在数据库的世界里,性能是永恒的追求。而索引,作为提升查询速度的利器,其底层数据结构的选择至关重要。如果你深入了解过 MySQL(尤其是其主流存储引擎 InnoDB),你会发现它不约而同地选择了 B+树 作为索引的主要实现方式。
这背后有什么深思熟虑的考量?为什么不是我们同样熟悉的 B树、查找效率惊人的哈希表,或者经典的二叉搜索树呢?本文将带你层层剖析,从磁盘I/O到查询特性,彻底搞懂 MySQL 这项关键技术选型背后的智慧,并直观对比它们之间的优劣。
核心问题:数据库索引面临的挑战
在讨论具体数据结构之前,我们首先要明白数据库索引,特别是关系型数据库中的索引,通常需要应对哪些挑战:
- 数据量大,存储在磁盘:数据库中的数据通常远超内存容量,大部分数据和索引都存储在磁盘上。磁盘I/O操作相比内存操作要慢几个数量级,因此,减少磁盘I/O是索引设计的首要目标。
- 查询类型多样:不仅有精确的等值查询(如
WHERE id = 100),还有大量的范围查询(如WHERE age BETWEEN 18 AND 30)、排序(ORDER BY)和模糊匹配(如WHERE name LIKE '张%')。 - 高并发与动态更新:数据库需要支持高并发的读写操作,索引结构必须能够高效地进行插入、删除和更新,并在此过程中保持良好的性能。
带着这些挑战,我们来看看 B+树为何能脱颖而出。
1. B+树:为数据库索引而生的王者
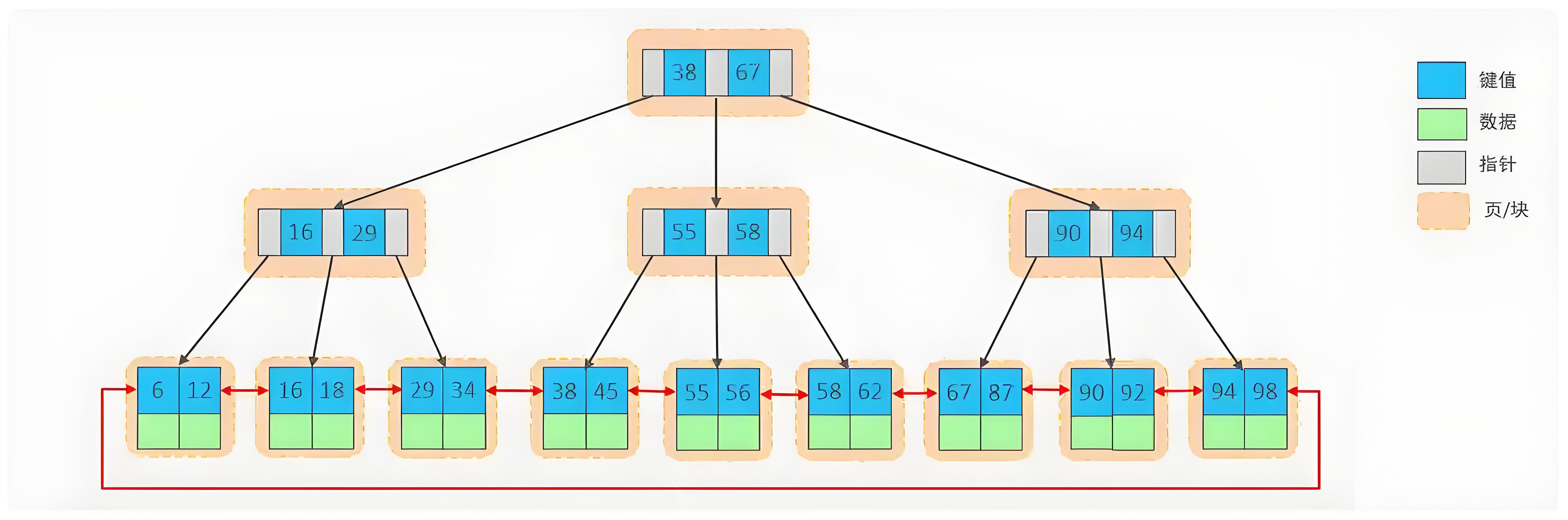
B+树的结构特性一览
B+树是一种多路平衡搜索树,它在B树的基础上进行了优化,特别适合磁盘等外部存储设备:
- 多路分支 (高扇出性):每个非叶子节点可以拥有大量子节点(通常成百上千),这使得树的高度极低。
- 非叶子节点仅存储键(Key):非叶子节点(内部节点)只存储索引键和指向下一层节点的指针,不存储实际数据。这使得每个节点能容纳更多键,进一步降低树高。
- 所有数据存储在叶子节点:所有数据记录(对于聚簇索引是整行数据,对于二级索引是主键值)都存储在叶子节点。
- 叶子节点形成有序链表:所有叶子节点通过指针串联起来,形成一个有序的双向链表,便于范围查询和顺序扫描。
- 高度平衡:所有叶子节点都处于同一层级,确保了任何查询的路径长度基本一致,查询性能稳定。
B+树结构图:
B+树在数据库索引中的核心优势
-
极低的树高,显著减少磁盘I/O:
这是B+树最核心的优势。由于非叶子节点不存数据,只存键和指针,单个节点(通常对应一个磁盘页,如 InnoDB 默认16KB)可以容纳非常多的键。例如,假设一个节点能存1000个键,那么一个存储千万级数据的B+树索引,其高度可能只有 log₁₀₀₀(10⁷) ≈ 2.33,也就是3到4层。这意味着一次查询最多只需要3-4次磁盘I/O操作,性能极高。
