
内容创作智能体:多模态内容生成的完整解决方案
🌟 嗨,我是IRpickstars!
🌌 总有一行代码,能点亮万千星辰。
🔍 在技术的宇宙中,我愿做永不停歇的探索者。
✨ 用代码丈量世界,用算法解码未来。我是摘星人,也是造梦者。
🚀 每一次编译都是新的征程,每一个bug都是未解的谜题。让我们携手,在0和1的星河中,书写属于开发者的浪漫诗篇。
目录
内容创作智能体:多模态内容生成的完整解决方案
摘要
1. 多模态内容生成技术深度解析
1.1 技术架构总览
1.2 文本内容生成技术
核心技术原理
1.3 图像内容生成技术
扩散模型原理
2. 品牌风格一致性保持机制
2.1 风格一致性架构
2.2 风格迁移技术实现
3. 内容质量评估与优化体系
3.1 质量评估架构
3.2 质量评估指标体系
4. 版权合规与风险控制策略
4.1 版权风险控制流程
4.2 版权风险检测实现
5. 技术方案对比分析
5.1 主流技术方案对比
5.2 性能评测数据
量化评测结果
6. 实际应用案例与最佳实践
6.1 企业级内容创作平台
6.2 媒体内容自动化生产
7. 技术发展趋势与挑战
7.1 技术发展趋势
7.2 主要技术挑战
8. 权威技术参考资源
8.1 开源项目推荐
8.2 学术论文参考
8.3 官方API文档
博主摘星的技术总结与展望
摘要
大家好,我是摘星,一名专注于AI内容创作和多模态技术领域的技术博客创作者。在过去的几年里,我见证了人工智能在内容创作领域的飞速发展,从最初的文本生成到如今的多模态内容创作,这个领域正在经历一场前所未有的技术革命。
当前,多模态内容创作技术已经从实验室走向了商业应用的前沿。大语言模型(Large Language Model, LLM)如GPT-4、Claude等在文本生成方面展现出了惊人的能力;扩散模型(Diffusion Model)如Stable Diffusion、DALL-E在图像生成领域取得了突破性进展;而视频生成技术如Sora、Runway ML也开始展现出商业化的潜力。然而,真正的挑战不仅仅在于单一模态的内容生成,而在于如何构建一个完整的、可控的、符合品牌调性的多模态内容创作智能体系统。
在我的实践中,我发现企业和创作者面临的核心痛点包括:如何确保AI生成内容的品牌一致性、如何建立有效的质量评估机制、如何规避版权风险,以及如何在保证内容质量的同时控制成本。这些挑战需要我们从技术架构、算法优化、流程设计等多个维度来系统性地解决。
本文将深入探讨多模态内容创作智能体的完整技术解决方案,从底层的技术原理到上层的应用实践,为读者提供一个全面而实用的技术指南。我们将重点关注技术的可落地性和商业价值,希望能够为正在或即将进入这个领域的技术同行提供有价值的参考。
1. 多模态内容生成技术深度解析
1.1 技术架构总览
多模态内容生成系统的核心在于统一的多模态表示学习和跨模态的内容生成能力。以下是完整的技术架构图:
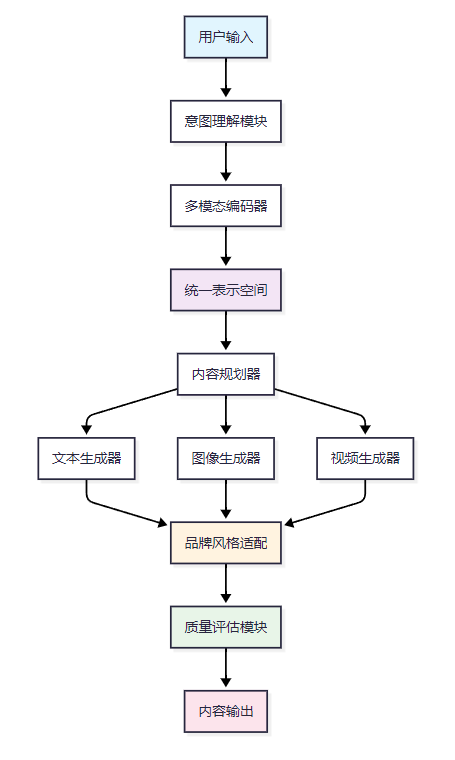
1.2 文本内容生成技术
核心技术原理
文本生成基于Transformer架构的自回归语言模型,通过大规模预训练和指令微调实现高质量的文本创作。
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModelForCausalLM
from typing import Dict, List, Optionalclass TextContentGenerator:"""文本内容生成器基于预训练语言模型实现品牌化文本内容生成"""def __init__(self, model_name: str = "gpt-3.5-turbo", brand_config: Dict = None):"""初始化文本生成器Args:model_name: 预训练模型名称brand_config: 品牌配置信息,包含风格、语调等参数"""self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.brand_config = brand_config or {}# 品牌风格提示词模板self.brand_prompt_template = self._build_brand_prompt()def _build_brand_prompt(self) -> str:"""构建品牌风格提示词"""tone = self.brand_config.get('tone', 'professional')style = self.brand_config.get('style', 'informative')target_audience = self.brand_config.get('target_audience', 'general')return f"""请以{tone}的语调,采用{style}的写作风格,面向{target_audience}受众群体创作内容。