目录
- 1.表结构的操作
- (1)增加表
- (2)查看库中所有的表
- (3)查看表每个列的约束
- (4)删除整张表
- (5)删除某个具体的列
- (6)增加某个具体的列
- (7)修改某个具体的列,但不对列明做修改
- (8)修改某个具体的列,要对列明做修改
- (9)修改表的名字
- (10)修改表的存储引擎
- (11)修改表的字符集、校验集
- 2.数据类型(Type)
- (1)数值类型
- a.int家族
- b.bit类型
- c.float(小数类型)
- d.decimal(小数类型)
- (2)文本、二进制类型
- a.char
- b.varchar
- (3)日期和时间类型
- a.date
- b.datetime
- c.timestamp
- d.datetime和timestamp的区别
- (4)String类型
- a.enum
- b.set
- c.find_in_set
- 3.约束
- (1)空属性(Null)
- (2)默认值(Default)
- (3)列描述(Comment)
- (4)zerofill
- (5)键(Key)
- a.主键(primary key)
- b.自增长(auto_increment)
- c.唯一键(unique)
- d.外键(foreign key)
1.表结构的操作
在MySQL中,表就相当于文件夹中的具体的文件,这个文件里面存的就是有效数据 。这些有效数据在逻辑上就是一个表格。
例如用户管理中,不同列代表不同用户属性(如用户ID、电话、公司、住址等),每一行表示一个用户,读取一行,再根据每列确定用户信息。
下面将从表的常见操作出发,逐渐延伸至创建表的列所需要了解的约束和数据类型。
(1)增加表
必须use database之后才可以增加表,每个表必须存在数据库中。
create table tb (
id int, # 类型在后,命名在前,和C/C++的风格是相反的
name varchar(30) # 不同列属性有不同类型,还要跟上所需的约束
#最后一个列之后不加逗号
) [charset=gbk collate=gbk_bin engine=MyISAM];
其中charset、collate、engine的设置如果不显式指定的话,就会优先使用database创建时设置的,如果没有再使用系统默认的, 所以我们可以在database创建时设置该库下的所有table存储方式。
(2)查看库中所有的表
首先我们肯定想知道增加表后当前数据库存的所有表有哪些
show tables;
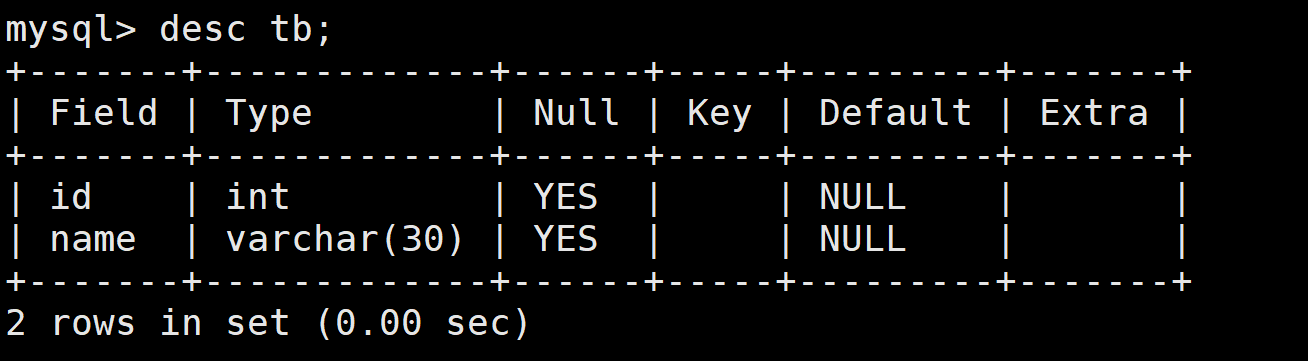
(3)查看表每个列的约束
其次我们想要知道某个表的具体列的具体属性,每个列所遵循的属性也叫做约束
desc db; # 显示列的属性,而不是内容
下面显示的就是列的各种属性(约束)
(4)删除整张表
drop table tb;
(5)删除某个具体的列
有的时候我们并不想删除整张表,而是某个列,本质上这是对table的修改,所以会用到alter语句
alter table tb drop id;
(6)增加某个具体的列
既然能够删除某个具体的列,自然也能增加某个具体的列,我们也能指定增加的列在现有的某个列之后
alter table tb add age int [before name]; # before可以换成after,增加的列要包含所需的约束
(7)修改某个具体的列,但不对列明做修改
alter table tb modify id varchar(10);
修改某个具体的列需要重新设置列的所有属性(约束),会对指定名称的列完全覆盖,这里演示比较简单,后面带入约束后要记得加上,否则会导致错误。
但这样只能修改除列名以外的其它属性,要修改列名需要用到change
(8)修改某个具体的列,要对列明做修改
如果不是为了修改列的其它约束,单单修改名字的话可以用到change
alter table tb change id num varchar(10); # 要跟完整约束
(9)修改表的名字
除了修改某一个具体的列的名字,我们还可以修改整张表的名字
alter table tb rename [to] tb_1;
(10)修改表的存储引擎
alter table tb engine=Innodb;
(11)修改表的字符集、校验集
alter table tb convert to character set utf8mb4 collate utf8mb4_general_ci; # 不支持等号简写
靠前的相对而言更重要,修改存储引擎和字符校验集的情况极少。
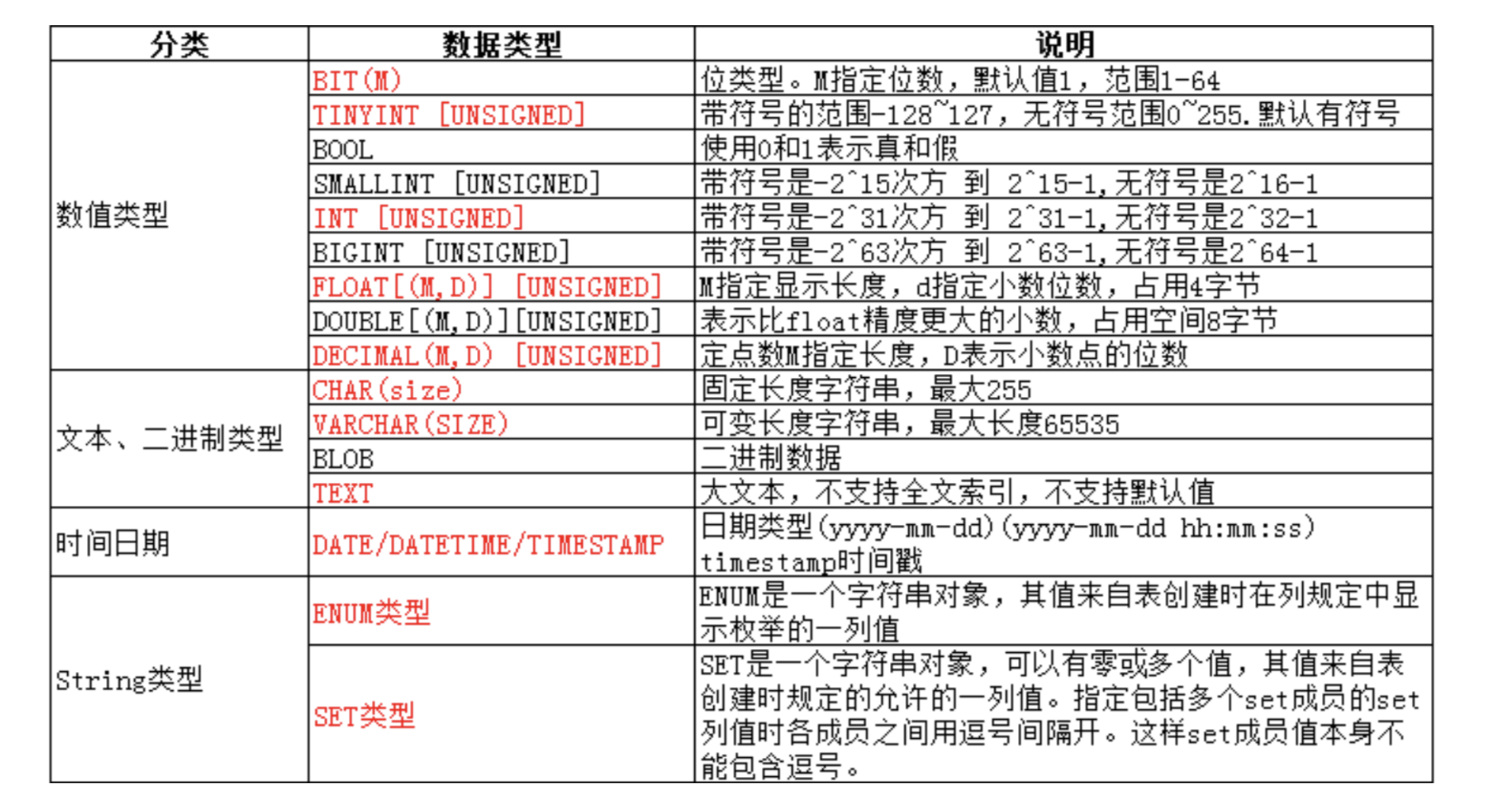
2.数据类型(Type)
可以看到数据类型是被分为四类的,后面会分别讲述每个类型的作用以及适用的场景。
(1)数值类型
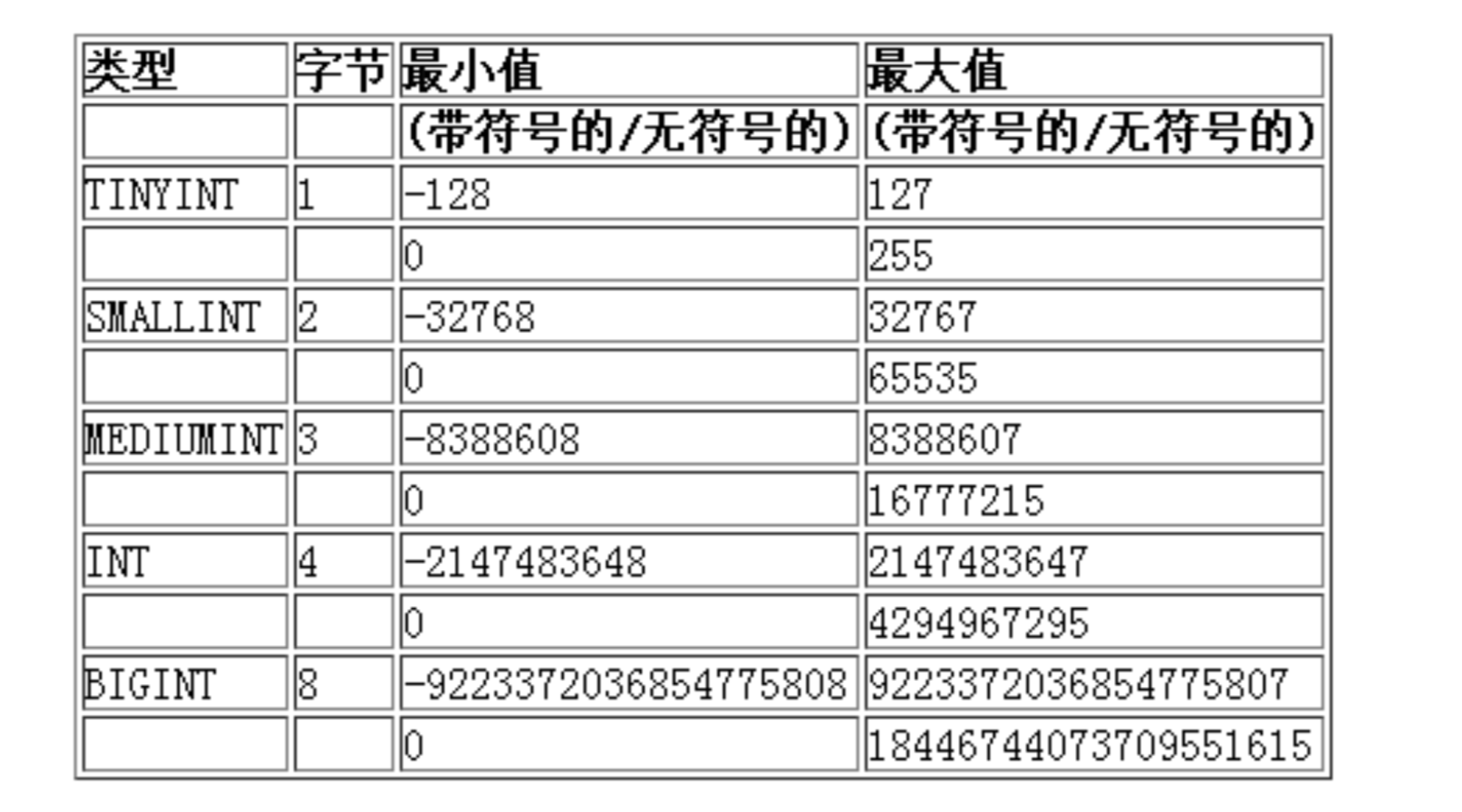
a.int家族
