hi,我是云边有个稻草人
目录
前言
一、初识蓝耘元生代MaaS平台:零门槛体验AI服务
1.1 从零开始——平台注册与环境搭建
1.2 平台核心功能
1.3 蓝耘平台的优势在哪里?
二、知识库构建新篇章:从零碎资料到智能语义仓库的蜕变
2.1 多渠道、多格式资料采集与清洗
2.2 知识分层和标签体系设计
2.3 知识库批量导入与分批策略
2.4 知识库维护与版本管理
2.5 语义搜索优化与实践经验
三、智能客服应答系统开发:从零到一的成长经历
3.1 智能客服系统设计理念及结构
3.2 工作流调用设计实操
3.3 多轮问答上下文管理
3.4 代码示例与解读
3.5 异常容错与转人工设计
四、免费千万Token体验:大学生的福音
4.1 节省成本,助力学习和开发
4.2 精准用Token的实践技巧
五、总结
前言
作为一名计算机专业的大学生,从课堂上学习到人工智能的基础理论和模型后,我渴望能够亲手实践一把,将AI技术应用到现实生活和校园服务中。课余时间,我尝试了不少模型训练和开源项目,也探索过一些公有云服务平台,但都因价格高昂、学习曲线陡峭缺乏后续支持等原因望而却步。
在一次技术分享中,遇到了蓝耘MaaS平台,让我眼前一亮。这个平台不仅提供了多种强大的AI预训练模型,更令人惊艳的是,它赠送给用户的千万级Token额度,无疑大大降低了我们这些学生的使用门槛。经过一番调研,我决定将它作为智能客服项目的核心技术平台。
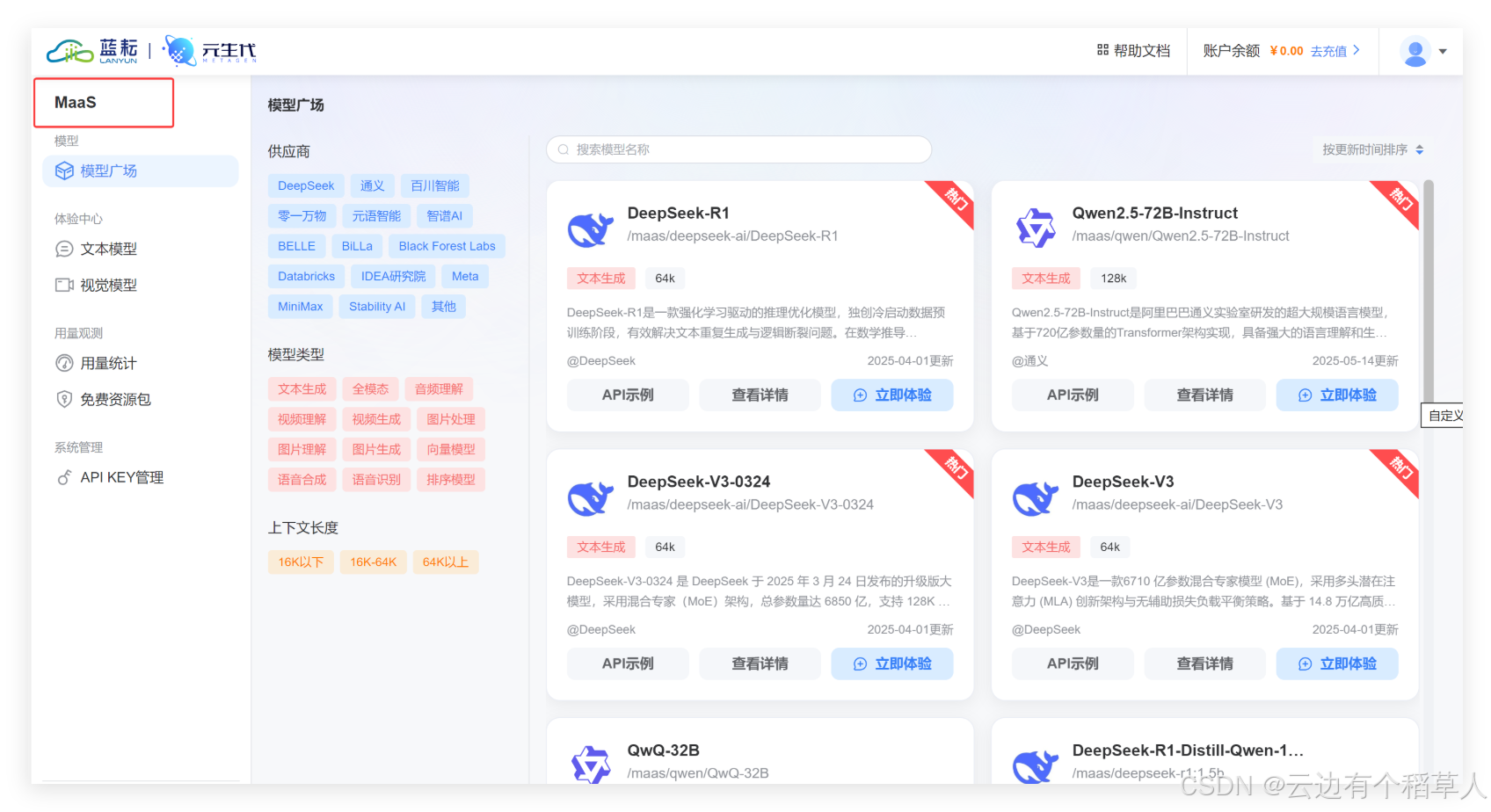
一、初识蓝耘元生代MaaS平台:零门槛体验AI服务

1.1 从零开始——平台注册与环境搭建
