一、人类反馈的强化学习(RLHF)
微调的目标是通过指令,包括路径方法,进一步训练你的模型,使他们更好地理解人类的提示,并生成更像人类的回应。
RLHF:使用人类反馈微调型语言模型,使用强化学习,使用人类反馈微调LLM,从而得到一个更符合人类偏好的模型。
Reinforcement Learning(强化学习):是一种机器学习类型,智能体在环境中采取行动,以达到最大化某种累积奖励的目标,从而学习做出与特定目标相关的决策。
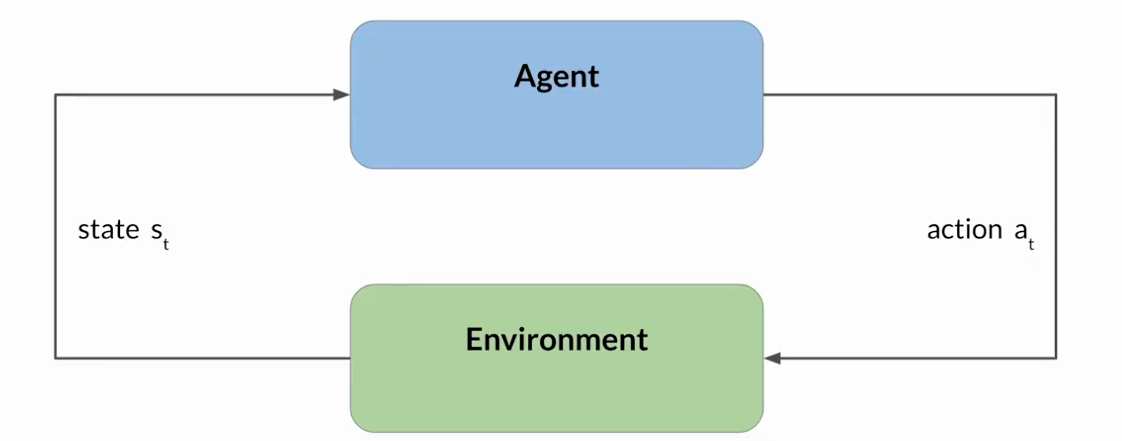
