MySQL
1. 数据库与缓存的一致性
引入缓存,因为缓存只是数据库数据的副本,那么就可能存在副本和原数据不一致的情况
一致性
ACID里面的C,和CAP中的C不是一个概念,虽然都叫一致性。CAP中的C,指的是多个副本之间逻辑上要相等。ACID里面的C,指的是多个数据在逻辑上的约束关系,比如转账时A账户减少了100,对应B账户一定要加上100
不建议使用缓存的场景
查询频率低的数据:就算有LRU算法,面对访问频率低但是占用空间大的数据,空间的利用率也不高
更新频率高的数据:缓存命中率低
数据一致性要求极高的数据:也不建议使用缓存
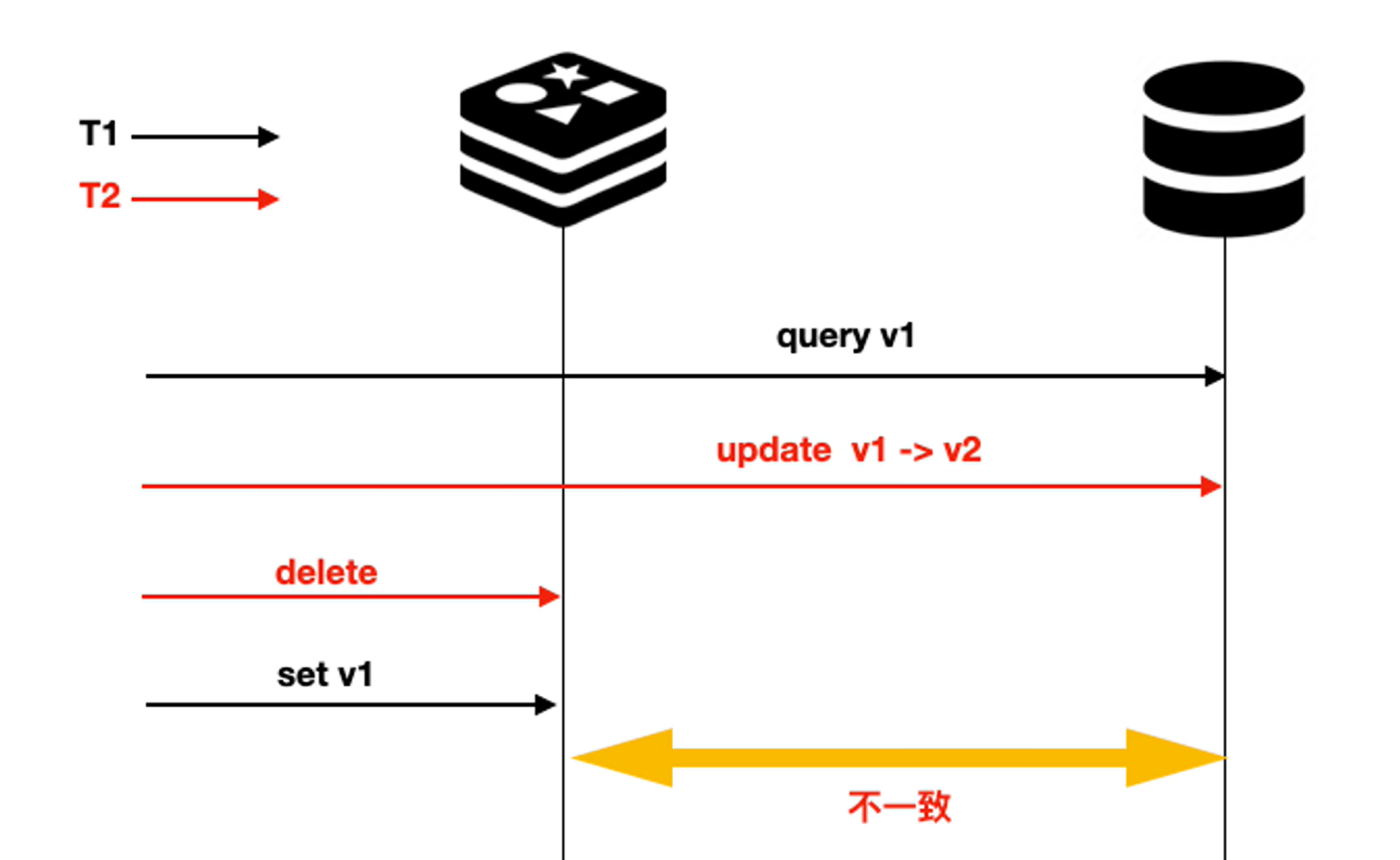
引起不一致的场景分析
删除数据
情况一:缓存中当前没有数据。此时缓存中没有副本,当然没有一致性的问题
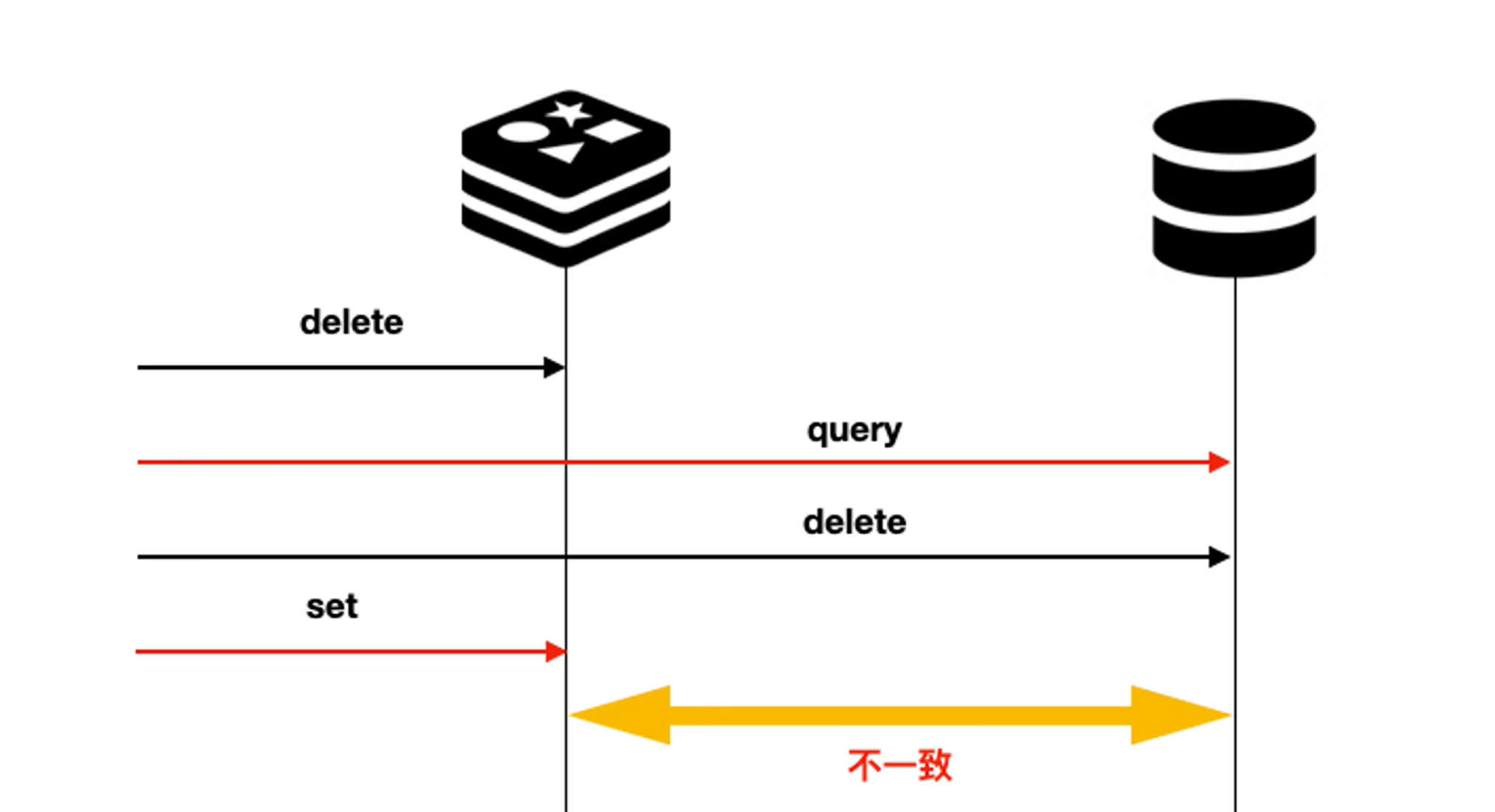
情况二:缓存中有当前数据。
