微信闭源代码库中的RAG代码补全:揭秘工业级场景下的检索增强生成技术
论文标题:A Deep Dive into Retrieval-Augmented Generation for Code Completion: Experience on WeChat
arXiv:2507.18515
A Deep Dive into Retrieval-Augmented Generation for Code Completion: Experience on WeChat
Zezhou Yang, Ting Peng, Cuiyun Gao, Chaozheng Wang, Hailiang Huang, Yuetang Deng
Comments: Accepted in ICSME 25 Industry Track
Subjects: Software Engineering (cs.SE)
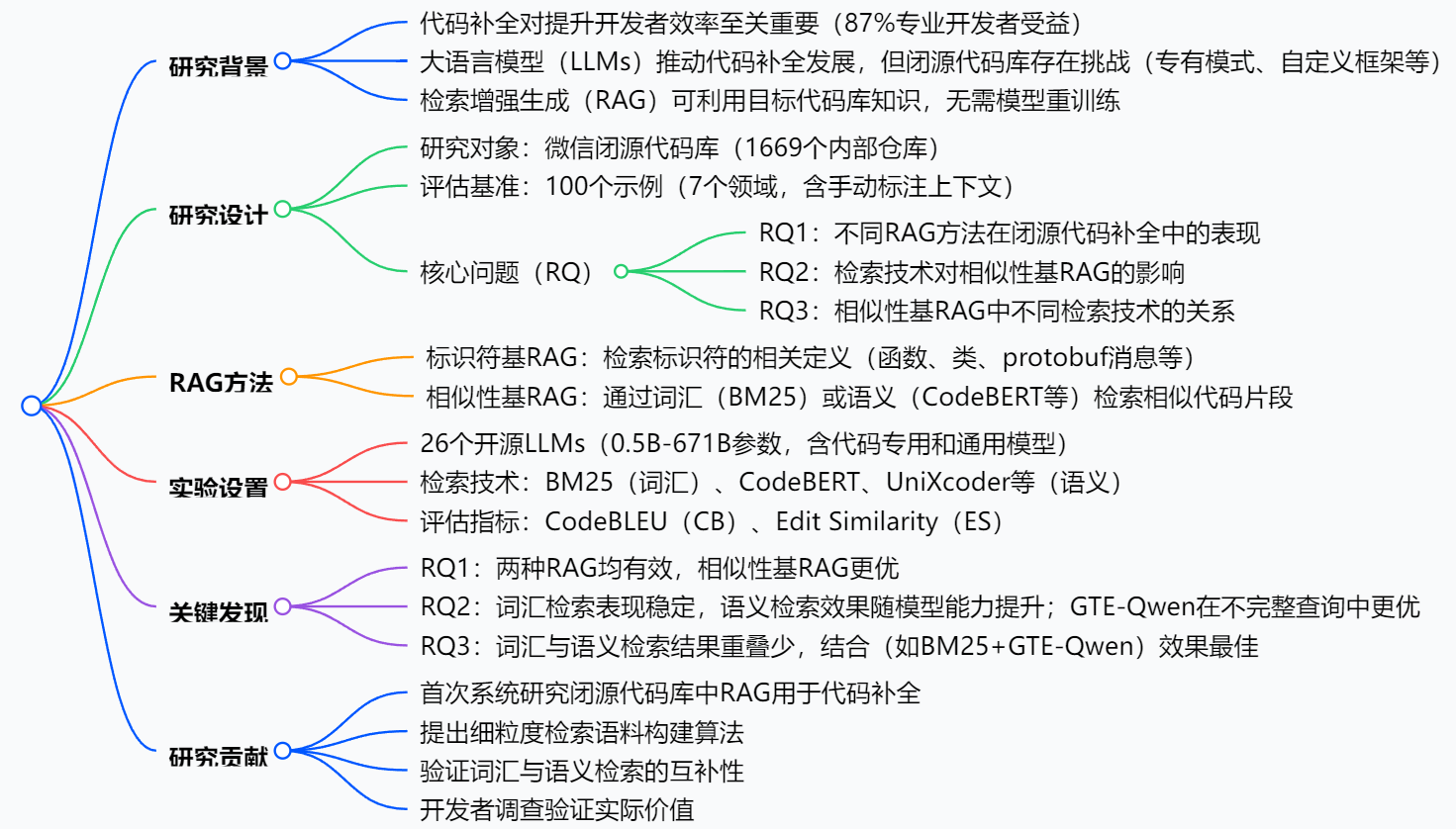
一段话总结:本文对检索增强生成(RAG)在闭源代码库的代码补全中应用进行了系统研究,以微信的工业级闭源代码库(含1669个内部仓库)为研究对象,构建了包含100个示例的评估基准,评估了26个参数从0.5B到671B的开源大语言模型(LLMs)。研究比较了标识符基RAG和相似性基RAG两种方法,发现两者在闭源代码补全中均有效,其中相似性基RAG表现更优;BM25(词汇检索) 和GTE-Qwen(语义检索) 在相似性基RAG中性能突出,且两者结合能产生最优结果。此外,开发者调查验证了这些发现的实际价值。
研究背景:代码补全的“闭源困境”与RAG的破局可能
想象一下,你是一家大型科技公司的程序员,每天要在公司内部的专有代码库里写代码。这些代码里满是公司独有的框架、业务逻辑和命名规则——就像只有内部员工才懂的“暗语”。这时候,你打开常用的代码补全工具,却发现它经常“说外行话”:要么推荐的代码风格和公司规范格格不入,要么根本看不懂那些自定义的函数和类。
这就是闭源代码库面临的现实问题。
代码补全作为提升开发效率的“利器”,早已被证明能让87%的专业开发者效率大增。近年来,大语言模型(LLMs)的爆发让代码补全能力突飞猛进,但这些模型大多是在开源代码库(如GitHub)上训练的。而闭源代码库(如微信的内部代码)有太多“私有信息”:自定义框架、专有业务逻辑、特殊编码习惯,和开源代码的“画风”差异很大。
