摘要
利用注意力机制的视觉表示模型在追求大感受野时面临着巨大的计算开销。在本研究中,我们通过引入基于物理热传导原理的热传导算子(Heat Conduction Operator, HCO)来缓解这一挑战这么高级咩(⊙o⊙)!。HCO将图像块视为热源,并通过自适应的热能扩散来模拟它们之间的相关性,从而实现鲁棒的视觉表示。HCO的计算复杂度为O(N^1.5),因为它可以通过离散余弦变换(DCT)操作实现。HCO是一种即插即用的模块,与深度学习主干网络结合后可以产生具有全局感受野的视觉表示模型(称为vHeat)。在各种视觉任务的实验中表明,除了性能更强之外,与Swin-Transformer相比,vHeat实现了高达3倍的吞吐量、减少80%的GPU内存分配以及减少35%的计算浮点运算量(FLOPs)。
代码可在以下链接获取:https://github.com/MzeroMiko/vHeat 和 https://openi.pcl.ac.cn/georgew/vHeat。
1、引言
卷积神经网络(CNNs)自深度学习兴起以来一直是视觉表示的基石,在各种视觉任务中展现出卓越的性能。然而,依赖于局部感受野和固定的卷积操作限制了其捕捉图像中长距离和复杂依赖关系的能力。这些局限性激发了开发替代视觉表示模型的浓厚兴趣,包括基于视觉变换器(ViTs)和状态空间模型的架构。尽管这些模型表现出色,但它们仍面临挑战,包括相对较高的计算复杂度和缺乏可解释性。
-----------------------------------------------------------------------------CNN和VIT架构解析---------------------------------------------------------------------------------
- CNN
- 卷积操作。基于卷积核在输入图像上滑动,提取局部特征,这种局部感受野特性使得CNN能够很好地捕捉图像中的局部纹理、边缘等信息。CNN的特征提取是先提取局部信息,在逐步抽象到整体特征。
- CNN结构。CNN结构通常包含卷积层、池化层和全连接层。池化层用于降低特征图的空间维度,减少计算量,同时保留重要特征。全连接层则用于将提取到的特征进行组合,输出最终的分类结果或回归值。
- 归纳偏置。归纳偏置其实就是一种先验知识,一种提前做好的假设。在CNN中的归纳偏置一般包括两类: locality(局部性)和translation equivariance(平移不变性):
- locality:假设相邻的区域会有相邻的特征,靠得越近的东西相关性能也就越强。局部性可以控制模型的复杂度。
