文章目录
- 一、作者
- 二、摘要
- 三、相关工作
- 四、算法概述
- 五、实验结果
- 六、主要贡献
一、作者
Yaroslav Akhremtsev, Tobias Heuer, Peter Sanders, Sebastian Schlag
二、摘要
我们开发了一种快速且高质量的多层算法,能够直接将超图划分为 k 个平衡的块 —— 无需借助递归二分法这一迂回方式。特别是,我们的算法能有效实现强大的 FM 局部搜索启发式算法,使其适用于复杂的 k 路情况。这对于依赖超边所连接块数的那些目标函数来说意义重大。此外,我们还消除了处理大型超边的多个瓶颈,开发了一种更快的收缩算法以及一种新的局部搜索自适应停止规则。为进一步缩小超边规模,我们基于 min - hashing 技术开发了一种将具有相似邻域的顶点聚类的引脚稀疏化方法。大量实验表明,我们的 KaHyPar 划分器与其他最佳的先前系统相比具有优势。KaHyPar 比 hMetis 更快且计算出的解更好。相比于(速度更快的)PaToH 划分器,KaHyPar 的结果要好得多。
三、相关工作
- 研究现状:
- 常用工具
- PaToH[7](科学计算)
- hMetis[8] [9](VLSI 设计)
- Mondriaan[10](稀疏矩阵划分)
- MLPart[11](电路划分)
- Zoltan[12]、Parkway[13]、UMPa[14](定向超图模型,多目标)
- kPaToH[15](多约束,固定顶点)
- 其他文献
- n 级范式一直运用于基于随机增量结构的几何数据结构[2] [3] 和布线计划的预处理阶段[4],而且,也成功运用于图和超图的划分中,例如:KaSPar[5](图直接 k 划分) 和 KaHyPar[1](超图递归 k 划分)。
- 有一个未正式发表的直接 k 路 n 级划分算法[6],尽管在部分实验取得不错的效果,但是运行时间比较长。
- 常用工具
- 准备工作:
- 术语表
| term | explanation |
|---|---|
| H = ( V , E , ω ( v ) , ω ( e ) ) H=(V,E,\omega(v),\omega(e)) H=(V,E,ω(v),ω(e)) | H 表示超图,V 表示超图的顶点集,E 表示超图的超边集, ω \omega ω 是权重 |
| ϵ \epsilon ϵ | 不平衡系数 |
| V x V_x Vx | 划分块 |
| E x E_x Ex | 包含顶点 x 的超边集合 |
| d ( v ) = ∣ E v ∣ d(v)=|E_v| d(v)=∣Ev∣ | 顶点 v 的度 |
| N ( v ) = { v ′ ∣ v ′ ∈ E v ∧ v ′ ≠ v } N(v)=\{v'|v'\in E_v \wedge v' \ne v\} N(v)={v′∣v′∈Ev∧v′=v} | 顶点 v 的邻居顶点 |
| P = { V 1 , … , V k ∣ ∪ i = 1 k V i = V ∧ ( V i ∩ V j = ∅ ⇔ i ≠ j ) } P=\{V_1,\dots,V_k | \cup_{i=1}^k V_i=V \wedge (V_i\cap V_j=\varnothing \Leftrightarrow i \ne j ) \} P={V1,…,Vk∣∪i=1kVi=V∧(Vi∩Vj=∅⇔i=j)} | 划分 P |
