一、对Redis的理解
Reids是一种基于内存的数据库,对数据的读写操作都在内存中完成,因此读写速度非常快,常用于缓存、消息队列、分布式锁等场景。除此之外,Redis还支持事务、持久化、Lua脚本、多种集群方案(主从复制模式、哨兵模式、切片机群模式)、发布/订阅模式、内存淘汰机制、过期删除机制等等。
二、五大基本数据类型
1、String(字符串)
String类型的底层数据结构实现主要是SDS(简单的动态字符串)。
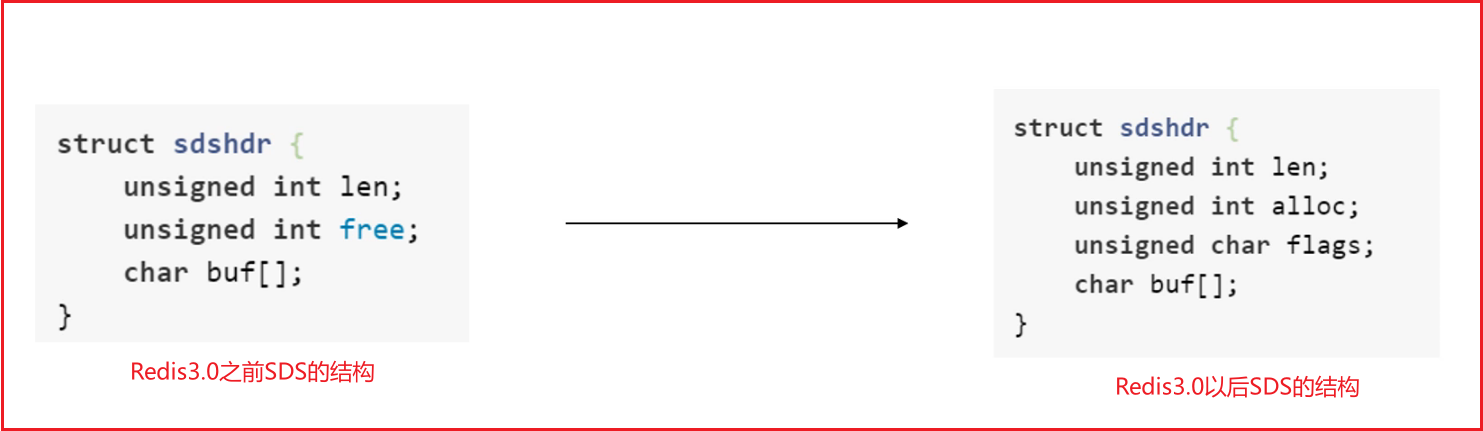
- SDS 不仅可以保存文本数据,还可以保存二进制数据。SDS的所有API都会以处理二进制的方式来处理SDS存放在buf[]数组中的数据。所以 SDS不仅可以保存文本数据,还可以保存图片、音频、视频等这些二进制数据。
- SDS 获取字符串长度的实践复杂度为O(1)。因为SDS不是采用C语言的“\0”来判断字符串是否结束,而是采用len属性的值,所以时间复杂度为O(1);
- Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。因为 SDS 在拼接之前对 SDS 的空间进行检查,不满足会进行扩容。
2、List(列表)
List类型的底层数据结构是由双向链表或压缩指针实现:
- 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),Redis 会使用压缩列表作为 List 类型的底层数据结构;
- 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
- 但是在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。
3、Hash(散列)
Hash 类型的底层数据结构是由压缩列表或哈希表实现的

- 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;
- 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的底层数据结构。在
- Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
4、Set(集合)
Set 类型的底层数据结构是由整数集或哈希表合实现的:

- 如果集合中的元素都是整数且元素个数小于 512(默认值,set-maxintset-entries 配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
5、sorted_set(有序集合)
Set 类型的底层数据结构是由压缩列表或跳表合实现的:

- 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
- 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
- 在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
三、持久化
RDB(快照形式、保存当前数据状态)
