前面提到过进程是由很多线程组成的,那么今天廖老师就详细解释了线程是如何运行的。
首先,,Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
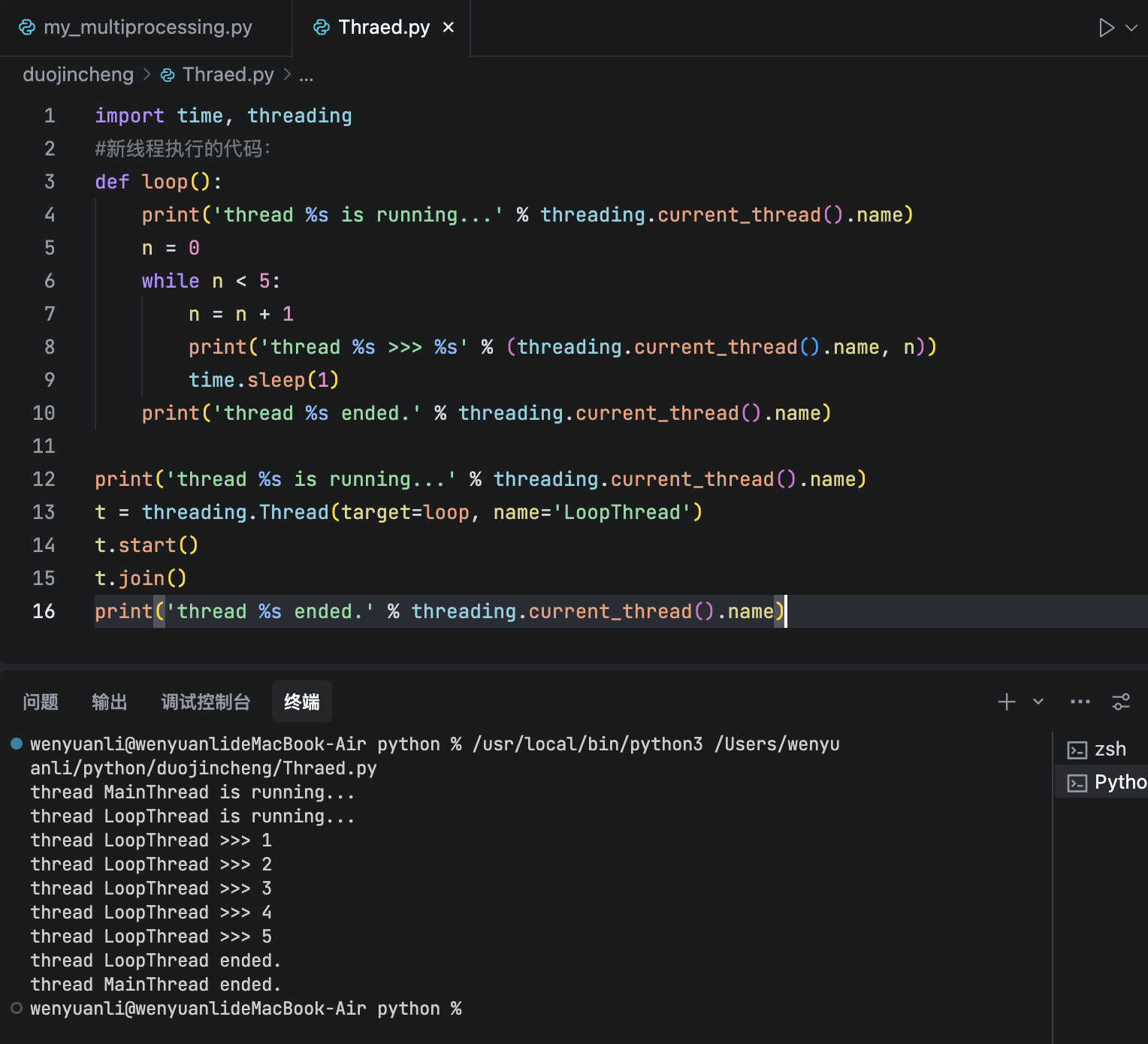
根据廖老师的例子,运行出来如此的结果。
任何 Python 程序默认都在一个主线程中运行,该线程通常名为 MainThread
threading.current_thread().name用于获取当前正在执行的线程的名称。
t = threading.Thread(target=loop, name='LoopThread') 这里使用 threading.Thread类来创建一个线程对象 ,也就是我们所需要的支线线程
start()方法会启动新线程。这意味着 Python 会创建新的执行上下文,并几乎同时开始在新线程中执行 loop函数
重要的是,调用 start()后,主线程不会阻塞,它会继续向下执行(t.join()),而新线程 LoopThread也开始并发地执行自己的任务。
不过由于多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。所以我们这里会引入一个lock语句
balance = 0
lock = threading.Lock()def run_thread(n):for i in range(100000):# 先要获取锁:lock.acquire()try:# 放心地改吧:change_it(n)finally:# 改完了一定要释放锁:lock.release()创建一个锁就是通过threading.Lock()来实现。
不过这里的锁虽然可以让我们的内容不那么紊乱,但是包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了甚至他会让多个锁在一起执行可能形成一个死锁。


:Kubernetes架构-原理-组件)

类型和Option类型)




)









:让大模型能够回答私域知识问题)