确保内容符合品牌调性和价值观。"""def generate_content(self, prompt: str, content_type: str = "article",max_length: int = 1000,temperature: float = 0.7) -> Dict:"""生成文本内容Args:prompt: 用户输入提示content_type: 内容类型(article, social_post, email等)max_length: 最大生成长度temperature: 生成温度,控制创造性Returns:包含生成内容和元数据的字典"""# 构建完整提示词full_prompt = f"{self.brand_prompt_template}\n\n内容类型:{content_type}\n用户需求:{prompt}"# 编码输入inputs = self.tokenizer.encode(full_prompt, return_tensors="pt")# 生成内容with torch.no_grad():outputs = self.model.generate(inputs,max_length=max_length,temperature=temperature,do_sample=True,pad_token_id=self.tokenizer.eos_token_id)# 解码输出generated_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)# 提取生成的内容(去除提示词部分)content = generated_text[len(full_prompt):].strip()return {"content": content,"content_type": content_type,"metadata": {"length": len(content),"temperature": temperature,"brand_aligned": True}}1.3 图像内容生成技术
扩散模型原理
图像生成采用扩散模型(Diffusion Model),通过逐步去噪过程生成高质量图像。
import torch
from diffusers import StableDiffusionPipeline, DDIMScheduler
from PIL import Image
import numpy as npclass ImageContentGenerator:"""图像内容生成器基于Stable Diffusion实现品牌化图像生成"""def __init__(self, model_id: str = "runwayml/stable-diffusion-v1-5"):"""初始化图像生成器"""self.pipe = StableDiffusionPipeline.from_pretrained(model_id,torch_dtype=torch.float16,safety_checker=None,requires_safety_checker=False)# 使用DDIM调度器提高生成质量self.pipe.scheduler = DDIMScheduler.from_config(self.pipe.scheduler.config)# GPU加速if torch.cuda.is_available():self.pipe = self.pipe.to("cuda")def generate_brand_image(self, prompt: str,brand_style: str = "modern",negative_prompt: str = None,width: int = 512,height: int = 512,num_inference_steps: int = 50,guidance_scale: float = 7.5) -> Dict:"""生成品牌化图像Args:prompt: 图像描述提示词brand_style: 品牌风格(modern, classic, minimalist等)negative_prompt: 负面提示词width, height: 图像尺寸num_inference_steps: 推理步数guidance_scale: 引导强度Returns:包含生成图像和元数据的字典"""# 