在进行保存时可能会阻塞当前redis服务器,直到当前rdb过程完成,所以如果数据量过大,可能造册长时间的阻塞,我们通常使用bgsave进行保存。RDB 触发条件:
手动触发:
- save:执行该指令后,主线程执行 rdbSave 函数,服务器进程阻塞,即不能处理任何其他请求
- bgsave(background save):本质上这个命令和 save 差不多,区别在于这个命令会 fork 了一个子进程,去执行 rdbSave 函数,因此主线程还是可以执行新请求的。
自动触发: 配置文件中写入
save m n,代表当m秒内发生n次变化时,会自动执行 bgsave
AOF(以日志的方式进行持久化)
redis可以通过AOF文件,将文件中的数据修改命令全部执行一遍,以恢复数据。
AOF重写:
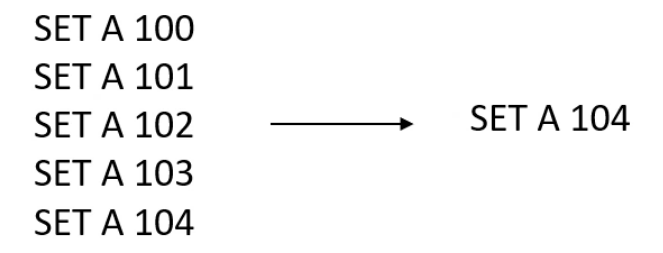
实现方式:创建一个新的AOF文件,替换原来的AOF文件。
AOF恢复:
AOF 触发条件
- 手动触发: bgrewriteaof
- 自动触发:配置文件中设置 appendonly yes 开启
- 自动触发的写入策略:
- Always:即同步写回,在每个写命令执行完成后,直接将命令落入磁盘文件(数据基本保证可靠性,但是影响 Redis 的性能)
- Everysec:即每秒写回,对于每个命令执行完成后,该命令被写入文件的内存缓存区,每过 1 秒,redis 会把该缓存区命令写到磁盘的 AOF 文件中(出了问题最多丢失一秒内数据,性能影响较小)
- No:这个 No 不是不执行 AOF,而是将操作命令全部只写到 Redis 缓存区,至于在何时将缓存数据落盘,交给操作系统决定(出了问题,数据丢失情况不可控,性能影响最小)
四、删除策略
1、基于过期时间(数据创建时固定时间)(过期的数据并没有真正的删除)
Redis是一种内存级数据库,所有数据均存放在内存中,内存中的数据可以通过TTL指令获取其状态 XX :具有时效性的数据
-1 :永久有效的数据
-2 :已经过期的数据或被删除的数据或未定义的数据
过期删除策略:
定时删除
创建定时器,当set数据设置的定时时间到达时,由定时器对该键值对执行删除任务,但是在执行期间会阻塞cpu,先进行删除,删除完成后才会释放cpu。(用cpu性能换区空间,那时间换空间)
惰性删除
当数据过期时,不做处理,当下次访问该数据时再进行删除,并返回不存在该数据。虽然会节约cpu的性能,但当过期数据一直不被访问时,则会长期占用内存。(相当于用内存空间来换取时间,cpu的性能)
定期删除(定时删除+惰性删除)
redis会主动执行定时删除策略,当不执行定期删除策略时,则执行惰性删除策略。
2、基于内存淘汰(内存满时)
LRU(最近最少使用)
传统的LRU算法是基于【链表】实现,链表中的元素会按照操作顺序从前往后进行排序,最新的操作的键会被移动到表头,当需要淘汰元素时,直接从表尾进行淘汰。
Redis并没有使用这样的方式进行实现LRU,因为会存在两个问题:
1、需要使用链表管理所有的缓存数据,会带来额外的空间开销。
2、当有数据被访问时,需要将链表中的元素移到表头,会很耗时,降低Redis缓存的性能。
Rids如何实现LRU算法?
