文章目录
- 零、写在前面
- 1、XV6 中的锁
- 2、XV6 进程切换
- 3、触发调度
- 一、Uthread: switching between threads
- 1.1 说明
- 1.2 实现
- 二、Using threads
- 2.1 说明
- 2.2 实现
- 三、Barrier
- 3.1 说明
- 3.2 实现
零、写在前面
可以读一下xv6 book 的第六章 锁 以及 第七章 调度:
- https://xv6.dgs.zone/tranlate_books/book-riscv-rev1/c6/s0.html
- https://xv6.dgs.zone/tranlate_books/book-riscv-rev1/c7/s0.html
本实验将使你熟悉多线程编程。你将实现一个用户级线程库中的线程切换,使用多个线程加速程序运行,并实现一个屏障(Barrier)机制。
1、XV6 中的锁
Xv6有两种类型的锁:自旋锁(spinlocks)和睡眠锁(sleep-locks)。我们将从自旋锁(注:自旋,即循环等待)开始。Xv6将自旋锁表示为struct spinlock (*kernel/spinlock.h*:2)。结构体中的重要字段是locked,当锁可用时为零,当它被持有时为非零。从逻辑上讲,xv6应该通过执行以下代码来获取锁
void acquire(struct spinlock* lk) // does not work!
{for(;;) {if(lk->locked == 0) {lk->locked = 1;break;}}
}上述代码严格意义上是不正确的,因为很可能两个 CPU 同时抵达第5行代码,然后都通过执行第6行持有锁,那么就有两个CPU 同时持有锁,违背了互斥属性。
我们需要一种方式,来使第5行和第6行作为**原子性(即不可分割)**步骤执行。
因为锁被广泛使用,多核处理器通常提供实现第5行和第6行的原子版本的指令。在RISC-V上,这条指令是amoswap r, a。amoswap读取内存地址a处的值,将寄存器r的内容写入该地址,并将其读取的值放入r中。也就是说,它交换寄存器和指定内存地址的内容。它原子地执行这个指令序列,使用特殊的硬件来防止任何其他CPU在读取和写入之间使用内存地址。
自旋锁
Xv6的acquire(*kernel/spinlock.c*:22)使用可移植的C库调用归结为amoswap的指令__sync_lock_test_and_set;返回值是lk->locked的旧(交换了的)内容。acquire函数将swap包装在一个循环中,直到它获得了锁前一直重试(自旋)。每次迭代将1与lk->locked进行swap操作,并检查lk->locked之前的值。如果之前为0,swap已经把lk->locked设置为1,那么我们就获得了锁;如果前一个值是1,那么另一个CPU持有锁,我们原子地将1与lk->locked进行swap的事实并没有改变它的值。
获取锁后,用于调试,acquire将记录下来获取锁的CPU。lk->cpu字段受锁保护,只能在保持锁时更改。
函数release(*kernel/spinlock.c*:47) 与acquire相反:它清除lk->cpu字段,然后释放锁。从概念上讲,release只需要将0分配给lk->locked。C标准允许编译器用多个存储指令实现赋值,因此对于并发代码,C赋值可能是非原子的。因此release使用执行原子赋值的C库函数__sync_lock_release。该函数也可以归结为RISC-V的amoswap指令。
