数据库基础介绍
面临的挑战:
数据库系统架构:
数据库DB、数据库管理系统DBMS(负责数据库的搭建、使用和维护的系统软件,通过组织、索引、查询、修改数据库文件、实现数据定义、组织、存储、管理以及数据库操作、运行和维护等主要功能)、数据库应用程序DBAP、数据库管理员DBA。
存储管理(负责数据的物理存储和管理)、数据库管理(负责数据的逻辑管理和操作)、应用管理(负责应用程序与数据库的交互)、用户管理(负责用户的权限管理的数据访问控制)
数据库发展史:人工管理——文件系统——数据库系统。
NoSQL数据库通过非关系模型来管理数据,适用于管理大规模、非结构化数据,具有高扩展性和高性能的特点;NewSQL数据库则结合了关系型数据库和NoSQL数据库的优点,提供高性能和高扩展性的同时,仍然支持SQL查询。
面临的挑战:
数据类型多样性和异构处理能力;高度的可扩展性和可伸缩性;时效性;大数据时代;
5V特性:Volume数量、Variety多样性、Value价值、Velocity速度、Veracity真实性
数据库类型:
结构化数据:指可以使用关系型数据库表进行存储的数据。数据格式固定、利于存储和管理。
非结构化数据:数据格式不固定、内容多样化,难以进行标准化处理。适用于大数据存储和处理技术
半结构化数据:数据格式不固定、但包含标签或标记,用于描述数据的层次和关系。适用于需要部分结构化信息的场景。
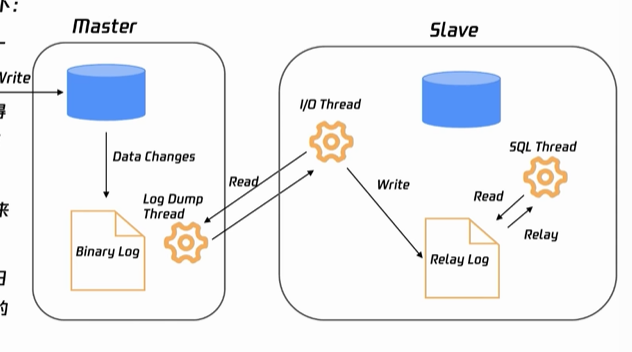
关系型数据库和非关系型数据库的区别:
关系型数据库是垂直扩展,即通过增加单个服务器的性能来提升数据库的处理能力;非关系数据库则更适合水平扩展,即通过增加更多的服务器节点来提升整体的处理能力,适用于大规模数据处理和分布式存储。
关系型数据库的数据一致性高,支持复杂的查询和事务处理,适用于结构化数据和严格数据一致性的应用场景;非关系型数据库扩展性强,读写性能高,适用于海量数据和高并发访问的应用场景。
关系型数据库简介:(结构化、完全符合ACID)
数据库:物理操作系统文件或磁盘数据块的集合
数据库实例:操作系统中一系列的进程以及为这些进程分配的内存。实例是数据库管理系统的运行环境,负责管理数据库的存储、管理和更新操作。
分布式集群:通过网络将多个服务器连接起来,形成一个逻辑上集中、物理上分布的大型数据库系统。
关系型数据库结构:
查询管理器:将用户的查询语句转化成内部命令;
存储管理器:负责执行这些命令,并管理数据库的物理存储结构;
数据存储和查询流程:
查询管理器接收用户查询,由DML和DDL解释器进行解释翻译——解析后的命令传给存储管理器——存储管理器根据命令对数据库文件、数据字典和索引进行操作——操作结果返回用户
模式Schema:包含表及其他数据库对象、数据类型、函数、操作符等,是对象的集合
