
在 AI 和大数据时代,企业通常需要构建各种数据同步管道。例如,实时数仓实现从数据库到数据仓库或者数据湖的实时复制,为业务部门和决策团队分析提供数据结果和见解;再比如,NoSQL 游戏玩家数据,需要转换为 SQL 数据库以供运营团队分析。那么,到底如何构造稳定而快速的数据 ETL 管道,并且可以进行数据合并或转换?
📢限时插播:Amazon Q Developer 来帮你做应用啦1!
🌟10分钟帮你构建智能番茄钟应用,1小时搞定新功能拓展、测试优化、文档注程和部署
⏩快快点击进入《Agentic Al 帮你做应用 -- 从0到1打造自己的智能番茄钟》实验
免费体验企业级 AI 开发工具的真实效果吧
构建无限,探索启程!
Amazon 提供了几种数据同步方法:
-
Amazon Zero-ETL
借助 Zero ETL ,数据库本身集成 ETL 到数据仓库的功能,减少了在不同服务间手动迁移或转换数据的工作。目前 Zero ETL 支持的源和目标有如下几种,都是托管的数据库或者数据分析服务。
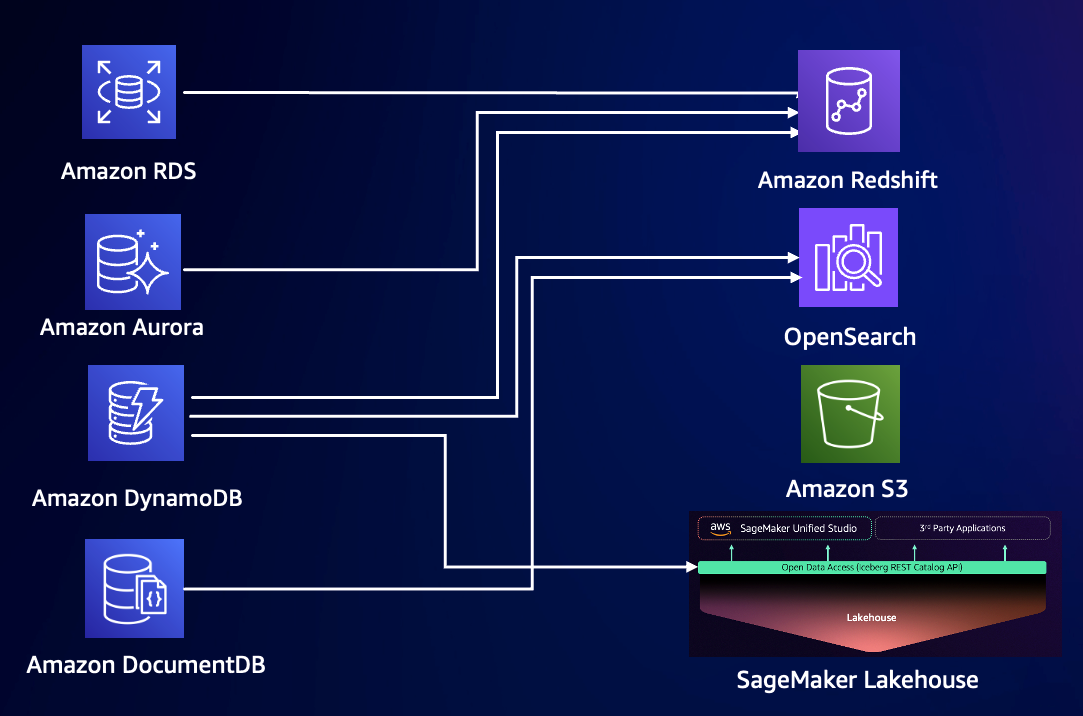
-
Amazon Database Migration Service(DMS)
DMS 可以迁移关系数据库、数据仓库、NoSQL 数据库及其他类型的数据存储,支持同构或者异构数据库和数据仓库的数据转换。DMS 运行于单个节点,即使有高可用设计,仍然只有单节点实际工作。在高并发写入的情况下,转换效率受到影响。DMS 支持的源和目标仍然有限,一些开源数据库或者上下游组件支持不足。
-
Apache Flink
Apache Flink 作为开源实时计算引擎,支持包括各种关系数据库、NoSQL 数据库和数据仓库的多种数据源和下游连接。数据转换流程也可以加入 Kafka 消息管道作为上下游解耦,满足高性能和高可用数据同步复制需求。亚马逊云科技提供 Amazon EMR Flink 组件和全托管 Amazon Managed Service for Apache Flink 两种服务。EMR 更适合于包括 Flink 在内的开源生态的各种组件,而托管 Flink 只提供单个服务。
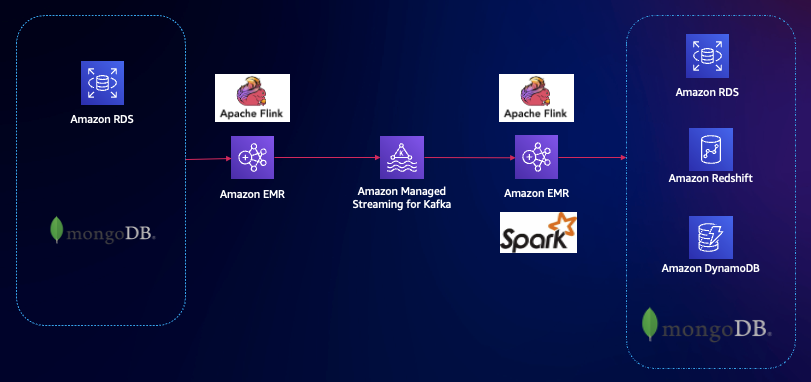
几种方案的对比请参考:合纵连横 – 以 Amazon Flink 和 Amazon MSK 构建 Amazon DocumentDB 之间的实时数据同步。
Flink 方案适用于以下场景:
-
各种数据库到数据仓库的实时 ETL
-
开源 NoSQL 到 DynamoDB 转换
-
DynamoDB 表合并
-
S3 离线数据快速写入 DynamoDB
-
中国和海外数据库稳定数据复制

Flink 方案优势在于:
-
托管服务,稳定运行。EMR 主节点可以设置高可用,计算节点以 resource manager 和 yarn 框架实现节点和任务的高可用管理以及任务调度。Flink Checkpoint 机制定期创建检查点,恢复失败任务。
-
高性能。EMR 可以设置多个计算节点,以及并行度,充分利用多节点计算能力,并发处理。实际测试复制写入速度可达几 GB/s,适合需要短时间内迁移数据。
-
一致性,避免数据重复写入。
-
开发灵活,可以根据需求进行表合并或者字段转换。
-
批流一体,支持全量和增量复制,几乎适用于任何数据复制场景。
-
开源生态丰富,支持多种数据源和目标。
以下对于细分场景单独以示例说明。
场景 1:实时数据聚合计算
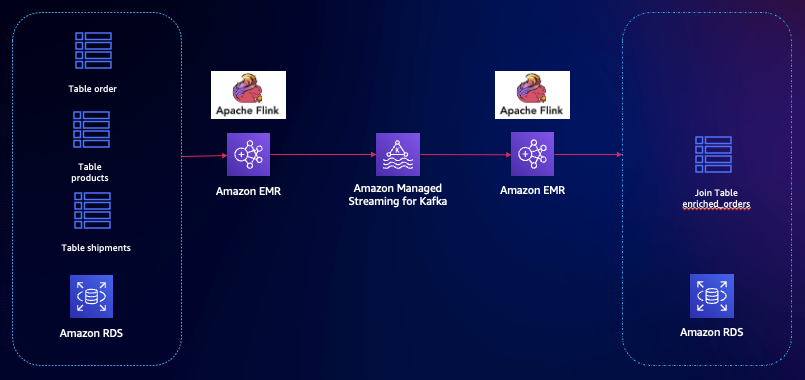
多个业务表需要实时 Join 查询,把结果写入目标表。例如电商业务,对订单数据进行统计分析,进行关联形成订单的大宽表,业务方使用业务表查询。
源端 Flink 创建 Mysql CDC 多表实时 Join,打入 Kafka。目标端 Flink 消费 Kafka 实时数据,同步到目标数据库。
环境设置
-
源数据库:RDS Mysql 8.0
创建数据库 mydb 以及表 products,并写入数据。
表数据参考 Building a Streaming ETL with Flink CDC | Apache Flink CDC。
-
目标数据库:RDS Postgresql 14,创建与 MySQL 相同结构的表,可参考上述链接。
-
MSK Kafka,禁用密码验证。
-
EMR 6.10.0:Flink 1.16.0、ZooKeeper 3.5.10,1 个 primary 节点 + 3 个 core 节点,通过 SSH 登录主节点。
下载与 Flink1.16 兼容的相关 Flink jar 软件包,包括 Flink CDC、Kafka、JDBC Connector,目标 PostgreSQL 还需要 JDBC 驱动:
https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.3.0/flink-sql-connector-mysql-cdc-2.3.0.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka/1.16.1/flink-sql-connector-kafka-1.16.1.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc/1.16.1/flink-connector-jdbc-1.16.1.jar
https://jdbc.postgresql.org/download/postgresql-42.7.5.jar
把下载的 jar 包复制到 Flink lib 目录,并修改权限,例如:
sudo cp /home/hadoop/flink-sql-connector-mysql-cdc-2.3.0.jar /usr/lib/flink/lib/
sudo chown flink:flink flink-sql-connector-mysql-cdc-2.3.0.jar
sudo chmod 755 flink-sql-connector-mysql-cdc-2.3.0.jar重启 Flink 服务使 jar 包加载成功:
cd /usr/lib/flink/bin
./stop-cluster.sh
./start-cluster.sh创建 Kafka topic,修改 –bootstrap-server 为创建的 MSK 地址:
kafka-topics.sh --create --bootstrap-server b-3.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092,b-1.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092,b-2.pingaws.jsi6j6.c6.kafka.us-east-1.amazonaws.com:9092 --replication-factor 3 --partitions 1 --topic flink-cdc-kafka以 yarn 启动 Flink 应用:
./yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -nm flink-cdc-kafka查看 Flink 启动应用:
