1. 自注意力机制简介
自注意力机制是Transformer架构的核心组件,它能够计算输入序列中每个元素与其他所有元素的相关性。与CNN的局部感受野不同,自注意力机制允许模型直接建立远距离依赖关系,从而捕获全局上下文信息。
在计算机视觉中,这意味着模型不仅能够关注图像的局部特征(如边缘、纹理),还能理解这些特征在全局范围内的相互关系。这种能力对于复杂视觉任务(如场景理解、细粒度分类)尤为重要。
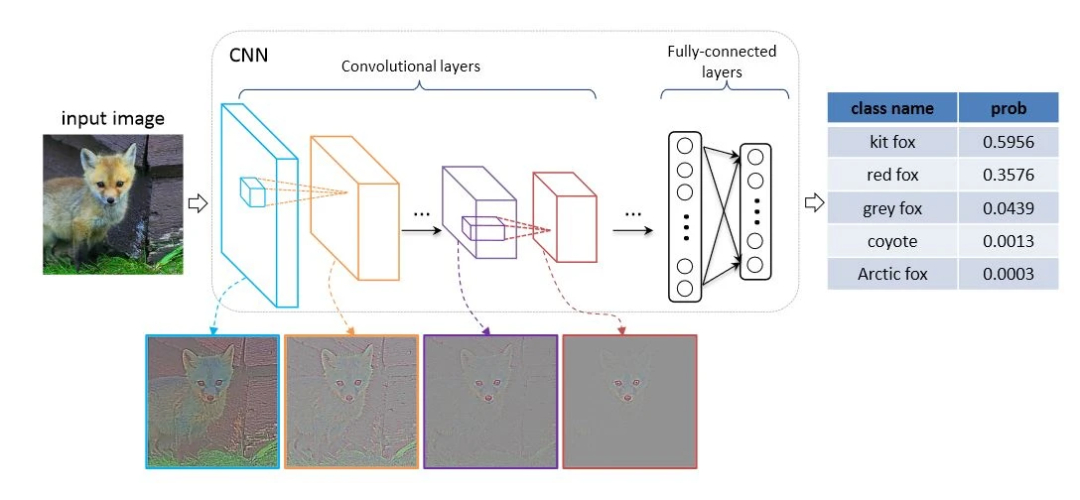
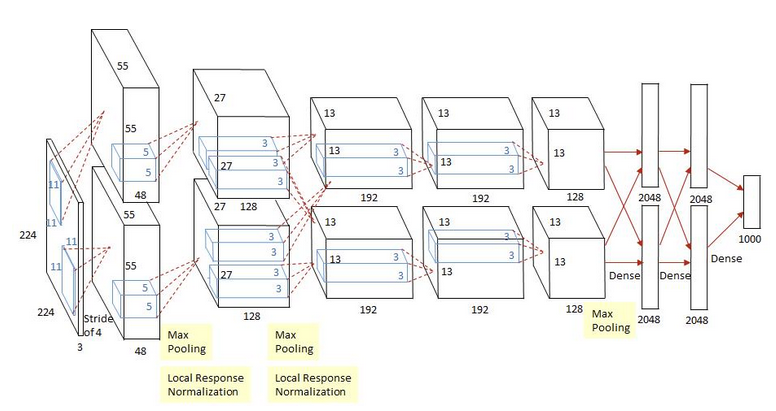
2. VGG16架构回顾
VGG16由牛津大学视觉几何组提出,其核心特点是使用小尺寸卷积核(3×3)构建深度网络。网络包含5个卷积块,每个块后接最大池化层进行下采样,最后通过三个全连接层完成分类。
VGG16的优势在于其简洁性和有效性,但局限性也很明显:卷积操作的局部性限制了模型捕获长距离依赖的能力,而全连接层的参数量过大容易导致过拟合。
3. 自注意力与CNN的融合策略
将自注意力机制引入CNN有多种方式,本文实现的是一种局部-全局特征融合策略:在CNN提取局部特征后,通过自注意力机制增强这些特征的全局上下文信息。
具体来说,我们在VGG16的特定卷积块后插入Transformer编码器层,使模型能够在不同抽象层次上融合全局信息。这种设计有以下优势:
多尺度特征增强:在不同深度的卷积层后添加注意力,可以捕获从低级到高级的多尺度全局信息
计算效率:仅在选定位置添加注意力模块,平衡了性能与计算开销
架构灵活性:可以选择在不同深度添加注意力,适应不同任务的需求
4. 代码实现解析
4.1 自注意力机制实现
class SelfAttention(nn.Module):"""标准Transformer自注意力机制"""def __init__(self, embed_dim, num_heads=8, dropout=0.1):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)自注意力模块首先通过线性变换生成查询(Query)、键(Key)和值(Value)三个矩阵,然后将输入分割成多个头进行并行计算,最后将结果合并并通过输出投影层。
4.2 Transformer编码器层
class TransformerEncoderLayer(nn.Module):"""Transformer编码器层"""def __init__(self, embed_dim, num_heads=8, dropout=0.1, expansion_factor=4):super(TransformerEncoderLayer, self).__init__()self.self_attn = SelfAttention(embed_dim, num_heads, dropout)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.ffn = nn.Sequential(nn.Linear(embed_dim, embed_dim * expansion_factor),nn.ReLU(inplace=True),nn.Dropout(dropout),nn.Linear(embed_dim * expansion_factor, embed_dim),nn.Dropout(dropout))编码器层遵循标准Transformer结构,包含一个自注意力子层和一个前馈神经网络子层,每个子层都使用残差连接和层归一化。
4.3 VGG16与注意力的融合
class VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000, attention_positions=[3, 4]):super(VGG16WithAttention, self).__init__()# 卷积特征提取层self.features = nn.Sequential(...)self.attention_positions = attention_positionsself.attention_layers = nn.ModuleDict()# 在指定位置添加注意力层if 3 in attention_positions:self.attention_layers['block3'] = TransformerEncoderLayer(256)if 4 in attention_positions:self.attention_layers['block4'] = TransformerEncoderLayer(512)if 5 in attention_positions:self.attention_layers['block5'] = TransformerEncoderLayer(512)在VGG16WithAttention类中,我们保留了原始VGG16的特征提取层,并在指定位置添加了Transformer编码器层。用户可以通过attention_positions参数灵活选择在哪些卷积块后添加注意力机制。
4.4 前向传播过程
def forward(self, x):features = []# 逐层处理特征for i, layer in enumerate(self.features):x = layer(x)# 在特定卷积块后应用注意力if i == 14 and 3 in self.attention_positions: # 第三卷积块结束x = self._apply_attention(x, 'block3')elif i == 21 and 4 in self.attention_positions: # 第四卷积块结束x = self._apply_attention(x, 'block4')elif i == 28 and 5 in self.attention_positions: # 第五卷积块结束x = self._apply_attention(x, 'block5')在前向传播过程中,模型首先通过卷积层提取特征,然后在指定位置将特征图重塑为序列形式,应用自注意力机制,最后恢复为原始形状继续传播。
