1. 创建go的入口函数
// Create a new g running fn.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
func newproc(fn *funcval) {gp := getg()pc := sys.GetCallerPC()systemstack(func() {newg := newproc1(fn, gp, pc, false, waitReasonZero)pp := getg().m.p.ptr()runqput(pp, newg, true)//true代表放置为runnext优先级g;内部随机数使得优先级g降级为普通g;runnext位置仅1,cas进行新旧替换;普通g放置在p队列尾if mainStarted {wakep() //内部使用cas 和 判断自旋m数量 来保证不过度创建m 和 避免抢占}})
}2.schedule函数
// 调度器的一轮操作:查找可运行的goroutine并执行它
// 该函数不会返回
func schedule() {mp := getg().m// 如果当前M持有锁,则抛出错误(锁的存在可能破坏调度逻辑)if mp.locks != 0 {throw("schedule: holding locks")}// 如果当前M被锁定到某个goroutine,需要先释放P再执行该Gif mp.lockedg != 0 {stoplockedm()execute(mp.lockedg.ptr(), false) // 该函数不会返回}// 我们不能从执行cgo调用的G中调度新的G,因为cgo调用正在使用M的g0栈if mp.incgo {throw("schedule: in cgo")}top:pp := mp.p.ptr()pp.preempt = false// 安全性检查:如果当前M处于自旋状态,本地运行队列应该为空// 在调用checkTimers之前执行此检查,因为checkTimers可能会调用goready// 将就绪的G放入本地运行队列if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {throw("schedule: spinning with local work")}// 找到可运行的G(findRunnable会阻塞直到有工作可用)gp, inheritTime, tryWakeP := findRunnable()// findRunnable可能收集了allp快照。快照仅在findRunnable内部需要,这里清除它// 以便GC可以回收该slicemp.clearAllpSnapshot()// 如果即将调度一个非普通G(如GCworker或tracereader),需要唤醒一个P(如果有的话)if tryWakeP {wakep()}// 如果G被锁定到某个M,则将当前P交给该锁定的M,然后阻塞等待新的Pif gp.lockedm != 0 {startlockedm(gp)goto top}// 执行G(该函数不会返回)execute(gp, inheritTime)
}
3.schedule中的findrunnable函数
// 查找可运行的goroutine执行
// 优先尝试从其他P窃取工作,或从本地/全局队列获取,或轮询网络
// tryWakeP表示返回的goroutine是非正常的(如GC工作线程、追踪读取器),调用者需要尝试唤醒P
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {mp := getg().m// 此处与handoffp中的条件需保持一致:如果findrunnable会返回可运行的G,handoffp必须启动一个M
top:// 可能已收集allp快照。快照仅在每次循环迭代时需要。清空快照以便GC回收切片mp.clearAllpSnapshot()pp := mp.p.ptr()// 如果处于gcwaitting状态 将当前m暂停 重新进行查找if sched.gcwaiting.Load() {gcstopm()goto top}if pp.runSafePointFn != 0 {runSafePointFn()}// now和pollUntil为后续工作窃取保存,可能窃取定时器// 在now到执行工作窃取期间不能阻塞,以确保这些数值相关now, pollUntil, _ := pp.timers.check(0, nil)// 尝试调度追踪读取器if traceEnabled() || traceShuttingDown() {gp := traceReader()if gp != nil {trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, true}}// 尝试调度GC工作线程if gcBlackenEnabled != 0 {gp, tnow := gcController.findRunnableGCWorker(pp, now)if gp != nil {return gp, false, true}now = tnow}// 偶尔检查全局可运行队列以确保公平性// 否则两个goroutine可能通过不断重启彼此完全占用本地队列if pp.schedtick%61 == 0 && !sched.runq.empty() {lock(&sched.lock)gp := globrunqget()unlock(&sched.lock)if gp != nil {return gp, false, false}}// 唤醒终结器Gif fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {if gp := wakefing(); gp != nil {ready(gp, 0, true)}}// 唤醒一个或多个清理Gif gcCleanups.needsWake() {gcCleanups.wake()}if *cgo_yield != nil {asmcgocall(*cgo_yield, nil)}// 本地运行队列if gp, inheritTime := runqget(pp); gp != nil {return gp, inheritTime, false}// 全局运行队列if !sched.runq.empty() {lock(&sched.lock)gp, q := globrunqgetbatch(int32(len(pp.runq)) / 2)unlock(&sched.lock)if gp != nil {if runqputbatch(pp, &q); !q.empty() {throw("Couldn't put Gs into empty local runq")}return