1.事务的作用
事务用于保证数据的一致性,它由一组相关的 dml (update delete insert) 语句组成,该组的 dml (update delete insert) 语句要么全部成功,要么全部失败。
如:转账就要用事务来处理,用以保证数据的一致性。
假设张三给李四转100块:
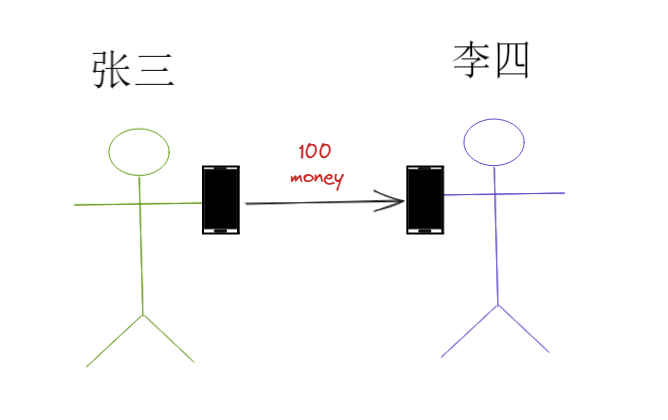
银行后台有一张简单的数据库余额表:
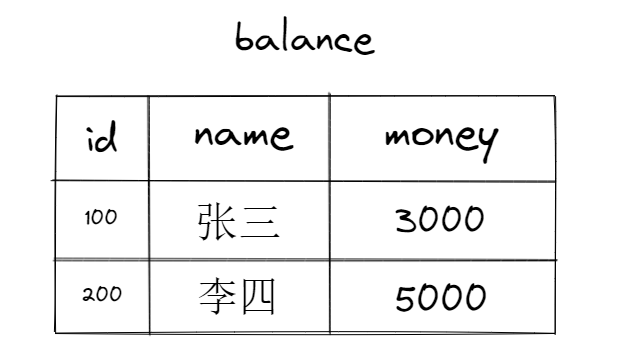
为了完成转账这件事,银行后台需要执行这两条sql语句:
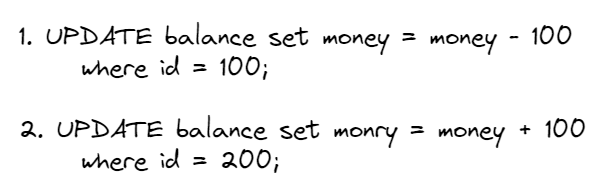
这时候就会出现三种情况:
1.第一条语句执行失败,第二条语句执行成功,结果出错;
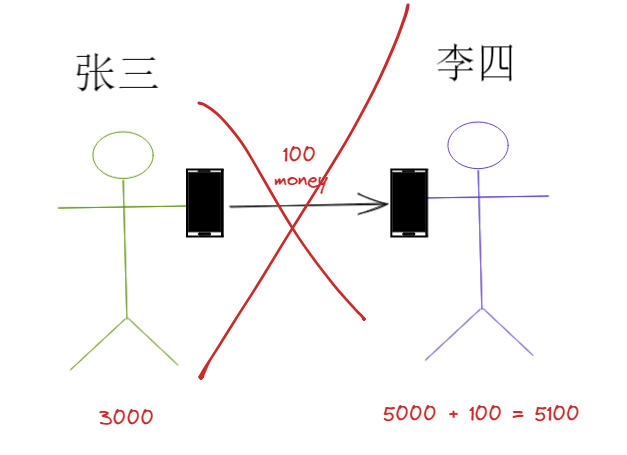
2.第一条语句执行成功,第二条语句执行失败,结果出错;
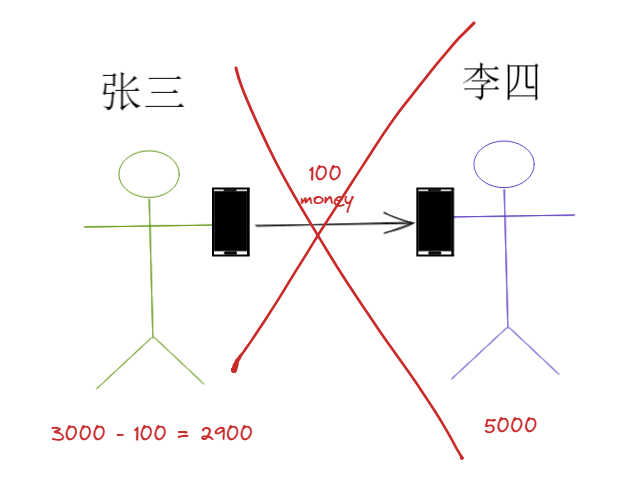
3.两条语句全部执行失败;
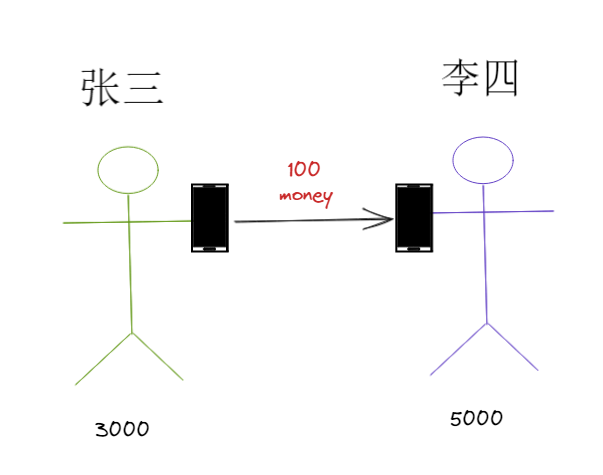
4.两条语句全部执行成功;
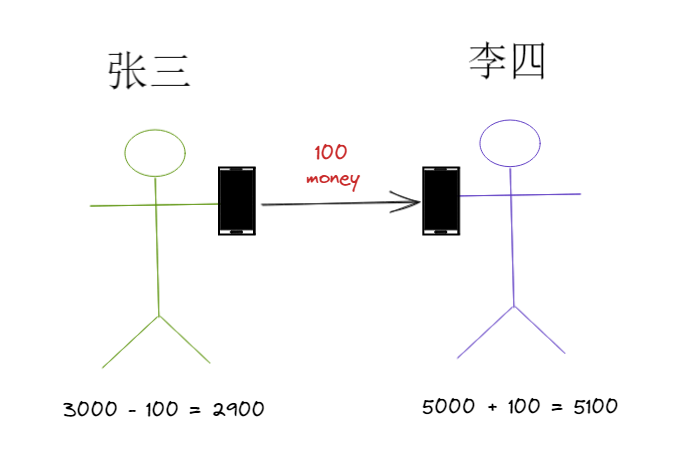
假如你是银行的话,当然会希望这两条语句要么同时失败,要么同时成功。
这就引出我们的需求:两个sql语句作为一个整体,用以保证数据的一致性。
当执行事务操作时 (dml (update delete insert) 语句) ,mysql 会在表上加锁,防止其它用户改表的数据。这对用户来讲是非常重要的。
2.事务的操作