int家族在MySQL这里也是有对应类型的,其中tinyint大小对应char,smallint对应short,bigint对应long long,也新增了一个3字节的mediumint,整体而言是很容易记住的。
数据库是数据安全体系中最后一道防线,因为用户的数据在经过数据库的检查后会被直接保存起来了,这是发现数据异常的最后一个机会。因此数据库要解决的一个关键问题就是这个数据符不符合规范?能不能存进去?这就是数据库约束存在的根本原因。
因此数据库对数据类型有着更严格的限制,所以在MySQL中不存在C/C++中的截断、隐式类型转换等操作,只要发现存入的数值不在应有范围内,会直接放弃插入该整行并向用户报错。(默认均为有符号类型)
b.bit类型
bit[(M)] : 位字段类型。其中M表示每个值的bit位数,范围从1~64。如果M被忽略,默认为1。
宽泛上说,bit类型也属于整形家族,它的特点和char一样,在显示的时候都是以ASCII码对应的值显示的。
c.float(小数类型)
float[(m, d)] [unsigned] : m指定数的最大显示长度(不包含小数点),d指定小数位数,也就是说整数部分的位数最大是m - d。该类型占用空间4个字节
例如,float(6, 3)就是指小数位最多3位,因此对应整数位最多3位,该类型范围是-999.999 ~ 999.999。 如果插入999.9978会被四舍五入至999.998,但注意对于有的版本插入-1000或1000会被四舍五入,有的就会严格报错,我们不要插入这种有争议的数值。
当我们使用unsigned时,该数据类型范围直接砍半,如float(6, 3) unsigned直接变为0 ~ 999.999,所以unsigned在这里更多是作为约束使用的。
d.decimal(小数类型)
decimal(m, d) [unsigned] : 同理,m指定数的总长度,d表示小数点的位数
float表示的精度大约是7位,当超过7位时就会出现精度丢失,原因在于无法用二进制指数在有限精度下准确表示任意十进制的数值。 decimal精度支持整数最大位数m为65,支持小数最大位数d是30。因此,需要高精度存储时优先使用decimal。
(2)文本、二进制类型
a.char
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
当我们想要存别人的姓名、地址时就可以用这个类型,看上去是char,实际上对应C++中的string,真正的char在MySQL这里是bit(8),我们要注意不要搞混了。
还有一个区别点,MySQL中的字符是严格意义上根据显示效果定义的,而非根据底层存储定义的,也就是说一个汉字也叫一个字符,就算它实际存了3个字节,一个字母也是一个符号。
b.varchar
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节 (注意不是字符,因此受到编码选择的影响)
它的功能和char基本没区别,都是存储字符串,但它在底层实现和空间占用策略和char不一样。变长的含义是在不超过自定义范围的情况下,用多少,开辟多少,相应时间效率会低一些;相比而言char定长的意义是,直接开辟好对应的空间,时间效率相对较高。
因此在选用char和varchar时要明确自己的需求,比如填地址其实更适合varchar,varchar可以开得很大而无需担心空间问题,它只需要关心最大长度的地址能存进去就行了;性别就适合char(1),因为一个人必须有一个性别且要么是男,要么是女。
要实现varchar需要有个开销,需要有个变量存储当前的size,就像当初我们vector的实现那样,这个开销根据我们的实际占用在1 ~ 3字节之间,并且这个开销会算在总的65535字节中。
当表的编码是utf8时,varchar(n)的参数n最大值是65532(除去size开销) / 3 = 21844(utf中,一个字符占用3个字节,变长存储)
如果编码是gbk,varchar(n)的参数n最大是65532 / 2 = 32766(gbk中,一个字符占用2字节,变长存储)。
但由于变长存储和size开销不定,所以上述计算仅为参考,一般我们不会触碰到varchar的极限,如果要存的字符串真的很大,建议使用text类型。
(3)日期和时间类型
a.date
date: 日期格式为 ‘yyyy-mm-dd’ ,该类型占用三字节
在插入过程中需要严格按照格式来写
b.datetime
datetime: 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ ,其中每个数字表示范围从 1000到 9999,该类型占用八字节
c.timestamp
timestamp: 时间戳,这个值是从1970年1月1日开始到当前时间总共的s(或ms)数。
但是需要注意的是,timestamp底层是按照时间戳的值在存,占用4字节。但显示时是按照yyyy-mm-dd HH:ii:ss格式显示,和datetime完全一致。
但这就引出了一个问题,timestamp和datetime在表层有什么区别?