- translation equivariance:由于卷积核是一样的所以不管图片中的物体移动到哪里,只要是同样的输入进来遇到同样的卷积核,那么输出就是一样的。利用平移等变形可以很好的提高模型的泛化能力。
- ViT
- 对比。先前将Transformer应用于CV领域的工作,都和CNN相关。要么时将CNN卷积后的特征图应用自注意力机制,要么是将注意力机制当成卷积核,应用于局部图像。这样做的原因是,假设一张图像的大小是224*224,那么对每个像素点进行自注意力操作后,计算量会变得很大。因此Transformer的最大改动是将图像分块,这样大大减少了计算量。
- 结构。ViT通过自注意力机制同时考虑图像块之间的全局关系。在处理图像时,每个图像块的特征更新都会受到其他所有图像块的影响。例如,在识别一张风景图片时,ViT能够同时考虑天空、山脉、河流等不同区域之间的关系,从而更好地理解整个图像的语义信息。不具有CNN那样的明确的层次化特征提取过程。虽然Vi也可以T通过堆叠多层Transformer模块来提取更复杂的特征,但它的每一层都是在全局范围内进行特征更新,而不是像CNN那样逐层从局部到整体提取特征。
- 在大规模数据集上表现出色。当有足够大的数据集进行训练时,ViT能够学习到更丰富的特征表示。例如在ImageNet - 21k(一个包含21000个类别的大规模图像数据集)上预训练的ViT模型,在迁移到其他任务时往往能够取得更好的性能。
- 总结
使用基于CNN的方法存在感受野有限的问题,不能很好的建模长远的依赖关系(全局信息),而基于transformer的方法可以很好的建模全局信息但是transformer反而缺乏类似于CNN的归纳偏置,这些先验信息必须通过大量的数据来进行学习,所以小的数据在CNN上取得的效果一般优于基于transformer的方法。训练基于CNN的方法通常只需要一个较小的数据集,而训练基于transformer的方法一般需要再大的数据集上进行预训练。
------------------------------------------------------------------------------结束---------------------------------------------------------------------------------------------------
在解决这些限制时,我们从热传导领域汲取灵感,其中空间局部性对于热能的传递至关重要,因为相邻粒子的碰撞导致了热能的传递。值得注意的是,热传导原理与视觉语义在空间域内的传播之间存在类比关系,因为特定尺度下相邻的图像区域往往包含相关的信息或具有相似的特征。基于这些联系,我们引入了vHeat,这是一种受物理启发的视觉表示模型,它将图像块视为热源,并将它们之间相关性的计算建模为热能的扩散。