这就好比用学了公开教材的学生去解公司内部考题——不是能力不够,是“水土不服”。
而检索增强生成(RAG)技术的出现,给了破局的可能。简单说,RAG就像给LLMs配了一个“专属搜索引擎”:在生成代码时,先从目标代码库里检索相关的代码片段或定义,再结合这些“上下文”生成更贴合的结果,而且不需要重新训练模型(保护隐私,还省资源)。
但问题是:RAG在开源场景里表现不错,在闭源场景还能用吗?哪种RAG方法更有效?不同的“检索方式”(比如按关键词找还是按语义找)搭配起来会不会更好?这正是这篇论文要解决的问题——以微信的工业级闭源代码库为研究对象,一探究竟。
主要作者及单位信息
- Zezhou Yang,腾讯(广州,中国)
- Ting Peng,腾讯(广州,中国)
- Cuiyun Gao*(通讯作者),香港中文大学(香港,中国)
- Chaozheng Wang,香港中文大学(香港,中国)
- Hailiang Huang,腾讯(广州,中国)
- Yuetang Deng,腾讯(广州,中国)
创新点:这篇论文的“独特价值”在哪里?
在RAG和代码补全的研究热潮中,这篇论文的创新之处尤为突出:
-
首次聚焦闭源代码库的系统研究:此前研究多基于开源代码库,而本文是首个在工业级闭源代码库(微信,1669个内部仓库)中,系统评估RAG用于代码补全的研究,填补了“闭源场景”的空白。
-
解决C++闭源项目的“数据预处理难题”:C++项目有很多“坑”——头文件依赖复杂、自动生成代码冗余、宏定义特殊等,论文提出了一套细粒度的预处理算法,能精准提取有效代码片段(如函数、类定义),解决了这些工业界实际问题。
-
发现词汇与语义检索的“互补密码”:通过实验发现,基于关键词的词汇检索(如BM25)和基于意义的语义检索(如GTE-Qwen)结果重叠极少,结合使用能大幅提升效果,这为工业界提供了明确的技术组合方案。
-
用开发者调查验证“实际价值”:不仅有实验数据,还通过3位资深开发者的调查,验证了技术在真实开发场景中的有效性,让研究结论更具落地意义。
研究方法和思路:一步步拆解“微信闭源代码补全实验”
