概述
在现代 Web 架构中,Nginx 作为高并发、高性能的 HTTP 和反向代理服务器,被广泛应用于提升服务性能、增强系统安全性和实现负载均衡。其中,反向代理能够隐藏后端服务器信息并优化请求处理流程,负载均衡则可将请求分发到多个后端节点,大幅提升系统并发能力。
一、反向代理(proxy 模块)
1. 作用
- 性能优化:增加业务并发量。Nginx 可缓存静态资源,减少后端服务器处理压力,提升响应速度;同时通过连接复用,提高并发处理能力。
- 提高业务安全性:隐藏后端业务服务器的真实 IP 和端口信息,避免直接暴露在公网中,降低被攻击风险,
- 功能扩展:可实现请求过滤、URL 重写、SSL 终结等功能,简化后端服务器的配置复杂度。
2. 核心配置语法
反向代理的核心是通过location 块配合proxy_pass 指令,将特定请求转发至后端服务器。
location URI {proxy_pass 后端服务器地址;
}
URI:匹配路径:指定需要代理的客户端请求路径(如/mp3、/download);
proxy_pass 后端服务器地址; 指定请求转发的后端服务器地址(可包含 IP、端口及路径)
- 后端服务器地址:实际访问地址
明确目标:代理服务器正确转发 + 后端服务器正确响应
(1)路径拼接规则
Nginx 会自动将location中的匹配路径与proxy_pass的后端地址拼接,拼接方式取决于后端地址是否以斜杠结尾:
- 若后端地址无斜杠(如http://192.168.140.11/music),客户端请求路径会直接拼接在后端路径后;
- 若后端地址有斜杠(如http://192.168.140.11/music/),客户端请求路径会替换location的匹配路径后拼接。
location /test1 {
proxy_pass http://aa.linux.com; //nginx的反向代理,hosts文件需要加上dns解析
}
192.168.140.10/music // 192.168.140.10的网页目录(/var/www/html)下的music文件
192.168.140.10:8088/music //若nginx换端口
(2)不同场景下的配置示例
场景 1:带 URI 的精确匹配转发
当访问 Nginx 的任意路径时,代理到后端服务器的/music3 路径:
location / {proxy_pass http://192.168.140.20/music3;
}
# 说明:当客户端访问 Nginx 服务器的任意路径(例如http://你的Nginx地址/xxx)时,
# Nginx 会将该请求转发到 http://192.168.140.20/music3 对应的服务,
# 并将后端服务的响应返回给客户端。场景 2:不带 URI 的路径转发
当后端服务器没有特定 URI 时,Nginx 会将 location 中的 URI 拼接到后端地址:
location /test {proxy_pass http://192.168.140.10;
}
# 说明:此时请求http://nginx-ip/test/xyz会被转发为http://192.168.140.10:9000/test/xyz
场景 3:正则表达式匹配的特殊规则
当 location 使用正则表达式(~或~*)匹配请求时,proxy_pass后的后端地址不允许包含任何 URI,否则会报错:
# 正确配置(无URI)
location ~ /music {proxy_pass http://192.168.140.10;
}# 错误配置(包含URI,会导致Nginx启动失败)
# location ~ /music {
# proxy_pass http://192.168.140.10/project; # 此处错误
# }
3. 后端服务器记录客户端真实 IP
默认情况下,后端服务器会将 Nginx 的 IP 识别为客户端 IP,如需记录真实客户端 IP,需通过以下配置实现:
(1)Nginx 反向代理添加标识字段
在代理规则中添加X-REAL-IP或X-Forwarded-For字段,传递客户端真实 IP:
location /mp3 {proxy_pass http://192.168.140.11/music;# 传递客户端真实IP给后端proxy_set_header X-REAL-IP $remote_addr;# 若后端为多代理架构,使用X-Forwarded-For记录代理链proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
(2)
① 后端为 Apache(httpd)时的配置
修改 Apache 的日志格式,使其解析X-REAL-IP字段:
# 在httpd.conf中修改combined日志格式
LogFormat "%{X-REAL-IP}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
② 后端为 Nginx 时的配置
修改后端 Nginx 的日志格式,使用$http_x_forwarded_for获取真实 IP:
# 在后端Nginx的main日志格式中添加
log_format main '$http_x_forwarded_for [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';二、负载均衡(upstream 模块)
Nginx 的 upstream 模块是用于管理后端服务器集群的核心组件,通过它可以实现对多台后端服务器的统一调度、状态监控和故障处理。
