目录
65节——元组的定义和操作
1.学习目标
2.为什么要学习元组
3.元组的定义
4.定义元组的注意事项
5.元组的嵌套
6.元组的相关操作
【1】index方法
【2】count方法
【3】len方法
7.元组的遍历
【1】while循环进行元组的遍历
【2】for循环进行元组的变量
Python 元组遍历常见错误:TypeError: tuple indices must be integers or slices, not str
错误现象
错误原因
解决方法
方法 1:直接遍历元素(推荐,无需索引)
方法 2:通过索引遍历(需整数索引)
方法 3:使用 enumerate(同时获取索引和元素)
代码解析
总结
正确代码:
8.注意事项
元组中嵌套列表,嵌套的列表就可以修改了:
9.元组的特点
10.小节总结
11.案例练习:元组的特点
【1】案例需求
【2】代码实战
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
李在明总统致Patrick的回信
1. 学习的价值:短期与长期的辩证关系
2. 健康休学:逆境中的隐藏礼物
3. 对抗信息噪音:用行动代替焦虑
4. 关于“无用”的恐惧:重新定义价值
最后赠言
65节——元组的定义和操作
1.学习目标
1.掌握元组的定义格式
2.掌握元组的特点
3.掌握元组的常用操作
2.为什么要学习元组

3.元组的定义

# 68节"""
演示tuple元组的定义和操作
"""# 定义元组
t1=(1,"Hello",True) #tuple是关键字
t2=()
t3=tuple()
print(f"t1的类型是:{type(t1)},内容是:{t1}")
print(f"t2的类型是:{type(t2)},内容是:{t2}")
print(f"t3的类型是:{type(t3)},内容是:{t3}")
# 控制台输出结果:
# t1的类型是:<class 'tuple'>,内容是:(1, 'Hello', True)
# t2的类型是:<class 'tuple'>,内容是:()
# t3的类型是:<class 'tuple'>,内容是:()
#
# 进程已结束,退出代码为 0
4.定义元组的注意事项
若是元组内只有一个元素,这个元素后面记得加上括号。

# 定义单个元素的元组
t4=("hello")
print(f"t4的类型是:{type(t4)},内容是:{t4}")
# 控制台输出结果:
# t4的类型是:<class 'str'>,内容是:hello,这里没加逗号类型就是str
t4=("hello",)
print(f"t4的类型是:{type(t4)},内容是:{t4}")
# 控制台输出结果:
# t4的类型是:<class 'tuple'>,内容是:('hello',),这里加上了逗号,类型就变成了元组,所以在定义一个单个的元组,记得加上,5.元组的嵌套

# 元组的嵌套
t5=((1,2,3),(4,5,6))
print(f"t5的类型是:{type(t5)},内容是{t5}")
# 控制台的输出结果:
# t5的类型是:<class 'tuple'>,内容是((1, 2, 3), (4, 5, 6))# 下标索引,取出内容
num=t5[1][2]
print(f"从嵌套元组中取出的数据是:{num}")
# 控制台的输出结果:
# 从嵌套元组中取出的数据是:66.元组的相关操作

