前面的博文美化显示GDB调试的数据结构介绍了如何美化显示GDB中调试的数据结构,本文将还是以mupdf库为例介绍如何美化显示LLDB中调试的数据结构。
先看一下美化后的效果:
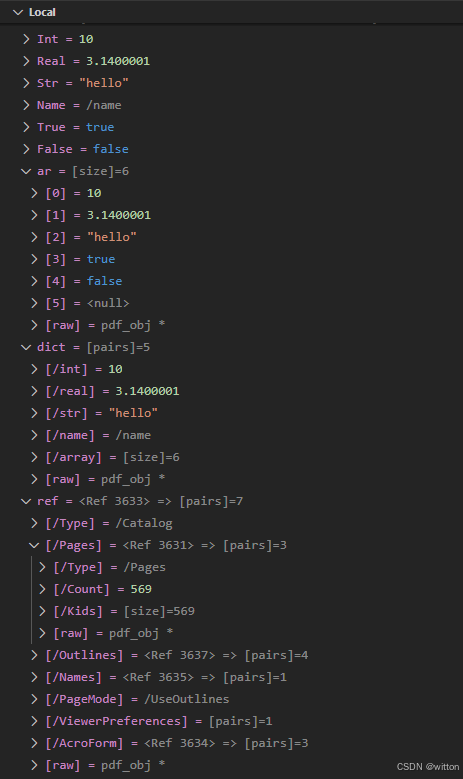
一、加载自定义脚本
与GDB类似,需要添加一个~/.lldbinit文件,可以在其中添加一些LLDB的命令,笔者的内容为:
setting set target.x86-disassembly-flavor intel
command script import C:/Users/admin/lldb/mupdf_printer.py
第一行设置LLDB反汇编格式为intel,第二行则是执行我们自定义的美化显示脚本mupdf_printer.py,如果是在VSCode中使用codelldb插件,则可以不用写第二行,而在.vscode/launch.json中设置调试配置的initCommands来加载脚本:
{"type": "lldb","request": "launch","name": "(lldb) 启动","program": "${workspaceFolder}/build/t.exe","args": [],"cwd": "${workspaceFolder}","initCommands": ["command script import ${workspaceFolder}/lldbscripts/mupdf_printer.py",]},
二、写测试代码
与博文美化显示GDB调试的数据结构中的测试代码一样。
三、写LLDB的python脚本
1. 向LLDB注册pdf_obj类型
LLDB必须使用__lldb_init_module(debugger : lldb.SBDebugger, internal_dict : dict)签名的函数来处理类型的注册。
注册分为概要(summary类型)和混合器(synthetic )类型。概要类型用于不需要展开即可显示的信息;而混合器类型用于展开时显示的信息,比如数组、字典等等。
def __lldb_init_module(debugger : lldb.SBDebugger, internal_dict : dict):debugger.HandleCommand(r'type summary add -x "^pdf_obj.*\*" --python-function mupdf_printer.PDFObjAPISummary')debugger.HandleCommand(r'type synthetic add -x "^pdf_obj.*\*" --python-class mupdf_printer.PDFObjAPIPrinter')print("MuPDF pdf_obj summary and synthetic provider (via API) loaded.")
