Focus模块:早期再yolov5版本提出,后期被常规卷积替换,作用是图像进入主干网络之前,进行隔行隔列采样,把空间维度堆叠到通道上,减少计算量。
SPPF:SPP的改进版本,把SPP的不同池化核改变为K = 5 的池化核,然后不同的其他池化核都是用 k = 5 进行替换,并行结构改为并行 + 串行。
新的激活函数:silu,swish,如果swish的β参数为1,就转化为silu
自动锚框计算:yolov5根据大量的数据集学习到比较好的一组尺寸的锚框,那么最开始的时候就是直接使用这些锚框,锚框自动计算,手动开启(默认开启)计算锚框的尺寸的时候,就会从新的基于数据集进行锚框计算。
1、模型训练
训练结果:
best.pt: 就是我们使用模型的文件,即整个训练过程中最好的一次
last.pt: 整个训练过程中最后一次,假设训练模型500次,但是在中间训练中断了,就用last.pt恢复训练,如果500次训练完了,但是觉得可以继续训练,可以考虑best.pt当初始化权重文件来使用
使用训练模型推理
yolov5s.yaml
网络结构配置文件,重点掌握depth_multiple和width_multiple的使用,还需要掌握如果更改主干网络或者检测头中的网络层次,比如加入CBAM之后,如何对网络的层次信息进行更新,因为新加入一个内容之后,在这一层之后的所有网络层数都要+1
depth_multiple: 0.33 # model depth multiple
#这个参数就是控制输出通道数量的倍率,最小为8
width_multiple: 0.50 # layer channel multiple
common.py
