目录
一、决策树简介
决策树建立过程
二、ID3决策树
核心思想:决策树算法通过计算信息增益来选择最佳分裂特征
1、信息熵
2、信息熵的计算方法
3、信息增益
4、信息增益的计算(难点)
5、ID3决策树构建案例
三、总结
一、决策树简介
决策树 (Decision Tree) 是一种树形结构的预测模型,它代表的是对象属性与对象值之间的一种映射关系。决策树通过学习数据特征,构建一套层次化的“判断-分支”规则,最终在叶子节点给出预测结果(每个叶子节点代表一种分类结果)。
根节点 (Root Node):代表整个数据集的起始点,包含所有样本。
内部节点 (Internal Node):对应特征或属性上的判断条件,每个判断会产生分支。
叶节点 (Leaf Node):代表决策的最终结果,即分类的类别或回归的预测值。
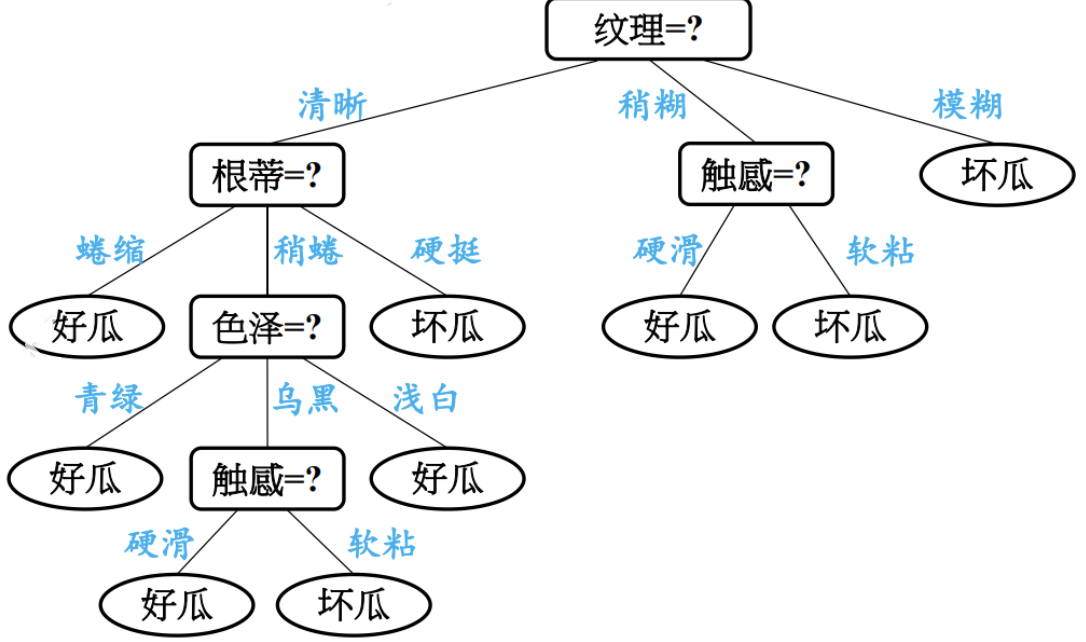
决策树建立过程
构建决策树的核心是递归地选择最优特征对数据进行划分,目标是使划分后子集的“纯度”最高。
1.特征选择:选取有较强分类能力的特征。
2.决策树生成:根据选择的特征生成决策树。
3. 决策树也易过拟合,采用剪枝的方法缓解过拟合。
二、ID3决策树
ID3(Iterative Dichotomiser 3)是一种经典的决策树学习算法,由 Ross Quinlan 在 1986 年提出,主要用于分类问题。它通过信息增益来选择特征进行划分,构建树形结构,其核心目标是生成一棵尽可能小的决策树(奥卡姆剃刀原理)。
核心思想:决策树算法通过计算信息增益来选择最佳分裂特征
- 计算当前数据集的初始信息熵(Entropy),衡量数据的混乱程度或不确定性
- 针对每个特征,计算其信息增益。信息增益表示使用该特征划分数据后,不确定性减少的程度
- 选择信息增益最大的特征作为当前节点的划分标准
- 根据该特征的每个取值,将数据集划分为不同的子集,并为每个子集创建新的子节点
- 对每个子节点递归地重复上述过程,直到满足停止条件(如所有样本属于同一类别,或没有更多特征可用)
1、信息熵
熵 Entropy :信息论中代表随机变量不确定度的度量
熵越大,数据的不确定性度越高,信息就越多(有序向无序变化)
熵越小,数据的不确定性越低