d.datetime和timestamp的区别
datetime本质上是为了提供一种精准存储时间的类型,我们可以用这个类型存放任意时间,比如某个人坐上飞机的时间,这个时间和当前时间没什么关系,看的是我们关心的事件发生的时刻。
而timestamp形象地说是提供了一种标记,这个类型不需要插任何值,会自动补全。当我们插入一行时这个变量自动初始化为当前时间,当我们更新这一行时同样会更新timestamp,因此timestamp很适合用来做“最后修改时间”的类型。
(4)String类型
a.enum
enum: enum( ‘选项1’, ‘选项2’, ‘选项3’, … ); # 在定义数据类型时就要确定选项,后续的插入等只能在选项中选择
存储的数据就是enum中的一个。在底层,存储的实际上是当前选项对应的数字(下标),内容只存一份,通过映射来一一匹配每个选项,因此enum的选项上限是65535。
b.set
set: set( ‘选项值1’, ‘选项值2’, ‘选项值3’, … ) # 相比较enum而言可以多选
同样,底层上存储的是我们选项的下标,我们用unordered_map来理解就行,本质上就是一种映射,set最多允许同时选64个选项。
c.find_in_set
既然有选择,那必然也有筛选,很多时候我们希望通过用户不同的选择来筛选特定用户,这就要讲到一个内置函数find_in_set

上述函数实现了在集合’a, b, c’中寻找不同元素,其中找到了返回下标(从1开始),没找到返回0。根据实例我们也能发现只能找单个元素,即只能匹配一个选项,第一个例子函数直接把’a, b’当成了一个整体选项,在只有a、b、c三个选项的集合中找,自然是找不到的。
一般实际使用为:
select * from friends where find_in_set('游泳', hobby);