2.写美化输出代码
根据LLDB的Python协议,概要类型的处理只能是一个函数,而混合器类型的处理是一个类。
所以pdf_obj的概要类型处理函数如下:
def PDFObjAPISummary(val : lldb.SBValue, internal_dict : dict):try:addr = val.GetValueAsAddress()if not addr:return "<null>"ref = ""if call_pdf_api("pdf_is_indirect", val):num = call_pdf_api(f"pdf_to_num", val)#gen = call_pdf_api(f"pdf_to_gen", valobj)ref = f"<Ref {num}> => "kind = detect_pdf_obj_kind(val)if kind == "null":return f"{ref}<null>"elif kind == "int":return f"{ref}{call_pdf_api("pdf_to_int", val)}"elif kind == "real":return f"{ref}{call_pdf_api(f"pdf_to_real", val, float)}"elif kind == "bool":v = call_pdf_api(f"pdf_to_bool", val)return f"{ref}{'true' if v else 'false'}"elif kind == "string":return f'{ref}{call_pdf_api("pdf_to_text_string", val, str)}'elif kind == "name":v = call_pdf_api("pdf_to_name", val, str)return f'{ref}/{v.strip('"')}'elif kind == "array":length = call_pdf_api("pdf_array_len", val)return f"{ref}[size]={length}"elif kind == "dict":length = call_pdf_api(f"pdf_dict_len", val)return f"{ref}[pairs]={length}"return f"{ref}{addr}"except Exception as e:return f"<error: {e}>"
混合器类型的处理函数如下:
class PDFObjAPIPrinter:def __init__(self, val : lldb.SBValue, internal_dict : dict):self.val = valself.kind = detect_pdf_obj_kind(val)self.size = self.num_children()def has_children(self):# 只在array/dict类型时允许展开return self.kind in ["array", "dict"]def num_children(self):if self.kind == "array":length = call_pdf_api(f"pdf_array_len", self.val)return int(length) if length else 0elif self.kind == "dict":length = call_pdf_api(f"pdf_dict_len", self.val)return int(length) if length else 0return 0def get_child_at_index(self, index):try:if index < 0 or index >= self.size:return Noneif self.kind == "array":v = call_pdf_api_1(f"pdf_array_get", self.val, index, object)# 根据索引取到pdf_obj对象了,需要获取其地址addr = v.GetValueAsAddress()# 再构造一个表达式,将这个地址强制转为pdf_obj的指针expr = f"(pdf_obj *){addr}"# 最后根据这个表达式创建一个新的值,LLDB会自动重新根据规则显示这个值return self.val.CreateValueFromExpression(f"[{index}]", expr)elif self.kind == "dict":key = call_pdf_api_1("pdf_dict_get_key", self.val, index, object)val = call_pdf_api_1("pdf_dict_get_val", self.val, index, object)# 将pdf_obj中字典的Key一定是一个name,取name的值key_str = call_pdf_api("pdf_to_name", key, str).strip('"')# 将字典的value取地址,构造一个新的表达式addr = val.GetValueAsAddress()expr = f"(pdf_obj *){addr}"# 最后根据这个表达式创建一个新的值,LLDB会自动重新根据规则显示这个值return self.val.CreateValueFromExpression(f"[/{key_str}]", expr)except Exception as e:print(f"Error in get_child_at_index: {e}")return None
代码中同样需要一些辅助函数,就不再一一列举了,直接给出完整代码。
3. 完整代码
mupdf_printer.py:
import lldbpdf_ctx : int | None = Nonedef get_mupdf_version_from_symbol(target : lldb.SBTarget):try:version = target.EvaluateExpression('(const char*)mupdf_version')return version.GetSummary()except Exception as e:return f"<symbol not found: {e}>"def call_mupdf_api(func_name : str, val : lldb.SBValue, retType : type, *args):try:target = val.GetTarget()addr = val.GetValueAsAddress() # 使用GetValueAsAddress获取指针值cast = {int: "(int)",float: "(float)",str: "(const char*)", # for functions returning const char*object: "(pdf_obj *)", # for pdf_obj pointers}.get(retType, "(void)")global pdf_ctxif pdf_ctx is None:ver = get_mupdf_version_from_symbol(target)print(f"[LLDB] MuPDF version: {ver}")ctx : lldb.SBValue = target.EvaluateExpression(f"(fz_context*)fz_new_context_imp(0,0,0,{ver})")pdf_ctx = ctx.GetValueAsAddress() # 保存为整数地址if args:args_str = ', '.join([str(arg) for arg in args])expr = f"{cast}{func_name}((fz_context*){pdf_ctx},{addr}, {args_str})"else:expr = f"{cast}{func_name}((fz_context*){pdf_ctx},(pdf_obj*){addr})"result : lldb.SBValue = target.EvaluateExpression(expr)if retType == int:return int(result.GetValue())elif retType == float:return float(result.GetValue())elif retType == str:return result.GetSummary()else:return resultexcept Exception as e:print(f"<error calling {func_name}: {e}>")return f"<error calling {func_name}: {e}>"def call_pdf_api(func_name : str, val : lldb.SBValue, rettype=int):return call_mupdf_api(func_name, val, rettype)def call_pdf_api_1(func_name : str, val : lldb.SBValue, arg, rettype=int):return call_mupdf_api(func_name, val, rettype, arg)# 检测除间隔引用外的数据类型