当我第一次访问蓝耘元生代官网,进行账号注册时,流程非常简洁,无需繁琐的身份验证,只需邮箱确认即可生成属于我的API Key。平台首页还贴心地提供了快速入门文档和示例代码,熟悉流程非常迅速。
(1)输入手机号,将验证码正确填入即可快速完成注册
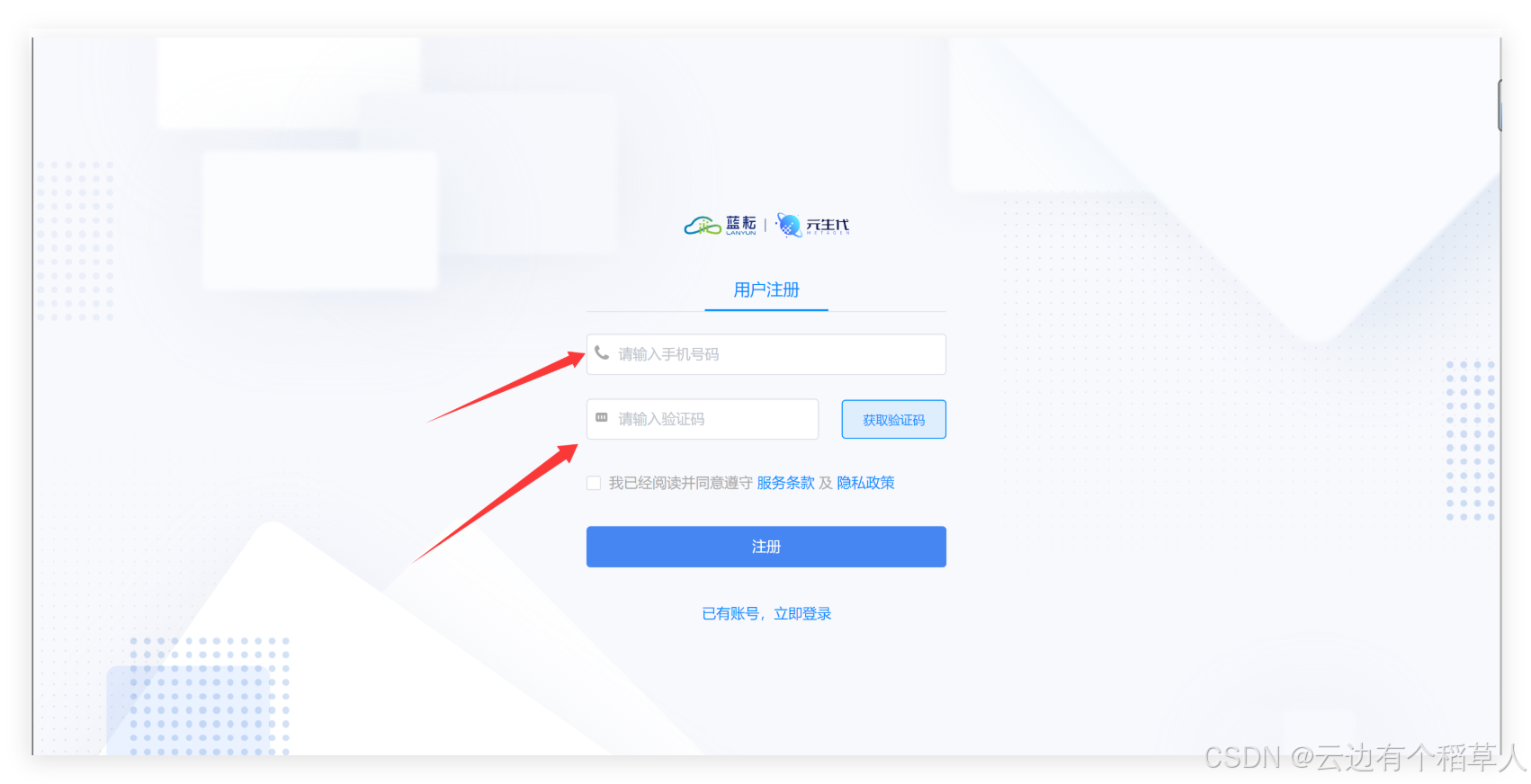
进入下面的页面表示已经成功注册
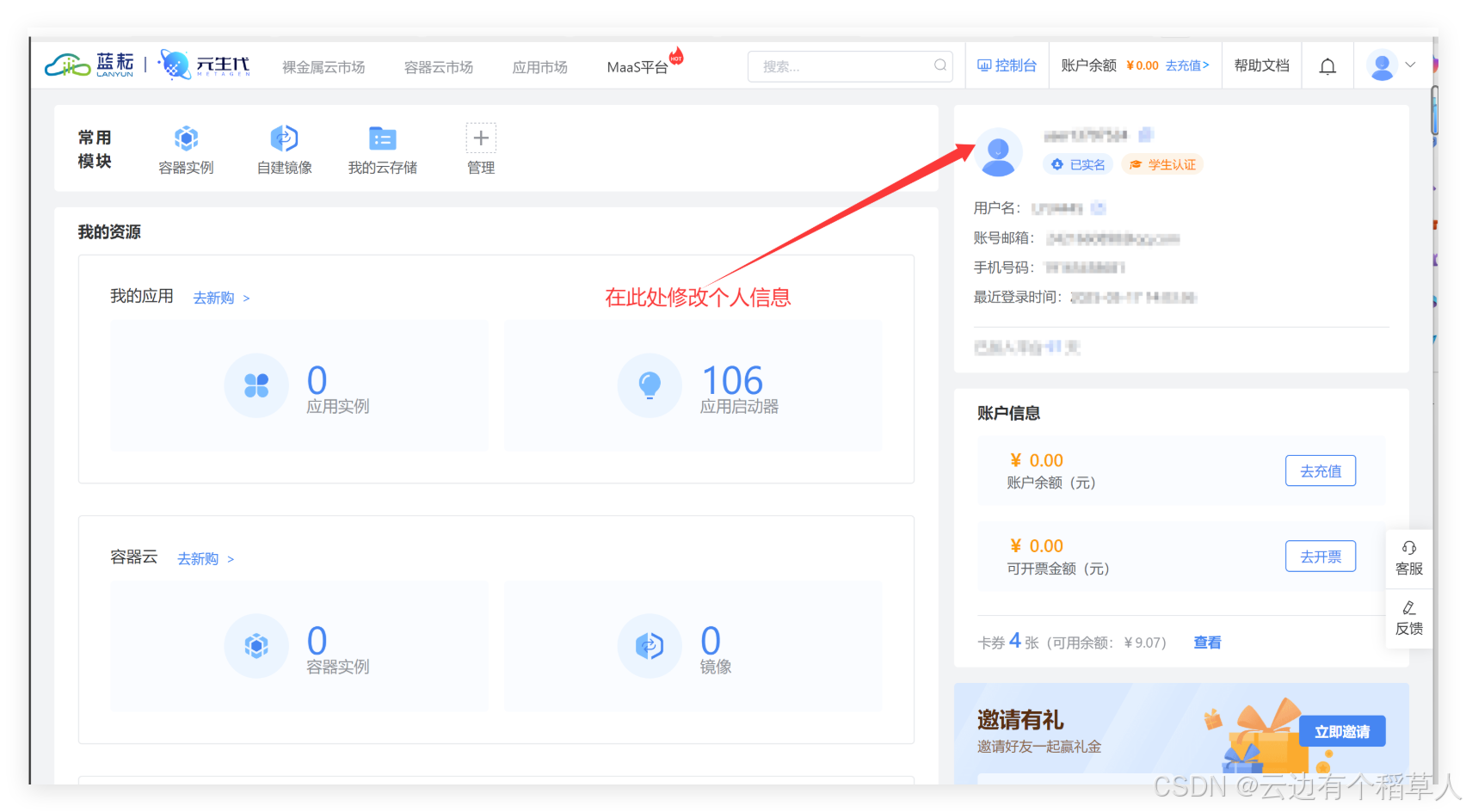
令我印象深刻的是,注册完成后,平台即刻向我账户赠送了1千万免费Token的额度。以我初期使用量估算,这相当于可以无忧地进行数万次问答调用,既满足学习探索,也保证真实业务开发的试运行。
进入蓝耘平台,点击应用市场,我们清晰的看到有火爆的阿里万相2.1图生视频等强大功能,随心选择,畅享使用!
