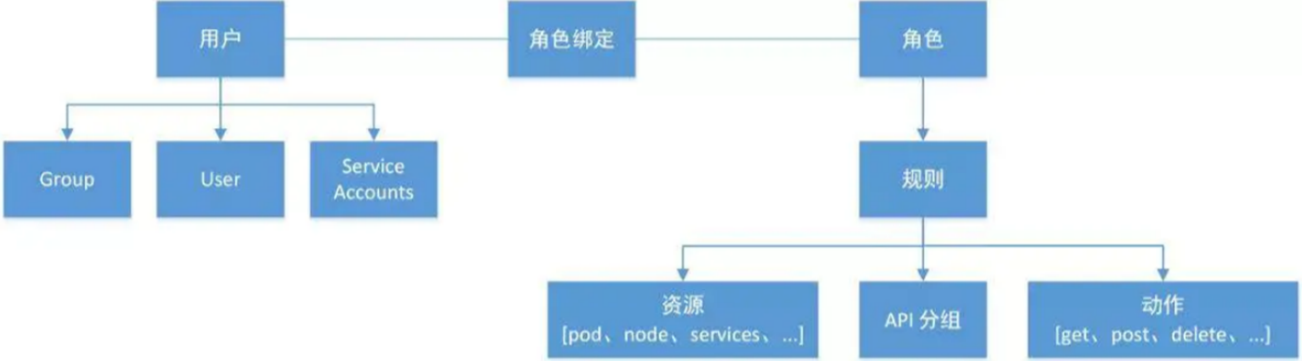
-
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
-
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
-
RBAC的三个基本概念
-
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
-
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
-
RoleBinding:定义了“被作用者”和“角色”的绑定关系
-
-
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
-
Role 和 ClusterRole
-
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
-
ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
-
Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
-
cluster-amdin、admin、edit、view
-
2.2.2 role授权实施
#生成role的yaml文件
[root@k8s-master rbac]# kubectl create role myrole --dry-run=client --verb=get --resource pods -o yaml > myrole.yml#更改文件内容
[root@k8s-master rbac]# vim myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:creationTimestamp: nullname: myrole
rules:
- apiGroups:- ""resources:- podsverbs:- get- watch- list- create- update- path- delete#创建role
[root@k8s-master rbac]# kubectl apply -f myrole.yml
[root@k8s-master rbac]# kubectl describe role myrole
Name: myrole
Labels: <none>
Annotations: <none>
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----pods [] [] [get watch list create update path delete]
#建立角色绑定
[root@k8s-master rbac]# kubectl create rolebinding timinglee --role myrole --namespace default --user timinglee --dry-run=client -o yaml > rolebinding-myrole.yml[root@k8s-master rbac]# vim rolebinding-myrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:name: timingleenamespace: default #角色绑定必须指定namespace
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: myrole
subjects:
- apiGroup: rbac.authorization.k8s.iokind: Username: timinglee[root@k8s-master rbac]# kubectl apply -f rolebinding-myrole.yml
rolebinding.rbac.authorization.k8s.io/timinglee created
[root@k8s-master rbac]# kubectl get rolebindings.rbac.authorization.k8s.io timinglee
NAME ROLE AGE
timinglee Role/myrole 9s
#切换用户测试授权
[root@k8s-master rbac]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".[root@k8s-master rbac]# kubectl get pods
No resources found in default namespace.
[root@k8s-master rbac]# kubectl get svc #只针对pod进行了授权,所以svc依然不能操作
Error from server (Forbidden): services is forbidden: User "timinglee" cannot list resource "services" in API group "" in the namespace "default"#切换回管理员
[root@k8s-master rbac]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
2.2.3 clusterrole授权实施
#建立集群角色
[root@k8s-master rbac]# kubectl create clusterrole myclusterrole --resource=deployment --verb get --dry-run=client -o yaml > myclusterrole.yml
[root@k8s-master rbac]# vim myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: myclusterrole
rules:
- apiGroups:- appsresources:- deploymentsverbs:- get- list- watch- create- update- path- delete
- apiGroups:- ""resources:- podsverbs:- get- list- watch- create- update- path- delete[root@k8s-master rbac]# kubectl describe clusterrole myclusterrole
Name: myclusterrole
Labels: <none>
Annotations: <none>
PolicyRule:Resources Non-Resource URLs Resource Names Verbs--------- ----------------- -------------- -----deployments.apps [] [] [get list watch create update path delete]pods.apps [] [] [get list watch create update path delete]#建立集群角色绑定
[root@k8s-master rbac]# kubectl create clusterrolebinding clusterrolebind-myclusterrole --clusterrole myclusterrole --user timinglee --dry-run=client -o yaml > clusterrolebind-myclusterrole.yml
[root@k8s-master rbac]# vim clusterrolebind-myclusterrole.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: clusterrolebind-myclusterrole
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: myclusterrole
subjects:
- apiGroup: rbac.authorization.k8s.iokind: Username: timinglee[root@k8s-master rbac]# kubectl describe clusterrolebindings.rbac.authorization.k8s.io clusterrolebind-myclusterrole
Name: clusterrolebind-myclusterrole
Labels: <none>
Annotations: <none>
Role:Kind: ClusterRoleName: myclusterrole
Subjects:Kind Name Namespace---- ---- ---------User timinglee#测试:
[root@k8s-master rbac]# kubectl get pods -A
[root@k8s-master rbac]# kubectl get deployments.apps -A
[root@k8s-master rbac]# kubectl get svc -A
Error from server (Forbidden): services is forbidden: User "timinglee" cannot list resource "services" in API group "" at the cluster scope
2.2.4 服务账户的自动化
服务账户准入控制器(Service account admission controller)
-
如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default。
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
-
如果 pod 不包含 ImagePullSecrets 设置,那么 将 ServiceAccount 中的 ImagePullSecrets 信息添加到 pod 中。
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中。
-
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中。
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为 “default” 的服务账户


)


)












)
)