2.1开始一个事务
基本语法:
start transaction; -- 开始一个事务2.2设置保存点
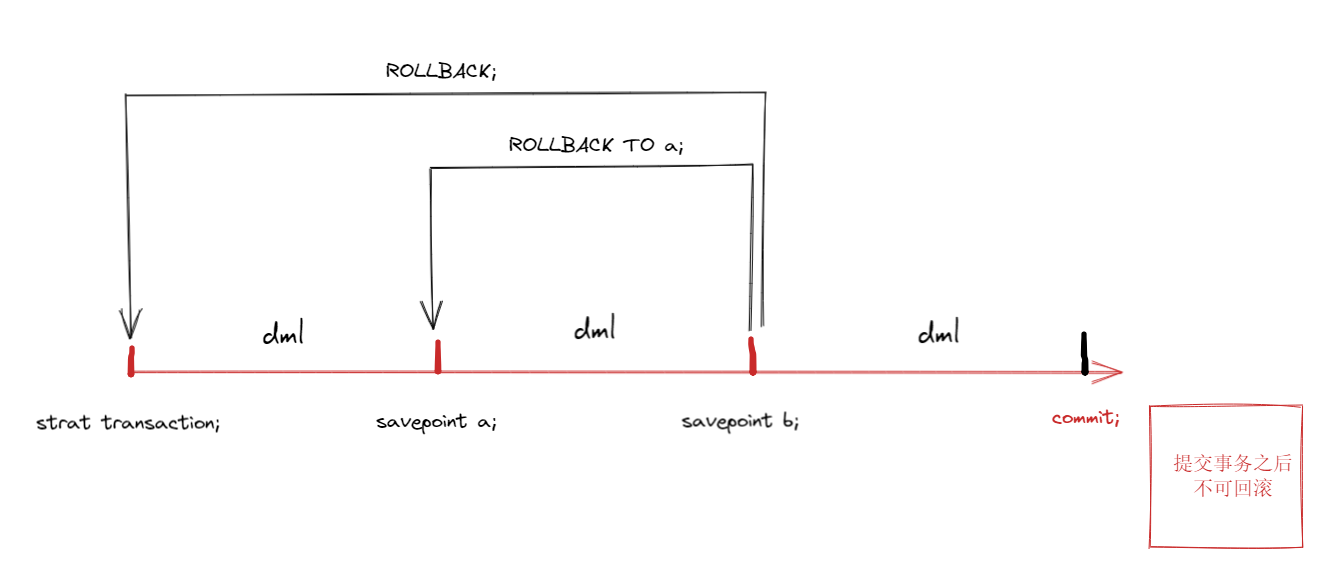
保存点 (savepoint), 保存点是事务中的点,用于取消部分事务,当结束事务时(commit),会自动的删除该事务所定义的所有保存点。
当执行回退事务时,通过指定保存点可以回退到指定的点。
基本语法:
savepoint 保存点名; -- 设置保存点2.3回退事务
基本语法:
rollback to 保存点名; -- 回退事务2.4回退全部事务
基本语法:
rollback; -- 回退全部事务2.5提交事务
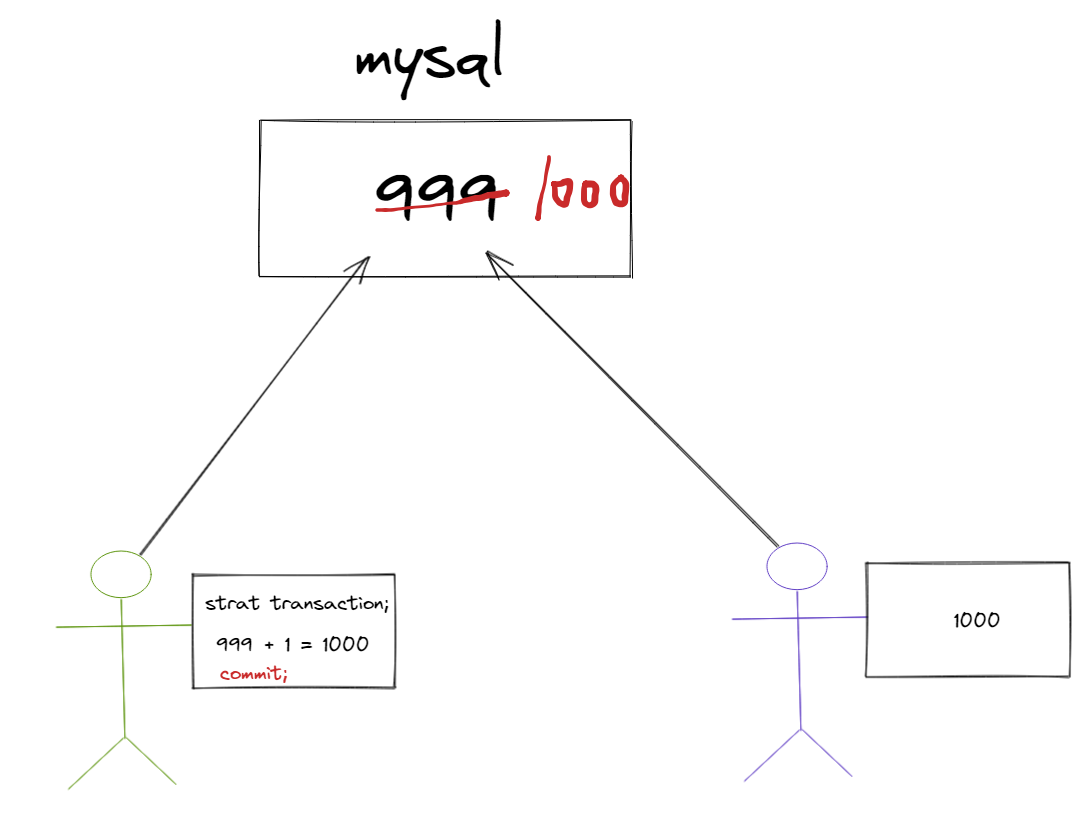
使用 commit 语句可以提交事务。当执行了 commit 语句子后,会确认事务的变化、结束事务、删除保存点、释放锁,数据生效。
当使用 commit 语句结束事务子后,其它会话【其他用户的连接】将可以查看到事务变化后的新数据。
类似于下图。而让用户2在用户1开始事务时对用户1的操作的数据不可见的功能就叫做隔离。
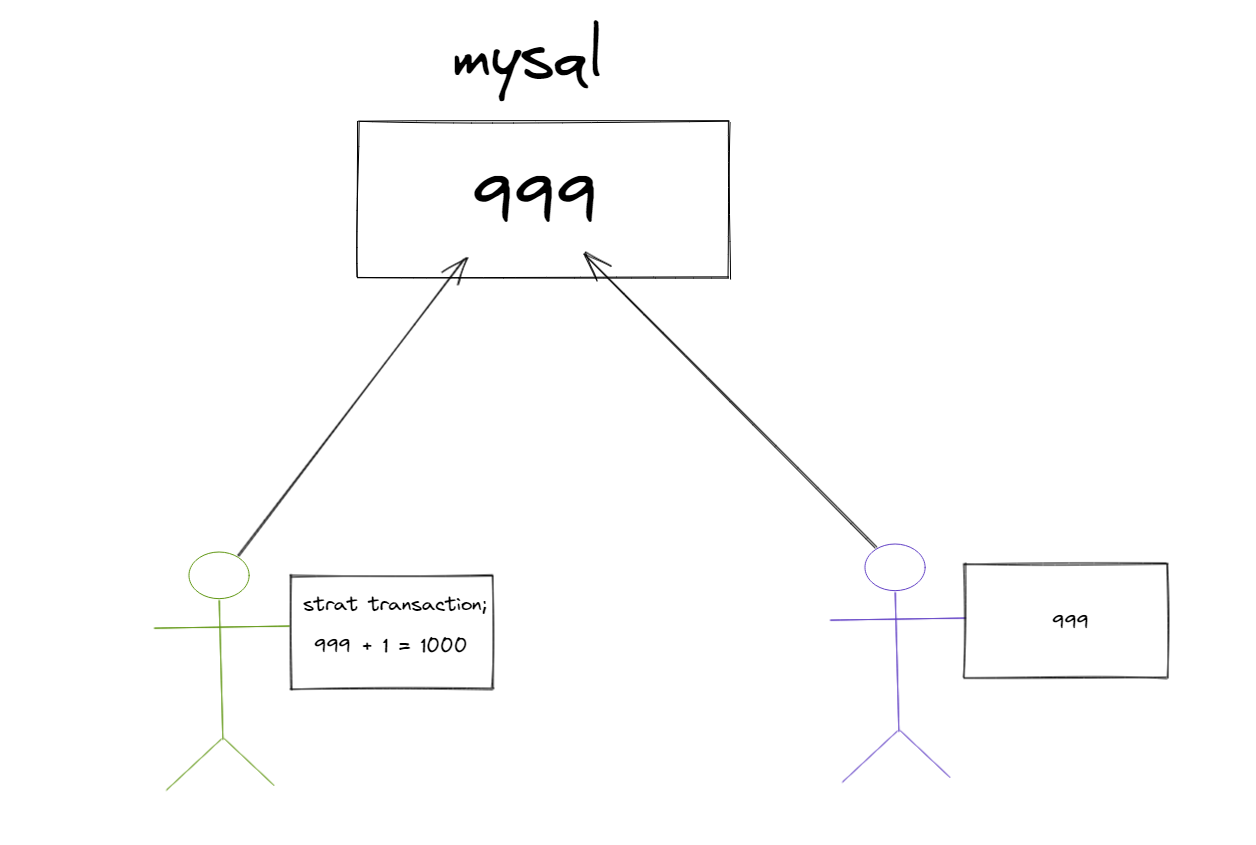
基本语法:
commit; -- 提交事务,所有的操作生效,不能回退2.6示例
先创建一个简单的表:
CREATE TABLE t03 (id INT,`name` VARCHAR(32)
);
开启一个事务:
START TRANSACTION;
插入一条数据:
insert into t03 values(1,'tom');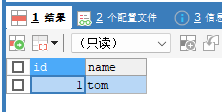
