一.当申请的内存大小大于256kb的处理方式
因为256kb对于我们当前的实现其实也就32页,我们的页缓存上限是128页.所以思路非常清晰明了:当申请内存大小大于32页同时小于等于128页时,我们按照一页的方式向上对齐后计算所需页数,然后向页缓存申请.而大于128页的请求我们直接向堆申请:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){//当PageCache能满足需要时,我们向PageCache申请,满足不了直接向堆申请size_t pages = (AlignMoudle::AlignUpwards(size)) >> PAGE_SHIFT;PageCache::GetInstance()->_smutex.lock();Span* span = PageCache::GetInstance()->NewSpan(pages);PageCache::GetInstance()->_smutex.unlock();void* res = (void*)(span->_pageId << PAGE_SHIFT);return res;}else{//<MAX_BYTES时的逻辑if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}return pTLSThreadCache->Allocate(size);}
}static void ConcurrentFree(void* ptr,size_t size)
{if (size > MAX_BYTES){Span* FreeSpan = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_smutex.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(FreeSpan);PageCache::GetInstance()->_smutex.unlock();}else{//<MAX_BYTES时的逻辑assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}Span* PageCache::NewSpan(size_t pos)
{if (pos >= MAX_PAGE){//此时页缓存无法满足需求,直接向堆进行申请void* ptr = SystemAlloc(pos);Span* BigSpan = new Span;BigSpan->_n = pos;BigSpan->_pageId = ((PAGE_ID)ptr) >> PAGE_SHIFT;_idmapspan[BigSpan->_pageId] = BigSpan;return BigSpan;}//<128页均走原来的逻辑
...........................................................................................
void PageCache::ReleaseSpanToPageCache(Span* span)
{if (span->_n >= MAX_PAGE){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}//同上,<128页的时候走原来的逻辑
...........................................................................................二.使用对象池脱离使用new与Delete
因为原高并发内存池是通过某种技术脱离使用new与Delete的.而我们原来的代码中涉及new与delete的地方一共有三个地方:PageCache.cpp申请新Span与释放Span,comm.h中对于spanlist的头结点的申请,以及每个线程池申请自己的pTLSThreadCache.
而这些地方都是对对象的申请,所以我们就可以使用对象池来替换他们.因为ppTLSThreadCache涉及到多线程竞争问题,所以我们需要对对象池的申请与释放进行额外的加锁,以避免多线程的竞争问题.对于comm.h应在构造函数处定义局部静态对象池,不然如果是类静态成员变量则需要额外的加锁解锁.
ly/Project-Code//可以从ConCurrentMemoryPool提交记录中找到这部分的修改
三.释放对象时优化为不传对象大小