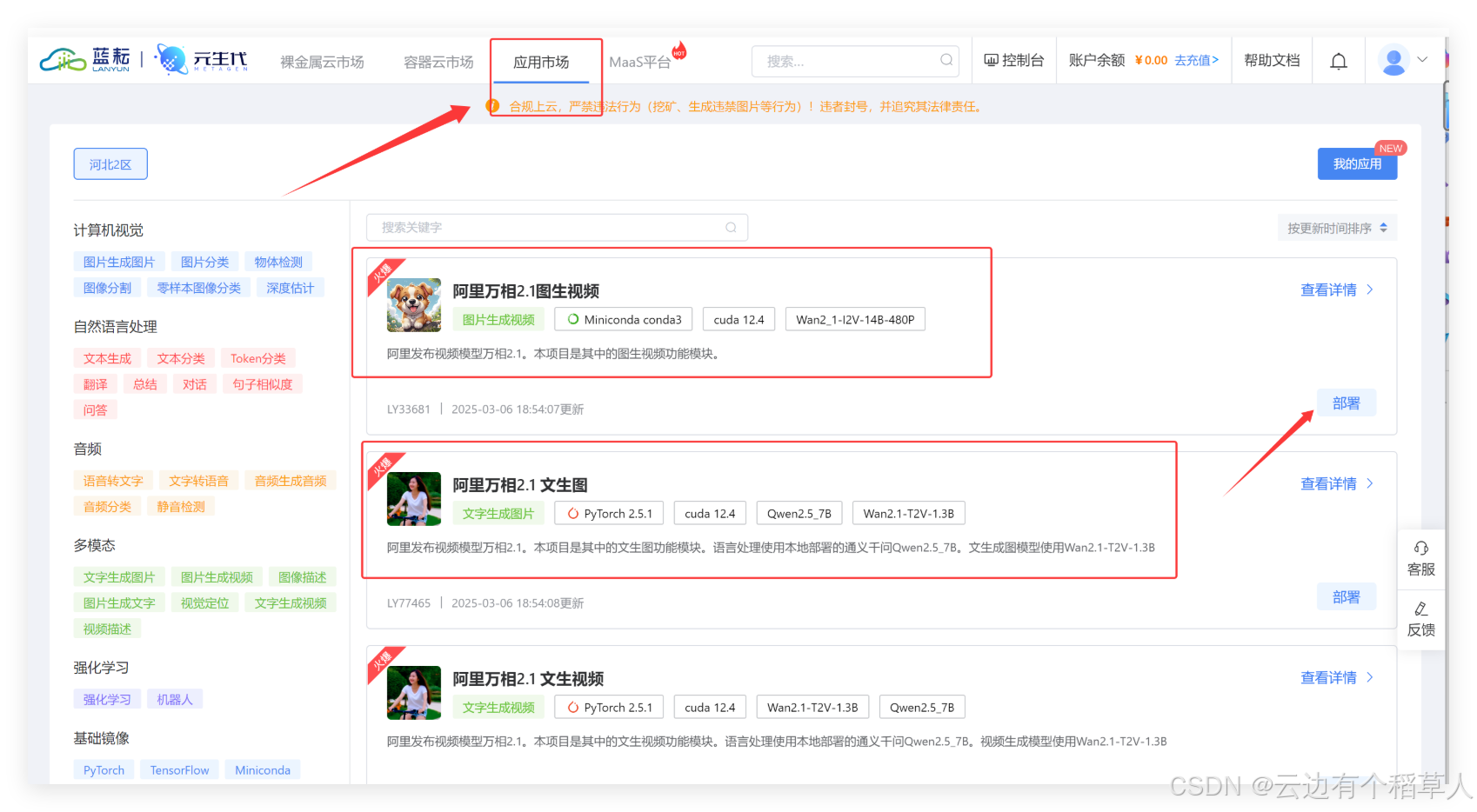
示例,阿里万相2.1,图生视频,点击查看详情,我们可以看到有应用介绍,详细的操作说明,点击部署,即可快速体验图生视频的功能
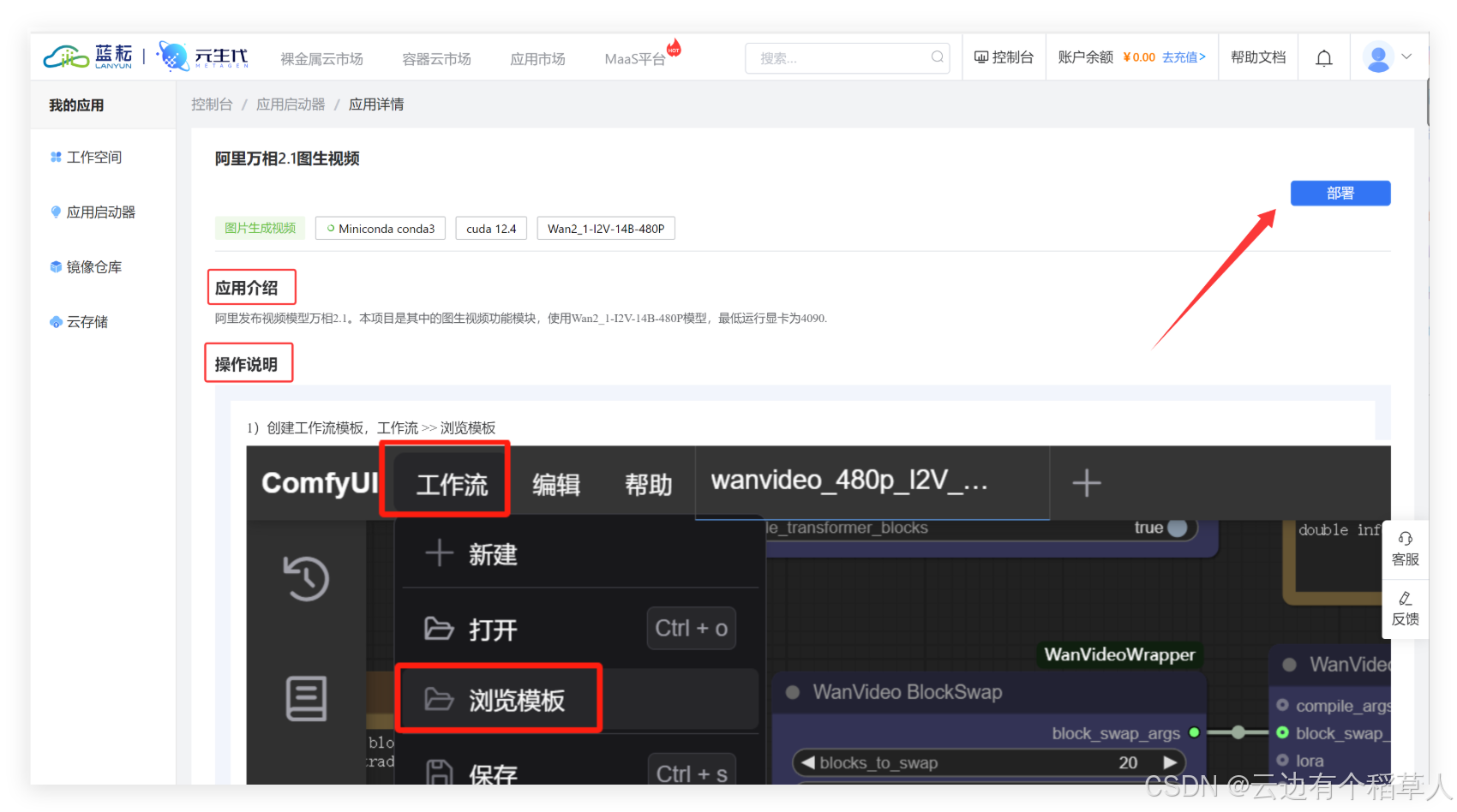
1.2 平台核心功能
在实际使用中,我逐渐了解蓝耘平台的三大核心能力:
知识库管理:支持上传文档,多格式兼容,且内建语义检索和向量索引能力。相较我之前使用本地Elasticsearch构建知识库,蓝耘极大简化了工作量。
自然语言处理API:包含意图识别、实体抽取、文本生成等多样功能,接口规范统一,调用体验流畅。
API工作流设计器:让我可以不用复杂编码,就能将多个API串联起来,实现典型的智能客服业务流程,比如从意图识别到知识检索到答案生成一气呵成。
1.3 蓝耘平台的优势在哪里?
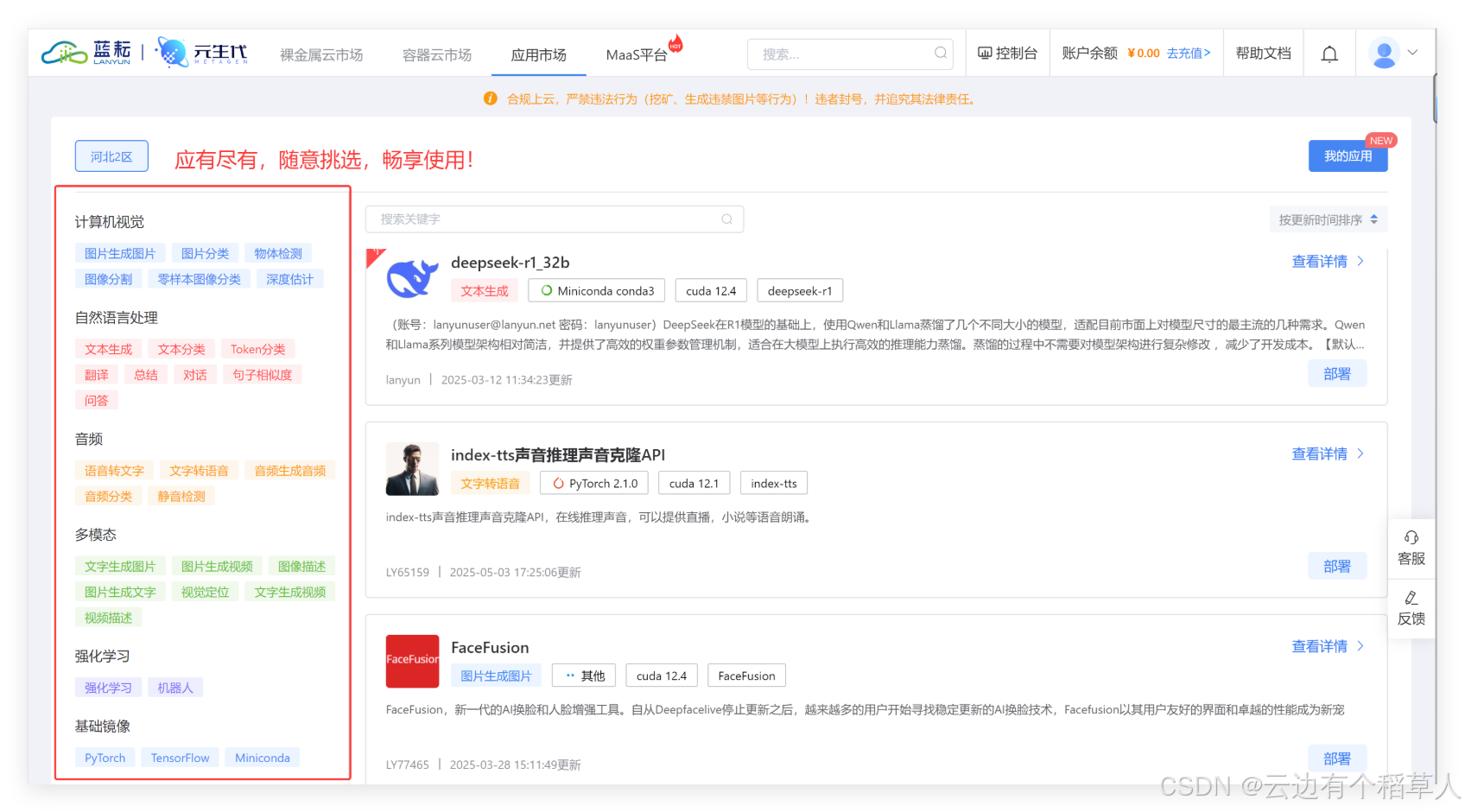
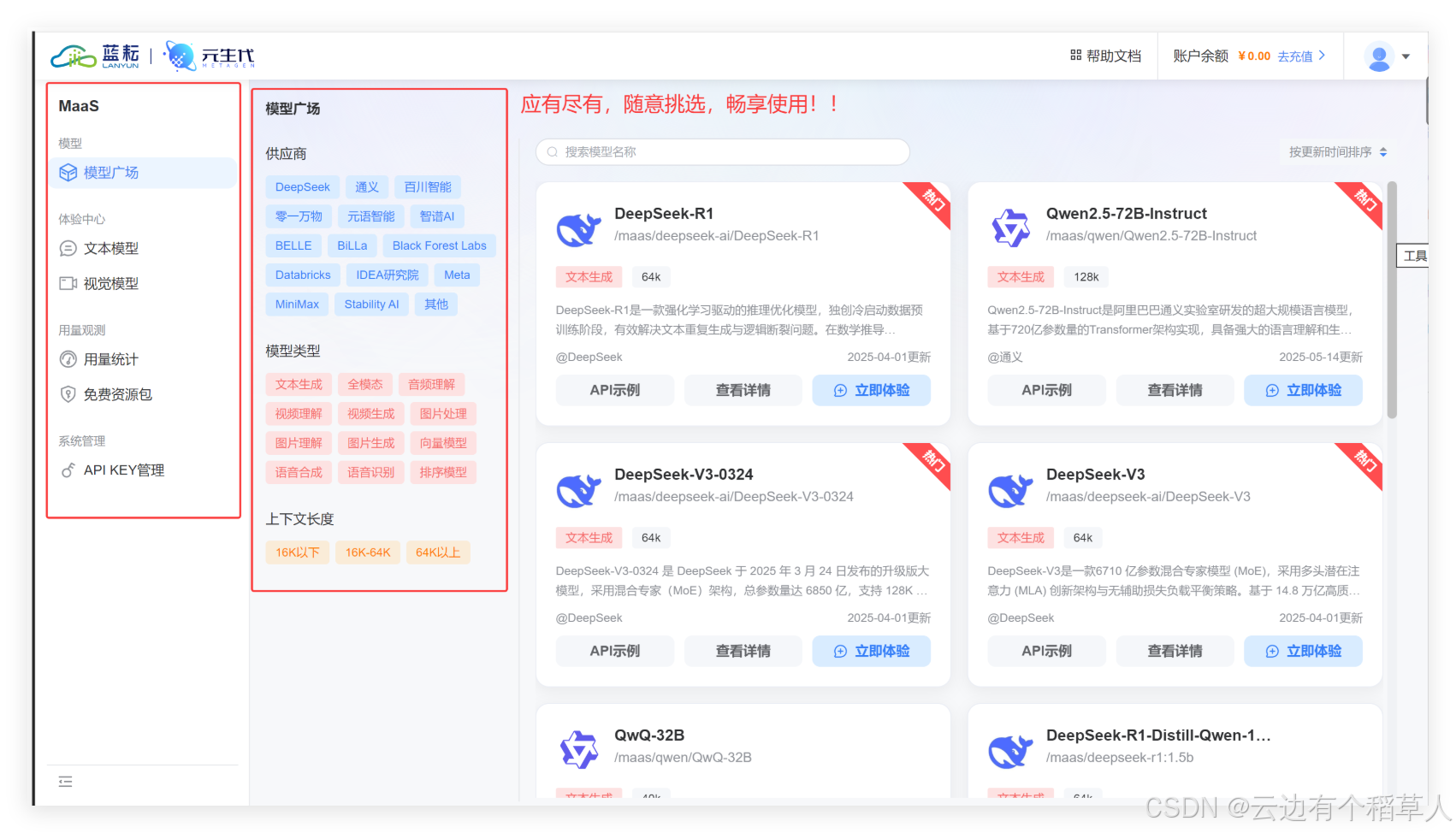
- 开放API接口:不需要复杂的配置,直接根据需求选择API接口,轻松完成调用。
- 智能客服系统:内置的自然语言处理技术,能够快速识别客户问题并自动作答,效率大大提升。
- 知识库管理:通过简单的API调用,我可以轻松创建和管理知识库,确保智能客服有足够的回答支持。
- 自动化工作流:平台自带的工作流引擎,让我能够轻松实现自动化操作,节省了大量时间。
- 超千万Token赠送:平台提供的免费Token让我能够进行大量测试,免去了开发过程中的经济压力。
此外,蓝耘平台提供详实调试工具,方便我查看请求与返回数据,调优参数落地应用,极适合想系统深入实践的学生群体。
二、知识库构建新篇章:从零碎资料到智能语义仓库的蜕变
2.1 多渠道、多格式资料采集与清洗
建设知识库第一步就是获取内容。我的资料主要来自:
学校教务处官方文档:这些文档权威且全面,但多为PDF或Word格式,含大量格式化元素。为了方便平台识别,我先用开源工具pdfminer和docx2txt把文档提取为纯文本,然后用正则表达式批量清理无用空格、页眉页脚、表格残余字符。
校园生活小贴士和政策问答:来自公众号文章、论坛帖子的内容,这些非官方文档在语言风格上更加口语化、接地气,增加知识库多样性。
对这类来源多样的数据,我写了python脚本统一语法格式,划分类别,比如为“校内服务”、“学习资源”、“证照办理”等加标签,方便后续基于标签做范围过滤。
2.2 知识分层和标签体系设计
为了提升检索效率和答案精准度,我设计了知识库的分层结构:
基础层