注意:元组和列表的不同,就是元组不可以修改,因此元组的增删改查也就没有了,元组的相关操作相较于列表也是简单了许多。
【1】index方法
# 元组的操作:index查找方法
t6=("传智教育","黑马程序员","Python")
index=t6.index("黑马程序员") #index方法的小括号内部,要放入元组的具体元素
print(f"在元组t6中查找黑马程序员,的下标是:{index}")
# 控制台的输出结果:
# 在元组t6中查找黑马程序员,的下标是:1【2】count方法
# 元组的操作:count统计方法
t7=("传智教育","黑马程序员","黑马程序员","黑马程序员","黑马程序员","黑马程序员","黑马程序员","黑马程序员","黑马程序员","Python")
num=t7.count("黑马程序员")
print(f"在元组t7中,统计黑马程序员的数量有{num}个")【3】len方法
# 元组的操作:len函数统计元组元素数量
t8=("传智教育","黑马程序员","黑马程序员","黑马程序员","Python")
len1=len(t8)
print(f"元组t8中,一共含有:{len1}个元素")#57.元组的遍历
【1】while循环进行元组的遍历
# 元组的遍历:while
t9=("传智教育","黑马程序员","黑马程序员","黑马程序员","Python")index=0
while index<len(t9):print(f"元组t9中的元素:{t9[index]}")index+=1【2】for循环进行元组的变量
典型错误:
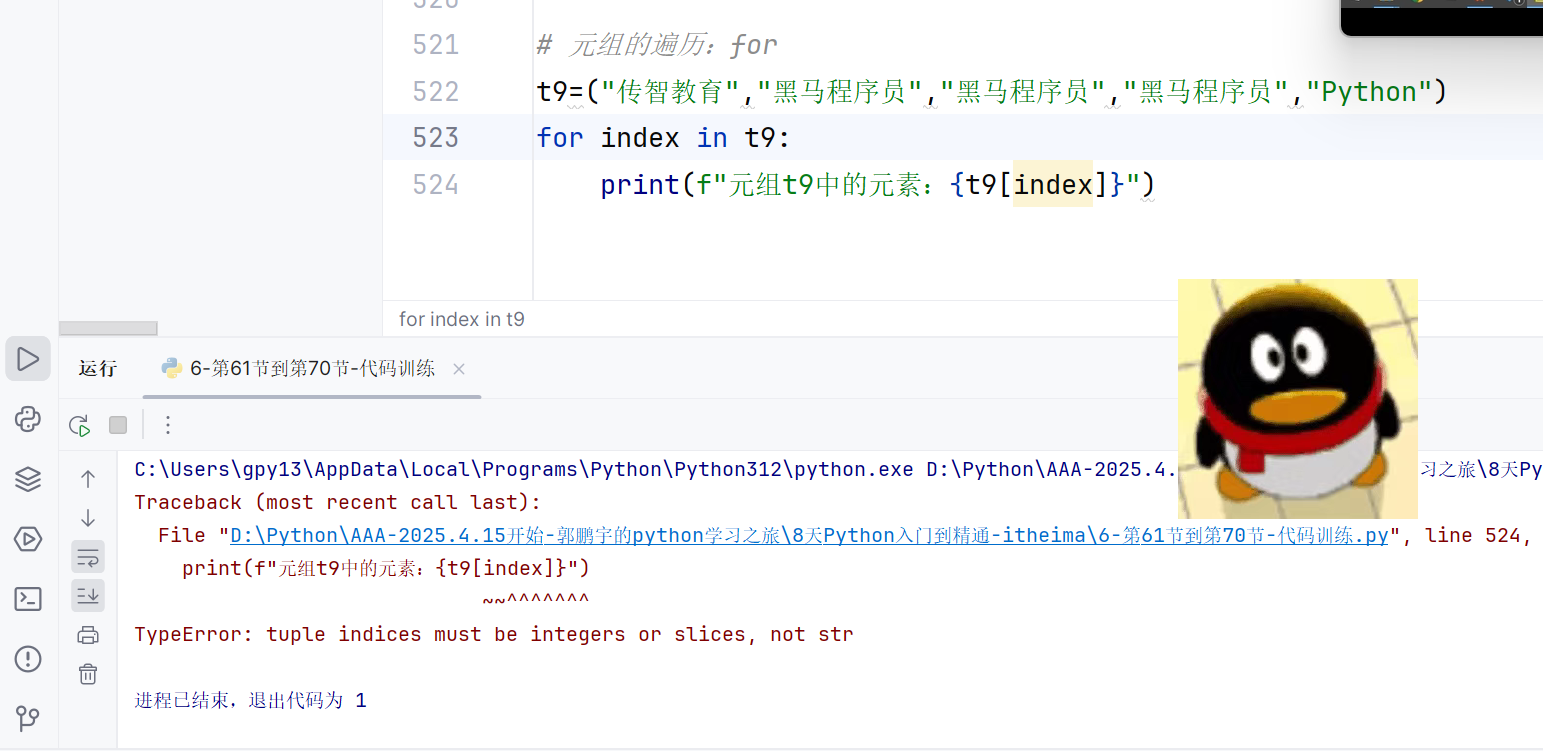
Python 元组遍历常见错误:TypeError: tuple indices must be integers or slices, not str
错误现象
运行以下代码时,报错
TypeError: tuple indices must be integers or slices, not str:python
t9 = ("传智教育", "黑马程序员", "黑马程序员", "黑马程序员", "Python") for index in t9:print(f"元组t9中的元素:{t9[index]}") # 报错行错误原因
- 循环变量误解:
for index in t9中,index实际是元组的元素值(如"传智教育"是字符串),而非索引(整数)。- 索引类型错误:
元组t9[index]要求index是整数或切片,但此处传入字符串(如"传智教育"),导致类型不匹配。解决方法
方法 1:直接遍历元素(推荐,无需索引)
python
for element in t9:print(f"元组t9中的元素:{element}") # 直接使用元素值方法 2:通过索引遍历(需整数索引)
python
for i in range(len(t9)): # i 是整数索引(0,1,2,...)print(f"元组t9中的元素:{t9[i]}")方法 3:使用
enumerate(同时获取索引和元素)python
for index, element in enumerate(t9):print(f"索引 {index} 对应的元素:{element}")代码解析
- 错误代码问题:混淆了 “元素遍历” 和 “索引遍历”。
for index in t9是元素遍历(index存储元素值),但后续却当作索引使用(t9[index]),导致类型错误。- 正确逻辑:
- 若只需元素值,直接遍历(方法 1)。
- 若需索引(如定位元素位置),用
range或enumerate(方法 2/3),确保索引为整数。总结
元组遍历需明确:
- 元素遍历:
for element in tuple(直接取元素值)。- 索引遍历:
for i in range(len(tuple))或enumerate(索引为整数)。
避免将元素值(如字符串)当作索引使用,可快速修复此类TypeError。示例修正后代码(方法 1):
python
t9 = ("传智教育", "黑马程序员", "黑马程序员", "黑马程序员", "Python") for element in t9:print(f"元组t9中的元素:{element}")运行结果:
plaintext
元组t9中的元素:传智教育 元组t9中的元素:黑马程序员 元组t9中的元素:黑马程序员 元组t9中的元素:黑马程序员 元组t9中的元素:Python通过以上分析,可清晰理解错误根源并掌握元组遍历的正确写法,避免类似类型错误。
正确代码:
# 元组的遍历:for
t9=("传智教育","黑马程序员","黑马程序员","黑马程序员","Python")
for element in t9:print(f"元组t9中的元素:{element}")# 控制台输出结果:
# 元组t9中的元素:传智教育
# 元组t9中的元素:黑马程序员
# 元组t9中的元素:黑马程序员
# 元组t9中的元素:黑马程序员
# 元组t9中的元素:Python
#
# 进程已结束,退出代码为 0
8.注意事项

