目录
1、为什么 BERT 能 “懂” 语言?先看它的 “出身”
2、核心逻辑
2.1、“自学阶段”—— 预训练,像婴儿学说话一样积累语感
2.1.1、简述
2.1.2、核心本事:“双向注意力”,像人一样 “聚焦重点”
2.2、“专项复习”—— 微调,针对任务 “量身定制”
BERT 为什么这么厉害?核心优势总结
3、BERT+Transformer
3.1、 搭骨架:直接用 Transformer 的 “编码器”
3.2、 练本事:双向学习,靠 Transformer 突破单向局限
3.3、 两步走:先 “自学” 再 “专项学”,全靠 Transformer 打底
4、详解代码和实验结果
4.1、加载数据集
4.2、准备预训练环境
4.3、激活词元分析器
4.4、处理数据
4.5、防止模型对填充词元进行注意力计算
4.6、拆分数据为训练集和测试集
4.7、将所有数据转换为torch张量
4.8、选择批量大小并创建迭代器
4.9、BERT模型配置
关键配置参数说明
4.10、加载Hugging Face BERT uncased base模型
4.11、优化器分组参数
4.12、训练循环的超参数
4.13、训练循环
训练循环的关键细节
4.13.1、 模式切换
4.13.2、 梯度清零
4.13.3、 内存优化
4.13.4、 学习率调度
训练过程示例
4.14、对训练进行评估
4.15、采用测试数据集进行预测和评估
4.15.1、数据准备
4.15.2、预测阶段
4.16、使用马修斯相关系数进行评估
4.16.1、什么是 MCC?
4.16.2、MCC 的计算公式
4.16.3、公式解析与适用场景
4.16.4、如何计算 MCC?
4.16.5、详细代码
4.17、整个数据集的马修斯评估
5、完整版代码
1、为什么 BERT 能 “懂” 语言?先看它的 “出身”
BERT 的全称是Bidirectional Encoder Representations from Transformers,翻译过来就是 “基于 Transformer 的双向编码器表示”。简单说,它的 “大脑” 是Transformer 的编码器(Transformer 是 2017 年提出的一种强大的语言处理框架),而 “双向” 是它最关键的本事 —— 能同时看一个词的前文和后文,真正理解这个词在语境中的意思。
比如 “苹果” 这个词,在 “我吃了个苹果” 和 “我用苹果手机” 里意思完全不同。传统模型可能只看前文或后文,容易理解错,而 BERT 会同时结合前后文,准确判断 “苹果” 在这里指水果还是手机。
2、核心逻辑
2.1、“自学阶段”—— 预训练,像婴儿学说话一样积累语感
2.1.1、简述
BERT 在正式 “工作” 前,会先在海量文本(比如维基百科、书籍等)上做两件事,就像人小时候通过读书、听人说话积累语言感觉:
-
完形填空(Masked Language Model,MLM)
随机 “遮住” 句子里 15% 的词,让 BERT 猜被遮住的是什么。比如把 “猫在 [MASK] 上睡觉” 中的 [MASK] 换成 “沙发”“床” 还是 “桌子”?通过亿次级的 “猜词练习”,BERT 慢慢学会了 “词与词的搭配规律”。 -
句子配对(Next Sentence Prediction,NSP)
给 BERT 两句话,让它判断第二句是不是第一句的 “自然延续”。比如 “我今天去了超市” 和 “买了一箱牛奶” 是连贯的(选 “是”),但和 “月球绕着地球转” 就不连贯(选 “否”)。这一步让 BERT 学会了 “句子之间的逻辑关系”。
通过这两个任务,BERT 相当于记住了人类语言的 “潜规则”:哪些词经常一起出现,哪些句子搭配更合理,一个词在不同语境下可能有哪些意思。
2.1.2、核心本事:“双向注意力”,像人一样 “聚焦重点”
BERT 能理解上下文的关键,是 Transformer 自带的注意力机制,而且是 “双向” 的。
可以把它想象成我们读书时的状态:看到一句话,不会平均分配注意力,而是会重点看和当前词相关的部分。比如读 “小明丢了钥匙,他很着急”,“他” 显然指 “小明”,BERT 的注意力会自动 “聚焦” 到 “小明” 上,从而理解 “他” 的含义。
这种 “双向” 体现在:它不是先读前半句再读后半句,而是同时 “扫描” 整句话的所有词,计算每个词和其他词的关联度,最终搞清楚每个词在当前语境下的准确意思。
2.2、“专项复习”—— 微调,针对任务 “量身定制”
预训练后的 BERT 已经有了强大的 “语言基础”,但具体到实际任务(如情感分析、机器翻译、问答),还需要 “微调”:
给 BERT 输入带标签的数据(比如 “这部电影太好看了!” 标签为 “正面”),让它在预训练的基础上,针对当前任务调整内部参数。就像学霸考完大考后,针对薄弱科目做专项练习,效率极高。
比如做 “问答任务” 时,给 BERT 一段文章和一个问题(如 “文章中提到的城市是哪里?”),它会通过微调学会从文章中定位答案的位置;做 “情感分析” 时,它能学会判断一句话是表扬还是批评。
BERT 为什么这么厉害?核心优势总结
- 双向理解:突破传统模型 “单向” 局限,真正像人一样结合上下文;
- 迁移能力强:预训练一次,就能通过微调适配几十种语言任务,不用为每个任务从头训练;
- 语义理解深:能处理一词多义、歧义句等复杂语言现象,比如区分 “打酱油” 是 “买酱油” 还是 “凑数”。
3、BERT+Transformer
BERT 的核心是用 Transformer 的 “注意力机制” 实现双向理解,简单说就是:借 Transformer 的本事同时看前后文,先海量 “刷题” 练语感,再针对任务调参数。
3.1、 搭骨架:直接用 Transformer 的 “编码器”
Transformer 是个厉害的语言处理框架,它的 “编码器” 擅长做一件事 ——注意力机制:处理句子时,每个词都会 “关注” 到和它相关的其他词。比如 “小明帮小红拿了她的书”,“她” 指 “小红”,Transformer 的注意力会让 “她” 重点 “看” 向 “小红”,搞清楚指代关系。