yarn application -listTotal number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1687084195703_0001 flink-cdc-kafka Apache Flink hadoop default RUNNING UNDEFINED 100% http://172.31.88.126:46397此时也可以通过 SSH Tunnel,查看 Flink Web UI 界面,显示任务运行状况:
Option 1: Set up an SSH tunnel to the Amazon EMR primary node using local port forwarding - Amazon EMR
下面开始 Flink 流程。启动 Flink SQL 客户端:
$ ./sql-client.sh embedded -s flink-cdc-kafka1、设置 Flink checkpoint,间隔 3 秒
SET execution.checkpointing.interval = 3s;2、创建 Flink 表,连接 Mysql 源数据
表结构和 Mysql 相同,使用 mysql-cdc connector 作为连接 Mysql 和 Flink 的组件,获取数据变化。
CREATE TABLE products (id INT,name STRING,description STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = 'Source RDS endpoint','port' = '3306','username' = 'user','password' = 'password','database-name' = 'mydb','table-name' = 'products');3、创建 Kafka 表
根据最终需求而设计的业务表,包含各个表和字段 Join 查询后的结果。指定 Kafka connector,格式为’debezium-json’,记录前后变化。
CREATE TABLE enriched_orders (order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'kafka','topic' = 'flink-cdc-kafka','properties.bootstrap.servers' = ‘xxxx:9092','properties.group.id' = 'flink-cdc-kafka-group','scan.startup.mode' = 'earliest-offset','format' = 'debezium-json');4、源 Mysql 数据写入 Kafka 表
多表 Join 结果写入大宽表,进入 Kafka 消息队列。
INSERT INTO enriched_ordersSELECT o.*, p.name, p.description, s.shipment_id, s.origin, s.destination, s.is_arrivedFROM orders AS oLEFT JOIN products AS p ON o.product_id = p.idLEFT JOIN shipments AS s ON o.order_id = s.order_id;查看 Kafka 消费程序,可以看到类似以下信息。Mysql 的数据以 debzium json 方式写入 Kafka,以 before & after 记录数据前后变化状况。以下是 INSERT 信息:
kafka-console-consumer.sh --bootstrap-server xxt:9092 --topic multi-table-join --from-beginning
{"before":null,"after":{"order_id":10001,"order_date":"2020-07-30 10:08:22","customer_name":"Jark","price":50.5,"product_id":102,"order_status":false,"product_name":"car battery","product_description":"12V car battery","shipment_id":10001,"origin":"Beijing","destination":"Shanghai","is_arrived":false},"op":"c"}5、消费 Kafka 实时数据,写入最终目标端业务数据库
创建目标表:
CREATE TABLE enriched_orders_output(order_id INT,order_date TIMESTAMP(0),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,product_name STRING,product_description STRING,shipment_id INT,origin STRING,destination STRING,is_arrived BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://<Target RDS endpoint>:3306/mydb','table-name' = 'kafka_orders_output', 'username' = ‘user', 'password' = ‘password'
);6、读取 Kafka 数据,写入目标数据库
INSERT INTO enriched_orders_output SELECT * FROM enriched_orders;7、在源数据库 Insert/Update/Delete,检查 Kafka 和目标数据库,变化几乎实时同步到目标数据库
源 Mysql:
mysql> INSERT INTO orders-> VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);
mysql> INSERT INTO shipments-> VALUES (default,10004,'Shanghai','Beijing',false);
mysql> UPDATE orders SET order_status = true WHERE order_id = 10004;
mysql> UPDATE shipments SET is_arrived = true WHERE shipment_id = 1004;至此,实时查询的需求已经实现。但生产环境需要可靠的方案,高可用和性能也是重要的考虑因素。因此接下来进行测试。
高可用测试:
EMR 可以实现主节点和计算节点高可用,出现节点故障时可以自动替换,并重新调度任务。模拟节点故障,重启 core node。Flink checkpoint 机制生成周期性数据快照用于恢复。
启用 Flink checkpoint:
