在扩散模型中,逆向过程的目标是从噪声数据逐步恢复出原始数据。本文将详细解析逆向条件分布 q(zt−1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt−1∣zt,x)的推导过程,揭示扩散模型如何通过高斯分布实现数据重建。
1. 核心问题
在扩散模型中,我们希望学习如何从含噪数据 (zt(\mathbf{z}_t(zt) 逐步恢复原始数据 x\mathbf{x}x。直接求逆向分布 q(zt−1∣zt)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t)q(zt−1∣zt) 是困难的,但若额外已知原始数据 x\mathbf{x}x,则条件分布 q(zt−1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt−1∣zt,x)可以简化为高斯分布。
2. 贝叶斯定理的应用
利用贝叶斯定理,将条件分布分解为:
q(zt−1∣zt,x)=q(zt∣zt−1,x)q(zt−1∣x)q(zt∣x)
q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \frac{q(\mathbf{z}_t \mid \mathbf{z}_{t-1}, \mathbf{x}) q(\mathbf{z}_{t-1} \mid \mathbf{x})}{q(\mathbf{z}_t \mid \mathbf{x})}
q(zt−1∣zt,x)=q(zt∣x)q(zt∣zt−1,x)q(zt−1∣x)
关键简化:
-
马尔可夫性质:前向过程中,zt\mathbf{z}_tzt仅依赖zt−1\mathbf{z}_{t-1}zt−1,因此:
q(zt∣zt−1,x)=q(zt∣zt−1) q(\mathbf{z}_t \mid \mathbf{z}_{t-1}, \mathbf{x}) = q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) q(zt∣zt−1,x)=q(zt∣zt−1)
此项由前向过程的定义给出(公式 20.4):
q(zt∣zt−1)=N(zt;1−βtzt−1,βtI) q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) = \mathcal{N}\left(\mathbf{z}_t; \sqrt{1-\beta_t} \mathbf{z}_{t-1}, \beta_t \mathbf{I}\right) q(zt∣zt−1)=N(zt;1−βtzt−1,βtI) -