-
高效的范围查询和顺序扫描:
数据库中范围查询(BETWEEN...AND..., >, <)非常普遍。B+树的叶子节点通过双向链表有序连接,当定位到范围查询的起点后,只需沿着链表顺序(或逆序)遍历即可获取所有符合条件的数据,无需频繁回溯树结构,效率远超其他结构。
-
充分利用磁盘预读特性:
B+树的叶子节点存储数据的顺序性,使得数据库的预读机制(如 InnoDB 的线性预读)能发挥更大作用。当访问一个叶子节点时,系统可以预先加载后续几个叶子节点到内存,从而减少后续访问的磁盘I/O。
-
高效的动态更新与平衡维护:
B+树通过节点的分裂和合并机制,在插入和删除数据时依然能保持树的平衡,且这些操作的局部性较好,开销相对可控,适合频繁更新的数据库环境。
-
聚簇索引与二级索引的良好支持:
在 InnoDB 中:
- 主键索引(聚簇索引):叶子节点直接存储完整的行数据。
- 二级索引(辅助索引):叶子节点存储索引列的值和对应行数据的主键值。查询时先通过二级索引找到主键,再通过主键索引(回表)找到完整数据。这种设计使得非叶子节点更小,树高更低。
2. 为什么不用 B树 (B-Tree)?
B树的结构特性
B树也是一种多路平衡搜索树,与B+树的主要区别在于:
- 节点同时存储键和数据:B树的每个节点(无论是叶子节点还是非叶子节点)都存储索引键以及对应的数据(或指向数据的指针)。
- 叶子节点间无链表:B树的叶子节点之间通常没有指针相连。
B树的不足之处
-
范围查询效率较低:
由于数据分散在所有节点中(包括非叶子节点和叶子节点),进行范围查询时,B树需要通过类似中序遍历的方式来访问所有符合条件的记录。这个过程涉及到在树的不同层级节点间的跳转和回溯,无法像B+树那样仅通过遍历叶子节点层的有序链表来高效完成。这往往意味着更多的随机磁盘I/O。
举例来说:B树的范围查询本质上是对树进行递归的中序遍历(访问左子树 -> 处理当前节点的数据 -> 访问右子树),以确保按键的顺序访问所有符合范围的记录。
- 假设一个B树的某个非叶子节点存储了键
[50](以及对应的数据),其左子节点指向的子树包含键范围如[30-49],右子节点指向的子树包含键范围如[51-70]。 - 当我们要查询键在
35到65之间的所有记录时:- 首先,算法会深入左子树,找到并处理
35到49之间的记录。 - 当左子树中所有符合条件的记录处理完毕后,需要回溯到包含键
50的这个父节点,处理键50对应的数据(因为它在35-65范围内)。 - 接着,算法再进入右子树,继续查找并处理
51到65之间的记录。
- 首先,算法会深入左子树,找到并处理