SET execution.checkpointing.interval = 3s; Checkpoint 有重试机制,直到超过最大重试次数。
如果禁用 Flink checkpoint ,任务失败不重启,导致中断。但是,默认情况下,即使设置 checkpoint,无论位于本地还是 S3,重启 core 节点也会导致任务中断。
解决办法:EMR Configuration 加入 Flink 高可用配置 zookeeper
[{"Classification": "yarn-site","Properties": {"yarn.resourcemanager.am.max-attempts": "10"}},{"Classification": "flink-conf","Properties": {"high-availability": "zookeeper","high-availability.storageDir": "hdfs:///user/flink/recovery","high-availability.zookeeper.path.root": "/flink","high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}","yarn.application-attempts": "10"}}
]结论:EMR 配置 Flink 高可用,即使出现节点故障,仍然可以保持任务继续运行,适合长期运行 CDC 任务的场景。
性能测试
运行 EMR Flink CDC 和 MSK 实时数据同步源 Mysql 到目标 PostgreSQL。运行测试程序,源 Mysql 持续快速批量插入数据,同时 4 个测试进程同时运行 20 分钟,Mysql 写入数据,打入 Kafka 并消费写入目标 PostgreSQL。性能指标显示:
RDS Mysql:CPU 26%, 写 IOPS 1400/s, 写入速度 23000/s
RDS PostgreSQL:DML(Insert) 23000/s
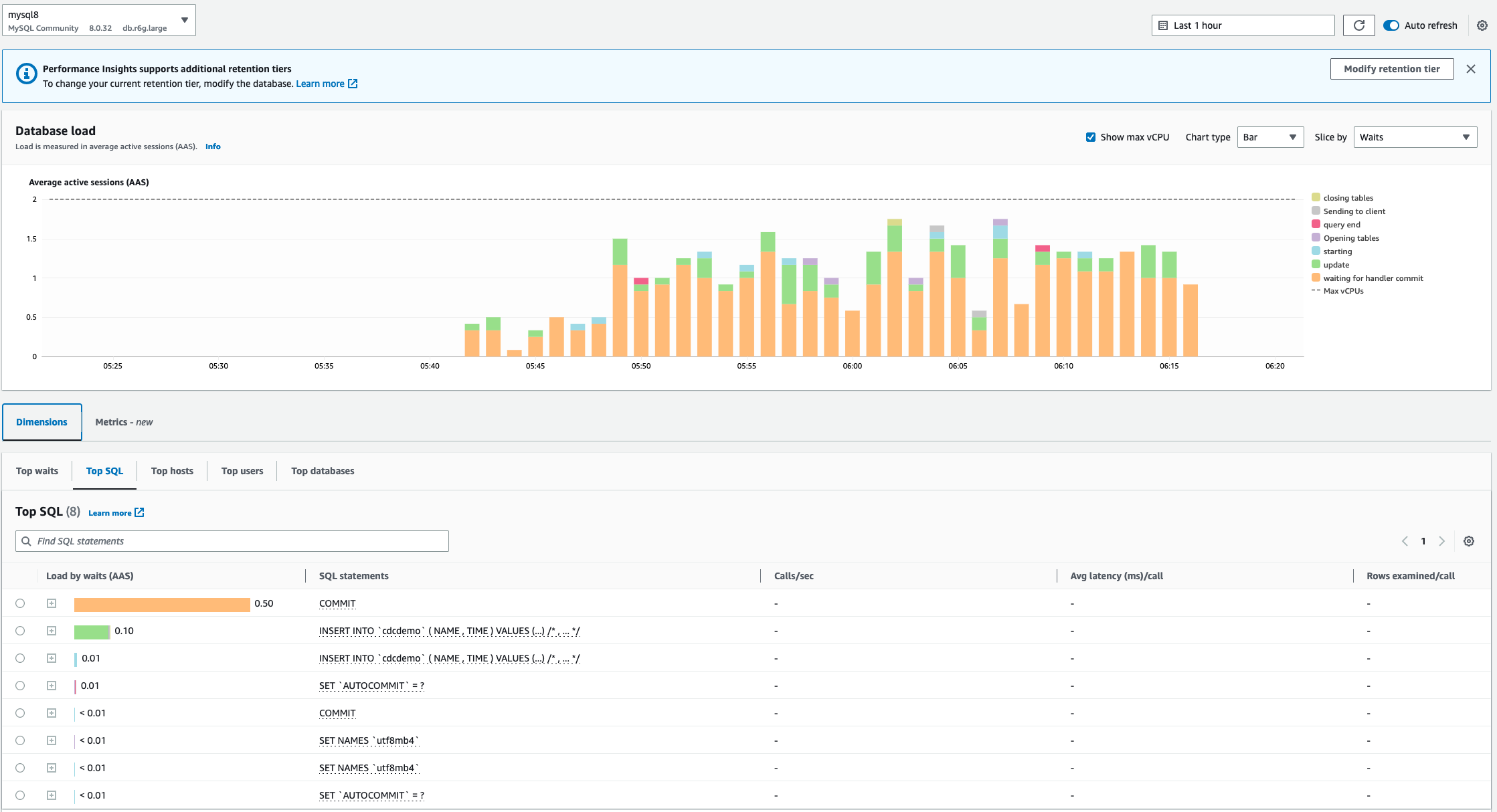
观察测试结果,以及源和目标数据对比,源 Mysql 经过 EMR Flink + MSK 到目标 PostgreSQL,即使写压力高的情况下,复制延迟保持在秒级。
此数据流转过程中加入了 MSK Kafka 解耦上下游数据,即使在目标端处理能力不足,或者网络延迟较大时,仍然可以保证整个数据管道正常运行。
场景 2:实时同步数据库到数据仓库
Flink 作为数据库到数据湖/仓库的 ETL 管道,实现在线和离线数据的统一处理。
以下示例说明从 Spark Streaming 从 Kafka 中消费 Flink CDC 数据,多库多表实时同步到 Redshift 数据仓库。

详情参考:多库多表场景下使用 Amazon EMR CDC 实时入湖最佳实践
场景 3:SQL 数据库(Mysql、PostgreSQL)在线迁移到 NoSQL(DocumentDB、DynamoDB)
传统 SQL 关系型数据库在现代化应用的高并发场景下不一定完全适用。由于索引多层效率问题,在数据库表特别大的时候,加上大量并发读写,可能导致数据库性能下降。分库分表可以解决扩展问题,但是也带来中间件 proxy 管理问题和性能损失,更难以解决的是,sharding key 以外的查询需要从所有分片获取数据,效率极低。
NoSQL 数据库是解决大表大并发的很好方法。简单的 Key Value 或者文档存储,不需要复杂的 Join 查询,可以利用 NoSQL 数据库的海量存储和远高于 SQL 数据库的高并发和低延迟。Amazon DynamoDB Key Value 数据库,更可以无需扩容升级运维等升级工作,支持几乎无上限的的数据容量,轻松扩展到百万 QPS。
要实现从 SQL 到 NoSQL 的转换,从应用程序到数据库都需要改造。在迁移数据库时,为尽量降低对业务的影响,在线迁移成为大多数客户的选择。Amazon DMS 工具是一个选择,但是对于源和目标,会有些限制。例如,DMS 对于 DynamoDB 复合主键支持不足,不允许更新主键。源和目标对于一些数据库并不支持,合并或者转换数据比较困难。
而 Flink 开发灵活,广泛的 connector 支持多种数据库,可以解决这些问题。
以下是方案示例:
此方案中,源数据为 RDS Mysql,通过 Flink CDC Connector,数据以 EMR Flink 处理,打入到 Kafka 消息队列,再以 Flink 消费数据,最终写入下游的目标数据库,包括 DynamoDB、DocumentDB 等。
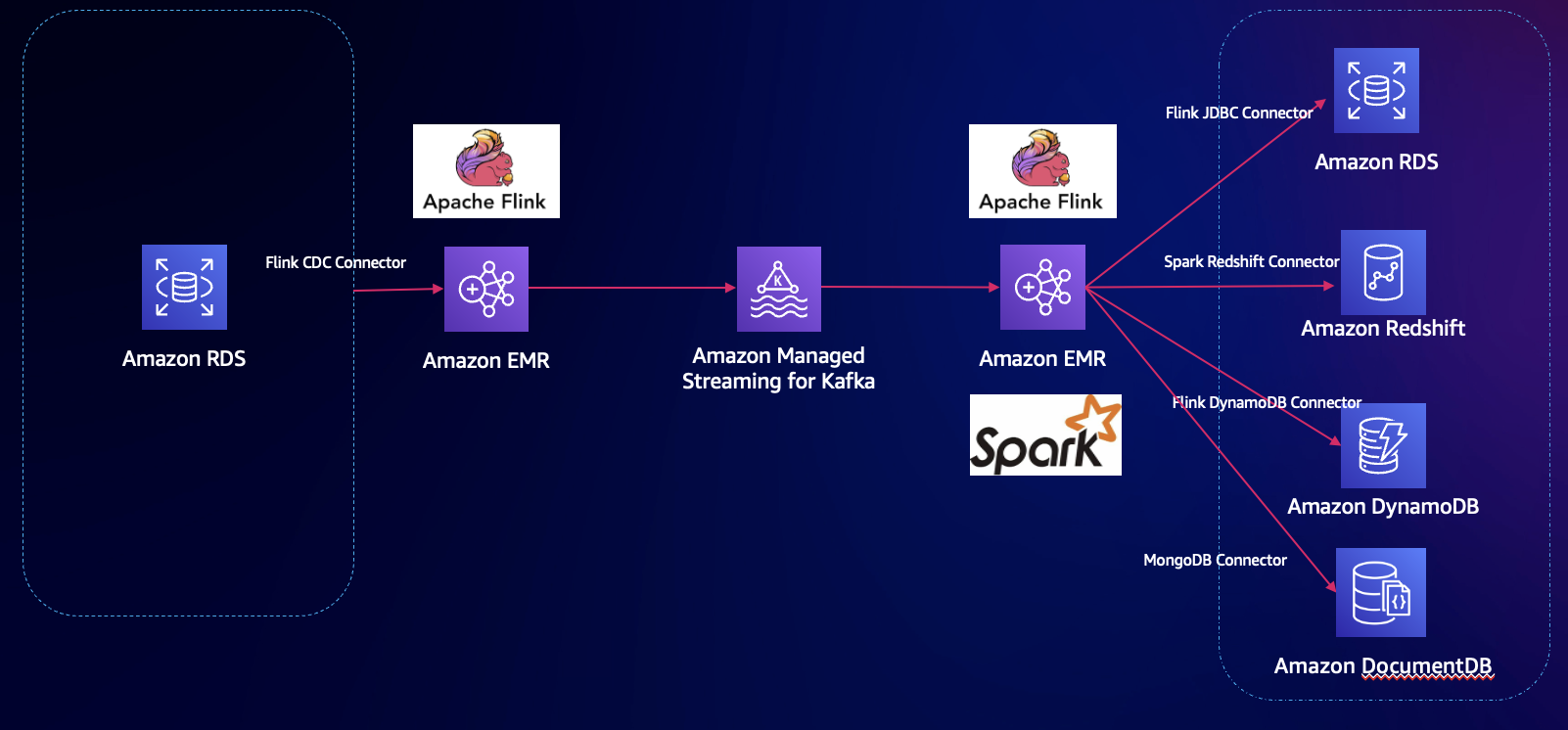
环境:
-
源数据库 RDS Mysql 8.0
-
目标数据库:DynamoDB
-
MSK Kafka 2.8.1
-
EMR 6.10.0: Flink 1.16.0, Flink SQL Connector MySQL CDC 2.3.0
下载相应 jar 包到 Flink lib目录 /usr/lib/flink,修改相关文件的权限和所有者:
flink-connector-jdbc-1.16.2.jar
flink-sql-connector-kafka-1.16.1.jar
flink-sql-connector-mysql-cdc-2.3.0.jar
flink-sql-connector-dynamodb-4.1.0-1.16.ja
cd /usr/lib/flink/lib
sudo chown flink:flink flink-sql-connector-dynamodb-4.1.0-1.16.jar
sudo chmod 755 flink-sql-connector-dynamodb-4.1.0-1.16.jar重启 Flink 以让 jar 成功加载:
/usr/lib/flink/bin
sudo ./stop-cluster.sh
sudo ./start-cluster.sh创建 Flink 应用:
./yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -nm flink-cdc-ddb查看 Flink 应用情况:
yarn application -listApplication-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1739533554641_0006 flink-cdc-ddb Apache Flink hadoop default RUNNING UNDEFINED 100% http://172.31.86.244:45475打开 Flink SQL 客户端:
./sql-client.sh embedded -s flink-cdc-ddb启用 checkpoint:
SET execution.checkpointing.interval = 3s;创建 Flink 表,关联 Mysql 表:
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = ‘xxxx',
'port' = '3306',
'username' = ‘user',
'password' = ‘password',