你小子叽里咕噜说什么呢,一点都听不懂,努力理解一下:
- 热传导原理:热传导是热量从一个地方传到另一个地方的过程,热量传导过程其实是铁棒里的粒子相互碰撞,热能就从热的地方传导冷的地方。
- 图像中的热传导类比:在图像里,相邻的区域往往也很相似。比如,一张照片里的一块草地,草地上的每一小块区域(比如几根草)看起来都差不多,它们的颜色、纹理等特征很相似。这就像是热传导里的“相邻粒子”,它们之间有很强的关联。
图2. 信息传导机制的比较:自注意力与热传导。(a)自注意力算子将信息从一个像素“传导”到所有其他像素,导致复杂度为O(N²)。(b)热传导算子(HCO)将中心像素视为热源,并通过离散余弦变换(DCT,记为F)和逆离散余弦变换(IDCT,记为F⁻¹)来传导信息传播,该方法具有可解释性、全局感受野以及O(N¹⁵)的复杂度。
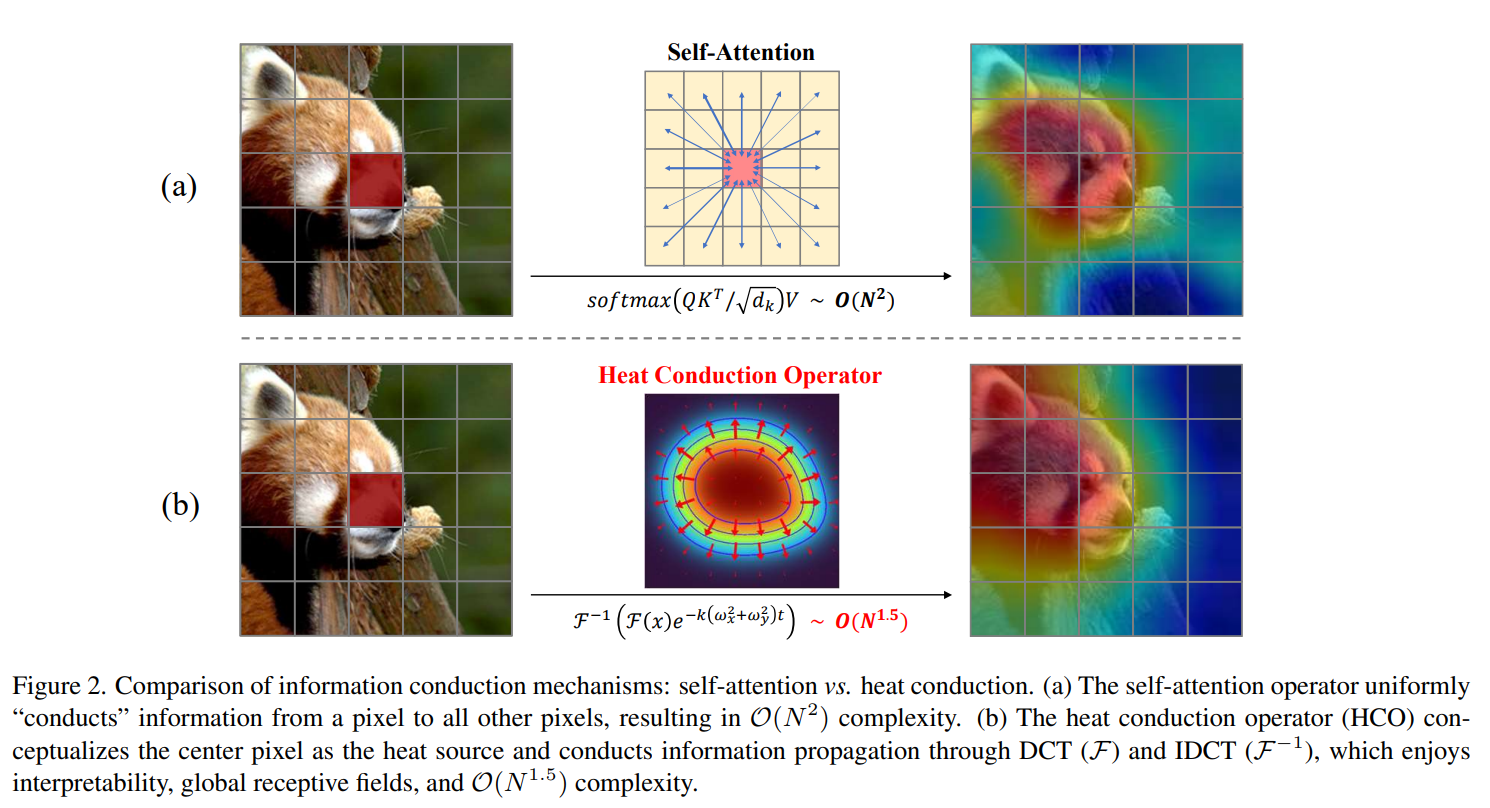
为了将热传导原理整合到深度网络中,我们首先推导出二维空间中热传导的一般解,并将其扩展到多个维度,对应于特征通道。基于这一一般解,我们设计了热传导算子(HCO),它模拟了视觉语义在图像块之间的多维传播。值得注意的是,我们证明了HCO可以通过二维离散余弦变换(DCT)和逆离散余弦变换(IDCT)近似实现,有效将计算复杂度降低到O(N^1.5)。这一改进由于DCT和IDCT操作的高度并行性,显著提高了训练和测试的效率。此外,由于DCT获得的频域中的每个元素都包含了图像空间中所有块的信息,因此vHeat能够建立长距离的特征依赖关系,并实现全局感受野。为了增强vHeat的表示适应性,我们提出了可学习的频率值嵌入(FVEs),以表征频率信息并预测视觉热传导的热扩散率。
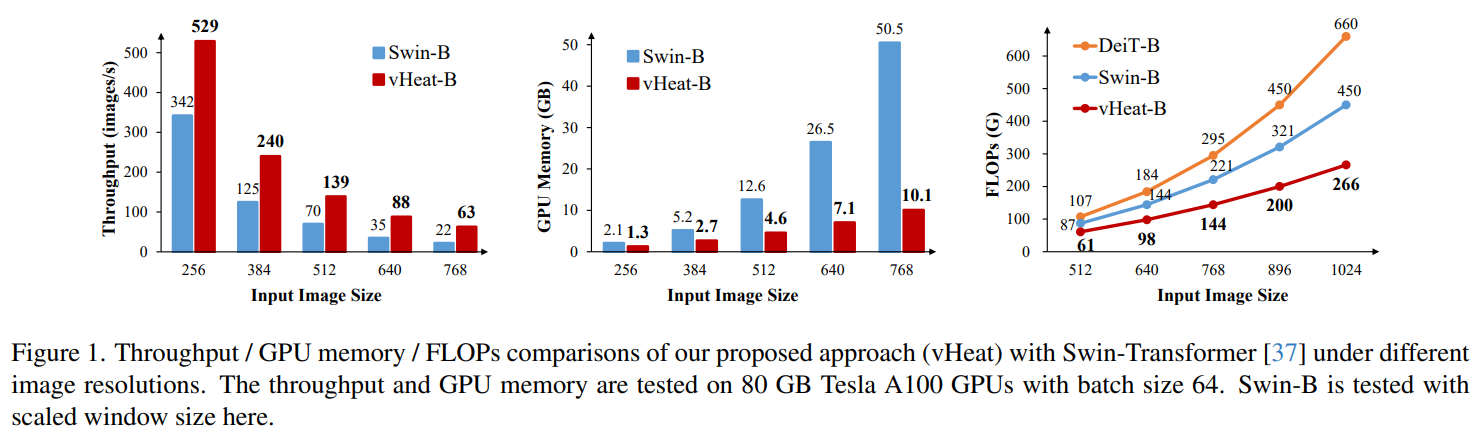
我们开发了一系列vHeat模型(即vHeat-Tiny/Small/Base),并通过广泛的实验验证了它们在多样化视觉任务中的有效性。与各种架构的基准视觉主干网络(例如ConvNeXt、Swin和Vim)相比,vHeat在图像分类、目标检测和语义分割任务中始终表现出更优的性能。具体而言,vHeat-Base在ImageNet-1K上实现了84.0%的top-1准确率,比Swin高出0.5%,并且其吞吐量比Swin高出超过40%(661对比456)。为了探索vHeat的泛化能力,我们还在鲁棒性评估基准和低级视觉任务中验证了其优越性。此外,由于HCO的O(N^1.5)复杂度,vHeat相比基于ViT的模型具有显著更低的计算成本,表现出更少的浮点运算量(FLOPs)和GPU内存需求,以及随着图像分辨率增加而更高的吞吐量。特别是当输入图像分辨率增加到768×768时,vHeat-Base的吞吐量比Swin高出3倍,GPU内存分配减少80%,计算FLOPs减少35%。