- 这里的“回溯”指的是在遍历完一个分支(如左子树)后,需要返回到其父节点,处理父节点自身的数据(如果符合条件),然后再去探索其他分支(如右子树)。这种跨层级、非连续的访问模式,在数据量大且存储在磁盘上时,会显著增加寻道时间和I/O次数,尤其与B+树叶子节点纯粹的顺序扫描相比,效率差距明显。
- 假设一个B树的某个非叶子节点存储了键
-
磁盘I/O次数可能更多 (树高可能更高):
因为非叶子节点也存储数据(或数据指针),这占用了节点内宝贵的空间。在相同的节点大小下,B树的非叶子节点能容纳的键数量会少于B+树。这意味着B树的“扇出”(一个节点能拥有的子节点数)可能更小,从而导致树的高度相对B+树更高,查询时需要的磁盘I/O次数随之增加。
-
顺序访问性能差:
缺乏叶子节点链表,使得B树在进行全表扫描或大范围的顺序数据访问时,效率不如B+树。
小结:B树在单点查询上性能可能与B+树接近,但数据库中大量的范围查询和对磁盘I/O的极致追求,使得B+树的特定优化(非叶子节点不存数据、叶子节点链表)更具优势。
3. 为什么不用哈希表 (Hash Table)?
哈希表的结构特性
哈希表通过哈希函数将键(Key)映射到一个桶(Bucket)中,理想情况下,查找、插入、删除的时间复杂度可以达到 O(1)。
哈希表的致命缺陷
-
不支持范围查询:
这是哈希表作为数据库主索引的最大硬伤。哈希函数会将相邻的键值映射到不相邻的存储位置,数据是无序存储的。因此,对于 WHERE id > 100 这样的范围查询,哈希表无能为力,只能进行全表扫描。
-
不支持前缀查询和排序:
类似于范围查询,对于 WHERE name LIKE 'abc%' 这样的前缀匹配,或者 ORDER BY column 这样的排序需求,无序的哈希表也无法高效支持。
-
哈希冲突问题:
当不同的键通过哈希函数计算出相同的哈希值时,就会发生哈希冲突。解决冲突(如链地址法、开放地址法)会带来额外的开销。在数据量大或哈希函数设计不佳时,冲突可能变得严重,使性能从 O(1) 退化到 O(n)。
-
动态扩展成本高:
当数据量增加,哈希表需要扩容(增加桶的数量)以维持性能时,通常需要对所有数据进行 Rehash 操作,这个过程非常耗时。
MySQL 中的哈希索引:
值得注意的是,MySQL 的某些存储引擎(如 Memory 引擎)确实支持显式的哈希索引。此外,InnoDB 引擎有一个“自适应哈希索引(Adaptive Hash Index, AHI)”特性,它会监控B+树索引的查找模式,如果发现某些索引值被频繁等值访问,InnoDB 会在内存中为这些热点页建立哈希索引,以加速等值查询。但这是一种辅助手段,底层的永久索引仍然是B+树。
小结:哈希表在等值查询场景下速度极快,但无法满足数据库多样化的查询需求,尤其是范围查询和排序。
4. 为什么不用二叉树 (及其变种,如AVL树、红黑树)?