| b ( v ) = { V i ∣ v ∈ V i } b(v)=\{V_i | v \in V_i\} b(v)={Vi∣v∈Vi} | 顶点 v 所属的划分块 |
| b ( e ) = { b ( v ) ∣ v ∈ e } b(e)=\{b(v)|v \in e \} b(e)={b(v)∣v∈e} | 超边 e 所属的划分块 |
| Z ( v ) = { b ( e ) ∣ e ∈ E v } − { b ( v ) } \Zeta(v)=\{b(e)|e\in E_v\}-\{b(v)\} Z(v)={b(e)∣e∈Ev}−{b(v)} | 顶点 v 的邻居划分块 |
| Φ ( e , V i ) = ∣ { v ∣ v ∈ e ∧ v ∈ V i } ∣ \Phi(e,V_i)=\big|\{v| v \in e \wedge v \in V_i\}\big| Φ(e,Vi)= {v∣v∈e∧v∈Vi} | 超边 e 在划分块 V i V_i Vi 的顶点数量 |
| C u t ( e ) = { ω ( e ) , ∣ b ( e ) ∣ > 1 0 , ∣ b ( e ) ∣ = 1 Cut(e)=\begin{cases} \omega(e) &, |b(e)|>1 \\ 0 &, |b(e)|=1 \end{cases} Cut(e)={ω(e)0,∣b(e)∣>1,∣b(e)∣=1 | e 的割边权重 |
- \;
- 约束
- 平衡约束
∀ V i ⊆ P , ω ( V i ) ≤ ( 1 + ϵ ) ⌈ ω ( V ) k ⌉ \begin{equation} \forall V_i \subseteq P,\;\; \omega(V_i)\le(1+\epsilon) \bigg\lceil \frac{\omega(V)}{k} \bigg\rceil \end{equation} ∀Vi⊆P,ω(Vi)≤(1+ϵ)⌈kω(V)⌉
- 平衡约束
- 目标:
- 最小割边
min ∑ e ∈ E C u t ( e ) \begin{equation} \min \sum\limits_{e\in E} Cut(e) \end{equation} mine∈E∑Cut(e) - 最小连接权重
min ∑ e ∈ E ( b ( e ) − 1 ) ⋅ ω ( e ) \begin{equation} \min \sum\limits_{e\in E} \big(b(e)-1\big) \cdot \omega(e) \end{equation} mine∈E∑(b(e)−1)⋅ω(e)
- 最小割边
- 约束
四、算法概述
- 基于 Min-Hash 的顶点划分器【限定顶点的更新范围】
- 指纹【每个顶点一个指纹,第 i 轮建立 hash 表 T i T_i Ti,使用指纹分量 g i ( v , z ( v ) ) g_i\big(v,z(v)\big) gi(v,z(v))作为 key】