'database-name' = 'test',
'table-name' = 'product_view'
);创建 Flink Kafka 表,并把 Mysql 数据写入 Kafka。扫描数据从最早开始,’scan.startup.mode’ = ‘earliest-offset’
CREATE TABLE product_view_kafka_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH ('connector' = 'kafka','topic' = 'flink-cdc-kafka','properties.bootstrap.servers' = ‘xxxx:9092','properties.group.id' = 'flink-cdc-kafka-group','scan.startup.mode' = 'earliest-offset','format' = 'debezium-json’
);insert into product_view_kafka_sink select * from product_view_source;创建 Flink DynamoDB 表,并把 Kafka 队列里的数据写入 DynamoDB。Flink DynamoDB Connector 需要设置 PARTITIONED BY ( ),以和 DynamoDB 主键一致。
CREATE TABLE kafka_output(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp
) PARTITIONED BY ( id )
WITH ('connector' = 'dynamodb','table-name' = 'kafka_ddb','aws.region' = 'us-east-1’
);INSERT INTO kafka_output SELECT * FROM product_view_kafka_sink;最终可以看到,源端 Mysql 全量和增量变化数据,都写入到目标端 DynamoDB。
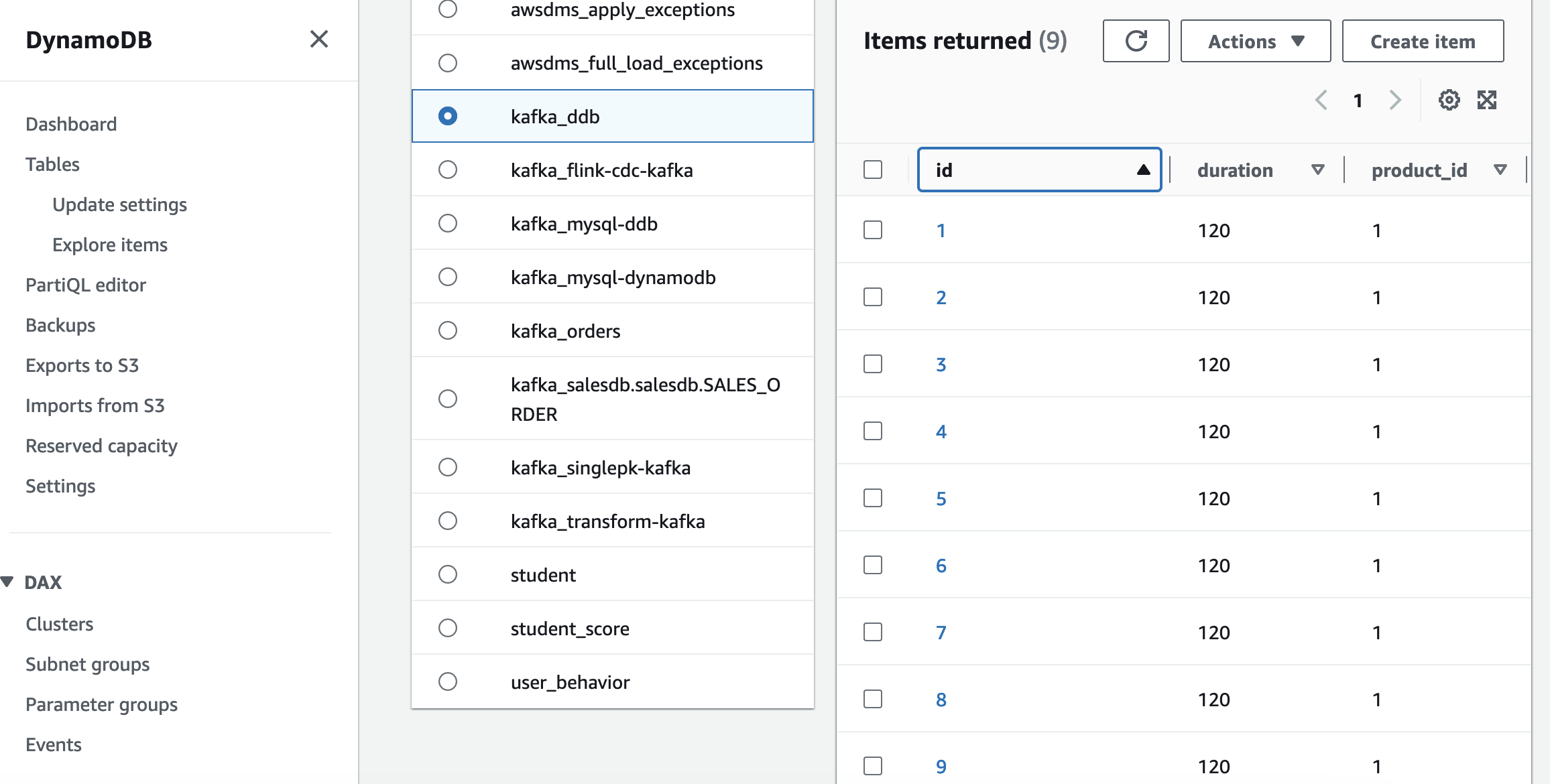
以下是 Kafka Debezium JSON 格式,包含数据前后变化:
{"before":null,"after":{"id":1,"user_id":1,"product_id":1,"server_id":1,"duration":120,"times":"120","time":"1587734040000"},"op":"c"}
{"before":null,"after":{"id":2,"user_id":1,"product_id":1,"server_id":1,"duration":120,"times":"120","time":"1587734040000"},"op":"c"}
…
{"before":{"id":10,"user_id":8,"product_id":1,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"after":null,"op":"d"}
{"before":null,"after":{"id":10,"user_id":8,"product_id":10,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"op":"c"}
{"before":{"id":10,"user_id":8,"product_id":10,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"after":null,"op":"d"}
{"before":null,"after":{"id":10,"user_id":8,"product_id":1,"server_id":2,"duration":120,"times":"120","time":"1589375640000"},"op":"c"}除了数据库之外,应用程序也需要从访问 Mysql 改为 DynamoDB,相应的数据库接口和读写语句也完全不一样。对于那些 DynamoDB 不是非常熟悉的开发者,如何更丝滑转换现有代码呢?Amazon Q Developer CLI AI 助手可以帮助我们大大降低转换代码的工作量。通过提示词,描述现有的项目情况,指定转换目标,实现业务需求。Amazon Q Developer CLI 会分析现有代码,根据需求和自己的理解,生成与原来业务实现一样的代码。整个过程无需过多干预,即使遇到错误,Amazon Q Developer CLI 也会自己排查然后解决,最终生成新的项目。
下面演示从 Mysql 到 DynamoDB 数据库代码改造的过程。项目使用 Python,Mysql 数据库作为聊天消息存储。
打开 Amazon Q Developer CLI,输入提示词:
Design Dynamodb as RDS Mysql table for chat message. Refer to SQL:
CREATE TABLE message (msgid STRING PRIMARY KEY,sessionid STRING NOT NULL,sender_id STRING NOT NULL,receiver_id STRING NOT NULL,message_type VARCHAR(20),content VARCHAR(1000),status VARCHAR(10),created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME
);
ID should be unique but incremental, considering snowflake algorithm. Each chat session(sessionid) may contain several messages with "msgid". Need query:
1. Chat sessions to get messages in time range.
2. Recent messages for sender and receiver.
Insert 10000 rows data.
RDS: <Your RDS Mysql endpoint>, user: admin, password: xxxx提示定义了 Mysql 聊天消息表结构,按照 snowflake 算法生成 id,查询实现两种业务,某个时间段的聊天会话,以及发送者或者接受者最近消息。在此基础上继续转换代码为 DynamoDB。
Amazon Q Developer CLI 进行以下工作:
1、构建 Mysql 代码,创建表,写入数据,并构造聊天消息的业务查询。
## MySQL Table Design
I've created a MySQL table with the following schema:
sql