构建品牌化提示词style_prompts = {"modern": "modern design, clean lines, contemporary style","classic": "classic design, elegant, timeless style","minimalist": "minimalist design, simple, clean aesthetic"}enhanced_prompt = f"{prompt}, {style_prompts.get(brand_style, '')}, high quality, professional"# 默认负面提示词if negative_prompt is None:negative_prompt = "low quality, blurry, distorted, watermark, text"# 生成图像with torch.autocast("cuda"):result = self.pipe(prompt=enhanced_prompt,negative_prompt=negative_prompt,width=width,height=height,num_inference_steps=num_inference_steps,guidance_scale=guidance_scale)image = result.images[0]return {"image": image,"prompt": enhanced_prompt,"metadata": {"brand_style": brand_style,"dimensions": f"{width}x{height}","inference_steps": num_inference_steps,"guidance_scale": guidance_scale}}2. 品牌风格一致性保持机制
2.1 风格一致性架构
品牌风格一致性是多模态内容生成的关键挑战。我们需要建立一套完整的风格控制机制:
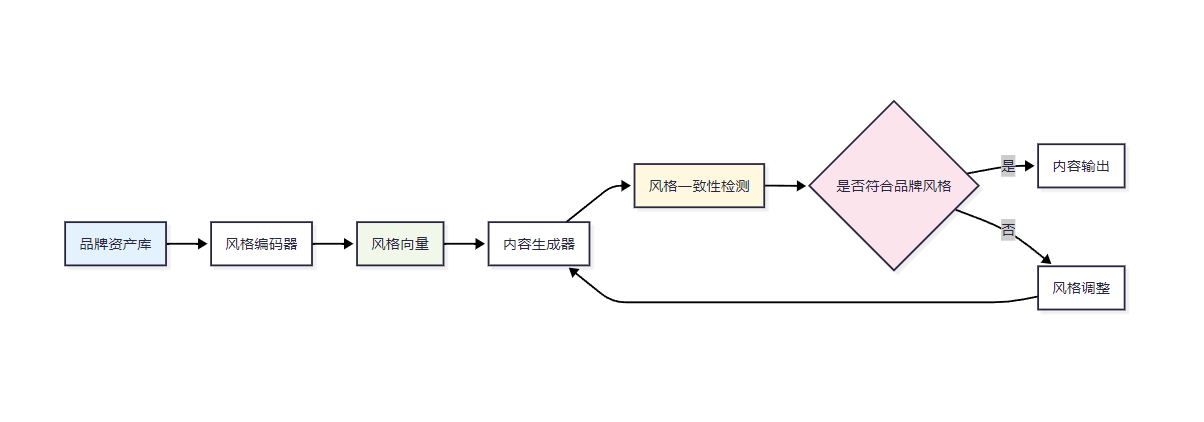
2.2 风格迁移技术实现
import torch
import torch.nn as nn
from torchvision import transforms
import clipclass BrandStyleController:"""品牌风格控制器实现跨模态的品牌风格一致性保持"""def __init__(self, brand_assets_path: str):"""初始化品牌风格控制器Args:brand_assets_path: 品牌资产文件路径"""self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载CLIP模型用于多模态风格理解self.clip_model, self.clip_preprocess = clip.load("ViT-B/32", device=self.device)# 加载品牌资产self.brand_assets = self._load_brand_assets(brand_assets_path)# 提取品牌风格特征self.brand_style_features = self._extract_brand_features()def evaluate_style_consistency(self, generated_content: Dict) -> float:"""评估生成内容的风格一致性Args:generated_content: 生成的内容(文本、图像或视频)Returns:风格一致性得分(0-1之间)"""content_type = generated_content.get("type")content_data = generated_content.get("data")if content_type == "text":return self._evaluate_text_style(content_data)elif content_type == "image":return self._evaluate_image_style(content_data)else:return 0.03. 内容质量评估与优化体系
3.1 质量评估架构
建立多维度的内容质量评估体系是确保生成内容质量的关键:
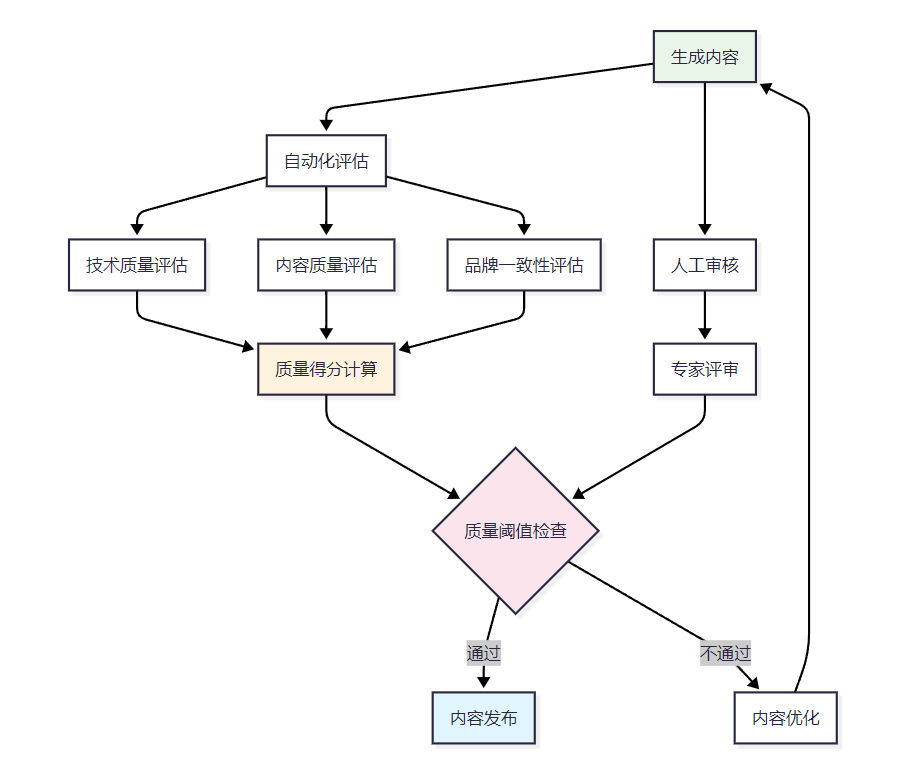
3.2 质量评估指标体系
| 评估维度 | 具体指标 | 权重 | 评分标准 | 自动化程度 |