睡眠锁
自旋锁也有着明显缺点:
- 如果另一个进程想要获取自旋锁,那么长时间保持自旋锁会导致获取进程在自旋时浪费很长时间的CPU
- 一个进程在持有自旋锁的同时不能让出(yield)CPU,然而我们希望持有锁的进程等待磁盘I/O的时候其他进程可以使用CPU
- 持有自旋锁时让步是非法的,因为如果第二个线程试图获取自旋锁,就可能导致死锁
- 因为
acquire不会让出CPU, - 第二个线程的自旋可能会阻止第一个线程运行并释放锁。在持有锁时让步也违反了在持有自旋锁时中断必须关闭的要求。因此,我们想要一种锁,它在等待获取锁时让出CPU,并允许在持有锁时让步(以及中断)。
Xv6以睡眠锁(sleep-locks)的形式提供了这种锁。acquiresleep (*kernel/sleeplock.c*:22) 在等待时让步CPU
睡眠锁有一个被自旋锁保护的锁定字段,acquiresleep对sleep的调用原子地让出CPU并释放自旋锁。结果是其他线程可以在acquiresleep等待时执行。
因为睡眠锁保持中断使能,所以它们不能用在中断处理程序中。因为acquiresleep可能会让出CPU,所以睡眠锁不能在自旋锁临界区域中使用(尽管自旋锁可以在睡眠锁临界区域中使用)。
因为等待会浪费CPU时间,所以自旋锁最适合短的临界区域;睡眠锁对于冗长的操作效果很好。
2、XV6 进程切换
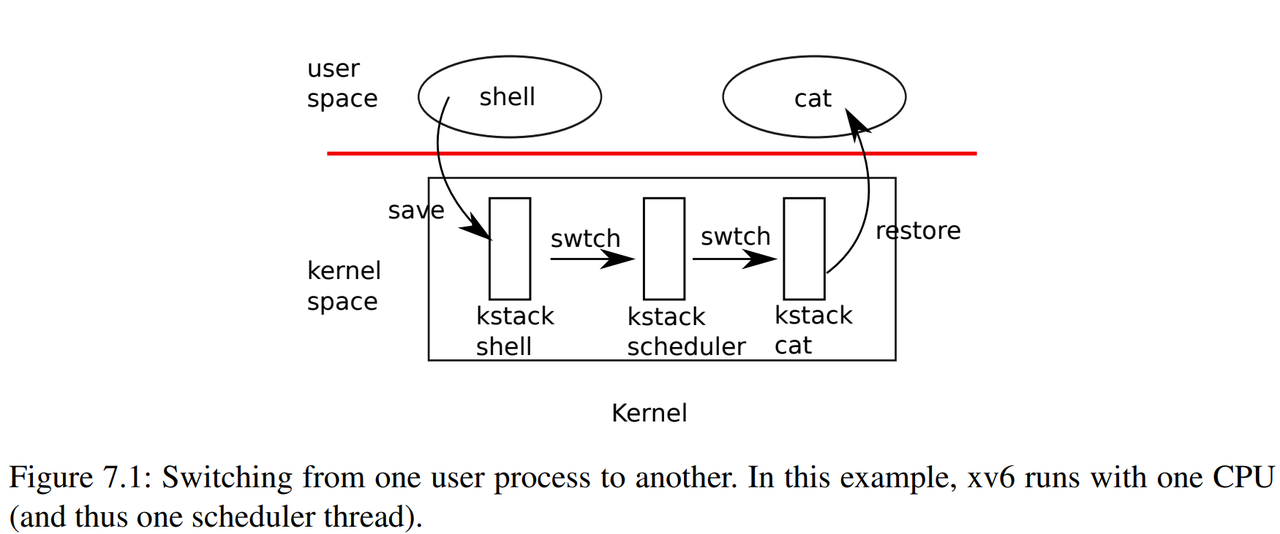
图7.1概述了从一个用户进程(旧进程)切换到另一个用户进程(新进程)所涉及的步骤:
- 一个到旧进程内核线程的用户-内核转换(系统调用或中断)
- 一个到当前CPU调度程序线程的上下文切换
- 一个到新进程内核线程的上下文切换
- 以及一个返回到用户级进程的陷阱
- 从上图可以看到,两个不同核心上使用了两个不同的内核栈,来保证安全执行。
XV6 进程切换主要依赖两个函数,swtch() 和 scheduler()
1、swtch
void swtch(struct context *old, struct context *new);
- 保存当前寄存器到 old 中
- 从 new 中加载寄存器
- 返回到new的 ra 寄存器指向的地址
.globl swtch
swtch:# 保存当前 CPU 的上下文到 old (a0 参数)sd ra, 0(a0) # 保存 ra 寄存器指向的函数返回地址 return addresssd sp, 8(a0) # 保存栈顶位置sd s0-s11... # 保存被调用者保存的寄存器# 加载新上下文 new (a1 参数)到 CPUld ra, 0(a1) # 加载新的返回地址ld sp, 8(a1) # 加载新的栈指针ld s0-s11... # 加载新的寄存器值ret # 返回到新上下文的 ra 指定的地址(ra 已经设置过了)- swtch 运行在内核态,此时,用户进程的状态在切换到 内核态 的时候已经保存到
trapframe里了,所以,这里的汇编程序只需要 保存/恢复 函数调用相关的寄存器即可
2、scheduler
板子上电后,每个 CPU 都会运行从 enter.S -> start.c -> main.c -> scheduler() 的流程。
// start() jumps here in supervisor mode on all CPUs.