允许多个用户使用一个数据库而不干扰其他用户;把数据库对象组织成逻辑组,让他们更便于管理;形成命名空间,避免对象的名字冲突。
可以更好地组织和管理数据库中的各种对象,确保用户可以高效地共享和使用同一个数据库而不会互相干扰。
表空间Tablespace:由一个或多个数据文件组成
通过表空间定义数据库对象文件的存放位置——频繁使用的索引放置在性能稳定且运算速度快的磁盘上;归档数据,使用频率低,对访问性能要求低的表存放在速度慢的磁盘上。
数据库中所有对象在逻辑上都存放在表空间中,在物理上储存在表空间所属的数据文件中——通过表空间限制物理空间使用上限,避免磁盘空间被耗尽。
帮助我们更好地管理数据库对象地存放位置,还能优化数据库的性能和资源利用。
数据库对象——表Table
行——记录、元组;列——字段(包含列名和数据类型)、域
其他数据库对象:视图view、index索引、sequence序列、store procedure存储过程、function函数
事务Transaction:一组原子性地SQL执行单元,具有ACID特性:原子性、一致性、隔离性、持久性
事务结束的标记:COMMIT(提交事务)正常结束;ROLLBACK(回滚事务)异常结束
MySQL 关系型数据库
物理存储结构和内存结构:
内存结构(主要用于存储临时数据和日志的缓冲)
缓冲池Buffer Pool:用于缓存数据页和索引页。通过缓冲池,MySQL可以减少对磁盘的访问,提高数据读取和写入的性能;
更改缓冲区Change Buffer:用于缓存对非唯一索引的更改操作。通过将这些更改操作缓存在内存中,可以减少对磁盘的写入次数,从而提高写入性能;
日志缓冲区Log Buffer:在事务提交之前,事务日志会先写入日志缓冲区,然后再批量写入磁盘,可以提高事务处理的效率;
物理架构:
系统表空间System Tablespace:存储引擎的核心部分
文件表空间File-Per-Table Tablespace:每个表都有自己独立的表空间文件,ibd文件,这种结构使得表的数据和索引存储在独立的文件中,便于管理和备份
重做日志Redo Log:用于记录事务的更改操作,以便在系统崩溃时进行数据恢复,包括Ib_logfile0和Ib_logfile1
撤销日志Undo Log:记录日志的撤销操作,在回滚时恢复数据
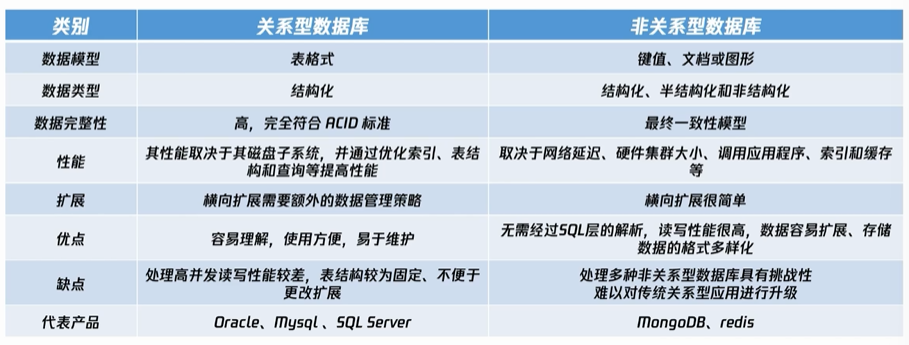
MySQL主从复制原理:
主从复制是MySQL常用的一种数据同步机制,能够实现数据的高可用性和负载均衡
从库生成两个线程,一个I/O线程和一个SQL线程
binlog(二进制日志)记录了主库上所有数据库更改操作,IO线程将从主库获取到的binlog日志写入到从库的Relay Log(中继日志)。