此时如果先删缓存、再删数据库。
先删数据库、再删缓存
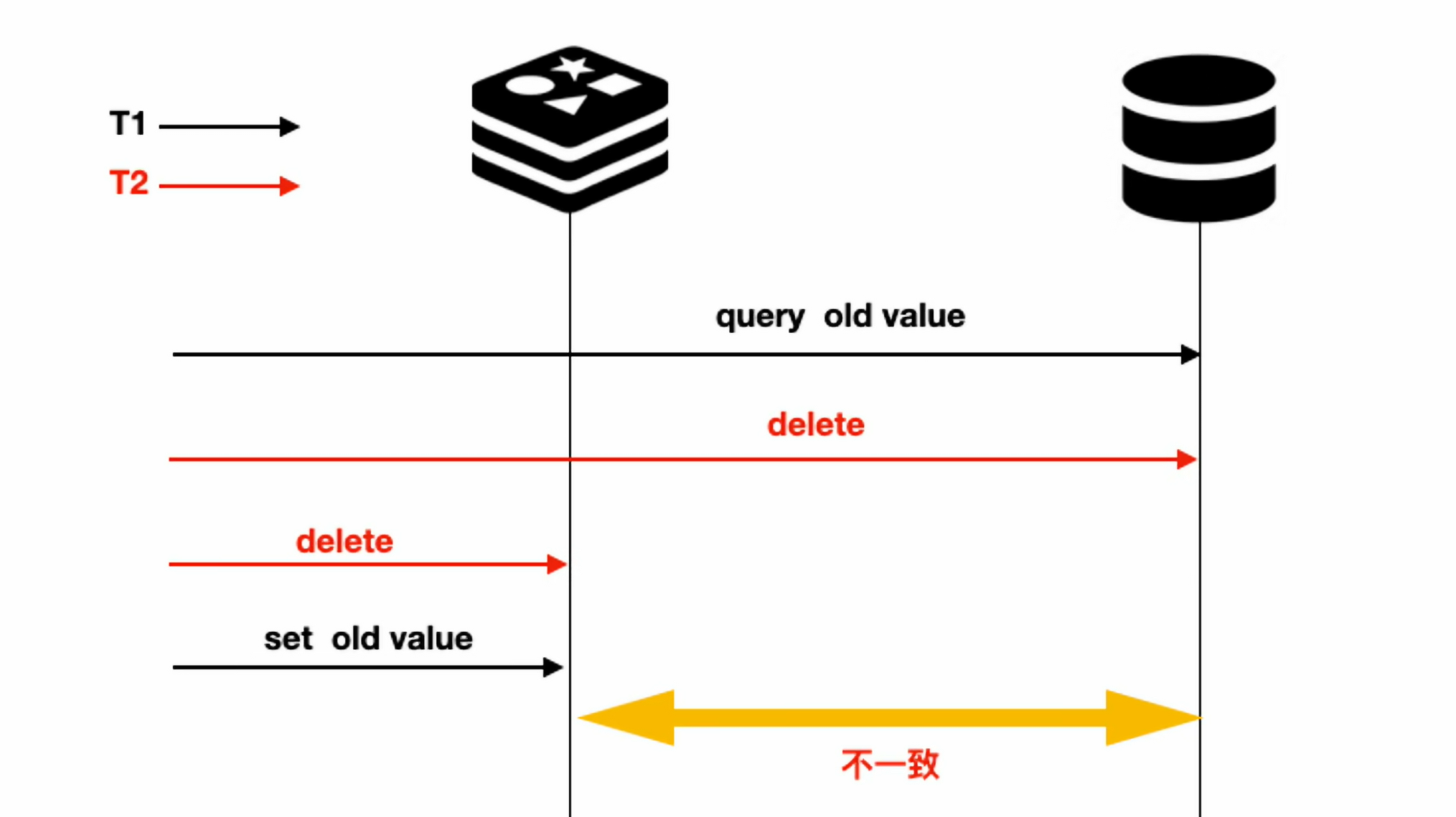
可以看到,以上两种场景都会导致缓存中有老数据,而数据库中最终没有数据。这是因为出现这种并发问题,我们没有办法控制这种时序问题,所以,这就是一个概率性问题
更新数据
先更新数据库、再更新缓存
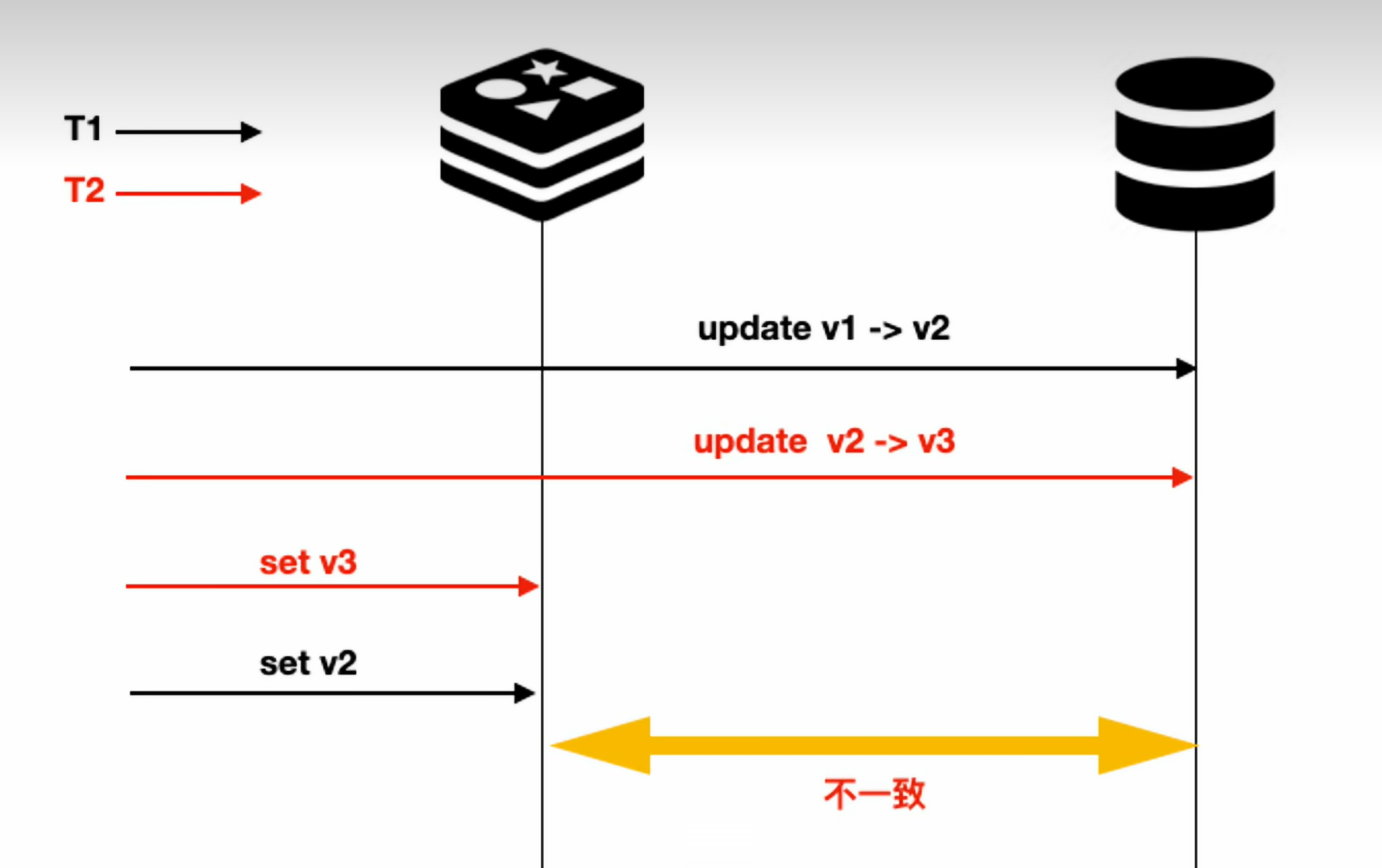
以上也是时序执行不同导致的一个概率性问题