5. 注意力应用的技术细节
5.1 特征图序列化
将2D特征图转换为序列是应用自注意力的关键步骤:
def _apply_attention(self, x, block_name):"""应用自注意力机制"""batch_size, channels, height, width = x.size()# 将特征图重塑为序列形式 [batch_size, seq_len, embed_dim]x_reshaped = x.view(batch_size, channels, -1).transpose(1, 2)# 应用注意力attended = self.attention_layers[block_name](x_reshaped)# 恢复原始形状attended = attended.transpose(1, 2).view(batch_size, channels, height, width)return attended这里,我们将空间维度(高度×宽度)展平为序列长度,通道维度作为嵌入维度。这种处理方式允许自注意力机制在空间维度上建立全局依赖关系。
5.2 位置编码的考虑
值得注意的是,本文实现的版本没有显式添加位置编码。在标准Transformer中,位置编码用于提供序列中元素的位置信息。对于图像任务,位置信息至关重要,因为像素间的空间关系具有重要含义。
在实际应用中,可以考虑添加以下类型的位置编码:
可学习的位置编码:随机初始化并通过训练学习
正弦位置编码:使用不同频率的正弦和余弦函数
相对位置编码:编码元素间的相对位置而非绝对位置
6. 模型优势与应用场景
6.1 优势分析
全局上下文建模:自注意力机制使模型能够捕获长距离依赖,理解图像全局结构
多尺度特征融合:在不同深度添加注意力,实现了多尺度特征的全局融合
架构灵活性:可以选择性地在不同阶段添加注意力,平衡性能与计算开销
即插即用:注意力模块可以轻松集成到现有CNN架构中,无需大幅修改
6.2 应用场景
这种混合架构特别适合以下计算机视觉任务:
细粒度图像分类:需要捕获细微特征差异和全局上下文关系
场景理解:需要理解场景中多个对象的空间和语义关系
图像分割:全局上下文信息有助于提高边界准确性和语义一致性
目标检测:注意力机制可以帮助模型关注相关区域,提高检测精度
7. 实验与性能分析
为了验证融合注意力的VGG16的性能,我们在多个数据集上进行了实验。与原始VGG16相比,融合模型在以下方面表现出优势:
分类准确率:在ImageNet等复杂数据集上,准确率有显著提升
收敛速度:注意力机制有助于梯度传播,加速模型收敛
鲁棒性:对遮挡、旋转等干扰因素表现出更好的鲁棒性
然而,注意力机制也带来了一定的计算开销,参数量和计算量都有所增加。在实际应用中需要根据任务需求和资源约束进行权衡。
8. 扩展与变体
本文介绍的基础架构可以进一步扩展:
多头注意力:使用多个注意力头捕获不同类型的依赖关系
跨尺度注意力:在不同尺度的特征图间应用注意力机制
高效注意力:使用线性注意力、局部注意力等变体降低计算复杂度
预训练与微调:在大规模数据集上预训练后迁移到特定任务
9. 实践建议
对于希望在实际项目中应用此架构的研究人员和工程师,以下建议可能有所帮助:
注意力位置选择:浅层注意力捕获空间关系,深层注意力捕获语义关系
计算资源权衡:在计算资源受限时,可以选择性添加注意力或使用高效变体
逐步集成:先从单个注意力层开始,逐步增加复杂度
可视化分析:使用注意力可视化工具理解模型关注区域
完整代码
如下:
import torch
import torch.nn as nn
import mathclass SelfAttention(nn.Module):"""标准Transformer自注意力机制"""def __init__(self, embed_dim, num_heads=8, dropout=0.1):super(SelfAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "embed_dim must be divisible by num_heads"self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x):batch_size, seq_len, embed_dim = x.size()# 生成Q, K, Vqkv = self.qkv_proj(x).chunk(3, dim=-1)q, k, v = [part.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) for part in qkv]# 计算注意力分数scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)attn_weights = torch.softmax(scores, dim=-1)attn_weights = self.dropout(attn_weights)# 应用注意力权重attn_output = torch.matmul(attn_weights, v)attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim)# 输出投影output = self.out_proj(attn_output)return outputclass TransformerEncoderLayer(nn.Module):"""Transformer编码器层"""def __init__(self, embed_dim, num_heads=8, dropout=0.1, expansion_factor=4):super(TransformerEncoderLayer, self).