扩散核:q(zt−1∣x)q(\mathbf{z}_{t-1} \mid \mathbf{x})q(zt−1∣x)是前向过程的闭式解(公式 20.6):
q(zt−1∣x)=N(zt−1;αt−1x,(1−αt−1)I) q(\mathbf{z}_{t-1} \mid \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \sqrt{\alpha_{t-1}} \mathbf{x}, (1-\alpha_{t-1}) \mathbf{I}\right) q(zt−1∣x)=N(zt−1;αt−1x,(1−αt−1)I)
其中αt−1=∏s=1t−1(1−βs)\alpha_{t-1} = \prod_{s=1}^{t-1} (1-\beta_s)αt−1=∏s=1t−1(1−βs)。 -
分母的忽略:分母 q(zt∣x)q(\mathbf{z}_t \mid \mathbf{x})q(zt∣x) 与zt−1\mathbf{z}_{t-1}zt−1无关,可视为常数。
3. 高斯分布的推导
分子部分是两个高斯分布的乘积:
q(zt∣zt−1)⋅q(zt−1∣x)
q(\mathbf{z}_t \mid \mathbf{z}_{t-1}) \cdot q(\mathbf{z}_{t-1} \mid \mathbf{x})
q(zt∣zt−1)⋅q(zt−1∣x)
通过配方法(completing the square),可以合并指数项,得到一个新的高斯分布:
q(zt−1∣zt,x)=N(zt−1;mt(x,zt),σt2I)
q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t), \sigma_t^2 \mathbf{I}\right)
q(zt−1∣zt,x)=N(zt−1;mt(x,zt),σt2I)
均值和方差的计算:
-
均值 (\mathbf{m}_t):
mt(x,zt)=αt−1βt1−αtx+1−βt(1−αt−1)1−αtzt \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t) = \frac{\sqrt{\alpha_{t-1}} \beta_t}{1-\alpha_t} \mathbf{x} + \frac{\sqrt{1-\beta_t} (1-\alpha_{t-1})}{1-\alpha_t} \mathbf{z}_t mt(x,zt)=1−αtαt−1βtx+1−αt1−βt(1−αt−1)zt
这是原始数据x\mathbf{x}x和当前噪声数据zt\mathbf{z}_tzt的线性组合。 -
方差 σt2\sigma_t^2σt2:
σt2=(1−αt−1)βt1−αt \sigma_t^2 = \frac{(1-\alpha_{t-1}) \beta_t}{1-\alpha_t} σt2=1−αt(1−αt−1)βt
仅依赖噪声调度参数βt\beta_tβt和累积系数αt\alpha_tαt。
4. 直观理解
- 给定x\mathbf{x}x的重要性:若已知原始数据x\mathbf{x}x,则从 zt\mathbf{z}_tzt推断 zt−1\mathbf{z}_{t-1}zt−1是一个确定性更强的去噪问题,解为高斯分布。
- 物理意义:均值 mt\mathbf{m}_tmt是“部分去噪”的结果,方差 σt2\sigma_t^2σt2表示剩余的不确定性。
5. 与逆向过程的关系
实际训练中,我们无法直接使用 x\mathbf{x}x(因需生成新数据),因此:
- 用神经网络 pθ(zt−1∣zt)p_\theta(\mathbf{z}_{t-1} \mid \mathbf{z}_t)pθ(zt−1∣zt)近似q(zt−1∣zt,x)q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x})q(zt−1∣zt,x)。
- 网络通过预测均值 mt\mathbf{m}_tmt 或噪声 ϵ\boldsymbol{\epsilon}ϵ来学习去噪。
6. 总结
- 数学本质:通过贝叶斯定理和高斯分布的性质,显式推导出条件逆向分布的闭式解。
- 实际意义:指导神经网络学习去噪步骤的理论基础。
- 关键公式:
q(zt−1∣zt,x)=N(zt−1;mt(x,zt),σt2I) q(\mathbf{z}_{t-1} \mid \mathbf{z}_t, \mathbf{x}) = \mathcal{N}\left(\mathbf{z}_{t-1}; \mathbf{m}_t(\mathbf{x}, \mathbf{z}_t), \sigma_t^2 \mathbf{I}\right) q(zt−1∣zt,x)=N(zt−1;mt(x,zt),σt2I)
这种推导是扩散模型理论的核心,确保了从噪声中生成数据的数学严谨性。
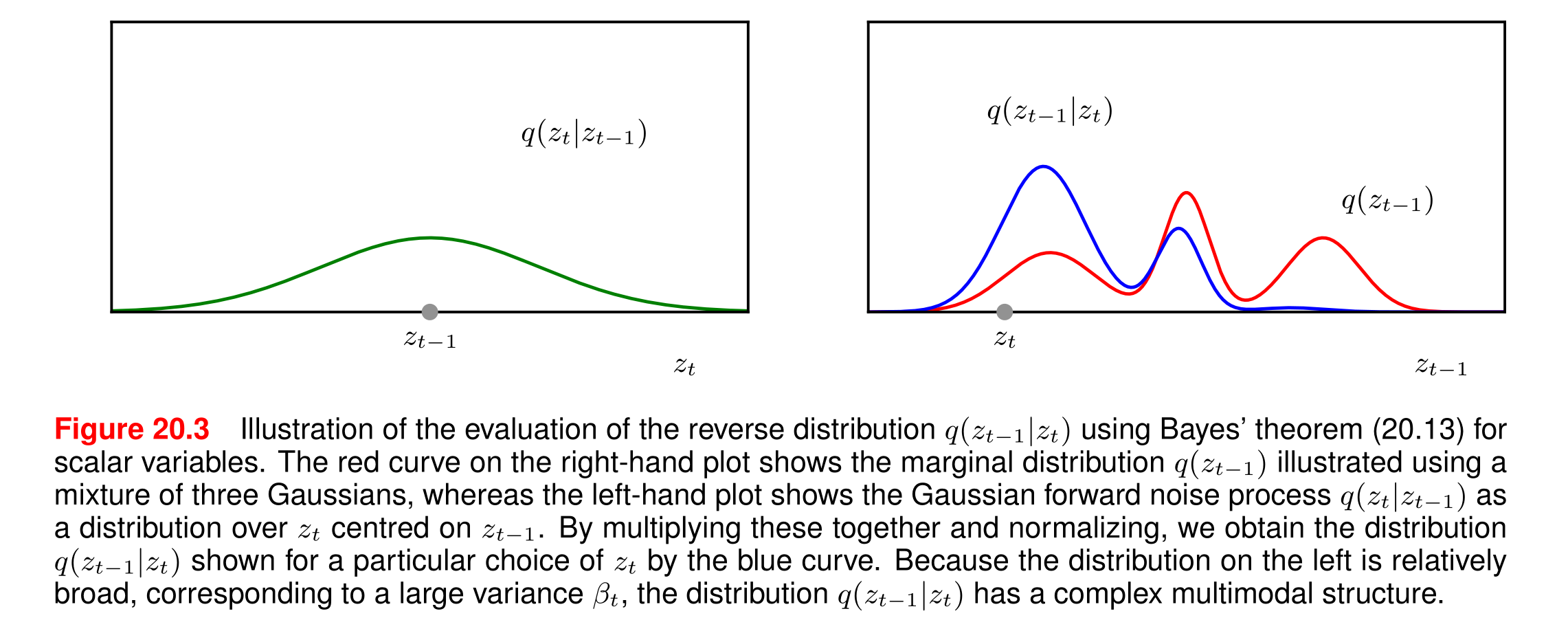
这张图(图20.3)展示了扩散模型中逆向分布的计算过程,以下是详细解析:
1. 图的组成与含义
(1) 左子图:前向噪声过程q(zt∣zt−1)q(z_t|z_{t-1})q(zt∣zt−1)
- 横轴:噪声数据 ztz_tzt
- 纵轴:概率密度
- 曲线特征:以 zt−1z_{t-1}zt−1为中心的高斯分布(钟形曲线)
- 关键参数:方差βt\beta_tβt较大 → 曲线"宽泛"(平坦)
- 物理意义:表示单步加噪时,ztz_tzt 可能取值的范围较大