CREATE TABLE message (msgid VARCHAR(255) PRIMARY KEY,sessionid VARCHAR(255) NOT NULL,sender_id VARCHAR(255) NOT NULL,receiver_id VARCHAR(255) NOT NULL,message_type VARCHAR(20),content VARCHAR(1000),status VARCHAR(10),created_at DATETIME DEFAULT CURRENT_TIMESTAMP,updated_at DATETIME
);With indexes for common query patterns:
sql
CREATE INDEX idx_sessionid ON message(sessionid);
CREATE INDEX idx_sender_id ON message(sender_id);
CREATE INDEX idx_receiver_id ON message(receiver_id);
CREATE INDEX idx_created_at ON message(created_at);2、创建 DynamoDB 表,按照 Mysql 业务逻辑构建,并创建相应索引。
## DynamoDB Design• **Primary Key**:• Partition Key: PK (String) - Composite key with different prefixes• Sort Key: SK (String) - Composite key for sorting and querying• **Global Secondary Indexes**:• GSI1: For session-based queries• GSI2: For sender-based queriesThis design efficiently supports your required query patterns:
1. Get messages in a session within a time range
2. Get recent messages for a sender or receiver## ID GenerationI've implemented a Snowflake-like ID generation algorithm in snowflake_id.py that creates:
• Time-sortable IDs (41 bits for timestamp)
• Unique across distributed systems (10 bits for machine ID)
• High throughput (12 bits for sequence number)3、写入测试数据,并从 Mysql 迁移数据到 DynamoDB,然后运行业务查询测试。
1. create_mysql_table.sql: SQL script to create the MySQL table
2. snowflake_id.py: ID generation utility
3. create_dynamodb_table.py: Script to create the DynamoDB table
4. generate_sample_data.py: Script to generate 10,000 sample messages in MySQL
5. migrate_to_dynamodb.py: Script to migrate data from MySQL to DynamoDB
6. query_examples.py: Examples of common query patterns
7. requirements.txt: Required Python packages
8. run.sh: Shell script to run the entire migration processAmazon Q Developer CLI 还总结了此方案的特点,包括:
-
高效 DynamoDB 查询
-
消息按照 DynamoDB 时间戳排序
-
使用 snowflake 雪花算法生成按时间排序的唯一消息 id
-
高扩展性
查看项目,Mysql 查询代码,改造为 DynamoDB:

DynamoDB 数据示例:
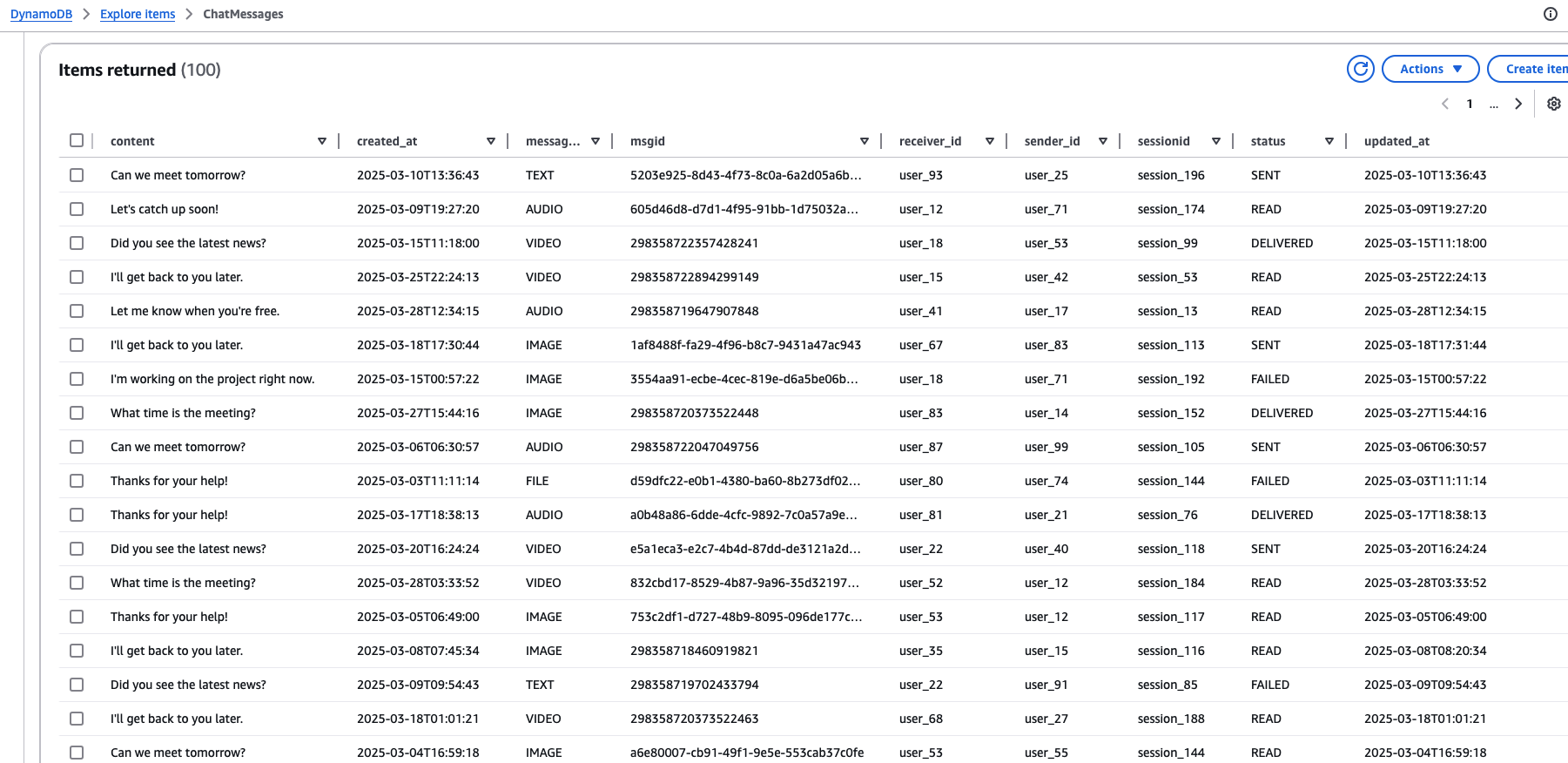
下面查看 Mysql 与 DynamoDB 的代码对比。
Mysql:实现按照时间查询会话,以及按照发送者查询消息。
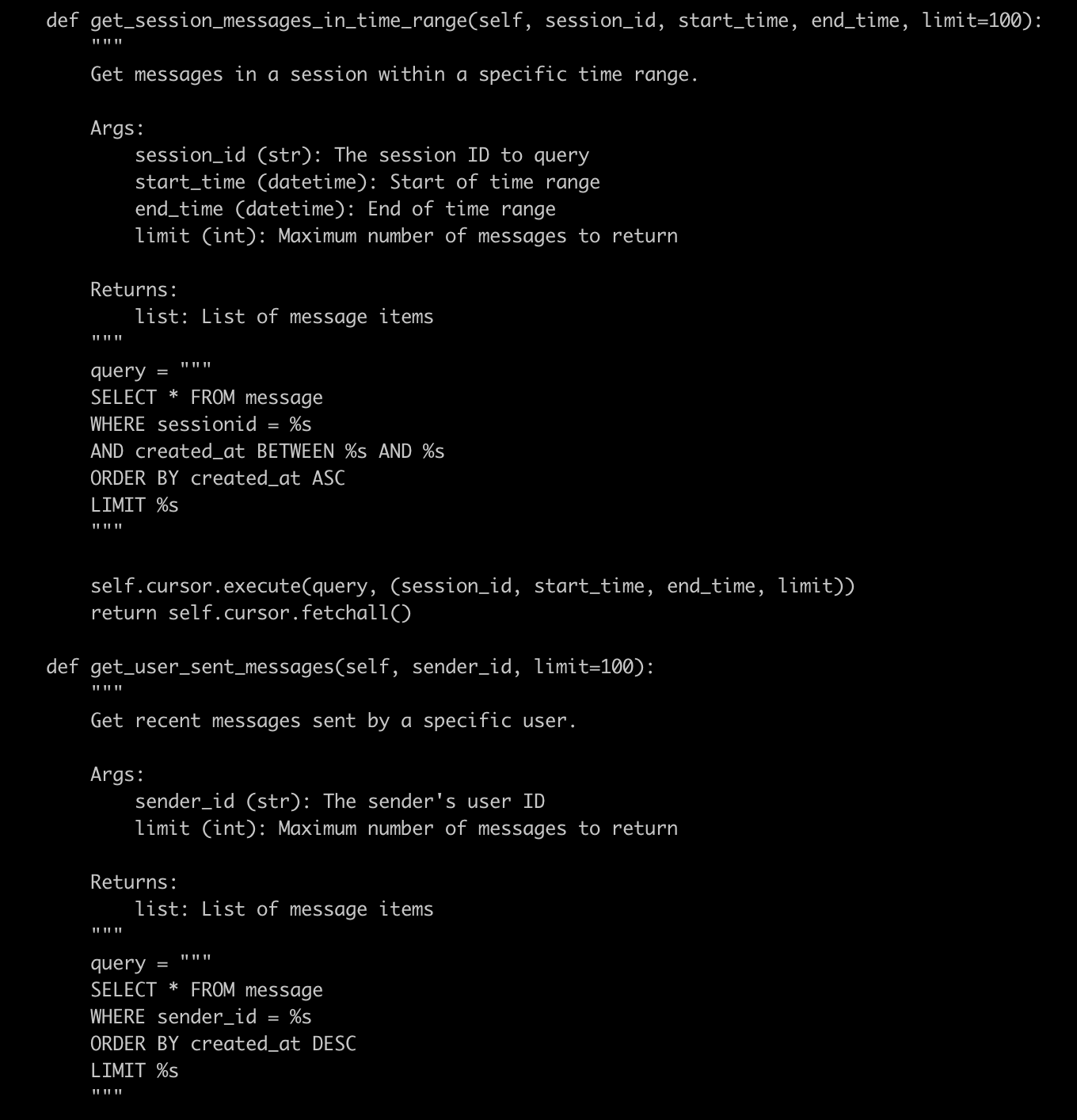
同样的业务逻辑,在 DynamoDB 实现时,原 Mysql SQL 语句为:
SELECT * FROM messageWHERE sessionid = %sAND created_at BETWEEN %s AND %sORDER BY created_at ASCLIMIT %s修改为 DynamoDB 查询后:
response = self.table.query(IndexName='SessionTimeIndex',KeyConditionExpression=Key('sessionid').eq(session_id) &Key('created_at').between(start_timestamp, end_timestamp),Limit=limit,ScanIndexForward=True # True for ascending (oldest first))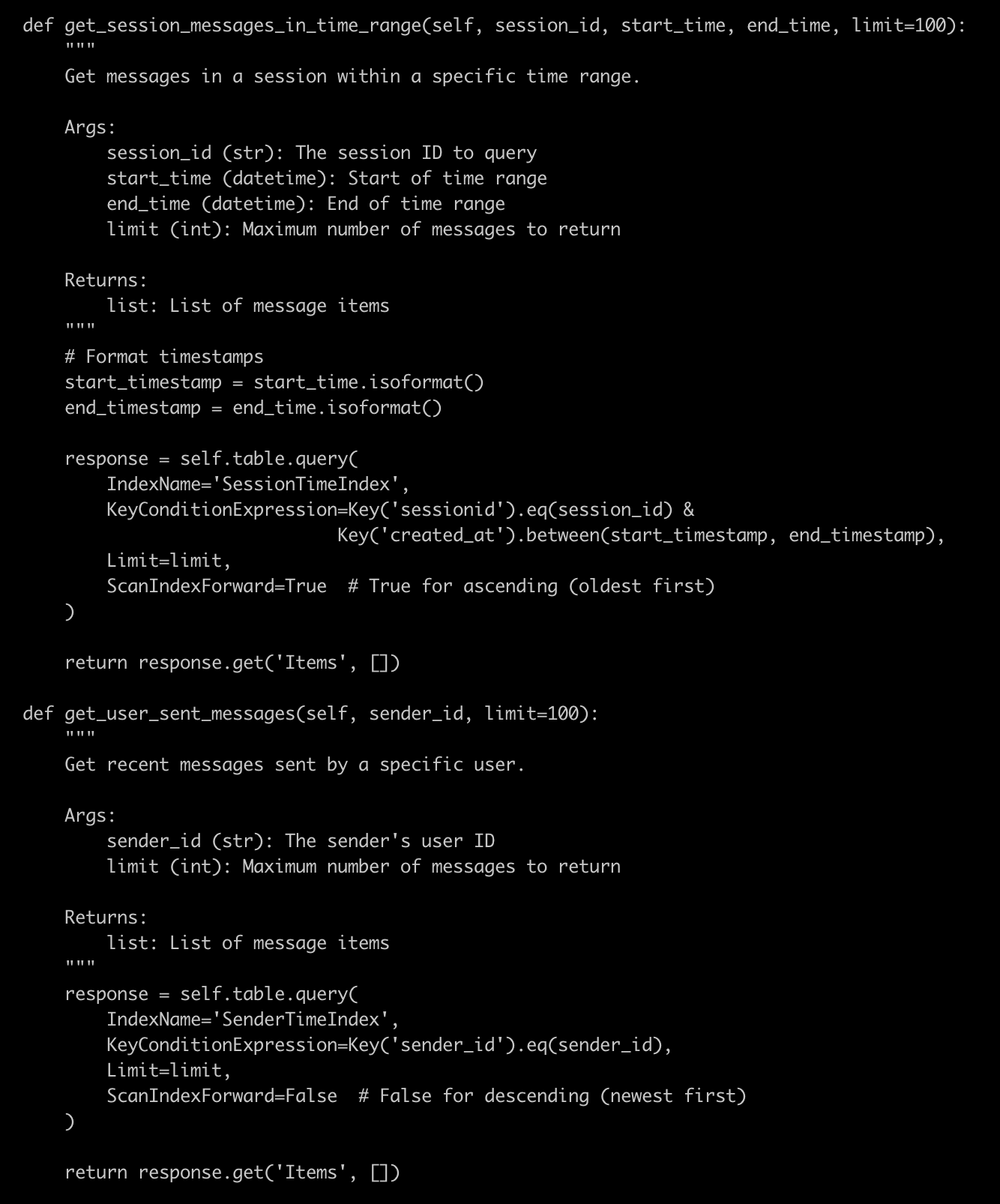
从以上示例可以看出,Amazon Q Developer CLI 可以加速 SQL 到更高效 NoSQL 的数据库代码改造。当然,我们可以给出更精确的要求,例如列出现有需求、合并或者转换数据等,都可以让 Amazon Q Developer CLI 帮助生成和转换代码。
Amazon Q Developer CLI 还生成了输出对比效果,转换前后结果一致。此过程中,无需编写任何一行代码,即可实现数据库代码的转换,业务功能没有变化,使用更为灵活的 NoSQL 数据库提高性能和扩展性。如果需要发挥 DynamoDB 更多性能优势,可以在提示词让 Amazon Q Developer CLI 遵循最佳实践来设计数据库,也可以按照业务需求做表合并等修改。
参考:GitHub - milan9527/mysql2nosql
场景 4:开源 NoSQL 数据库在线迁移到 Amazon SQL/NoSQL
NoSQL 数据库已经在很多行业广泛使用。例如,游戏中使用 MongoDB 作为战斗服玩家数据更新,Cassandra/CouchDB/Couchbase 等开源数据库也有应用。如果想要更多云原生 NoSQL 数据库的优势,无需自己维护分片和升级,或者更高弹性满足业务,Amazon DynamoDB/DocumentDB 更为适合。但是,不同数据库访问接口不一样,如何从开源 NoSQL 数据库平滑迁移到 DynamoDB?对于没有接触过 DynamoDB 的客户,需要一定的学习,而迁移工具也是影响落地的重要因素。Flink 支持多种开源 NoSQL Connector,也支持定制开发,在迁移过程中合并或者转换数据。