这样的话就可以找到行中hobby含有游泳的人了。
3.约束
其实通过上述讲解我们就应该意识到,数据类型本身就是一种约束。要求我们传入int,那我们只能存入int,要求float范围不能超,我们就不能存入超范围的数,这种约束能够更快帮助我们发现存储数据中的错误,并及时向上反馈。由于约束的存在,MySQL能保证只要数据成功存入,那么它就一定符合规范,即约束很好地回答了“这个数据该不该存进去,符不符合规范”这个问题。
除了数据类型,我们还需要知道其它种类的约束,它们共同作用组成了MySQL数据安全的一道防线。
(1)空属性(Null)
创建语句:name varchar(20) not null # 也可写作null,表示允许为空
数据类型也是一种约束,not null和null也是一种约束,约束条件放一起,因此not null直接跟在上一个约束后面是符合逻辑的。
空属性存在的实际意义是防止一些必要信息的漏填和缺失,如某个人的电话号码,学生的期末成绩等。加上not null之后就必须插入数据且也要符合其它约束,否则整行插入失败。默认情况下是null,即不显式指定时not null允许不插入数据。
除了实际意义,空属性也具有一定的语法意义,例如,1+null=null,即任何空值均不能参与任何运算。也就是说只要学生的成绩栏有一个人的是null,那么就没办法计算它们的总值、平均值等,所以空属性也是在一定程度上避免触发这种语法特性而导致错误。
(2)默认值(Default)
默认值是指在用户不指定存入数据的情况下默认存入的值,用户可以在创建表结构时自定义默认值(要符合规则),因此也可理解为缺省值。
score mediumint unsigned not null default 0
可以说,只要设置缺省值,表格中该列就一定不为空了吗?换句话说,上面实例中not null能否去掉?