BERT 直接把这个 “编码器” 拿来当骨架,所以天生就有这种 “抓重点” 的能力。
3.2、 练本事:双向学习,靠 Transformer 突破单向局限
以前的模型要么只看前文(比如从左到右猜下一个词),要么只看后文,理解容易跑偏。而 Transformer 的编码器能同时处理整个句子,BERT 就借着这个能力实现 “双向理解”:
比如 “我用苹果手机拍苹果”,BERT 会让第一个 “苹果” 重点 “关注”“手机”,第二个 “苹果” 重点 “关注”“拍”,从而分清前者指品牌,后者指水果。
3.3、 两步走:先 “自学” 再 “专项学”,全靠 Transformer 打底
-
预训练(自学):用 Transformer 的注意力机制在海量文本上练两个任务
- 完形填空:遮住 15% 的词让模型猜,练 “词和词的搭配”(比如 “雨停了,[MASK] 出来了” 该填 “太阳”)。
- 句子配对:判断两句话是否连贯,练 “句和句的逻辑”(比如 “我吃饭了” 和 “饱了” 是连贯的)。
这一步让 BERT 吃透了语言规律,就像 Transformer 给了它 “理解的底子”。
-
微调(专项学):针对具体任务(如翻译、问答),用 Transformer 的结构快速适配
比如做问答时,给 BERT 文章和问题,它会用注意力机制定位答案在哪;做情感分析时,会让 “好”“棒” 这些词重点 “影响” 正面判断。
4、详解代码和实验结果
数据集见资源绑定
4.1、加载数据集
"""查看数据集是否加载成功"""df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])print(df.shape)print(df.sample(10))
4.2、准备预训练环境
#创建句子、标注列表以及添加[CLS]和[SEP]词元sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences] #for sentence in sentences的作用是遍历所有原始句子,为每个句子添加上 BERT 模型所需的特殊标记,从而让处理后的句子符合 BERT 模型的输入格式要求。labels = df.label.values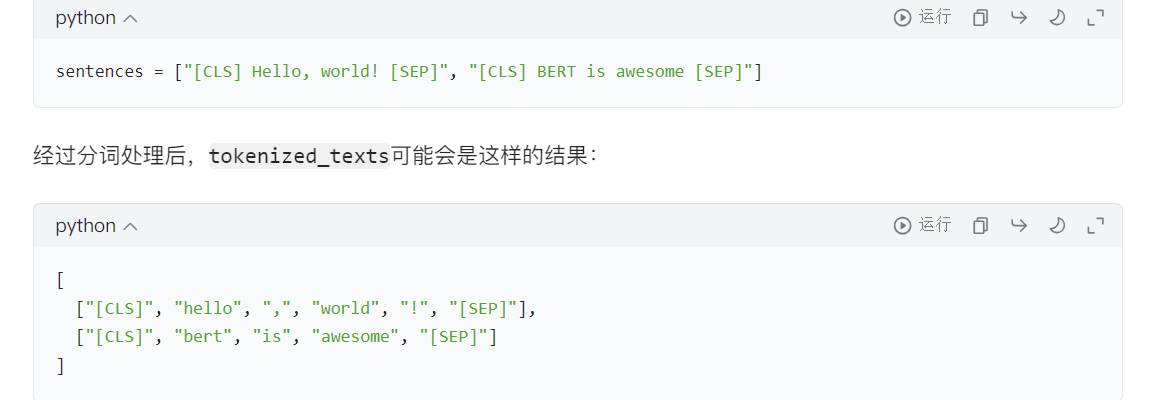
4.3、激活词元分析器
# 加载BERT分词器# BertTokenizer:它是 Hugging Face Transformers 库中的一个类,专门用于处理 BERT 模型的分词工作。# from_pretrained:这是一个类方法,能够加载预训练的分词器配置和词汇表。# 'bert-base-uncased':这里指定了要加载的预训练模型的名称。bert-base-uncased表示基础版本的 BERT 模型,并且该模型使用的是小写文本。# do_lower_case=True:此参数表明在分词之前,需要先将所有文本转换为小写形式。这与bert-base-uncased模型的要求是相符的。tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)# 对文本进行分词处理# tokenizer.tokenize(sent):该方法会把输入的句子sent分割成 BERT 模型能够识别的词元(tokens)。# for sent in sentences:遍历sentences列表中的每一个句子。# tokenized_texts:最终得到的结果是一个二维列表,列表的每个元素代表一个句子分词后得到的词元列表。tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]print("Tokenize the first sentence:")print(tokenized_texts[0])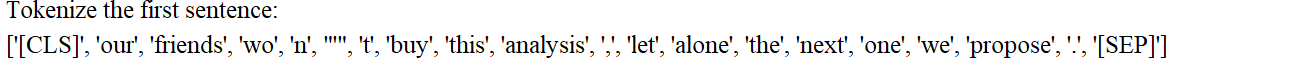
4.4、处理数据
MAX_LEN = 128 #设置了输入序列的最大长度为 128 个词元(tokens)# 将词元转换为 IDinput_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]# 对序列进行填充和截断,使所有序列的长度保持一致# maxlen=MAX_LEN:把所有序列的长度统一调整为 128。# dtype="long":将输出的数据类型设置为长整型(对应 PyTorch 中的torch.long)。# truncating="post":如果某个序列的长度超过 128,就从序列的尾部进行截断。# padding="post":如果某个序列的长度不足 128,就在序列的尾部填充 0input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")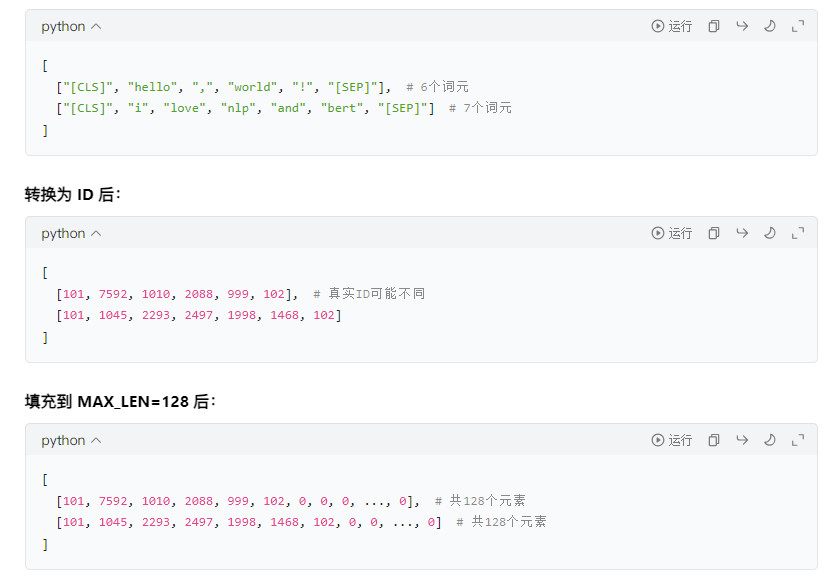
4.5、防止模型对填充词元进行注意力计算
# 初始化注意力掩码列表attention_masks = []# 遍历每个序列(句子)for seq in input_ids:# 生成单个句子的掩码# 这是一个列表推导式,作用是将seq中的每个 ID 转换为掩码值:# 若 IDi > 0(表示真实词元,如[CLS]、[SEP]或普通词元),则转换为1.0(有效)。# 若 IDi = 0(表示填充的[PAD]标记),则转换为0.0(无效)。# 结果seq_mask是一个与seq长度相同的列表,例如[1.0, 1.0, 0.0, 0.0, ..., 0.0]。seq_mask = [float(i > 0) for i in seq]# 保存掩码到列表attention_masks.append(seq_mask)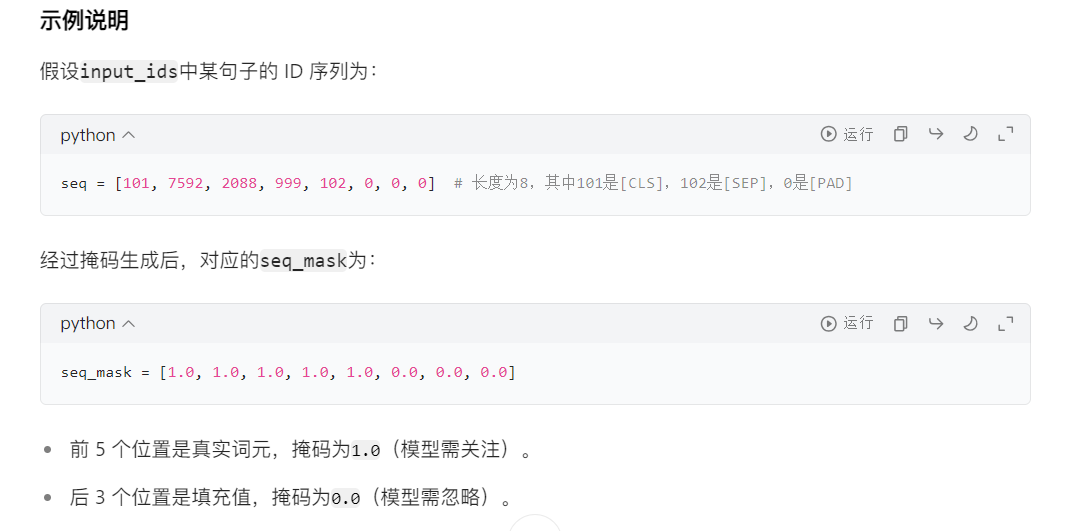
4.6、拆分数据为训练集和测试集