方案架构:
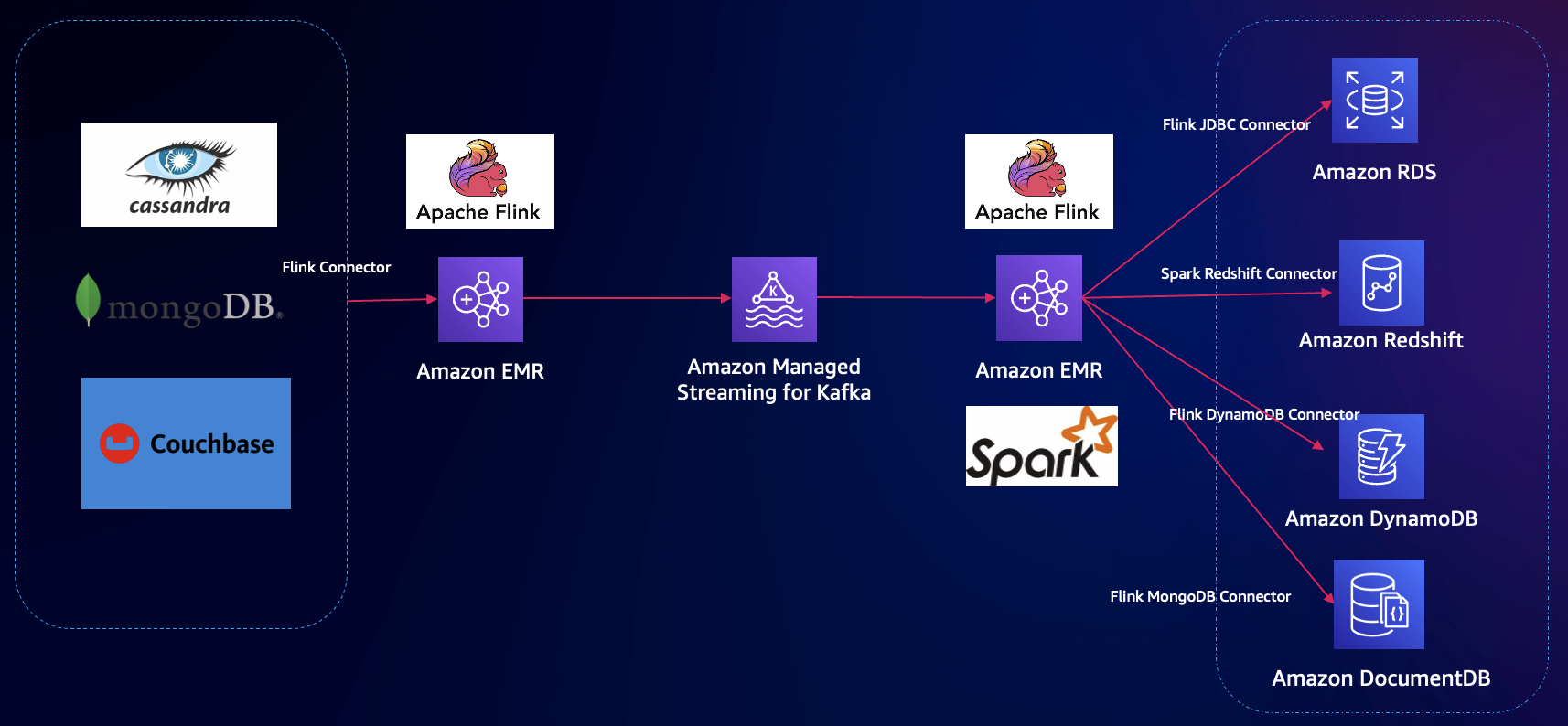
与场景 3 类似,只是源数据库从 SQL 变成 NoSQL 数据库,目标端可以是 NoSQL 或者 SQL 数据库,源数据库和 Flink 使用相应的 Connector 即可。
以下示例用 Amazon Q Developer CLI 生成 Flink 项目,从 Couchbase 迁移数据到 DynamoDB。此简易示例中没有使用 Kafka,而是直接以 Flink 连接源和目标,实现全量和增量数据复制。当然,Kafka 也支持一些 Connector,以此接入消息队列。
步骤:
安装 Couchbase,生成测试数据。
Amazon Q Developer CLI 提示词:
Need migrate database from Couchbase to Dynamodb. Create data pipeline by Flink. I have local Couchbase 7.6.6, Flink 1.6.2. Create project which can run in intellij idea IDEAmazon Q Developer CLI 生成 Flink Java 代码,运行出错:
org.apache.flink.api.common.eventtime.WatermarkStrategy;自动排错:
Let me fix those import errors. The issue is that some of the dependencies might not be correctly specified in the pom.xml file. Let‘s update the pom.xml to include the correct dependencies:Flink batch 模式错误,继续修复:
Exception in thread "main" java.lang.IllegalStateException: Detected an UNBOUNDED source with the 'execution.runtime-mode' set to 'BATCH'.
This error occurs because the Flink job is configured to run in BATCH mode, but your CouchbaseSource is being treated as an unbounded source (which is not allowed in BATCH mode).
Let me fix this issue by modifying the CouchbaseSource class to implement the SourceFunction interface correctly for batch processing:出现查询表错误,源表不存在,继续修复:
Caused by: com.couchbase.client.core.error.IndexFailureException: com.couchbase.client.core.error.IndexFailureException: The server reported an issue with the underlying index
I see the error. The issue is that the Couchbase query is trying to access a bucket named "default" but your configuration is set to use"gamesim-sample" as the bucket. Let me fix this mismatch至此,已经成功把数据从 Couchbase 通过 Flink 写入 DynamoDB。
下面继续优化,使用高可用设置,提高性能。自动修改代码,加入 Flink checkpoint 和重试机制,使用 batch 批量写入 DynamoDB,调整 Flink 并行度。
最后在项目中生成 Readme 文件,总结架构、使用方法、配置文件。
整个过程中无需手动编写代码,即可丝滑生成迁移项目。对于不熟悉 Flink 的开发者,也能实现迁移功能,建议 review 生成的代码功能,先在测试环境验证。
生成项目如下:simple-flink-migration/simple-flink-migration at main · milan9527/simple-flink-migration · GitHub
场景 5:DynamoDB 多表合并
游戏场景中经常有合服操作,多个游戏服务合成一个,相应的组件也需要合并。这里演示 DynamoDB 多表合并,此过程中还需要把数据结构稍微调整,并要求合并过程在线完成,不影响线上业务。
可以考虑的方案:
-
S3 export/import:DynamoDB 支持 S3 导入导出,但是需要异步进行,在数据量大时时间过久,并且不支持增量复制,要求目标表为新表。这些限制使得快速在线迁移难以实现。
-
DMS:DMS 源不支持 DynamoDB,复合主键有限制,此方案技术上不可行。
-
Hive + DynamoDB Stream:Hive 支持 DynamoDB,以外表方式操作 DynamoDB 表,结合 DynamoDB Stream 可以自己编写 Lambda 处理增量变化数据。但是此方案对 map 字段支持有限,也排除考虑。
-
Glue + DynamoDB Stream:Glue 以 Spark 程序访问 DynamoDB,也需要一些 Spark 开发经验,Glue 性能以 DPU 来控制,需要对此服务有所了解。
-
Flink:流批一体,支持全量+增量复制,可以在线迁移。灵活的数据接口和开发支持合并和转换操作。Flink 方案最合适。
具体实现方式上,Flink SQL 虽然简单,以 SQL 方式操作数据表,但是只支持 DynamoDB Sink 不支持 Source。Flink DataStream API 可以支持 DynamoDB 作为源和目标,需要开发代码。并非所有开发人员都熟悉 Flink,但是 Amazon Q Developer CLI 可以帮助实现整个数据流程、编写代码、构建 jar 包,并提交任务到 EMR Flink 应用。原来即使熟悉 Flink,整个开发过程也需要几天时间,而现在可以让 Flink 帮助我们几个小时完成测试。
整个方案架构如下。创建 EMR Flink,编写 Flink 程序,使用 Datastream API 访问多个 DynamoDB 表,合并转换数据,写入目标 DynamoDB 表。此过程还需要获取 DynamoDB 变化并写入目标表,开启 DynamoDB Stream。
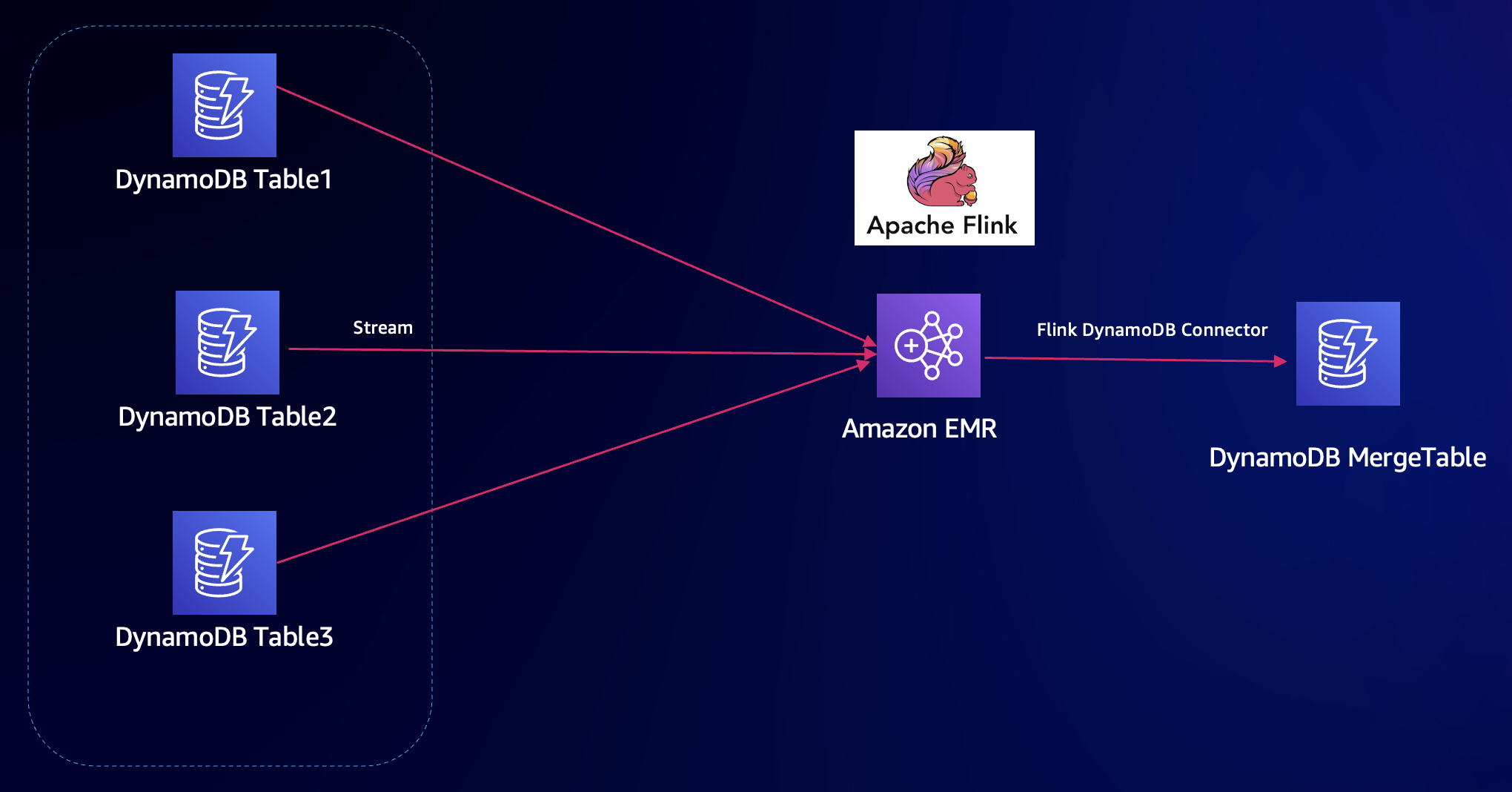
以下演示Amazon Q Developer CLI 构建过程:
提示词:{JSON}部分是 DynamoDB 数据结构,提供合并转换前后的数据样例。
Use EMR flink to merge and sync Dynamodb tables.