设置一个保存点:
savepoint a;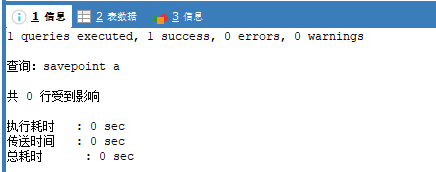
再次插入一条数据:
insert into t03 values(2,'Jack');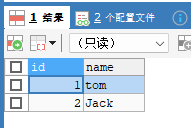
再设置一个保存点:
savepoint b;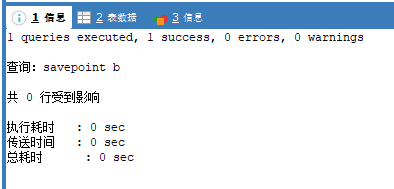
再次插入一条数据:
insert into t03 values(3,'lucy');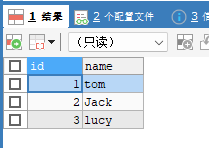
回滚到保存点a:
ROLLBACK TO a;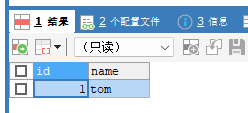
回滚全部:回到了最开始刚开启事务时的样子。
ROLLBACK;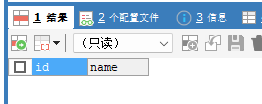
再次插入一条数据:
insert into t01 values(4,'jep');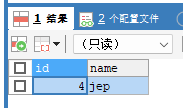
提交事务:
COMMIT;
再次回滚全部:
ROLLBACK;数据已经生效,保存点全部被删除,回滚不了了。
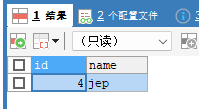
3.事务的使用细节
3.1 没有设置保存点
如果不开始事务,默认情况下,dml 操作是自动提交的,不能回滚。
如果开始一个事务,你没有创建保存点。你可以执行 rollback,默认就是回退到你事务开始的状态.