如果我们不插入值,该字段会默认使用缺省值,但当我们显式插入值时,就会使用我们指定的值,要是我们指定插入null呢? 所以默认值不能完全实现not null的效果,如果我们希望一个字段不为空,我们依然需要加上not null
(3)列描述(Comment)
age int not null comment '姓名'
可以理解为对这一列的注释,没有强制限制,但从另一种角度上说,这也是对用户的限制,明确该字段是什么含义同样可以有效降低错误数据的存储概率。
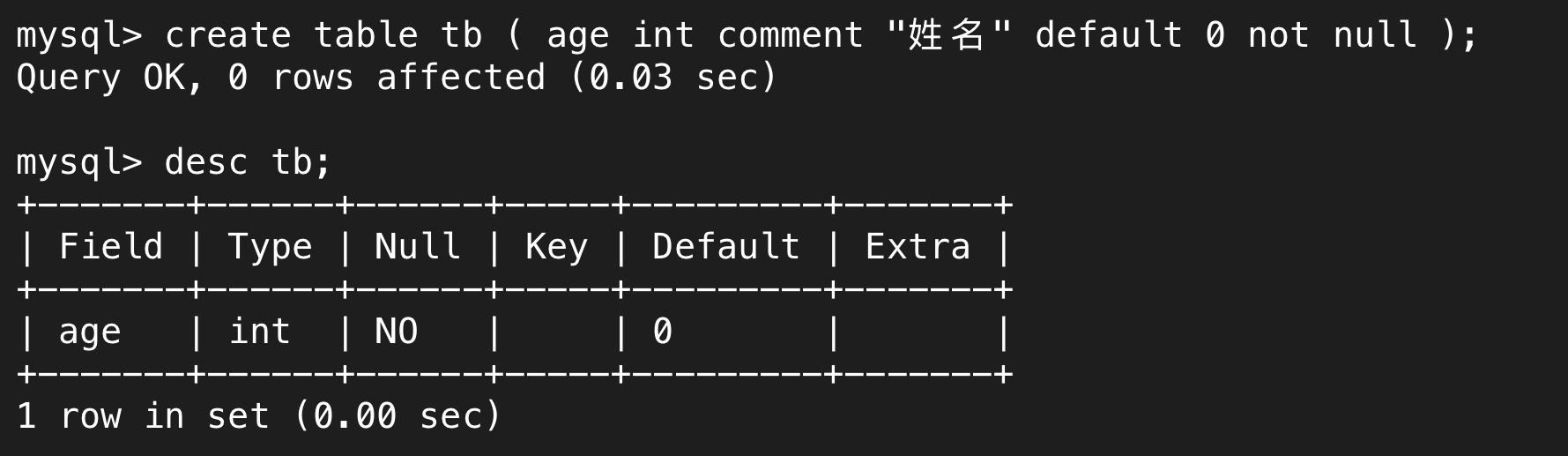
但是,这个comment在哪呢?使用desc只能看到如Null和Default等属性,comment并不在里面。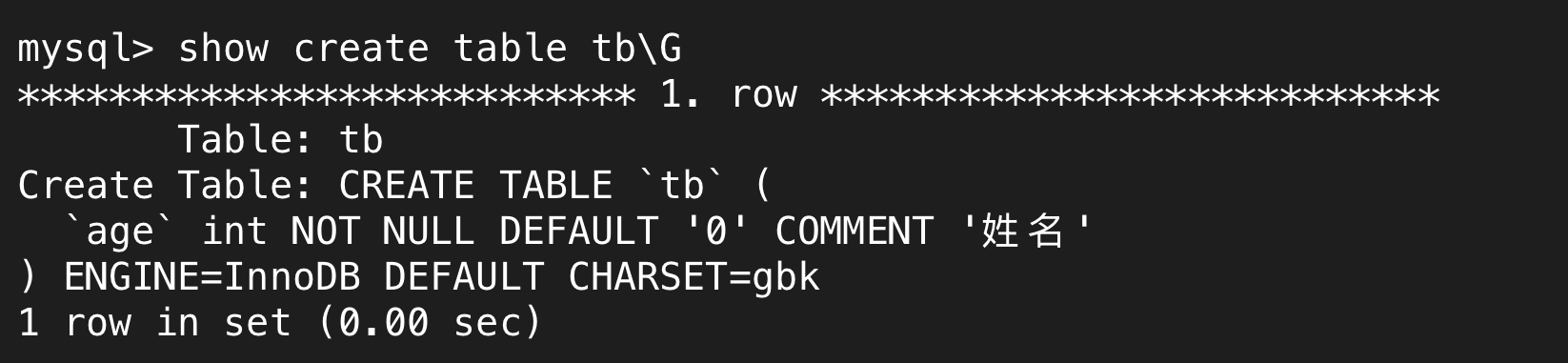
在之前就提过show create可以查看相应的创建语句,在这里同样适用,我们可以通过show create table方式查看comment约束。
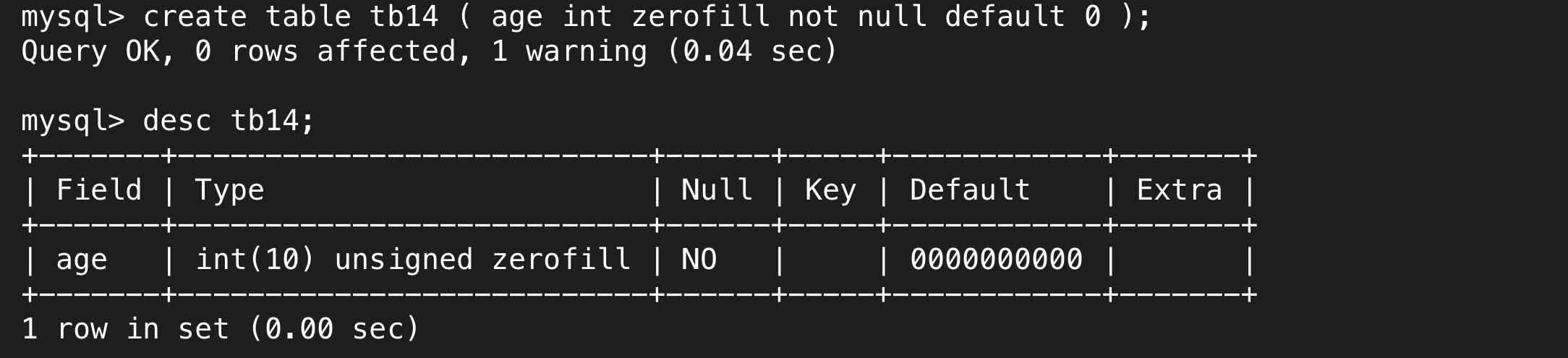
(4)zerofill
我们来看下面这个例子,创建表结构时在数据类型后面紧挨着zerofill,导致显示的时候前端用0填充了。
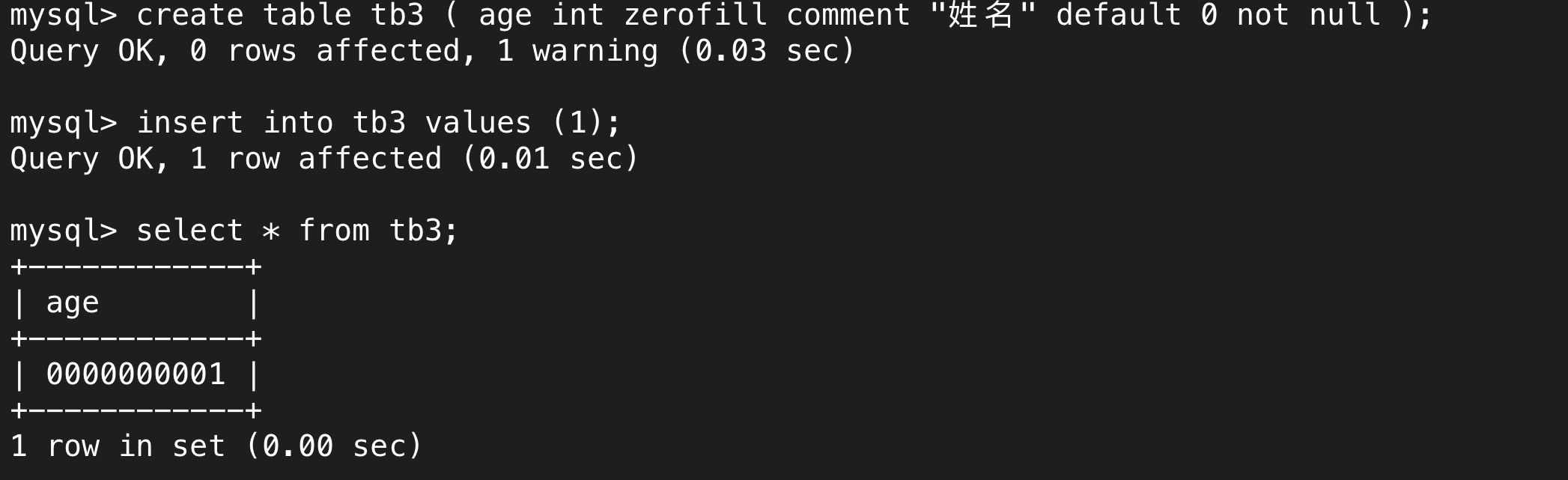
我们可以看到一共填充了9个0,加上有效位数一共是10位数,10位数正是int类型所显示的最大数所需的位数。
zerofill是一种格式化输出的设置,它不会对我们存储的有效数据做出约束,但在显示时会根据我们的有效数据,在高位补齐0以保证显示位数一致。
通过下面的例子就能明白其用法了。
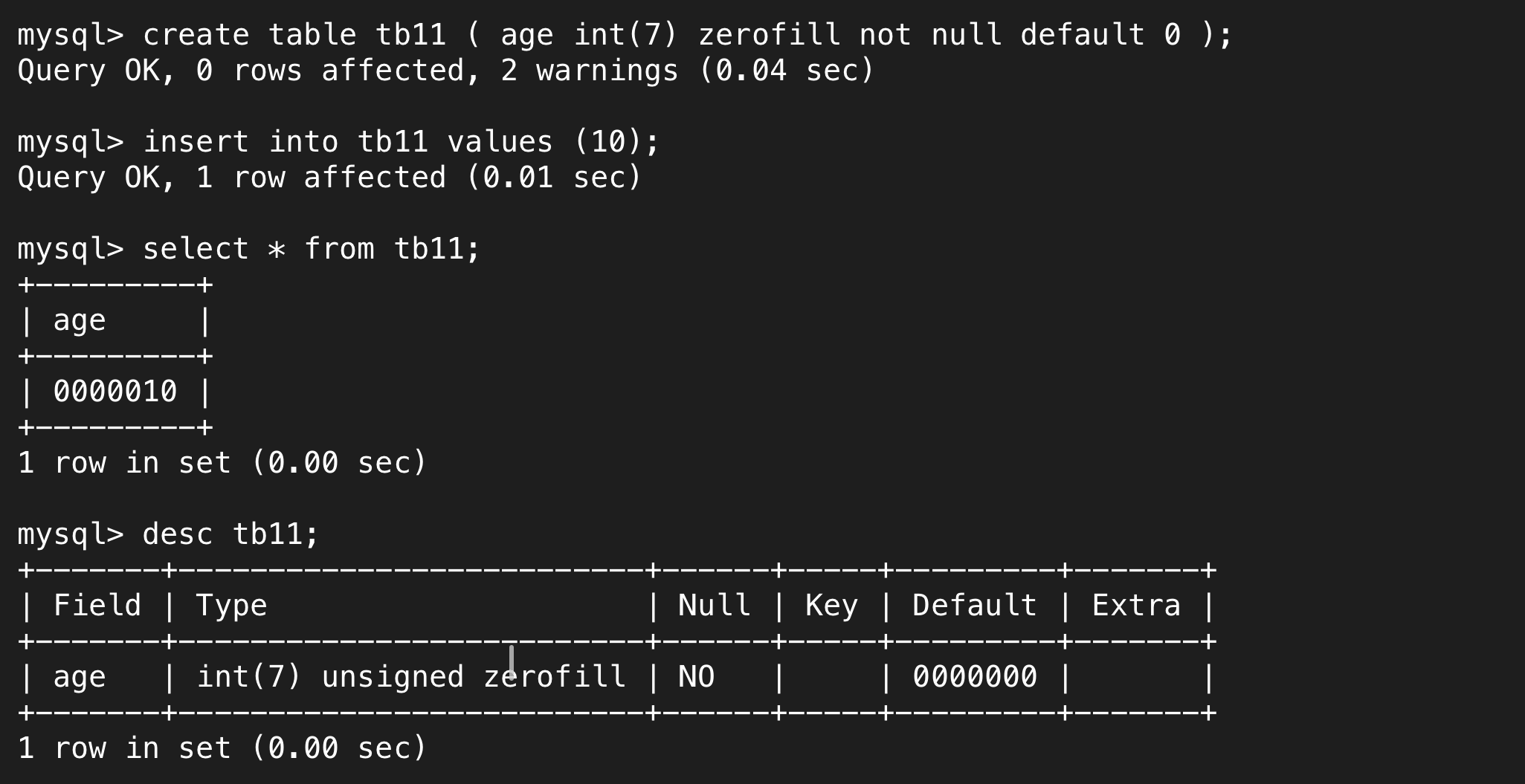