In us-east-1 region, 3 Dynamodb tables already exist(GameMailbox1, GameMailbox2, GameMailbox3) with the same schema for gaming mail box. Sample data:
{JSON}
Field "reward" data type is map.
Each table has almost 10000 items.
Combine the 3 tables into one merged table(GameMailboxMerged) with data format like:
(JSON}
The target merged table has the same gameId. Partition key is built as "gameId#mailId".
Data is processed via Flink includeing full load and cdc without interruption. Source table stream should be enabled. You can use existing EMR cluster "mvdemo" with flink 1.16. Make sure Flink keeps running for cdc. Use Flink datastream connector with Java for cdc. Also Java for full load.整个过程几乎无需过多干预,Amazon Q Developer CLI 自动调试运行,最终生成 Flink Java项目,并提交 EMR Flink 任务。
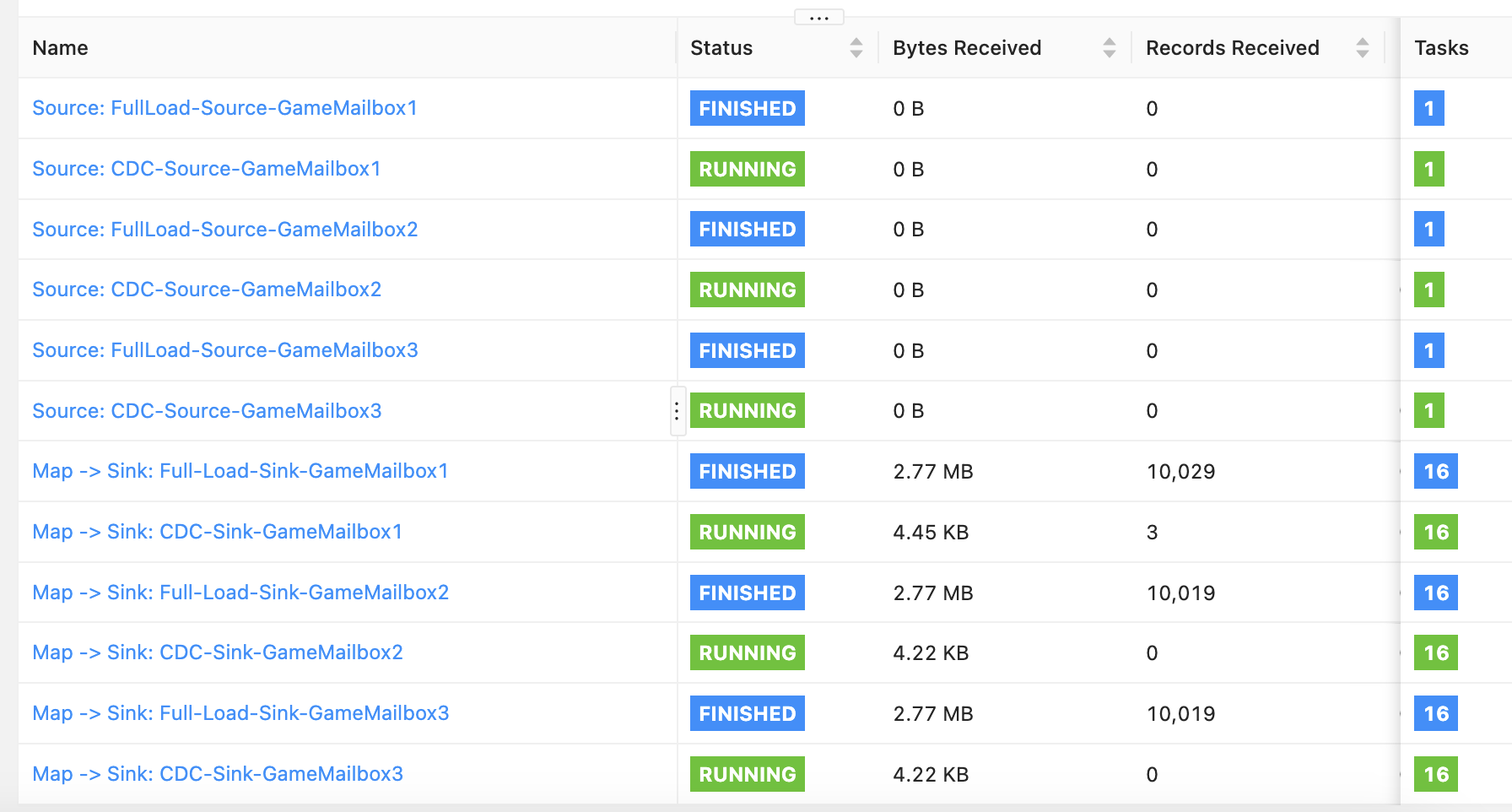
Flink UI 界面可以看到,全量 Full load 和增量 CDC 任务正常运行:
项目结构如下:GitHub - milan9527/dynamodbmerge
以下为合并处理逻辑,包含了处理删除操作,处理 Map 类型,写入 DynamoDB 数据:
public void invoke(GameMailboxMergedItem value, Context context) {try {// Check if this is a delete operationif (value.isDeleteOperation()) {// Delete the item from the target tabledeleteItem(value);} else {// Convert the item to a DynamoDB item and write itMap<String, AttributeValue> item = convertToAttributeValues(value);// Write to DynamoDBPutItemRequest putItemRequest = PutItemRequest.builder().tableName(tableName).item(item).build();dynamoDbClient.putItem(putItemRequest);LOG.info("Successfully wrote item with PK: {} to table: {}", value.getPK(), tableName);}最终,我们实现了业务需求,全量数据迅速加载,增量数据以 KCL 读取 DynamoDB Stream,增删改都可以快速复制,源表数据转换后按照预定格式复制到目标表。而且,Amazon Q Developer CLI 还提高了 Flink 运行效率和可靠性,以 checkpoint 实现 Exactly-once 只写一次,多表并行处理。
需要注意的是,Amazon Q Developer CLI 生成的代码仍然需要 review。测试中,Amazon Q Developer CLI 自由发挥,最开始的 stream pulling 时间稍长,在增量 CDC 部分使用 DynamoDB scan 到内存对比,虽然功能可以实现,但是效率低,成本高,后来改成更优的 DynamoDB Stream + KCL(Kinesis Client Library)方式。
场景 6:S3 离线数据快速写入数据库
对于应用程序收集的打点数据,离线数据会存储在 S3 以降低成本,每隔一段时间写入 S3。业务上需要在数据库快速访问这些数据,如何快速把这些离线数据写入数据库,是个很大的挑战。
通常此类数据量很大,并且并发访问很高,可以考虑 DynamoDB 这类高性能 NoSQL 数据库。批量写入可以使用 Flink,源端支持 S3 文件系统方式接口,目标端支持 DynamoDB。Flink SQL 支持简单的查询插入。
让我们看看以下需求:
S3 离线数据存储在 6 个目录,压缩 1.8 TB,一共 130 亿行。每隔一段时间批量写入 DynamoDB,要求尽快写完,最好 1 小时内。此需求的挑战在于,时间很短,整个方案要求写入处理速度很高。
考虑方案:
-
Dynamodb import from S3:导入为异步运行,导入时间过长,并且目标表必须为空。
-
DMS:单实例处理性能不足,不支持 DynamoDB 复合主键。
-
Hive MR/Tez:Hive 适合离线数据仓库,并非为高性能设计。MapReduce 引擎性能较低,即使使用 Tez,性能仍然成为瓶颈。