{ g i ( x , z ) = ( h i , 1 ( x ) , h i , 2 ( x ) , ⋯ , h i , z ( x ) ) } i = 1 , 2 , ⋯ , l \begin{equation} \{g_i(x,z)=\big(h_{i,1}(x),h_{i,2}(x),\cdots,h_{i,z}(x)\big)\}_{i=1,2,\cdots,l} \end{equation} {gi(x,z)=(hi,1(x),hi,2(x),⋯,hi,z(x))}i=1,2,⋯,l - Min-Hash 簇
H = { h σ ( v ) = min { σ ( e ) ∣ e ∈ E v } ∣ σ ∈ Σ } \begin{equation} H=\{h_{\sigma}(v)=\min \{ \sigma(e) | e\in E_v\}|\sigma \in \Sigma\} \end{equation} H={hσ(v)=min{σ(e)∣e∈Ev}∣σ∈Σ} - hash 函数
σ ( x ) = ( a x + b ) m o d P \begin{equation} \sigma(x)=(ax+b)\;mod\;P \end{equation} σ(x)=(ax+b)modP - 构建 hash 表
- 初始化:
- 将所有顶点设置为活跃状态,
- z = 1 , h m i n = 10 , h m a x = 100 z = 1,\;h_{min}=10,\;h_{max}=100 z=1,hmin=10,hmax=100
- 建立空表 T。
- 迭代:
- 迭代条件:存在活跃顶点 且 z ≤ h m a x z\le h_{max} z≤hmax
- 迭代过程:
- 建立 hash 表 T ′ T' T′
- 遍历所有活跃顶点 v,将活跃顶点按照 { g ( v , z ) , v } \{g(v,z),v\} {g(v,z),v}插入到 T ′ T' T′。
- 遍历所有活跃顶点 v:
- 如果 ∣ T [ v ] ∣ = ∣ T ′ [ v ] ∣ |T[v]|=|T'[v]| ∣T[v]∣=∣T′[v]∣ 且 z ≥ h m i n z \ge h_{min} z≥hmin,将 T ′ [ v ] T'[v] T′[v] 的顶点全部标记为不活跃。
- 如果 v 为活跃顶点 且 ∣ T [ v ] ∣ ≤ c m a x |T[v]| \le c_{max} ∣T[v]∣≤cmax 且 z ≥ h m i n z \ge h_{min} z≥hmin,将 T [ v ] T[v] T[v] 的顶点全部标记为不活跃。
- z = z + 1 z=z+1 z=z+1
- T = T ′ T=T' T=T′
- 初始化:
- 自适应聚类算法
- 初始化
- i = 1 , c m i n = 2 , c m a x = 10 , l = 5 i=1,\;c_{min}=2,\;c_{max}=10,\;l=5 i=1,cmin=2,cmax=10,l=5
- 迭代:
- 迭代条件:如果簇的数量大于顶点数的一半 且 i ≤ l i\le l i≤l
- 迭代过程:
- 构建 hash 表 T i T_i Ti