(2) 右子图:边缘分布q(zt−1)q(z_{t-1})q(zt−1)
- 横轴:数据 zt−1z_{t-1}zt−1
- 纵轴:概率密度
- 红色曲线:三个高斯分布的混合(多峰结构)
- 物理意义:反映数据在t−1t-1t−1 步的整体分布(可能对应不同模态的真实数据)
(3) 蓝色曲线:逆向分布q(zt−1∣zt)q(z_{t-1}|z_t)q(zt−1∣zt)
- 生成方式:通过贝叶斯定理将左、右子图的分布相乘并归一化
- 特征:复杂多峰结构(多个局部最大值)
- 物理意义:给定当前噪声ztz_tzt,可能对应多个潜在的 zt−1z_{t-1}zt−1状态
2. 关键句解析
“由于左侧分布(对应大方差βt)相对宽泛,导致逆向分布q(zt−1∣zt)q(zt−1|zt)q(zt−1∣zt)呈现出复杂的多峰结构。”
(1) 因果关系
- 大方差 βt\beta_tβt → 前向分布 q(zt∣zt−1)q(z_t|z_{t-1})q(zt∣zt−1) 平坦 → 允许 ztz_tzt 偏离 zt−1z_{t-1}zt−1更远
- 结果:一个 ztz_tzt可能由多个不同的zt−1z_{t-1}zt−1生成 → 逆向分布出现多峰
(2) 多峰结构的含义
- 每个峰:对应一个可能的zt−1z_{t-1}zt−1 来源
- 示例:若原始数据包含"猫"和"狗"两类,加噪后的ztz_tzt可能无法确定源自哪类 → 逆向分布同时保留两种可能
(3) 数学解释
贝叶斯定理中:
q(zt−1∣zt)∝q(zt∣zt−1)⏟宽泛分布⋅q(zt−1)⏟多峰分布
q(z_{t-1}|z_t) \propto \underbrace{q(z_t|z_{t-1})}_{\text{宽泛分布}} \cdot \underbrace{q(z_{t-1})}_{\text{多峰分布}}
q(zt−1∣zt)∝宽泛分布q(zt∣zt−1)⋅多峰分布q(zt−1)
- 宽泛的似然q(zt∣zt−1)q(z_t|z_{t-1})q(zt∣zt−1)不会压制q(zt−1)q(z_{t-1})q(zt−1) 的多峰性
- 最终逆向分布继承q(zt−1)q(z_{t-1})q(zt−1) 的多峰特征
3. 对扩散模型的意义
- 理论挑战:多峰性说明直接计算逆向分布极其困难
- 解决方案:
- 用神经网络pθ(zt−1∣zt)p_\theta(z_{t-1}|z_t)pθ(zt−1∣zt)近似为单峰高斯
- 通过训练使网络学会选择"最可能"的峰(对应高质量生成)
- 设计启示:
- 需控制βt\beta_tβt大小:方差过大导致多峰性增强,训练难度增加
- 多峰性也赋予模型捕捉数据多样性的能力
4. 实例说明
假设:
- 右子图的三个峰对应zt−1=−1,0,1z_{t-1} = -1, 0, 1zt−1=−1,0,1(三种潜在状态)