def detect_pdf_obj_kind(val : lldb.SBValue):try:if call_pdf_api("pdf_is_null", val):return "null"elif call_pdf_api("pdf_is_int", val):return "int"elif call_pdf_api("pdf_is_real", val):return "real"elif call_pdf_api("pdf_is_bool", val):return "bool"elif call_pdf_api("pdf_is_string", val):return "string"elif call_pdf_api("pdf_is_name", val):return "name"elif call_pdf_api("pdf_is_array", val):return "array"elif call_pdf_api("pdf_is_dict", val):return "dict"return "unknown"except Exception as e:print(f"<error detecting pdf_obj kind: {e}>")return "<error>"def PDFObjAPISummary(val : lldb.SBValue, internal_dict : dict):try:addr = val.GetValueAsAddress()if not addr:return "<null>"ref = ""if call_pdf_api("pdf_is_indirect", val):num = call_pdf_api(f"pdf_to_num", val)#gen = call_pdf_api(f"pdf_to_gen", valobj)ref = f"<Ref {num}> => "kind = detect_pdf_obj_kind(val)if kind == "null":return f"{ref}<null>"elif kind == "int":return f"{ref}{call_pdf_api("pdf_to_int", val)}"elif kind == "real":return f"{ref}{call_pdf_api(f"pdf_to_real", val, float)}"elif kind == "bool":v = call_pdf_api(f"pdf_to_bool", val)return f"{ref}{'true' if v else 'false'}"elif kind == "string":return f'{ref}{call_pdf_api("pdf_to_text_string", val, str)}'elif kind == "name":v = call_pdf_api("pdf_to_name", val, str)return f'{ref}/{v.strip('"')}'elif kind == "array":length = call_pdf_api("pdf_array_len", val)return f"{ref}[size]={length}"elif kind == "dict":length = call_pdf_api(f"pdf_dict_len", val)return f"{ref}[pairs]={length}"return f"{ref}{addr}"except Exception as e:return f"<error: {e}>"
class PDFObjAPIPrinter:def __init__(self, val : lldb.SBValue, internal_dict : dict):self.val = valself.kind = detect_pdf_obj_kind(val)self.size = self.num_children()def has_children(self):# 只在array/dict类型时允许展开return self.kind in ["array", "dict"]def num_children(self):if self.kind == "array":length = call_pdf_api(f"pdf_array_len", self.val)return int(length) if length else 0elif self.kind == "dict":length = call_pdf_api(f"pdf_dict_len", self.val)return int(length) if length else 0return 0def get_child_at_index(self, index):try:if index < 0 or index >= self.size:return Noneif self.kind == "array":v = call_pdf_api_1(f"pdf_array_get", self.val, index, object)# 根据索引取到pdf_obj对象了,需要获取其地址addr = v.GetValueAsAddress()# 再构造一个表达式,将这个地址强制转为pdf_obj的指针expr = f"(pdf_obj *){addr}"# 最后根据这个表达式创建一个新的值,LLDB会自动重新根据规则显示这个值return self.val.CreateValueFromExpression(f"[{index}]", expr)elif self.kind == "dict":key = call_pdf_api_1("pdf_dict_get_key", self.val, index, object)val = call_pdf_api_1("pdf_dict_get_val", self.val, index, object)# 将pdf_obj中字典的Key一定是一个name,取name的值key_str = call_pdf_api("pdf_to_name", key, str).strip('"')# 将字典的value取地址,构造一个新的表达式addr = val.GetValueAsAddress()expr = f"(pdf_obj *){addr}"# 最后根据这个表达式创建一个新的值,LLDB会自动重新根据规则显示这个值return self.val.CreateValueFromExpression(f"[/{key_str}]", expr)except Exception as e:print(f"Error in get_child_at_index: {e}")return Nonedef __lldb_init_module(debugger : lldb.SBDebugger, internal_dict : dict):debugger.HandleCommand(r'type summary add -x "^pdf_obj.*\*" --python-function mupdf_printer.PDFObjAPISummary')debugger.HandleCommand(r'type synthetic add -x "^pdf_obj.*\*" --python-class mupdf_printer.PDFObjAPIPrinter')print("MuPDF pdf_obj summary and synthetic provider (via API) loaded.")