非关系型数据库简介:(最终一致性、易扩展)
关系型数据库的不足:无法适应多变的数据结构、高并发读写的瓶颈、可扩展性的限制
新需求:放松数据一致性的要求;改变固定的表结构;去除事务、关联等复杂操作;
NoSQL:非关系型数据库、分布式数据库。不保证遵循ACID原则的数据存储系统
特点:灵活性、可扩展性(通过使用分布式硬件集群来横向扩展)、高性能、功能强大(提供API和数据模型)
应用场景:
键值数据库:代表产品Redis。缓存、会话管理、配置管理、参数、购物车
文档数据库:代表产品MongoDB。内容管理、实时分析、博客、新闻网站
向量数据库:代表产品腾讯云向量数据库。推荐系统、图像搜索、推荐系统、自然语言处理等AI领域
其他数据库:图形数据库(Neo4j)、时序数据库(InfluxDB)、搜索引擎数据库(Elasticsearch)、列式数据库(HBase)
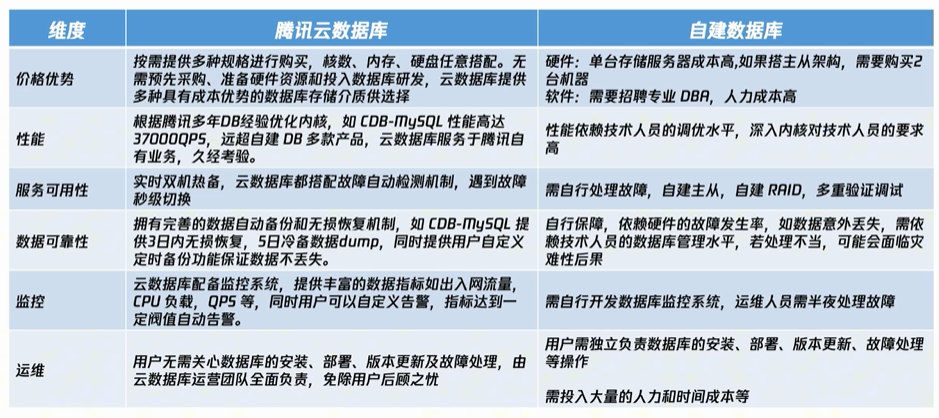
云数据库
云数据库产品介绍
特征:按需扩展、高可用性、高安全性、多种数据库类型(关系型、非关系型)、自动化管理
云数据库架构原理
基本概念:
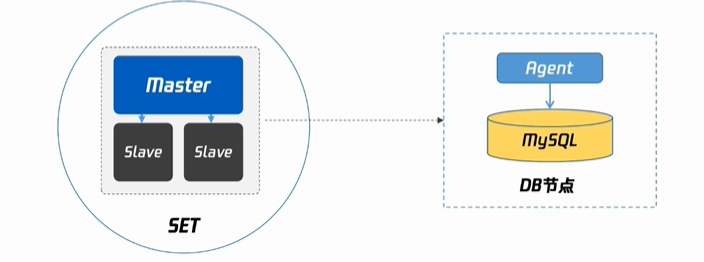
实例Instance:用户实际使用的一个最小单位的数据库服务集合
分片Sharding:将数据分成多个部分,分别存储在不同的数据库实例上
集群Cluster:一个数据库系统由多个数据库服务器组成
节点组Set:在数据库集群中,若干服务器组成的逻辑分组。每个节点组包含多个节点,多个节点组组成一个集群。进一步细化集群的管理和调度,提高系统的灵活性和可扩展性
主机、从机Master/Slave:主机直接承担读写;主从复制到从机,从机只可读不可写,也叫做备机
数据库引擎SQL Engine:核心,用于存储、处理和保护数据。确保数据的一致性和完整性。
整体架构:
VIP(统一入口)——SQL引擎——多个节点组,包括多个数据库实例,为分布式实例;如果只有一个节点组,就是一个关系型实例——冷备集群
SQL引擎:权限校验、读写分离、全局路由、语法分析、协议解析、路由执行
位于接入层,无主备之分,要求多节点部署;CPU密集型服务,对CPU、内存要求高;英文简称proxy
DB模块:DB节点上部署数据库服务,属于IO密集型服务,对IO要求高,建议配置SSD硬盘
Agent属于旁路模块,主要承担DB的状态监控、存活检测以及其他功能性任务的执行
目前DB内核可以提供兼容MariaDB和MySQL的不同版本
数据一致性:
强同步(不可退化)、强同步(可退化)、异步
故障转移步骤:主节点故障、主机降级为从机——参与选举的从机上报最新的Binlog文件偏移——选择出Binlog文件偏移最大节点——重建各个节点的主备关系——修改路由请求发给新的主机