对于new与delete接口,delete释放对象的时候是不需要显示给对象大小的.但是我们能够获取释放对象的地址.因此,我们可以在span中新增一个objsize对象,用于记录当前span管理的页面上分配的对象的大小:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){//当PageCache能满足需要时,我们向PageCache申请,满足不了直接向堆申请size_t pages = (AlignMoudle::AlignUpwards(size)) >> PAGE_SHIFT;PageCache::GetInstance()->_smutex.lock();Span* span = PageCache::GetInstance()->NewSpan(pages);span->_objsize = size;PageCache::GetInstance()->_smutex.unlock();void* res = (void*)(span->_pageId << PAGE_SHIFT);return res;}else{//<MAX_BYTES时的逻辑if (pTLSThreadCache == nullptr){static ObjectPool<ThreadCache> _threcpool;//pTLSThreadCache = new ThreadCache;pTLSThreadCache = _threcpool.New();}return pTLSThreadCache->Allocate(size);}
}static void ConcurrentFree(void* ptr)
{Span* FreeSpan = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = FreeSpan->_objsize;if (size > MAX_BYTES){PageCache::GetInstance()->_smutex.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(FreeSpan);PageCache::GetInstance()->_smutex.unlock();}else{//<MAX_BYTES时的逻辑assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}//CentralCache::GetOneSpan
//走到这里说明当前中心缓存的该list哈希桶没有空闲页,则需要向页缓存申请新页,加全局锁
PageCache::GetInstance()->_smutex.lock();
Span* span = PageCache::GetInstance()->NewSpan(AlignMoudle::NumMovePage(byte_size));
span->_isUse = true;
span->_objsize = byte_size;
PageCache::GetInstance()->_smutex.unlock();四. 与malloc/free的性能对比
测试用例如下:
#include"ConcurrentAlloc.h"// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(malloc(16));v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){//v.push_back(ConcurrentAlloc(16));v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime.load());printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime.load());printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks * rounds * ntimes, malloc_costtime.load() + free_costtime.load());
}int main()
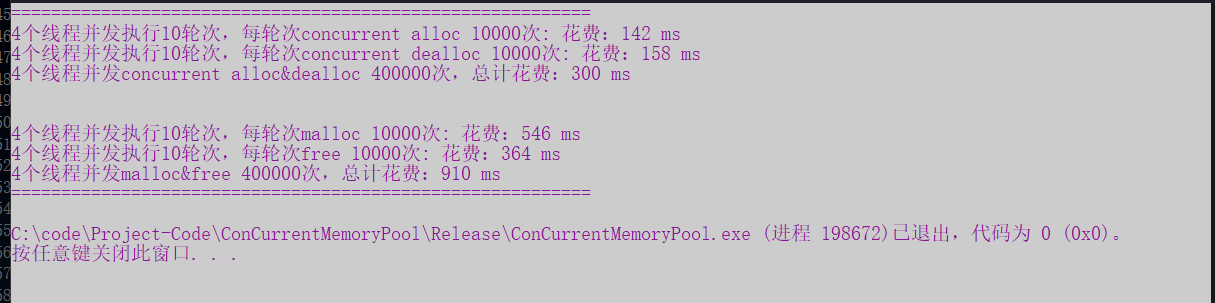
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" << endl;return 0;
} 
五.性能瓶颈分析
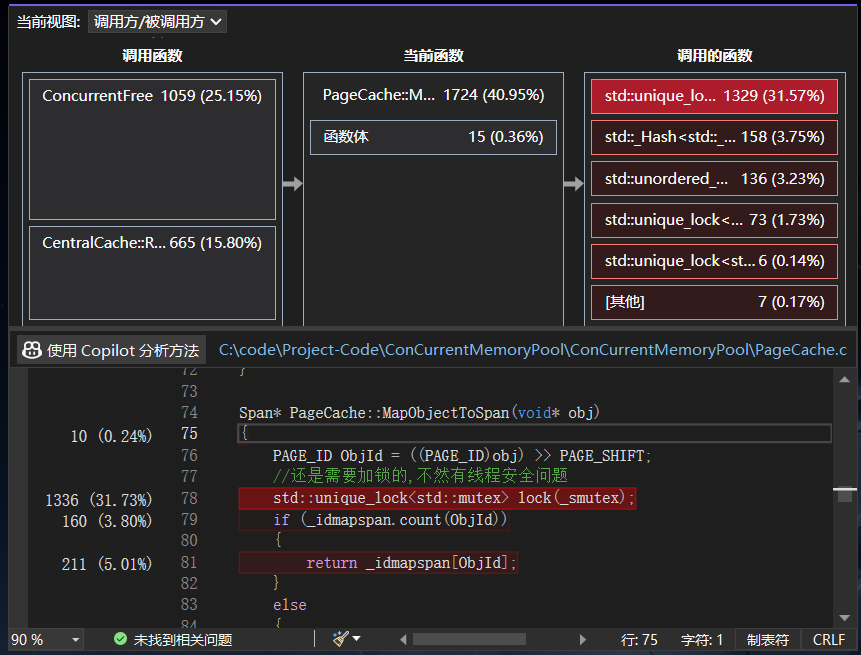
使用vs2022的性能分析工具,我们可以发现较为耗时的部分为查找映射表的函数部分,尤其是加锁解锁操作最为耗时.所以我们可以采取基数树的方式进行优化,也就是去掉MapObjectToSpan中的加锁解锁操作.