- 遍历所有活跃顶点 v ,如果 ∣ T i [ v ] ∣ ≤ c m a x |T_i[v]| \le c_{max} ∣Ti[v]∣≤cmax , 将 T i [ v ] T_i[v] Ti[v] 中的顶点加入到簇 c v c_v cv 中,并且移除 T i [ v ] T_i[v] Ti[v] 。
- 如果 c v ≥ c m i n c_v \ge c_{min} cv≥cmin, c v c_v cv 中的所有顶点都标记为不活跃。
- i = i + 1 i=i+1 i=i+1
- 初始化
- 指纹【每个顶点一个指纹,第 i 轮建立 hash 表 T i T_i Ti,使用指纹分量 g i ( v , z ( v ) ) g_i\big(v,z(v)\big) gi(v,z(v))作为 key】
- 聚类:
- 瓶颈【使用 n 级范式来消除】
- 使用 PQ 来确定下一个聚类的顶点对
- 聚类后更新邻居顶点的评分函数
- 预处理
- 移除单顶点网络【 ∣ e ∣ = 1 |e|=1 ∣e∣=1】
- 合并平行网络
- 建立指纹【在聚类前】
f ( e ) = ∑ v ∈ e v 2 \begin{equation} f(e)=\sum\limits_{v\in e}v^2 \end{equation} f(e)=v∈e∑v2 - 更新指纹【合并顶点 u 和顶点 v 时,保留顶点 u】
- 超边 e 不包含 u 和 v ,不需要更新
- 超边 e 同时包含 u 和 v , f ( e ) = f ( e ) − v 2 f(e)=f(e)-v^2 f(e)=f(e)−v2
- 超边 e 只包含 u ,不需要更新
- 超边 e 只包含 v , f ( e ) = f ( e ) − v 2 + u 2 f(e)=f(e)-v^2+u^2 f(e)=f(e)−v2+u2【但是论文中没有 − v 2 -v^2 −v2 】
- 建立指纹【在聚类前】
- 顶点合并 C ( u , v ) C(u,v) C(u,v)
- 评分函数
r ( u , v ) = ∑ e ∈ E u ∩ E v ω ( e ) ∣ e ∣ − 1 \begin{equation} r(u,v)=\sum\limits_{e\in E_u \cap E_v}\frac{\omega(e)}{|e|-1} \end{equation} r(u,v)=e∈Eu∩Ev∑∣e∣−1ω(e) - 合并步骤【将 v 替换为 u】
(1) ω ( u ) = ω ( u ) + ω ( v ) \omega(u)=\omega(u)+\omega(v) ω(u)=ω(u)+ω(v)
(2) v = u ⇔ v ∈ { E v − E u } v=u \Leftrightarrow v\in \{E_v-E_u\} v=u⇔v∈{Ev−Eu}
(3)删除 v ⇔ v ∈ { E v ∩ E u } v \Leftrightarrow v\in \{E_v \cap E_u\} v⇔v∈{Ev∩Eu} - 约束【满足约束的顶点才可以进行合并, t = 160 k t=160k t=160k】