目前主流一致性解决策略cache aside
- 读数据时,先读缓存,如果有就返回。没有再读数据源,将数据放到缓存
- 写数据时,先写数据源,然后删除缓存
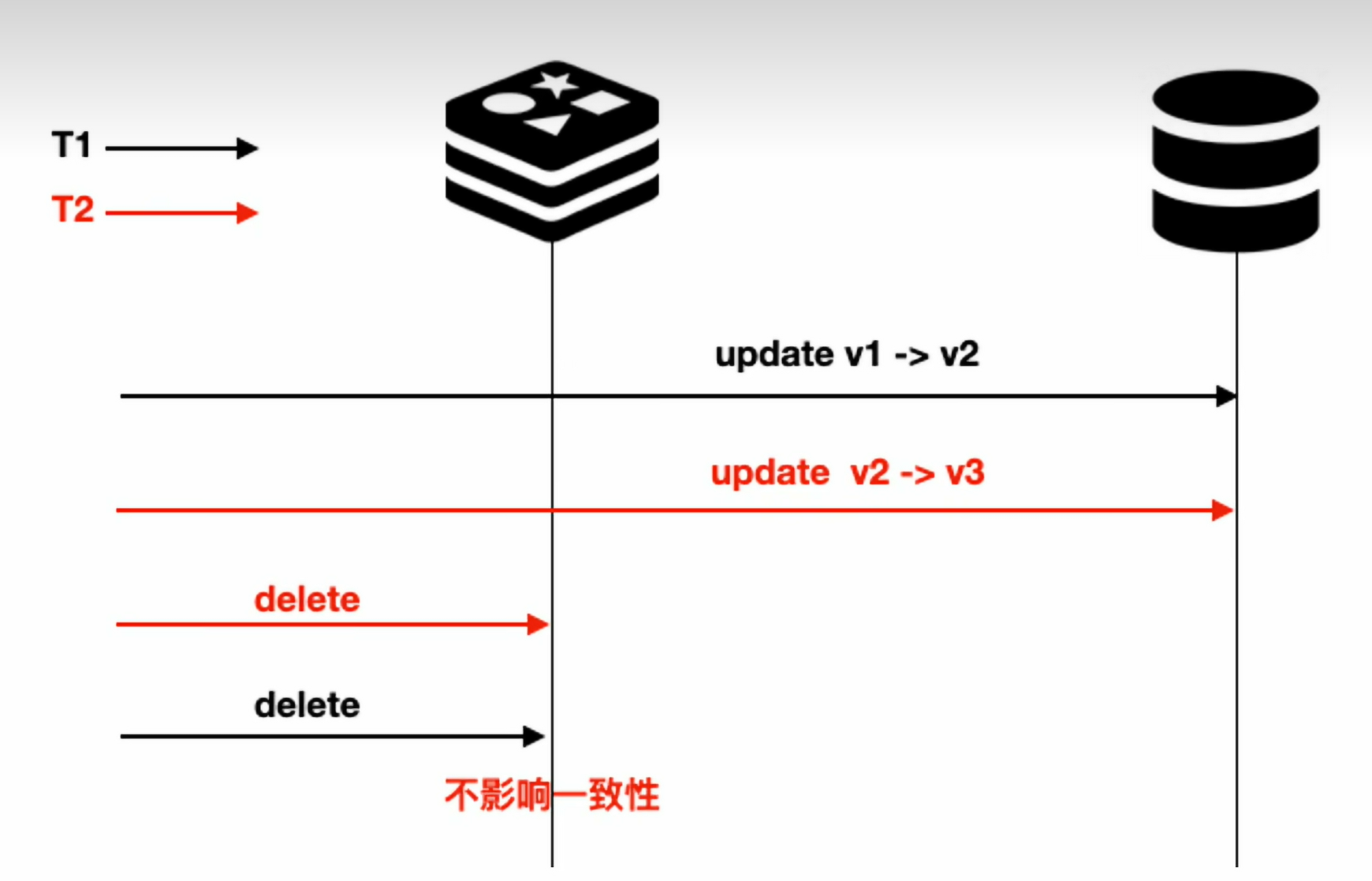
都是会把缓存中的数据删掉,后续查询查不到缓存就从数据库中取最新的数据
弊端:
Cache Aside 不能保证一致性上绝对不出问题