3.2 多个保存点
你也可以在这个事务中 (还没有提交时), 创建多个保存点。
比如:
savepoint aaa;
执行 dml;
savepoint bbb;
你可以在事务没有提交前,选择回退到哪个保存点。
3.3 存储引擎
mysql 的事务机制需要 innodb 的存储引擎才可以使用,myisam 不好使。
3.4 开始事务方式
开始一个事务有两种方式:
start transaction;
set autocommit=off;4.四种隔离级别
4.1隔离的基本介绍
事务隔离级别介绍:
- 多个连接开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性。(通俗解释)
- 如果不考虑隔离性,可能会引发如下问题:
➢ 脏读
➢ 不可重复读
➢ 幻读
举个例子:当MySQL同时又两个连接C1,C2
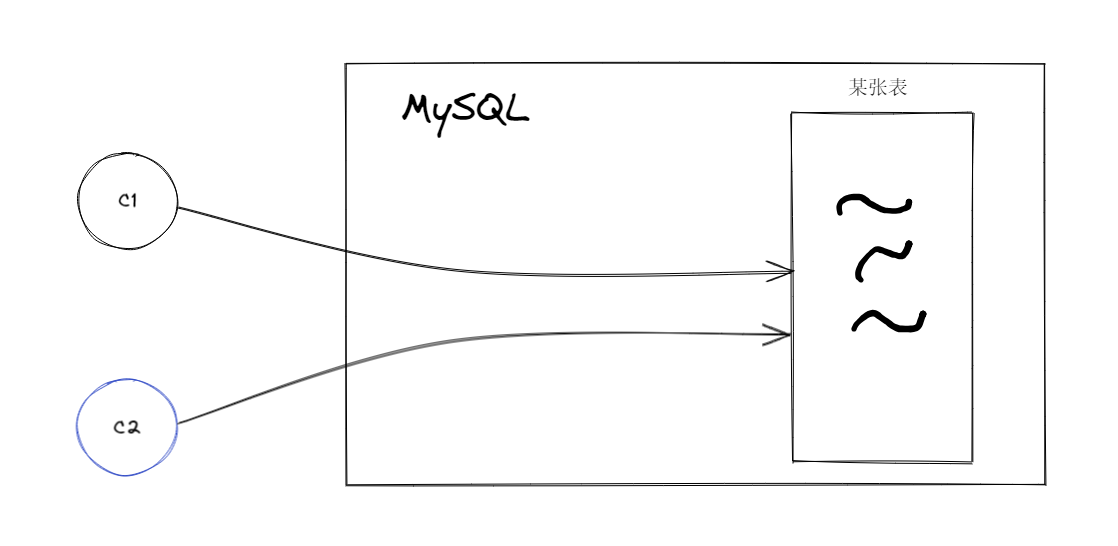
C1在对这个表进行dml操作的时候,C2再查询这张表的时候所看到的是怎样的一种数据,取决于C2的隔离级别。
4.2不做隔离引发的问题
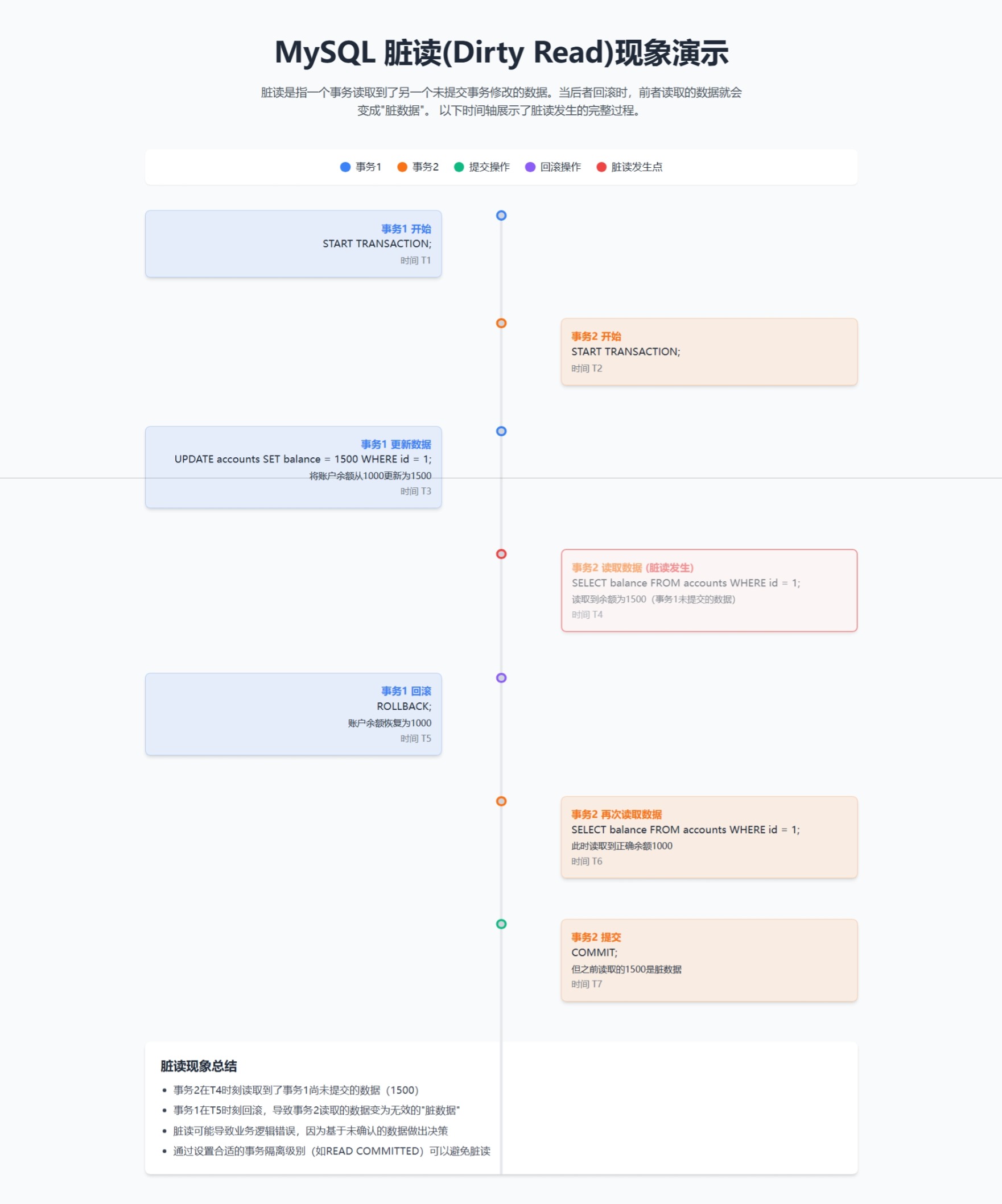
①脏读(dirty read):
当一个事务读取另一个事务尚未提交的修改时,产生脏读。
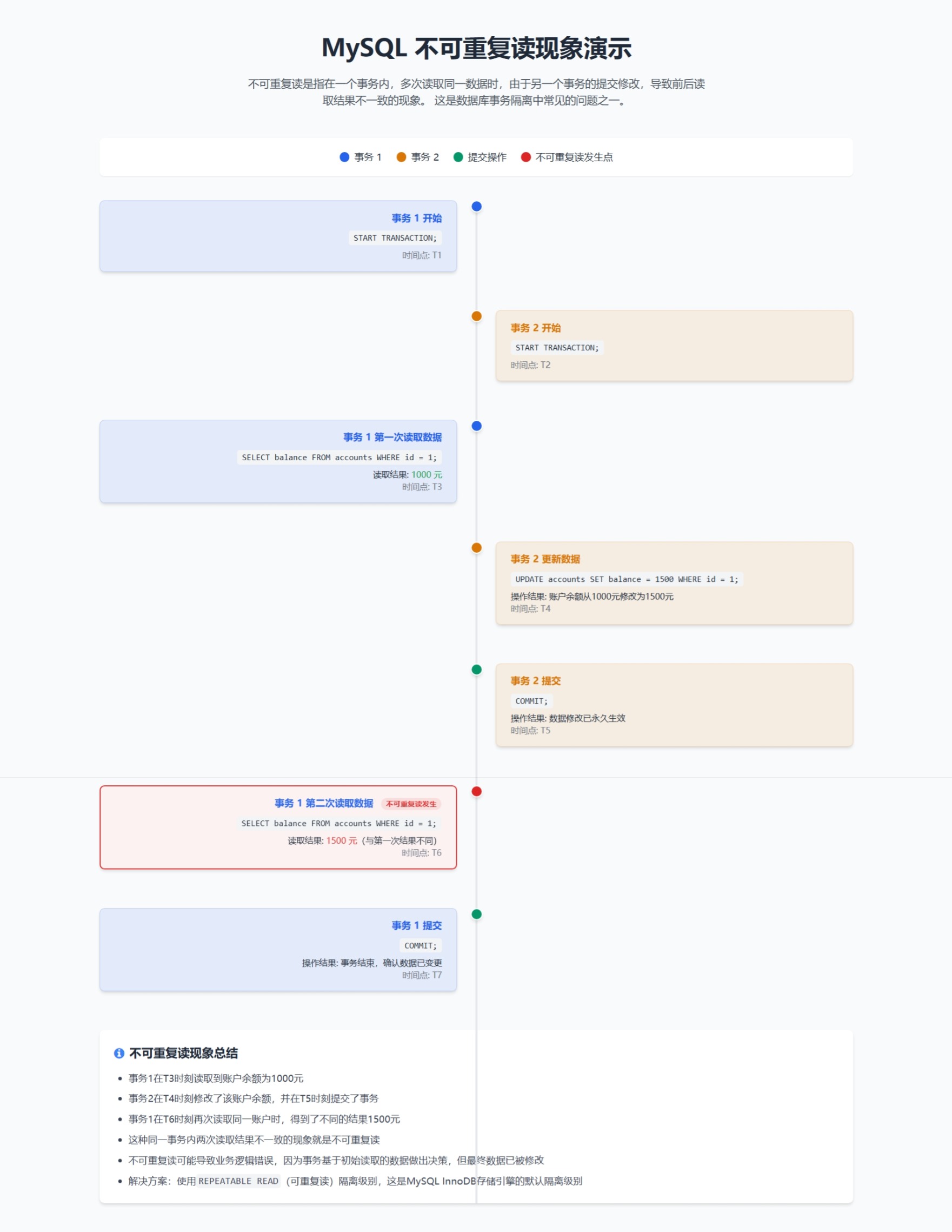
②不可重复读(nonrepeatable read):
同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生不可重复读。
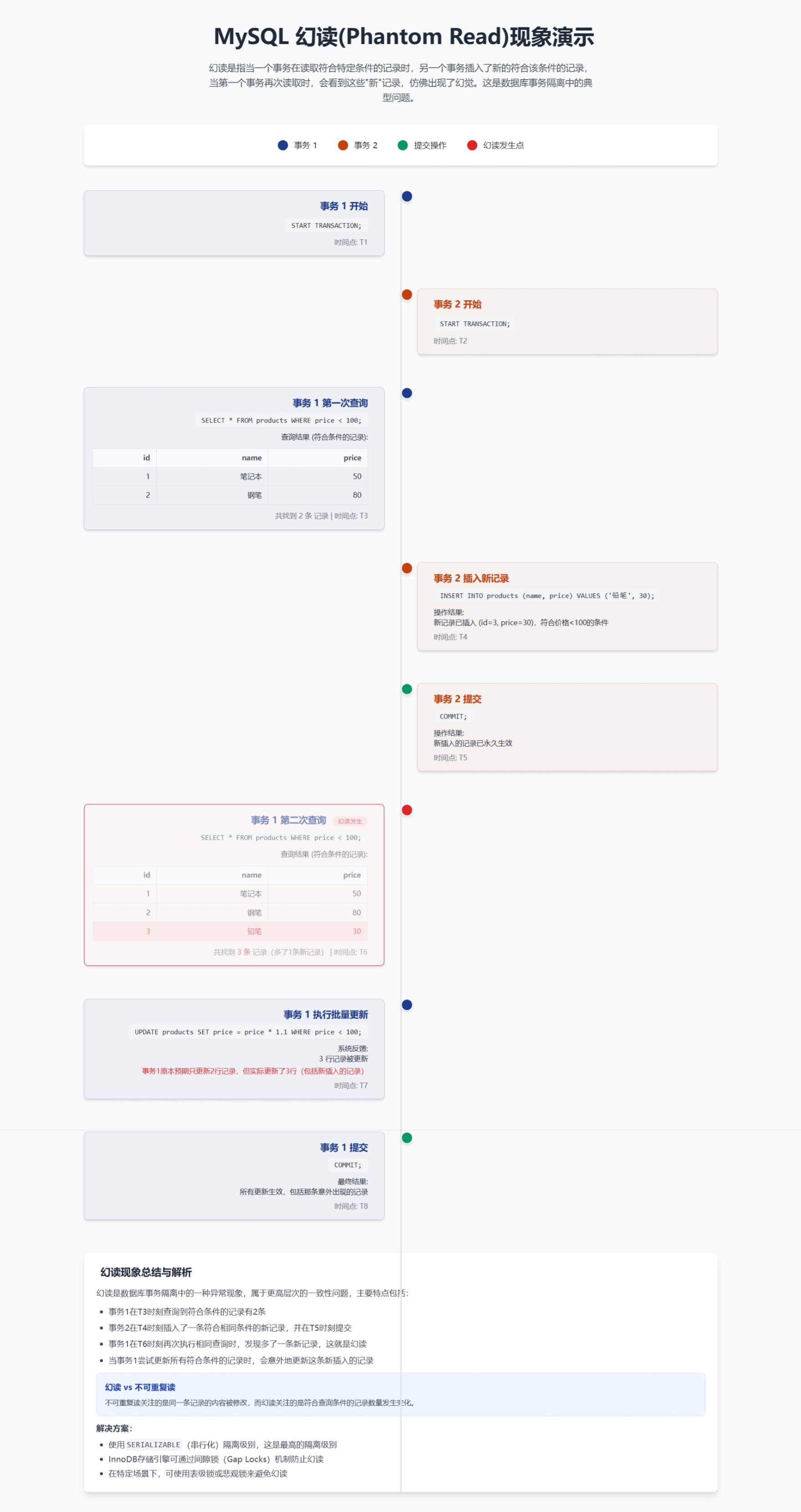
③幻读(phantom read):
同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻读。
4.3事务隔离级别
概念:Mysql隔离级别定义了事务与事务之间的隔离程度。
Mysql隔离级别(4种) | 脏读 | 不可重复读 | 幻读 | 加锁读 | 加锁写 |
读未提交(Read uncommitted) | V | V | V | 不加锁 | 加锁(排他锁) |
读已提交(Read committed) | x | V | V | 不加锁 | 加锁(排他锁) |
可重复读(Repeatable read) | x | x | x | 不加锁 | 加锁(排他锁 + 间隙锁 / 临键锁) |