gp, false, false}}// 网络轮询// 该netpoll是工作窃取前的优化操作// 如果没有等待者或线程已阻塞在netpoll中,可以安全跳过// 若与阻塞线程存在逻辑竞争(如已返回但未设置lastpoll),后续仍会处理// 为避免多核机器内核争用,每次仅允许一个线程进行轮询if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 && sched.pollingNet.Swap(1) == 0 {list, delta := netpoll(0)sched.pollingNet.Store(0)if !list.empty() { // 非阻塞gp := list.pop()injectglist(&list)netpollAdjustWaiters(delta)trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}}// 自旋线程:从其他P窃取工作// 自旋线程数量限制为忙碌P数量的一半// 这是为了防止GOMAXPROCS>>1但程序并行度低时的CPU过载if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {if !mp.spinning {mp.becomeSpinning()}gp, inheritTime, tnow, w, newWork := stealWork(now)if gp != nil {// 成功窃取return gp, inheritTime, false}if newWork {// 可能有新的定时器或GC工作,重启循环goto top}now = tnowif w != 0 && (pollUntil == 0 || w < pollUntil) {// 更早的定时器需要等待pollUntil = w}}// 没有工作可做// 如果处于GC标记阶段且有安全扫描/染色对象的工作,则运行空闲时间标记而非放弃Pif gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())if node != nil {pp.gcMarkWorkerMode = gcMarkWorkerIdleModegp := node.gp.ptr()trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}gcController.removeIdleMarkWorker()}// WASM平台专用逻辑// 如果回调返回且没有其他goroutine唤醒,则唤醒事件处理goroutine// 该goroutine会暂停执行直到回调被触发gp, otherReady := beforeIdle(now, pollUntil)if gp != nil {trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}if otherReady {goto top}// 释放P前获取allp快照,该切片可能在不再阻塞安全点时被修改// 不需要快照内容因为直到cap(allp)都是不可变的// 通过mp.clearAllpSnapshot(在schedule中)和每次循环迭代后清除快照allpSnapshot := mp.snapshotAllp()// 同时快照掩码。值变化可以接受,但长度不能在我们处理时变化idlepMaskSnapshot := idlepMasktimerpMaskSnapshot := timerpMask// 释放P并阻塞lock(&sched.lock)if sched.gcwaiting.Load() || pp.runSafePointFn != 0 {unlock(&sched.lock)goto top}if !sched.runq.empty() {gp, q := globrunqgetbatch(int32(len(pp.runq)) / 2)unlock(&sched.lock)if gp == nil {throw("global runq empty with non-zero runqsize")}if runqputbatch(pp, &q); !q.empty() {throw("Couldn't put Gs into empty local runq")}return gp, false, false}if !mp.spinning && sched.needspinning.Load() == 1 {// 参考下方"Delicate dance"注释mp.becomeSpinning()unlock(&sched.lock)goto top}if releasep() != pp {throw("findrunnable: wrong p")}now = pidleput(pp, now)unlock(&sched.lock)// 精密的舞蹈:线程从自旋状态转为非自旋状态时,可能与新工作提交并发// 必须先减少nmspinning计数,再通过StoreLoad内存屏障检查所有源// 若顺序颠倒,其他线程可能在我们检查完所有源后提交工作但之前已减少nmspinning// 导致无人唤醒线程执行工作//// 适用于以下工作源:// * 加入全局或P本地运行队列的goroutine// * P本地定时器堆的新/修改定时器// * 空闲优先级的GC工作(除非golang.org/issue/19112)//// 如果发现新工作,需要恢复m.spinning状态以唤醒新工作线程// (因为可能有多个饥饿的goroutine)//// 但若发现新工作后又观察到没有空闲P(在此处或resetspinning中),则存在问题// 我们可能与上方非自旋M的释放P并发竞争,导致P进入空闲状态// 这会丢失工作守恒(空闲P时仍有可运行工作),极端情况下可能导致死锁//// 通过sched.needspinning与非自旋M同步// 当非自旋M准备释放P时,若发现needspinning被设置则中止释放并转为自旋// 若没有并发竞争且系统完全负载,则无需自旋线程,下一个自然转为自旋的线程会清除标志// 另见文件顶部的"Worker thread parking/unparking"注释wasSpinning := mp.spinningif mp.spinning {mp.spinning = falseif sched.nmspinning.Add(-1) < 0 {throw("findrunnable: negative nmspinning")}// 注意正确性要求:只有最后一个从自旋转为非自旋的线程需要重新检查// 但运行时存在一些nmspinning的临时增加未通过此路径减少的情况// 因此必须保守地对所有自旋线程执行检查// 参考https://go.dev/issue/43997// 