本研究的贡献总结如下:
- 我们提出了vHeat,这是一种受热传导物理原理启发的视觉主干模型,同时实现了全局感受野、低计算复杂度和高可解释性。
- 我们设计了热传导算子(HCO),这是一个物理上合理的模块,将图像块视为热源,通过频率值嵌入(FVEs)预测自适应的热扩散率,并按照热传导原理传递信息。
- vHeat在视觉任务(包括图像分类、目标检测和语义分割)中取得了令人鼓舞的性能,同时在高分辨率图像上实现了更高的推理速度、更少的FLOPs和更低的GPU内存使用。
2、相关工作
2.1 卷积神经网络(CNNs)
CNNs在视觉感知的历史中一直是里程碑式的模型[30, 31]。CNNs的独特特性体现在卷积核上,这些卷积核在特定设计的GPU上具有很高的计算效率。借助强大的GPU和大规模数据集[14],人们提出了越来越深[24, 29, 52, 57]、更高效的模型[27, 46, 58, 73],以在各种视觉任务中实现更高的性能。为了提升卷积操作的能力[10]、效率[28, 74]和适应性[11, 69],人们对其进行了大量改进。然而,CNNs的局部感受野这一固有限制依然存在。最近开发的大型卷积核[16]在扩大感受野方面迈出了一步,但在处理高分辨率图像时遇到了困难。
2.2 视觉变换器(Vision Transformers)
基于自注意力算子[63]构建的ViTs在构建全局特征依赖方面具有天然优势。凭借自注意力在所有图像块之间的学习能力,ViTs在有大规模数据集用于预训练的情况下,已成为迄今为止最强大的视觉模型[18, 45, 61]。引入分层架构[12, 15, 17, 37, 41, 60, 67, 79, 80]进一步提升了ViTs的性能。然而,ViTs是O(N²)的计算复杂度,这意味着在处理高分辨率图像时会带来巨大的计算开销。人们通过引入窗口注意力、线性注意力和交叉协方差注意力算子[1, 6, 37, 66]来提高模型效率,但代价是缩小了感受野或降低了非线性能力。还有研究通过在ViTs中引入卷积操作[12, 64, 68]或设计混合架构将CNN与ViT模块结合起来[12, 41, 54],提出了混合网络。
2.3 状态空间模型和循环神经网络(RNNs)