它的实现方式是在Redis的对象结构体中添加一个额外的字段,用来保存该数据最后一次访问的时间。当Redis进行内存淘汰时,会使用随机采样的方式来进行淘汰数据,它会随机选取5个值,然后淘汰最久没有使用的那个。可以解决传承LRU存在的两个问题。但也会出现新的问题【缓存污染问题】:当软件一次读取大量数据,而这些数据只需要使用一次,那么这些数据就会在Redis缓存中存在很长的时间,造成数据污染。因此在Redis4.0后引入了 LFU 算法。
LFU(最近最不常用)
LFU 算法是根据访问次数来决定淘汰数据,他的核心思想【如果数据被访问多次,那将来的访问的频率也会更高】,所以 LFU 算法会记录每个数据的访问次数,当数据被访问一次则会增加一次访问次数,这样就解决了 LRU 中数据污染的问题。
Rids如何实现LFU算法?
Redis对象头中的24bits的lru字段被分为,高16bit存储idt,低8bit用来存储logc。

- ldt:是用来记录key被访问的时间戳。
- logc:是用来记录key的访问频次【不是次数】,数值越小越容易被淘汰,key初始值为5。
Redis在访问key时,对 logc 的变化:
- 先按照这次访问时间和上次访问时间的间隔,对 logc 进行衰减;
- 再按一定的概率增加 logc 的值;
五、企业级解决方案
缓存击穿
当一个热点key突然失效时,那么这些请求就会击穿缓存(Redis)自己对数据库进行查找,从而导致性能下降。