为了搞清楚RAG在闭源场景的表现,研究团队做了一套“组合拳”实验,步骤清晰可复制:
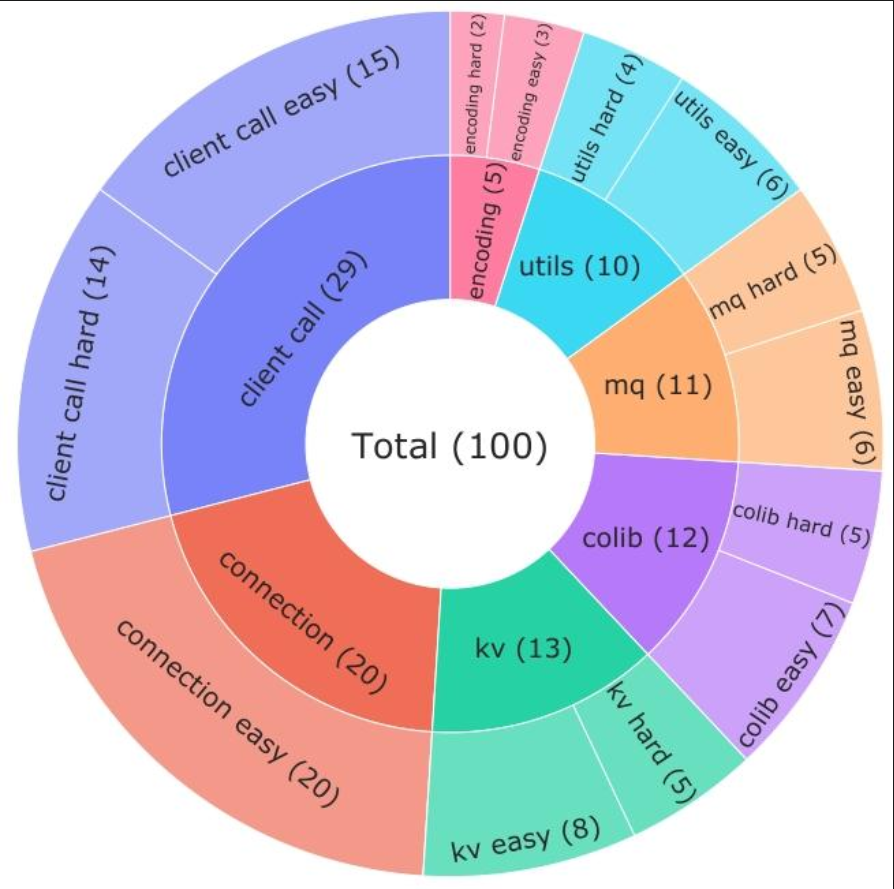
第一步:搭好“考场”——构建评估基准
- 从微信7个核心业务领域(如远程调用、消息队列、工具函数等)中,精选100个真实开发场景的函数作为“考题”。
- 每个“考题”都由3位5年以上经验的开发者手动标注:相关上下文、难度(简单/困难),确保贴合实际开发需求。
第二步:备好“参考书”——构建检索语料
- 收集微信1669个内部项目作为“参考书库”,涵盖不同业务和开发周期。
- 重点解决C++项目的4大难题:
- 文件分割:C++头文件内容多,直接用整个文件做检索单位太冗余,所以拆成函数、类定义等细粒度片段。
- 递归依赖:头文件互相引用像“连环套”,通过递归处理所有依赖,避免漏信息。
- 自动生成代码:protobuf生成的代码没用,直接从原始proto文件提取消息定义。
- 宏定义:把C++的宏转换成类似函数的结构,方便检索和理解。
第三步:测试两种“解题思路”——实现RAG方法
- 标识符基RAG:就像查“名词解释”。比如代码里出现一个陌生函数
sendMsg,就去检索它的定义、参数、用法,让LLMs看懂这个“暗语”再补全。 - 相似性基RAG:就像查“例题”。比如要补全一个消息队列相关的函数,就去搜代码库里类似功能的函数片段,让LLMs参考“例题”写代码。
第四步:用“不同学生”测试——选择26个LLMs
- 涵盖从0.5B到671B参数的26个开源模型,既有代码专用模型(如Qwen-Coder、CodeLlama),也有通用模型(如Llama-3.3),全面测试RAG的适配性。
第五步:比较“不同检索工具”——测试5种检索技术
- 词汇检索:用BM25(类似关键词搜索,看代码里的词匹配度)。
- 语义检索:用CodeBERT、UniXcoder、CoCoSoDa、GTE-Qwen(类似“理解意思”搜索,看代码语义相似性)。
第六步:打分标准——评估指标
- 用CodeBLEU(看代码结构和语义相似度)和Edit Similarity(看最少改多少字符能匹配正确代码)给补全结果打分。
主要贡献:这些发现对工业界有多重要?
