先给出并查集的模板,还有一些leetcode算法题,以后遇见了相关题目再往上增加
并查集模板
整体模板C++代码如下:
-
空间复杂度: O(n) ,申请一个father数组。
-
时间复杂度
路径压缩后的并查集时间复杂度在O(logn)与O(1)之间,且随着查询或者合并操作的增加,时间复杂度会越来越趋于O(1)。
int n = 51000;
vector<int> father = vector<int>(n);
/*
错误的方法
class Foo(){
private:vector<string> name(5); //error in these 2 linesvector<int> val(5,0);
}
正确的方法
C++11以后:
class Foo(){
private:vector<string> name = vector<string>(5);vector<int> val{vector<int>(5,0)};
}
*/// 并查集初始化
void init() {for (int i = 0; i < father.size(); i++) {father[i] = i;}
}// 并查集里寻根的过程:路径压缩
int find(int a) {if (father[a] == a)return a;elsereturn father[a] = find(father[a]);
}bool same(int a, int b) {a = find(a);b = find(b);return a == b;
}// 将a->b 这条边加入并查集
void join(int a, int b) {a = find(a); //找根b = find(b);if (a == b)return;elsefather[a] = b;
}init();
1、1971. 寻找图中是否存在路径
- 思路:直接并查集套用即可
提示:
1 <= n <= 2 * 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ui, vi <= n - 1ui != vi0 <= source, destination <= n - 1- 不存在重复边
- 不存在指向顶点自身的边
class Solution {
public:int n = 200001;vector<int> father = vector<int>(n);void init() {for (int i = 0; i < n; i++) {father[i] = i;}}int find(int a) {if (a == father[a])return a;else {return father[a] = find(father[a]);}}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;else {father[a] = b;}}bool validPath(int n, vector<vector<int>>& edges, int source,int destination) {init();for (auto& a : edges) {join(a[0], a[1]);}return find(source) == find(destination);}
};
image-20240509155416437

2、547. 省份数量

- 思路:并查集:再通过set来统计个数
有
n个城市,其中一些彼此相连,另一些没有相连。如果城市a与城市b直接相连,且城市b与城市c
直接相连,那么城市a与城市c间接相连。省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个
n x n的矩阵isConnected,其中isConnected[i][j] = 1表示第i
个城市和第j个城市直接相连,而isConnected[i][j] = 0表示二者不直接相连。返回矩阵中 省份 的数量。
示例 1:
输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] 输出:2示例 2:
输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] 输出:3提示:
1 <= n <= 200n == isConnected.lengthn == isConnected[i].lengthisConnected[i][j]为1或0isConnected[i][i] == 1isConnected[i][j] == isConnected[j][i]
class Solution {
public:int n = 205;vector<int> father{vector<int>(n)};void init() {for (int i = 0; i < n; i++) {father[i] = i;}}int find(int a) {if (a == father[a])return a;else {return father[a] = find(father[a]);}}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;else {father[a] = b;}}int findCircleNum(vector<vector<int>>& isConnected) {init();int len = isConnected.size();for (int i = 0; i < len; i++) {for (int j = 0; j < len; j++) {if (isConnected[i][j]) {join(i, j);}}}// 统计父节点的个数有两种方式:// 1、使用set比较直观:但是复杂度高// unordered_set<int> st;// for (int i = 0; i < len; i++) {// st.insert(find(i));// }// return st.size();// 2、直接在范围内统计 father[i] == i为父节点,其他的都是指向父节点的子节点int res = 0;for(int i = 0;i<len;i++){if(father[i]==i){res++;}}return res;}
};
3、684. 冗余连接
- 在一棵树中,边的数量比节点的数量少 1。如果一棵树有 n 个节点,则这棵树有 n−1 条边。这道题中的图在树的基础上多了一条附加的边,因此边的数量也是 n。
- 树是一个连通且无环的无向图,在树中多了一条附加的边之后就会出现环,因此附加的边即为导致环出现的边。
- 可以通过并查集寻找附加的边。初始时,每个节点都属于不同的连通分量。遍历每一条边,判断这条边连接的两个顶点是否属于相同的连通分量。
- 并查集解决问题:**只有出现环时,才会出现两个根相同。**如果一棵树有 n 个节点,则这棵树有 n−1 条边。那么这两个节点根一定不同。
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵
n个节点 (节点值1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在1到n
中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为n的二维数组edges,edges[i] = [ai, bi]表示图中在ai和bi之间存在一条边。请找出一条可以删去的边,删除后可使得剩余部分是一个有着
n个节点的树。如果有多个答案,则返回数组edges中最后出现的那个。示例 1:
输入: edges = [[1,2], [1,3], [2,3]] 输出: [2,3]示例 2:
输入: edges = [[1,2], [2,3], [3,4], [1,4], [1,5]] 输出: [1,4]提示:
n == edges.length3 <= n <= 1000edges[i].length == 21 <= ai < bi <= edges.lengthai != biedges中无重复元素- 给定的图是连通的
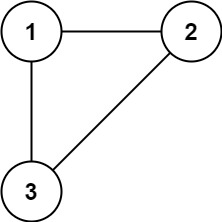
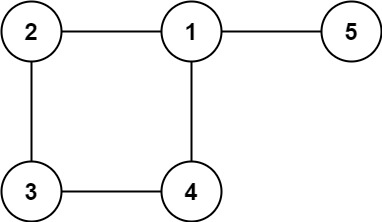
/*思路:题目中有个环:环比树路径多,找到重复的路径一般的树,不会出现,同一个根,只有环才可能出现两个节点的根一样
*/class Solution {
public:int n = 1001;vector<int> father{vector<int>(n)};void init() {for (int i = 0; i < n; i++) {father[i] = i;}}int find(int a) {if (a == father[a])return a;elsereturn father[a] = find(father[a]);}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;father[a] = b;}vector<int> findRedundantConnection(vector<vector<int>>& edges) {init();vector<int> res;for (auto& a : edges) {if (find(a[0]) == find(a[1])) {res = a;break;}join(a[0], a[1]);}return res;}
};

