Spring AI 是一个用于 AI 工程的应用框架
Spring AI 是一个用于 AI 工程的应用框架。其目标是将可移植性和模块化设计等 Spring 生态系统设计原则应用于 AI 领域,并推广使用 POJO 作为应用程序的构建块到 AI 领域。
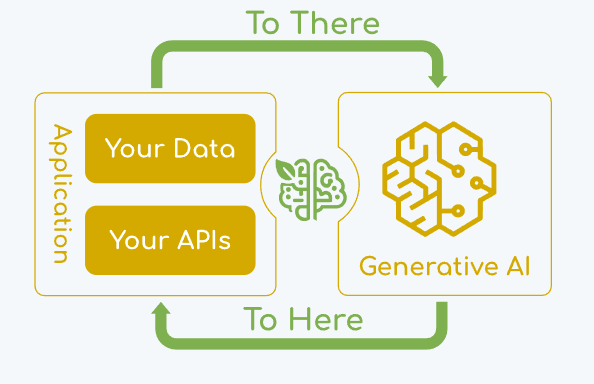
Spring AI 的核心是解决 AI 集成的基本挑战:将企业数据和 API 与 AI 模型连接起来。
特征
支持所有主要的 AI 模型提供商,例如 Anthropic、OpenAI、Microsoft、Amazon、Google 和 Ollama。支持的模型类型包括
基于Spring AI与Cassandra整合
以下是基于Spring AI与Cassandra整合的实用示例,涵盖从基础操作到高级应用场景,代码均以Spring Boot为框架。
基础CRUD操作
1. 实体类定义
@Table
public class Product {@PrimaryKeyprivate UUID id;private String name;private double price;// Lombok注解省略
}
2. 插入数据
@Repository
public interface ProductRepository extends CassandraRepository<Product, UUID> {@InsertProduct save(Product product);
}
3. 批量插入
List<Product> products = Arrays.asList(new Product(...));
productRepository.saveAll(products);
4. 按ID查询
Optional<Product> product = productRepository.findById(uuid);
5. 更新数据
product.setPrice(29.99);
productRepository.save(product);
查询与条件操作
6. 自定义查询方法
@Query("SELECT * FROM products WHERE price > ?0 ALLOW FILTERING")
List<Product> findByPriceGreaterThan(double price);
7. 分页查询
Page<Product> page = productRepository.findAll(PageRequest.of(0, 10));
8. 排序查询
Sort sort = Sort.by(Sort.Direction.DESC, "price");
List<Product> products = productRepository.findAll(sort);
9. IN条件查询
@Query("SELECT * FROM products WHERE id IN ?0")
List<Product> findByIds(List<UUID> ids);
10. 使用CassandraTemplate
cassandraTemplate.select("SELECT * FROM products", Product.class);
高级数据建模
11. 使用UDT(用户定义类型)
@UserDefinedType("address")
public class Address {private String city;private String street;
}
12. 集合类型字段
@Table
public class User {private Set<String> tags;private Map<String, String> attributes;
}
13. 时间序列数据建模
@PrimaryKeyClass
public class SensorReadingKey {@PrimaryKeyColumn(type = PrimaryKeyType.PARTITIONED)private String sensorId;@PrimaryKeyColumn(type = PrimaryKeyType.CLUSTERED, ordering = Ordering.DESCENDING)private Instant timestamp;
}
AI集成示例
14. 存储AI模型输出
@Table
public class ModelPrediction {@PrimaryKeyprivate UUID id;private String modelName;private Map<String, Double> probabilities;
}
15. 特征向量存储
@Table
public class FeatureVector {@PrimaryKeyprivate String entityId;private List<Float> vector; // 用于相似性搜索
}
16. 推荐结果缓存
@Table
public class UserRecommendation {@PrimaryKeyprivate String userId;private List<String> recommendedItems;
}
性能优化
17. 批量异步写入
ListenableFuture<Void> future = cassandraTemplate.insertAsynchron(entities);
18. 轻量级事务
@Insert(ifNotExists = true)
boolean insertIfNotExists(Product product);
19. 物化视图查询
@Table
@MaterializedView("products_by_price")
public class ProductByPrice {@PrimaryKeyprivate double price;private UUID productId;
}
错误处理与监控
20. 重试策略配置
@Retryable(maxAttempts = 3, backoff = @Backoff(delay = 100))
public void saveWithRetry(Product product) {productRepository.save(product);
}
21. 指标监控
@Timed("cassandra.query.time")
public List<Product> findAllProducts() {return productRepository.findAll();
}
分布式场景
22. 多数据中心配置
spring:data:cassandra:keyspace-name: my_keyspacelocal-datacenter: DC1contact-points: host1,host2
23. 跨分区查询
@Query("SELECT * FROM products WHERE token(id) > token(?0) LIMIT 100")
List<Product> findAfterToken(UUID lastId);
测试与调试
24. 单元测试配置
@TestConfiguration
@EmbeddedCassandra
static class TestConfig {@BeanCassandraTemplate testTemplate() {return new CassandraTemplate(session);}
}
25. 查询日志打印
logging:level:org.springframework.data.cassandra.core.CassandraTemplate: DEBUG
以上示例覆盖了Spring Data Cassandra的核心功能,结合AI场景的特性存储需求,可根据实际业务扩展修改。注意生产环境中需优化分区键设计、添加适当的索引策略。
基于Spring和Azure Vector Search的实例
以下是一些基于Spring和Azure Vector Search的实例示例,涵盖不同场景和使用方法:
基础配置与初始化
在application.properties或application.yml中配置Azure Vector Search的连接信息:
azure.search.endpoint=https://{your-service-name}.search.windows.net
azure.search.api-key={your-api-key}
azure.search.index-name={your-index-name}
在Spring Boot中注入SearchClient:
@Bean
public SearchClient searchClient(@Value("${azure.search.endpoint}") String endpoint,@Value("${azure.search.api-key}") String apiKey,@Value("${azure.search.index-name}") String indexName) {return new SearchClientBuilder().endpoint(endpoint).credential(new AzureKeyCredential(apiKey)).indexName(indexName).buildClient();
}
向量搜索基础示例
使用预生成的向量进行相似性搜索:
public List<SearchResult> searchByVector(float[] vector, int k) {SearchOptions options = new SearchOptions().setVector(new SearchQueryVector().setValue(vector).setKNearestNeighborsCount(k));return searchClient.search(null, options, Context.NONE).stream().collect(Collectors.toList());
}
文本嵌入与搜索
结合Azure OpenAI生成文本嵌入后搜索:
public List<SearchResult> searchByText(String query, int k) {float[] embedding = openAIClient.generateEmbedding(query); // 假设已配置OpenAI客户端return searchByVector(embedding, k);
}
混合搜索(向量+关键词)
同时使用向量和关键词进行搜索:
public List<SearchResult> hybridSearch(String query, float[] vector, int k) {SearchOptions options = new SearchOptions().setVector(new SearchQueryVector().setValue(vector).setKNearestNeighborsCount(k)).setSearchText(query);return searchClient.search(null, options, Context.NONE).stream().collect(





技术架构与工程实践:从原理到部署)
)
数据库安装教程)
)
![[LINUX操作系统]shell脚本之循环](http://pic.xiahunao.cn/[LINUX操作系统]shell脚本之循环)