1、 作用
- 提升并发能力:将客户端请求分发到多个后端服务器,避免单节点压力过大,提高系统整体吞吐量。
- 增强可用性:通过健康检查自动剔除故障节点,确保服务持续可用;同时支持备用节点,进一步提升可靠性。
- 灵活扩展:可根据业务需求动态增减后端节点,实现无缝扩容。
2、工作流程
(以 Nginx 为负载均衡器为例)
- 定义后端服务器组:通过upstream块定义一组后端服务器(如192.168.1.10:8080、192.168.1.11:8080),并配置调度算法和节点参数。
- 接收客户端请求:客户端请求首先到达 Nginx 负载均衡器(通常是前端入口服务器)。
- 选择后端节点:Nginx 根据upstream中配置的调度算法(如轮询、IP 哈希等),从服务器组中选择一台 “合适” 的后端服务器。
- 转发请求并返回响应:Nginx 将客户端请求转发到选中的后端服务器,后端处理后将响应返回给 Nginx,再由 Nginx 返回给客户端。
3、 调度算法 / 策略
Nginx 提供多种负载均衡算法,可根据业务场景选择:
① rr(Round Robin,轮询)
upstream app_servers {server 192.168.140.10:9000 weight=3; # 权重3,接收3/5的请求server 192.168.140.11:9000 weight=2; # 权重2,接收2/5的请求
}
- 默认算法,请求按顺序轮流分配到后端节点。
- 支持通过 weight 设置权重(权重越高,分配的请求越多),适用于后端节点性能不均的场景。
- 会话持久问题(见补充)
② sh(Source Hash,源哈希)
upstream app_servers {ip_hash; # 启用源哈希算法server 192.168.140.10:9000;server 192.168.140.11:9000;
}
- 根据客户端 IP 计算哈希值,将同一客户端的请求固定分配到同一后端节点。
- 适用于需要会话保持的场景(如未使用分布式会话的系统)。
③ lc(Least Connections,最少连接)
upstream app_servers {least_conn; # 启用最少连接算法server 192.168.140.10:9000;server 192.168.140.11:9000;
}
- 优先将请求分配到当前连接数最少的后端节点,适用于请求处理时间差异较大的场景。
4、健康状态检查与故障隔离
自动检测后端服务器的可用性,对故障节点进行隔离,避免请求转发到不可用的服务器,保障服务稳定性。
5、配置语法与示例
# 定义后端服务器组
upstream 服务器组名称 {[调度算法]; # 可选,默认rrserver IP:port [参数]; # 后端节点及可选参数server IP:port [参数];
}# 引用服务器组
location URI {proxy_pass http://服务器组名称;
}
常用参数说明
- weight=数值:设置节点权重(默认 1),数值越大优先级越高。
- max_fails=次数:允许请求失败的最大次数(默认 1),超过则标记节点为不可用。
- fail_timeout=秒数:标记节点不可用的时间(默认 10 秒),超时后会重新检测节点。
- backup:标记为备用节点,仅当所有非备用节点不可用时才接收请求。
- down:标记节点为永久不可用(手动下线时使用)。
完整配置示例
# 定义Java应用服务器组(使用轮询算法)
upstream java_servers {server 192.168.140.10:9000 weight=1 max_fails=2 fail_timeout=3s; # 权重1,失败2次后3秒内不分配server 192.168.140.10:9001 weight=1 max_fails=2 fail_timeout=3s;server 127.0.0.1:8000 backup; # 备用节点,主节点全故障时启用
}# 转发所有根路径请求到java_servers
location / {proxy_pass http://java_servers/project/;proxy_set_header X-REAL-IP $remote_addr; # 传递真实客户端IPproxy_set_header Host $host; # 传递原始请求的Host头
}# 转发/music路径请求到java_servers的/music目录
location /mp3 {proxy_pass http://java_servers/music/;proxy_set_header X-REAL-IP $remote_addr;
}# 备用节点的本地服务配置(当主节点故障时提供降级页面)
server {listen 8000;server_name localhost;location / {root /usr/share/nginx/sorry; # 存放降级页面的目录index index.html; # 降级页面}
}演示:
环境准备
假设有 3 台机器,IP 分别为:
负载均衡器(Nginx):
192.168.140.20(接收客户端请求,分发到后端)后端服务器 1(nginx):
192.168.140.10后端服务器 2(httpd):
192.168.140.30
步骤 1:配置后端服务器(10 和 30)
在 10 和 30 上安装 Nginx/httpd(模拟 Web 服务)
创建测试页面(区分两台服务器,方便验证负载均衡效果)
