数据结构
在数据结构部分,研究数据在内存中如何存储。
数据存储的形式有两种:变量和数组(数据结构的顺序表)。
一、什么是数据结构?
数据类型被用来组织和存储数据。
程序设计 = 数据结构 + 算法
二、数据与数据之间的关系
1、逻辑结构
数据元素与元素之间的关系。
1)集合:元素与元素之间平等的集合关系。
2)线性结构:元素与元素之间存在一对一的关系(eg. 顺序表、链表、队列、栈)。
3)树形结构:元素与元素之间存在一对多的关系(eg. 二叉树)。
4)图形结构(网状结构):元素与元素之间存在多对多的关系。
内存为线形存储结构。
2、物理结构
数据元素在计算机内存中的存储方式。
1)顺序结构:在内存中选用一段连续的内存空间进行存储。
特点:(1) 数据访问方便 (算法复杂度O(1) )。
(2) 插入和删除数据时需要移动大量数据。
(3) 需要域内存分配 (连续的) 。
(4) 可能造成大量内存碎片 (分为内内存碎片和外内存碎片两种 )。
| 内存碎片分类 | 内存碎片特点 |
| 内内存碎片 | 操作系统已分配给程序的内存中部分小内存空间不能再被使用,例如结构体数据类型存储时的中间空闲块 |
| 外内存碎片 | 内存中存在大量不连续的空闲块,因分散在内存的不同位置而不能合并成一块连续的大空间,导致程序无法被加载到内存中 |
2)链式结构:可以在内存中选用一段不连续的内存空间进行存储。
给内存元素后加上指针,指针指向元素访问下一个元素。
特点:(1) 数据访问必须从头遍历 (算法复杂度O(n) );
(2) 插入和删除元素方便;
(3) 不需要与内存分配 (离散的),是一种动态内存操作 (只要有部分内存空间能放下部分数据,直至存放完全部数据就行)。
3)索引结构:将要存储的数据的关键字和存储位置之间构建一个索引表。
4)散列结构(哈希结构):将数据的存储位置与数据元素之间的关键字建立起对应的关系( 哈希函数 )。
索引结构与散列结构都用于快速定位数据。
三、基本功能
指针、结构体、动态内存分配。
四、数据结构内容
数据结构内容包含:顺序表、链式表(单向链表、双向链表、循环链表、内核链表)、栈、队列、二叉树、哈希表、常用算法。
五、单向链表
1、概念
单向链表是一种常见的线形数据结构,由多个节点组成,每个节点包含两部分:
1) 数据域:存储结点本身的信息(如数值、字符等)。
2) 指针域:存储下一个结点的地址,用于指向链表中的下一个结点。
示意图如下:
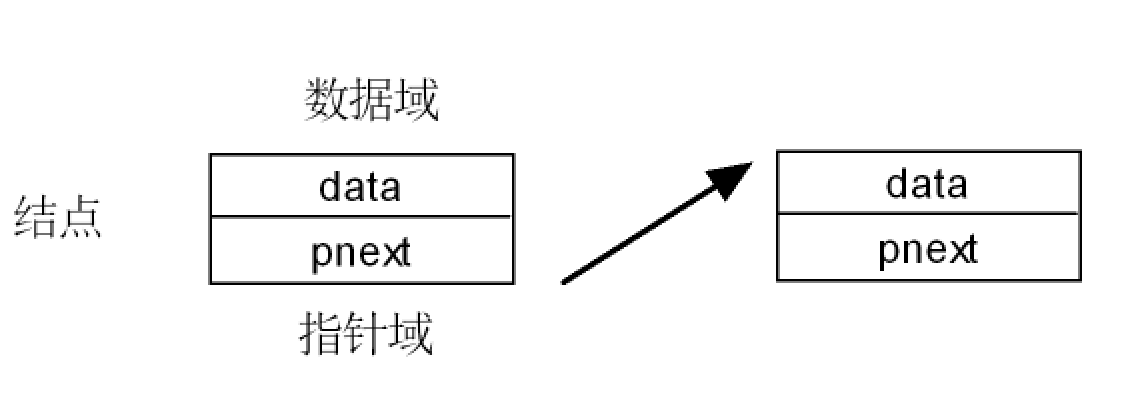
特点:整个链表的访问需从第一个结点开始,依次通过指针域找到下一个节点,最后一个结点的指针域为空指针(NULL),单向链表无法访问前一个结点。
2、链表的对象
链表的对象是存储数据的对象。
链表对象的属性特征(变量):第一个结点、结点的个数。
链表对象的行为(函数):创建链表对象、插入数据、删除数据、修改数据、查找数据、销毁链表。
3、单项链表的应用
1)单向链表的封装
(1) 封装结点(存放在声明文件中)
/*链表的结点类型*/
typedef struct node
{Data_type_t data;struct node *pnext;
}Node_t;(2) 封装对象(存放在声明文件中)
/*链表对象类型*/
typedef struct link
{Node_t *phead;int clen;
}Link_t;
(3) 创建单向链表函数封装
/*创建单向链表*/
Link_t *create_link()
{Link_t *plink = malloc(sizeof(Link_t));if(NULL == plink){printf("malloc error!\n");return NULL;}plink->phead = NULL;plink->clen = 0;return plink;
}(4) 单向链表---头部插入数据函数的封装
/*向单向链表的头部插入数据*/
int insert_link_head(Link_t *plink, Data_type_t data)
{//申请结点Node_t *pnode = malloc(sizeof(Node_t));if(NULL == pnode){printf("malloc error!");return -1;}//初始化结点pnode->data = data;pnode->pnext = NULL;//头插2步插入结点pnode->pnext = plink->phead;plink->phead = pnode;plink->clen++;return 0;
}(5) 单向链表---遍历函数的封装
//遍历
void link_for_each(Link_t *plink)
{Node_t *ptmp = plink->phead;while(ptmp != NULL){printf("%d ", ptmp->data);ptmp = ptmp->pnext;}printf("\n");
}(6) 单向链表---查找函数的封装
//查找
Node_t *find_link(Link_t *plink, Data_type_t mydata)
{Node_t *ptmp = plink->phead;while(ptmp != NULL){if(mydata == ptmp->data){return ptmp;}ptmp = ptmp->pnext;}return NULL;
}(7) 单向链表---遍历函数的封装
//修改
int change_link(Link_t *plink, Data_type_t olddata, Data_type_t newdata)
{Node_t *ptmp = find_link(plink, olddata);if(ptmp != NULL){ptmp->data = newdata;return 0;}return -1;
}(8)单向链表---头删函数的封装(删除前需判断是不是空结点)
/*是不是空结点*/
int is_empty_link(Link_t *plink)