Cache Aside 并不能保证强一致性,不然也就不会有 Paxos 这种复杂的共识算法了
- 考虑redis做缓存时,必然就必须容忍一定的数据不一致的可能
- 考虑让redid做数据库我没用过
缓存的兜底策略
- 因为Cache Aside 并不能保证强一致性,因为很难保证操作数据库和操作缓存的操作的原子性,除非加分布式锁。
- 所以,总有极少数不一致的场景,所以最后都要加一个超时时间,避免长时间的缓存数据与数据库中不一致
异步化解决缓存一致性
canal监听binlog,然后发MQ,然后监听MQ来刷新缓存。
异步化解决方案的优势,将一致性解决方案,与业务代码进行解耦。第二个是同步操作缓存的性能肯定没有异步化高
异步化的缺点是,需要单独维护一套canal和MQ的中间件,如果中间件挂了,会产生影响
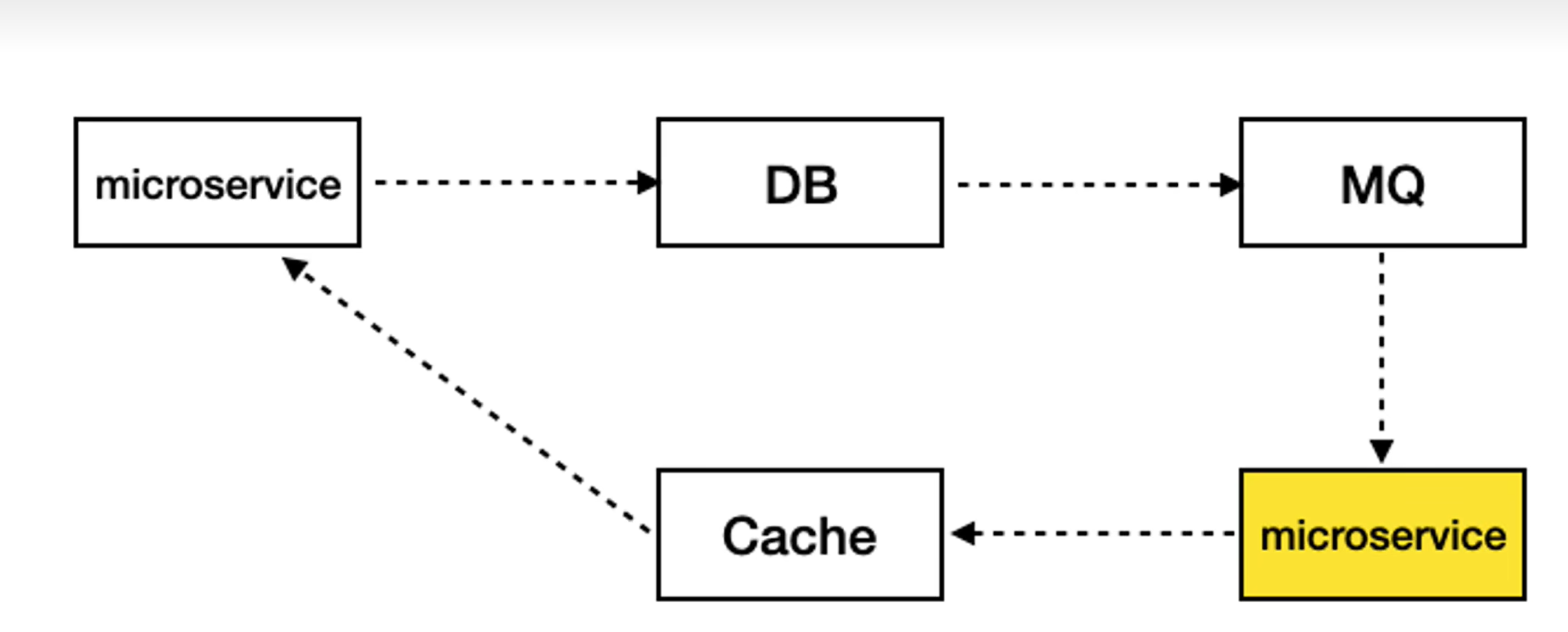
业务操作数据库的模块,和监听MQ去刷新缓存的模块,是否应该放在同一个微服务中?