智能体通过采取行动,观察环境中的变化,并根据其行动的结果接收奖励或者惩罚,不断从其经验中学习,迭代这一过程。
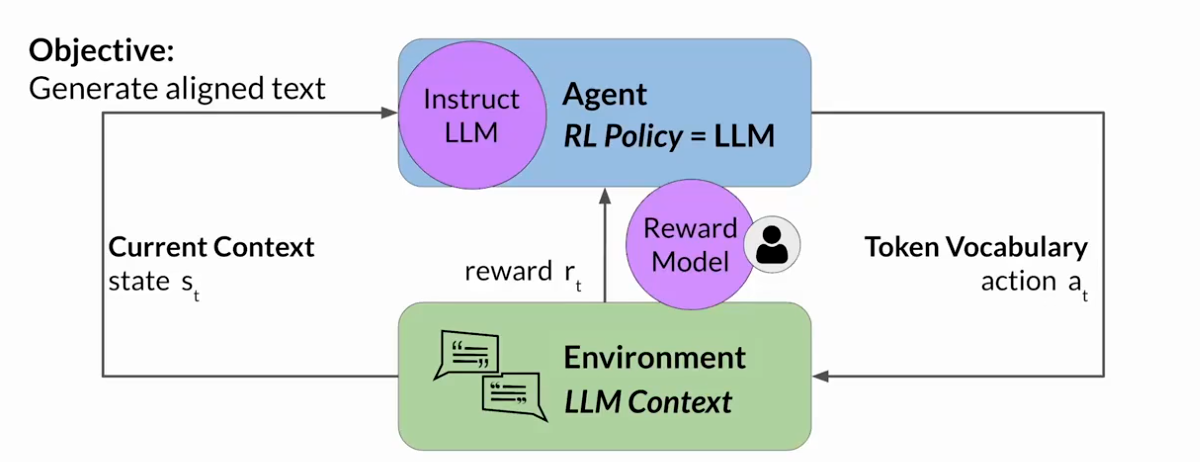
RLHF:获取人类反馈的信息
首先,必须决定你希望人类根据什么标准来评估LLM的生成结果
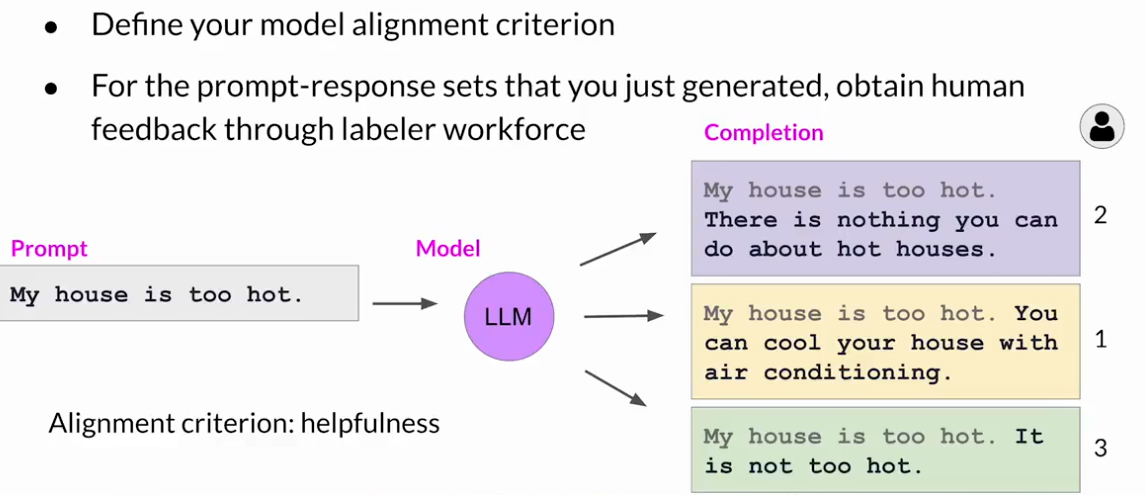
RLHF:奖励模式
奖励模型将有效地取代人类的数据标注员并自动选择在RLHF过程中自动挑选最佳的结果