# 划分输入 ID 和标签# 参数说明:# input_ids:经过填充处理的输入词元 ID(形状:[样本数, MAX_LEN])# labels:对应的标签(如情感分类的 0/1 标签)# random_state=2018:随机种子,确保每次划分结果一致(可复现)# test_size=0.1:验证集占比 10%(训练集占 90%)# 返回值:# train_inputs:训练集的输入 ID# validation_inputs:验证集的输入 ID# train_labels:训练集的标签# validation_labels:验证集的标签train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,random_state=2018,test_size=0.1)# 划分注意力掩码train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,random_state=2018, test_size=0.1)4.7、将所有数据转换为torch张量
# 转换训练集和验证集的输入 IDtrain_inputs = torch.tensor(train_inputs)validation_inputs = torch.tensor(validation_inputs)# 转换训练集和验证集的标签train_labels = torch.tensor(train_labels)validation_labels = torch.tensor(validation_labels)# 转换训练集和验证集的注意力掩码train_masks = torch.tensor(train_masks)validation_masks = torch.tensor(validation_masks)4.8、选择批量大小并创建迭代器
# 预处理后的张量数据封装成 PyTorch 的DataLoader,方便按批次加载数据进行模型训练和验证# 批次大小# 为何需要批次训练:# 减少内存占用:若一次性输入所有样本(如 10000 个),可能超出 GPU/CPU 内存。# 加速训练:批次计算可利用矩阵运算并行性,比单样本逐个训练更快。# 稳定梯度:批次梯度是单样本梯度的平均值,可减少梯度波动,使训练更稳定。batch_size = 32# 数据集封装train_data = TensorDataset(train_inputs, train_masks, train_labels)validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)# 采样器(Sampler):控制数据加载顺序train_sampler = RandomSampler(train_data) #随机打乱样本顺序validation_sampler = SequentialSampler(validation_data) #按原始顺序读取样本# 数据加载器(DataLoader)# 按批次从数据集中读取样本,支持多线程加速train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)4.9、BERT模型配置
# 创建 BERT 配置对象configuration = BertConfig()# 根据配置初始化 BERT 模型model = BertModel(configuration)# 获取模型的配置信息configuration = model.config# 打印配置信息print(configuration)BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.26.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
关键配置参数说明
打印出的配置信息中,核心参数及其含义如下:
| 参数名称 | 含义说明 |
|---|---|
hidden_size | 隐藏层维度,默认 768(bert-base),bert-large为 1024。 |
num_hidden_layers | 隐藏层数量,默认 12(bert-base),bert-large为 24。 |
num_attention_heads | 注意力头数量,默认 12(bert-base),bert-large为 16,影响并行注意力能力。 |
intermediate_size | 前馈神经网络中间层维度,默认 3072(bert-base),bert-large为 4096。 |
hidden_act | 激活函数,默认gelu(高斯误差线性单元),是 BERT 的标准激活函数。 |
hidden_dropout_prob | 隐藏层 dropout 概率,默认 0.1,用于防止过拟合。 |
attention_probs_dropout_prob | 注意力层 dropout 概率,默认 0.1,增强注意力机制的稳健性。 |
vocab_size | 词表大小,默认 30522(bert-base-uncased的词表规模)。 |
max_position_embeddings | 最大序列长度,默认 512,超过此长度的文本会被截断。 |
4.10、加载Hugging Face BERT uncased base模型