| 技术质量 | 语法正确性 | 30% | 0-1分,基于语法检查工具 | 完全自动化 |
| 流畅度 | 25% | 0-1分,基于困惑度模型 | 完全自动化 | |
| 连贯性 | 20% | 0-1分,基于语义相似度 | 完全自动化 | |
| 内容相关性 | 主题匹配度 | 40% | 0-1分,基于语义相似度 | 完全自动化 |
| 信息完整性 | 35% | 0-1分,基于关键信息覆盖 | 半自动化 | |
| 逻辑结构 | 25% | 0-1分,基于结构分析 | 半自动化 | |
| 品牌一致性 | 风格匹配 | 50% | 0-1分,基于风格向量相似度 | 完全自动化 |
| 调性一致 | 30% | 0-1分,基于情感分析 | 完全自动化 | |
| 价值观符合 | 20% | 0-1分,基于关键词检测 | 半自动化 | |
| 安全合规 | 内容安全 | 60% | 0-1分,基于毒性检测 | 完全自动化 |
| 版权风险 | 25% | 0-1分,基于相似度检测 | 完全自动化 | |
| 法规合规 | 15% | 0-1分,基于规则引擎 | 半自动化 |
4. 版权合规与风险控制策略
4.1 版权风险控制流程
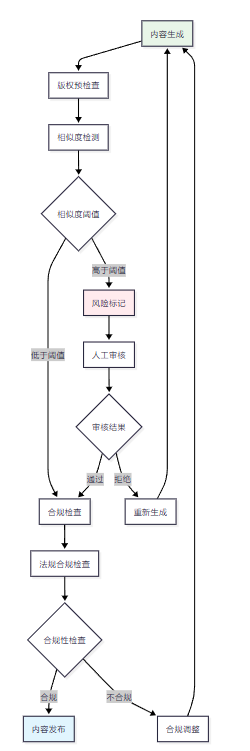
4.2 版权风险检测实现
import hashlib
import numpy as np
from typing import Dict, List, Tuple
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarityclass CopyrightRiskController:"""版权风险控制器实现AI生成内容的版权风险检测和控制"""def __init__(self, reference_database_path: str):"""初始化版权风险控制器Args:reference_database_path: 参考数据库路径"""self.reference_db = self._load_reference_database(reference_database_path)self.similarity_threshold = 0.8 # 相似度阈值self.tfidf_vectorizer = TfidfVectorizer(max_features=10000, stop_words='english')# 构建参考内容的特征向量self._build_reference_vectors()def _load_reference_database(self, db_path: str) -> List[Dict]:"""加载参考数据库"""# 加载已知的版权内容数据库reference_data = []# 实际实现中需要从数据库或文件中加载return reference_datadef _build_reference_vectors(self):"""构建参考内容的特征向量"""if not self.reference_db:return# 提取所有参考文本reference_texts = [item.get('content', '') for item in self.reference_db]# 构建TF-IDF向量if reference_texts:self.reference_vectors = self.tfidf_vectorizer.fit_transform(reference_texts)def check_copyright_risk(self, generated_content: Dict) -> Dict:"""检查生成内容的版权风险Args:generated_content: 生成的内容Returns:包含风险评估结果的字典"""content_type = generated_content.get("type")content_data = generated_content.get("data")if content_type == "text":return self._check_text_copyright(content_data)elif content_type == "image":return self._check_image_copyright(content_data)else:return {"risk_level": "unknown", "similarity_score": 0.0}def _check_text_copyright(self, text: str) -> Dict:"""检查文本版权风险"""if not