有的公司是采取的把监听模块独立出来,但是也有公司将监听MQ去刷新缓存的模块仍放在原来的业务操作数据库的模块中,是没有拆分的
我倾向于每个微服务自己管理自己的存储细节,不要暴露给外部,所以监听MQ获取MQ中的数据库记录的各个字段,从而更新到缓存中去的功能,我是更倾向于放在原有业务模块中,不暴露出去
参考视频:大厂一致性方案补充,优缺点分析,微服务设计权衡思考_哔哩哔哩_bilibili
2. 缓存穿透、雪崩
参考视频:经典面试题,大厂几个巧妙的方案,复杂高并发系统缓存设计_哔哩哔哩_bilibili
3. 连接池配置
数据库连接池到底该设置多大才合适?_哔哩哔哩_bilibili
1,连接池太小最开始只有10个连接,慢SQL长达几秒,长期占用连接
2,通过压测发现连接池一般设置为50比较合适
3,学习hikariCP的各种使用特性
HikariCP连接池详细配置优化方案-java教程-PHP中文网
4. MySQL三大日志
面试官内心os:MySQL三大日志还得是你讲的好_哔哩哔哩_bilibili
通过Mysql的日志设计我们学到:要保证持久化就得记日志,对于连续写的日志最好搞一个Cache,先写cache然后异步刷盘。通过日志就能做备份恢复,主从同步
redis的rdb和aof也是这个逻辑
binlog和redolog如何保证数据的一致性
redo log和binlog如何保证一致性:将redo log的写拆成两个步骤,prepare 和commit也就是两阶段提交
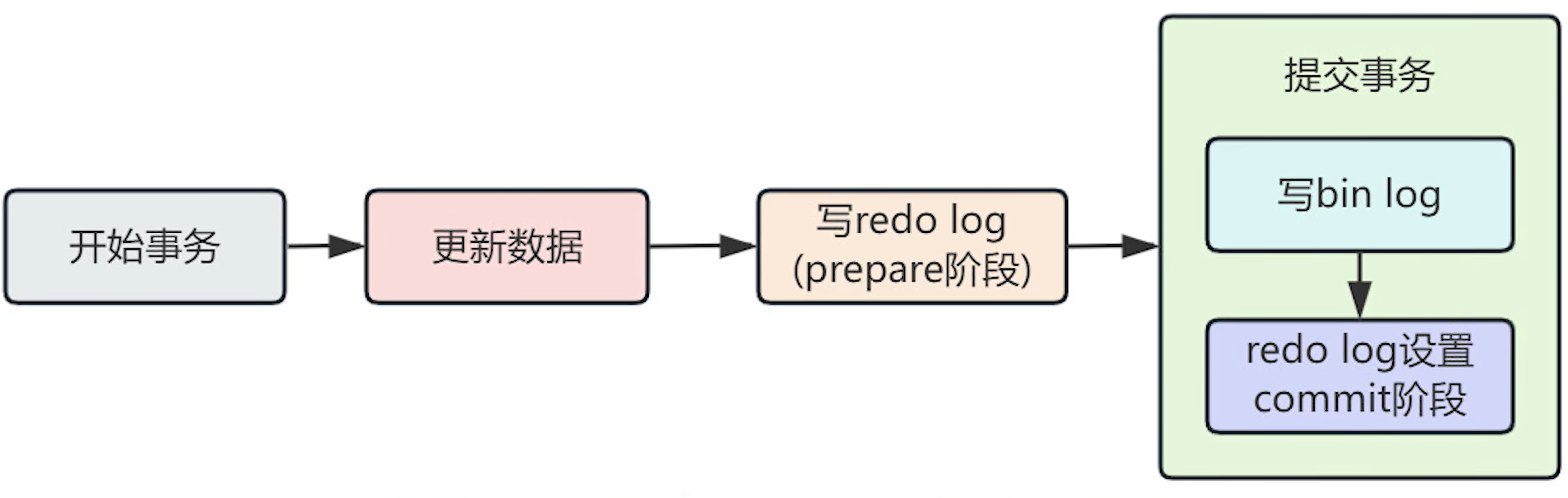