这个文件的内容就是定义模块的。比如Conv 、C3等模块,提供给后续文件使用构建网络。
1、改进点
-
主干网络是修改后的 CSPDarknet53,后面跟了 SPPF 模块
-
网络最开始增加 Focus 结构
-
颈部网络采用 PANet、FPN
-
激活函数换成了 SiLU、Swish
-
采用 CloU 损失
2、Focus 模块
-
YOLOv5 刚推出时,为了提升模型效率,采用了 Focus 模块 作为网络的初始特征提取层,传统卷积下采样会丢失部分空间信息,Focus 模块旨在在不丢失信息的前提下进行高效下采样
-
核心目标:将高分辨率图像的空间信息通过切片操作转换为通道信息,从而实现高效、无信息损失的下采样
-
Focus 模块是一种用于特征提取的卷积神经网络层,用于将输入特征图中的信息进行压缩和组合,从而提取出更高层次的特征表示,它被用作网络中的第一个卷积层,用于对输入特征图进行下采样,以减少计算量和参数量
-
Focus 层在 YOLOv5 中是图片进入主干网络前,对图片进行切片操作,原理与 Yolov2 的 passthrough 层类似,采用切片操作把高分辨率的图片(特征图)拆分成多个低分辨率的图片(特征图),即隔列采样+拼接
-
具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了 4 张图片,4 张图片互补,但是没有信息丢失,这样一来,将空间信息就集中到了通道空间,输入通道扩充了 4 倍,即拼接起来的图片相对于原先的 RGB 3 通道模式变成了 12 个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图