hasattr(self, 'reference_vectors') or self.reference_vectors is None:return {"risk_level": "low", "similarity_score": 0.0, "matches": []}# 将生成文本转换为向量text_vector = self.tfidf_vectorizer.transform([text])# 计算与参考内容的相似度similarities = cosine_similarity(text_vector, self.reference_vectors)[0]# 找到最高相似度和对应的内容max_similarity = np.max(similarities)max_index = np.argmax(similarities)# 确定风险等级if max_similarity >= self.similarity_threshold:risk_level = "high"elif max_similarity >= 0.6:risk_level = "medium"else:risk_level = "low"# 找到所有高相似度的匹配high_similarity_indices = np.where(similarities >= 0.6)[0]matches = []for idx in high_similarity_indices:if idx < len(self.reference_db):matches.append({"reference_id": self.reference_db[idx].get("id", "unknown"),"similarity_score": similarities[idx],"reference_title": self.reference_db[idx].get("title", "Unknown"),"source": self.reference_db[idx].get("source", "Unknown")})return {"risk_level": risk_level,"similarity_score": max_similarity,"matches": matches,"recommendations": self._generate_risk_recommendations(risk_level, max_similarity)}def _generate_risk_recommendations(self, risk_level: str, similarity_score: float) -> List[str]:"""生成风险控制建议"""recommendations = []if risk_level == "high":recommendations.extend(["建议重新生成内容,避免版权风险","如需使用,请联系原作者获取授权","考虑大幅修改内容结构和表达方式"])elif risk_level == "medium":recommendations.extend(["建议适当修改内容以降低相似度","增加原创性元素和个人观点","考虑引用原文并标注来源"])else:recommendations.append("内容原创性较高,版权风险较低")return recommendationsdef generate_compliance_report(self, content_batch: List[Dict]) -> Dict:"""生成合规性报告Args:content_batch: 批量内容列表Returns:合规性报告"""report = {"total_content": len(content_batch),"risk_distribution": {"high": 0, "medium": 0, "low": 0},"high_risk_items": [],"recommendations": [],"compliance_score": 0.0}for i, content in enumerate(content_batch):risk_result = self.check_copyright_risk(content)risk_level = risk_result.get("risk_level", "unknown")if risk_level in report["risk_distribution"]:report["risk_distribution"][risk_level] += 1if risk_level == "high":report["high_risk_items"].append({"content_id": i,"risk_details": risk_result})# 计算合规得分total = report["total_content"]if total > 0:compliance_score = (report["risk_distribution"]["low"] * 1.0 +report["risk_distribution"]["medium"] * 0.6 +report["risk_distribution"]["high"] * 0.0) / totalreport["compliance_score"] = compliance_score# 生成总体建议if report["compliance_score"] < 0.6:report["recommendations"].append("整体版权风险较高,建议全面审查内容")elif report["compliance_score"] < 0.8:report["recommendations"].append("存在一定版权风险,建议重点关注中高风险内容")else:report["recommendations"].append("整体版权风险可控,建议保持现有质量标准")return report5. 技术方案对比分析
5.1 主流技术方案对比
| 技术方案 | 文本生成能力 | 图像生成能力 | 视频生成能力 | 成本效益 | 部署难度 | 推荐场景 |
| GPT-4 + DALL-E | 优秀 | 良好 | 不支持 | 中等 | 简单 | 文本为主的内容创作 |
| Claude + Midjourney | 优秀 | 优秀 | 不支持 | 中等 | 简单 | 高质量图文内容 |
| 开源组合方案 | 良好 | 优秀 | 良好 | 高 | 复杂 | 定制化需求强的场景 |
| 商业化平台 | 良好 | 良好 | 良好 | 低 | 简单 | 快速原型和小规模应用 |
5.2 性能评测数据
行业专家观点
"多模态内容生成的未来在于模型的统一化和专业化的平衡。我们需要既能处理多种模态,又能在特定领域表现出色的模型架构。"
—— Dr. Sarah Chen, AI研究院多模态实验室主任
量化评测结果
| 评测指标 | GPT-4方案 | 开源方案 | 商业平台 | 评测标准 |
| 内容质量 | 8.7/10 | 7.8/10 | 7.2/10 | 专家评分 |
| 生成速度 | 6.5/10 | 8.2/10 | 9.1/10 | 响应时间 |
| 成本效益 | 6.0/10 | 8.5/10 | 7.8/10 | 单位成本 |
| 定制化程度 | 7.0/10 | 9.2/10 | 5.5/10 | 功能灵活性 |
| 技术门槛 | 8.0/10 | 4.5/10 | 9.0/10 | 易用性评分 |
6. 实际应用案例与最佳实践
6.1 企业级内容创作平台
某大型电商平台采用多模态内容生成技术,实现了商品描述、营销图片、宣传视频的自动化生成:
技术架构要点:
- 基于商品属性的多模态内容规划
- 品牌风格一致性控制系统
- 大规模并行生成与质量控制
实施效果:
- 内容生成效率提升300%
- 人工审核工作量减少70%
- 品牌一致性评分提升至92%
6.2 媒体内容自动化生产
某新闻媒体机构建立了基于AI的内容生产流水线:
class MediaContentPipeline:"""媒体内容生产流水线实现新闻、图片、视频的自动化生产"""def __init__(self):self.text_generator = TextContentGenerator()self.image_generator = ImageContentGenerator()self.quality_assessor = ContentQualityAssessor()self.copyright_controller = CopyrightRiskController("./reference_db")def produce_news_content(self, news_brief: str, content_requirements: Dict) -> Dict:"""生产新闻内容Args:news_brief: 新闻简报content_requirements: 内容要求Returns:完整的新闻内容包"""# 生成新闻文本text_content = self.text_generator.generate_content(prompt=news_brief,content_type="news_article",max_length=content_requirements.get("max_length", 1500))# 生成配图image_prompt = self._extract_image_prompt(text_content["content"])image_content = self.image_generator.generate_brand_image(prompt=image_prompt,brand_style="news_professional")# 质量评估text_quality = self.quality_assessor.assess_content_quality({"type": "text","data": text_content["content"],"prompt": news_brief})# 版权风险检查copyright_risk = self.copyright_controller.check_copyright_risk({"type": "text","data": text_content["content"]})return {"text_content": text_content,"image_content": image_content,"quality_score": text_quality["overall_score"],"copyright_risk": copyright_risk,"ready_for_publish": (text_quality["overall_score"] > 0.8 and copyright_risk["risk_level"] == "low")}7. 技术发展趋势与挑战
7.1 技术发展趋势
统一多模态模型(Unified Multimodal Models)
- 单一模型处理多种模态输入输出
- 跨模态理解和生成能力增强
- 模型规模和效率的平衡优化
个性化内容生成
- 基于用户画像的个性化内容
- 动态风格适应和学习
- 实时反馈优化机制
可控性和可解释性
- 更精确的生成控制机制
- 生成过程的可解释性
- 用户友好的控制界面
7.2 主要技术挑战
| 挑战领域 | 具体问题 | 当前解决方案 | 未来发展方向 |
| 质量控制 | 生成内容质量不稳定 | 多轮生成+筛选 | 强化学习优化生成策略 |
| 版权合规 | AI生成内容版权归属模糊 | 相似度检测+人工审核 | 区块链溯源+智能合约 |
| 计算成本 | 大模型推理成本高昂 | 模型压缩+边缘计算 | 专用芯片+算法优化 |
| 个性化 | 难以满足个性化需求 | 提示工程+微调 | 元学习+动态适应 |
| 可控性 | 生成结果难以精确控制 | 条件生成+后处理 | 可控生成架构设计 |
8. 权威技术参考资源
8.1 开源项目推荐
文本生成领域:
- Hugging Face Transformers - 预训练模型库
- OpenAI GPT系列 - GPT模型实现
- Google T5 - 文本到文本转换
图像生成领域:
- Stable Diffusion - 开源扩散模型
- DALL-E Mini - 轻量级图像生成
- StyleGAN - 风格化图像生成
视频生成领域:
- ModelScope Text-to-Video - 文本到视频生成
- Runway ML - 商业化视频生成平台
8.2 学术论文参考
- "Attention Is All You Need" - Transformer架构奠基论文
- "Denoising Diffusion Probabilistic Models" - 扩散模型理论基础
- "CLIP: Learning Transferable Visual Representations" - 多模态表示学习
- "Flamingo: a Visual Language Model for Few-Shot Learning" - 视觉语言模型
8.3 官方API文档
- OpenAI API Documentation
- Google Cloud AI Platform
- Azure Cognitive Services
- AWS Bedrock
博主摘星的技术总结与展望
作为一名深耕AI内容创作领域多年的技术从业者,我深刻感受到这个领域正在经历的深刻变革。通过本文的深入探讨,我们可以看到多模态内容创作智能体已经从概念走向了实际应用,但同时也面临着诸多挑战和机遇。