再次检查全局和P运行队列lock(&sched.lock)if !sched.runq.empty() {pp, _ := pidlegetSpinning(0)if pp != nil {gp, q := globrunqgetbatch(int32(len(pp.runq)) / 2)unlock(&sched.lock)if gp == nil {throw("global runq empty with non-zero runqsize")}if runqputbatch(pp, &q); !q.empty() {throw("Couldn't put Gs into empty local runq")}acquirep(pp)mp.becomeSpinning()return gp, false, false}}unlock(&sched.lock)pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)if pp != nil {acquirep(pp)mp.becomeSpinning()goto top}// 再次检查空闲优先级GC工作pp, gp := checkIdleGCNoP()if pp != nil {acquirep(pp)mp.becomeSpinning()// 运行空闲工作线程pp.gcMarkWorkerMode = gcMarkWorkerIdleModetrace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}// 最后检查定时器创建/过期是否与自旋状态转换并发// 注意此处不能使用checkTimers因为它可能分配内存,而我们没有活动P时不允许分配pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)}// 此时不再需要allp快照,但没有P时不能清除(需写屏障)// 轮询网络直到下一个定时器if netpollinited() && (netpollAnyWaiters() || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 {sched.pollUntil.Store(pollUntil)if mp.p != 0 {throw("findrunnable: netpoll with p")}if mp.spinning {throw("findrunnable: netpoll with spinning")}delay := int64(-1)if pollUntil != 0 {if now == 0 {now = nanotime()}delay = pollUntil - nowif delay < 0 {delay = 0}}if faketime != 0 {// 使用假时间时直接轮询delay = 0}list, delta := netpoll(delay) // 阻塞直到有新工作// 刷新时间戳(可能阻塞后)now = nanotime()sched.pollUntil.Store(0)sched.lastpoll.Store(now)if faketime != 0 && list.empty() {// 使用假时间且无就绪工作时停止M// 当所有M停止时,checkdead会调用timejumpstopm()goto top}lock(&sched.lock)pp, _ := pidleget(now)unlock(&sched.lock)if pp == nil {injectglist(&list)netpollAdjustWaiters(delta)} else {acquirep(pp)if !list.empty() {gp := list.pop()injectglist(&list)netpollAdjustWaiters(delta)trace := traceAcquire()casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0)traceRelease(trace)}return gp, false, false}if wasSpinning {mp.becomeSpinning()}goto top}} else if pollUntil != 0 && netpollinited() {pollerPollUntil := sched.pollUntil.Load()if pollerPollUntil == 0 || pollerPollUntil > pollUntil {netpollBreak()}}stopm()goto top
}
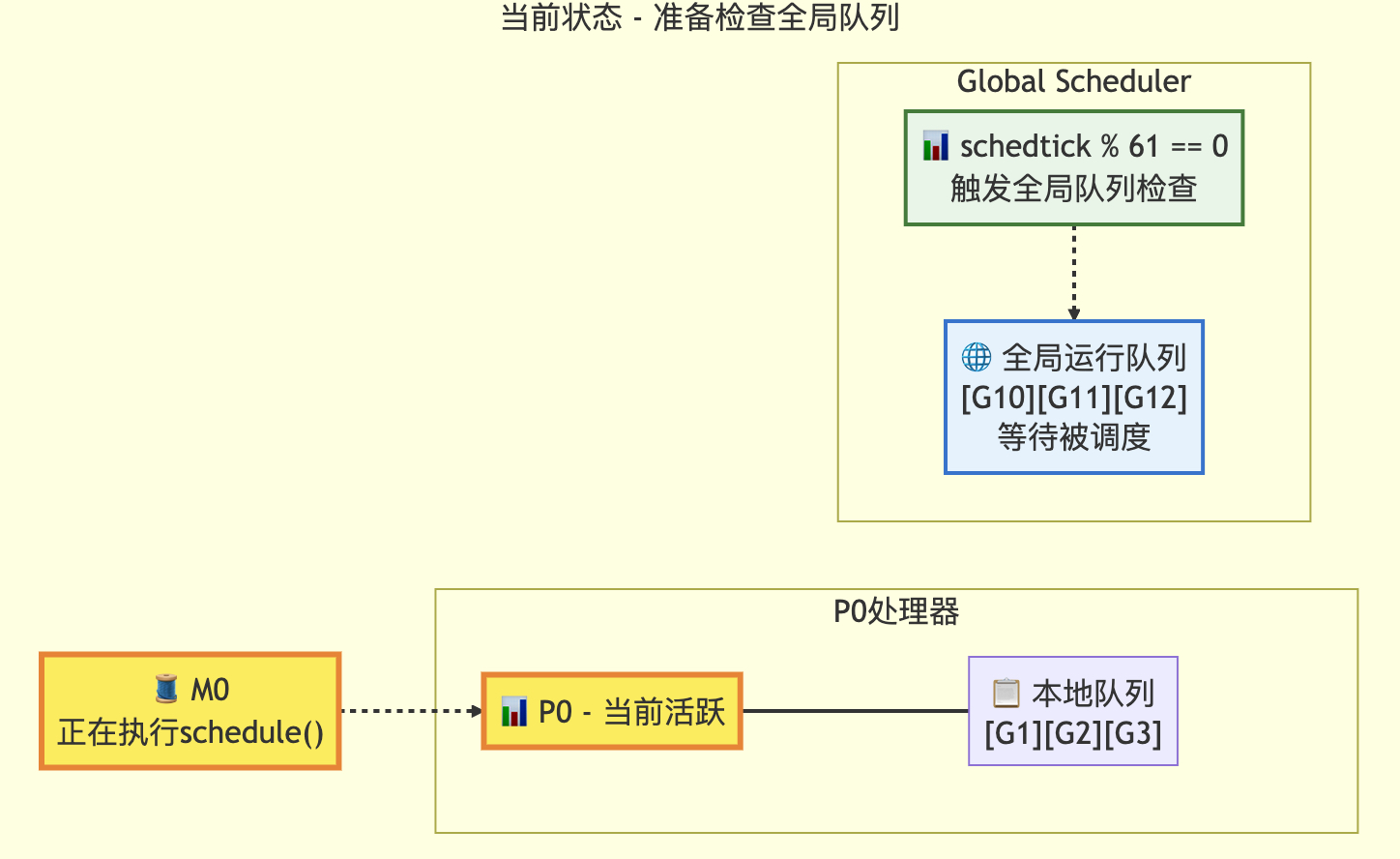
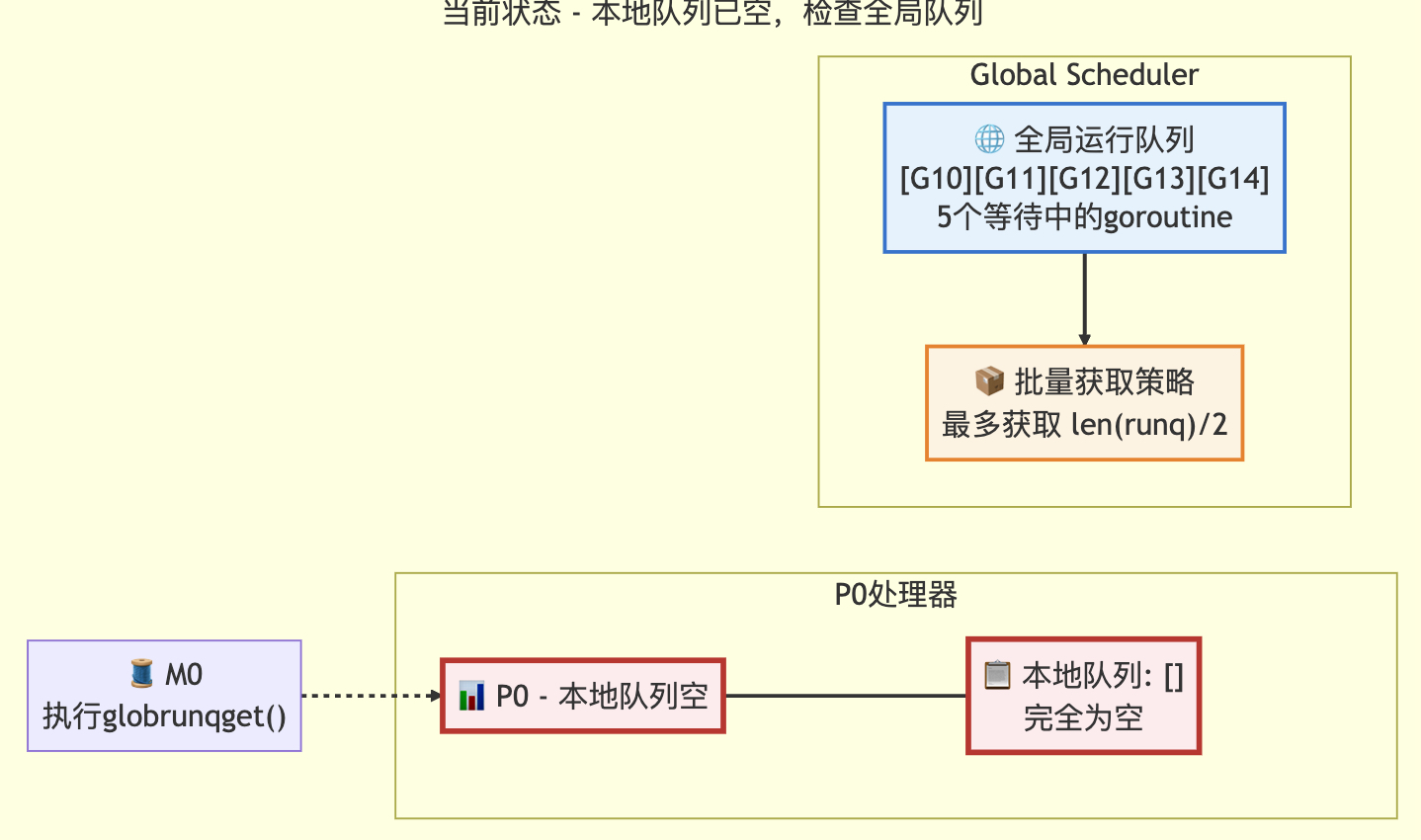
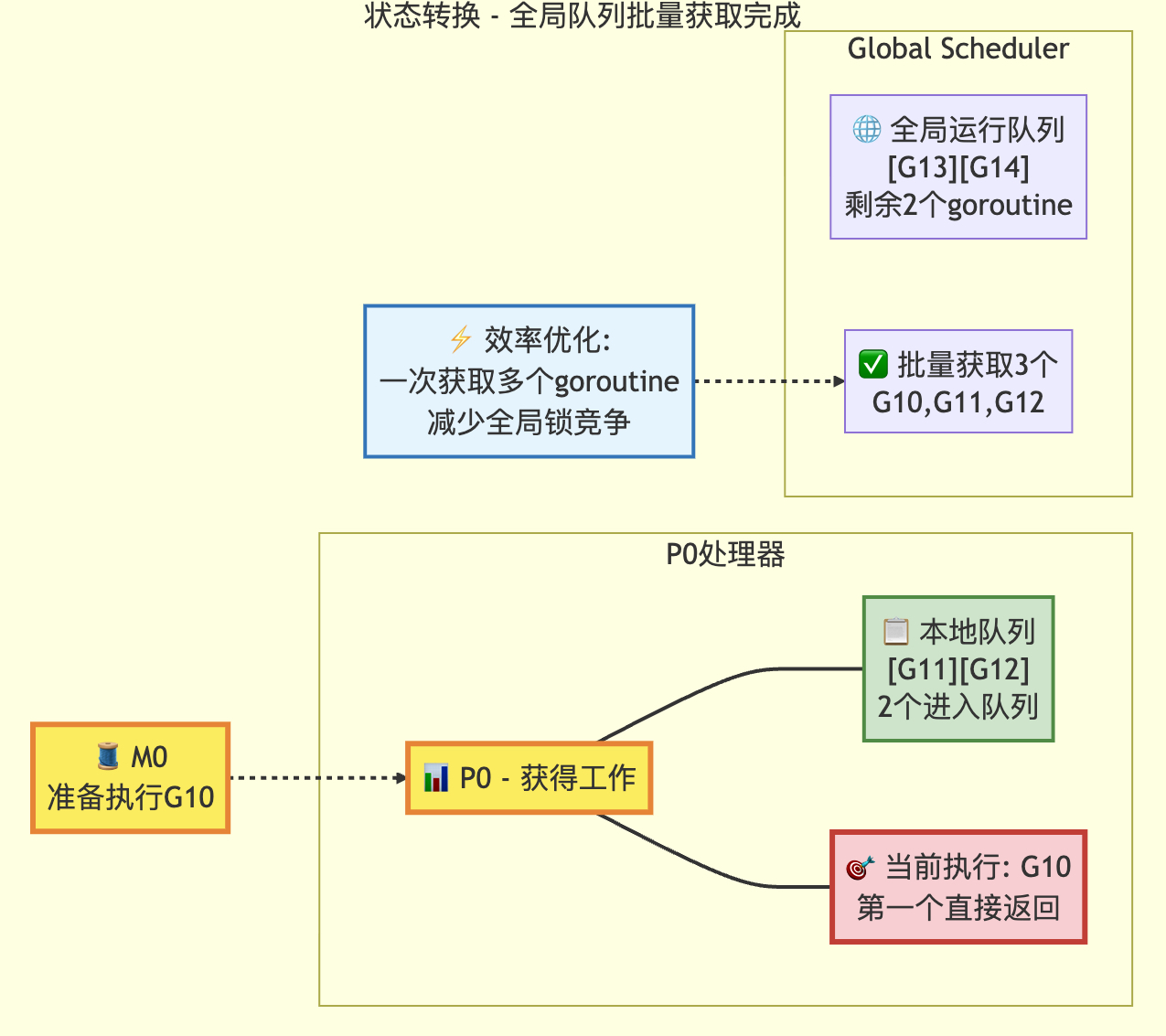
3.1 适当检查全局队列策略
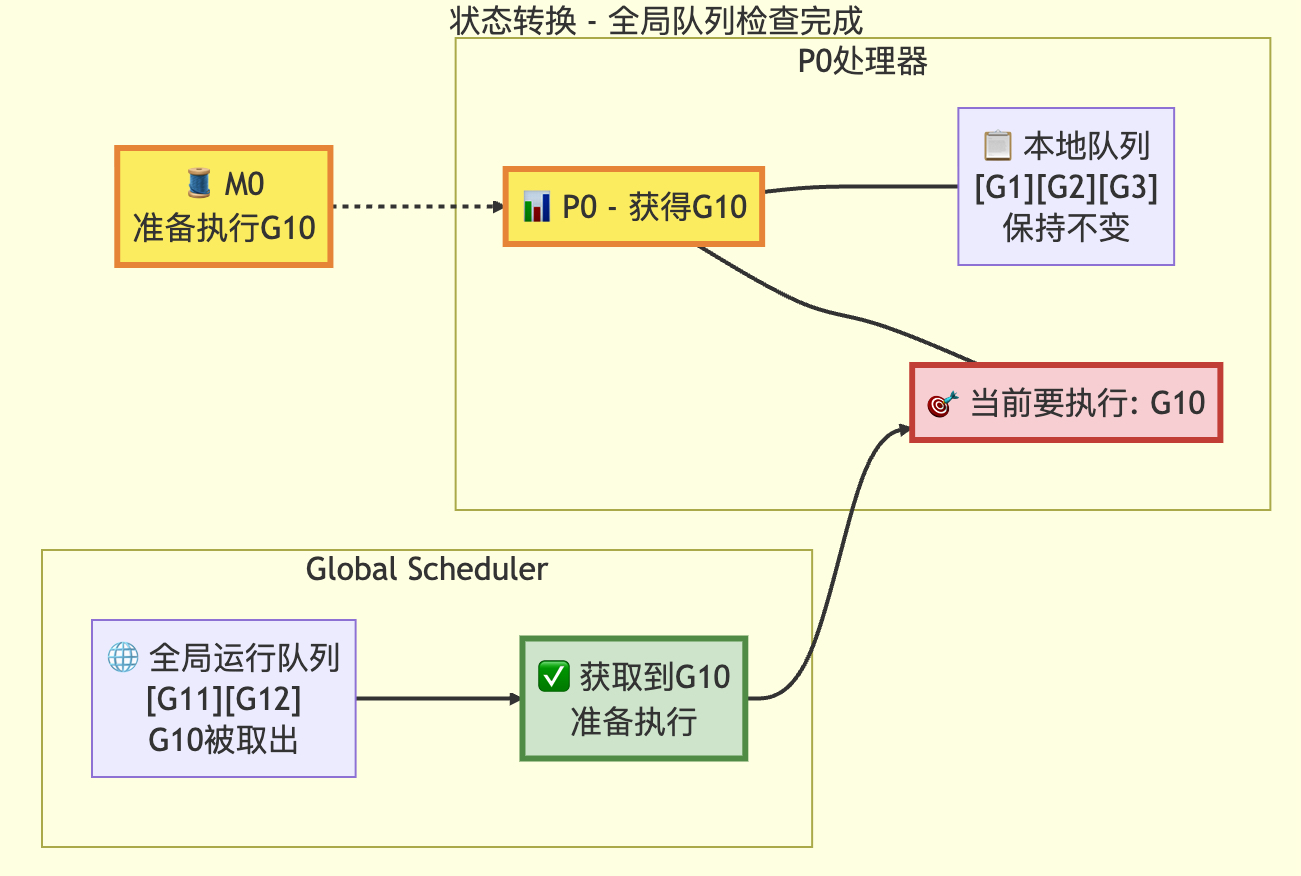
// 偶尔检查全局可运行队列以确保公平性// 否则两个goroutine可能通过不断重启彼此完全占用本地队列if pp.schedtick%61 == 0 && !sched.runq.empty() {lock(&sched.lock)gp := globrunqget()unlock(&sched.lock)if gp != nil {return gp, false, false}}// local runqif gp, inheritTime := runqget(pp); gp != nil {return gp, inheritTime, false}// global runqif !sched.runq.empty() {lock(&sched.lock)gp, q := globrunqgetbatch(int32(len(pp.runq)) / 2)unlock(&sched.lock)if gp != nil {if runqputbatch(pp, &q); !q.empty() {throw("Couldn't put Gs into empty local runq")}return gp, false, false}}这是findRunnable函数的一部分,其中检查全局队列,每61次检查全局队列,并取一个g,日常使用本地队列获取g。
定次数检查全局队列的状态转换图
转换前
转换后
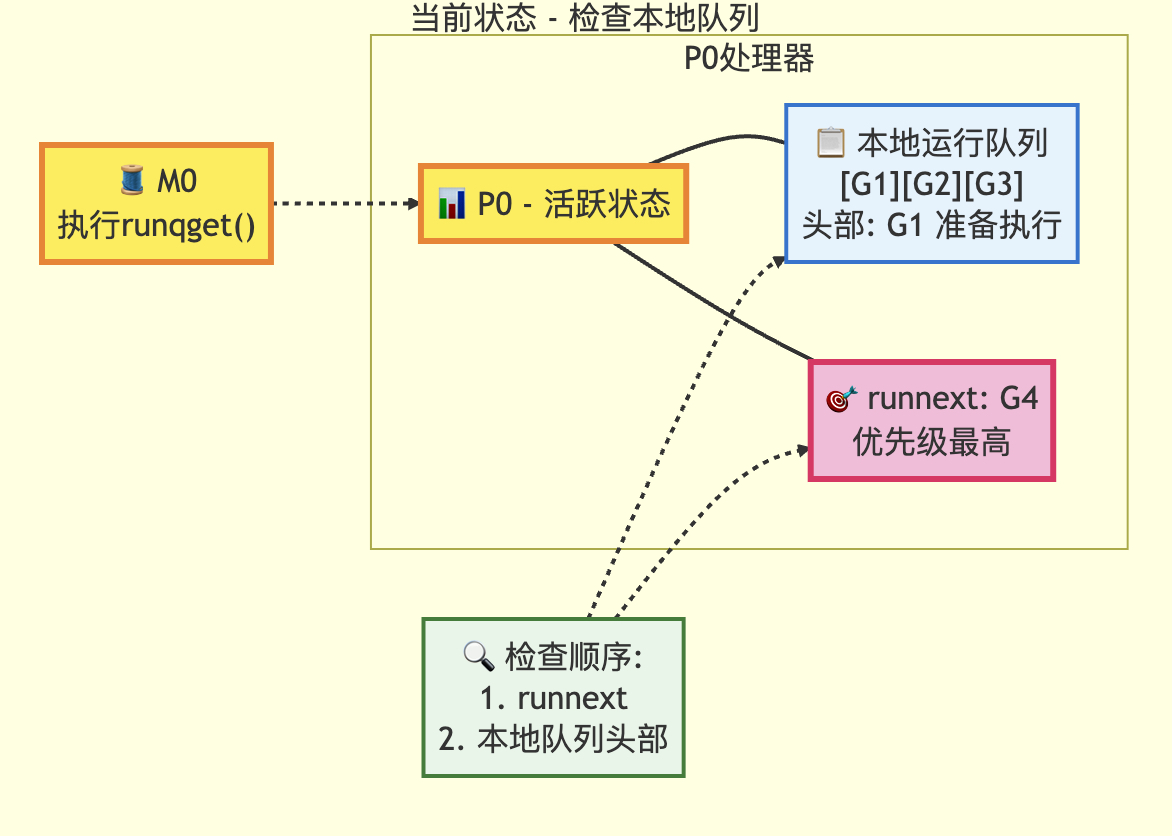
检查本地队列的状态转换图
// 从本地可运行队列获取Goroutine
// 如果 inheritTime 为 true,gp 应该继承当前时间片中剩余的时间
// 否则,它应该开始一个新的时间片