void
main()
{if(cpuid() == 0){... // 一系列的初始化工作__sync_synchronize();started = 1;} else {while(started == 0) // 其他 CPU 等待 0 号位完成初始化再执行;__sync_synchronize();kvminithart(); // turn on paging 开启分页trapinithart(); // install kernel trap vector 注册 trap ...}scheduler(); // 进入自己的调度器
}- 对于 0 号 CPU,负责初始化 内存、进程、文件管理 以及 启动第一个用户程序 等工作,全局初始化 执行完以后,进入 scheduler()。
- 对于其他 CPU,在等待 0 号位完成 全局初始化 后,再进行开启自己的 分页(每个 CPU 的寄存器都是独立的)、注册中断 等工作,最终也进入 scheduler()。
在 xv6 中,结构体 cpu 保存了当前 CPU 的上下文 context,以及当前 CPU 正在运行的进程 proc。
// Per-CPU state.
struct cpu {struct proc *proc; // The process running on this cpu, or null.struct context context; // swtch() here to enter scheduler().
};- 调度器(scheduler)以每个CPU上一个特殊线程的形式存在,每个线程都运行
scheduler函数。此函数负责选择下一个要运行的进程 - scheduler函数逻辑:
- 遍历进程表,寻找一个处于
runnable状态的进程,然后调用swtch()切换到该进程。- 当前CPU 的状态会被保存到 c->context 中,
- ra 寄存器保存的是 swtch() 的下一条指令地址(对应代码中的 c->proc = 0)
- 进程p 返回时,ra 会被恢复为 swtch 时的值,即 c->proc = 0
- p->context 会被加载到 CPU,然后返回到 ra 指向的地址继续执行
- p->context ra 保存的是上一次执行的位置,如果是新进程,则ra 会指向 forkret()函数(forkret() 负责新进程创建后的收尾工作)
- 当前CPU 的状态会被保存到 c->context 中,
- 如果没有需要执行的进程,执行
wfi指令,让 CPU 进入 低功耗 等待状态,直到有 中断 发生。
- 遍历进程表,寻找一个处于
void scheduler(void)
{struct proc *p;struct cpu *c = mycpu();c->proc = 0;for(;;){// 允许中断,这样 I/O 中断才能唤醒等待的进程intr_on();// 遍历进程表,选取一个处于 runnable 状态的进程for(p = proc; p < &proc[NPROC]; p++){// 确保每一个进程只有一个 CPU 在修改状态acquire(&p->lock);// 找到了if(p->state == RUNNABLE){p->state = RUNNING;c->proc = p;// 保存当前调度器(cpu->context)的状态,恢复 p->context(保存了进程 p 上次离开时的内核上下文)swtch(&c->context, &p->context);// 当进程 p 再次切回到 CPU 后,继续执行此处,即 ra 寄存器返回的地址c->proc = 0;}release(&p->lock);}if(nproc <= 2) { // only init and sh existintr_on();asm volatile("wfi");}}
}XV6 创建新进程的时候,会为该进程创建新的上下文 context,这一步用来保证:如果一个新创建的进程首次被调度器选中,p->context 不会为空。
static struct proc* allocproc(void)
{...// Set up new context to start executing at forkret,// which returns to user space.memset(&p->context, 0, sizeof(p->context));p->context.ra = (uint64)forkret;p->context.sp = p->kstack + PGSIZE;...