四、调试LLDB的python代码
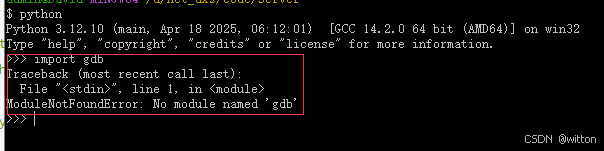
gdb中的python美化显示脚本不能直接使用普通的python调试器进行调试,那是因为GDB中不是使用的常规Python。常规Python不能import gdb包:
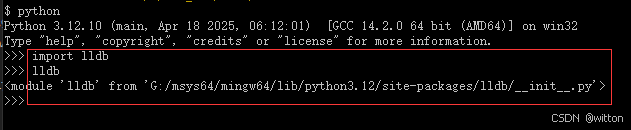
而常规Python是可以import lldb包的:
所以lldb中的python脚本是可以使用常规的python调试器调试的,下面就介绍一下在VSCode中如何调试它。
首先,需要在.vscode/launch.json中添加lldb调试配置和python调试配置,需要注意的是python的调试配置是附加到进程的类型:
{"version": "0.2.0","configurations": [{"name": "Python 调试程序: 使用进程 ID 附加","type": "debugpy","request": "attach","processId": "${command:pickProcess}"},{"type": "lldb","request": "launch","name": "(lldb) 