// 该函数仅由当前P(逻辑处理器)的拥有者执行
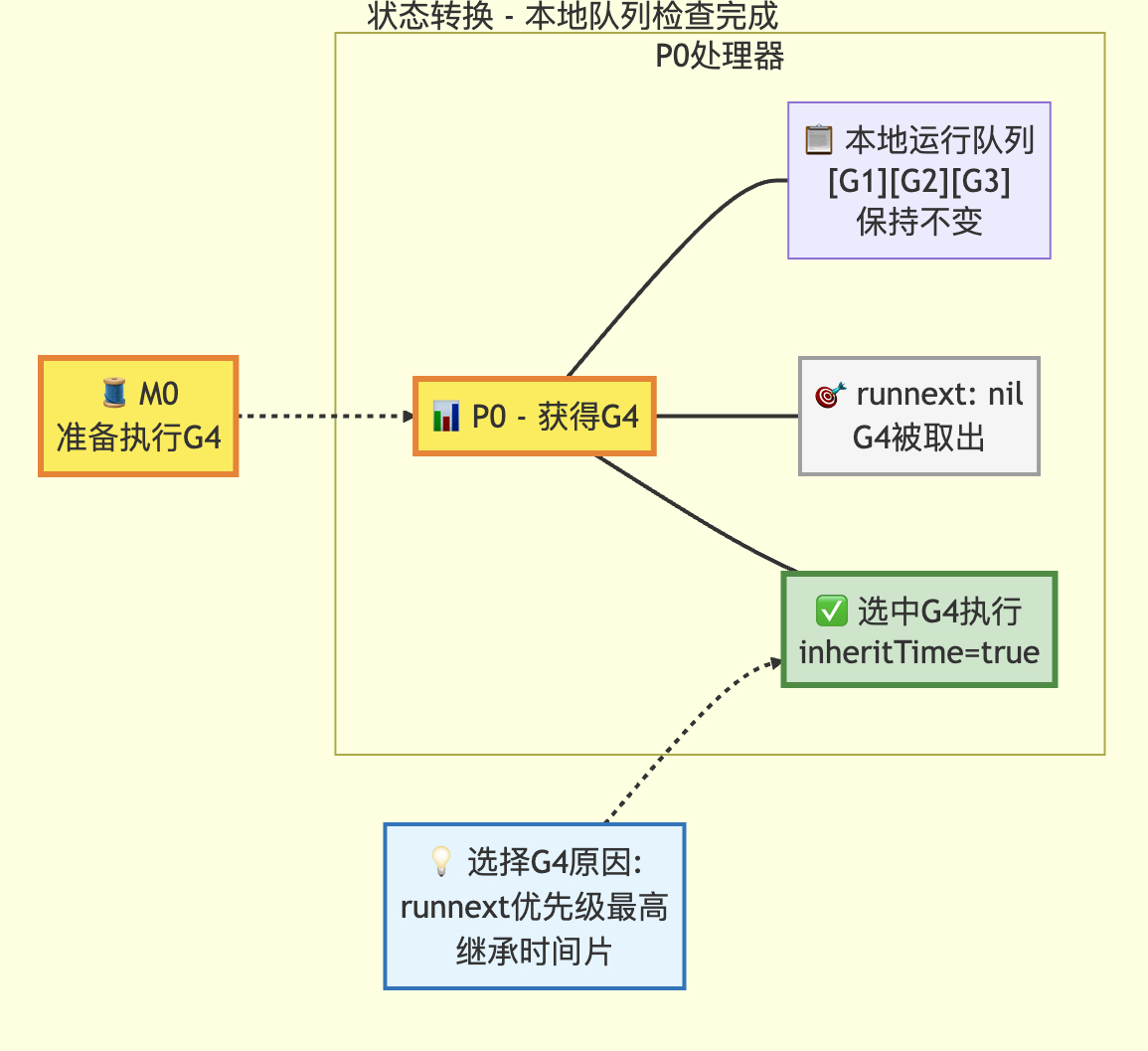
func runqget(pp *p) (gp *g, inheritTime bool) {// 如果存在 runnext,则优先获取该Goroutinenext := pp.runnext// 如果 runnext 不为0且CAS(比较并交换)操作成功,说明该Goroutine未被其它P抢占// 注意:若CAS失败,可能是其它P将runnext置为0,无需重试// 因为只有当前P能将runnext设置为非0值if next != 0 && pp.runnext.cas(next, 0) {return next.ptr(), true}// 无限循环尝试从环形队列中获取Goroutinefor {// 原子读取队列头指针(load-acquire语义:与其它消费者同步)h := atomic.LoadAcq(&pp.runqhead)t := pp.runqtail// 如果队列为空(尾指针等于头指针),返回nilif t == h {return nil, false}// 计算Goroutine在环形队列中的索引// 并获取对应的Goroutine指针gp = pp.runq[h%uint32(len(pp.runq))].ptr()// 原子更新头指针(cas-release语义:提交消耗,保证操作可见性)// 若成功,则返回获取到的Goroutineif atomic.CasRel(&pp.runqhead, h, h+1) {return gp, false}}
}
队列使用环形队列的方式进行存储,首先检查runnext优先级g是否存在(runnext只能被当前p置为0);然后检查本地队列,获取其中的g,并且返回。
转换前
转换后
检查全局队列状态转移图
// Try get a batch of G's from the global runnable queue.
// sched.lock must be held.
func globrunqgetbatch(n int32) (gp *g, q gQueue) {assertLockHeld(&sched.lock) //必须拥有全局队列锁if sched.runq.size == 0 {return}n = min(n, sched.runq.size, sched.runq.size/gomaxprocs+1)gp = sched.runq.pop()n--for ; n > 0; n-- {gp1 := sched.runq.pop()q.pushBack(gp1)}return
}执行到本函数时,前提是上一步骤本地队列为空的情况下,将从全局队列中取g,g的数量为给定的n(输入为本地队列长度的一半),全局队列长度,全局队列长度/最大设置p数量 + 1的最小值。
// runqputbatch tries to put all the G's on q on the local runnable queue.
// If the local runq is full the input queue still contains unqueued Gs.
// Executed only by the owner P.
func runqputbatch(pp *p, q *gQueue) {if q.empty() {return}h := atomic.LoadAcq(&pp.runqhead)t := pp.runqtailn := uint32(0)for !q.empty() && t-h < uint32(len(pp.runq)) {gp := q.pop()pp.runq[t%uint32(len(pp.runq))].set(gp)t++n++}// 随机化处理 打乱g加入队列的顺序 防止饥饿等问题if randomizeScheduler {// 计算偏移量off := func(o uint32) uint32 {return (pp.runqtail + o) % uint32(len(pp.runq))}for i := uint32(1); i < n; i++ {j := cheaprandn(i + 1)pp.runq[off(i)], pp.runq[off(j)] = pp.runq[off(j)], pp.runq[off(i)]}}atomic.StoreRel(&pp.runqtail, t)return
}将从全局队列获取的g,尽可能的存放入本地p队列当中。
转换前
转换后
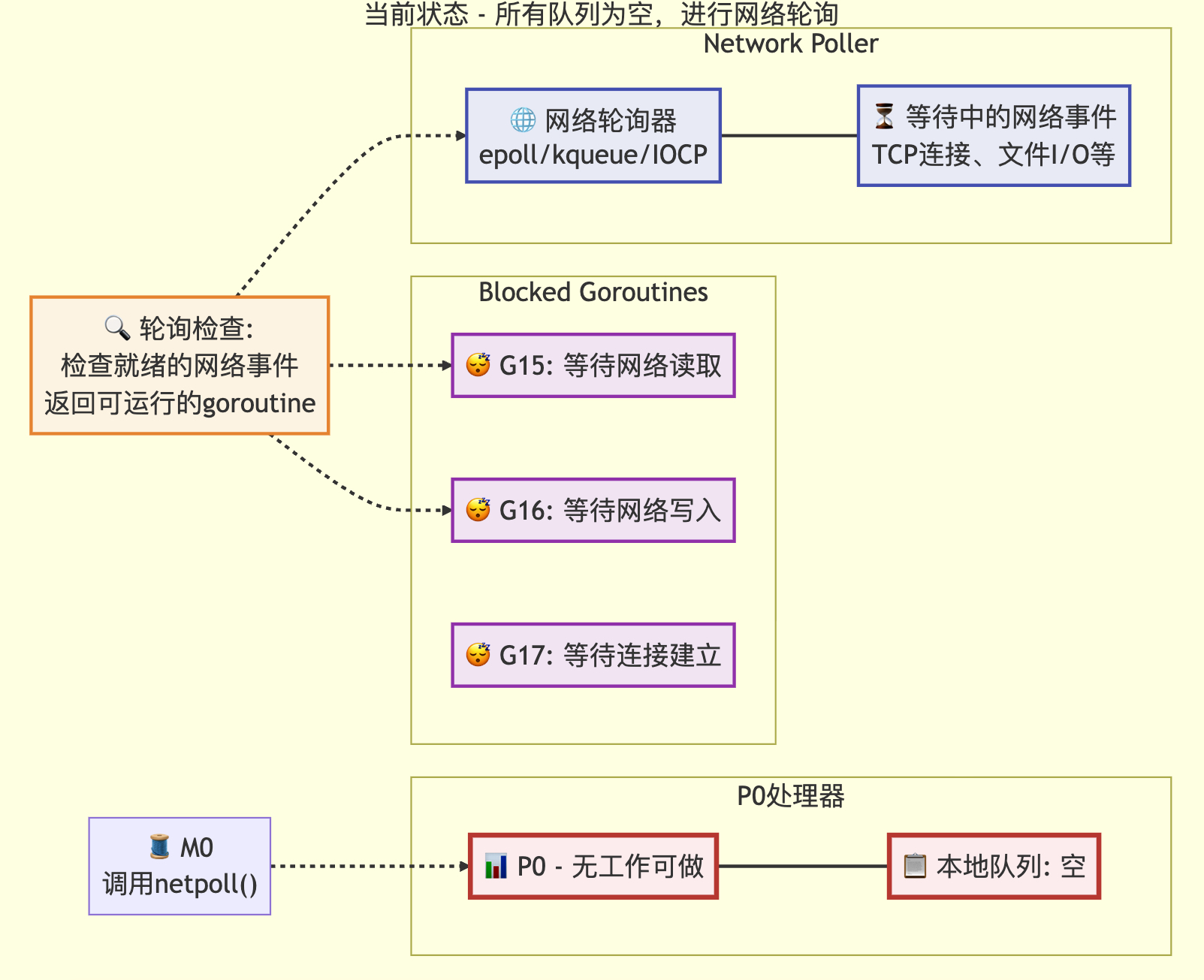
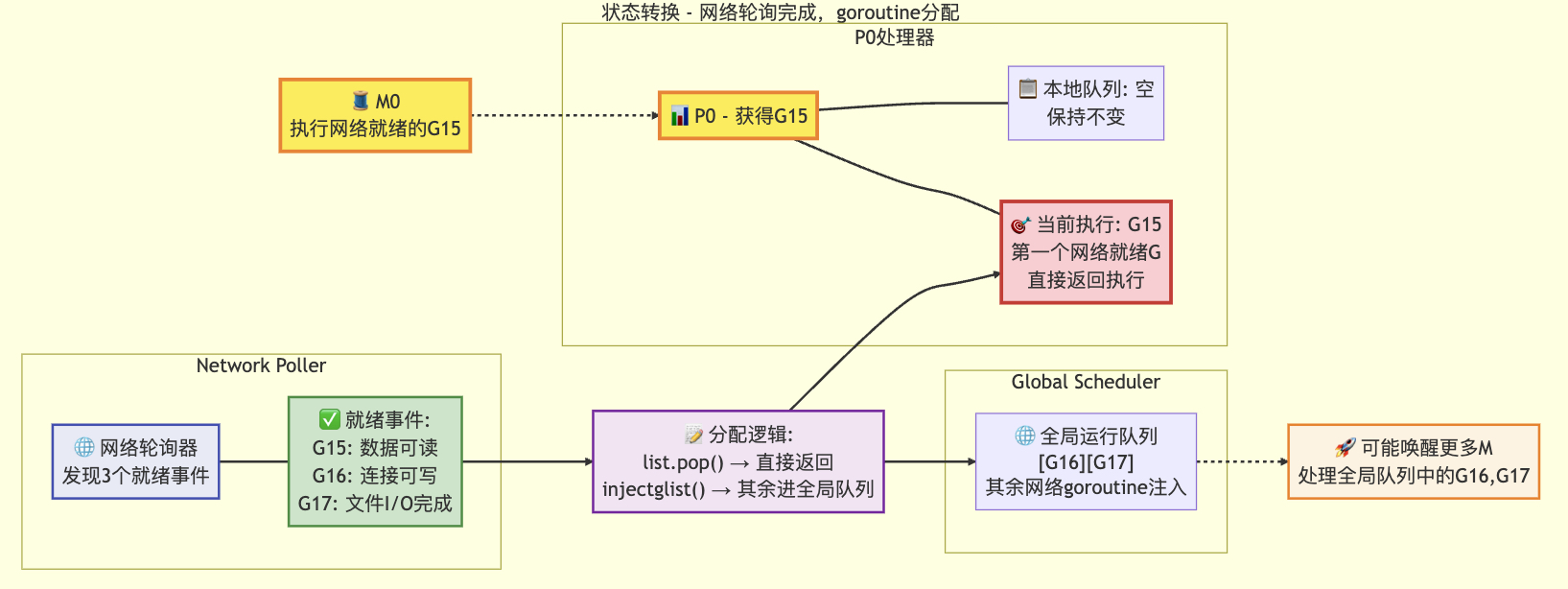
3.2 网络轮询的处理
// 网络轮询
// 此netpoll仅作为优化措施,用于在工作窃取之前尝试获取网络事件。
// 如果没有等待者或线程已阻塞在netpoll中,可以安全地跳过此步骤。
// 当与阻塞线程存在逻辑竞争时(例如该线程已从netpoll返回但尚未设置lastpoll),
// 本线程仍会执行阻塞式netpoll操作。
// 为避免多核机器上的内核争用,我们确保同一时间只有一个线程在进行轮询。
if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 && sched.pollingNet.Swap(1) == 0 {list, delta := netpoll(0) // 非阻塞式轮询sched.pollingNet.Store(0) // 重置轮询状态标志if !list.empty() {gp := list.pop() // 获取等待的goroutineinjectglist(&list) // 将goroutine列表注入运行队列netpollAdjustWaiters(delta) // 调整等待计数trace := traceAcquire()// 原子状态转换:从等待状态转为可运行状态casgstatus(gp, _Gwaiting, _Grunnable)if trace.ok() {trace.GoUnpark(gp, 0) // 跟踪goroutine解除阻塞traceRelease(trace) // 释放跟踪资源}return gp, false, false // 返回可运行的goroutine}
}func injectglist(glist *gList) {if glist.empty() {return}lock(&sched.lock)var n intfor n = 0; !glist.empty(); n++ {gp := glist.pop()casgstatus(gp, _Gwaiting, _Grunnable)globrunqput(gp) // 其余goroutine放入全局队列}unlock(&sched.lock)// 尝试启动新的M来处理这些goroutinefor ; n != 0 && sched.npidle.Load() != 0; n-- {startm(nil, false, false)}