状态空间模型(SSMs)[22, 43, 65]具有线性复杂度的长序列建模能力,也被从自然语言领域迁移过来(例如Mamba[21])。通过将选择性扫描机制适应于二维图像,设计了视觉SSMs[36, 82]。然而,基于选择性扫描机制的SSMs由于并行性有限,限制了其整体潜力。最近的受控加权键值(RWKV)和RetNet模型[44, 56]在保持线性复杂度的同时提高了并行性。它们结合了Transformer的高效并行化训练和RNN的高效推理,利用线性注意力机制,使模型既可以表示为Transformer,也可以表示为RNN,从而在训练期间并行化计算,并在推理期间保持恒定的计算和内存复杂度。尽管具有这些优势,但将二维图像建模为序列会降低可解释性。
2.4 生物和物理启发模型
生物和物理原理一直是创造视觉模型的源泉。扩散模型[26, 49, 53]受到非平衡热力学[13]的启发,能够通过为扩散步骤定义马尔可夫链来生成图像。QB-Heat[8]利用物理热传导方程作为掩码图像建模任务的监督信号。脉冲神经网络(SNNs)[20, 32, 59]声称能更好地模拟生物神经元的信息传递,为简单的视觉任务构建模型[4]。这些模型的成功鼓励我们探索物理热传导原理,以开发视觉表示模型。(○´・д・)ノ
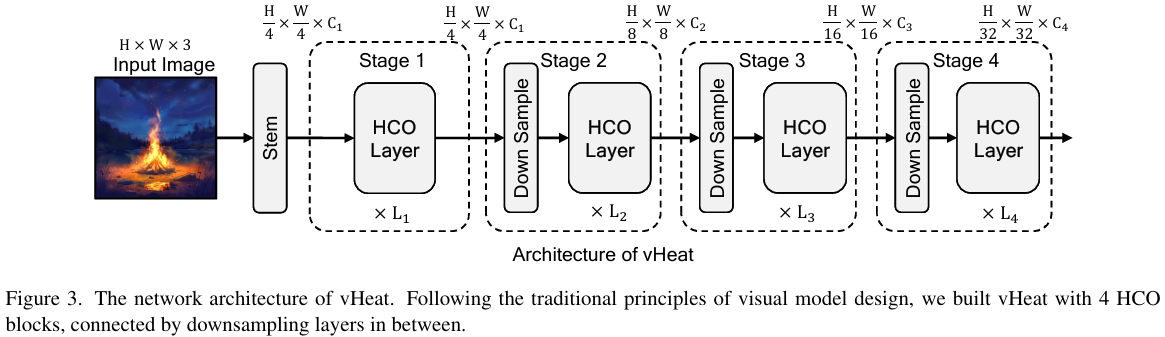
3、 Methodology





4、实验
1. 图像分类
图像分类的结果总结在表1中。在相似的计算量(FLOPs)下,vHeat实现了82.2%的top-1准确率,分别超过了Swin-T和Vim-S 0.9%和0.8%。值得注意的是,vHeat在Small和Base尺度上也表现出优越性。具体来说,vHeat-B在仅11.2 GFLOPs和68M模型参数的情况下,实现了84.0%的top-1准确率,分别超过了Swin-B和Vim-B 0.5%和0.8%。
在计算效率方面,vHeat在Tiny/Small/Base模型尺度上相比基准模型享有显著更高的推理速度。例如,vHeat-T实现了每秒1514张图像的吞吐量,比Vim-S高出87%,比ConvNeXt-T高出26%,比Swin-T高出22%,同时保持了性能优势。
2. 目标检测和实例分割
作为骨干网络,vHeat在MSCOCO2017数据集上进行了目标检测和实例分割的测试。我们加载了分类预训练的vHeat权重进行下游评估。由于输入图像大小与分类任务不同,需要将FVEs或k的形状对齐到下游任务的目标图像大小。更多细节请参考补充材料中的D.1节。