# 确定计算设备(CPU/GPU)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载适用于分类任务的 BERT 模型# BertForSequenceClassification:Hugging Face 提供的 BERT 变体模型,专为序列分类任务设计(如情感分析、文本分类等)。# 基础结构:在 BERT 编码器(BertModel)的输出层后,添加了一个分类头(全连接层 + 激活函数),用于输出分类概率。# from_pretrained("bert-base-uncased"):# 从 Hugging Face 仓库加载预训练权重,使用的是bert-base-uncased模型(基础版、小写处理的 BERT)。# 预训练权重包含 BERT 编码器的参数,分类头的参数会随机初始化(需通过微调训练)。# num_labels=2:指定分类任务的类别数为 2(二分类任务,如 “正面 / 负面”“正确 / 错误”)。若为多分类,需修改此参数(如num_labels=3)。model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)# 配置多 GPU 并行计算model = nn.DataParallel(model)# 将模型转移到指定设备model.to(device)4.11、优化器分组参数
# 获取模型所有参数及其名称# 将模型参数分为两组,一组应用权重衰减(0.1),另一组不应用(0.0),以提高模型泛化能力param_optimizer = list(model.named_parameters())# 定义不应用权重衰减的参数类型# 这是一个列表,指定了两种不需要应用权重衰减的参数:# 'bias':所有偏置参数(参数名称中包含bias)。# 'LayerNorm.weight':LayerNorm 层的权重参数(参数名称中包含LayerNorm.weight)。no_decay = ['bias', 'LayerNorm.weight']# 分组参数并设置权重衰减率optimizer_grouped_parameters = [# 第一组:应用权重衰减(0.1){'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay_rate': 0.1},# 第二组:不应用权重衰减(0.0){'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay_rate': 0.0}]4.12、训练循环的超参数
# 设置训练轮次(epochs)# 为何设置为4?:BERT等预训练模型微调时,通常不需要太多轮次(2 - 10轮),# 过多可能导致过拟合(在训练集表现好,验证集差)。具体需根据任务调整,# 可通过验证集性能判断是否需要增加。epochs = 4# 初始化优化器(AdamW)optimizer = AdamW(optimizer_grouped_parameters,lr=2e-5,eps=1e-8)# 计算总训练步数# 训练数据加载器的批次数量(每轮训练的步数)total_steps = len(train_dataloader) * epochs# 配置学习率调度器scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps)关键参数说明:
| 参数 | 含义 | 为何这样设置? |
|---|---|---|
optimizer_grouped_parameters | 前文定义的参数分组(含权重衰减策略) | 确保不同参数按分组应用权重衰减,提升训练稳定性 |
lr=2e-5 | 初始学习率(2×10⁻⁵) | BERT 微调的经验值:预训练模型参数已较优,需用小学习率避免破坏已有特征,通常在 1e-5~5e-5 之间 |
eps=1e-8 | 数值稳定性参数(防止除以零) | 避免训练中因梯度或参数过小导致的数值 |
# 用于计算分类任务准确率的函数 flat_accuracy,它将模型预测结果与真实标签进行比较,返回预测正确的样本比例
def flat_accuracy(preds, labels):# 获取预测的类别索引pred_flat = np.argmax(preds, axis=1).flatten()# 展平真实标签labels_flat = labels.flatten()# 计算准确率return np.sum(pred_flat == labels_flat) / len(labels_flat)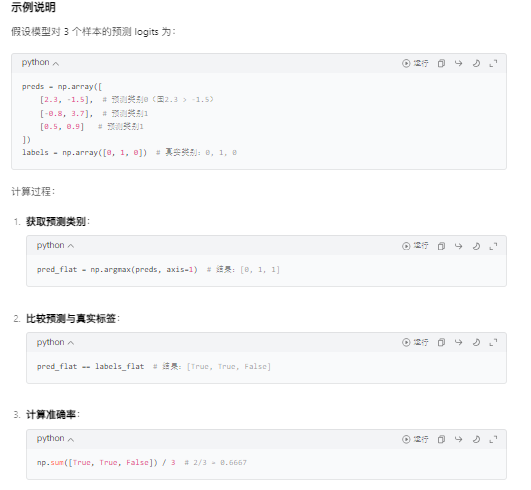
4.13、训练循环
#初始化跟踪变量t = [] # 存储训练过程中的时间戳或其他监控数据train_loss_set = []#记录每个批次的训练损失#外层循环:控制训练轮次(Epochs)for _ in trange(epochs, desc="Epoch"):#训练阶段model.train()# 开启训练模式(启用dropout等)tr_loss = 0 # 累积训练损失nb_tr_examples, nb_tr_steps = 0, 0 # 样本数和步数计数器#内层循环:批次处理流程for step, batch in enumerate(train_dataloader):#数据准备# 将批次数据转移到 GPU/CPUbatch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向传播optimizer.zero_grad() # 清除上一步的梯度outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)loss = outputs['loss'] # 获取损失值train_loss_set.append(loss.item())# 记录当前批次损失#反向传播与优化loss.backward()# 计算梯度optimizer.step()# 更新参数scheduler.step()# 更新学习率#统计训练指标tr_loss += loss.item()nb_tr_examples += b_input_ids.size(0) # 累积样本数nb_tr_steps += 1 # 累积步数print("Train loss: {}".format(tr_loss / nb_tr_steps))# 验证阶段model.eval()# 开启评估模式(禁用dropout等)#数据准备eval_loss, eval_accuracy = 0, 0nb_eval_steps, nb_eval_examples = 0, 0for batch in validation_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向传播(不计算梯度)with torch.no_grad():# 不计算梯度,节省内存和计算资源logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)#计算验证准确率logits = logits['logits'].detach().cpu().numpy()# 转为NumPy数组label_ids = b_labels.to('cpu').numpy()tmp_eval_accuracy = flat_accuracy(logits, label_ids) # 使用前文定义的准确率函数eval_accuracy += tmp_eval_accuracynb_eval_steps += 1print("Validation Accuracy: {}".format(eval_accuracy / nb_eval_steps))训练循环的关键细节
4.13.1、 模式切换
model.train():启用训练模式,激活 dropout 和 batch normalization 等训练专用机制。model.eval():启用评估模式,禁用 dropout 等,确保结果可复现。
4.13.2、 梯度清零
optimizer.zero_grad():清除上一步的梯度(PyTorch 默认累积梯度,需手动清零)。
4.13.3、 内存优化
with torch.no_grad():验证阶段不计算梯度,大幅减少内存占用。.detach().cpu().numpy():将张量从 GPU 移到 CPU 并转为 NumPy 数组,释放 GPU 内存。
4.13.4、 学习率调度
scheduler.step():每更新一次参数,学习率按线性策略衰减,有助于模型稳定收敛。
训练过程示例
假设训练集有 900 个样本,batch_size=32,epochs=4,则:
- 每轮训练步数:
900 ÷ 32 ≈ 29(向上取整)。 - 总训练步数:
29 × 4 = 116。 - 学习率从
2e-5开始,每步线性衰减,最终降至 0。
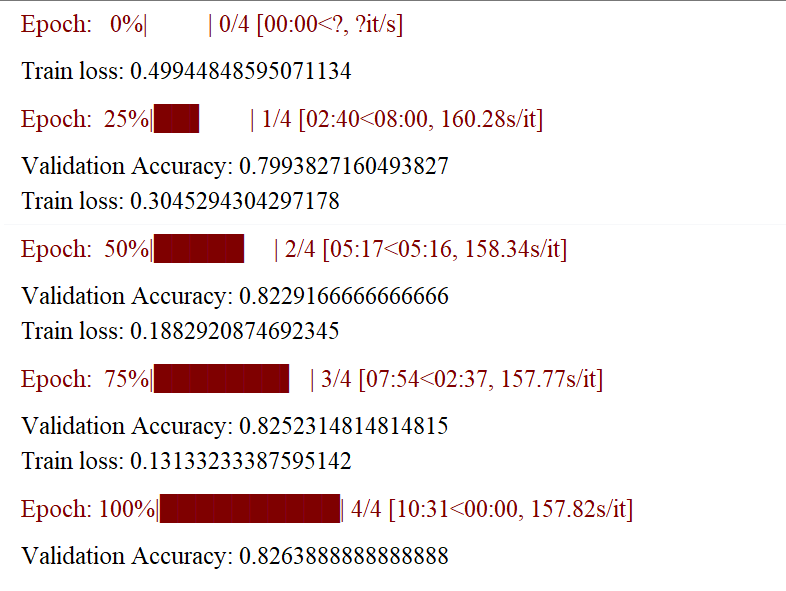
4.14、对训练进行评估
plt.figure(figsize=(15,8))
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.plot(train_loss_set)
plt.show()
4.15、采用测试数据集进行预测和评估
4.15.1、数据准备
"""数据准备"""# 读取数据df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]labels = df.label.values# 分词处理tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]# 转换为 ID 并填充MAX_LEN = 128input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")# 创建注意力掩码attention_masks = []for seq in input_ids:seq_mask = [float(i > 0) for i in seq]attention_masks.append(seq_mask)# 转换为 PyTorch 张量prediction_inputs = torch.tensor(input_ids)prediction_masks = torch.tensor(attention_masks)prediction_labels = torch.tensor(labels)# 创建数据加载器batch_size = 32prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)prediction_sampler = SequentialSampler(prediction_data)prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)4.15.2、预测阶段
# 切换模型为评估模式model.eval()# 初始化跟踪变量predictions, true_labels = [], []# 预测循环 批量预测for batch in prediction_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch# 无梯度计算的前向传播with torch.no_grad():logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)# 结果处理# 将logits和预测标注从GPU移到CPUlogits = logits['logits'].detach().cpu().numpy()label_ids = b_labels.to('cpu').numpy()predictions.append(logits) #存储模型预测的 logits(原始分数)true_labels.append(label_ids)#存储对应的真实标签4.16、使用马修斯相关系数进行评估
4.16.1、什么是 MCC?