}
状态转移前
状态转移后
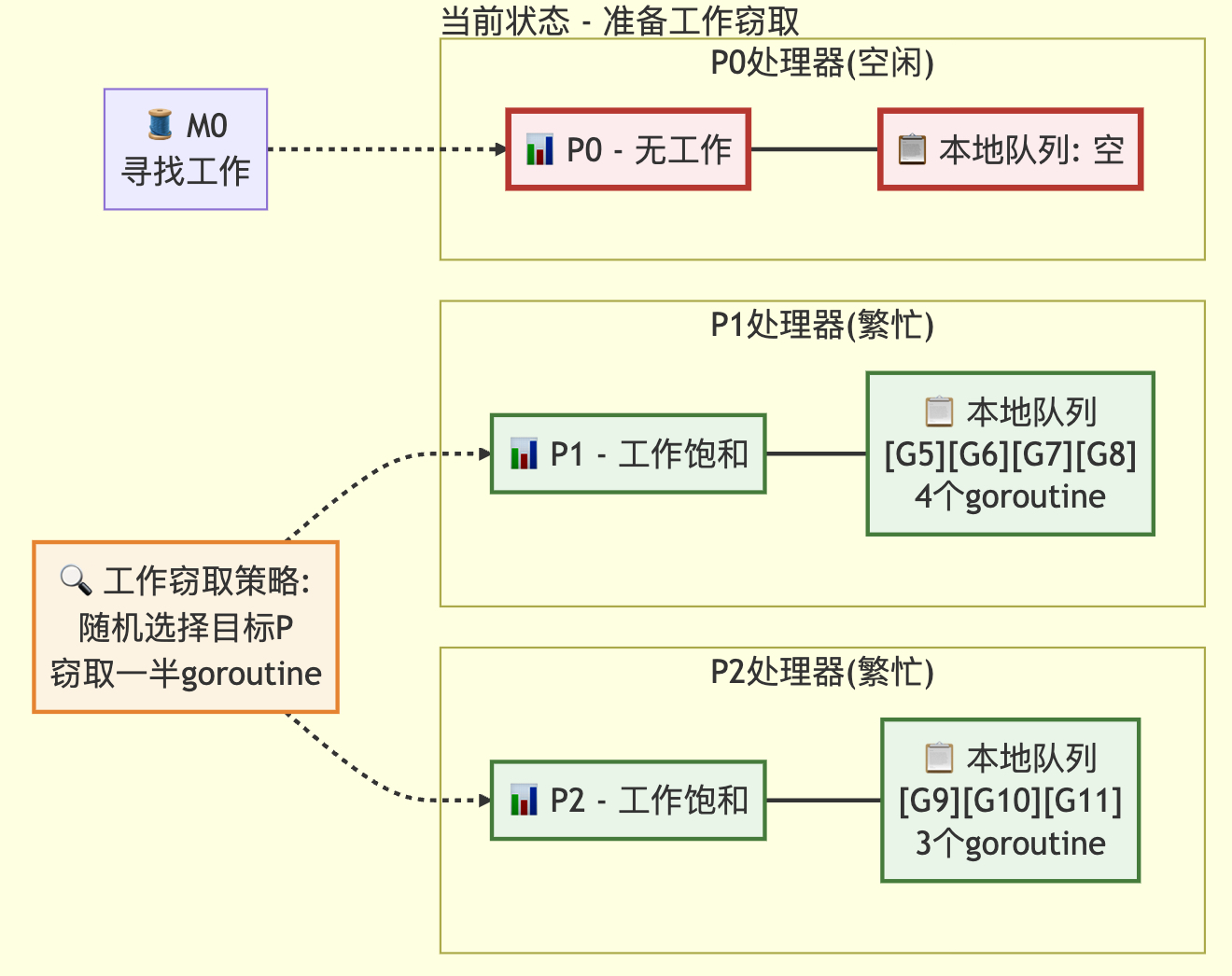
3.3 窃取其他p的本地g操作
// 自旋的M:从其他P偷取工作
//
// 限制自旋M的数量不超过忙碌P的一半。
// 这是为了防止当GOMAXPROCS远大于1但程序并行度较低时
// 出现过高的CPU消耗。
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {if !mp.spinning {mp.becomeSpinning()}gp, inheritTime, tnow, w, newWork := stealWork(now)if gp != nil {// 成功偷取工作return gp, inheritTime, false}if newWork {// 可能有新的定时器或GC工作;需要重新启动以发现goto top}now = tnowif w != 0 && (pollUntil == 0 || w < pollUntil) {// 有更早的定时器需要等待pollUntil = w}
}
核心操作函数
在本地p队列为空,随机获取其他p的g(最大偷取数量为目标p队列长度的一半),持有目标p的runq.lock;在本地队列p为空且定时器堆也为空,则获取其他p的定时器来获取关联g,持有目标p的mu。
// stealWork 尝试从任何P中偷取可运行的goroutine或定时器
//
// 如果newWork为true,表示可能有新工作被就绪
//
// 如果now不为0,则表示传入的当前时间。stealWork返回传入的时间或
// 当now为0时返回当前时间
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {pp := getg().m.p.ptr()ranTimer := falseconst stealTries = 4for i := 0; i < stealTries; i++ {stealTimersOrRunNextG := i == stealTries-1for enum := stealOrder.start(cheaprand()); !enum.done(); enum.next() {if sched.gcwaiting.Load() {// GC工作可能已就绪return nil, false, now, pollUntil, true}p2 := allp[enum.position()]if pp == p2 {continue}// 从p2偷取定时器。这个checkTimers调用是唯一可能持有// 其他P的定时器锁的地方。我们在这个循环的最后阶段检查// runnext之前先检查定时器,因为从其他P的runnext偷取// 应该是最后的选择,如果存在可偷取的定时器优先处理//// 我们只在其中一个偷取循环中检查定时器,因为now的值// 在这个循环中不会变化,多次检查相同时间点的定时器// 可能浪费性能//// timerpMask告诉我们P是否可能拥有定时器。如果P不可能// 拥有定时器,则无需检查if stealTimersOrRunNextG && timerpMask.read(enum.position()) {tnow, w, ran := p2.timers.check(now, nil)now = tnowif w != 0 && (pollUntil == 0 || w < pollUntil) {pollUntil = w}if ran {// 运行定时器可能使任意数量的G就绪// 并将它们添加到本P的本地运行队列中// 这会破坏runqsteal的假设(运行队列有足够空间)// 所以现在需要检查本P本地队列是否有G可运行if gp, inheritTime := runqget(pp); gp != nil {return gp, inheritTime, now, pollUntil, ranTimer}ranTimer = true}}// 如果p2处于空闲状态,无需尝试偷取if !idlepMask.read(enum.position()) {if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {return gp, false, now, pollUntil, ranTimer}}}}// 未找到可偷取的goroutine。不管怎样,运行定时器可能使// 某些goroutine就绪。指示需要等待的下一个定时器return nil, false, now, pollUntil, ranTimer
}
状态转移前
状态转移后
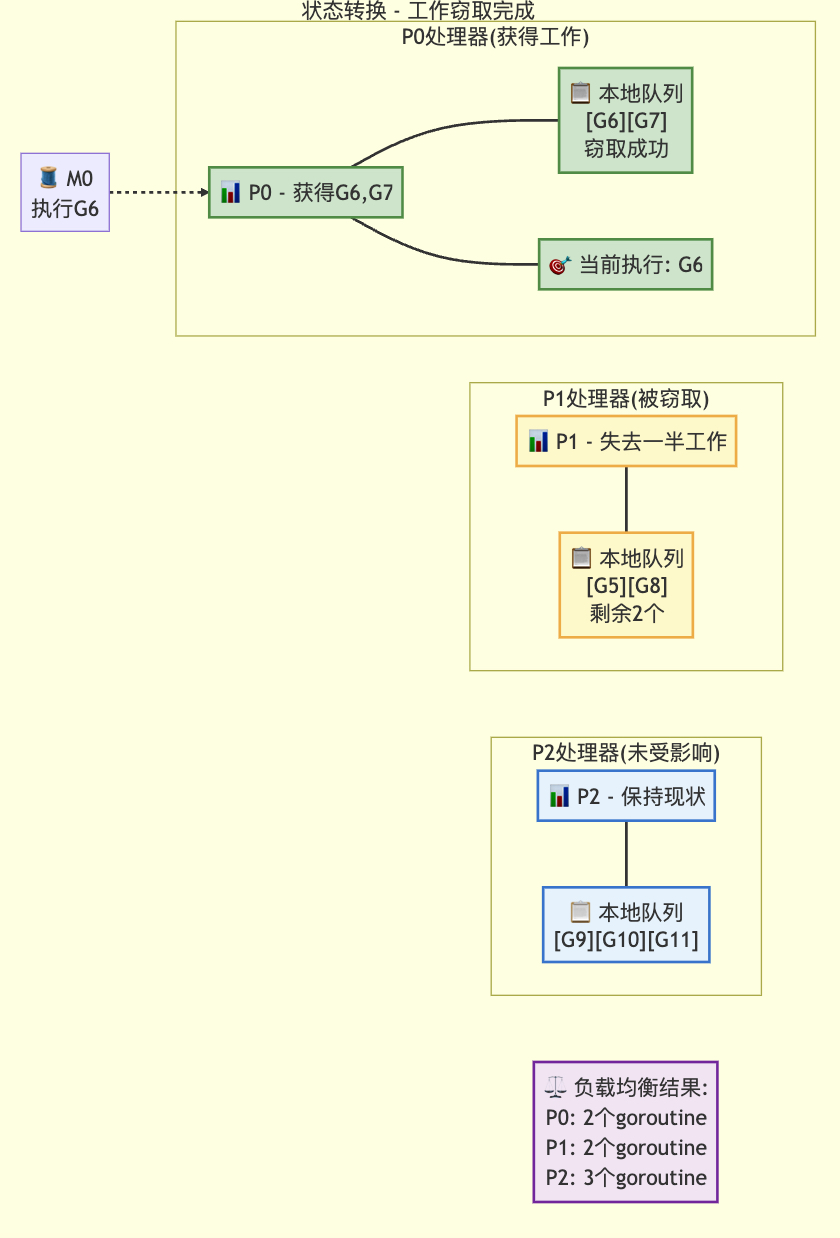
最后,当所有的工作都找不到可用的g来运行,就会休眠m,等待唤醒。
3.4 execute唤醒
// 将gp调度到当前M上运行
// 如果inheritTime为true,则gp继承当前时间片的剩余时间,否则开始新的时间片
// 此函数不会返回// 允许写屏障操作,因为该函数在多个位置获取P后立即调用
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {mp := getg().mif goroutineProfile.active {// 确保gp的堆栈信息已记录到goroutine profile中// 记录时保持goroutine profiler首次暂停世界时的状态tryRecordGoroutineProfile(gp, nil, osyield)}// 在进入_Grunning状态前为运行中的G绑定Mmp.curg = gpgp.m = mpgp.syncSafePoint = false // 清除可能由morestack设置的标志casgstatus(gp, _Grunnable, _Grunning) // 原子操作修改goroutine状态gp.waitsince = 0 // 清除等待时间戳gp.preempt = false // 清除抢占标志gp.stackguard0 = gp.stack.lo + stackGuard // 设置栈保护指针if !inheritTime {mp.p.ptr().schedtick++ // 时间片不继承时增加调度计数器}// 检查是否需要开启/关闭CPU profilerhz := sched.profilehzif mp.profilehz != hz {setThreadCPUProfiler(hz) // 设置线程CPU分析频率}trace := traceAcquire()if trace.ok() {trace.GoStart() // 启动追踪事件traceRelease(trace) // 释放追踪资源}gogo(&gp.sched) // 进入goroutine执行入口