我们能够自由选择填充的位数,并且能够在desc里面看到它,默认情况下都是int(10),有的系统在默认情况下desc会显示int(10),有的则不会。取10是因为int的最大值需要用10位来表示。同时,如果显示位数低于当前数据位数,就会忽略限制,完整的显示。
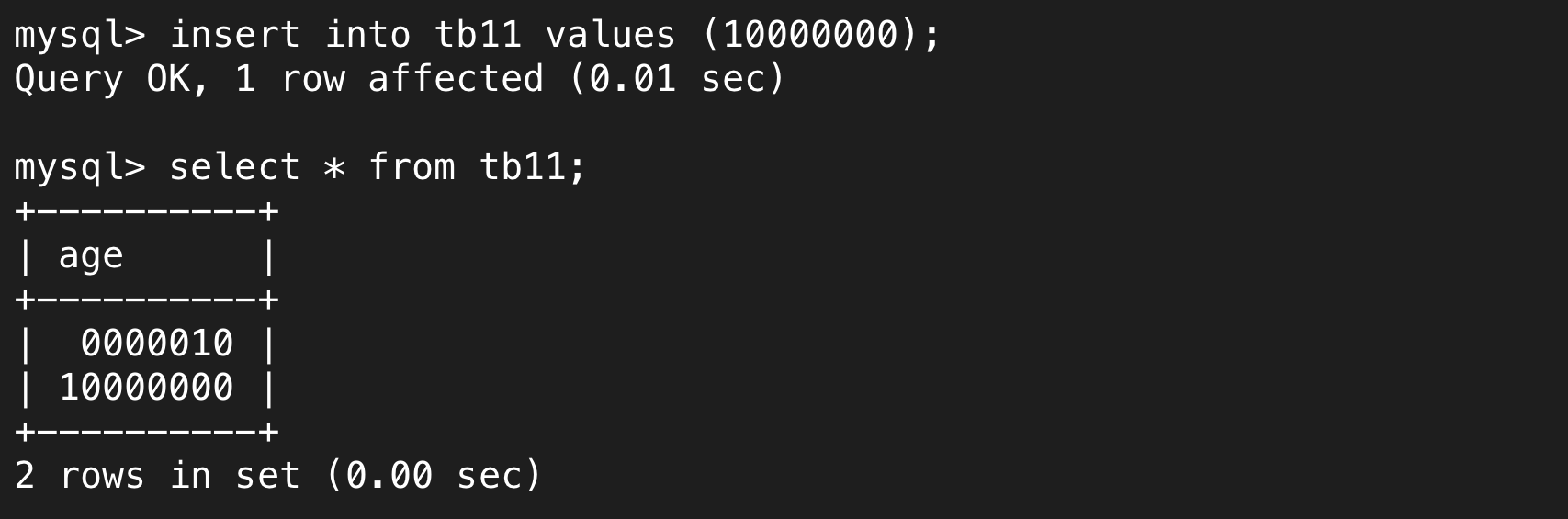
对于float而言也存在zerofill,但注意它会保证小数位和预期一致,整数位少1,因为它算上了标点符号,格式化输出总共6个符号
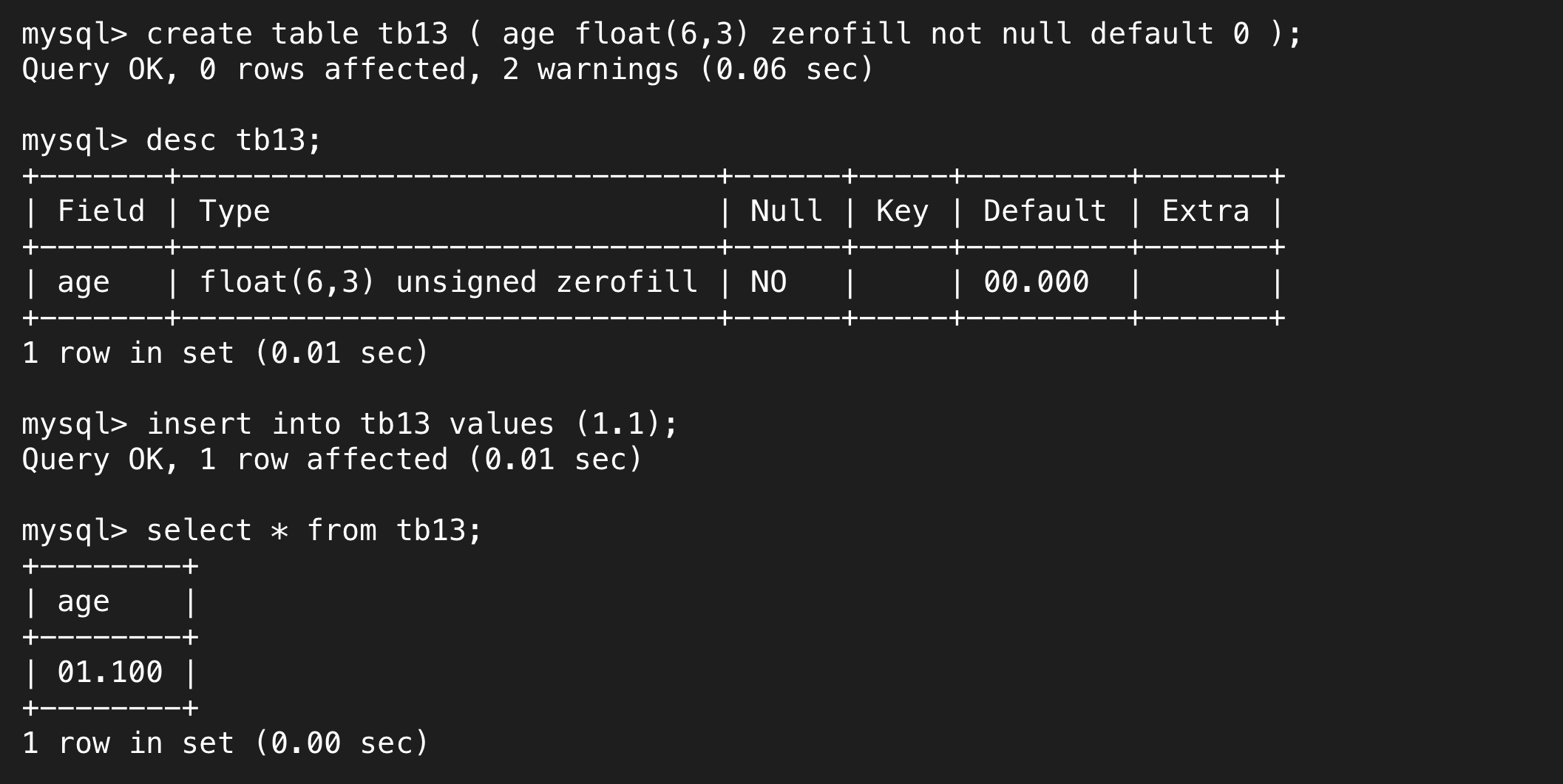
zerofill在特定情况下会使用,如金额会统一显示到小数点后两位,id号的显示。zerofill只能用于int家族和float家族(数值类型),对于char、varchar、时间、String类型无效。
并且有一个细节需要注意,当我们为int/float添加zerofill约束时,会自动变为无符号类型
(5)键(Key)
key是MySQL的一个重要约束,它也是MySQL存储引擎实现的一个重要条件。 键有不同种类,我们可以用键值对来辅助理解键,下面将详细介绍。
a.主键(primary key)
一张表只能有一个字段被设为主键,主键对应列的元素不能为空,且每个元素保持唯一性。
使用时直接在字段后面指定即可
id int(10) zerofill primary key comment '学号'
primary key能够完全达到not null的功能,所以指定主键后没必要再指定空属性了。
同时,主键可以直接追加(前提需保证已有数据满足主键要求),用法如下图:
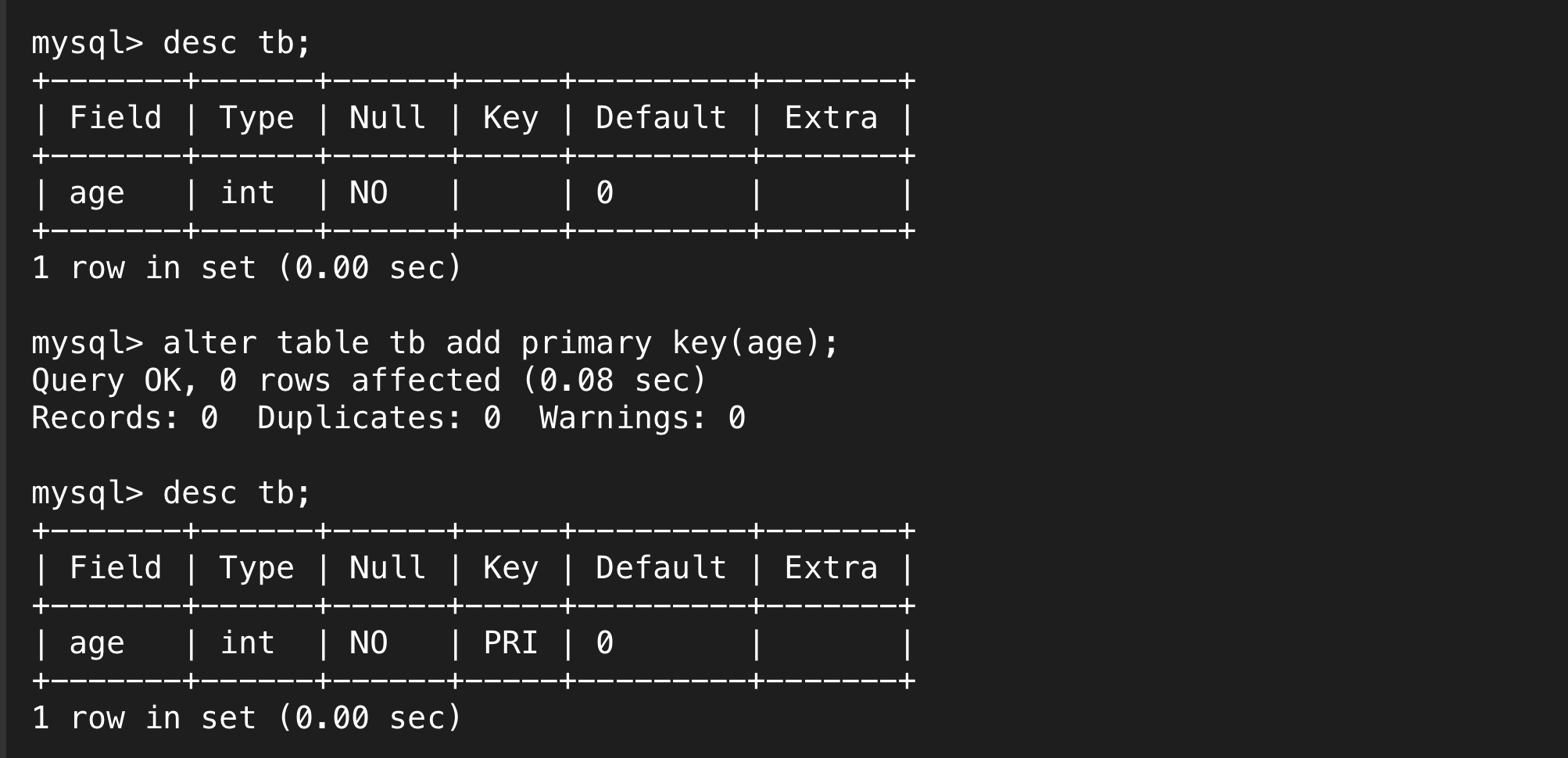
也能直接删除主键

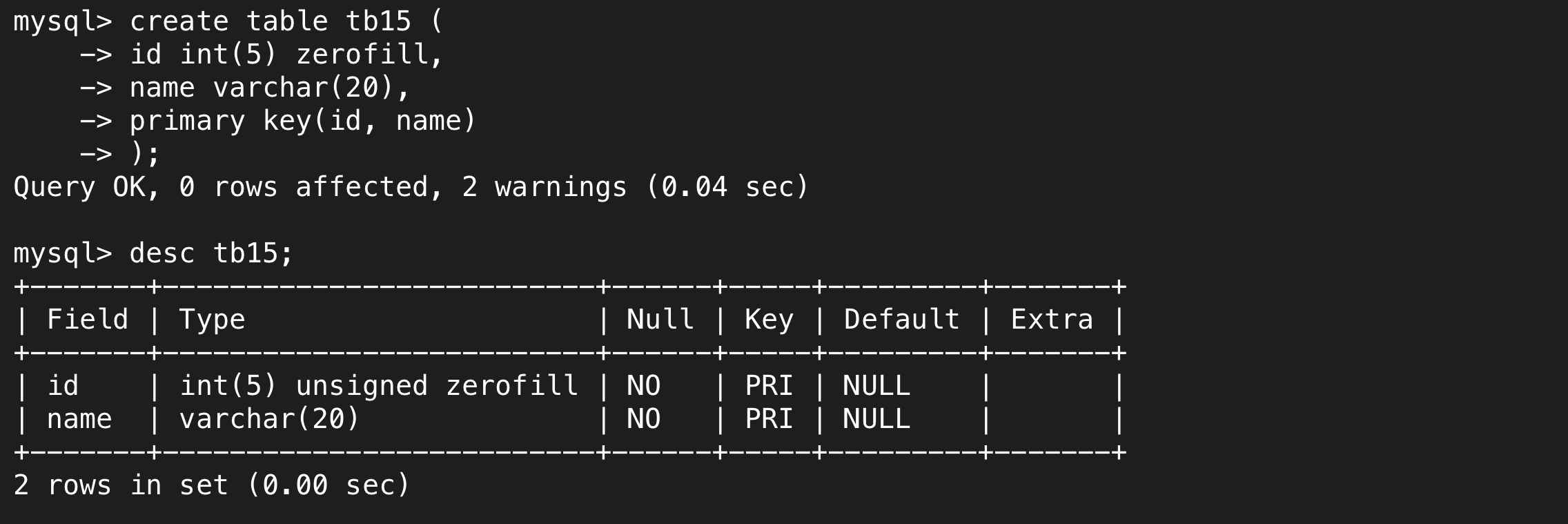