}那么开机首次从 内核 scheduler() 切换到 用户进程的过程可以有如下描述:
首次切换:
scheduler() 运行↓
swtch(&c->context, &p->context)↓ 保存 scheduler() 的上下文到 c->context↓ 加载进程的上下文(从 p->context 中获取)↓ usertrapret() -> trampoline.S:1. 切换到用户页表2. 从 trapframe 恢复所有用户寄存器3. 返回用户态继续执行XV6 如何从 用户进程切换回 scheduler() ?
3、触发调度
在 XV6 中,有 三个 主要入口会调用 swtch() 切换回 scheduler():
- yield():主动让出 CPU
```c
void yield(void) {struct proc *p = myproc();acquire(&p->lock);p->state = RUNNABLE;sched(); // 调用 swtch 切换到 schedulerrelease(&p->lock);
}```
-
exit():进程退出
void exit(int status) {// ... 清理进程资源 ...p->state = ZOMBIE;release(&original_parent->lock);sched(); // 切换到 scheduler,永不返回panic("zombie exit"); } -
sleep():进程休眠
void sleep(void *chan, struct spinlock *lk) {// ... 设置休眠条件 ...p->chan = chan;p->state = SLEEPING;sched(); // 切换到 scheduler// ... 唤醒后的清理工作 ... }我们下面只看 用户进程时间片用完,触发定时器中断的场景:
void usertrap(void) {// ... if(which_dev == 2) { // 时钟中断yield();} }void kerneltrap(void) {// ...if(which_dev == 2 && myproc() != 0 && myproc()->state == RUNNING) {yield();} }-
如果 which_dev == 2,说明是 时钟中断,触发了
yield()。 -
定时器的时长是在 CPU0 执行初始化工作的时候设置的:
kernel/start.c // 为每个 CPU 的时钟中断间隔为 1000,000 个 CPU 周期 timerinit() {... int interval = 1000000; // cycles; about 1/10th second in qemu.*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;... } -
每个进程允许执行 1000,000 个 CPU 周期,到期触发 时钟中断,然后调用
yield(),yield()又调用了sched()函数让出 CPU。void sched(void) {...struct proc *p = myproc();swtch(&p->context, &mycpu()->context);... } -
sched() 函数很简单,转头调用 swtch() 执行切换,入参 old = p->context,new = mycpu->context
- 把当前 CPU 状态保存到正在运行进程的 context 。
- 取出上次 mycpu->context 保存的上下文,恢复到 CPU
- switch 汇编执行最后一行 ret 的那一刻,切换回 scheduler() 继续运行(c->proc = 0)。
-
void scheduler(void) {...for(;;){...for(p = proc; p < &proc[NPROC]; p++){...swtch(&c->context, &p->context);c->proc = 0; }} } -
切回 调度器 后,
scheduler()继续查找 下一个 需要调度的进程,进程的时间片用完了,触发 定时器中断,调用yield()切换回 内核调度器scheduler(),……
-
记得切换到分支 thread
一、Uthread: switching between threads
1.1 说明
在本练习中,你将设计并实现一个用户级线程系统的上下文切换机制。为帮助你开始,xv6 提供了两个文件:user/uthread.c 和 user/uthread_switch.S,以及一个在 Makefile 中构建 uthread 程序的规则。uthread.c 包含了大部分用户级线程库的代码以及三个简单测试线程的代码,但线程的创建和线程间切换的部分尚未完成。、
你的任务是设计一个方案来创建线程,并实现寄存器的保存和恢复,从而在多个线程间切换,并将该方案实现出来。
你需要完成以下几个函数中的代码:
thread_create()和thread_schedule()(位于user/uthread.c)thread_switch()(位于user/uthread_switch.S)
你的目标之一是:当 thread_schedule() 首次运行某个线程时,该线程应在它自己的栈上执行传给 thread_create() 的函数。
另一个目标是:thread_switch() 需要保存当前线程的寄存器状态(从这个线程切换出去),恢复目标线程的寄存器状态(切换到它),并跳回该线程上次执行到的位置继续运行。
你需要决定把寄存器保存在哪里。一个好的方法是修改 struct thread 来保存寄存器。你还需要在 thread_schedule() 中调用 thread_switch(),你可以按需传递参数,但目的是从当前线程 t 切换到 next_thread。
官网的一些提示:
thread_switch只需要保存和恢复**被调用者保存(callee-save)**的寄存器。- 因为调用者的寄存器已经保存在了 thread_schedule 的栈上了
- 你可以查看
user/uthread.asm文件中的汇编代码,这在调试时可能很有用。 - 为了测试你的代码,可以使用
riscv64-linux-gnu-gdb单步调试thread_switch。你可以这样开始:
(gdb) file user/_uthread
Reading symbols from user/_uthread...