Matthews 相关系数(Matthews Correlation Coefficient,简称 MCC) 是衡量二分类或多分类模型预测结果与实际标签相关性的指标,取值范围为 [-1, 1]:
- 1 表示预测完全正确;
- 0 表示预测结果与随机猜测无异;
- -1 表示预测完全错误。
MCC 的优势在于对不平衡数据不敏感,即使正负样本比例悬殊,也能客观反映模型性能,因此在医疗诊断、欺诈检测等领域尤为常用。
4.16.2、MCC 的计算公式
MCC 的计算基于混淆矩阵的四个核心指标:
- 真阳性(TP):实际为正例且被正确预测为正例的样本数;
- 真阴性(TN):实际为负例且被正确预测为负例的样本数;
- 假阳性(FP):实际为负例但被错误预测为正例的样本数;
- 假阴性(FN):实际为正例但被错误预测为负例的样本数。
公式如下:
4.16.3、公式解析与适用场景
为更直观理解 MCC 的计算逻辑,可结合其与其他指标的对比:
| 指标 | 计算公式 | 特点 | 适用场景 |
|---|---|---|---|
| MCC | 综合考虑所有混淆矩阵元素,抗不平衡性强 | 不平衡数据集、二分类 / 多分类 | |
| 准确率(Accuracy) | 易受不平衡数据影响 | 平衡数据集 | |
| F1 分数 | 聚焦正例的精确率和召回率平衡 | 关注正例识别的场景 |
- 当数据平衡时,MCC 与准确率、F1 分数可能趋势一致;
- 当数据不平衡(如正例占比 1%),准确率可能因 “全预测为负例” 而高达 99%,但 MCC 会接近 0,更真实反映模型无效。
4.16.4、如何计算 MCC?
在实际应用中,可直接调用工具库计算:
- Python 的
sklearn库:from sklearn.metrics import matthews_corrcoef,输入真实标签和预测标签即可。
from sklearn.metrics import matthews_corrcoef
y_true = [1, 0, 1, 1, 0]
y_pred = [1, 0, 1, 0, 0]
print(matthews_corrcoef(y_true, y_pred)) # 输出约0.63
4.16.5、详细代码
"""使用马修斯相关系数进行评估"""# 初始化结果列表# 包含每一批次数据的 MCC 值。matthews_set = []# 遍历每一批次数据for i in range(len(true_labels)):# 计算当前批次的 MCC# true_labels[i]:当前批次的真实标签(一维数组)。# np.argmax(predictions[i], axis=1).flatten():# np.argmax(predictions[i], axis=1):从预测 logits 中获取最大分数对应的类别索引(即预测类别)。# .flatten():确保结果是一维数组(与真实标签形状一致)。# matthews_corrcoef MCCmatthews = matthews_corrcoef(true_labels[i], np.argmax(predictions[i], axis=1).flatten())# 存储结果matthews_set.append(matthews)print(matthews_set)[0.049286405809014416,
-0.29012942659282975,
0.4040950971038548,
0.41179801403140964,
0.44440090347500916,
0.6777932975034471,
0.37084202772044256,
0.47519096331149147,
0.8320502943378436,
0.7530836820370708,
0.7679476477883045,
0.7419408268023742,
0.8150678894028793,
0.7141684885491869,
0.3268228676411533,
0.6625413488689132,
0.0]
4.17、整个数据集的马修斯评估
"""整个数据集的马修斯评估"""flat_predictions = [item for sublist in predictions for item in sublist]flat_predictions = np.argmax(flat_predictions, axis=1).flatten()flat_true_labels = [item for sublist in true_labels for item in sublist]print(matthews_corrcoef(flat_true_labels, flat_predictions))![]()
5、完整版代码
"""
文件名: BERT+Transformer
作者: 墨尘
日期: 2025/7/27
项目名: llm_finetune
备注:
"""
import os
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0' # 禁用 oneDNN 优化
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 使用国内镜像
from transformers import BertTokenizer
import tensorflow as tf
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
#March 2023 update
#from keras.preprocessing.sequence import pad_sequences
# from tensorflow.keras.utils import pad_sequences
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from transformers import BertModel,BertTokenizer, BertConfig
from torch.optim import AdamW
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup
from tqdm import tqdm, trange
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests
from sklearn.metrics import matthews_corrcoef
# 用于计算分类任务准确率的函数 flat_accuracy,它将模型预测结果与真实标签进行比较,返回预测正确的样本比例
def flat_accuracy(preds, labels):# 获取预测的类别索引pred_flat = np.argmax(preds, axis=1).flatten()# 展平真实标签labels_flat = labels.flatten()# 计算准确率return np.sum(pred_flat == labels_flat) / len(labels_flat)if __name__ == '__main__':"""查看数据集是否加载成功"""df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])print(df.shape)print(df.sample(10))"""准备预训练环境"""#创建句子、标注列表以及添加[CLS]和[SEP]词元sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences] #for sentence in sentences的作用是遍历所有原始句子,为每个句子添加上 BERT 模型所需的特殊标记,从而让处理后的句子符合 BERT 模型的输入格式要求。labels = df.label.values"""激活词元分析器"""# 加载BERT分词器# BertTokenizer:它是 Hugging Face Transformers 库中的一个类,专门用于处理 BERT 模型的分词工作。# from_pretrained:这是一个类方法,能够加载预训练的分词器配置和词汇表。# 'bert-base-uncased':这里指定了要加载的预训练模型的名称。bert-base-uncased表示基础版本的 BERT 模型,并且该模型使用的是小写文本。# do_lower_case=True:此参数表明在分词之前,需要先将所有文本转换为小写形式。这与bert-base-uncased模型的要求是相符的。tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)# 对文本进行分词处理# tokenizer.tokenize(sent):该方法会把输入的句子sent分割成 BERT 模型能够识别的词元(tokens)。