- echo "This is backend server 10 " > /usr/local/nginx/html/index.html //在 10 上执行
- echo "This is backend server 30" > /usr/share/nginx/html/index.html //在 30 上执行
验证后端服务:
分别访问 http://192.168.140.10 和 http://192.168.140.30, 应显示各自的测试内容。
步骤 2:配置负载均衡器(100)
在负载均衡器上安装 Nginx,并通过 upstream 模块定义后端服务器集群,实现请求分发。
安装 Nginx:
修改 Nginx 配置文件(/usr/local/nginx/conf/nginx.conf),在http块中添加 upstream(后端集群)和server(负载均衡规则):
http {# ... 其他默认配置(保留不动)# 1. 定义后端服务器集群(包含101和102)upstream backend_servers {# 调度算法:默认轮询(可按需改为weight、ip_hash等)server 192.168.1.101:80; # 后端服务器1server 192.168.1.102:80; # 后端服务器2server 127.0.0.1:8000 backup; # 备用节点,主节点全故障时启用# 可选:添加健康检查参数(自动剔除故障节点)# max_fails=2:允许2次请求失败# fail_timeout=10s:失败后隔离10秒# server 192.168.1.101:80 max_fails=2 fail_timeout=10s;}# 2. 配置负载均衡入口(接收客户端请求)server {listen 80; # 监听80端口(客户端访问的端口)server_name 192.168.1.100; # 负载均衡器的IP# 所有请求转发到后端集群location / {proxy_pass http://backend_servers; # 转发到upstream定义的集群proxy_set_header Host $host; # 传递客户端访问的Host(如192.168.1.100)proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header X-Forwarded-Proto $scheme; # 传递协议(http/https)}}server {listen 8000; # 备用服务端口server_name 127.0.0.1;location / {root /usr/local/nginx/backup_html; # 备用服务的网页目录index index.html;}}
}
# 创建备用服务的测试页面:
mkdir -p /usr/local/nginx/backup_html
# 写入备用内容(如“主节点故障,已切换至备用服务”)
echo "This is backup server (local 8000)" > /usr/local/nginx/backup_html/index.html// 加权轮询:若后端服务器性能不同,可通过weight分配请求比例(值越高,接收请求越多):
upstream backend_servers {server 192.168.1.101:80 weight=3; # 承担3/5的请求server 192.168.1.102:80 weight=2; # 承担2/5的请求
}
// 若需同一客户端请求固定到同一后端(如未做会话共享),使用ip_hash:
upstream backend_servers {ip_hash; # 基于客户端IP哈希server 192.168.1.101:80;server 192.168.1.102:80;
}检查配置并重启 Nginx
步骤 3:修改httpd/nginx配置文件
- vim /etc/httpd/conf/httpd.conf
- vim /usr/local/nginx/conf/nginx.conf
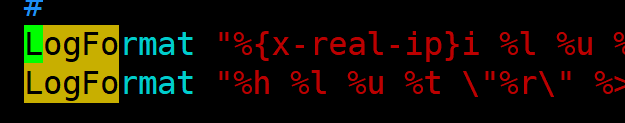
步骤 4:测试负载均衡效果
通过客户端访问负载均衡器的 IP(192.168.140.20),验证请求是否被分发到两台后端服务器。
1、多次访问测试:
在浏览器或终端多次访问 http://192.168.140.20,应交替显示:
This is backend server 10
This is backend server 30
(默认轮询算法下,请求会依次分发到 10 和 30)。
2、模拟故障测试:
- 停止后端10 的 Nginx(systemctl stop nginx),再次访问 http://192.168.140.20,应始终显示 30 的内容(Nginx 会自动剔除故障节点)。
- 停止后端10 和20的,再次访问 http://192.168.140.20,应始终显示备用节点
特殊的:如果负载均衡如此设置

- echo "This is backend server 10/ab " > /usr/local/nginx/html/ab/index.html
- echo "This is backend server 30/ab" > /var/www/html/ab/index.html
此时搜索192.168.140.20依次显示This is backend server 10/ab、This is backend server 20/ab
一、什么是会话?