可串行化(Serializable) | x | x | x | 加锁 | 加锁(排他锁) |
说明:V 可能出现 ×不会出现
4.4事务隔离级别的特性
mysql事务ACID
- 事务的acid特性
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 - 一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
- 原子性(Atomicity)
4.5事务隔离级别的设置与查看
mysql事务隔离级别
- 查看当前会话隔离级别(用户临时登录时的隔离级别)
select @@tx_isolation; - 查看系统当前隔离级别(所有用户登录时默认的隔离级别)
select @@global.tx_isolation; - 设置当前会话隔离级别
set session transaction isolation level [Read uncommitted/Read committed/repeatable read/Serializable]; - 设置系统当前隔离级别
set global transaction isolation level [Read uncommitted/Read committed/repeatable read/Serializable]; - mysql 默认的事务隔离级别是 repeatable read ,一般情况下,没有特殊要求,没有必要修改(因为该级别可以满足绝大部分项目需求)
真的想改mysql系统默认隔离级别的话:
全局修改,修改 mysql.ini 配置文件,在最后加上transaction-isolation = REPEATABLE-READ
--可选参数有:READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.之后重启mysql服务,就完成了修改。
4.6事务隔离级别的演示
①读未提交
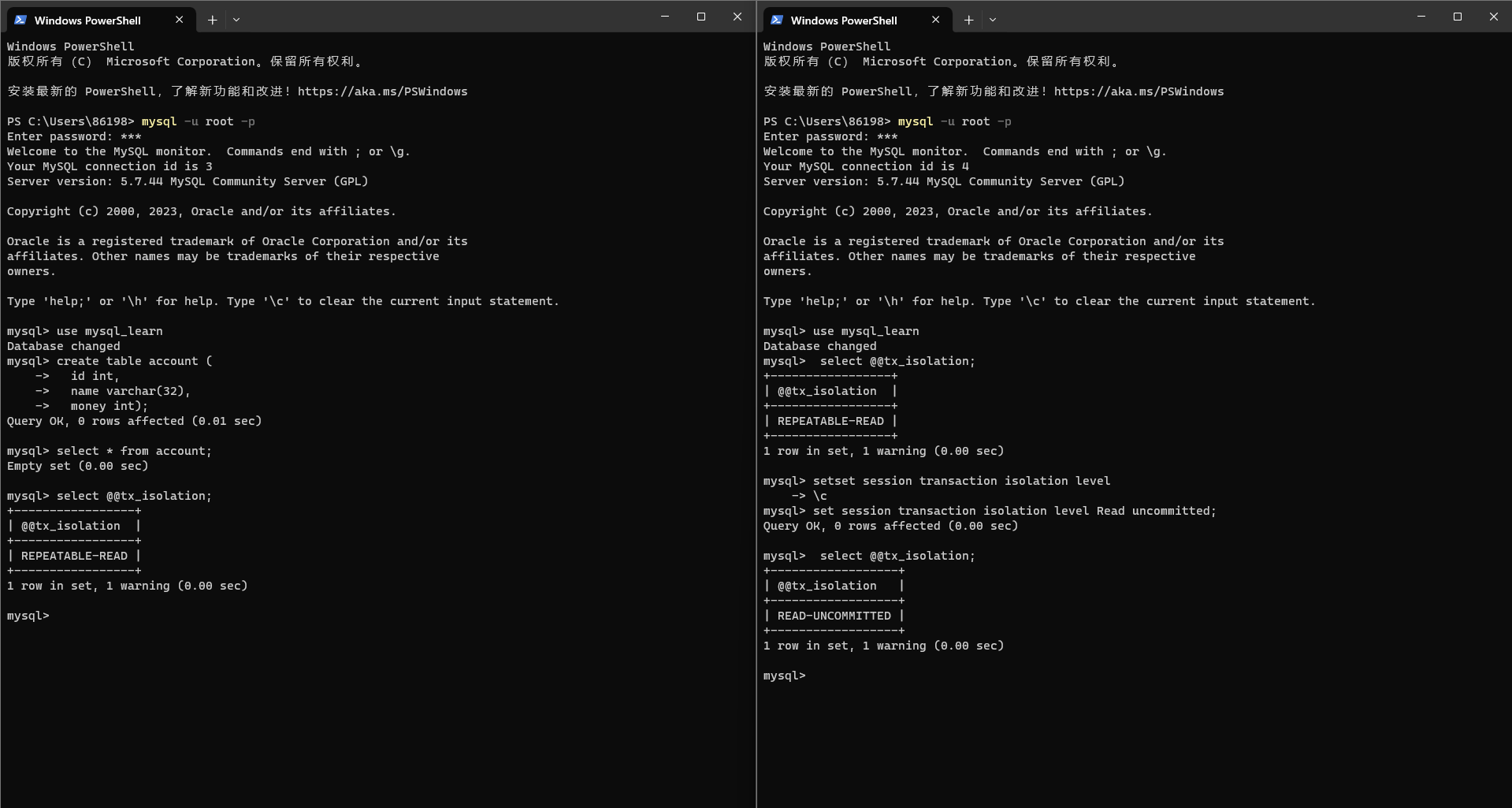
左右都开一个mysql的连接,左边我们取做连接1,右边取做连接2;
选取一个数据库:
use mysql_learn;在该数据库下创建一个表:
create table account (id int,name varchar(32),money int);查看一下两边的事务隔离级别:
