目录
1、核心思想
2、实现方式
2.1 模式结构
2.2 实现案例
3、优缺点分析
4、适用场景
5、注意事项
1、核心思想
目的:针对某种语言并基于其语法特征创建一系列的表达式类(包括终极表达式与非终极表达式),利用树结构模式将表达式对象组装起来,最终将其翻译成计算机能够识别并执行的语义树。
概念:解释器模式其实就是一种组合模式的特殊应用,它巧妙地利用了组合模式的数据结构,基于上下文生成表达式(解释器)组合起来的语义树,最终通过逐级递进解释完成上下文的解析。
核心思想:将每个语法规则表示为一个类,通过组合这些类实现复杂语法的解析
举例:
1> 结构型数据库对查询语言SQL的解析
2> 浏览器对HTML语言的解析
3> 操作系统Shell对命令的解析
4> 数学公式
5> 正则表达式
2、实现方式
2.1 模式结构
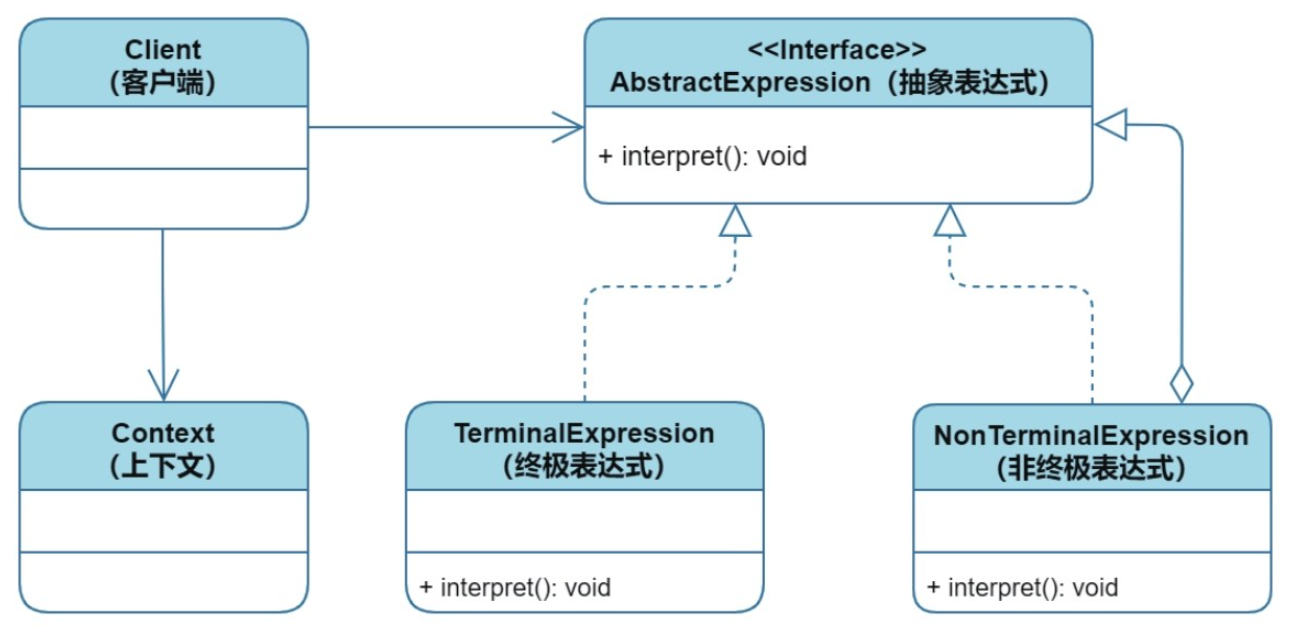
五个核心角色:
- AbstractExpression(抽象表达式):定义解释器的标准接口interpret(),所有终极表达式类与非终极表达式类均需实现此接口。
- TerminalExpression(终极表达式):抽象表达式接口的实现类,具有原子性、不可拆分性的表达式。表示语法中的基本元素(如变量、常量),直接完成具体的解释操作。
- NonTerminalExpression(非终极表达式):抽象表达式接口的实现类,包含一个或多个表达式接口引用,所以它所包含的子表达式可以是非终极表达式,也可以是终极表达式。表示语法中的组合规则(如运算、逻辑表达式),通过递归调用子表达式完成解释。
- Context(上下文):需要被解释的语言类,它包含符合解释器语法规则的具体语言。存储解释器需要的全局信息(如变量值、环境配置)。
- Client(客户端):构建语法树并触发解释操作。
2.2 实现案例
实现一个简单的加减法解释器,支持变量替换(如 x + y - 2):
//1、抽象表达式
public interface Expression {int interpret(Context context);
}//2、终极表达式
// 变量表达式(终结符)
public class Variable implements Expression {private String name;public Variable(String name) {this.name = name;}@Overridepublic int interpret(Context context) {return context.getValue(name); // 从上下文中获取变量值}
}// 数字表达式(终结符)
public class Number implements Expression {private int value;public Number(int value) {this.value = value;}@Overridepublic int interpret(Context context) {return value; // 直接返回数字值}
}//3、非终极表达式
// 加法表达式(非终结符)
public class Add implements Expression {private Expression left;private Expression right;public Add(Expression left, Expression right) {this.left = left;this.right = right;}@Overridepublic int interpret(Context context) {return left.interpret(context) + right.interpret(context);}
}// 减法表达式(非终结符)
public class Subtract implements Expression {private Expression left;private Expression right;public Subtract(Expression left, Expression right) {this.left = left;this.right = right;}@Overridepublic int interpret(Context context) {return left.interpret(context) - right.interpret(context);}
}//4、上下文:存储变量值
import java.util.HashMap;
import java.util.Map;public class Context {private Map<String, Integer> variables = new HashMap<>();public void setValue(String name, int value) {variables.put(name, value);}public int getValue(String name) {return variables.getOrDefault(name, 0);}
}//5、客户端:构建语法树并解释
public class Client {public static void main(String[] args) {Context context = new Context();context.setValue("x", 5);context.setValue("y", 3);// 构建表达式:x + y - 2Expression expression = new Subtract(new Add(new Variable("x"), new Variable("y")),new Number(2));int result = expression.interpret(context);System.out.println("计算结果:" + result); // 输出:6(5+3-2=6)}
}3、优缺点分析
优点:
-
易于扩展语法:新增语法规则只需添加新的表达式类。
-
符合单一职责原则:每个表达式类只负责一个语法规则。
-
灵活组合:通过嵌套表达式实现复杂逻辑。
缺点:
-
类数量膨胀:复杂语法需要大量表达式类,增加维护难度。
-
执行效率低:递归解释可能导致性能问题。
-
难以处理复杂语法:对层级嵌套较多的语法(如编程语言)支持较差。
4、适用场景
-
领域特定语言(DSL)
-
如SQL条件解析、金融规则引擎、游戏技能脚本。
-
-
简单语法解析
-
如数学表达式、布尔逻辑表达式、配置文件解析。
-
-
需要动态扩展语法
-
如工作流引擎中的条件分支配置。
-
5、注意事项
-
避免过度设计
-
若语法简单且稳定,可直接使用现成的解析库(如ANTLR、JavaCC)。
-
-
优化性能
-
对高频调用的解释器,可预编译表达式或缓存中间结果。
-
-
处理语法错误
-
需在解释过程中添加语法校验和异常处理逻辑。
-



