ω ( v ) ≤ ⌈ ω ( V ) t ⌉ \begin{equation} \omega(v)\le \bigg\lceil \frac{\omega(V)}{t} \bigg\rceil \end{equation} ω(v)≤⌈tω(V)⌉ - 停止条件:不存在满足约束的顶点 或者 顶点数小于 t t t
- 评分函数
- 瓶颈【使用 n 级范式来消除】
- 初始划分
同上篇论文的 初始划分 一致,不过进行了优化,将被分割的网络生成两个小的网络的加入到对应的划分块中【上一篇论文是不考虑被分割的网络】
n 0 = { v ∣ v ∈ e ∧ b [ v ] ∈ V 0 } n 1 = { v ∣ v ∈ e ∧ b [ v ] ∈ V 1 } \begin{equation} \begin{aligned} n_0=\{ v\; |\; v\in e \wedge b[v] \in V_0\} \\ n_1=\{ v\; |\; v\in e \wedge b[v] \in V_1\} \end{aligned} \end{equation} n0={v∣v∈e∧b[v]∈V0}n1={v∣v∈e∧b[v]∈V1} - 局部搜索
- 优化
- 每个块一个优先队列【共计 k 个优先队列】【 Sanchis 的算法[16],优先队列数量为 k ( k − 1 ) k(k-1) k(k−1)】
- 顶点 v 的移动目标只考虑邻居块 Z ( v ) \Zeta(v) Z(v)
- 初始化
- 所有优先队列设置为空且禁用的。【禁用的优先队列不会考虑移动增益】
- 所有顶点都设置为不活跃的且未标记的。【未标记的顶点代表没有移动过】
- 局部搜索
- 激活所有边界顶点【如果不存在边界顶点,跳过这一轮局部搜索】【不考虑 ∣ e ∣ > 1000 |e|>1000 ∣e∣>1000 的超边的顶点】
- 计算边界顶点 v 的移动增益 G i ( v ) G_i(v) Gi(v) 并插入到对应优先队列 Q i Q_i Qi【只考虑顶点 v 的邻居划分块 Z ( v ) \Zeta(v) Z(v)】
G i ( v ) = ∑ e ∈ E v { ω ( e ) : Φ ( e , b ( v ) ) = 1 } − ∑ e ∈ E v { ω ( e ) : Φ ( e , V i ) = 0 } \begin{equation} G_i(v)=\sum\limits_{e \in E_v}\{\omega(e):\Phi(e,b(v))=1\}-\sum\limits_{e \in E_v}\{\omega(e):\Phi(e,V_i)=0\} \end{equation} Gi(v)=e∈Ev∑{ω(e):Φ(e,b(v))=1}−e∈Ev∑{ω(e):Φ(e,Vi)=0} - 激活所有轻负载的优先队列。
- 迭代移动【一个顶点一轮至多移动一次】
- 查询所有激活的优先队列,获得最高移动增益 G i ( v ) G_i(v) Gi(v)
- 如果满足平衡约束,移动该顶点 v 到划分块 V i V_i Vi,并将该顶点标记不活跃且已标记。否则,则跳过。
- 激活顶点 v 的所有不活跃的邻居顶点
- 如果邻居顶点不是边界顶点,则标记为不活跃的且从优先队列中删除其移动增益。