使用基数树进行优化
先来看效果:
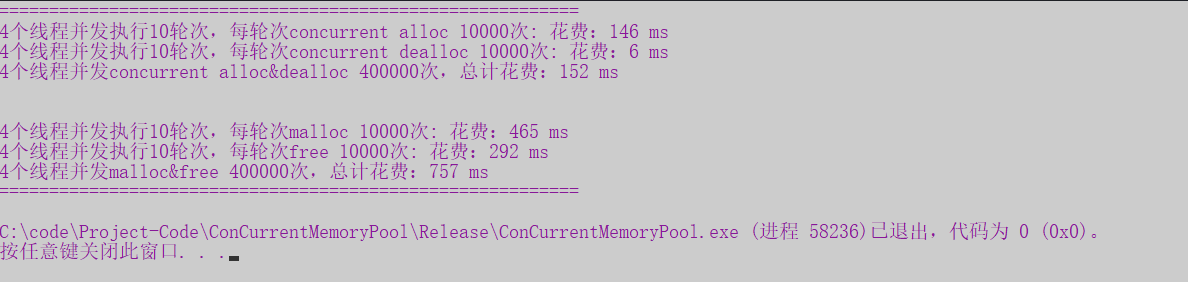
再来看基数树替换原来pagecache中哈希表的代码:
#pragma once
#include"Comm.h"// Single-level array
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//explicit TCMalloc_PageMap1(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap1() {//array_ = reinterpret_cast<void**>((*allocator)(sizeof(void*) << BITS));size_t size = sizeof(void*) << BITS;size_t alignSize = AlignMoudle::_AlignUpwards(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}// Return the current value for KEY. Returns NULL if not yet set,// or if k is out of range.void* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}// REQUIRES "k" is in range "[0,2^BITS-1]".// REQUIRES "k" has been ensured before.//// Sets the value 'v' for key 'k'.void set(Number k, void* v) {array_[k] = v;}
};// Two-level radix tree
template <int BITS>
class TCMalloc_PageMap2 {
private:// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodesvoid* (*allocator_)(size_t); // Memory allocatorpublic:typedef uintptr_t Number;//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {explicit TCMalloc_PageMap2() {//allocator_ = allocator;memset(root_, 0, sizeof(root_));PreallocateMoreMemory();}void* get(Number k) const {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 || root_[i1] == NULL) {return NULL;}return root_[i1]->values[i2];}void set(Number k, void* v) {const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);ASSERT(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> LEAF_BITS;// Check for overflowif (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) {//Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));//if (leaf == NULL) return false;static ObjectPool<Leaf> leafPool;Leaf* leaf = (Leaf*)leafPool.New();memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS);}
};// Three-level radix tree
template <int BITS>
class TCMalloc_PageMap3 {
private:// How many bits should we consume at each interior levelstatic const int INTERIOR_BITS = (BITS + 2) / 3; // Round-upstatic const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;// How many bits should we consume at leaf levelstatic const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Interior nodestruct Node {Node* ptrs[INTERIOR_LENGTH];};// Leaf nodestruct Leaf {void* values[LEAF_LENGTH];};Node* root_; // Root of radix treevoid* (*allocator_)(size_t); // Memory allocatorNode* NewNode() {Node* result = reinterpret_cast<Node*>((*allocator_)(sizeof(Node)));if (result != NULL) {memset(result, 0, sizeof(*result));}return result;}public:typedef uintptr_t Number;explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {allocator_ = allocator;root_ = NewNode();}void* get(Number k) const {const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 ||root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {return NULL;}return reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3];}void set(Number k, void* v) {ASSERT(k >> BITS == 0);const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);reinterpret_cast<Leaf*>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;}bool Ensure(Number start, size_t n) {for (Number key = start; key <= start + n - 1;) {const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);// Check for overflowif (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)return false;// Make 2nd level node if necessaryif (root_->ptrs[i1] == NULL) {Node* n = NewNode();if (n == NULL) return false;root_->ptrs[i1] = n;}// Make leaf node if necessaryif (root_->ptrs[i1]->ptrs[i2] == NULL) {Leaf* leaf = reinterpret_cast<Leaf*>((*allocator_)(sizeof(Leaf)));if (leaf == NULL) return false;memset(leaf, 0, sizeof(*leaf));root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node*>(leaf);}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory() {}
};基数树优化比原来快的根本原因是因为它避免了频繁的加锁解锁,因为他是读写分离的(STL容器不保证线程安全问题).为什么是这样,我们这里不再介绍,有兴趣的读者可以参考下面连接的文章:
查找——图文翔解RadixTree(基数树) - wgwyanfs - 博客园
完整的基数树优化代码如下:
ConCurrentMemoryPool · ly/Project-Code - 码云 - 开源中国








(yakit方式))




)