}
状态转移前
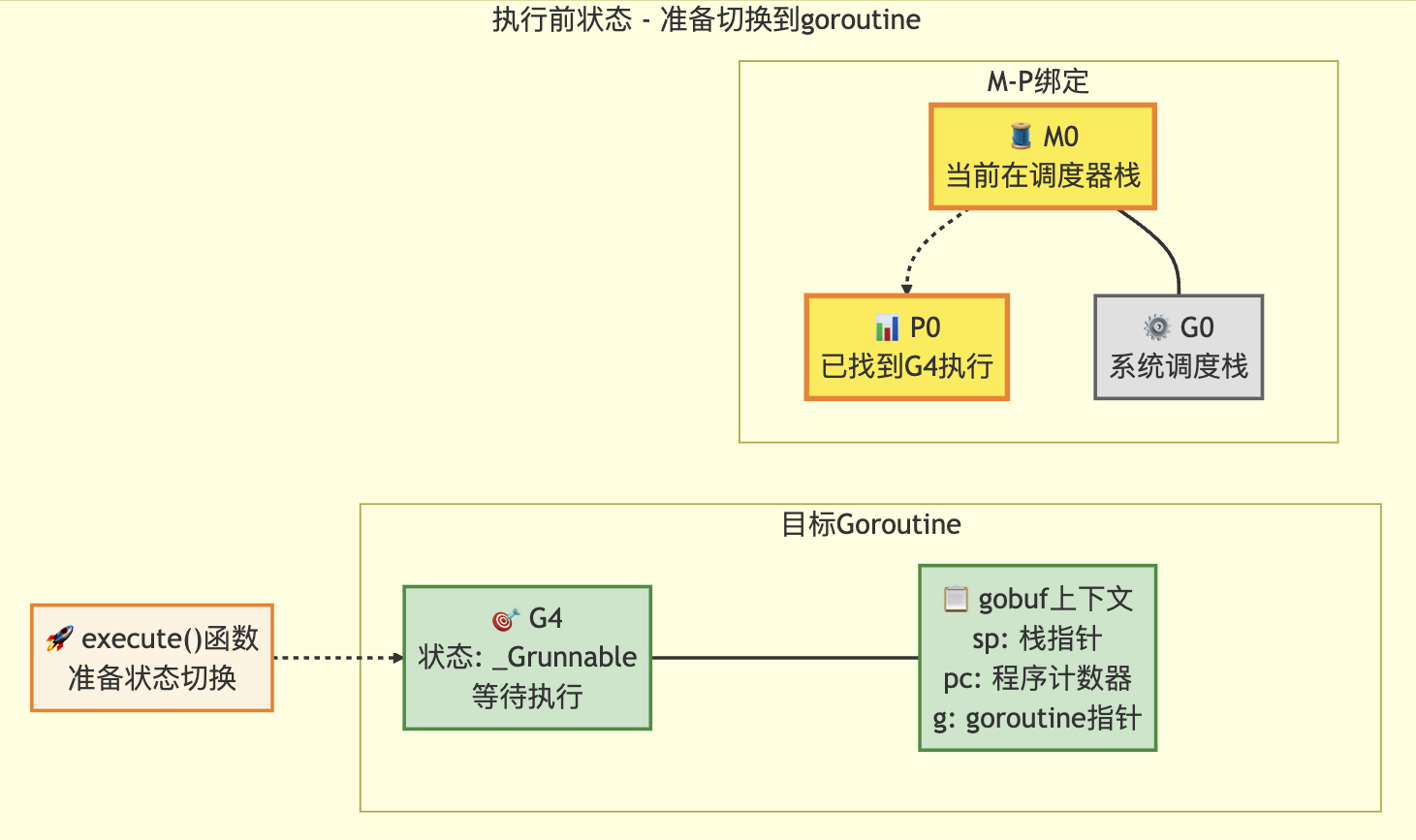
状态转移
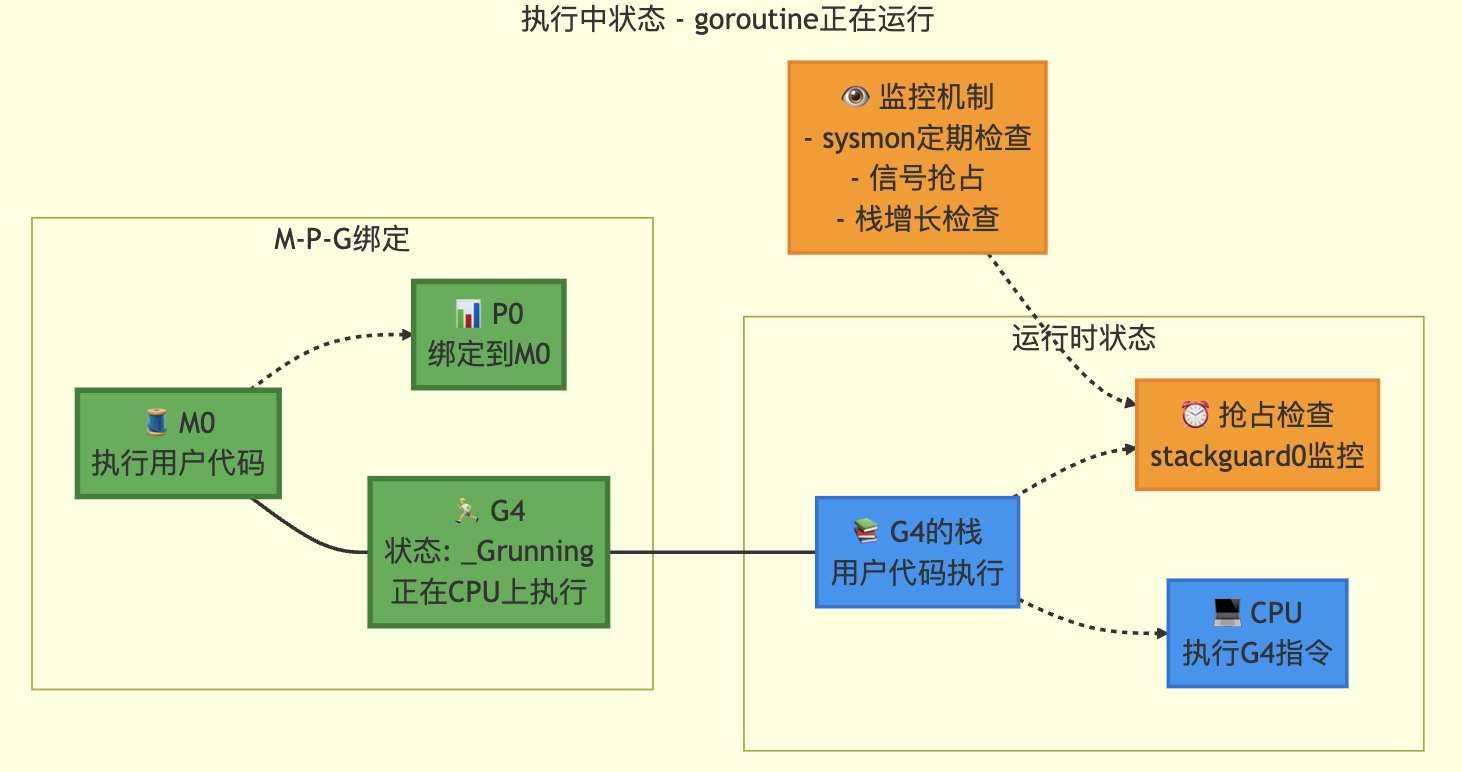
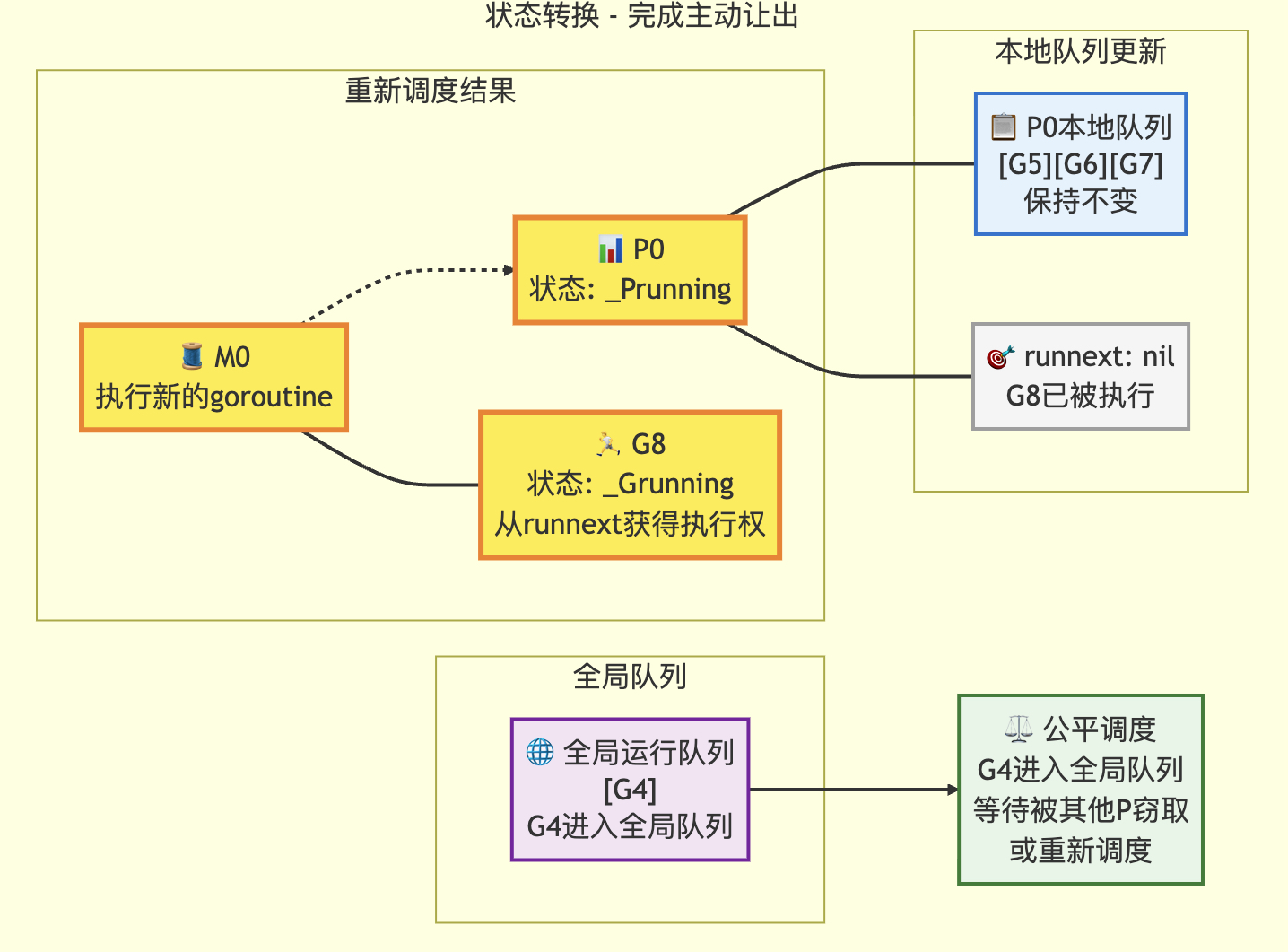
3.5 gosched 主动让出
// Gosched让出处理器,允许其他goroutine运行。该函数不会挂起当前goroutine,
// 因此当前goroutine会在后续自动恢复执行。
//
//go:nosplit // 编译器指令:禁止函数分割栈(保持原栈结构执行)
func Gosched() {// 检查是否有定时器需要处理(如超时事件)checkTimeouts()// 调用系统调用处理函数,将控制权交还调度器// mcall会切换到系统栈执行gosched_m函数mcall(gosched_m)
}// goschedImpl函数让出处理器,允许其他goroutine运行。preempted参数表示是否是被抢占的情况。
// 该函数不会挂起当前goroutine,执行会自动恢复。
func goschedImpl(gp *g, preempted bool) {// 获取追踪资源trace := traceAcquire()// 读取当前goroutine状态status := readgstatus(gp)// 验证当前状态是否为运行中状态(排除扫描状态)if status&^_Gscan != _Grunning {dumpgstatus(gp) // 打印状态信息用于调试throw("bad g status") // 状态异常时抛出错误}// 如果追踪可用,记录相关事件if trace.ok() {// 在状态转换前记录追踪事件,可能需要获取堆栈信息// 但转换后将不再拥有当前堆栈if preempted {trace.GoPreempt() // 抢占事件追踪} else {trace.GoSched() // 主动让出处理器的追踪}}// 原子操作将当前goroutine状态从运行中改为可运行casgstatus(gp, _Grunning, _Grunnable)// 释放追踪资源if trace.ok() {traceRelease(trace)}// 从当前M的绑定关系中解绑goroutinedropg()// 加锁操作lock(&sched.lock)// 将当前goroutine放入全局运行队列globrunqput(gp)// 解锁操作unlock(&sched.lock)// 如果主程序已启动,唤醒空闲的处理器if mainStarted {wakep()}// 调度器开始寻找下一个要运行的goroutineschedule()
}// Gosched函数在g0栈上的执行入口(被抢占后执行)
func gosched_m(gp *g) {// 调用核心实现,传入preempted=false表示主动让出而非被抢占goschedImpl(gp, false)
}
转移前
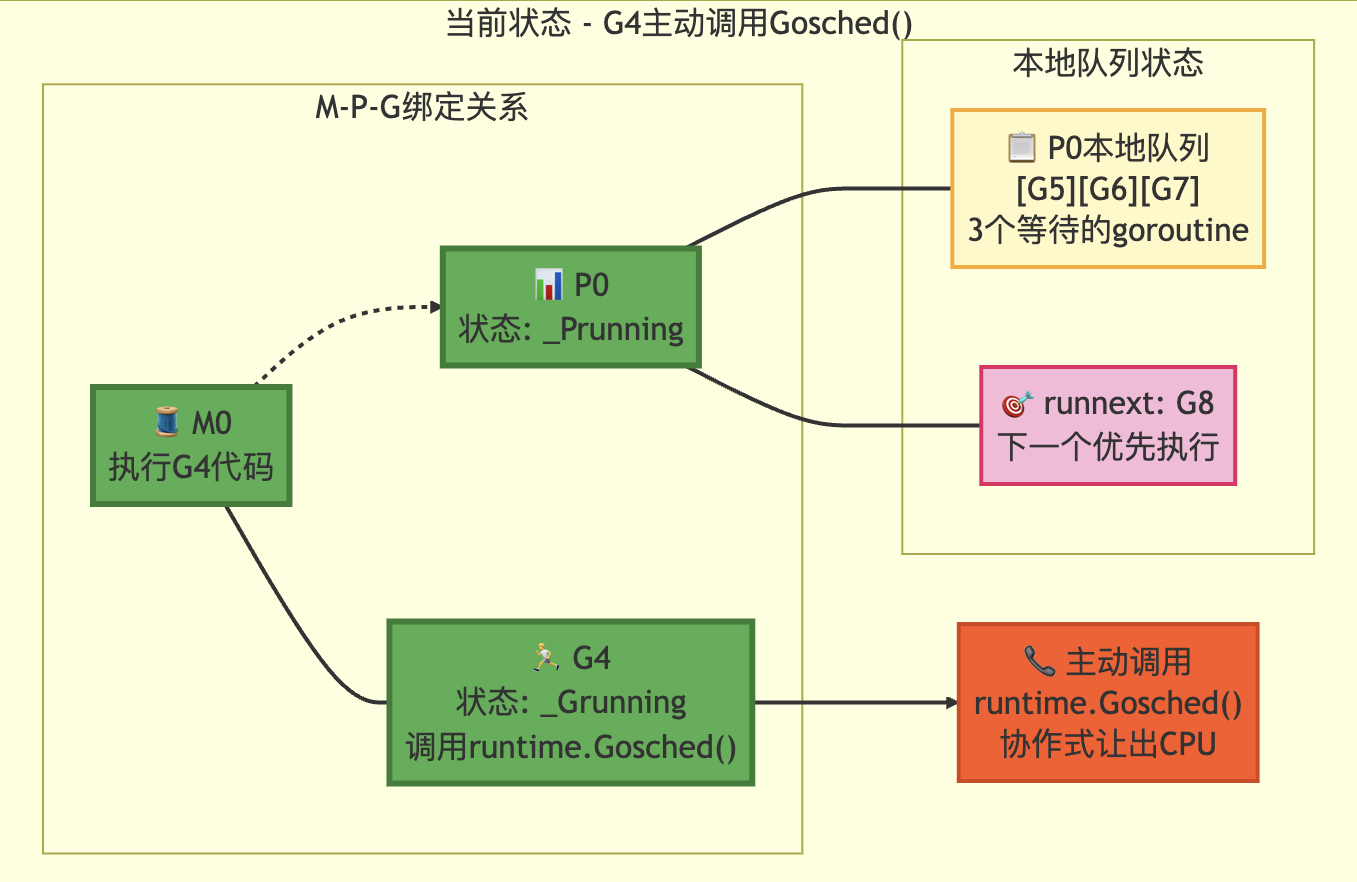
转移后
3.6 系统调用
// 当前goroutine g 即将进入系统调用
// 记录其不再占用CPU的状态
// 此函数仅由Go系统调用库和cgo调用调用,不会被运行时的低层系统调用使用// entersyscall不能分割栈:保存操作必须使g->sched指向调用者的栈段,因为
// entersyscall将在立即返回后执行。在此期间g处于Gsyscall状态,但g.sched字段
// 的结构可能不完整,不能让GC观察到这种不一致状态// entersyscall调用的任何函数都不能分割栈
// 在活跃的系统调用期间,我们无法安全地移动栈,因为不知道uintptr参数中哪些
// 是实际的指针(指向栈内部)。实践中,这意味着快速路径必须使用无分割操作,
// 慢速路径则需要通过systemstack在系统栈上执行更大操作// reentersyscall是cgo回调使用的入口点,用于恢复显式保存的SP和PC
// 这在需要从调用栈更上层的函数调用exitsyscall时是必要的,因为g.syscallsp
// 必须始终指向有效的栈帧。下面的entersyscall是正常系统调用入口,从调用者获取SP和PC//go:nosplit
func reentersyscall(pc, sp, bp uintptr) {trace := traceAcquire()gp := getg()// 禁用抢占,因为此时g处于Gsyscall状态但g.sched字段可能不一致gp.m.locks++// entersyscall不能调用可能分割/扩展堆栈的函数(详情见上方注释)// 通过替换堆栈保护指针为会触发堆栈检查的值,并设置标志位让newstack终止gp.stackguard0 = stackPreemptgp.throwsplit = true// 保留SP用于GC和追踪回溯save(pc, sp, bp)gp.syscallsp = spgp.syscallpc = pcgp.syscallbp = bpcasgstatus(gp, _Grunning, _Gsyscall)if staticLockRanking {// 静态锁排序时,casgstatus可能调用systemstack并覆盖g.schedsave(pc, sp, bp)}if gp.syscallsp < gp.stack.lo || gp.stack.hi < gp.syscallsp {systemstack(func() {print("entersyscall inconsistent sp ", hex(gp.syscallsp), " [", hex(gp.stack.lo), ",", hex(gp.stack.hi), "]\n")throw("entersyscall")})}if gp.syscallbp != 0 && gp.syscallbp < gp.stack.lo || gp.stack.hi < gp.syscallbp {systemstack(func() {print("entersyscall inconsistent bp ", hex(gp.syscallbp), " [", hex(gp.stack.lo), ",", hex(gp.stack.hi), "]\n")throw("entersyscall")})}if trace.ok() {systemstack(func() {trace.GoSysCall() // 记录系统调用事件traceRelease(trace) // 释放追踪资源})// systemstack本身会覆盖g.sched.