{return NULL == plink->phead;
}//删除
int delete_link_head(Link_t *plink)
{if(is_empty_link(plink)){return -1;}Node_t *ptmp;ptmp = plink->phead;plink->phead = ptmp->pnext;free(ptmp);plink->clen--;return 0;
}(9) 单向链表---尾部插入数据的函数的封装
/*向单向链表的尾部插入数据*/
int insert_link_tail(Link_t *plink, Data_type_t data)
{//申请结点Node_t *pnode = malloc(sizeof(Node_t));if(NULL == pnode){printf("malloc error!");return -1;}pnode->data = data;pnode->pnext = NULL;if(is_empty_link(plink) == 0){plink->phead = pnode;pnode->pnext = NULL;plink->clen++;}else{Node_t *ptmp = plink->phead;while(ptmp->pnext != NULL){ptmp = ptmp->pnext;}ptmp->pnext = pnode;plink->clen++;}return 0;
}(10) 单向链表---尾删函数的封装
//尾删
int delete_link_tail(Link_t *plink)
{if(is_empty_link(plink) == 0){return -1;}Node_t *ptmp = plink->phead;if(NULL == ptmp->pnext){delete_link_head(plink);}else{while(ptmp->pnext->pnext != NULL){ptmp = ptmp->pnext;}ptmp->pnext = NULL;plink->clen--;//free(ptmp->pnext);}return 0;
}
(11) 单向链表---链表销毁函数的封装
//销毁
void destroy_link(Link_t *plink)
{while(is_empty_link(plink) != 0){delete_link_head(plink);}free(plink);printf("success!\n");
}
(11) 上述代码在封装函数框需包含以下三种头文件,其中“link.h”是自己命名的声明文件,在后续内容中说明
#include<stdio.h>
#include<stdlib.h>
#include"link.h"
2)单向链表的函数声明
#ifndef _LINK_H
#define _LINK_H/*链表存储的数据的数据类型*/
typedef int Data_type_t;extern Link_t *create_link();
extern int insert_link_head(Link_t *plink, Data_type_t data);
extern void link_for_each(Link_t *plink);
extern Node_t *find_link(Link_t *plink, Data_type_t mydata);
extern int change_link(Link_t *plink, Data_type_t olddata, Data_type_t newdata);
extern int delete_link_head(Link_t *plink);
extern int insert_link_tail(Link_t *plink, Data_type_t data);
extern int delete_link_tail(Link_t *plink);
extern void destroy_link(Link_t *plink);#endif3)单向链表的上述函数在主函数中的运行格式
#include<stdio.h>
#include"link.h"int main(int argc, const char *argv[])
{Node_t *ret = NULL;Link_t *plink = create_link();if(NULL == plink){return -1;}insert_link_head(plink, 1);insert_link_head(plink, 2);insert_link_head(plink, 3);insert_link_head(plink, 4);insert_link_head(plink, 5);link_for_each(plink);ret = find_link(plink, 4);if(ret == NULL){printf("not found\n");}else{printf("found %d\n", ret->data);}change_link(plink, 4, 15);link_for_each(plink);delete_link_head(plink); link_for_each(plink);*/尾插、尾删、销毁insert_link_tail(plink, 1);insert_link_tail(plink, 2);insert_link_tail(plink, 3);insert_link_tail(plink, 4);insert_link_tail(plink, 5);link_for_each(plink);delete_link_tail(plink);link_for_each(plink);destroy_link(plink);*/return 0;
}【END】









实现)
)

)
React +Ts(vite创建项目/useState/Props/Interface))

解释)



,严禁抄袭!)