这篇论文的成果可不是“实验室游戏”,而是能直接指导企业提升开发效率的“干货”:
-
闭源场景下RAG真的有用:两种RAG方法都能让代码补全效果提升,比如DeepSeek-V3模型用GTE-Qwen检索后,代码相似度指标(CodeBLEU)提升71.1%,编辑相似度提升33.3%。这意味着企业不用从头训练模型,用开源LLM加内部代码库就能提升补全效果。
-
相似性基RAG更胜一筹:比起查“名词解释”的标识符基RAG,查“例题”的相似性基RAG效果更好。比如Qwen2.5-Coder-1.5B用相似性基RAG,效果比标识符基高25%以上。
-
最佳“检索组合”出炉:
- 词汇检索(BM25)表现稳定,不管模型大小都好用。
- 语义检索(尤其是GTE-Qwen)在模型够强时效果惊艳,而且特别擅长处理“不完整查询”(比如只写了一半的代码)。
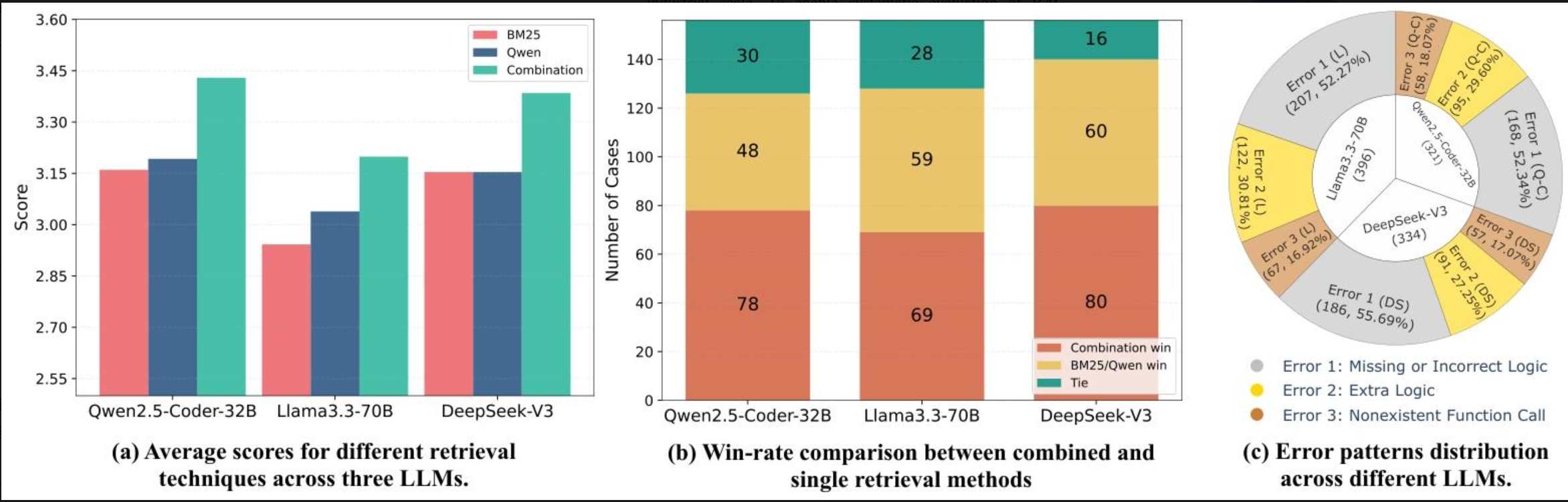
- 把BM25和GTE-Qwen结合,效果最佳(像同时用关键词和语义搜资料,覆盖更全)。比如DeepSeek-V3用这个组合,指标比单独用提升5%~10%。
-
保护隐私还省钱:用开源LLM加RAG,不用把内部代码给模型训练,既保护了闭源代码的隐私,又避免了训练大模型的高额成本。
详细总结:
一、研究背景与目的
- 代码补全的重要性:代码补全能自动预测代码片段,显著提升开发者效率,87%的专业开发者在工业环境中受益。
- RAG的作用:检索增强生成(RAG)通过检索目标代码库的相关上下文增强LLMs性能,无需参数更新,适用于闭源代码库(保护隐私、适应特定编码风格)。
- 研究缺口:现有研究多基于开源代码库,闭源代码库因专有模式等特点存在挑战,需系统研究RAG在闭源场景的表现。
- 研究对象:微信的闭源代码库(1669个内部仓库),构建包含100个示例(7个领域)的评估基准。
二、研究方法与实验设置
1. 数据预处理与语料构建
- 挑战:C++项目的文件分割、递归依赖、自动生成代码、宏定义等问题。
- 解决方案:提出细粒度算法,提取函数/类定义、处理递归依赖、转换宏为函数结构等。
2. RAG方法
| RAG类型 | 核心思路 | 关键步骤 |
|---|---|---|
| 标识符基RAG | 检索标识符的定义帮助LLMs理解逻辑 | 构建索引→提取需检索的标识符→构建提示词补全代码 |
| 相似性基RAG | 提供相似代码片段辅助补全 | 构建索引(词汇/语义)→检索相似代码→构建提示词补全代码 |
3. 实验细节
- LLMs:26个开源模型(0.5B-671B参数),包括代码专用(如Qwen-Coder)和通用模型(如Llama-3.3)。
- 检索技术:词汇检索(BM25)、语义检索(CodeBERT、GTE-Qwen等)。
- 评估指标:CodeBLEU(CB,考虑代码结构和语义)、Edit Similarity(ES,衡量编辑距离)。
三、实验结果与分析
1. RQ1:不同RAG方法的表现
- 两种RAG均优于基础模型,相似性基RAG表现更优。例如,DeepSeek-V3用GTE-Qwen检索后,CB提升71.1%,ES提升33.3%。
- 标识符基RAG中,函数定义检索效果最佳;相似性基RAG中,BM25和GTE-Qwen表现突出。