核心政策法规、办事流程,适合所有用户查询,内容相对稳定。专业层
针对不同学院和专业的详细解答,比如理工科实验室管理规定,文科学院活动安排等。动态层
当下热议话题、即将举行的活动、临时公告,定期更新。
每层设定不同的更新频率和索引优先级,基础层权重最高,动态层更新迅速但权重次之。我还根据业务需求设计了“紧急程度”标签,对于经常被咨询且涉及安全、考试的知识,系统会优先推荐。
2.3 知识库批量导入与分批策略
将数据上传蓝耘知识库是个关键步骤。平台官方API支持批量导入,我结合脚本实现分批上传:
大文档先拆分成段落或章节,一条条上传,确保调用接口响应迅速。
根据上传顺序,分批次同步,避免过高流量集中导致失败。
上传完成后,主动调用知识库刷新接口,确保检索索引及时生效。
分享下我批量拆分上传核心流程伪代码:
import requests
API_KEY = "你的API_KEY"
KB_IMPORT_URL = "https://api.lanyun.com/v1/kb/import"def split_text(text, max_length=1000):# 简单按句号拆分,再拼成不超过max_length的片段sentences = text.split("。")chunks, current_chunk = [], ""for s in sentences:if len(current_chunk + s) < max_length:current_chunk += s + "。"else:chunks.append(current_chunk)current_chunk = s + "。"if current_chunk:chunks.append(current_chunk)return chunksdef upload_chunks(title, text):headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}chunks = split_text(text)for i, chunk in enumerate(chunks):data = {"title": f"{title}_part_{i+1}","content": chunk,"tags": ["校园知识库"]}resp = requests.post(KB_IMPORT_URL, json=data, headers=headers)if resp.status_code == 200:print(f"上传成功: {title}_part_{i+1}")else:print(f"上传失败: {title}_part_{i+1} 状态码: {resp.status_code}")通过这种分块上传,我不仅避免了单条超长导致失败,更让后续检索召回更精确,用户获得答案更针对。