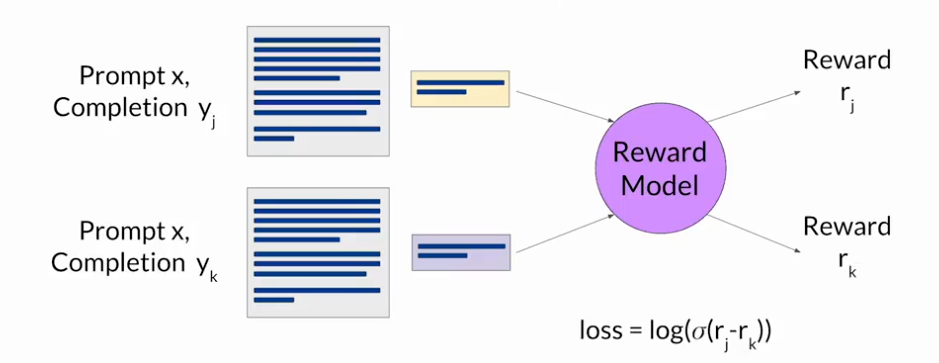
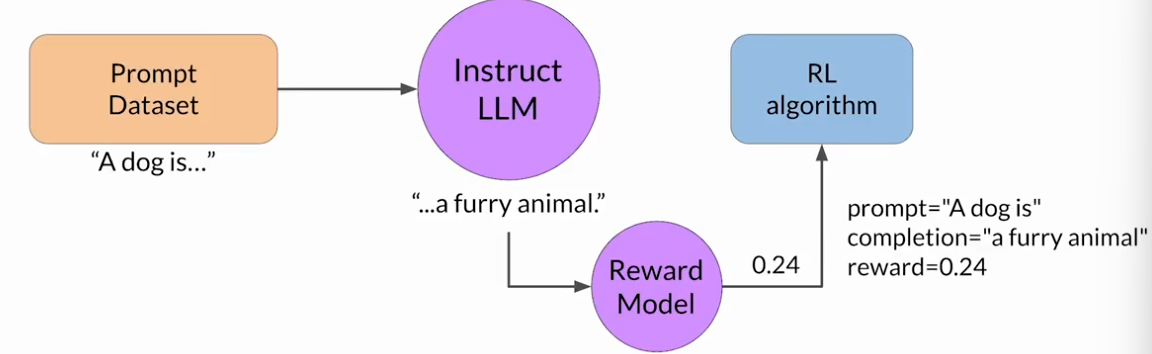
RLHF:利用强化学习进行微调
优先选择一个在所关注的任务上已经做的很好的模型
首先,从提示词数据集中选择一个提示词,使用LLM进行补全,反馈至奖励模型得到一个奖励值,将这个提示词-补全对于奖励值反馈至强化学习算法,来更新LLM的权重
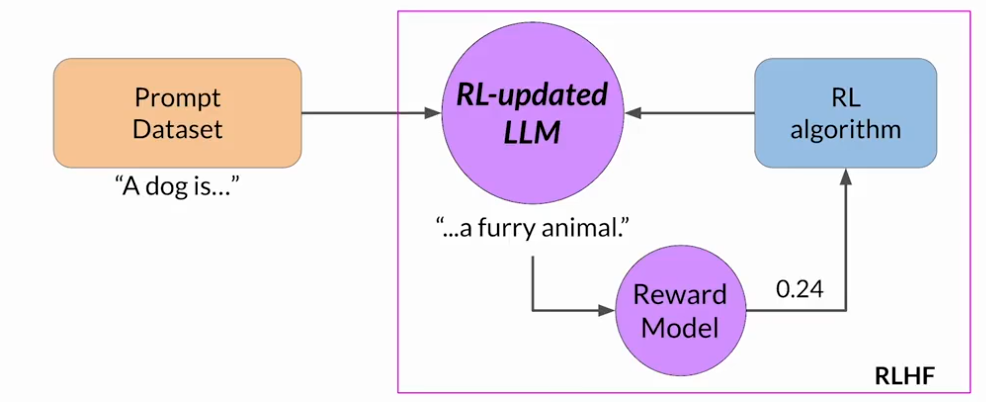
把微调过的模型成为人类对齐的LLM