select @@tx_isolation;连接1的为REPEATABLE-READ(可重复读),也就是mysql默认的事务隔离级别;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
连接2的设置为读未提交:
set session transaction isolation level Read uncommitted;再次查看一下连接2的隔离级别为READ-UNCOMMITTED(读未提交):
select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
现在我们在两个连接上同时开启事务:
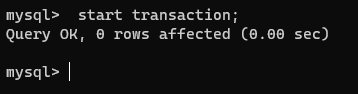
连接2的事务中查看一下该表:
![]()
我们在连接1执行几条dml语句:
insert into account values(100,'tom',3000);
insert into account values(200,'jack',5000);
update account set money = money + 100 where id = 100;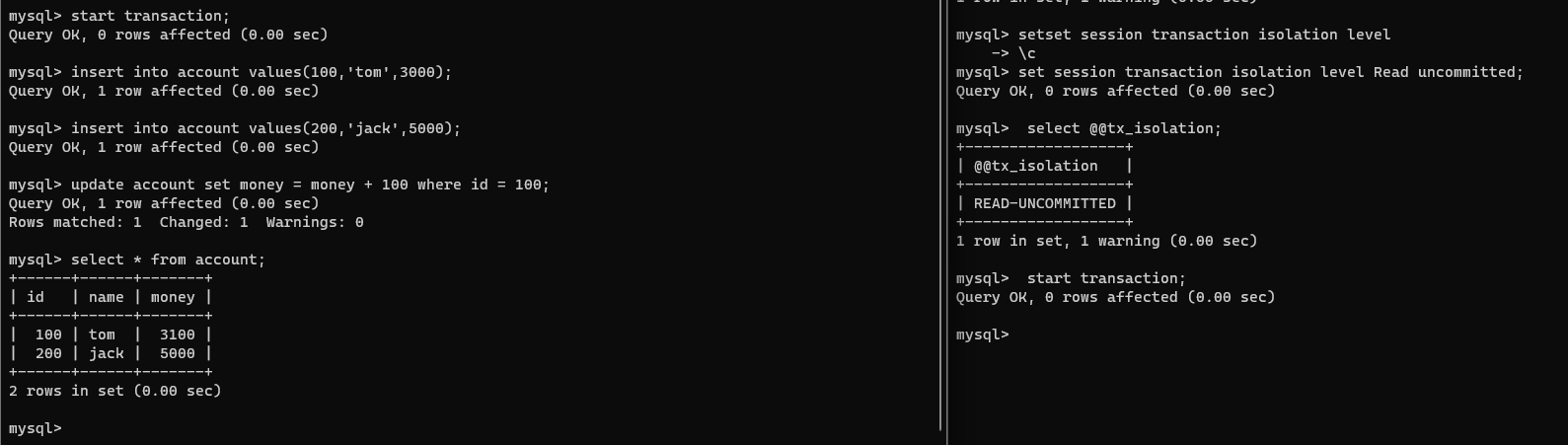
注意!我们连接1和连接2的事务都是没有提交的,但是此刻在连接2查看一下这张表:
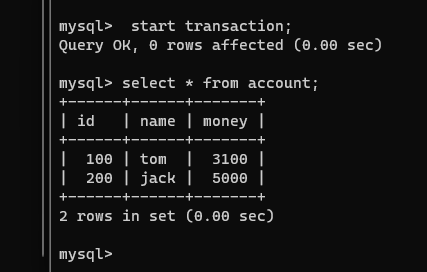
连接1提交一下事务,再在连接2查看一下这张表:
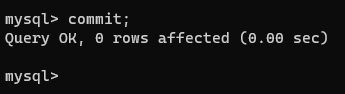
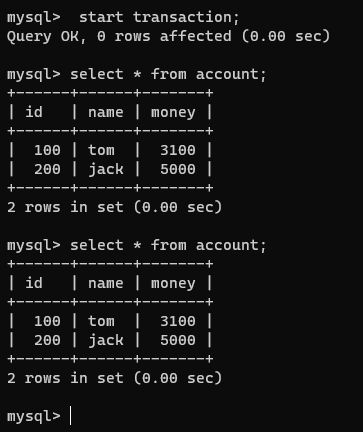
在并行的连接1和连接2中的事务中,我们会发现,在连接2中还未提交的事务中多次查看account表的结果会由于连接1中的事务中的dml操作以及事务的提交而变化。
这也就是“读未提交”这个隔离级别可能会造成赃读,不可重复读,幻读等问题。
②读已提交
将连接2的事务也提交一下(其实什么都没做,只是演示);
现在将连接2的隔离级别设置为:Read committed(读已提交);
set session transaction isolation level Read committed;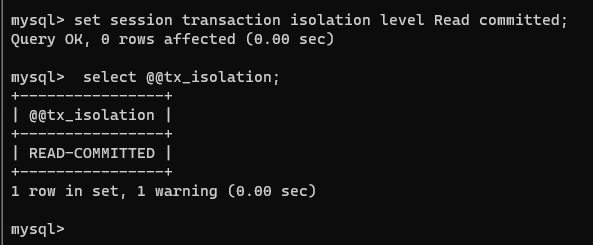
