专栏:大模型垂直应用技术
个人主页:云端筑梦狮
大模型应用落地亟需解决的核心问题有一个是:如何与私域数据交互。私域数据主要的问题是:需要有效地将企业数据整合进大语言模型中。由于大模型的上下文处理能力有限,一次性把太多的数据给到大模型是不现实的,所以必须精准的选择出哪些数据在当前对话上下文中是有效的。
一.传统RAG
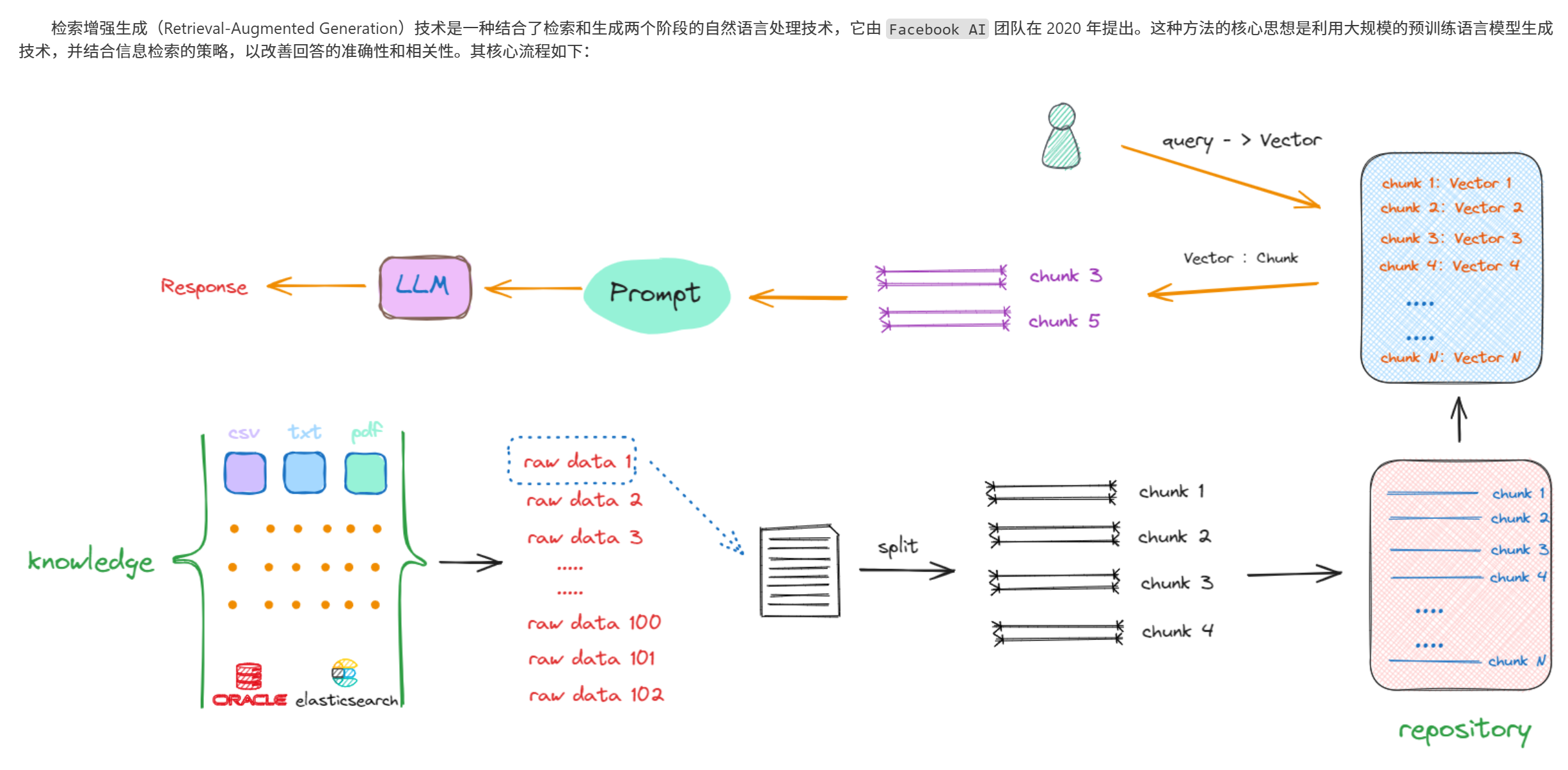
RAG`的实现是包括两个阶段的:检索阶段和生成阶段。在检索阶段,从知识库中找出与问题最相关的知识,为后续的答案生成提供素材。在生成阶段,`RAG`会将检索到的知识内容作为输入,与问题一起输入到语言模型中进行生成。这样,生成的答案不仅考虑了问题的语义信息,还考虑了相关私有数据的内容。