(gdb) b uthread.c:60
这会在 uthread.c 的第 60 行设置一个断点。这个断点可能在你运行 uthread 之前就被触发。
当你的 xv6 shell 运行起来后,输入 uthread,gdb 就会在第 60 行处中断。此时你可以使用如下命令查看 uthread 的状态:
(gdb) p/x *next_thread
使用 x 命令可以检查内存内容,例如:
(gdb) x/x next_thread->stack
你可以直接跳到 thread_switch 的开始:
(gdb) b thread_switch
(gdb) c
使用如下命令逐条执行汇编指令:
(gdb) si
1.2 实现
- 先在uthread.c 添加 上下文结构体context
- 然后在 thread_schedule 的相应位置(即找到的要执行的线程和当前不一样)调用 thread_switch
- 然后在 thread_create 中完成对于新线程上下文的初始化,并将传入的func 放入 ra,sp 初始化
struct context{uint64 ra;uint64 sp;uint64 s0;uint64 s1;uint64 s2;uint64 s3;uint64 s4;uint64 s5;uint64 s6;uint64 s7;uint64 s8;uint64 s9;uint64 s10;uint64 s11;
};struct thread {char stack[STACK_SIZE]; /* the thread's stack */int state; /* FREE, RUNNING, RUNNABLE */struct context context; /* thread context */
};void thread_schedule(void)
{struct thread *t, *next_thread;// ...if (current_thread != next_thread) { /* switch threads? */next_thread->state = RUNNING;t = current_thread;current_thread = next_thread;/* YOUR CODE HERE* Invoke thread_switch to switch from t to next_thread:* thread_switch(??, ??);*/thread_switch((uint64)&t->context, (uint64)&next_thread->context);} elsenext_thread = 0;
}void thread_create(void (*func)())
{struct thread *t;for (t = all_thread; t < all_thread + MAX_THREAD; t++) {if (t->state == FREE) break;}t->state = RUNNABLE;// YOUR CODE HEREmemset(&t->context, 0, sizeof t->context);t->context.ra = (uint64)func;t->context.sp = (uint64)t->stack + STACK_SIZE;
}
还有一个是 完善一下 uthread_switch.S:
- 挺没技术含量的,就把旧线程的寄存器存一下,新线程的恢复一下就好了
/* YOUR CODE HERE */
# a0 old context
# a1 new context# store cur context
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)# restore context of new t
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret /* return to ra */
make qemu 运行 uthread测试:
二、Using threads
2.1 说明
在本次实验中,你将通过使用哈希表来探索使用线程和锁进行并行编程。你应当在一台真实的 Linux 或 macOS 计算机上完成该实验(不是 xv6,也不是 qemu),并且该计算机应具有多个核心。