2、信息熵的计算方法
总的熵 = 各个熵的累加和
其中 表示数据中类别出现的概率,H(x) 表示信息的信息熵值,信息熵的单位是比特 (bit)
举例
计算数据 α(ABCDEFGH) 信息熵,其中A、B、C、D、E、F、G、H 出现的概率为:1/8
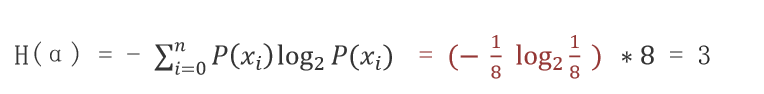
计算数据 β(AAAABBCD) 信息熵,其中A 出现的概率为1/2,B 出现的概率为1/4,C、D 出现的概率为1/8
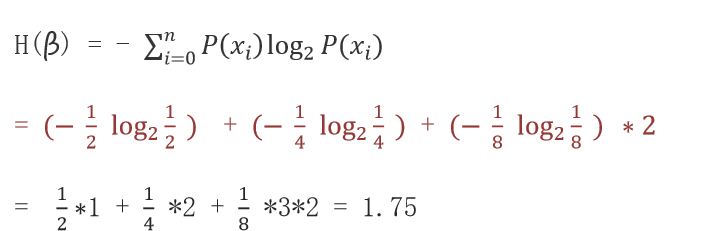
3、信息增益
信息增益衡量的是,在知道某个特征的信息之后,目标变量的不确定性减少的程度。它的核心思想比较知道特征前后不确定性的变化。
信息增益就是初始熵与条件熵的差值。这个差值越大,说明该特征对于降低目标变量不确定性的贡献越大,也就越重要。
条件熵描述了在已知第二个随机变量 Y的值的前提下,随机变量 X的剩余不确定性或信息熵 。换句话说,它表示在我们已经知道 Y的一些信息后,要完全确定 X的值还需要多少额外的信息。
4、信息增益的计算(难点)
,即信息增益 = 熵 - 条件熵
熵看标签,条件熵看特征和标签
条件熵的计算
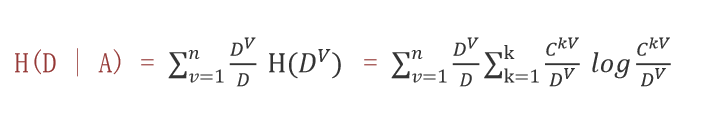
举例计算
已知6个样本,根据特征a:
α 部分对应的目标值为: AAAB
β 部分对应的目标值为:BB
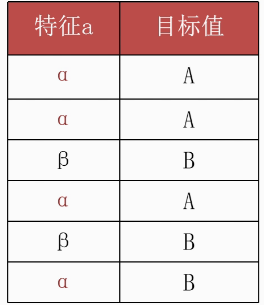
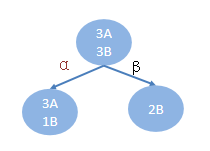
解析:一共6个样本,下面有两个类别:α和β
1、计算信息熵:
A的信息熵 =
B的信息熵 =
信息熵 = × 2 = 1
2、计算条件熵(条件熵 = 每个自己的信息熵 × 在整个数据集占比的概率)

α 的条件熵 =
β的条件熵 =
条件熵 =
3、计算:信息增益 = 熵 - 条件熵
信息增益
至此计算完了特征a的信息增益,以此类推计算其他特征列的信息增益。
与其他列相比,谁大谁当根节点。
5、ID3决策树构建案例
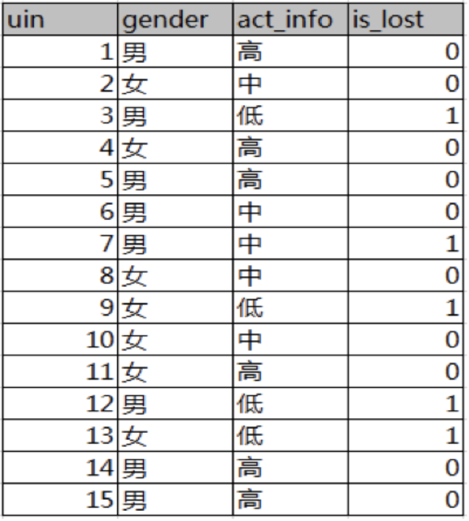
已知 某一个论坛客户流失率数据
需求:考察性别、活跃度特征哪一个特征对流失率的影响更大
分析:
15条样本:5个正样本、10个负样本
- 计算熵
- 计算性别信息增益
- 计算活跃度信息增益
- 比较两个特征的信息增益
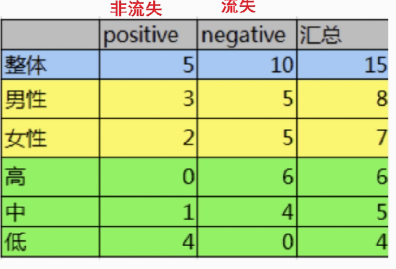


结论:活跃度的信息增益比性别的信息增益大,对用户流失的影响比性别大。由此可知,偏向于选择种类多的特征作为分裂依据。
三、总结
ID3算法是决策树家族的奠基性算法,它通过信息增益选择特征来构建树形分类模型。虽然它存在对连续特征和不完整数据支持不佳、容易过拟合等局限,但其核心思想清晰且易于理解,为后续更强大的算法(如C4.5和CART)奠定了基础。
)


软件调试---bug排查记录(36))












-尝试将存贮事件的地方改成数组(非必要解决方案)(附源码))
)