{pc,sp},而我们可能需要这些信息// 当G真正被系统调用阻塞时save(pc, sp, bp)}if sched.sysmonwait.Load() {// 系统监控等待期间需要特殊处理systemstack(entersyscall_sysmon)save(pc, sp, bp)}if gp.m.p.ptr().runSafePointFn != 0 {// 在当前栈上执行runSafePointFn可能导致栈分割// 通过系统栈执行确保安全systemstack(runSafePointFn)save(pc, sp, bp)}// 记录当前系统调用计数gp.m.syscalltick = gp.m.p.ptr().syscalltickpp := gp.m.p.ptr()pp.m = 0gp.m.oldp.set(pp)gp.m.p = 0atomic.Store(&pp.status, _Psyscall) // 更新P状态为系统调用中if sched.gcwaiting.Load() {// 如果GC正在等待,需要特殊处理systemstack(entersyscall_gcwait)save(pc, sp, bp)}// 减少锁计数器,允许抢占恢复gp.m.locks--
}
转移前
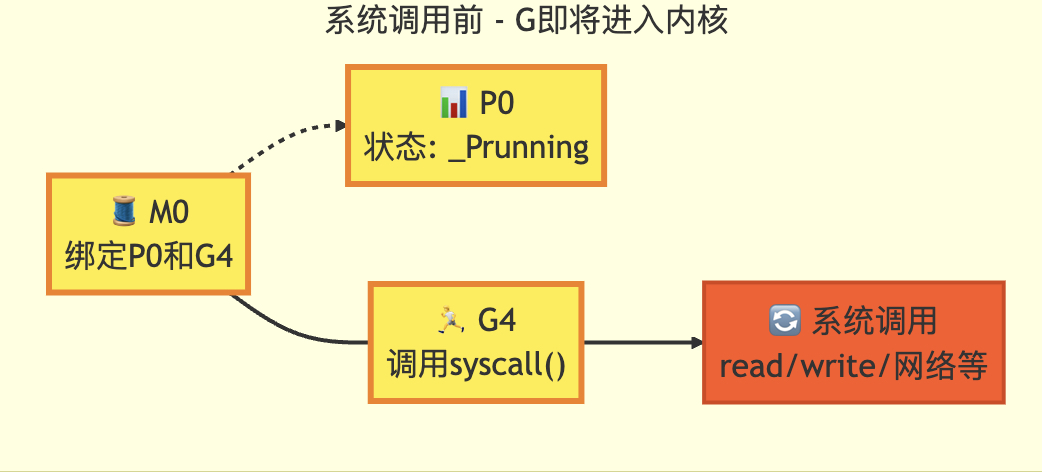
转移后
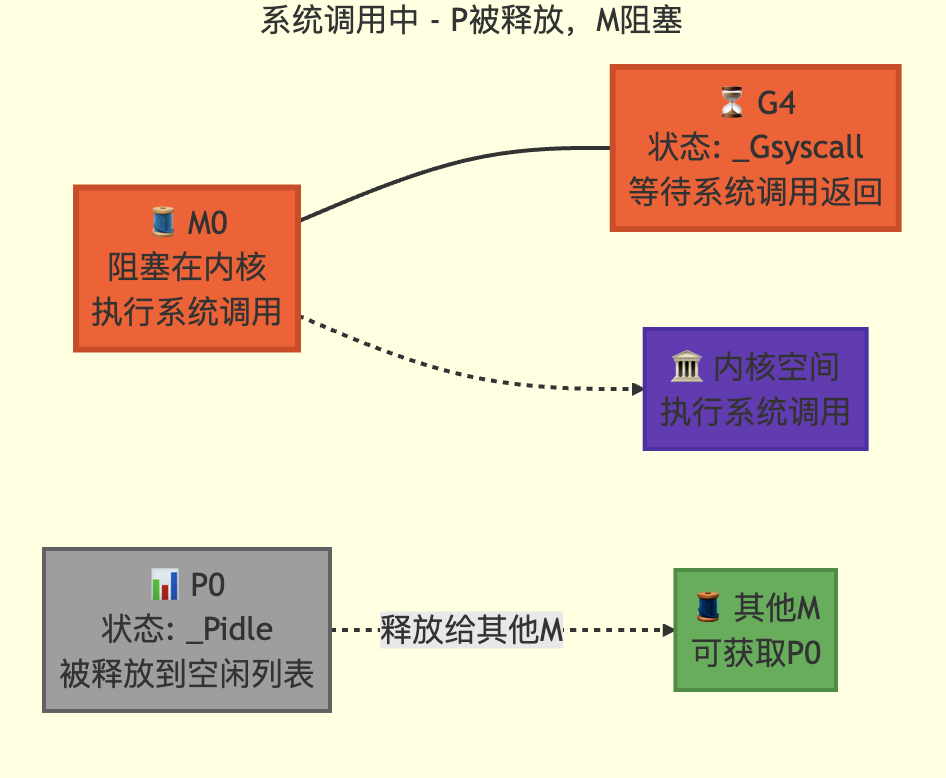
3.7 网络阻塞
// 将当前goroutine置于等待状态,并在系统栈上调用unlockf函数
//
// 如果unlockf返回false,则当前goroutine会被恢复执行
//
// unlockf不能访问该G的栈,因为G可能在调用gopark和unlockf之间被移动到其他M
//
// 注意:由于unlockf是在将G置于等待状态后调用的,调用时G可能已经被其他goroutine准备就绪
// 除非有外部同步机制阻止G被准备。如果unlockf返回false,必须保证G不能被外部准备
//
// reason参数说明goroutine被阻塞的原因,会在堆栈跟踪和堆转储中显示
// 原因应该保持唯一性和描述性,不要复用原因,应添加新原因
//
// gopark应该作为运行时内部实现细节
// 但广泛使用的包通过linkname指令访问它
// 羞耻堂成员包括:
// - gvisor.dev/gvisor
// - github.com/sagernet/gvisor
//
// 不要删除或修改类型签名(见go.dev/issue/67401)
//
//go:linkname gopark
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {if reason != waitReasonSleep {checkTimeouts() // 两个goroutine可能同时让调度器繁忙,此时需要检查超时}mp := acquirem() // 获取当前Mgp := mp.curg // 当前M绑定的Gstatus := readgstatus(gp)// 验证当前G状态是否合法(运行中或扫描运行中)if status != _Grunning && status != _Gscanrunning {throw("gopark: bad g status")}mp.waitlock = lock // 保存等待锁mp.waitunlockf = unlockf // 保存解锁函数gp.waitreason = reason // 设置等待原因mp.waitTraceBlockReason = traceReason // 设置追踪阻塞原因mp.waitTraceSkip = traceskip // 设置追踪跳过层级releasem(mp) // 释放当前M// 不能在此处执行可能导致G在多个M之间移动的操作mcall(park_m) // 调用系统调用处理函数
}
状态转移前
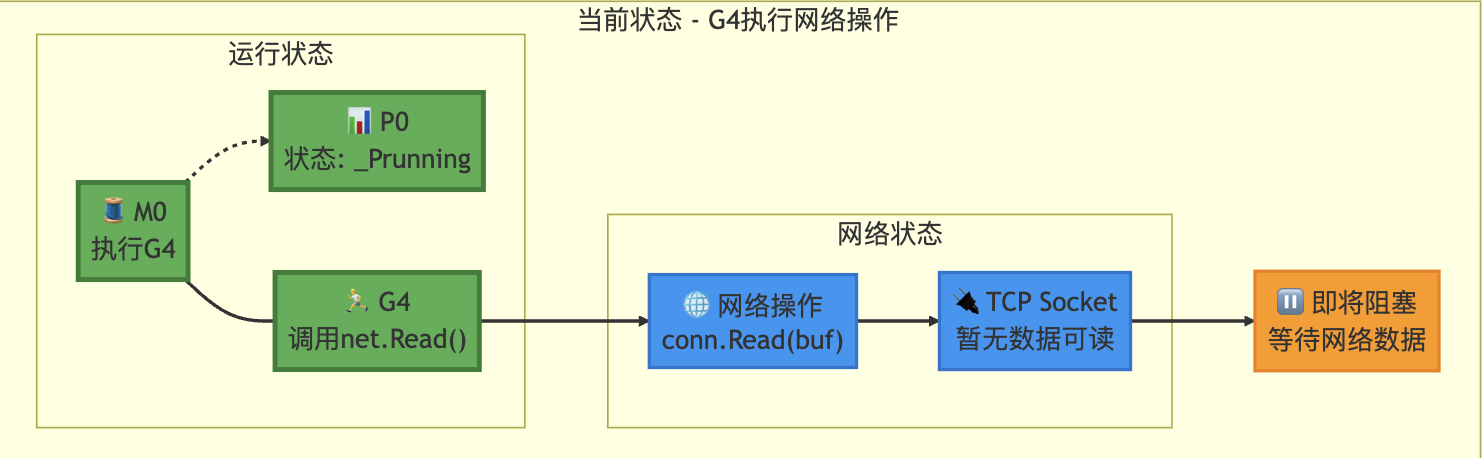
状态转移后
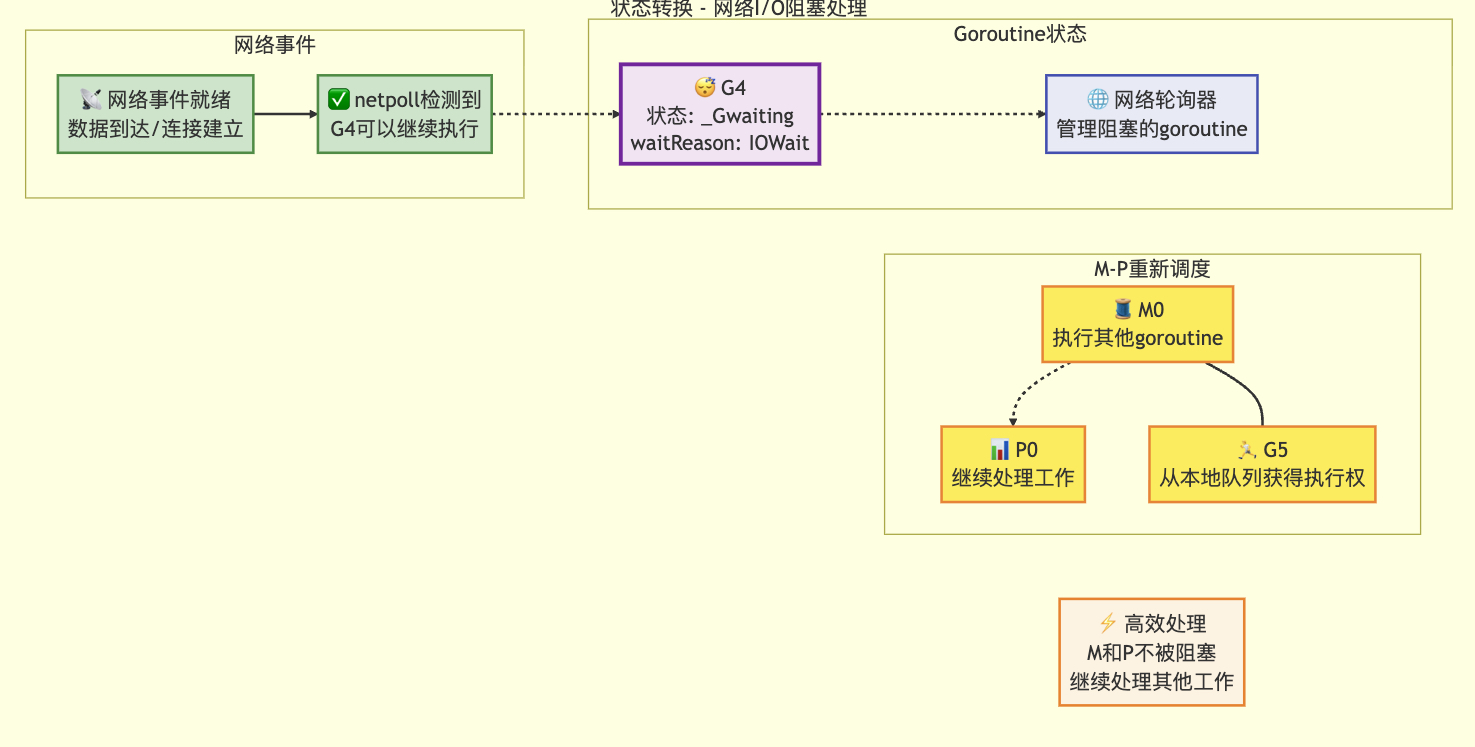
3.8 定时器操作
// time.Sleep函数的实现
//
// 该函数使当前goroutine休眠至少ns纳秒
//
//go:linkname timeSleep time.Sleep
func timeSleep(ns int64) {if ns <= 0 {return}gp := getg() // 获取当前goroutinet := gp.timer // 获取当前goroutine的定时器if t == nil {// 如果没有定时器则创建新定时器t = new(timer)t.init(goroutineReady, gp) // 初始化定时器回调为goroutineReadyif gp.bubble != nil { // 如果处于时间气泡中t.isFake = true // 标记为虚拟定时器}gp.timer = t // 绑定定时器到当前goroutine}var now int64if bubble := gp.bubble; bubble != nil {// 如果处于时间气泡中,使用气泡内的时间戳now = bubble.now} else {// 否则获取当前实际时间now = nanotime()}// 计算唤醒时间(当前时间+休眠时长)when := now + ns// 检查溢出情况if when < 0 {when = maxWhen // 设置为最大时间值}gp.sleepWhen = when // 保存唤醒时间// 根据是否为虚拟定时器选择不同处理方式if t.isFake {// 在协程内部调用定时器重置(因为处于时间气泡中)// 不需要担心定时器函数在协程挂起前执行,因为时间不会在挂起前推进resetForSleep(gp, nil)// 挂起当前协程,等待时间气泡中的时间推进gopark(nil, nil, waitReasonSleep, traceBlockSleep, 1)} else {// 使用系统调度器进行定时器重置gopark(resetForSleep, nil, waitReasonSleep, traceBlockSleep, 1)}
}
定时器阻塞前
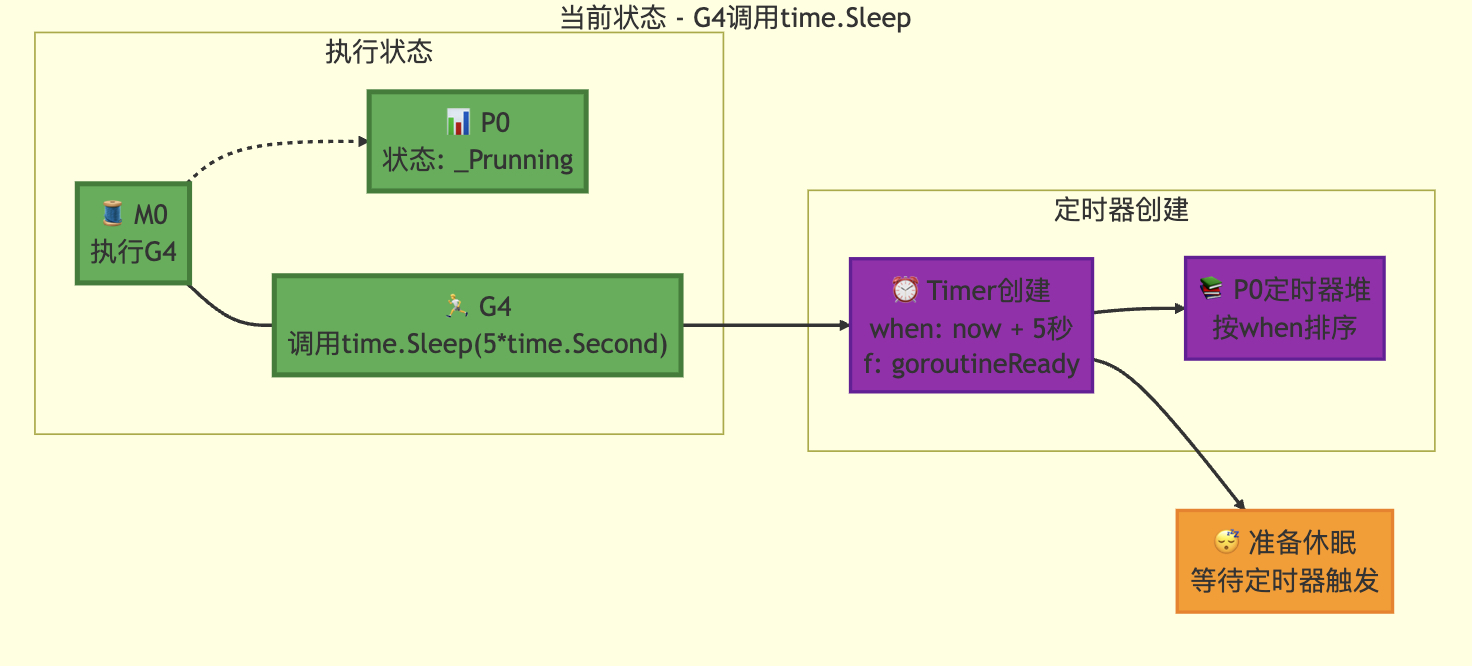
定时器唤醒
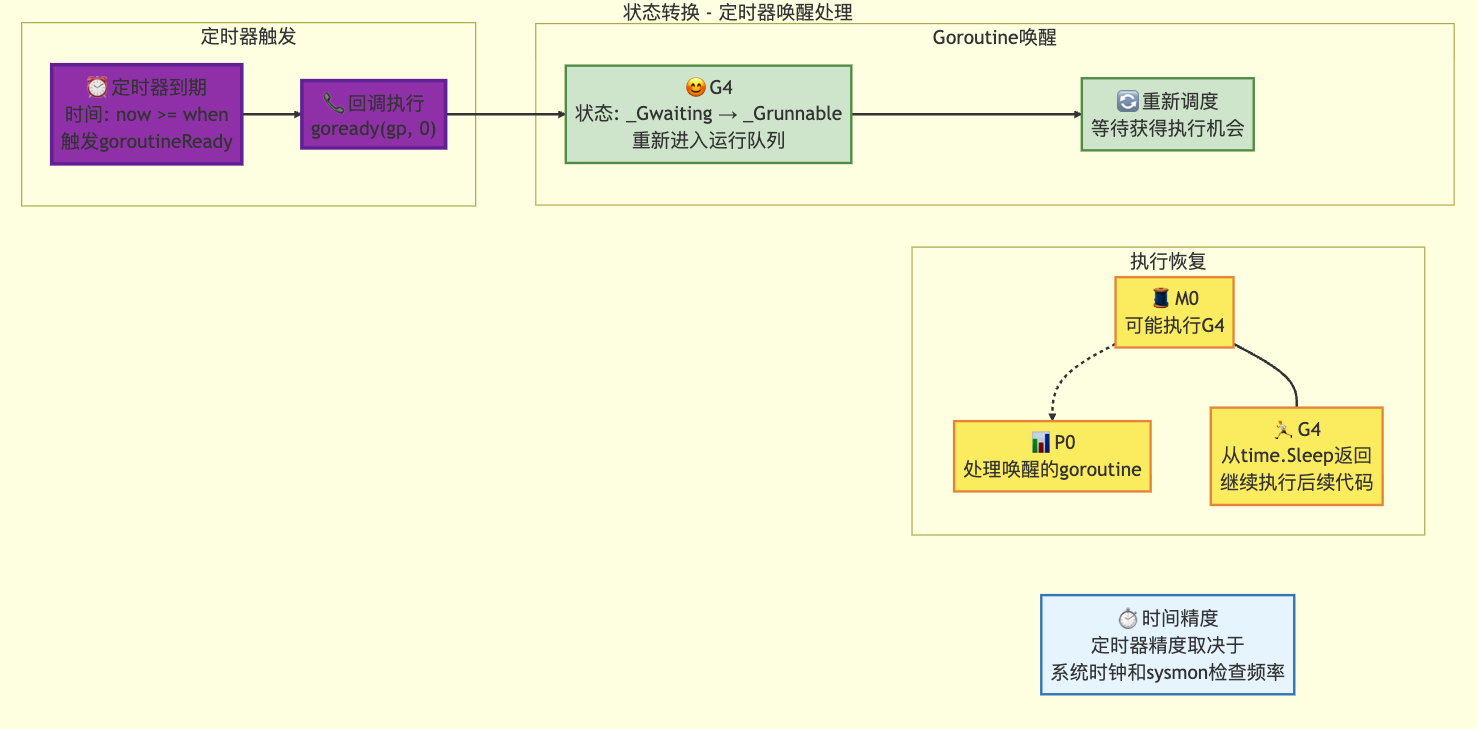
3.9 Goroutine正常结束
// Finishes execution of the current goroutine.