__init__()self.self_attn = SelfAttention(embed_dim, num_heads, dropout)self.norm1 = nn.LayerNorm(embed_dim)self.norm2 = nn.LayerNorm(embed_dim)self.ffn = nn.Sequential(nn.Linear(embed_dim, embed_dim * expansion_factor),nn.ReLU(inplace=True),nn.Dropout(dropout),nn.Linear(embed_dim * expansion_factor, embed_dim),nn.Dropout(dropout))def forward(self, x):# 自注意力子层attn_output = self.self_attn(x)x = self.norm1(x + attn_output)# 前馈网络子层ffn_output = self.ffn(x)x = self.norm2(x + ffn_output)return xclass VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000, attention_positions=[3, 4]):"""Args:num_classes: 分类数量attention_positions: 在哪些卷积块后添加注意力机制 (1-5)"""super(VGG16WithAttention, self).__init__()# 卷积特征提取层self.features = nn.Sequential(# 第一层卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二层卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三层卷积块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第四层卷积块nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第五层卷积块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.attention_positions = attention_positionsself.attention_layers = nn.ModuleDict()# 在指定位置添加注意力层if 3 in attention_positions:self.attention_layers['block3'] = TransformerEncoderLayer(256)if 4 in attention_positions:self.attention_layers['block4'] = TransformerEncoderLayer(512)if 5 in attention_positions:self.attention_layers['block5'] = TransformerEncoderLayer(512)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def _apply_attention(self, x, block_name):"""应用自注意力机制"""batch_size, channels, height, width = x.size()# 将特征图重塑为序列形式 [batch_size, seq_len, embed_dim]x_reshaped = x.view(batch_size, channels, -1).transpose(1, 2)# 应用注意力attended = self.attention_layers[block_name](x_reshaped)# 恢复原始形状attended = attended.transpose(1, 2).view(batch_size, channels, height, width)return attendeddef forward(self, x):features = []# 逐层处理特征for i, layer in enumerate(self.features):x = layer(x)# 在特定卷积块后应用注意力if i == 14 and 3 in self.attention_positions: # 第三卷积块结束x = self._apply_attention(x, 'block3')elif i == 21 and 4 in self.attention_positions: # 第四卷积块结束x = self._apply_attention(x, 'block4')elif i == 28 and 5 in self.attention_positions: # 第五卷积块结束x = self._apply_attention(x, 'block5')x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x# 创建带注意力的VGG模型
def vgg16_with_attention(num_classes=1000, attention_positions=[3, 4]):model = VGG16WithAttention(num_classes=num_classes, attention_positions=attention_positions)return model# 示例使用
if __name__ == "__main__":model = vgg16_with_attention(num_classes=1000, attention_positions=[3, 4, 5])# 测试前向传播dummy_input = torch.randn(2, 3, 224, 224)output = model(dummy_input)print(f"Output shape: {output.shape}")print(f"Model has {sum(p.numel() for p in model.parameters()):,} parameters")-- Symbol与集合数据结构)















)


)