4、 1061. 按字典序排列最小的等效字符串
给出长度相同的两个字符串s1 和 s2 ,还有一个字符串 baseStr 。
其中 s1[i] 和 s2[i] 是一组等价字符。
- 举个例子,如果
s1 = "abc"且s2 = "cde",那么就有'a' == 'c', 'b' == 'd', 'c' == 'e'。
等价字符遵循任何等价关系的一般规则:
- 自反性 :
'a' == 'a' - 对称性 :
'a' == 'b'则必定有'b' == 'a' - 传递性 :
'a' == 'b'且'b' == 'c'就表明'a' == 'c'
例如, s1 = "abc" 和 s2 = "cde" 的等价信息和之前的例子一样,那么 baseStr = "eed" , "acd" 或 "aab",这三个字符串都是等价的,而 "aab" 是 baseStr 的按字典序最小的等价字符串
利用 s1 和 s2 的等价信息,找出并返回 baseStr 的按字典序排列最小的等价字符串。
示例 1:
输入:s1 = "parker", s2 = "morris", baseStr = "parser"
输出:"makkek"
解释:根据 A 和 B 中的等价信息,我们可以将这些字符分为 [m,p], [a,o], [k,r,s], [e,i] 共 4 组。每组中的字符都是等价的,并按字典序排列。所以答案是 "makkek"。
示例 2:
输入:s1 = "hello", s2 = "world", baseStr = "hold"
输出:"hdld"
解释:根据 A 和 B 中的等价信息,我们可以将这些字符分为 [h,w], [d,e,o], [l,r] 共 3 组。所以只有 S 中的第二个字符 'o' 变成 'd',最后答案为 "hdld"。
示例 3:
输入:s1 = "leetcode", s2 = "programs", baseStr = "sourcecode"
输出:"aauaaaaada"
解释:我们可以把 A 和 B 中的等价字符分为 [a,o,e,r,s,c], [l,p], [g,t] 和 [d,m] 共 4 组,因此 S 中除了 'u' 和 'd' 之外的所有字母都转化成了 'a',最后答案为 "aauaaaaada"。
提示:
1 <= s1.length, s2.length, baseStr <= 1000s1.length == s2.length- 字符串
s1,s2, andbaseStr仅由从'a'到'z'的小写英文字母组成。
/*思路:使用并查集将根节点都变成最小的,再遍历一下全换成根就行有个坑点:if (find(s1[i]-'a') > find(s2[i]-'a'))这里需要每次找到根,再去判断。
*/class Solution {
public:int n = 50;vector<int> father = vector<int>(n);void init() {for (int i = 0; i < father.size(); i++) {father[i] = i;}}int find(int a) {if (father[a] == a)return a;elsereturn father[a] = find(father[a]);}bool same(int a, int b) {a = find(a);b = find(b);return a == b;}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;elsefather[a] = b;}string smallestEquivalentString(string s1, string s2, string baseStr) {init();for (int i = 0; i < s1.size(); i++) {if (find(s1[i]-'a') > find(s2[i]-'a'))join(s1[i] - 'a', s2[i] - 'a');elsejoin(s2[i] - 'a', s1[i] - 'a');}for (auto& a : baseStr) {a = find(a-'a')+'a';}return baseStr;}