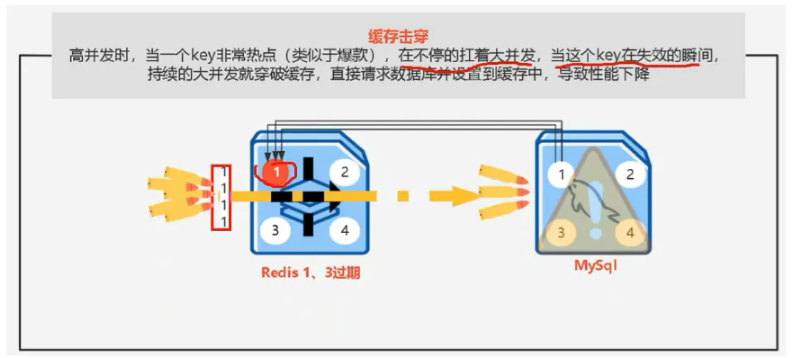
解决方案:
1、可以将key设置成永不过期的状态;
2、可以加锁排队,当一个key突然失效,会有一个线程进入数据库进行查询,并将读取的数据重新放回 Reids 缓存中,该过程在加锁的状态下只允许一个线程对数据库进行请求,当第一个线程将数据写入缓存就可以正常进行查询。
缓存雪崩
当大量key集中失效时,或者缓存服务宕机,会导致大量请求访问数据库,造成压力过大,甚至宕机。
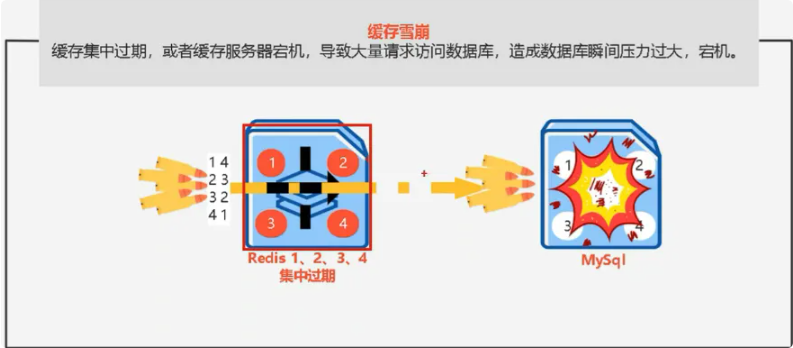
解决方案:
1、给不同的Key的TTL添加随机值
2、利用Redis集群提高服务的可用性
3、给缓存业务添加降级限流策略
4、给业务添加多级缓存
缓存穿透
当大量请求所查询的值缓存和数据库中都不存在时,会对数据库进行查询,会导致压力过大,甚至宕机。
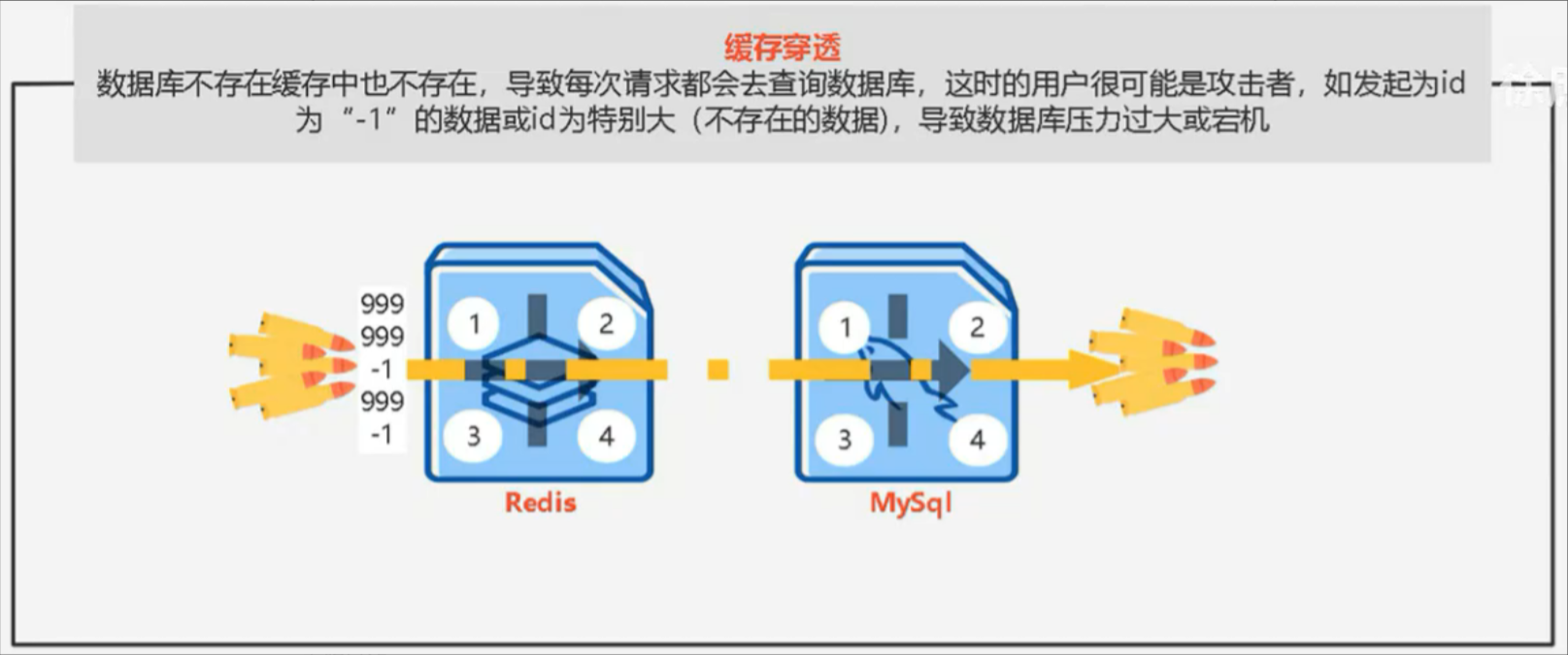
解决方案:
1、缓存空对象:单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis 中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存 了
2、布隆过滤
六、主从复制