两阶段提交的成功关键,还是要看bin log,只要bin log刷盘了,那就能提交事务
MVCC有了解嘛
(YY直播一面)
5. MySQL分页
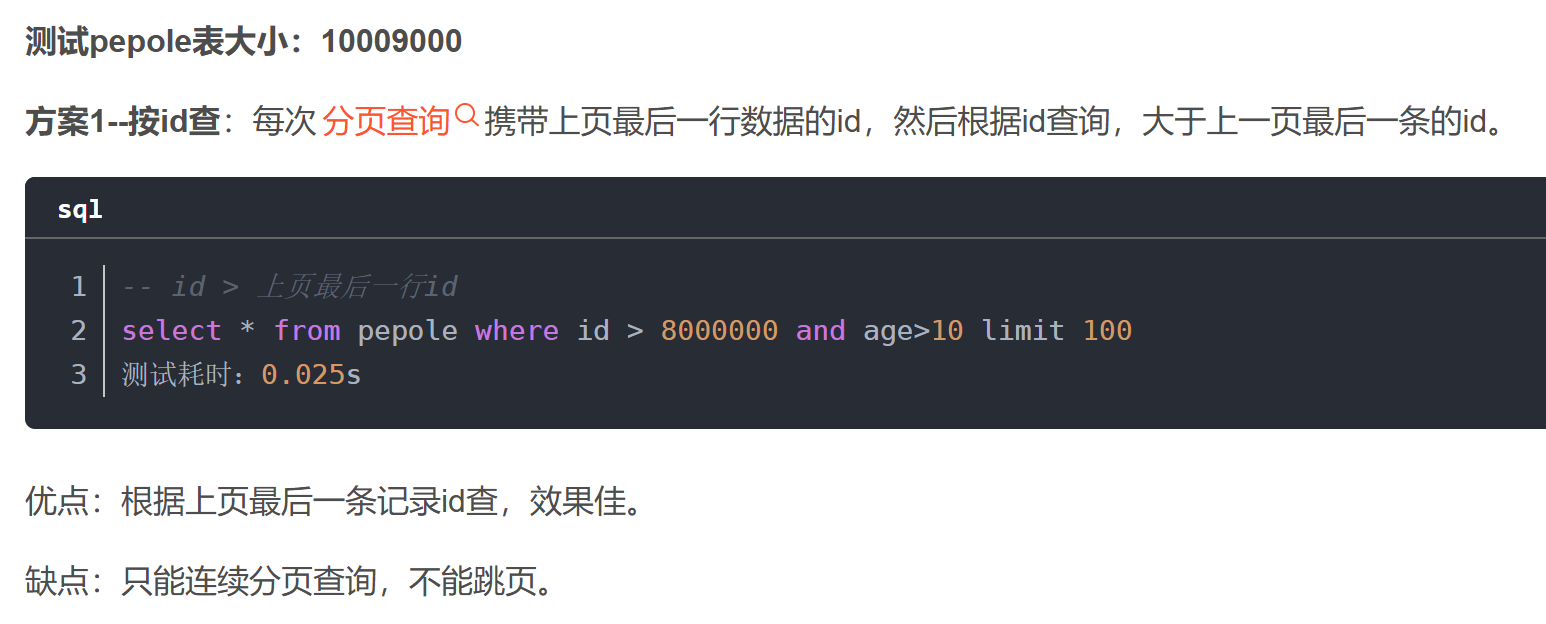
select * from people
where id > 8000000 and age > 10
order by id
limit 100
参考视频:毕业第一次发布就有高并发经验了!有惊无险!_哔哩哔哩_bilibili
6. 慢查询
隐式转换造成索引失效
关注mybatis会自动进行java Date类型到数据库Timestamp类型的转换,但是数据的create_time字段是Date类型
隐式类型转换发生在索引字段时,会导致索引失效,索引失效也就导致慢查询
参考链接:一次慢查询暴露的隐蔽的问题
7. MySQL与ES同步
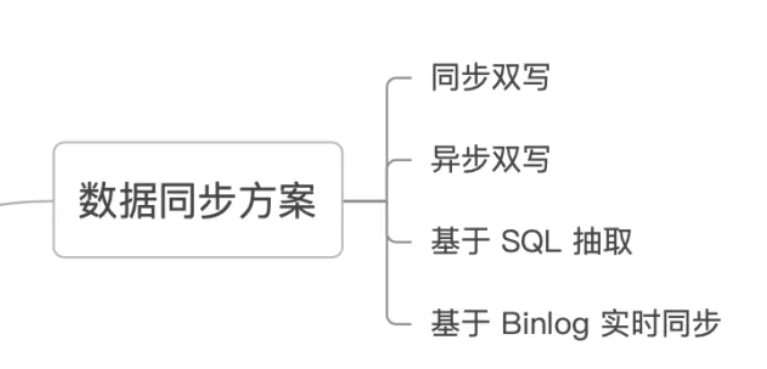
参考链接:4 种 MySQL 同步 ES 方案,yyds!
主流还是canal
8. 索引
索引覆盖和索引下推是什么?
锁住余额,为何还会更新异常?
MVCC多版本控制
1)多版本控制: 指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。
2)文中还有一个关于多版本并发控制的例子,可以记一下











` 数据库查询函数)
![[系统架构设计师]通信系统架构设计理论与实践(十七)](http://pic.xiahunao.cn/[系统架构设计师]通信系统架构设计理论与实践(十七))

)


)
)