-
案例:假设输入一张图像大小为 640x640x3
-
第一步:640 x 640 x 3的图像输入Focus结构,采用切片操作
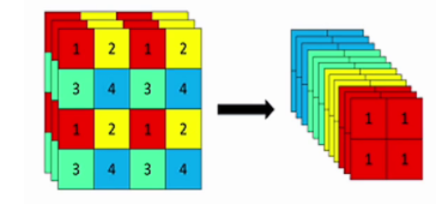
-
第二步:然后进行一个连接(concat),变成 320 x 320 x 12 的特征图
-
第三步:经过一次 32 个卷积核的卷积操作,最终输出 320 x 320 x 32 的特征图
-
-
在 YOLOv5 刚提出来的时候,有 Focus 结构,从 YOLOv5 第六版开始, 就舍弃了这个结构,改用 k=6×6,stride=2 的常规卷积
3、网络结构
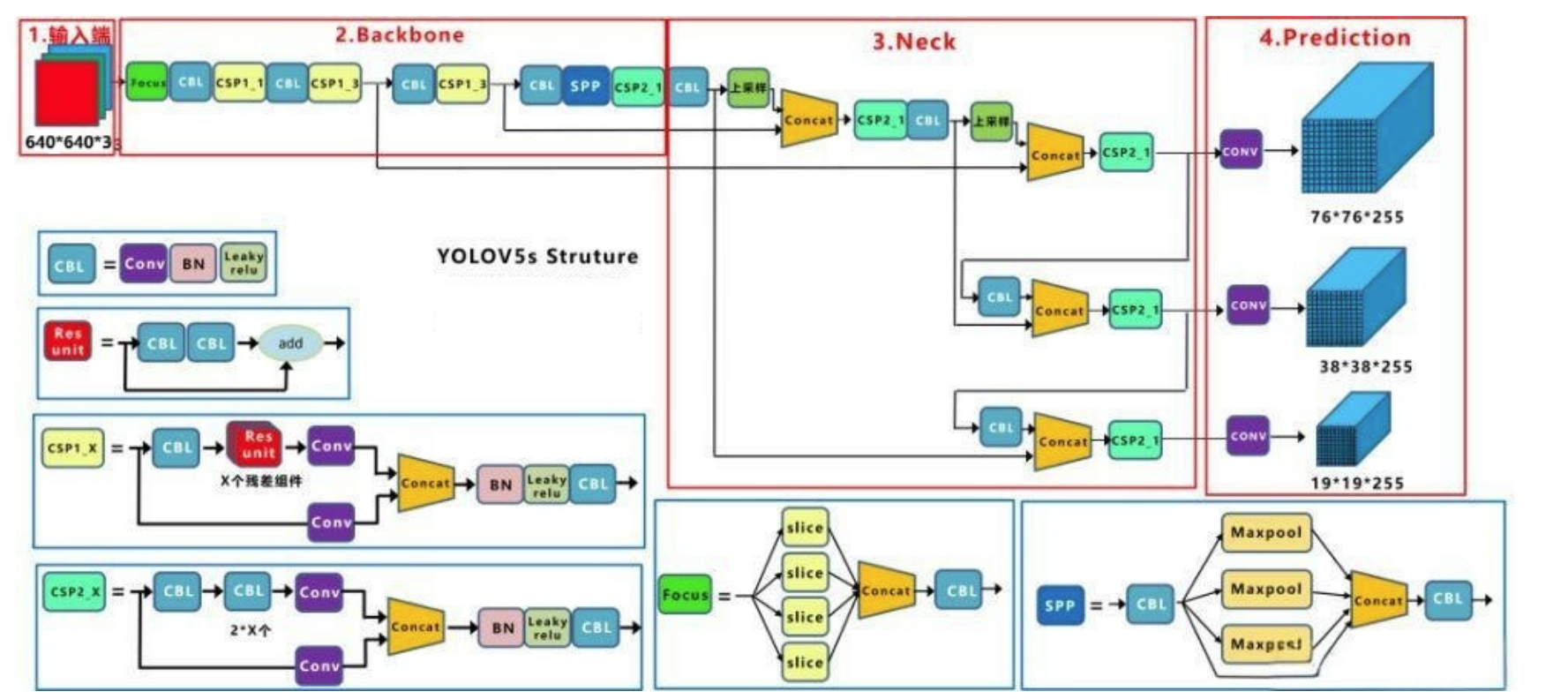
3.1 CSP1_X 与 CSP2_X
-
CSP1_X:
-
定义:带 shortcut(残差连接)的 CSP 模块
-
结构特点:内部包含带有 shortcut 的 Bottleneck 结构
-
应用场景:主要用于 backbone 部分,如 CSPDarknet53,增强特征提取能力
-
X 的含义:表示 bottleneck 的数量
-
-
CSP2_X:
-
定义:不带 shortcut 的 CSP 模块
-
结构特点:内部没有 shortcut 连接,仅通过卷积操作进行特征提取
-
应用场景:主要用于 neck 部分,如 PANet(Path Aggregation Network),进行特征聚合
-
X 的含义:表示 bottleneck 或其他卷积模块的数量
-
3.2 自适应Anchor的计算
-