-
Flink:高性能,多节点并发处理,DynamoDB 支持每秒几百万的写入,成为解决问题的关键。
Flink 方案架构如下:
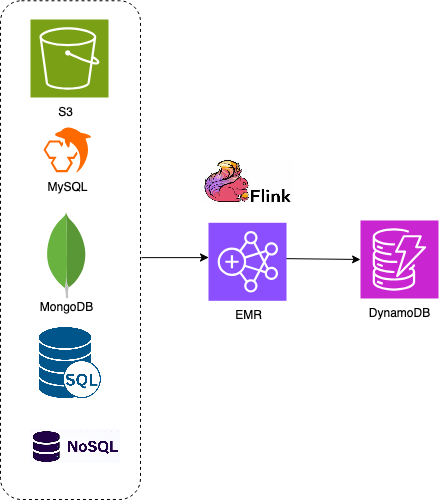
测试环境:
-
DynamoDB:WCU 10M,RCU 1.5M,需要提前预热,表读写容量可以根据需求调整。
-
EMR 6.10.0:Flink 1.16.0,1 个 primary 节点 + 32 个 core 节点,r8g.2xlarge,Flink 并行度 Parallelism=128,节点和并行度也可以调整。
Flink 运行过程参考之前场景 3。
创建 Flink S3 表:
CREATE TABLE s3_duf_3d(oneid string, duf_3d_feas_map string,
PRIMARY KEY (oneid) NOT ENFORCED
) WITH ('connector' = 'filesystem','path' = 's3://pingawsdemo/duf_1_3d_by_region/','format' = 'csv','csv.field-delimiter'='\t'
);创建 Flink DynamoDB 表:
CREATE TABLE ddb_fea (oneid string, type string, feas string
)
WITH ('connector' = 'dynamodb','table-name' = 'mydemo','aws.region' = 'us-east-1'
);S3 数据写入 DynamoDB:
INSERT INTO ddb_fea
SELECT oneid, 'duf_3d' AS type, duf_3d_feas_map AS feas FROM s3_duf_3d;
从 EMR Flink UI 可以看到,6 个任务同时运行:
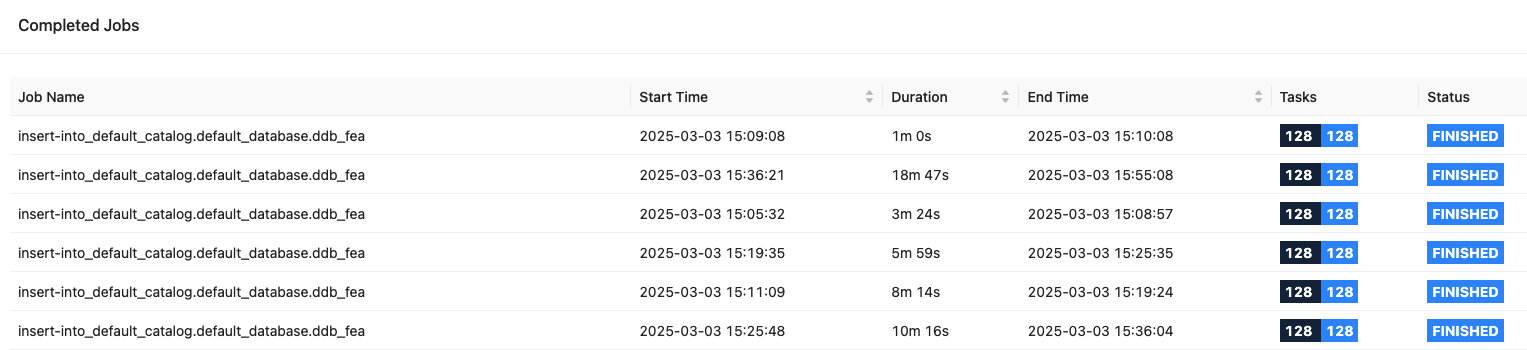
DynamoDB 指标:WCU 10M,相当于每秒写入 1 千万条 1KB 数据,写延迟 6ms,性能相当优异。
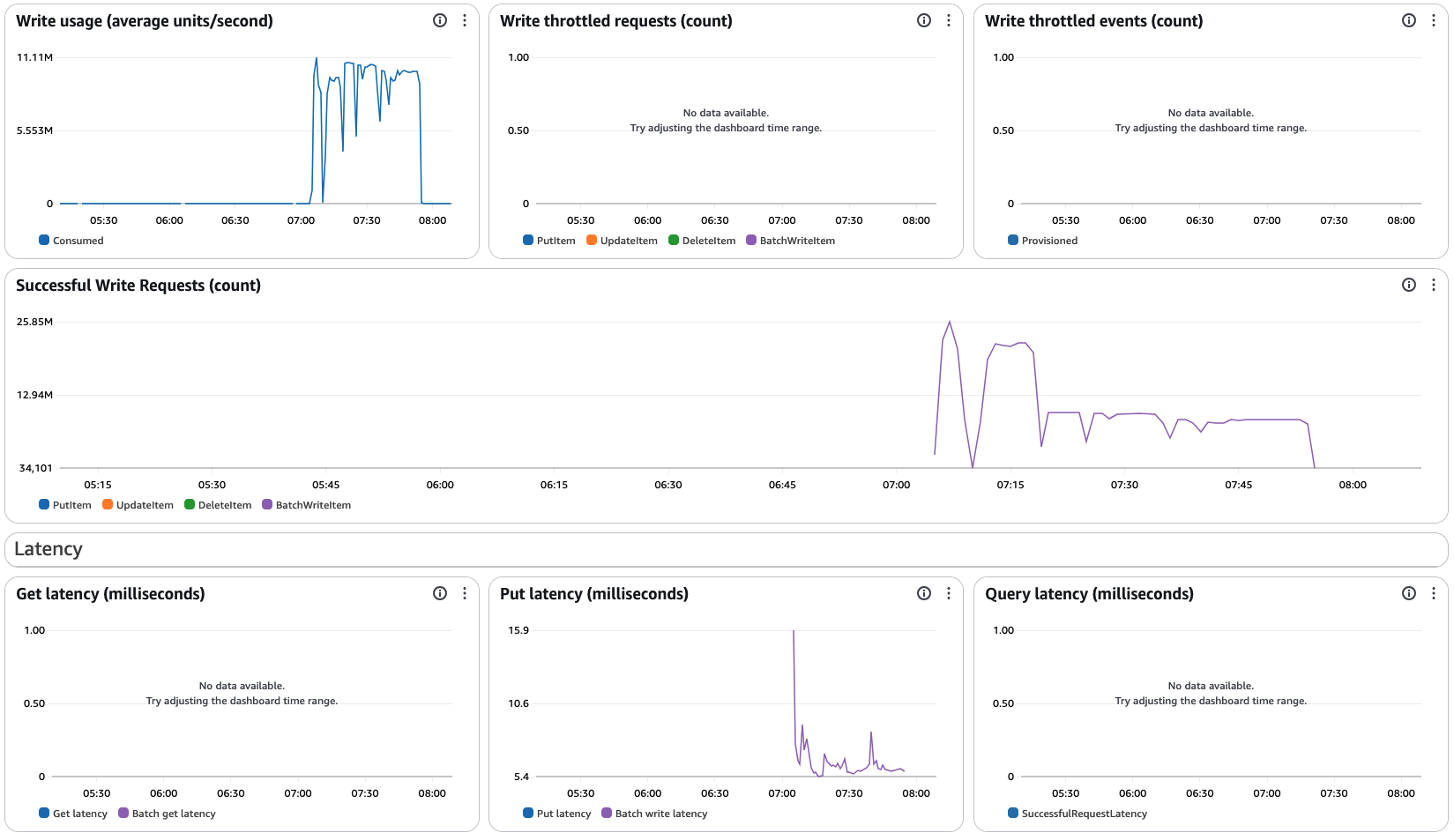
任务运行结果:
-
S3 文件解压后 20TB,总处理写入时间 47 分钟,平均 7GB/s。
-
这是 32 个 EMR 节点以及 Flink 并行度 128 的表现,可以适当调整 EMR 节点和并行度,以及 DynamoDB WCU。
-
Flink SQL 即可完成,无需编写代码。
此过程也可以用 Flink DataStream 开发,可考虑 Amazon Q Developer CLI AI 助手加速生成代码。
场景 7:中国和海外数据库数据复制
中国和海外区域隔离,服务不能互通,原生的跨区域数据复制功能不支持。对于需要国内外数据复制的场景,需要自行搭建复制工具。
参考:《合纵连横 – 以 Amazon Flink 和 Amazon MSK 构建 Amazon DocumentDB 之间的实时数据同步》。
Flink 作为 Zero ETL/DMS 的补充方案,在更多场景下可以发挥作用,也存在一些落地难度问题。Flink 提供多种使用方式,Flink SQL 更简单,用 SQL 即可完成表创建和上下游写入,但是部分源和目标可能不支持,并且合并转换不能用 SQL 完全实现。
相对而言,代码方式更加灵活。但是,并非所有运维人员都了解 Flink 开发,即使是开发人员,也不一定懂 Flink。Amazon Q Developer CLI AI 助手实现方案落地。我们只需要提需求,所有 Flink 开发工作交给大模型处理,包括下载 mvn 依赖,项目打包,创建 Flink 应用并提交任务,极大降低了 Flink 使用难度。
结论
Flink 可以构建灵活的数据库和数据仓库的数据管道,实现:
-
实时数据聚合计算
-
实时同步数据库到数据仓库
-
SQL 数据库在线迁移到 NoSQL
-
开源 NoSQL 到 Amazon DynamoDB 转换
-
DynamoDB 表合并
-
S3 离线数据快速写入 DynamoDB
-
中国和海外数据库稳定数据复制
使用 Amazon Q Developer CLI 快速搭建 Flink 管道,只需要描述需求,即可构建代码和服务组件,进行部署和测试,完成整个部署流程,大量节省时间,即使不熟悉 Flink 开发也可以使用。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者

本期最新实验为《Agentic AI 帮你做应用 —— 从0到1打造自己的智能番茄钟》
✨ 自然语言玩转命令行,10分钟帮你构建应用,1小时搞定新功能拓展、测试优化、文档注释和部署
💪 免费体验企业级 AI 开发工具,质量+安全全掌控
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!


![[特殊字符] FFmpeg 学习笔记](http://pic.xiahunao.cn/[特殊字符] FFmpeg 学习笔记)







高级应用和使用示例)

)

:完善解析逻辑/文档撰写模式全新升级)


![[深度学习]搭建开发平台及Tensor基础](http://pic.xiahunao.cn/[深度学习]搭建开发平台及Tensor基础)