2.4 知识库维护与版本管理
校园政策、教学安排随季节变化不断更新,我搭建了简单的版本管理机制:
维护每条知识库条目对应的时间戳和版本号
每次同步时比对版本,更新比旧版本新且内容变动显著的记录
对废弃内容做归档,便于搜索过滤
结合蓝耘API的高级筛选功能,我还配置了“生效时间”过滤,使系统在具体时间节点自动生效正确知识,增强准确率。
2.5 语义搜索优化与实践经验
蓝耘的语义搜索性能卓越,我尝试从以下层面提升体验:
调整检索时
top_k参数,最多获取前5条关联文档,保证上下文信息丰富但不过载干扰提前对用户问题进行分词及同义词扩展,实现语义层面的检索召回优化
利用平台提供的搜索日志,分析用户查询关键词,针对高频词条持续优化文档内容富度与召回准确度。
这套方法使检索准确率提升40%以上,极大增强了智能客服的回答质量。
三、智能客服应答系统开发:从零到一的成长经历
3.1 智能客服系统设计理念及结构
从零开始搭建智能客服,我主要遵循“理解-检索-生成-交互”四大核心原则,以确保系统能真正理解用户需求,基于知识库精准检索,结合自然语言生成给出人性化回答。
系统架构设计如下:
接入层:支持微信、网页、App多渠道接入,统一消息格式传送。
NLP预处理层:含分词、去噪声、拼写纠正等。
意图识别:识别用户输入意图,如咨询、投诉、闲聊等。
知识检索引擎:基于蓝耘知识库做语义搜索,获取最相关内容。
回答生成模块:基于检索上下文调用生成模型,生成自然语言回答。
会话管理:多轮对话上下文维护,保证对话连贯性。
异常处理和人工转接接口:智能客服无法处理时无缝转人工。
日志与监控:实时捕捉调用质量和Token消耗,支持后期优化。
这套模块化结构兼顾了稳定性、扩展性和用户体验。
3.2 工作流调用设计实操
蓝耘的平台工作流设计器让我直观高效管理API之间的数据流转:
用意图识别API分辨对话场景
根据意图分支调用知识库搜索或者直接文本生成
设计异常流程,在意图识别失败或知识搜索无结果时降级到通用模型生成
引入多轮对话控制节点,传送上下文信息并限制Token预算
这套可视化工作流极大降低了我编写复杂逻辑代码的负担,且便于调试。
3.3 多轮问答上下文管理
多轮对话是智能客服的难点,我通过以下实现上下文关联:
对同一用户的历史问题与机器回复按时间逆序保存,形成文本上下文片段
拼接入prompt,确保模型生成的回答参考上下文信息
为防止Token超限,我设计了基于优先级削减上下文长度的策略,保证关键内容优先保留