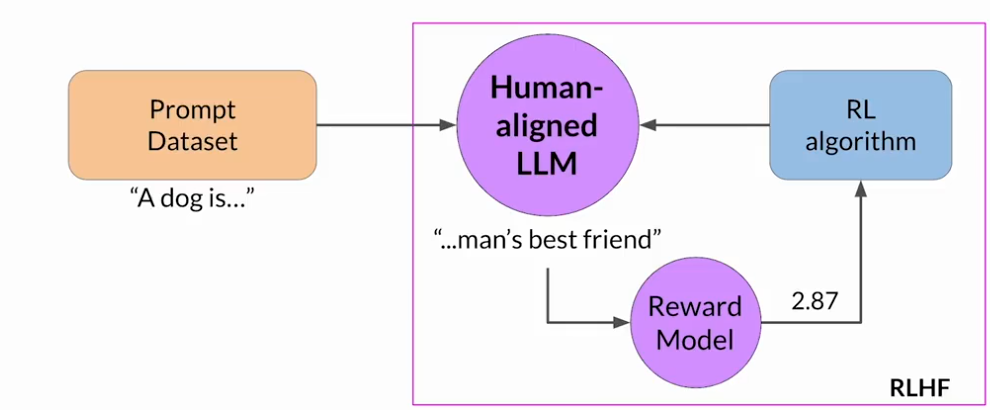
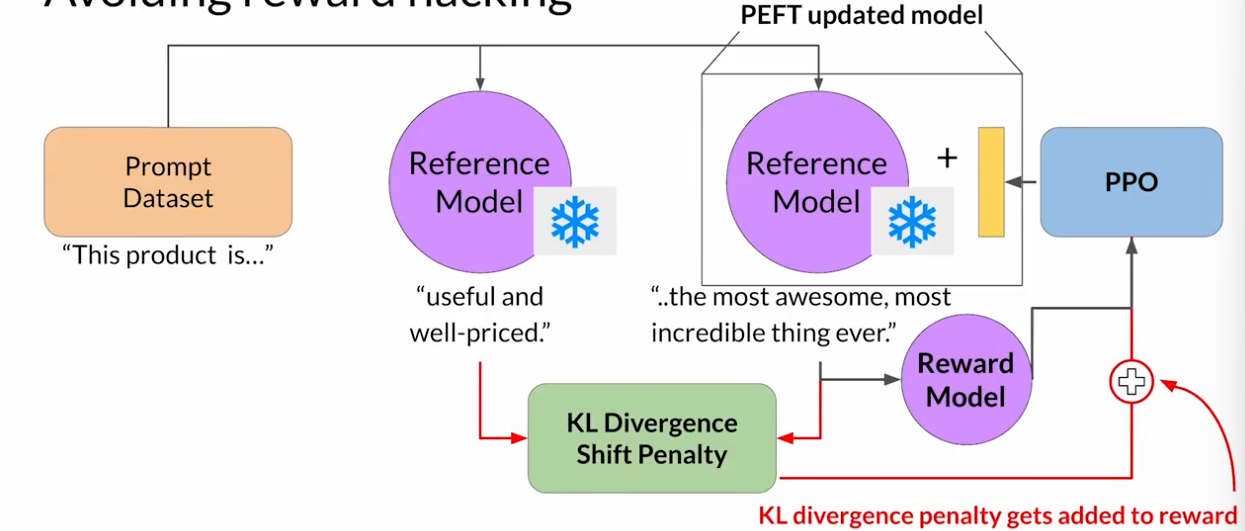
RLHF:奖励黑客行为
代理通过选择那些使其获得最大奖励的行为来欺骗系统,即使这些行动并不符合原始的目标
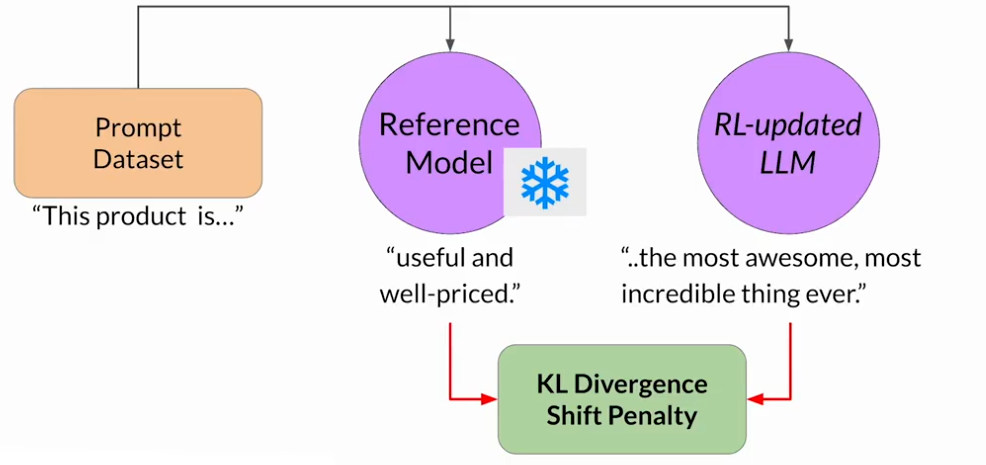
KL散度是一个统计度量,用来衡量两个概率分布有多不同,可以用它来比较两个模型的生成结果,来确定RL更新模型已经偏离了多少参考。




)




——个人笔记)