启动","program": "${workspaceFolder}/build/t.exe","args": [],"cwd": "${workspaceFolder}","initCommands": ["command script import ${workspaceFolder}/lldbscripts/mupdf_printer.py",]}]
}
先在C/C++代码中打好断点:
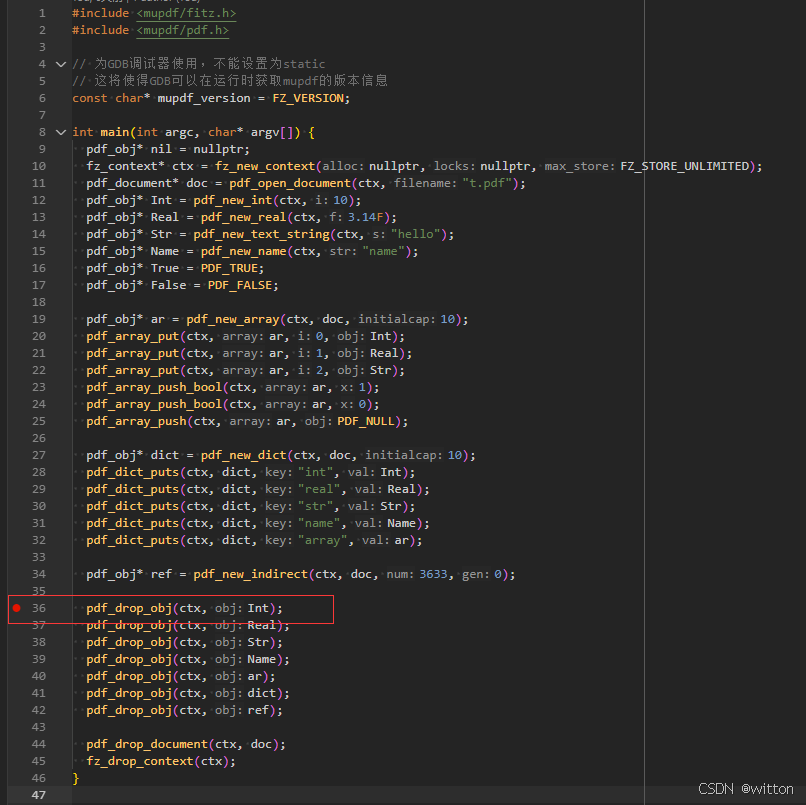
然后启动LLDB调试器,此时会在断点处中断。
再启动Python调试,附加到codelldb进程:
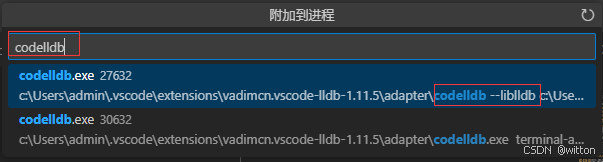
附加成功后,在LLDB的python脚本中打的断点就生效了:
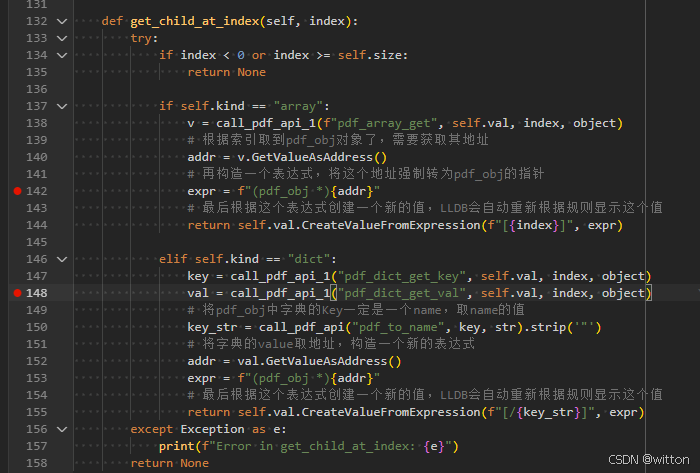
此时在LLDB调试器中展开还未获取到值的变量,比如数组、字典需要展开的但从未展开过的变量(展开后有缓存,再次展开不会再触发Python脚本,如果要想再次触发,可以如后面介绍的方法,在调试控制台直接使用p命令显示)
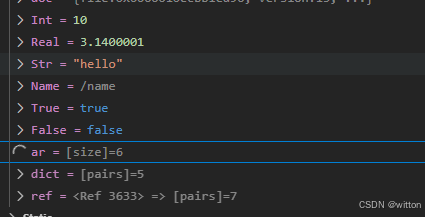
将调试器切换到Python调试器:

就可以看到触发了Python中的断点了,可以调试Python代码了:
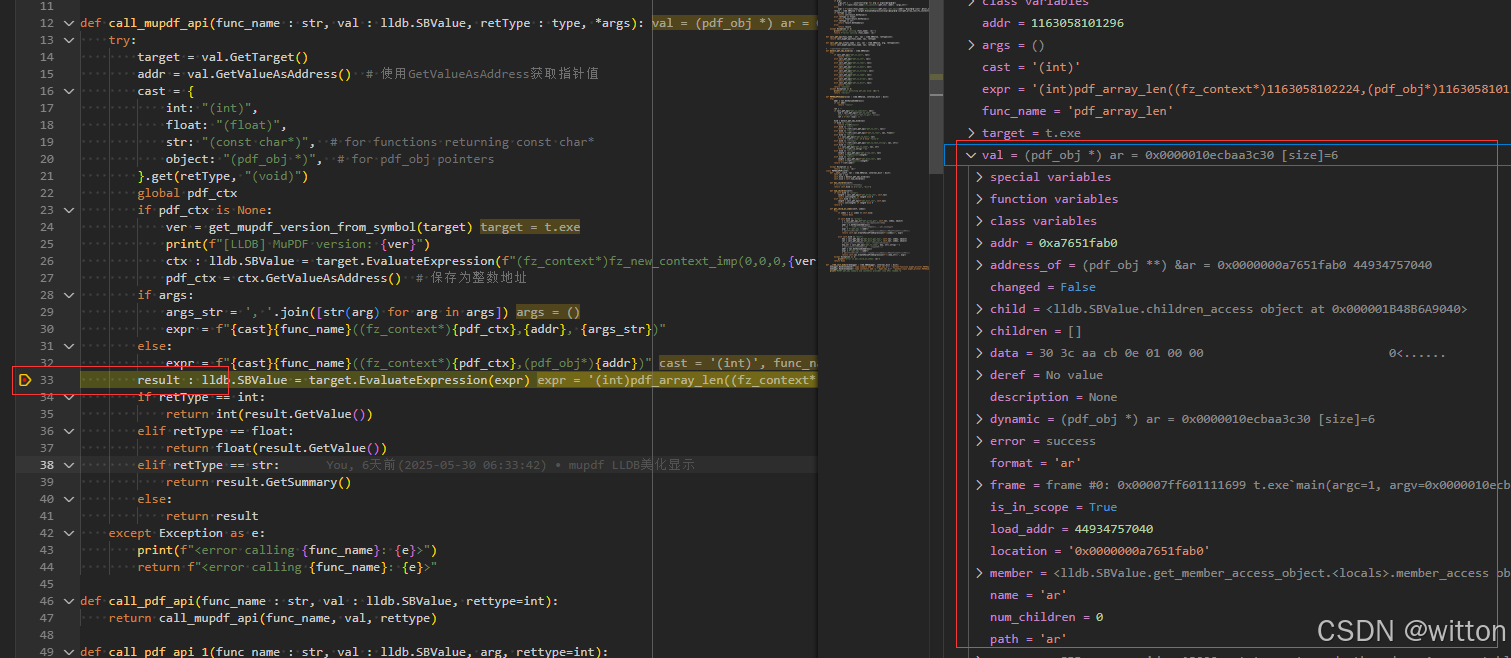
由于调试了Python代码,LLDB可能会获取超时,出现后面的值显示不了的情况:
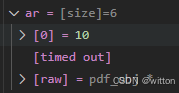
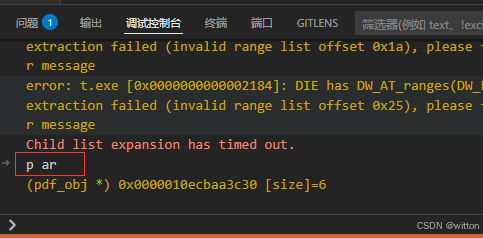
可以在VSCode的调试控制台中直接输入LLDB命令:p ar,刷新一下就显示出来了,此时会再次触发Python脚本。
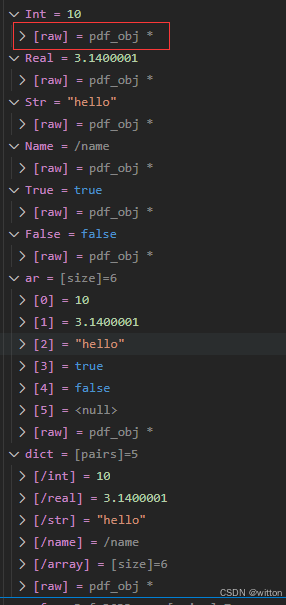
五、总结
细心的读者可能会发现,所有的pdf_obj变量前面都有一个展开箭头,不管是基本的数据类型,还是数组与字典,展开后都有一个[raw]项,这是因为pdf_obj注册了混合器。
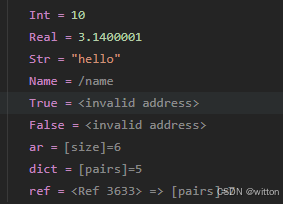
如果不注册混合器就不会有展开箭头,但数组与字典也无法展开查看内容,同时pdf_obj的bool值也会有问题:
有解决办法的读者也可以在评论区留言讨论!
笔者可能会持续改进与补充,欲知后续版本,请移步:
https://github.com/WittonBell/demo/tree/main/mupdf/lldbscripts
如果本文对你有帮助,欢迎点赞收藏!







)




先进技术)