func goexit1() {if raceenabled {if gp := getg(); gp.bubble != nil {racereleasemergeg(gp, gp.bubble.raceaddr())}racegoend()}trace := traceAcquire()if trace.ok() {trace.GoEnd()traceRelease(trace)}mcall(goexit0)
}// goexit continuation on g0.
func goexit0(gp *g) {gdestroy(gp)schedule()
}
3.10 抢占式调度 - 信号/栈增长
func retake(now int64) uint32 {n := 0// 防止allp切片发生变化。这个锁只有在暂停世界时才可能被竞争// This lock will be completely uncontended unless we're already stopping the world.lock(&allpLock)// 我们不能在循环中使用range遍历allp,因为可能会// 临时释放allpLock。因此需要每次循环都重新获取allp。for i := 0; i < len(allp); i++ {pp := allp[i]if pp == nil {// 这可能发生在procresize已经扩容// allp但尚未创建新的P时continue}pd := &pp.sysmonticks := pp.statussysretake := falseif s == _Prunning || s == _Psyscall {// 如果某个G在同一个schedtick上运行太久就抢占// 可能是单个长时间运行的goroutine,或通过// runnext运行的一系列goroutine共享的调度时间片t := int64(pp.schedtick)if int64(pd.schedtick) != t {pd.schedtick = uint32(t)pd.schedwhen = now} else if pd.schedwhen+forcePreemptNS <= now {preemptone(pp)// 如果是系统调用状态,preemptone()可能失效// 因为此时M和P没有绑定sysretake = true}}if s == _Psyscall {// 如果系统调用时间超过1个sysmon tick(至少20us)就回收P// 一方面我们不希望在没有其他工作时回收P// 另一方面我们需要回收P以避免sysmon线程无法进入深度睡眠t := int64(pp.syscalltick)if !sysretake && int64(pd.syscalltick) != t {pd.syscalltick = uint32(t)pd.syscallwhen = nowcontinue}// 在CAS操作前需要减少空闲锁定的M数量// 否则从系统调用返回的M可能增加nmidle并报告死锁// (假装有1个M在运行)unlock(&allpLock)incidlelocked(-1)trace := traceAcquire()if atomic.Cas(&pp.status, s, _Pidle) {if trace.ok() {trace.ProcSteal(pp, false)traceRelease(trace)}n++pp.syscalltick++handoffp(pp)} else if trace.ok() {traceRelease(trace)}incidlelocked(1)lock(&allpLock)}}unlock(&allpLock)return uint32(n)
}// 通知在处理器P上运行的goroutine停止
// 该函数是尽力而为的,可能会失败或通知错误的goroutine
// 即使通知了正确的goroutine,如果它同时正在执行newstack操作,也可能忽略请求
// 无需持有任何锁
// 返回true表示已发起抢占请求
// 实际抢占将在未来某个时刻发生,并通过gp->status不再是Grunning状态来体现
func preemptone(pp *p) bool {mp := pp.m.ptr()if mp == nil || mp == getg().m {return false}gp := mp.curgif gp == nil || gp == mp.g0 {return false}gp.preempt = true// 每个goroutine中的调用都会检查栈溢出// 通过比较当前栈指针和gp->stackguard0的值// 将gp->stackguard0设置为StackPreempt值// 可以将抢占请求合并到正常的栈溢出检查流程中gp.stackguard0 = stackPreempt// 请求对这个P进行异步抢占if preemptMSupported && debug.asyncpreemptoff == 0 {pp.preempt = truepreemptM(mp)}return true
}检测是否有g占用过久cpu,通过信号机制强制进行调度切换。
抢占检测
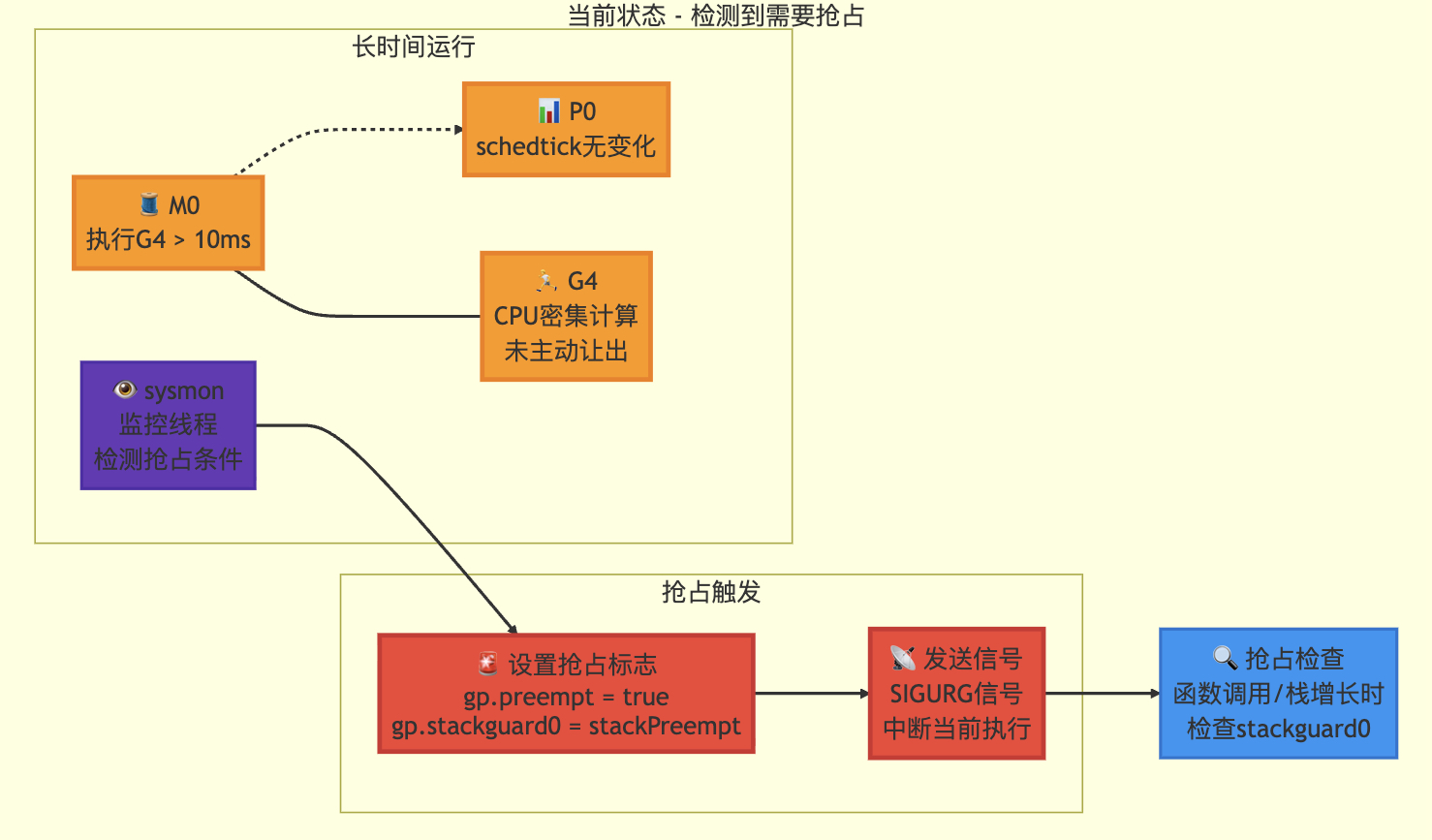
抢占执行

4.其他操作原因
4.1 cgo调用为什么不能抢占
(1) 栈隔离
- Go 调用 C 时,会创建一个新的 C 栈,与 Go 栈分离。
- C 代码无法直接操作 Go 栈,反之亦然。
(2) 调度器的限制
- 抢占机制失效:Go 的抢占式调度依赖 g0 栈。在 cgo 调用期间,g0 栈被占用,调度器无法中断当前 goroutine。
- M 与 P 的绑定:执行 cgo 调用的 M 会与 P(逻辑处理器)解绑,直到 C 调用返回。
(3) 内存和垃圾回收
- C 代码不能被 Go 的垃圾回收器(GC)管理,因此需要手动处理内存(如
C.free释放 C 分配的内存)。 - 如果 C 代码中分配的内存未释放,可能导致内存泄漏。
4.2 为什么需要clearAllpSnapshot()
避免内存泄漏
allpSnapshot是对所有P(逻辑处理器)的引用快照。若在循环中重复保留旧快照,会导致内存中存在大量不再使用的P引用。Go的GC无法回收被强引用占用的内存,长期积累可能引发内存泄漏。解除GC压力
快照作为slice类型,其底层数组会持有P对象的引用。即使当前迭代结束后不再使用该快照,GC仍需跟踪这些引用以判断是否可回收。主动清零(clearAllpSnapshot())可立即解除引用关系,允许GC回收相关内存。确保数据一致性
P的状态在运行时可能被动态修改(如迁移、销毁)。若保留旧快照,后续操作可能基于过期数据,导致逻辑错误。每次迭代后清理快照,可强制下一次迭代重新获取最新状态。并发安全需求
在多线程环境中,未清理的快照可能被其他goroutine访问。通过及时释放快照,减少竞态条件的风险,确保每次迭代的数据来源独立且最新。
4.3 为什么stealwork里需要窃取定时器
每个p都有独属于自己的定时器和定时器队列,结构体如下,会维护以g的过期时间作为值维护的最小堆,保证最早到期的g优先处理。同时每个p私有化定时器,也可以减少锁的竞争。
// A timers is a per-P set of timers.
// timers 是每个P(逻辑处理器)的定时器集合
type timers struct {// mu protects timers; timers are per-P, but the scheduler can// access the timers of another P, so we have to lock.// mu 用于保护定时器;虽然定时器是每个P私有的,但调度器可能访问其他P的定时器// 因此需要锁来保证并发安全mu mutex// heap is the set of timers, ordered by heap[i].when.// Must hold lock to access.// heap 是定时器数组,按 heap[i].when(触发时间)排序// 访问此字段时必须持有锁heaptimerWhen// len is an atomic copy of len(heap).// len 是 heap 长度的原子副本,用于并发读取len atomic.Uint32// zombies is the number of timers in the heap// that are marked for removal.// zombies 是堆中标记为待移除的定时器数量zombies atomic.Int32// raceCtx is the race context used while executing timer functions.// raceCtx 是执行定时器函数时使用的竞态检测上下文raceCtx uintptr// minWhenHeap is the minimum heap[i].when value (= heap[0].when).// The wakeTime method uses minWhenHeap and minWhenModified// to determine the next wake time.// If minWhenHeap = 0, it means there are no timers in the heap.// minWhenHeap 是堆中最小的触发时间(即 heap[0].when)// wakeTime 方法会结合 minWhenHeap 和 minWhenModified// 计算下一个唤醒时间// 若 minWhenHeap = 0,表示堆中无定时器minWhenHeap atomic.Int64// minWhenModified is a lower bound on the minimum// heap[i].when over timers with the timerModified bit set.// If minWhenModified = 0, it means there are no timerModified timers in the heap.// minWhenModified 是所有标记为 timerModified 的定时器中最小的触发时间的下界// 若 minWhenModified = 0,表示堆中无 timerModified 的定时器// timerModified 标志用于表示定时器被修改过(例如重新设置触发时间)minWhenModified atomic.Int64
}



)








 React的状态管理工具--Redux,案例--移动端外卖平台)
(上))