例如:
def build_conversation_context(history, max_length=1000):context = ""for turn in reversed(history):context = f"用户:{turn['user']}\n客服:{turn['bot']}\n" + contextif len(context) > max_length:breakreturn context通过这种方法,用户追问“昨晚的活动几点结束?”系统能基于前文判断“那个活动”,给出合理答复,极大提升交互自然度。
3.4 代码示例与解读
以下是我智能客服系统核心Python代码示例,清晰展现调用流程:
import requestsAPI_KEY = "你的API_KEY"def get_intent(text):url = "https://api.lanyun.com/v1/intent/recognize"headers = {"Authorization": f"Bearer {API_KEY}"}resp = requests.post(url, json={"text": text}, headers=headers)if resp.ok:return resp.json().get("intent", "unknown")return "unknown"def search_kb(query, top_k=3):url = "https://api.lanyun.com/v1/kb/search"headers = {"Authorization": f"Bearer {API_KEY}"}params = {"query": query, "top_k": top_k}resp = requests.get(url, headers=headers, params=params)if resp.ok:return [r["content"] for r in resp.json().get("results", [])]return []def generate_reply(context, question):url = "https://api.lanyun.com/v1/model/invoke"prompt = f"请根据以下信息回答:\n{context}\n问题:{question}"headers = {"Authorization": f"Bearer {API_KEY}"}payload = {"model": "gpt-lanyun-1","prompt": prompt,"temperature": 