现在,将连接1和连接2中同时开启事务:

连接2的事务中查看一下该表:
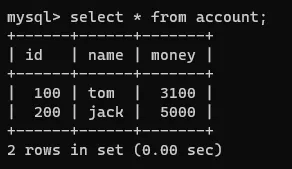
在连接1的事务中执行几句dml:
insert into account values(300,'lucy',9999);
insert into account values(400,'chen',10000);
update account set money = money + 10000 where id = 300;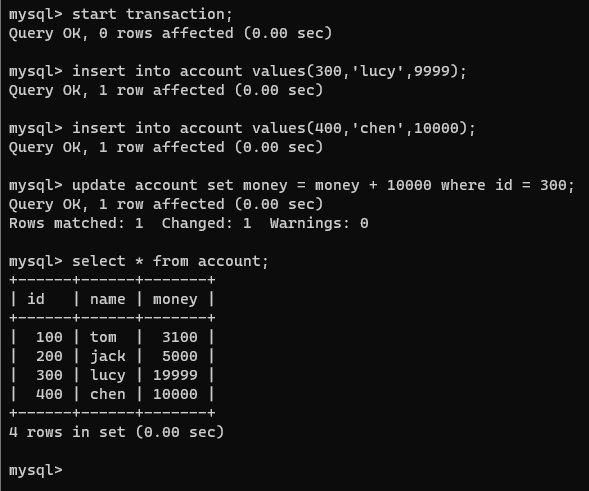
注意!此刻连接1和2的事务都是没有提交的,我们在连接2的事务中查看一下该表:
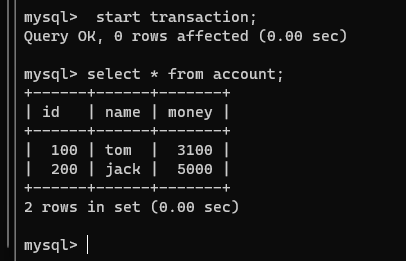
可以发现,连接1未提交的事务中做的修改,没有在连接2的事务中查看到;
将连接1的事务提交一下,再在没有提交的连接2开启的事务中查看该表:
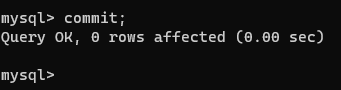
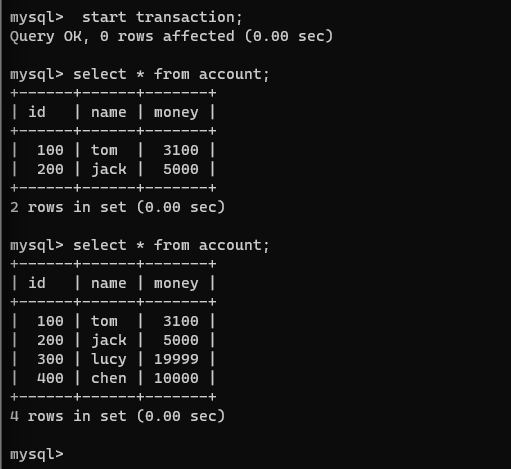
在并行的连接1和连接2中的事务中,可以发现在没有提交的连接2开启的事务当中,对account表的查看结果受到了连接1中的含有dml操作的事务的提交而改变。
在“读已提交”的隔离级别下,可能会引起不可重复读以及幻读问题。
③可重复读
将连接2的事务提交一下,并且将其隔离级别设置为Repeatable read(可重复读):
commit;
set session transaction isolation level repeatable read; 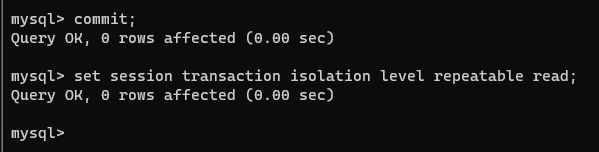
连接1和连接2再次开启事务:

连接2的事务中查看一下该表:
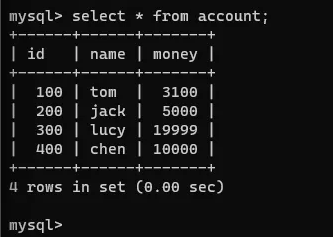
在连接1的事务中执行几句dml:
insert into account values(500,'kimi',8888);
insert into account values(600,'liu',20000);
update account set money = money - 1000 where id = 500;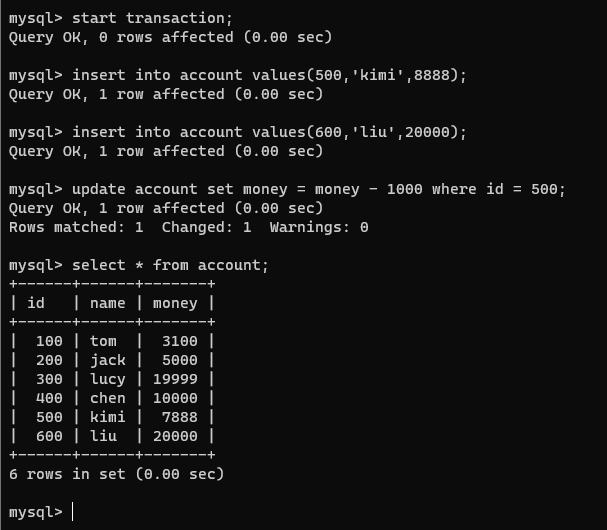