Redis 主从复制(Master-Slave Replication)是 Redis 实现高可用、数据备份和读写分离的核心机制。其核心思想是:一个主节点(Master)负责处理写操作和数据同步,多个从节点(Slave)通过复制主节点的数据,仅处理读操作,从而分担主节点压力、提高系统吞吐量,并实现数据冗余。
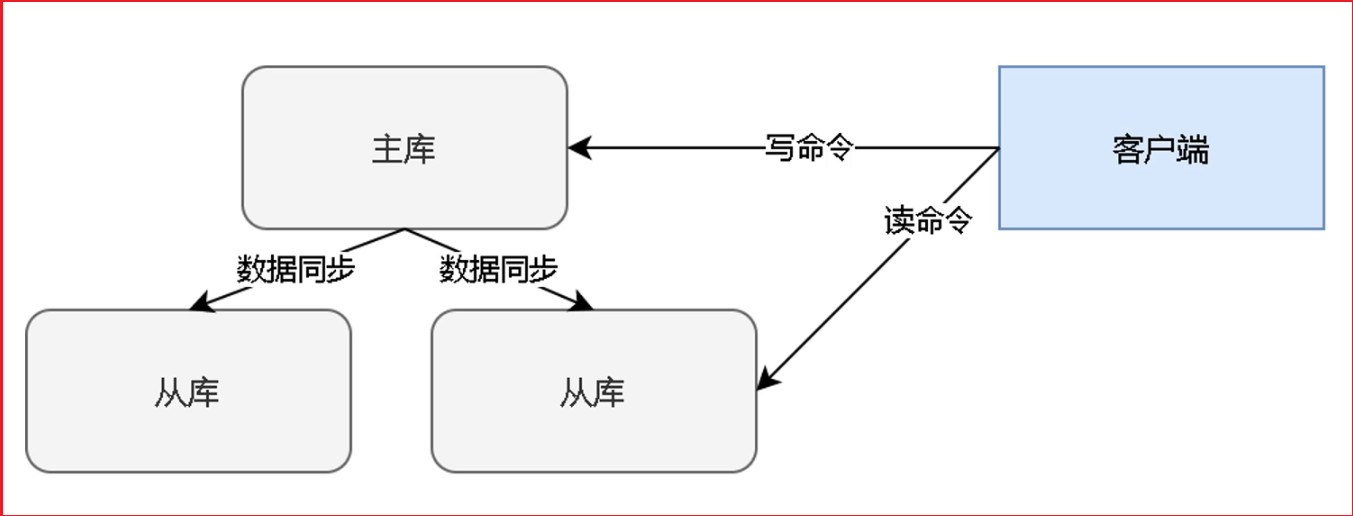
一、主从复制的核心作用
- 读写分离:Master 处理写请求(SET、DEL 等),Slaves 处理读请求(GET、ZRANGE 等),避免读写冲突,提升系统并发能力。
- 数据备份:Slave 是 Master 的实时备份,避免因 Master 单点故障导致数据丢失。
- 故障转移基础:当 Master 故障时,可通过哨兵(Sentinel)或集群机制将某个 Slave 升级为新 Master,实现高可用。
二、主从复制的核心原理(3 个阶段)
Redis 主从复制的过程分为「建立连接」「数据同步」「命令传播」三个阶段
建立连接:当主库从库上线后,不着急直接进行负责过程,首先需要握手进行信息验证。
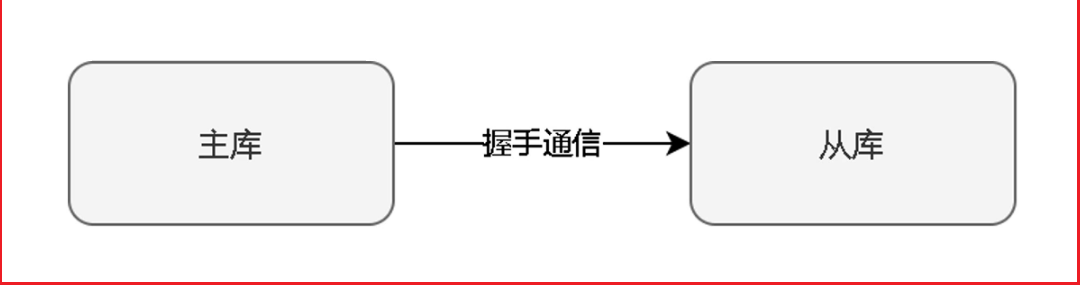
数据同步:当捂手完成后,从库需向主库发送PSYN命令,即同步命令,开启数据同步过程,并发送主库ID,复制进度偏移量offset。
主库会根据从库发送的消息,进行逻辑判断,并告诉从库进行全量复制/断线后重复制。
全量复制:初次复制后的同步
- 主库执行