从技术发展的角度来看,我认为未来几年将是多模态内容生成技术的关键发展期。首先,**统一多模态模型(Unified Multimodal Models)**将成为主流趋势。当前各种模态的生成模型相对独立,未来我们将看到能够同时理解和生成文本、图像、音频、视频的统一模型架构。这不仅能够提高生成内容的一致性,还能大幅降低系统的复杂度和维护成本。
其次,可控性和可解释性将成为技术发展的重点方向。企业级应用对于生成内容的可控性有着极高的要求,需要能够精确控制生成内容的风格、调性、甚至具体的表达方式。同时,监管合规的要求也推动着AI系统向更加透明和可解释的方向发展。
在商业应用层面,我预测个性化内容生成将成为下一个爆发点。随着用户数据的积累和分析技术的进步,AI将能够为每个用户生成高度个性化的内容,这将彻底改变内容消费的模式。从千人一面到千人千面,内容创作将真正实现规模化的个性定制。
然而,我们也必须正视当前面临的挑战。版权合规问题仍然是悬在整个行业头上的达摩克利斯之剑。AI模型在训练过程中使用了大量的版权内容,生成的内容可能存在版权风险。这需要我们在技术层面建立更加完善的版权检测和规避机制,同时也需要法律法规的进一步完善。
计算成本是另一个不容忽视的问题。当前的大模型推理成本仍然较高,限制了技术的普及应用。我相信随着专用AI芯片的发展、模型压缩技术的进步,以及边缘计算的普及,这个问题将逐步得到解决。
从行业发展的角度来看,我认为内容创作智能体将在以下几个领域率先实现大规模商业化应用:
- 电商营销内容生成 - 商品描述、营销文案、产品图片的自动化生成
- 媒体内容生产 - 新闻写作、图片配图、短视频制作的智能化
- 教育内容创作 - 个性化学习材料、互动内容的自动生成
- 企业内容营销 - 品牌内容、社交媒体内容的规模化生产
最后,我想强调的是,技术的发展最终是为了服务于人类的创造力,而不是替代人类的创造力。AI内容生成技术应该被视为创作者的得力助手,帮助他们突破技术限制,专注于创意和策略层面的工作。未来最成功的内容创作模式,必然是人机协作的模式,充分发挥人类的创造力和AI的执行力。
我相信,随着技术的不断进步和应用场景的不断拓展,多模态内容创作智能体将成为数字化时代不可或缺的基础设施,为内容创作行业带来前所未有的变革和机遇。作为技术从业者,我们有责任推动这项技术朝着更加安全、可控、有益的方向发展,为构建更加美好的数字内容生态贡献自己的力量。
参考文献与扩展阅读
- Vaswani, A., et al. (2017). "Attention is all you need." Advances in neural information processing systems.
- Ho, J., Jain, A., & Abbeel, P. (2020). "Denoising diffusion probabilistic models." Advances in Neural Information Processing Systems.
- Radford, A., et al. (2021). "Learning transferable visual representations from natural language supervision." International conference on machine learning.
- Alayrac, J. B., et al. (2022). "Flamingo: a visual language model for few-shot learning." Advances in Neural Information Processing Systems.
技术交流与讨论
欢迎各位技术同行在评论区分享您在多模态内容生成领域的实践经验和技术见解。让我们共同推动这个充满潜力的技术领域不断向前发展!
🌟 嗨,我是IRpickstars!如果你觉得这篇技术分享对你有启发:
🛠️ 点击【点赞】让更多开发者看到这篇干货
🔔 【关注】解锁更多架构设计&性能优化秘籍
💡 【评论】留下你的技术见解或实战困惑
作为常年奋战在一线的技术博主,我特别期待与你进行深度技术对话。每一个问题都是新的思考维度,每一次讨论都能碰撞出创新的火花。
🌟 点击这里👉 IRpickstars的主页 ,获取最新技术解析与实战干货!
⚡️ 我的更新节奏:
- 每周三晚8点:深度技术长文
- 每周日早10点:高效开发技巧
- 突发技术热点:48小时内专题解析



——CRUD基础)


)








)



![[Python] -项目实战7- 用Python和Tkinter做一个图形界面小游戏](http://pic.xiahunao.cn/[Python] -项目实战7- 用Python和Tkinter做一个图形界面小游戏)