};
5、990. 等式方程的可满足性
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:"a==b" 或 "a!=b"。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
示例 1:
输入:["a==b","b!=a"]
输出:false
解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。
示例 2:
输入:["b==a","a==b"]
输出:true
解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。
示例 3:
输入:["a==b","b==c","a==c"]
输出:true
示例 4:
输入:["a==b","b!=c","c==a"]
输出:false
示例 5:
输入:["c==c","b==d","x!=z"]
输出:true
提示:
1 <= equations.length <= 500equations[i].length == 4equations[i][0]和equations[i][3]是小写字母equations[i][1]要么是'=',要么是'!'equations[i][2]是'='
/*思路:取等号说明可以加入并查集使用不等号进行判断:如果不等号两边是同一个根:说明之前等号过注意:并查集加入似乎跟前后的顺序没有关系
*/class Solution {
public:int n = 30;vector<int> father = vector<int>(n);void init() {for (int i = 0; i < n; i++) {father[i] = i;}}int find(int a) {if (a == father[a])return a;return father[a] = find(father[a]);}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;father[a] = b;}bool equationsPossible(vector<string>& equations) {init();for (auto& a : equations) {if (a[1] == '=')join(a[0] - 'a', a[3] - 'a');}for (auto& a : equations) {if (a[1] == '!') {if (find(a[0] - 'a') == find(a[3] - 'a')) {return false;}}}return true;}
};
6、947. 移除最多的同行或同列石头
-
解决连通性问题:记模板:x->y+max,如果联通则最后结果都是最右边的y+max
-
把二维坐标平面上的石头想象成图的顶点,如果两个石头横坐标相同、或者纵坐标相同,在它们之间形成一条边。
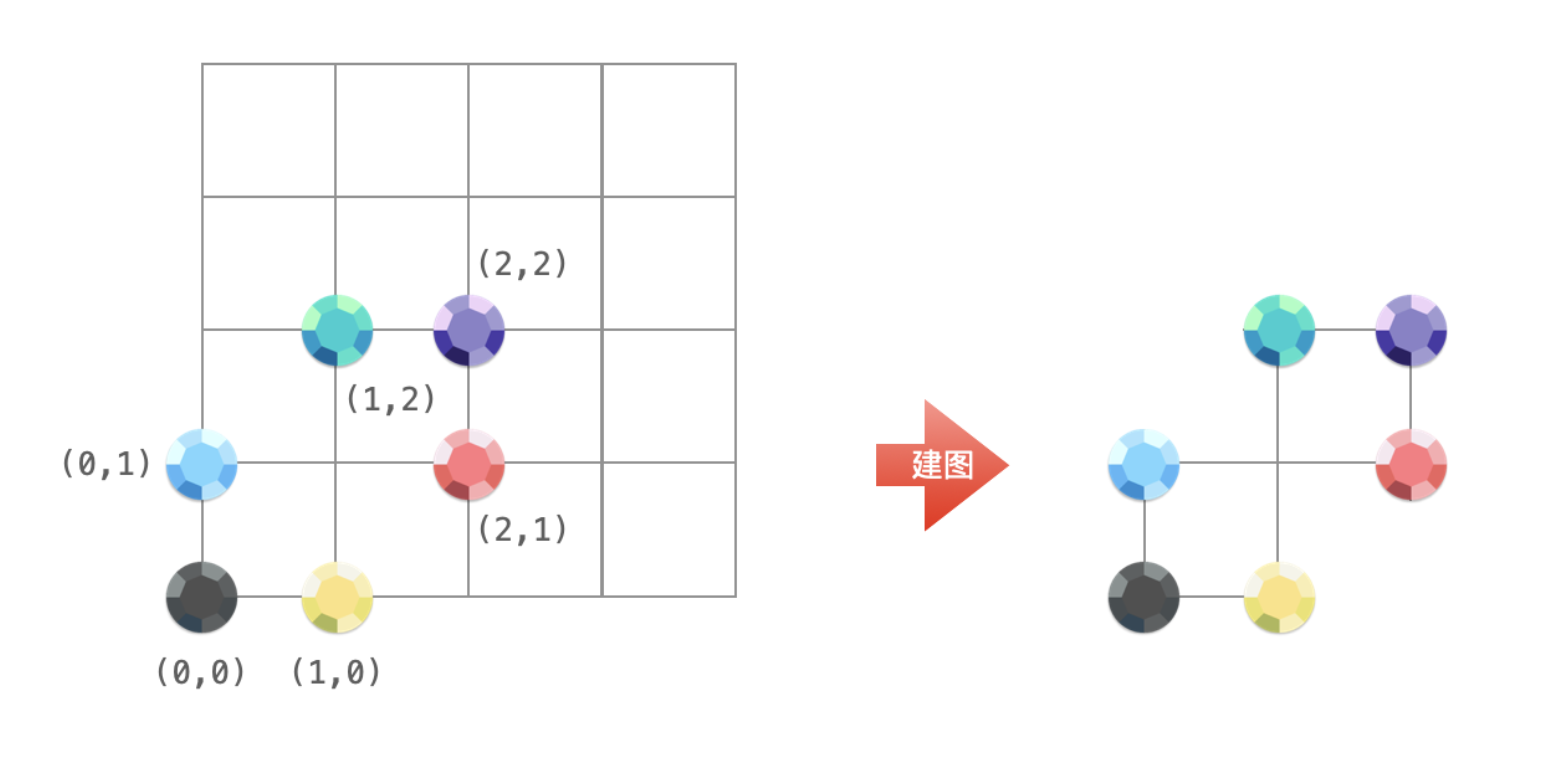
根据可以移除石头的规则:如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。可以发现:一定可以把一个连通图里的所有顶点根据这个规则删到只剩下一个顶点。