- 如果邻居顶点是边界顶点,则通过 D e l t a G a i n U p d a t e ( v , V f r o m , V t o ) DeltaGainUpdate(v, V_{from}, V_{to}) DeltaGainUpdate(v,Vfrom,Vto) 来更新邻居顶点的移动增益。
- 回滚移动,直到处于最优的目标状态。
- 自适应停止规则: l o g n log\;n logn 步非正增益移动,则停止。
- D e l t a G a i n U p d a t e ( v , V f r o m , V t o ) DeltaGainUpdate(v, V_{from}, V_{to}) DeltaGainUpdate(v,Vfrom,Vto)
【当一个顶点 v 移动后,在目标划分块 V t o V_{to} Vto 中可以连接到所有超边,则该划分块对于超边 e ∈ E v e\in E_v e∈Ev 来说是不可移动的。如果一个由于平衡约束而无法移动,则源划分块 V f r o m V_{from} Vfrom 对于超边 e ∈ E v e\in E_v e∈Ev 是不可移动的。如果源和目标划分块都是不可移动的,则这部分超边 e 不进行更新】- 遍历顶点 v 的所有超边 E v E_v Ev
- 对于 e ∈ E v e\in E_v e∈Ev,遍历超边 e 的所有顶点 u ∈ e u\in e u∈e
- 如果顶点 u 是已标记的,则跳过;【已经移动过的就不用更新了】
- 如果 Φ ( e , V f r o m ) = 0 \Phi(e,V_{from})=0 Φ(e,Vfrom)=0 【e 在划分块 V f r o m V_{from} Vfrom 已经没有顶点了】
- 如果 V f r o m ∉ Z ( u ) V_{from} \not\in \Zeta(u) Vfrom∈Z(u),则优先队列 Q f r o m Q_{from} Qfrom 移除顶点 u ;【如果划分块 V f r o m V_{from} Vfrom 不在是 u 的邻居块】
- 否则,优先队列 Q f r o m Q_{from} Qfrom 更新顶点 u 的增益 G f r o m ( u ) = G f r o m ( u ) − ω ( e ) G_{from}(u)=G_{from}(u)-\omega(e) Gfrom(u)=Gfrom(u)−ω(e) ;
- 如果 Φ ( e , V t o ) = 1 \Phi(e,V_{to})=1 Φ(e,Vto)=1 【顶点 v 移动后对 e 产生了新的划分块连接】
- 如果 V t o ∉ Z ( u ) V_{to} \not\in \Zeta(u) Vto∈Z(u) ,则依据公式 G_i(v) 计算 G t o ( u ) G_{to}(u) Gto(u) 并插入到优先队列 Q t o Q_{to} Qto 中;【如果对于 u 来说, V t o V_{to} Vto 是不是其邻居划分块】
- 否则,优先队列 Q t o Q_{to} Qto 更新顶点 u 的增益 G t o ( u ) = G t o ( u ) + ω ( e ) G_{to}(u)=G_{to}(u)+\omega(e) Gto(u)=Gto(u)+ω(e) ;