在计算机网络和 Web 开发中,会话(Session) 指的是用户与系统(通常是服务器)之间的一次连续交互过程,核心作用是记录用户的状态信息,解决 HTTP 协议 “无状态” 的问题。
二、为什么需要会话?
HTTP 协议本身是 “无状态” 的:每次客户端(如浏览器)向服务器发送请求时,服务器无法默认记住 “这个请求来自哪个用户”“用户之前做过什么操作”。例如:
- 你在电商网站登录后,浏览商品、加入购物车,如果没有会话,服务器会 “忘记” 你已登录,也记不住你的购物车内容;
- 你在论坛发帖时,服务器需要知道 “你是谁” 才能关联到你的账号。
会话的出现,就是为了让服务器 “记住” 用户的状态(如登录信息、操作历史、偏好设置等),让交互更连贯。
会话的核心逻辑:会话的实现依赖 “会话标识(Session ID)”,流程大致如下:
- 创建会话:用户第一次访问服务器时,服务器生成一个唯一的 Session ID(如一串随机字符串),并创建一个对应的 “会话空间”(存储用户状态,如登录状态、购物车数据等);
- 传递标识:服务器将 Session ID 通过Cookie(主流方式)或 URL 参数返回给客户端,客户端后续请求时会自动携带这个 ID;
- 识别用户:服务器收到请求后,通过 Session ID 找到对应的 “会话空间”,从而识别用户身份和状态,继续处理请求(如确认 “已登录”、读取购物车内容);
- 销毁会话:当用户主动退出(点击 “退出登录”)或会话超时(如 30 分钟未操作),服务器会删除对应的会话数据,Session ID 失效。
二、什么是 “会话持久问题”?
在负载均衡(多后端服务器)环境中,用户的请求会被分发到不同的服务器。但默认情况下,用户的会话信息(如登录状态、临时数据)是存储在单个服务器的本地内存 / 文件中的。这会导致一个问题:
- 用户第一次请求被分到服务器 A,登录状态保存在 A 的本地;
- 第二次请求被负载均衡器分到服务器 B,B 没有用户的登录状态,用户需要重新登录。
这种 “用户状态无法在多服务器间共享” 的问题,就是会话持久问题。
三、如何解决?—— 会话共享
核心思路:将用户的会话信息从 “单服务器本地存储” 迁移到 “所有服务器都能访问的集中式存储”,让所有后端服务器都能读取到相同的会话数据。
NoSQL 数据库非关系型数据库(如 Redis、MongoDB、memached)实现会话共享。
- 高性能:NoSQL(尤其是 Redis)支持内存存储,读写速度极快,适合会话这种高频访问的数据;(对内存要求高)
- 键值结构适配:会话数据通常是 “会话 ID→用户信息” 的键值对形式,与 NoSQL 的存储模型天然匹配;
- 支持过期时间:可直接为会话数据设置过期时间(如 2 小时),自动清理无效会话,无需手动维护;
- 高可用:NoSQL 可通过集群部署(如 Redis 主从、哨兵)避免单点故障,确保会话数据不丢失。
四、基于 NoSQL 的会话共享流程
以最常用的 Redis 为例,完整流程如下:
用户首次登录:
- 用户在浏览器输入账号密码,请求被负载均衡器分发到某台后端服务器(如服务器 A);
- 服务器 A 验证通过后,生成一个唯一的会话 ID(如session_id=xxxx);
- 将用户的会话数据(如用户 ID、登录时间、权限等)以session_id为键,存储到 Redis 中(例如:SET session:xxxx "{user_id:100, status:login}" EX 7200,设置 2 小时过期);
- 服务器 A 将session_id通过 Cookie 或 URL 参数返回给客户端(浏览器),客户端后续请求会自动携带该session_id。
用户后续请求:
- 客户端携带 session_id 发送请求,被负载均衡器分发到任意服务器(如服务器 B);
- 服务器 B 收到请求后,从 Redis 中通过session_id查询会话数据(GET session:xxxx);
- 若查询到有效数据,说明用户已登录,直接返回请求结果;若未查询到(过期或无效),则要求用户重新登录。
会话过期 / 注销:
- 若用户主动退出登录,服务器删除 Redis 中对应的session_id数据;
- 若用户长时间未操作,Redis 会自动根据预设的过期时间删除会话数据,实现 “自动登出”。











:构建与PDF/PPT文档对话的AI助手)





)