2. RQ2:检索技术对相似性基RAG的影响
- 词汇检索(BM25)在各模型中表现稳定;语义检索效果随模型能力提升。
- 多数技术在完整查询中更优,但GTE-Qwen在不完整查询(代码补全场景)中更优。
3. RQ3:不同检索技术的关系
- 词汇与语义检索结果重叠少(如BM25与GTE-Qwen在100个示例中64个完全不同),互补性强。
- 结合后效果更佳,如DeepSeek-V3用BM25+GTE-Qwen,CB达63.62,ES达75.26,优于单独使用。
四、开发者调查与研究贡献
- 开发者调查:BM25+GTE-Qwen的组合评分最高,约半数案例中优于单独技术;主要错误为逻辑缺失或错误(52%)。
- 贡献:系统研究闭源场景RAG、提出细粒度语料构建算法、验证检索技术互补性、开发者调查验证实际价值。
-
关键问题:
-
问题:在闭源代码补全中,标识符基RAG和相似性基RAG的核心区别是什么,哪种更有效?
答案:标识符基RAG通过检索标识符(如函数、类)的相关定义帮助LLMs理解其逻辑和用法;相似性基RAG则检索与当前代码相似的实现(通过词汇或语义技术)。实验表明,两种方法均有效,但相似性基RAG表现更优,例如DeepSeek-V3使用相似性基RAG(GTE-Qwen)时,CodeBLEU和Edit Similarity分别比标识符基RAG提升约42.7%和18.4%。 -
问题:不同检索技术对相似性基RAG的影响有何差异,哪种技术更适合代码补全场景?
答案:词汇检索(如BM25)在不同模型和查询类型中表现稳定;语义检索(如GTE-Qwen)的效果随模型能力提升。多数技术在完整代码片段查询中更优,但GTE-Qwen在不完整查询(代码补全的典型场景)中表现最佳,例如在DeepSeek-V3中,其CodeBLEU达60.28,显著高于其他语义检索技术。 -
问题:词汇检索(如BM25)和语义检索(如GTE-Qwen)为何能通过结合提升代码补全效果?
答案:两者检索结果重叠极少(如在100个示例中,BM25与GTE-Qwen有64个完全不同的结果),说明它们捕获代码相似性的不同方面(词汇层面vs语义层面),具有互补性。结合后能覆盖更全面的信息,例如DeepSeek-V3使用BM25+GTE-Qwen时,CodeBLEU达63.62,高于单独使用任一技术。
总结:闭源代码补全,RAG这样用才高效
这篇论文以微信的工业级闭源代码库为“试验场”,系统回答了“RAG在闭源场景怎么用才有效”的问题:
- 解决的核心问题:填补了RAG在闭源代码补全领域的研究空白,明确了不同方法和技术的效果。
- 关键结论:相似性基RAG优于标识符基,BM25(词汇)和GTE-Qwen(语义)结合是“最优解”,且效果能被开发者实际感知(调查验证)。
- 价值:为企业提供了一套低成本、高隐私的代码补全优化方案——用开源LLM+内部代码库+RAG,就能让代码补全更懂“公司方言”。

![[2025CVPR-目标检测方向] CorrBEV:多视图3D物体检测](http://pic.xiahunao.cn/[2025CVPR-目标检测方向] CorrBEV:多视图3D物体检测)





)





)