在 YOLOv3、YOLOv4 中,训练不同的数据集时,计算初始 Anchor 的值是通过单独的程序运行的。但 YOLOv5 中将此功能嵌入到代码中,每次训练时会自适应的计算不同训练集中的最佳 Anchor 值
-
实现方式:
-
在训练开始前,YOLOv5 会自动加载训练集中的标注框
-
使用 K-Means 聚类算法计算 Anchor
-
将结果作为初始 Anchor 值用于模型初始化
-
-
源码位置:
utils/autoanchor.py/check_anchors()

3.3 激活函数
-
激活函数:使用了 SiLU 激活函数、Swish 激活函数两种激活函数
3.3.1 SiLU
-
YOLOv5 的 Backbone 和 Neck 模块和 YOLOv4 中大致一样,都采用 CSPDarkNet 和 FPN+PAN 的结构,但是网络中其他部分进行了调整,其中 YOLOv5 使用的激活函数是 SiLU
-
SiLU(x) = x·\sigma(x),具备无上界有下届、平滑、非单调的特性
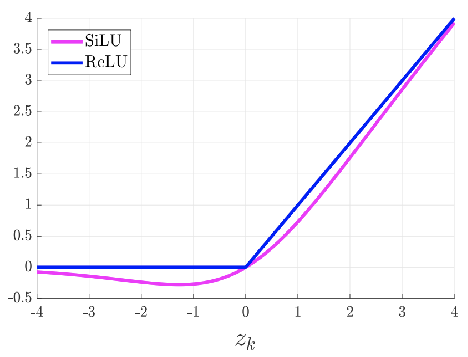
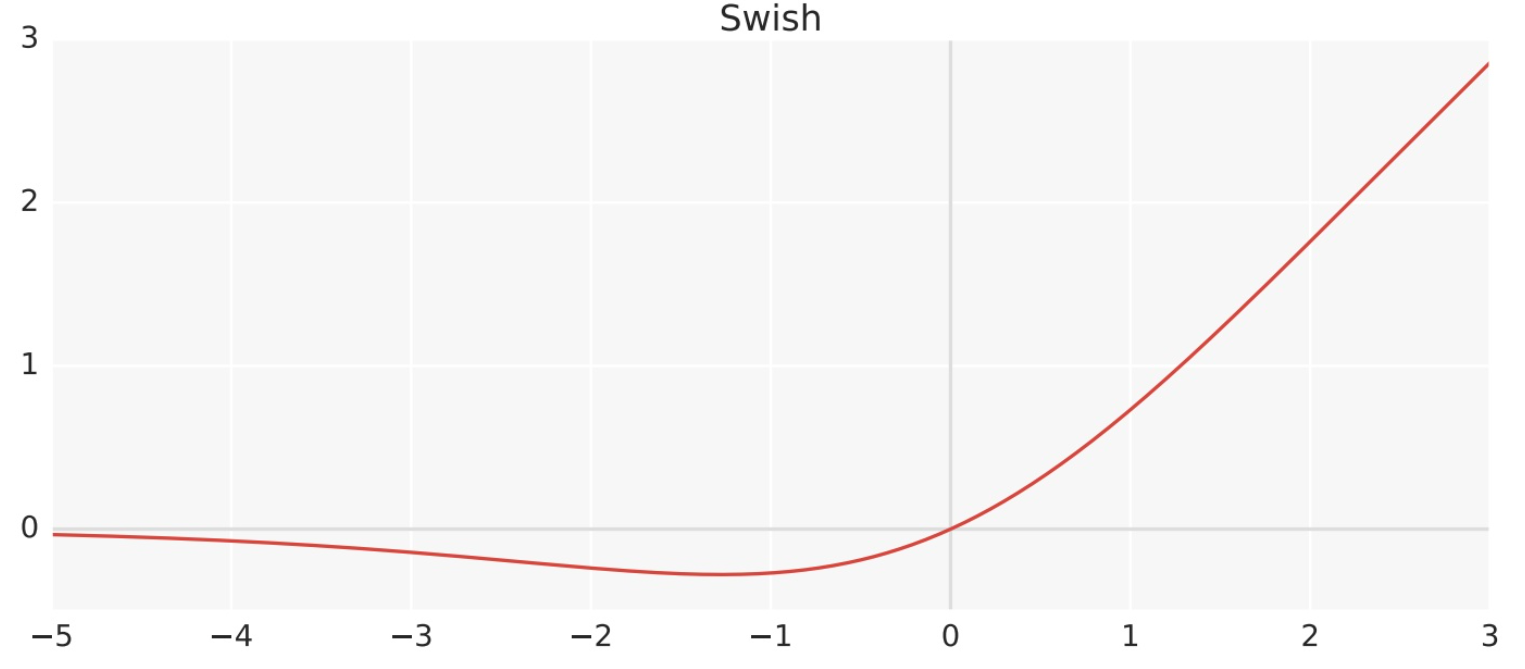
3.3.2 Swish
-
Swish 激活函数是一个近似于 SiLU 函数的非线性激活函数,具有以下形式:
-
\beta是一个可调节的参数,通常设定为 1
-
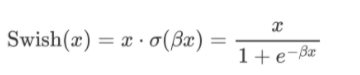
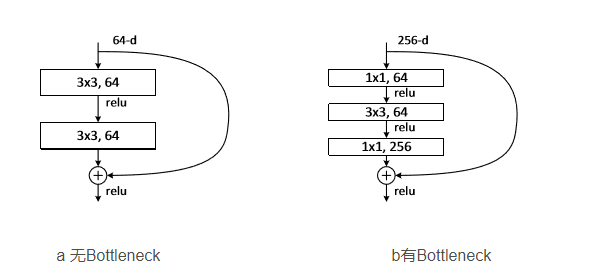
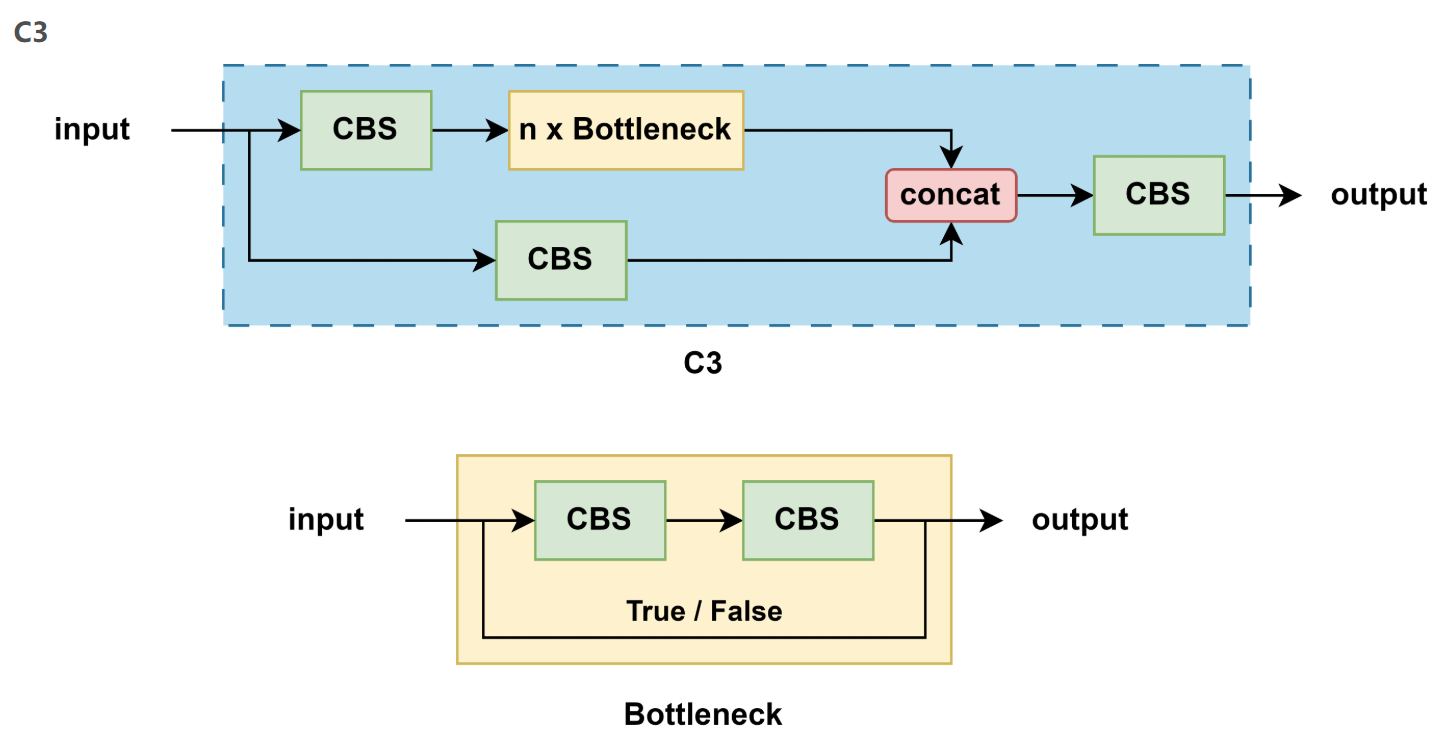