- 如果 b ( u ) = V f r o m ∧ Φ ( e , V f r o m ) = 1 b(u)=V_{from} \wedge \Phi(e,V_{from})=1 b(u)=Vfrom∧Φ(e,Vfrom)=1 ,更新顶点 u 的所有增益 G i ( u ) = G i ( u ) + ω ( e ) G_i(u)=G_i(u)+\omega(e) Gi(u)=Gi(u)+ω(e) ;【对于 e 来说,其在划分块 V f o r m V_{form} Vform 只剩下顶点 u 了,所以 u 移动到其他顶点就可以减少其的连接数】
- 如果 b ( u ) = V t o ∧ Φ ( e , V t o ) = 2 b(u)=V_{to} \wedge \Phi(e,V_{to})=2 b(u)=Vto∧Φ(e,Vto)=2 ,更新顶点 u 的所有增益 G i ( u ) = G i ( u ) − ω ( e ) G_i(u)=G_i(u)-\omega(e) Gi(u)=Gi(u)−ω(e) ;【对于 e 来说,原本 V t o V_{to} Vto 只有 u 一个顶点,所以它移动到其他划分块可以减少连接;但是 v 移动过来后,u 在移动到其他划分块就不会减少连接数,所以移动增益要减去 ω ( e ) \omega(e) ω(e) 】
- 对于 e ∈ E v e\in E_v e∈Ev,遍历超边 e 的所有顶点 u ∈ e u\in e u∈e
- 遍历顶点 v 的所有超边 E v E_v Ev
- 增益缓存
- 对于每个顶点 v ,用 O ( k ) \Omicron(k) O(k) 的空间来存放邻居划分块和移动到该块的增益。【可以在 O ( 1 ) \Omicron(1) O(1) 时间内添加和删除一个块,在 O ( ∣ Z ( v ) ∣ ) \Omicron(\big|\Zeta(v)\big|) O( Z(v) ) 内遍历所有邻居块,此外,还可以在 O ( 1 ) \Omicron(1) O(1) 时间内完成更新】
- 具体做法:
- 用 C v [ i ] C_v[i] Cv[i] 表示顶点 v 和划分块 V i V_i Vi 的缓存条目。
- 在初始划分结束后,计算每个顶点所有可能的移动增益。【每轮局部搜索都要重新计算相应顶点的移动增益(不需要全部顶点重新计算)】
- 每次激活顶点时,使用缓存增益值来激活顶点;
- 移动顶点后,缓存增益更新操作如下:【移动后顶点 v 的邻居划分块,有可能新增 V f r o m V_{from} Vfrom ,一定减少 V t o V_{to} Vto】
- 删除 C v [ t o ] C_v[to] Cv[to] ; 【因为顶点 v 移动到了划分块 V t o V_{to} Vto】
- 如果 V f r o m ∈ Z ( v ) V_{from} \in \Zeta(v) Vfrom∈Z(v) ,则 C v [ f r o m ] = − C v [ t o ] C_v[from]=-C_v[to] Cv[from]=−Cv[to] ;【如果划分块 V f r o m V_{from} Vfrom 是 v 的邻居划分块】