官网说了balabala一堆,其实就是让我们给哈希表加锁来保证并发访问安全性。
2.2 实现
们打开./notxv6/下的 ph.c:
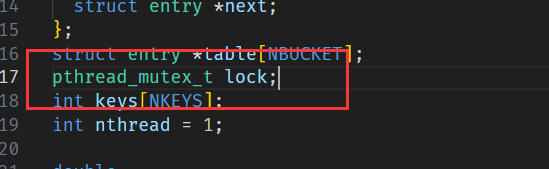
添加一个锁:
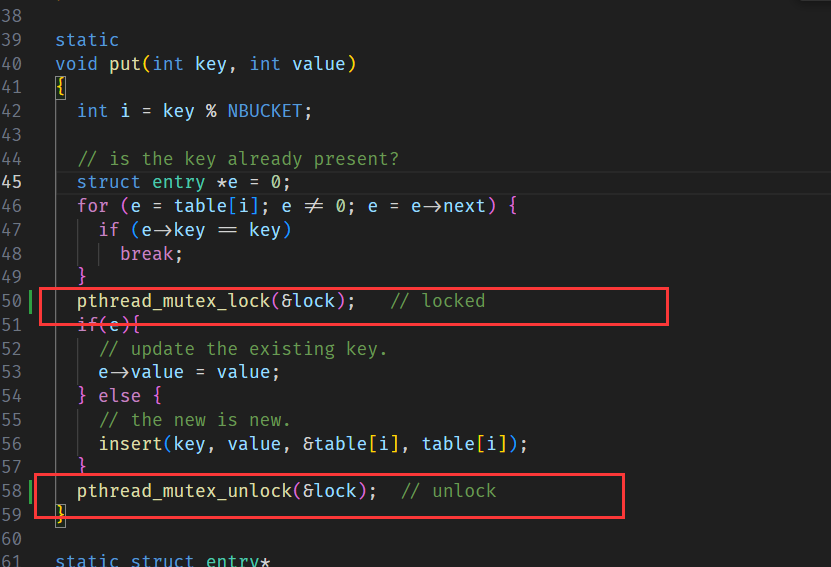
put 时上锁:
记得初始化:

我们单独make grade 测试,发现关于ph_safe 和 ph_fast 的部分都能通过:

三、Barrier
3.1 说明
在本次实验中,你将实现一个 屏障(barrier):这是一个程序中的同步点,所有参与的线程必须在此等待,直到所有其他线程也到达该点后才能继续执行。
你将使用 pthread 条件变量 来实现屏障机制,条件变量是一种线程间的同步机制,类似于 xv6 中的 sleep 和 wakeup。
notxv6/barrier.c 文件中包含一个未正确实现的屏障:
$ make barrier
$ ./barrier 2
barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.其中 2 表示参与屏障同步的线程数(即 barrier.c 中的 nthread 变量)。每个线程执行一个循环,在每次迭代中调用 barrier(),然后随机睡眠一段微秒级时间。
这个 assert 失败的原因是:某个线程在其他线程还没到达屏障前就提前通过了屏障。
目标行为是:每个线程都在 barrier() 中阻塞,直到所有 nthread 个线程都调用了 barrier() 之后,才能一起继续。
你的任务是:实现正确的屏障行为。除了你在前一个 ph 实验中用到的 pthread_mutex 锁,这里你还需要用到两个新的 pthread 原语。
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond
pthread_cond_wait 在调用时会释放传入的 mutex,并在被唤醒时重新获得这个 mutex 锁。
我们已经为你提供了 barrier_init() 的实现。你的任务是实现 barrier(),让程序不再 panic。
结构体 struct barrier 的各个字段是为你实现功能而准备的。
你在实现时需要处理两个问题:
- 多轮屏障调用的区分:即同一个线程会多次调用
barrier(),每一次调用构成一个新的“轮次(round)”。变量bstate.round记录当前是哪一轮。当所有线程都到达当前轮次的屏障时,你应将bstate.round加一。 - 线程间的竞态问题:某个线程可能在离开当前轮次的屏障后太快,结果在其他线程还没离开时就已经进入下一轮了。如果此时它修改了
bstate.nthread等共享变量,会造成错误。你需要确保:离开屏障的线程不会影响正在等待的前一轮的线程。
3.2 实现
打开notxv6 下的barrier.c,我们只需实现里面的barrier 函数即可
- 获取锁,增加 nthread
- 如果够了就修改轮次,然后重置 nthread
- 然后唤醒其它线程
- 否则,让步等待
static void
barrier()
{// YOUR CODE HERE//// Block until all threads have called barrier() and// then increment bstate.round.//pthread_mutex_lock(&bstate.barrier_mutex);++bstate.nthread;if (bstate.nthread >= nthread) {++ bstate.round;bstate.nthread = 0;// wake up all the threadspthread_cond_broadcast(&bstate.barrier_cond);} else {// wait for other threadspthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);}pthread_mutex_unlock(&bstate.barrier_mutex);
}
make grade 的 barrier 部分:













论文详解(包括解题思路和写作要点))


第2期)