# for sent in sentences:遍历sentences列表中的每一个句子。# tokenized_texts:最终得到的结果是一个二维列表,列表的每个元素代表一个句子分词后得到的词元列表。tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]print("Tokenize the first sentence:")print(tokenized_texts[0])"""处理数据"""MAX_LEN = 128 #设置了输入序列的最大长度为 128 个词元(tokens)# 将词元转换为 IDinput_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]# 对序列进行填充和截断,使所有序列的长度保持一致# maxlen=MAX_LEN:把所有序列的长度统一调整为 128。# dtype="long":将输出的数据类型设置为长整型(对应 PyTorch 中的torch.long)。# truncating="post":如果某个序列的长度超过 128,就从序列的尾部进行截断。# padding="post":如果某个序列的长度不足 128,就在序列的尾部填充 0input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")"""防止模型对填充词元进行注意力计算"""# 初始化注意力掩码列表attention_masks = []# 遍历每个序列(句子)for seq in input_ids:# 生成单个句子的掩码# 这是一个列表推导式,作用是将seq中的每个 ID 转换为掩码值:# 若 IDi > 0(表示真实词元,如[CLS]、[SEP]或普通词元),则转换为1.0(有效)。# 若 IDi = 0(表示填充的[PAD]标记),则转换为0.0(无效)。# 结果seq_mask是一个与seq长度相同的列表,例如[1.0, 1.0, 0.0, 0.0, ..., 0.0]。seq_mask = [float(i > 0) for i in seq]# 保存掩码到列表attention_masks.append(seq_mask)"""拆分数据为训练集和测试集"""# 划分输入 ID 和标签# 参数说明:# input_ids:经过填充处理的输入词元 ID(形状:[样本数, MAX_LEN])# labels:对应的标签(如情感分类的 0/1 标签)# random_state=2018:随机种子,确保每次划分结果一致(可复现)# test_size=0.1:验证集占比 10%(训练集占 90%)# 返回值:# train_inputs:训练集的输入 ID# validation_inputs:验证集的输入 ID# train_labels:训练集的标签# validation_labels:验证集的标签train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,random_state=2018,test_size=0.1)# 划分注意力掩码train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,random_state=2018, test_size=0.1)"""将所有数据转换为torch张量"""# 转换训练集和验证集的输入 IDtrain_inputs = torch.tensor(train_inputs)validation_inputs = torch.tensor(validation_inputs)# 转换训练集和验证集的标签train_labels = torch.tensor(train_labels)validation_labels = torch.tensor(validation_labels)# 转换训练集和验证集的注意力掩码train_masks = torch.tensor(train_masks)validation_masks = torch.tensor(validation_masks)"""选择批量大小并创建迭代器"""# 预处理后的张量数据封装成 PyTorch 的DataLoader,方便按批次加载数据进行模型训练和验证# 批次大小# 为何需要批次训练:# 减少内存占用:若一次性输入所有样本(如 10000 个),可能超出 GPU/CPU 内存。# 加速训练:批次计算可利用矩阵运算并行性,比单样本逐个训练更快。# 稳定梯度:批次梯度是单样本梯度的平均值,可减少梯度波动,使训练更稳定。batch_size = 32# 数据集封装train_data = TensorDataset(train_inputs, train_masks, train_labels)validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)# 采样器(Sampler):控制数据加载顺序train_sampler = RandomSampler(train_data) #随机打乱样本顺序validation_sampler = SequentialSampler(validation_data) #按原始顺序读取样本# 数据加载器(DataLoader)# 按批次从数据集中读取样本,支持多线程加速train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)"""BERT模型配置"""# 创建 BERT 配置对象configuration = BertConfig()# 根据配置初始化 BERT 模型model = BertModel(configuration)# 获取模型的配置信息configuration = model.config# 打印配置信息print(configuration)"""加载Hugging Face BERT uncased base模型"""# 确定计算设备(CPU/GPU)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载适用于分类任务的 BERT 模型# BertForSequenceClassification:Hugging Face 提供的 BERT 变体模型,专为序列分类任务设计(如情感分析、文本分类等)。# 基础结构:在 BERT 编码器(BertModel)的输出层后,添加了一个分类头(全连接层 + 激活函数),用于输出分类概率。# from_pretrained("bert-base-uncased"):# 从 Hugging Face 仓库加载预训练权重,使用的是bert-base-uncased模型(基础版、小写处理的 BERT)。# 预训练权重包含 BERT 编码器的参数,分类头的参数会随机初始化(需通过微调训练)。# num_labels=2:指定分类任务的类别数为 2(二分类任务,如 “正面 / 负面”“正确 / 错误”)。若为多分类,需修改此参数(如num_labels=3)。model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)# 配置多 GPU 并行计算model = nn.DataParallel(model)# 将模型转移到指定设备model.to(device)"""优化器分组参数"""# 获取模型所有参数及其名称# 将模型参数分为两组,一组应用权重衰减(0.1),另一组不应用(0.0),以提高模型泛化能力param_optimizer = list(model.named_parameters())# 定义不应用权重衰减的参数类型# 这是一个列表,指定了两种不需要应用权重衰减的参数:# 'bias':所有偏置参数(参数名称中包含bias)。# 'LayerNorm.weight':LayerNorm 层的权重参数(参数名称中包含LayerNorm.weight)。no_decay = ['bias', 'LayerNorm.weight']# 分组参数并设置权重衰减率optimizer_grouped_parameters = [# 第一组:应用权重衰减(0.1){'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay_rate': 0.1},# 第二组:不应用权重衰减(0.0){'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay_rate': 0.0}]"""训练循环的超参数"""# 设置训练轮次(epochs)# 为何设置为4?:BERT等预训练模型微调时,通常不需要太多轮次(2 - 10轮),# 过多可能导致过拟合(在训练集表现好,验证集差)。具体需根据任务调整,# 可通过验证集性能判断是否需要增加。