注意!此刻连接1和2的事务都是没有提交的,我们在连接2的事务中查看一下该表:
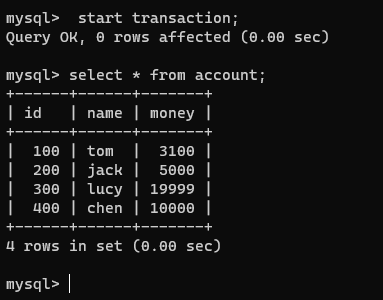
可以发现,连接1未提交的事务中做的修改,没有在连接2的事务中查看到;
将连接1的事务提交一下,再在没有提交的连接2开启的事务中查看该表:
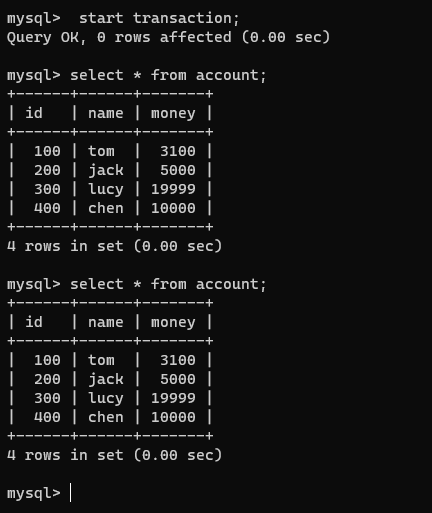
在并行的连接1和连接2中的事务中,可以发现在没有提交的连接2开启的事务当中对account表的多次查看结果并没有受到已经提交了的连接1开启的事务的dml操作以及提交而改变。
也就是说可重复读这个隔离级别不会有赃读,不可重复读以及幻读等问题。
④可串行化
将连接2的事务提交一下,并且将其隔离级别设置为:Serializable(可串行化);
commit;
set session transaction isolation level Serializable; 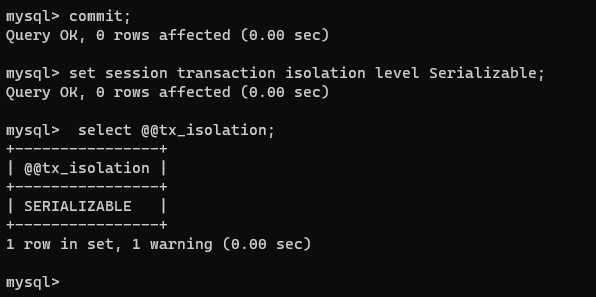
连接1和连接2再次开启事务:
连接2的事务中查看一下该表:
在连接1的事务中执行几句dml:
insert into account values(700,'chuyi',22222);
insert into account values(800,'shiwu',33333);
update account set money = money + 11111 where id = 700;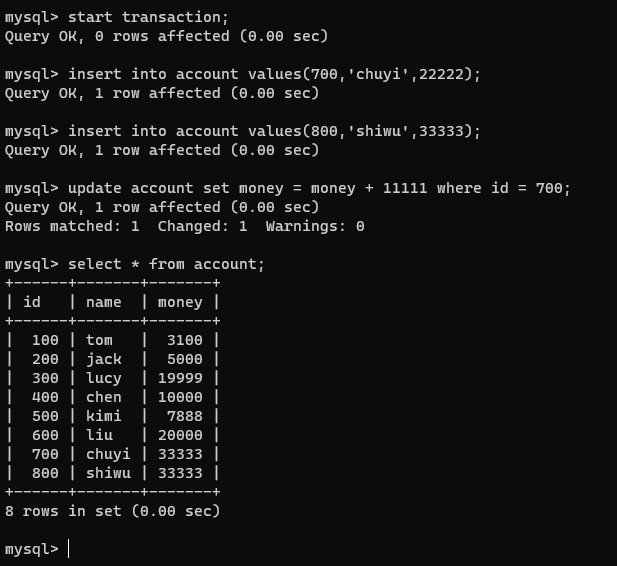
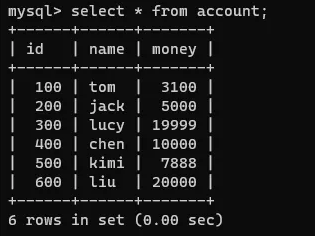
注意!此刻连接1和2的事务都是没有提交的,我们在连接2的事务中查看一下该表:
会发现回车键输入无效,连接2的事务中查看不了正在被连接1事务操作的account这张表!
这就说明account这张表对于隔离级别为“可串行化”的连接2开启的事务来说是被上了锁的。
我们将连接1的事务提交一下:
再在没有提交的连接2开启的事务中查看该表:
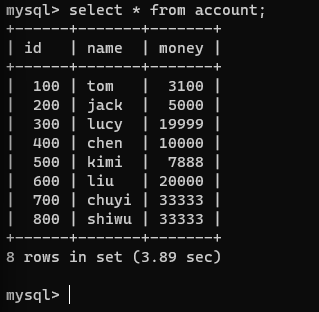
在实际上并行的连接1和连接2中的事务中,由于可串行化的隔离级别的加锁机制,使得连接1和连接2中的事务得到了形式上串行的效果,并且也达到了数据同步得效果。
)












)

模式)