- 观测到zt=0.5z_t = 0.5zt=0.5(左子图中心在某个 zt−1z_{t-1}zt−1
- 蓝色曲线可能在zt−1=0z_{t-1} = 0zt−1=0和zt−1=1z_{t-1} = 1zt−1=1处各有一个峰
→ 说明zt=0.5z_t = 0.5zt=0.5可能由zt−1=0z_{t-1} = 0zt−1=0或111 加噪得到
5. 总结
该图揭示了扩散模型中逆向过程的本质困难:
前向噪声的随机性(大方差)导致逆向推断存在歧义,而模型必须通过学习解决这种歧义,才能实现高质量生成。这一现象也解释了为什么扩散模型需要复杂的网络结构和训练技巧。
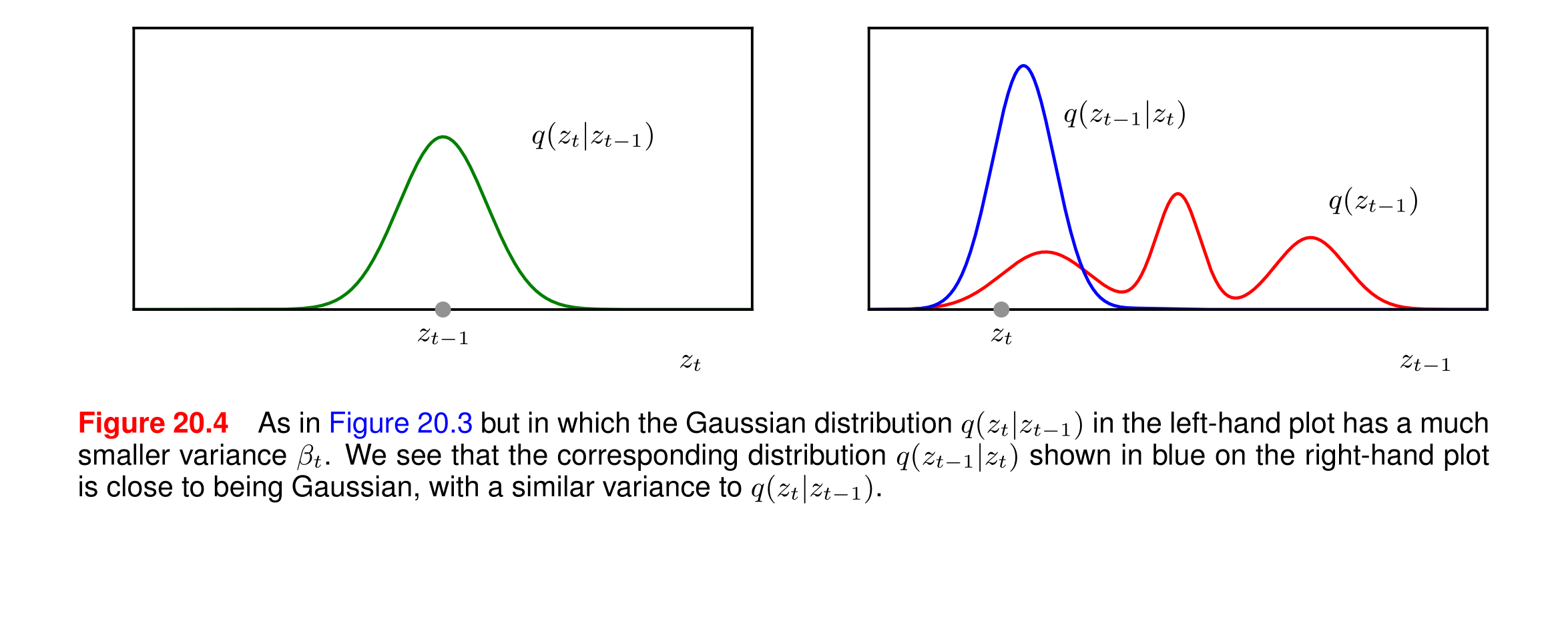
在图20.4中,左图展示了条件概率分布q(zt∣zt−1)q(z_t | z_{t-1})q(zt∣zt−1),其方差βt\beta_tβt较小,这意味着分布更窄。右图展示了相应的逆过程分布q(zt−1∣zt)q(z_{t-1} | z_t)q(zt−1∣zt)。
为什么分布更窄并不意味着变化更明显?
-
方差与变化幅度:
- 方差是衡量数据分布的离散程度的指标。较小的方差意味着数据点更集中在均值附近。
- 在条件概率分布 q(zt∣zt−1)q(z_t | z_{t-1})q(zt∣zt−1)中,较小的方差表示在给定 zt−1z_{t-1}zt−1 的情况下, ztz_tzt 的取值更集中在某个特定值附近,即 ztz_tzt 的变化幅度较小。
-
逆过程分布:
- 右图中的蓝色曲线 q(zt−1∣zt)q(z_{t-1} | z_t)q(zt−1∣zt)展示了在给定 ztz_tzt的情况下, zt−1z_{t-1}zt−1 的分布。
- 由于左图中的 q(zt∣zt−1)q(z_t | z_{t-1})q(zt∣zt−1) 分布较窄,意味着 ztz_tzt 的取值相对集中,因此在逆过程中, zt−1z_{t-1}zt−1 的分布也相对集中,接近高斯分布。
-
变化幅度与学习难度:
- 分布更窄意味着在每一步变换中,潜在变量的变化幅度较小。这种微小的变化使得模型更容易学习如何逆转这些变换,因为每一步的变换都是可预测的、稳定的。
- 如果方差较大,潜在变量的变化幅度会更大,这会增加模型学习逆过程的难度,因为每一步的变换更加不可预测。
总结
- 分布更窄(方差较小)意味着潜在变量的变化幅度较小,而不是变化更明显。
- 这种微小的变化使得逆过程更容易学习和预测,因为每一步的变换都是相对稳定和可预测的。
- 因此,较小的方差有助于简化模型的学习过程,但可能需要更多的步骤来达到显著的总体变化。








)
)
操作)
)







)