高可用性:透明故障转移、
可扩展性:
如果是关系型实例,除最大规格实例外均提供无缝升级功能。
实例一键升级(通过Web控制台)、分布式性能线性增加(由单个分片性能和分片数量决定)、不存在性能瓶颈(关键模块基于分布式架构设计)、数据库内核优化(消除开源Bug)
数据备份:实力默认开启备份并备份7天,用户需手动设置
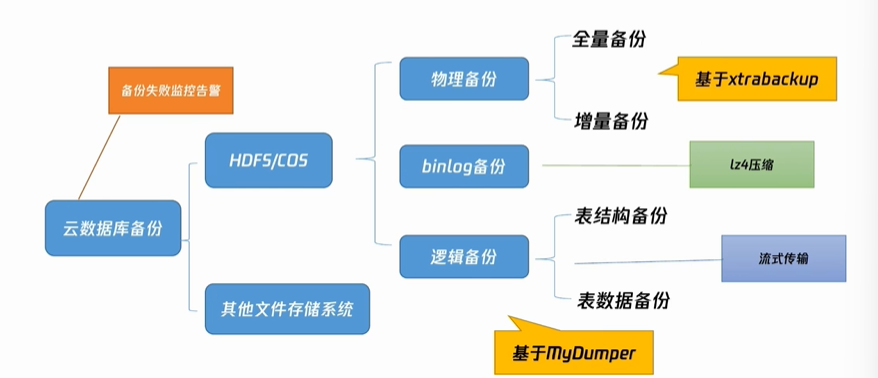
读写分离
创建账号时标记为只读账号;加入代码注释/*slave*/;只读实例;
高安全性:事前(传输加密、数据加密)、事中(内核级安全策略、内置SQL防火墙、防误操作机制)、事后(运维操作审计、数据库审计、服务器审计、超级权限控制)
云数据库分布式原理
云数据库对业务来说读写数据完全透明,对业务呈现的表实际上是逻辑表,逻辑表屏蔽了物理层实际存储规格,业务无需关心数据层如何存储,只需要关注基于业务表应该如何设计。
水平分表:
单实例模式:一张库表(逻辑表/物理表)分布在一个mysql实例上
分布式模式:业务侧呈现一张逻辑表、数据存储在不同的物理分片上。可以通过水平扩展来提升系统的性能和容量,适用于大规模数据和高并发场景。
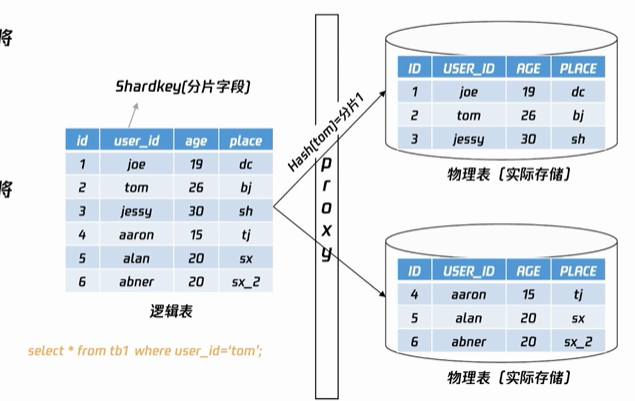
拆分原理:基于日期顺序(time);基于某字段划分范围(range,如按用户id);基于某字段求模(hash);——hash算法原理可以保证数据相对均匀分布
按照shardkey拆分:不同分片负责不同范围的号段,网关根据SQL中的shardkey发往对应的分片。
更新原理:
创建表时需指定路由字段shardkey——业务SQL的增、删、改、查包含shardkey时,Proxy通过对shardkey进行hash——数据根据分片算法,将SQL发往对应的分片
查询原理:
若SQL查询有明确的shardkey值,将直接从对应分片取出数据;
若没有shardkey,SQL查询请求将发往所有分片。返回数据按原始SQL语义进行合并后返回给用户。
云数据库TDSQL
云数据库:可以提供MySQL/MariaDB协议的关系型数据库实例、TDSQL MySQL版实例。时面向OLTP的分布式数据库。
产品优势:互联网高性能、高安全性、良好的扩展、便捷的运维、数据强一致、金融级高可用。
适用于:
大型应用(超高并发实时交易场景);物联网数据(PB级数据存储访问场景);文件索引(万亿行数据秒级存取);高性价比商业数据库解决方案。






)

TDD系统:光收发端编解码与信号处理分析与方案(数字版))









B860AV2.1-A2和CM311-5-zg刷机手记)
】项目管理下:软件质量与配置管理:构建可靠软件的基础保障)