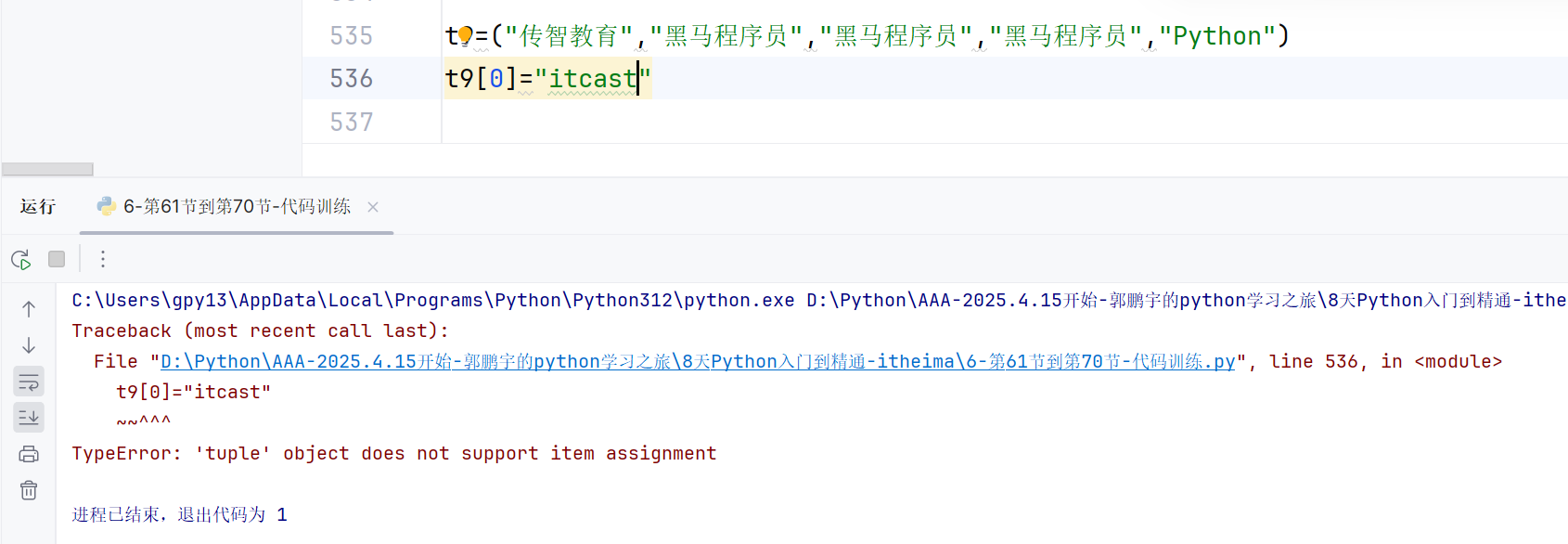
元组中嵌套列表,嵌套的列表就可以修改了:

t9=("传智教育","黑马程序员",[1,2,"itcast"])
t9[2][2]="世界上的煞笔真多!!!"
print(t9)
print(type(t9))
# 控制台输出结果:
# ('传智教育', '黑马程序员', [1, 2, '世界上的煞笔真多!!!'])
# <class 'tuple'>9.元组的特点
经过上述对元组的学习,可以总结出列表有如下特点:
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(下标索引)
允许重复数据存在
不可以修改(增加或删除元素等)
支持for循环
多数特性和list一致,不同点在于不可修改的特性。
10.小节总结