- 对于其他邻居划分块 V i V_i Vi ,遍历所有超边 e ∈ E v e\in E_v e∈Ev
- 如果 Φ ( e , V f r o m ) = 0 ∧ Φ ( e , V t o ) > 1 \Phi(e,V_{from})=0 \wedge \Phi(e,V_{to})>1 Φ(e,Vfrom)=0∧Φ(e,Vto)>1 ,则 C v [ V i ] = C v [ V i ] − ω ( e ) C_v[V_i]=C_v[V_i]-\omega(e) Cv[Vi]=Cv[Vi]−ω(e) 【原本在 from ,移动到其他块可以减少连接数,而移动到 to 时,超边 e 在 to 有其他顶点,所以如果要移动到其他块,就不会减少连接数,所以移动增益要减少】
- 如果 Φ ( e , V f r o m ) = 0 ∧ Φ ( e , V t o ) = 1 \Phi(e,V_{from})=0 \wedge \Phi(e,V_{to})=1 Φ(e,Vfrom)=0∧Φ(e,Vto)=1 ,则 C v [ V i ] = C v [ V i ] + ω ( e ) C_v[V_i]=C_v[V_i]+\omega(e) Cv[Vi]=Cv[Vi]+ω(e) 【原本在 from ,移动到其他块可以减少连接数,而移动到 to 时,超边 e 在 to 没有其他顶点,所以如果要移动到其他块,就会减少连接数,所以移动增益要增加】
- 回滚时同时回滚增益缓存
- 优化
- 实验结果:
- 测试用例:
- the ISPD98 VLSI Circuit Benchmark Suite [17]
- the University of Florida Sparse Matrix Collection [18]
- the international SAT Competition 2014 [19]
- 实验参数
- k = { 2 , 4 , 8 , 16 , 32 , 64 , 128 } ∪ { 5 , 23 , 47 , 107 } k=\{2,4,8,16,32,64,128\} \cup \{5,23,47,107\} k={2,4,8,16,32,64,128}∪{5,23,47,107}
- ϵ = 0.03 \epsilon=0.03 ϵ=0.03
- 比较对象
- PaToH-Q
- PaToH-D
- hMetis-R
- hMetis-K
- 测试用例:
五、实验结果
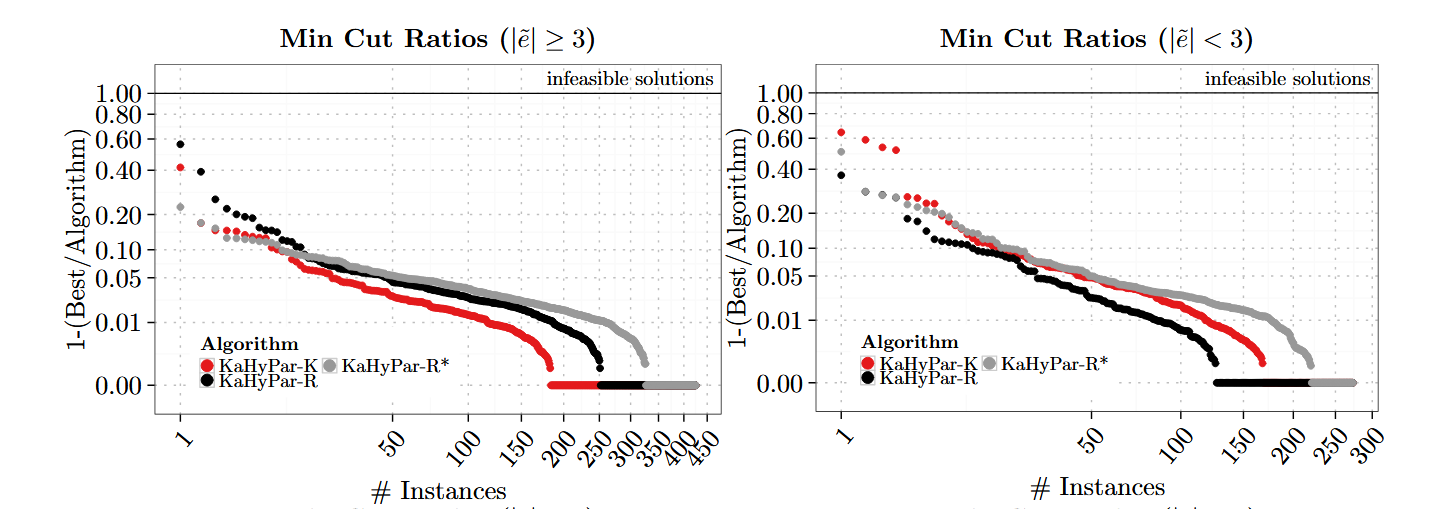
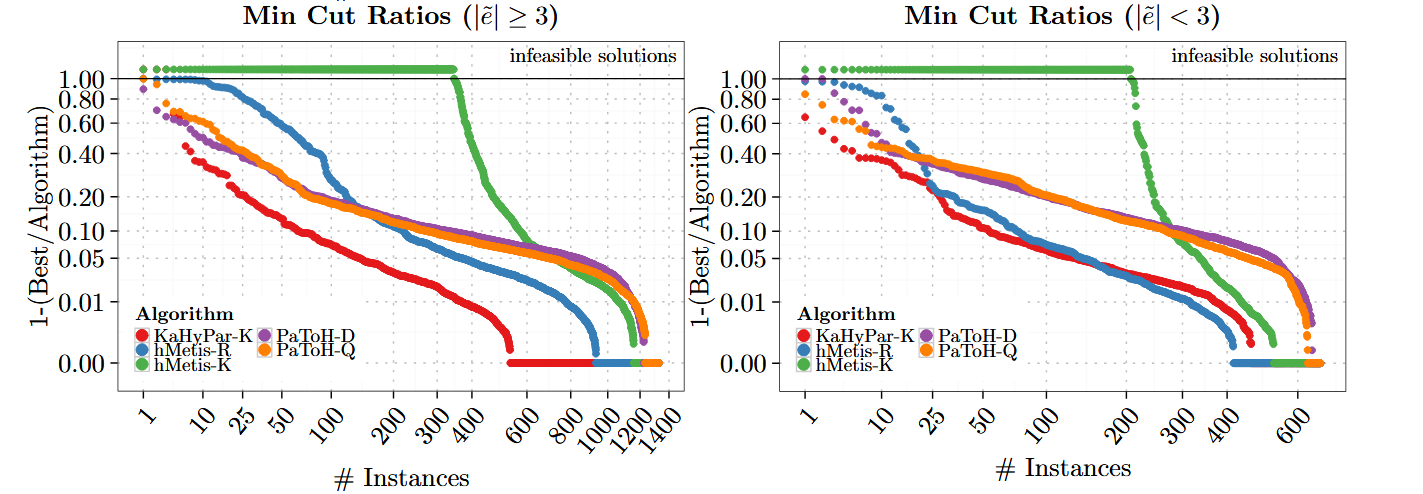
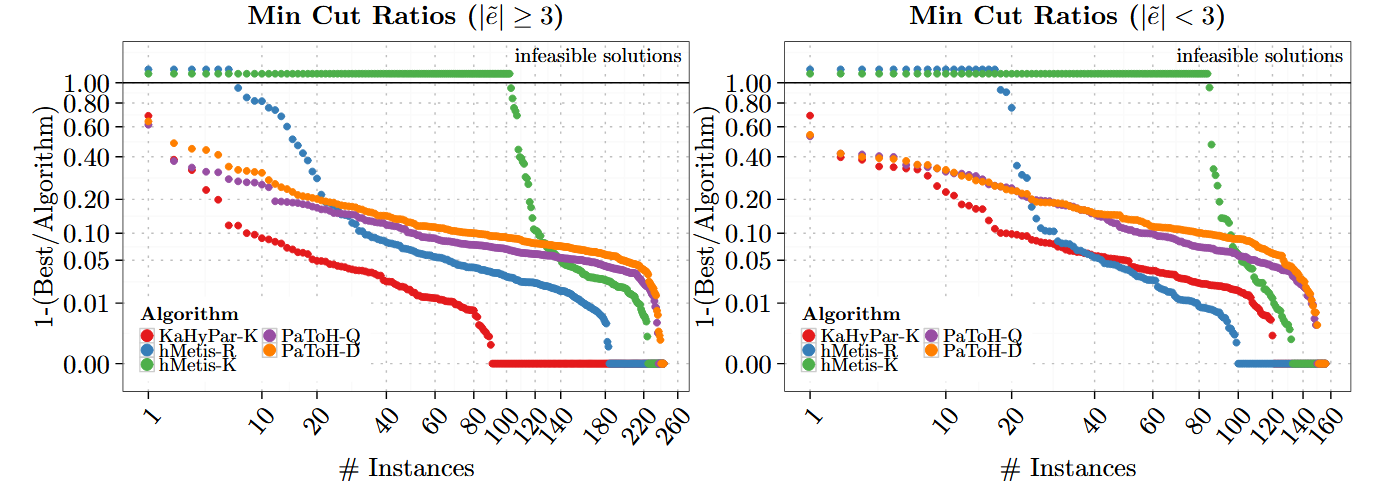
六、主要贡献
- 提出了 n 级直接 k 划分算法
- 引入 min-hash 技术,加快了聚类和局部搜索的计算速度
- 提出了一个聚类函数,消除了 PQ 的瓶颈且不会影响整体结果的质量
- 提出局部搜索算法,使用 DeltaGainUpdate 、增益缓存的技术来提高算法速度
- 提出了一种自适应停止规则
视频弹题功能实例)

—— 评估算法(一))

没有之一,已亲自使用!)






介绍)







 接口)