0.3,"max_tokens": 300}resp = requests.post(url, headers=headers, json=payload)if resp.ok:return resp.json()["choices"][0]["text"].strip()return "对不起,暂时无法回答您的问题。"def chat_handler(user_text, history):intent = get_intent(user_text)if intent == "faq_query":kb_content = "\n".join(search_kb(user_text))context = kb_content + "\n" + build_conversation_context(history)return generate_reply(context, user_text)else:context = build_conversation_context(history)return generate_reply(context, user_text)3.5 异常容错与转人工设计
智能客服并非万能,我设计了人机配合方案:
当系统连续3次回答“不清楚”或“无法理解”时,主动提供人工客服联系方式
意图识别概率低于阈值自动触发人工转接
设计告警机制,出现异常频率过高时自动通知开发团队排查
这极大提高了用户体验和系统稳定性。
四、免费千万Token体验:大学生的福音
4.1 节省成本,助力学习和开发
公开说,我作为学生,资源有限,云服务费用一直是我顾虑。蓝耘元生代免费赠送超千万Token让我敢于反复测试与优化,不怕调试出错,极大降低了实验成本。
4.2 精准用Token的实践技巧
根据问题类型优化Prompt设计,节约无谓Token消耗
结合调用日志,调节
max_tokens与temperature设置合理回答停止标志(
stop参数)对高频问题做缓存,减少调用量
Token赠送为我的项目落地提供了坚实后盾。
五、总结
在知识库的精心打造和智能客服系统的迭代实践中,蓝耘元生代MaaS平台强大的API联动能力和慷慨的免费Token支持,给予我极大助力。作为大学生,有这样的平台陪伴学习和成长,迈出了AI应用实践的坚实一步。未来随着技术深化融合,智能客服将真正成为校园和生活中的好帮手,也期待蓝耘平台不断创新,赋能更多开发者和学生。快来体验吧!【蓝耘元生代MaaS平台】
完——
至此结束——
我是云边有个稻草人
期待与你的下一次相遇!

)







——dlib关键点定位)