BGSAVE,生成对应的RDB文件,同时开辟缓冲区,记录在RDB文件实行过程中,收到的新数据命令 RDB文件产生后,主库发给从库,从库通过RDB恢复数据
断线后重复制:从库与主库断线重连后复制
- 服务器运行 Id:唯一确定主库身份
- 复制偏移量:代表主节点传输了的字节数
- 复制积压缓冲区:复制积压缓冲区是一个先进先出队列,存储了最近主节点的数据修改命令。
命令传播:
数据同步完成后,主从进入「稳定复制阶段」。此时 Master 每执行一条写命令,都会立即将命令发送给所有 Slave,Slave 执行后保持与 Master 数据实时一致。
七、哨兵系统
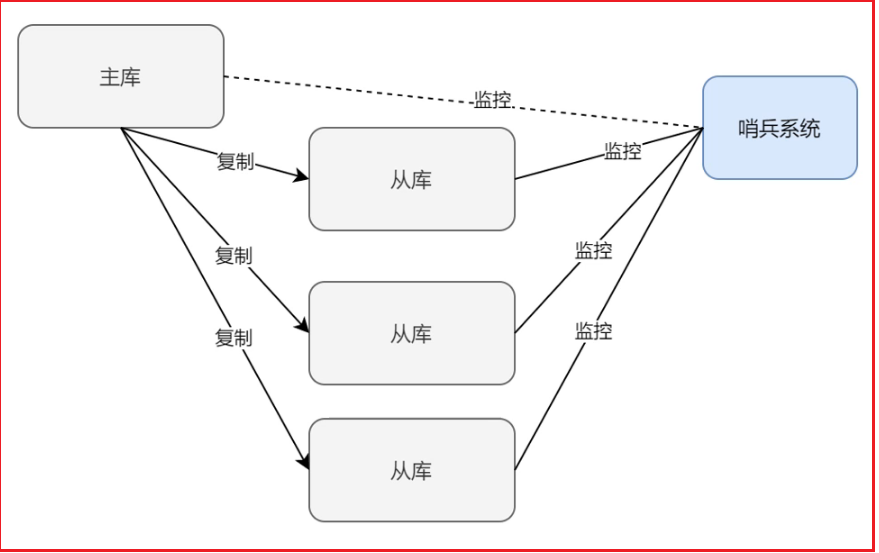
哨兵系统:哨兵会对主库和从库进行监控,所有库每隔一段时间(10s)会向系统发送消息(心跳),如果一段时间没有收到消息,也就认为这个库挂掉了,如果挂的是主库,那么多个哨兵会选一个老大哨兵对所有从库的状态进行评估,选择一个最适合做主库的从库进行升级。当主库又成功上线会将主库降为从库。
![【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包]](http://pic.xiahunao.cn/【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包])
)





---初始轨迹生成后的关键点采样)
)

及与Kafka实现的对比分析)
)