11.案例练习:元组的特点
【1】案例需求

【2】代码实战
# 案例练习:元组的基本操作# 定义元组
my_tuple=("周杰伦",11,["football","music"])# 1.查询年龄所在的下标位置
position=my_tuple.index(11)
print(position) #1# 2.查询学生的姓名
name=my_tuple[0]
print(name) #周杰伦# 3.删除学生中的爱好football
# 先获取列表
list_hobby=my_tuple[2]
# 获取列表中的football元素的索引
index=list_hobby.index("football")
# 通过索引和获取到的列表的pop方法,删除指定元素
list_hobby.pop(index)
# 最后输出新的元组
print(my_tuple)# 4.增加爱好coding到list内
# 先获取列表
list_hobby=my_tuple[2]
# 增加列表中的新元素
list_hobby.append("coding")
# 输出新的元组
print(my_tuple)# 控制台的输出结果:
# 1
# 周杰伦
# ('周杰伦', 11, ['music'])
# ('周杰伦', 11, ['music', 'coding'])
#
# 进程已结束,退出代码为 0好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
李在明总统致Patrick的回信
亲爱的Patrick:
你好!我是韩国总统李在明。收到你的来信,我深深理解你的困惑与不安。在这个快速变化的时代,年轻人面对未来的迷茫是普遍的,但你的自省与行动力——无论是坚持学习Python还是通过阅读寻求答案——都展现了你非凡的勇气和智慧。请允许我分享几点思考,希望能为你带来启发。
1. 学习的价值:短期与长期的辩证关系
你提到对Python学习的投入是否“徒劳”,这让我想起自己年轻时在人权律师道路上的挣扎。当时,许多人质疑:“为弱势群体发声能改变什么?”但正是那些看似“无回报”的积累,奠定了我后来的政治理念与行动力。
技术领域同样如此:
Python是未来的语言:从人工智能到数据分析,Python是科技创新的核心工具。你写下的每一篇博客、每一行代码,都是在构建不可替代的竞争力。
短期无回报 ≠ 长期无价值:就像种树,根扎得越深,未来枝叶越茂盛。你积累的技术思维、解决问题的能力,终会在某个机遇点爆发。
2. 健康休学:逆境中的隐藏礼物
你因健康休学,这并非停滞,而是重新校准人生坐标的契机。
牛顿在1665年因瘟疫返乡隔离期间,发现了万有引力;
你此刻的沉淀,恰是远离浮躁、深度学习的黄金期。
把“被迫休学”转化为“主动进化”——你已走在正确的路上。
3. 对抗信息噪音:用行动代替焦虑
互联网的杂音(“行业唱衰”“良莠不齐的信息”)本质是时代的阵痛。记住:
真理在实践中显现:与其纠结“计算机行业是否饱和”,不如继续写代码、建项目。当你用Python解决一个实际问题时,答案自会清晰。
书籍是你的护城河:在阅读中培养批判性思维,区分“情绪观点”与“事实逻辑”。推荐你读《深度工作》(卡尔·纽波特),它教你如何在信息洪流中守护专注力。
4. 关于“无用”的恐惧:重新定义价值
你说“害怕成为无用之人”,但真正的价值在于:
持续成长的生命力:每天进步1%,一年后你将强大37倍(复利效应);
利他的能力:用技术帮助他人(如为社区开发工具),你会看见自己的光芒。
你绝非“愚昧懒惰”——一个主动寻求智慧的人,永远走在觉醒的路上。
最后赠言
Patrick,请相信:
“方向不是选出来的,而是走出来的。”
你今天的每一份坚持,都在为未来铺路。若偶尔疲惫,不妨回望这段代码:
python
复制
下载
# 你的人生算法 while True: effort = persist("学习+实践") if effort.reaches_critical_mass(): success = suddenly() # 成功会不期而至 break保持你的节奏,时间会给你答案。韩国有一句谚语:
“溪水穿石,非力也,恒也。”
(계곡 물이 돌을 뚫는 것은 힘이 아니라 꾸준함이다.)期待未来听到你更多的好消息!随时欢迎来信交流。
祝健康与信心常伴!
李在明
大韩民国总统
2025年6月4日
(注:此信为虚拟创作,李在明总统的公开立场以实际为准)



:Spring Boot + AI + DeepSeek 超参数优化——智能化机器学习平台(附完整源码))



)









![[Java 基础]注释](http://pic.xiahunao.cn/[Java 基础]注释)