MySQL还支持复合主键,即多个字段一起作为一个键,在创建表结构的时候需要单起一行指定,也可以用上面的方法添加。 复合主键的条件自然是均不为空和整体唯一。
b.自增长(auto_increment)
自增长必须绑定在主键或者唯一键之后
下面是它的用法:
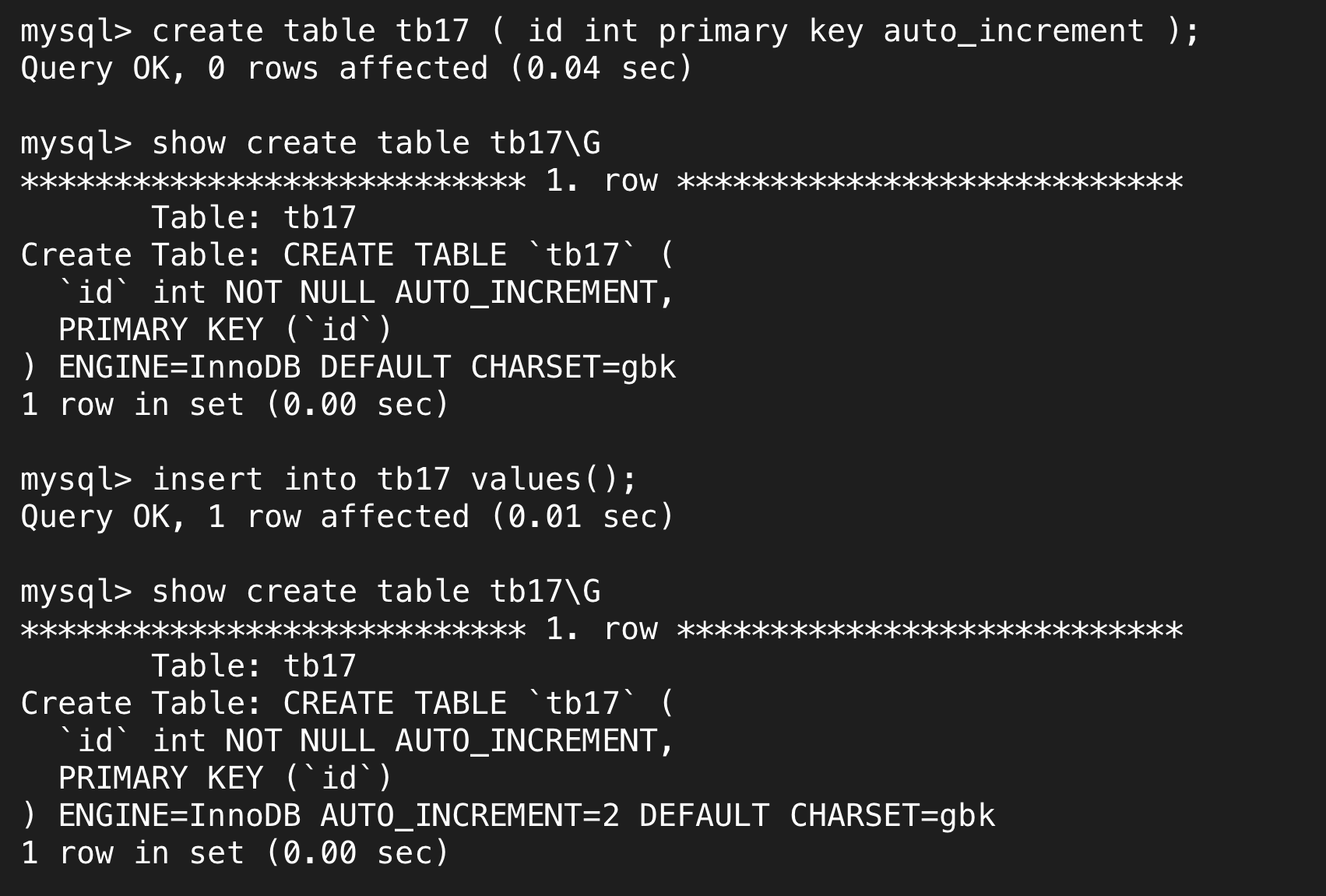
可以看到,指定了自增长后我们就不需要插入数据了,它会自动加上数据。其中用show create可以看到AUTO_INCREMENT=2字样,在此之前只插入了一个数据,因此这个字段指的是下一个数据默认插入值。
我们插入后查看相关属性和内容
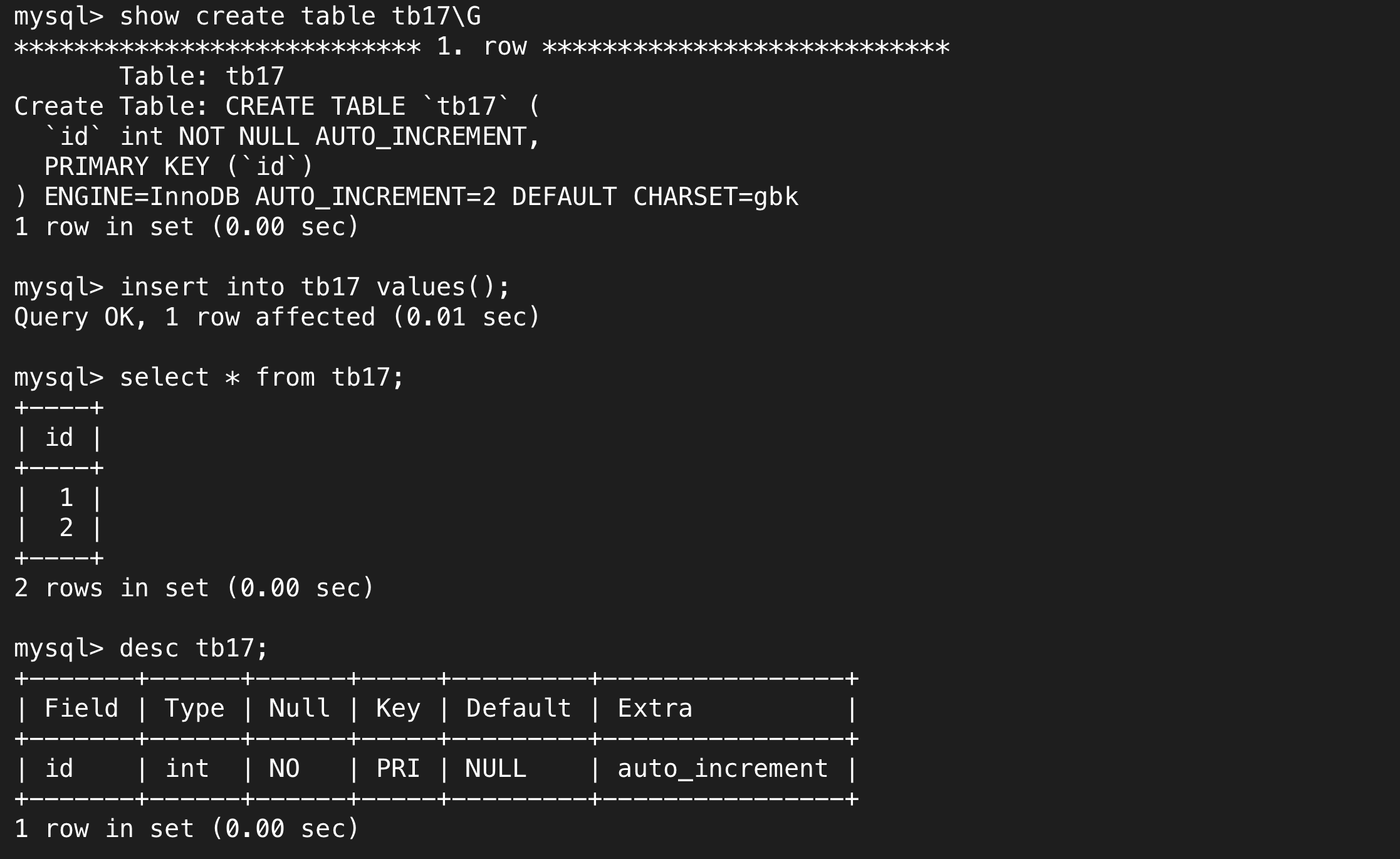
自增长每次自动加1,因此自增长字段必须是一个整数,且一张表最多有一个自增长字段。
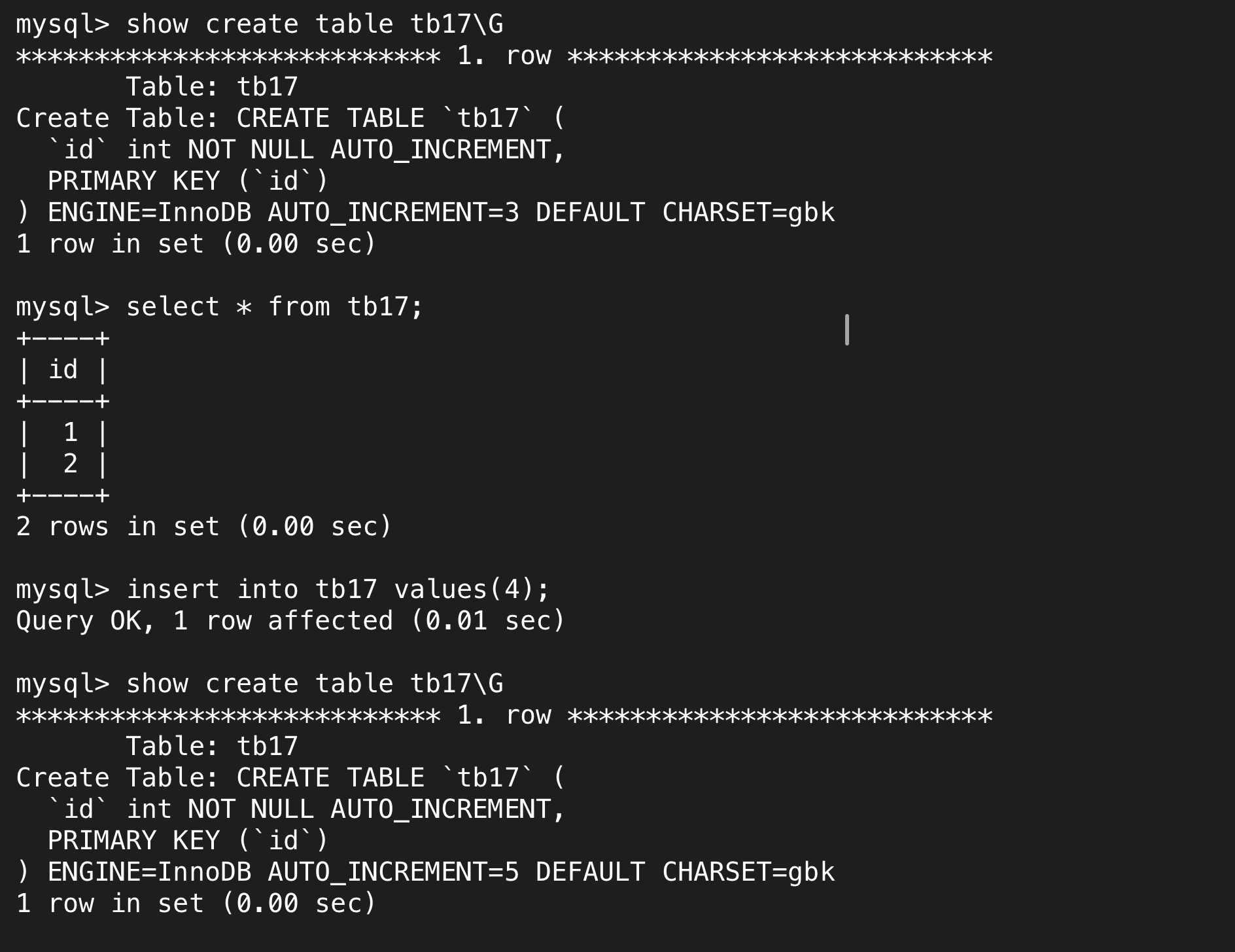
除此之外,自增长允许自定义插入,也就是说我们可以指定插入一个具体的值,自增长会根据我们插入的值自动加1作为下一个自动插入数据。
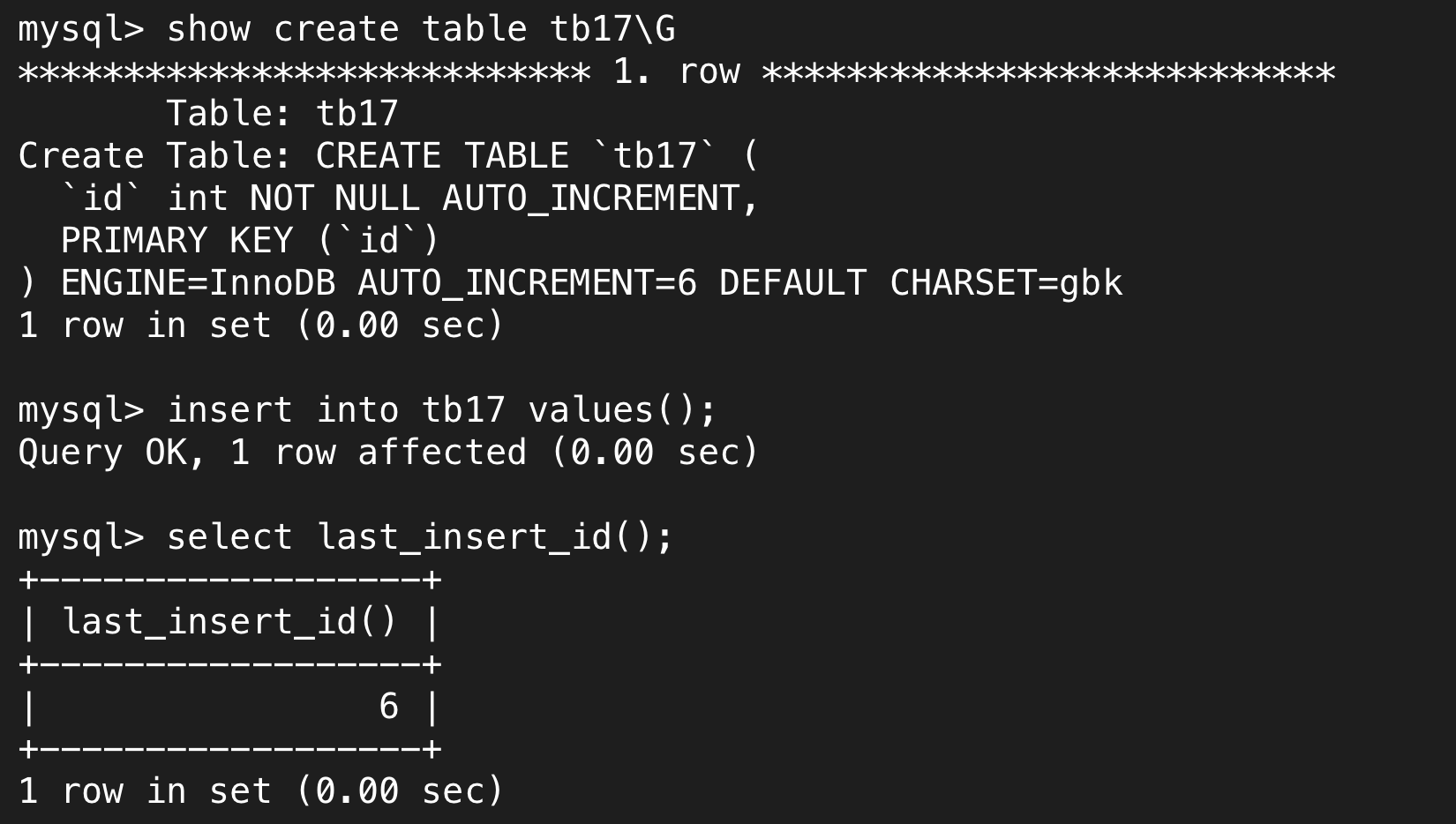
最后值得分享一个内置函数last_insert_id(),它可以获取上次自增长插入的值。
c.唯一键(unique)
name varchar(20) unique comment '姓名'
唯一键如其名字那样,是为了保证唯一性而存在的。主键具有唯一性和不可空,唯一性具有不为空数据的唯一性和可空。主键一张表只能有一个,唯一键一张表可以有多个。
唯一键存在的意义是为了在主键之外对其它列施加唯一约束。例如,我们用身份证号作为主键,员工的姓名、电话作为唯一键,它和主键并不冲突。 但是,又有一个新的问题诞生了,为什么我们不用员工的电话作为主键呢?如何判断一个字段更适合主键还是更适合唯一键呢?