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。
示例 1:
1 1 0
1 0 1
0 1 1-》0->100 0->100->101 0
1->101 0 1->101->102
0 2->101->102 102->102102 102 0
102 0 102
0 102 1020 1
1 0 0 0->1
1->0 00 0->101
1->100 0输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
解释:一种移除 5 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,1] 同行。
2. 移除石头 [2,1] ,因为它和 [0,1] 同列。
3. 移除石头 [1,2] ,因为它和 [1,0] 同行。
4. 移除石头 [1,0] ,因为它和 [0,0] 同列。
5. 移除石头 [0,1] ,因为它和 [0,0] 同行。
石头 [0,0] 不能移除,因为它没有与另一块石头同行/列。
示例 2:
1 0 1
0 1 0
1 0 1
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
解释:一种移除 3 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,0] 同行。
2. 移除石头 [2,0] ,因为它和 [0,0] 同列。
3. 移除石头 [0,2] ,因为它和 [0,0] 同行。
石头 [0,0] 和 [1,1] 不能移除,因为它们没有与另一块石头同行/列。
示例 3:
输入:stones = [[0,0]]
输出:0
解释:[0,0] 是平面上唯一一块石头,所以不可以移除它。
提示:
1 <= stones.length <= 10000 <= xi, yi <= 104- 不会有两块石头放在同一个坐标点上
/*思路难以想象:只能记模板:把坐标x->y+10000上就能实现连通性分析问题:只要在坐标上是联通的就可以得到同一个结果:同一个根:为什么?可以模拟出来,但是想不通注意:Y需要加上最大值:为了解决0 1 1 0的问题最后的结果都是:y的值最右边y的值
*/class Solution {
public:int n = 51000;vector<int> father = vector<int>(n);void init() {for (int i = 0; i < father.size(); i++) {father[i] = i;}}int find(int a) {if (father[a] == a)return a;elsereturn father[a] = find(father[a]);}bool same(int a, int b) {a = find(a);b = find(b);return a == b;}void join(int a, int b) {a = find(a);b = find(b);if (a == b)return;elsefather[a] = b;}int removeStones(vector<vector<int>>& stones) {init();for (auto a : stones) {join(a[0], a[1] + 20005);}unordered_map<int, int> mp;for (auto a : stones) {mp[find(a[0])] = 1;}return stones.size() - mp.size();}
};
)
)


处理)
)





)

redis)

(下))