二叉树的结构特性
二叉搜索树(BST)及其平衡变种(如AVL树、红黑树)每个节点最多有两个子节点。它们在内存中的查找效率很高,时间复杂度为 O(log₂n)。
二叉树的磁盘瓶颈
-
树高过高,导致大量磁盘I/O:
这是二叉树不适用于磁盘存储作为主索引的根本原因。由于每个节点分支有限(最多两个),对于海量数据,树的高度会非常大。例如,存储1000万条记录,二叉树的高度约为 log₂(10⁷) ≈ 23.25,即大约24层。这意味着一次查询可能需要多达24次磁盘I/O,这在数据库应用中是无法接受的,而B+树通常只需3-4次。
-
磁盘页利用率低下:
数据库从磁盘读取数据是按“页”(Page,如 InnoDB 默认16KB)为单位的。二叉树的一个节点只存储一个键、数据(或指针)和两个子节点指针,远未填满一个磁盘页,造成了大量的空间浪费和I/O浪费。而B+树的一个节点可以存储成百上千个键,充分利用了磁盘页的存储能力。
-
范围查询不友好:
虽然平衡二叉树可以通过中序遍历实现范围查询,但其过程涉及大量非顺序的节点访问,无法像B+树叶子节点链表那样高效。
-
平衡维护的复杂性(针对磁盘):
像AVL树这样的强平衡二叉树,在插入删除时可能需要频繁的旋转操作来维持平衡。这些旋转在内存中尚可,但在磁盘上可能引发多次、分散的I/O操作。
小结:二叉树(包括其平衡变种)是优秀的内存数据结构,但其结构特性导致在面对磁盘存储和海量数据时,I/O瓶颈过于突出,不适合作为数据库的主流索引结构。
直观对比总结:群雄逐鹿,B+树胜出
为了更清晰地展示这几种数据结构的特点及其在数据库索引场景下的适用性,我们总结如下表:
| 特性/数据结构 | B+树 (MySQL InnoDB) | B树 | 哈希表 | 二叉树 (平衡) |
| 基本结构 | 多路平衡搜索树 | 多路平衡搜索树 | 哈希函数+数组/链表 | 最多两路平衡搜索树 |
| 存储方式 | 非叶存键,叶存数据/主键 | 所有节点存键+数据 | 键值对,无序 | 节点存键+数据 |
| 磁盘I/O | 极低 (树高矮) | 低 (树高可能略高) | 通常低 (冲突时增加) | 极高 (树高) |
| 单点查询 | O(log<sub>m</sub>N) | O(log<sub>m</sub>N) | O(1) (理想情况) | O(log₂N) |
| 范围查询 | 高效 (叶子链表) | 中等 (需遍历树) | 极差 (不支持) | 中等 (中序遍历) |
| 顺序访问 | 高效 | 一般 | 极差 | 一般 |
| 前缀查询 | 支持 | 支持 | 不支持 | 支持 |
| 排序支持 | 高效 | 一般 | 不支持 | 一般 |
| 空间利用率 | 高 (节点复用好) | 中等 (数据分散) | 取决于冲突和填充因子 | 低 (针对磁盘页) |
| 动态更新 | 高效 (分裂/合并) | 高效 (分裂/合并) | 复杂 (冲突/扩容成本高) | 复杂 (旋转,对磁盘不友好) |
| 适用场景 | 数据库通用索引 | 文件系统、部分数据库 | 缓存、特定内存数据库索引 | 内存查找 |
核心结论:
- B+树:凭借其针对磁盘I/O的深度优化(低树高)、对范围查询的完美支持(叶子节点链表)以及高效的动态维护能力,成为MySQL等关系型数据库索引的首选。
- B树:虽然也是优秀的多路搜索树,但在范围查询和I/O效率上略逊于B+树。
- 哈希表:等值查询的王者,但在数据库更看重的范围查询、排序等场景下无能为力。
- 二叉树:因其在海量数据下树高过高,导致磁盘I/O成为不可逾越的瓶颈,不适用于磁盘数据库索引。
总结:没有银弹,只有最合适的选择
数据结构的选择从来都不是“一招鲜,吃遍天”,而是针对特定场景和需求的权衡与折中。MySQL 选择 B+树作为其核心索引结构,正是因为它在关系型数据库面临的典型挑战——海量磁盘数据、多样化查询需求(尤其是范围查询)和高并发更新之间,找到了一个极佳的平衡点。
理解B+树及其与其他数据结构的差异,不仅能帮助我们更好地理解MySQL的内部工作原理,也能在进行数据库设计、SQL优化以及解决性能问题时,提供更深刻的洞察力。希望本文能让你对MySQL的索引机制有一个更清晰、全面的认识!

)













![[AI Claude] 软件测试2](http://pic.xiahunao.cn/[AI Claude] 软件测试2)