传统的RAG技术很难去搜索到全局信息,若问题散落在不同的语言块中,基于传统RAG就很难检索到全局信息。
图结构Graph的优势在于:在图谱中建立实体关系,从而检索到全局的信息

GraphRAG可以向大模型提供结构化实体信息,文本与属性的关系相结合,借助GraphRAG可以丰富上下文表示,但是GraphRAG的成本极高!
二. Microsoft GraphRAG(仅仅为GraphRAG的一种实现模式)

GraphRAG 整个 Indexing 过程可以通过以下简单的方式来理解:
- 类似于 Baseline RAG,将源文档分块为较小的子文档;
- 执行两个并行提取:实体提取用于识别人名、地名、组织名等实体,关系提取:查找不同数据块中实体之间的关系,比如朋友、同事,员工等;
- 创建知识图谱,其中节点表示实体,边表示它们之间的关系,比如张三是李四的朋友, 张三是王五的同事;
- 通过识别密切相关的实体来构建社区;
- 生成不同社区级别的分层摘要;
- 使用 reduce - map 方法通过逐步组合块来创建摘要,直到实现整体概览;
这个过程非常复杂,因此是需要一些配置文件来控制整个流程的。Microsoft GraphRAG 实现的是完整的索引构建流程逻辑,但具体到每个环节的一些关键参数,比如:文本分块的大小,实体提取、关系提取的粒度,选择使用的大模型,Embedding 模型等,都是需要通过配置文件来控制的。
1. 文档加载器的输入输出格式---过程补
2.创建文本单元
准备好数据以后,才正式进入`Microsoft GraphRAG`实现的索引构建流程。其中,第一阶段要做的事情是:将传入的文档内容进行分块,然后生成`TextUnit`。`TextUnit`是用于图提取技术的文本块,同时会被提取的知识项用作源引用,以便能够溯源到最原始的文本。

3.图元素的提取
在对文档进行分块成`TextUnit`以后,接下来就要对每个`TextUnit`中的内容进行图元素的提取。 元素主要包括:实体、关系。

4.社区检测

现在有了可用的实体和关系图,但是这些实体和关系都是孤立的,没有形成一个完整的图谱。因此需要做的就是将这些实体和关系进行聚合,形成一个完整的图谱。所以接下来的任务就是要将识别出来的实体和关系分组成相关关联的子集。
社区检索是图论中的一个重要任务,旨在识别图中节点的聚集结构。其中社区是指在图中,节点之间的连接比与其他节点的连接更为密切的子集。通过识别社区,我们就可以理解数据的内在结构,发现潜在的模式和关系。其中莱顿算法(Leiden Algorithm)是一种用于社区检测的高效算法,旨在优化社区结构的识别过程。它是基于 Louvain 算法的改进,具有更好的性能和准确性。
微软实现的就是分层的莱顿算法(Hierarchical Leiden Algorithm),它将图中的节点分成多个层次的社区,从而形成一个层次化的社区结构。
5. 生成社区报告
要做的就是对每个社区中的节点、关系和摘要的定义进行总结。这样做的目的是为了方便查询,当查询时需要根据问题匹配知识库中的实体信息和关系信息时,只需要根据总结后的实体描述和关系描述就可以进行匹配了。不然遍历所有的`Description`进行匹配,效率会非常低下。

二.自定义接入图数据库与知识图谱
Neo4j 是一个开源的 NoSQL 图数据库,它使用图来表示和存储数据。在 DB - Engines 排名中根据数据库管理系统的受欢迎程度对其进行排名中,Graph DBMS 榜单中 Neo4j 排名第一。

)






)


)





)
实验详解,结尾有详细脚本)
 SparseViT: 用于图像篡改检测的Spare-Coding Transformer)