epochs = 4# 初始化优化器(AdamW)optimizer = AdamW(optimizer_grouped_parameters,lr=2e-5,eps=1e-8)# 计算总训练步数# 训练数据加载器的批次数量(每轮训练的步数)total_steps = len(train_dataloader) * epochs# 配置学习率调度器scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps)"""训练循环"""#初始化跟踪变量t = [] # 存储训练过程中的时间戳或其他监控数据train_loss_set = []#记录每个批次的训练损失#外层循环:控制训练轮次(Epochs)for _ in trange(epochs, desc="Epoch"):#训练阶段model.train()# 开启训练模式(启用dropout等)tr_loss = 0 # 累积训练损失nb_tr_examples, nb_tr_steps = 0, 0 # 样本数和步数计数器#内层循环:批次处理流程for step, batch in enumerate(train_dataloader):#数据准备# 将批次数据转移到 GPU/CPUbatch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向传播optimizer.zero_grad() # 清除上一步的梯度outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)loss = outputs['loss'] # 获取损失值train_loss_set.append(loss.item())# 记录当前批次损失#反向传播与优化loss.backward()# 计算梯度optimizer.step()# 更新参数scheduler.step()# 更新学习率#统计训练指标tr_loss += loss.item()nb_tr_examples += b_input_ids.size(0) # 累积样本数nb_tr_steps += 1 # 累积步数print("Train loss: {}".format(tr_loss / nb_tr_steps))# 验证阶段model.eval()# 开启评估模式(禁用dropout等)#数据准备eval_loss, eval_accuracy = 0, 0nb_eval_steps, nb_eval_examples = 0, 0for batch in validation_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch#前向传播(不计算梯度)with torch.no_grad():# 不计算梯度,节省内存和计算资源logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)#计算验证准确率logits = logits['logits'].detach().cpu().numpy()# 转为NumPy数组label_ids = b_labels.to('cpu').numpy()tmp_eval_accuracy = flat_accuracy(logits, label_ids) # 使用前文定义的准确率函数eval_accuracy += tmp_eval_accuracynb_eval_steps += 1print("Validation Accuracy: {}".format(eval_accuracy / nb_eval_steps))plt.figure(figsize=(15, 8))plt.title("Training loss")plt.xlabel("Batch")plt.ylabel("Loss")plt.plot(train_loss_set)plt.show()"""采用测试数据集进行预测和评估""""""数据准备"""# 读取数据df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None,names=['sentence_source', 'label', 'label_notes', 'sentence'])sentences = df.sentence.valuessentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]labels = df.label.values# 分词处理tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]# 转换为 ID 并填充MAX_LEN = 128input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")# 创建注意力掩码attention_masks = []for seq in input_ids:seq_mask = [float(i > 0) for i in seq]attention_masks.append(seq_mask)# 转换为 PyTorch 张量prediction_inputs = torch.tensor(input_ids)prediction_masks = torch.tensor(attention_masks)prediction_labels = torch.tensor(labels)# 创建数据加载器batch_size = 32prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)prediction_sampler = SequentialSampler(prediction_data)prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)"""预测阶段"""# 切换模型为评估模式model.eval()# 初始化跟踪变量predictions, true_labels = [], []# 预测循环 批量预测for batch in prediction_dataloader:batch = tuple(t.to(device) for t in batch)b_input_ids, b_input_mask, b_labels = batch# 无梯度计算的前向传播with torch.no_grad():logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)# 结果处理# 将logits和预测标注从GPU移到CPUlogits = logits['logits'].detach().cpu().numpy()label_ids = b_labels.to('cpu').numpy()predictions.append(logits) #存储模型预测的 logits(原始分数)true_labels.append(label_ids)#存储对应的真实标签"""使用马修斯相关系数进行评估"""# 初始化结果列表# 包含每一批次数据的 MCC 值。matthews_set = []# 遍历每一批次数据for i in range(len(true_labels)):# 计算当前批次的 MCC# true_labels[i]:当前批次的真实标签(一维数组)。# np.argmax(predictions[i], axis=1).flatten():# np.argmax(predictions[i], axis=1):从预测 logits 中获取最大分数对应的类别索引(即预测类别)。# .flatten():确保结果是一维数组(与真实标签形状一致)。# matthews_corrcoef MCCmatthews = matthews_corrcoef(true_labels[i], np.argmax(predictions[i], axis=1).flatten())# 存储结果matthews_set.append(matthews)"""各批量的分数"""print(matthews_set)"""整个数据集的马修斯评估"""flat_predictions = [item for sublist in predictions for item in sublist]flat_predictions = np.argmax(flat_predictions, axis=1).flatten()flat_true_labels = [item for sublist in true_labels for item in sublist]print(matthews_corrcoef(flat_true_labels, flat_predictions))








)


--字符指针变量,数组指针变量,二维数组传参的本质,函数指针变量,函数指针数组)





流程)