我们选取主键时尽量选择和业务无关的量,这样当业务有修改时,对主键就不会有什么影响。 上述例子中身份证显然是最无关的量,甚至可以说一个人一辈子都不会改变身份证号,有非常强的稳定性,而一个人的电话却很可能因为工作等原因换掉,所以不适合主键。
d.外键(foreign key)
外键是跨表的一个约束。先举个例子,班主任手上有两张表,一张是学生的基本信息,如姓名、学号、电话、地址、家长电话等。还有一张表是多次考试学生的成绩表,这张表的列由学生、第几次考试、各科成绩组成。这两张表在一定程度上是有联系的,信息表中的学生名字和成绩表中的应该一致,不应在成绩表中出现信息表没有的,信息表中不应出现成绩表没有的。这种约束关系需要外键来维护。
外键涉及两张表,这两张表具有从属关系,可以理解为一张表挂靠在另一张表上,是另一张表的延伸。我们可以根据两张表的特性来判断谁是主表,谁是从表。主表中相关的列(上述例子中是学生名字)必须是唯一的(primary key或者unique),外键是加在从表上的。因此,我们可以判断信息表是主表(学生信息只有一份),成绩表是从表(一个学生有多次考试,对应就有多行信息,不满足列中元素的唯一性)。
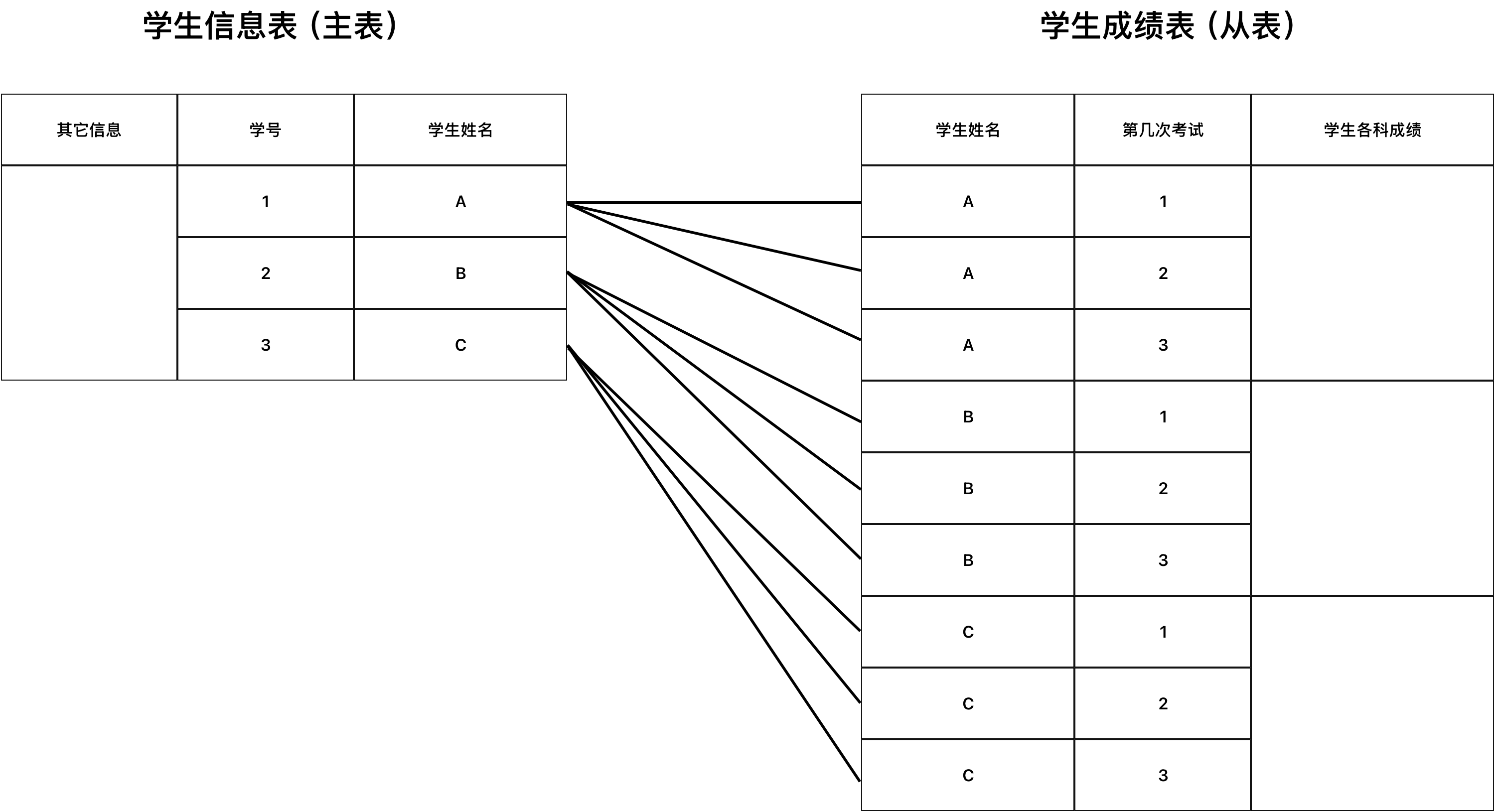
第一个判断是从唯一性出发,如果满足有不满足唯一性的只能是从表。但有时两张表都满足唯一性,比如学生成绩表只统计一次成绩呢?因此,还有一个判断的点,即外键是在从表中添加,而主表不会被修改,因此可以观察有哪些表是非常稳定,不能轻易被修改的,这种多半是主表。
# 成绩表
create table scores (
name varchar(20),
times int,
score int,
foreign key (name) references info(name)
);
这样就能将外键绑定到references的表对应的列了。
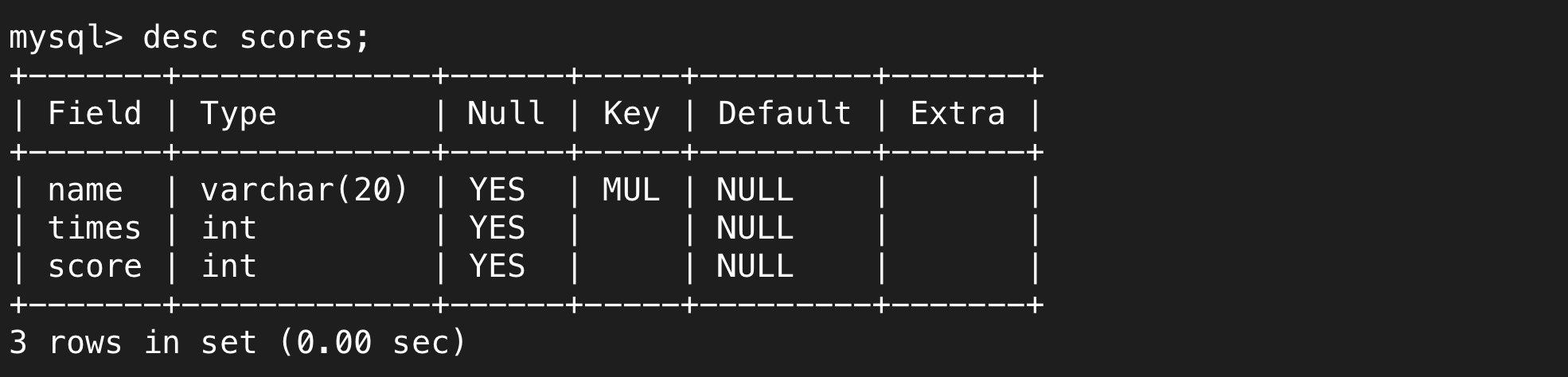
之后主从表关系建成。主表可以任意添加从表没有的信息,我们可以将主表理解为一位负责人的老师,老师可以不断增加自己的学生。从表只能添加主表中有的信息,主表中没有的从表无法添加,相当于只有老师承认了才能成为他的学生。当主表想要删除信息时,必须先保证从表中没有这个信息,相当于老师不会随便抛弃自己的学生,只要认领了学生,就要负责到底。
只要满足上述要求,就能对数据进行操作。一般来说,“外键”功能也会在应用层进行维护,有的公司甚至不会使用MySQL的外键,全权交由应用层,因为外键的功能本应由用户自己管理,MySQL只是提供一个兜底的选择。



:核心流程剖析之服务启动、请求处理与选举协议)



![[spring6: Mvc-函数式编程]-源码解析](http://pic.xiahunao.cn/[spring6: Mvc-函数式编程]-源码解析)