目标检测的结果总结在表2中,vHeat在两种训练计划(12或36个epoch)中均在box/mask平均精度(APb和APm)方面表现出优越性。例如,在12个epoch的微调计划下,vHeat-T/S/B模型分别实现了45.1%/46.8%/47.7%的目标检测mAP,分别超过了Swin-T/S/B 2.4%/2.0%/0.8% mAP,以及ConvNeXt-T/S/B 0.9%/1.4%/0.7% mAP。在相同的配置下,vHeat-T/S/B分别实现了41.2%/42.3%/43.0%的实例分割mAP,超过了Swin-T/S/B和ConvNeXt-T/S/B。在36个epoch(3×)的微调计划下,vHeat的优势依然存在,且在多尺度训练下表现稳定。此外,vHeat相比Swin和ConvNeXt享有更高的推理速度(FPS)。例如,vHeat-B实现了每秒20.2张图像,比Swin-B/ConvNeXt-B(13.8/14.1张图像/秒)高出46%/43%。这些结果突出了vHeat在密集预测下游任务中提供强大性能和效率的潜力。
3. 语义分割
在ADE20K数据集上的结果总结在表3中,vHeat在Tiny/Small/Base尺度上一致地超过了其他基线模型。例如,vHeat-B分别超过了NAT-B和ViL-B 1.1%/0.8% mIoU。
4. 鲁棒性评估
为了验证vHeat的鲁棒性,我们在ObjectNet和ImageNet-A等分布外分类数据集上评估了vHeat-B。我们在表4中测量了这两个基准的Top-1准确率(%)。结果表明,vHeat在分布外数据上一致地超过了Swin和ConvNeXt(更好的结果用粗体标记)。这些实验突出了vHeat在处理分布外数据(如旋转对象、不同视角(ObjectNet)和自然对抗性样本(ImageNet-A))时的鲁棒性。
5. 低级视觉任务
为了进一步评估我们提出的vHeat模型的泛化能力,我们将热传导算子(HCO)集成到SwinIR模型中,替换了自注意力模块,从而得到了vHeatIR架构。然后我们在几个标准的低级视觉任务上进行了一系列实验,以评估vHeatIR的性能。这些任务包括在Set12和McMaster数据集上的灰度和彩色图像去噪,以及在LIVE1数据集上的JPEG压缩伪影减少。在这些实验中,我们使用了与SwinIR相同的设置,以确保公平比较。结果总结在表5中,表明vHeatIR一致地超过了其他基线模型。这一改进主要归功于HCO在频率域中高效运行的能力,这增强了模型在处理低级图像细节方面的性能。在训练了15,000次迭代后,我们在图6中可视化了噪声水平为σ=15的彩色图像的去噪结果。如图所示,与SwinIR相比,vHeatIR产生了明显更清晰的图像,表明其在恢复图像质量方面的优越能力。这些结果不仅突出了提出的vHeat模型的有效性,还验证了其在低级视觉任务中的强大泛化能力。








)


)




》——有你在的地方才最美)

)