3.4 Bottleneck
-
Bottleneck 是用于减少参数和计算量的结构,其设计灵感来自于ResNet,结构如下:
-
1x1卷积:用于减少特征图的通道数
-
3x3卷积:用于提取特征,后接一个 Batch Normalization 层和 ReLU 激活函数
-
1x1卷积:用于恢复特征图的通道数,后接一个BN层
-
跳跃连接(Shortcut):将输入直接加到输出上,以形成残差连接
-
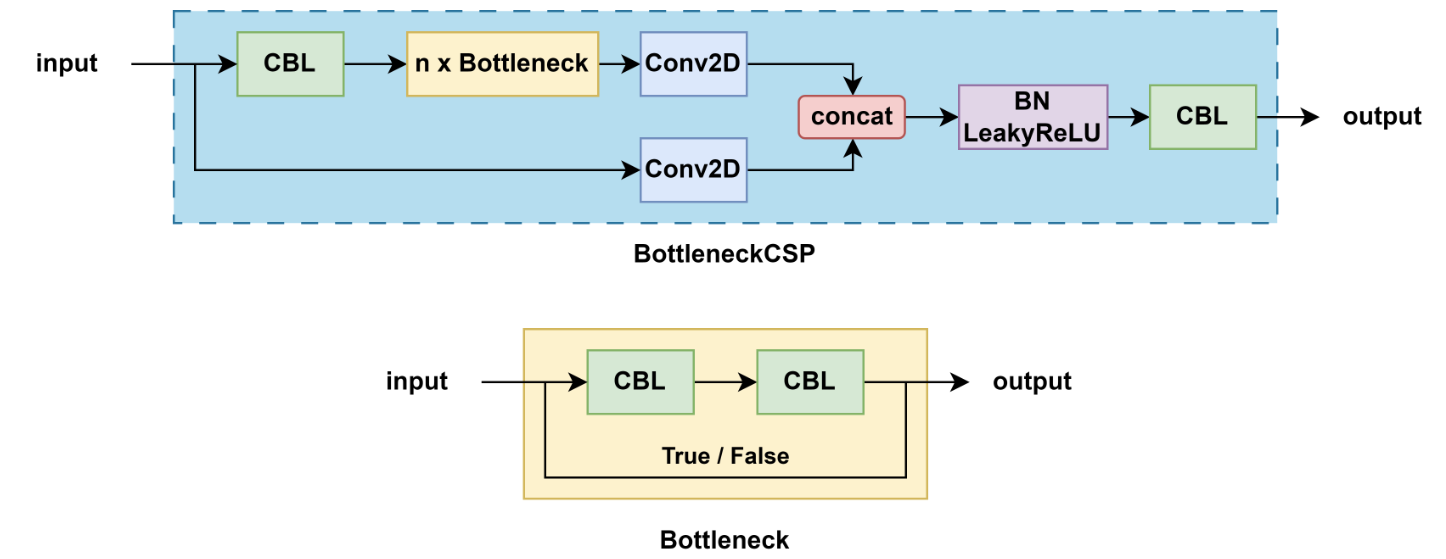
3.5 C3
-
YOLOv5 中的 C3 模块在 CSP上进行了优化,非常相似但略有不同:
-
YOLOv5 一共使用过两种 CSP 模块
-
v4.0 版本之前的 BottleneckCSP,用的 LeakyReLU 作为激活函数
-
v4.0 版本之后的 C3,用的 SiLU 作为激活函数
-
3.5.1 BottleneckCSP
-
结构特点:
-
包含多个带 shortcut 的 Bottleneck
-
输入通道被划分,一部分直接传递,一部分经过 Bottleneck 块
-
-
激活函数:LeakyReLU
-
用途:主要用于早期 YOLOv5 的 backbone
3.5.2 C3
-
结构特点:
-
不再使用 shortcut(即 Bottleneck 不带残差连接)
-
更加简洁,更适合部署
-
-
激活函数:SiLU
-
用途:广泛用于 backbone 和 neck(如 PANet)
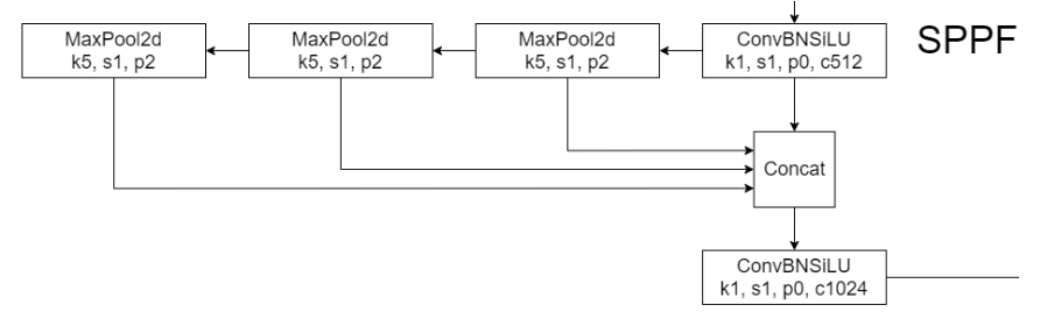
3.6 SPPF
-
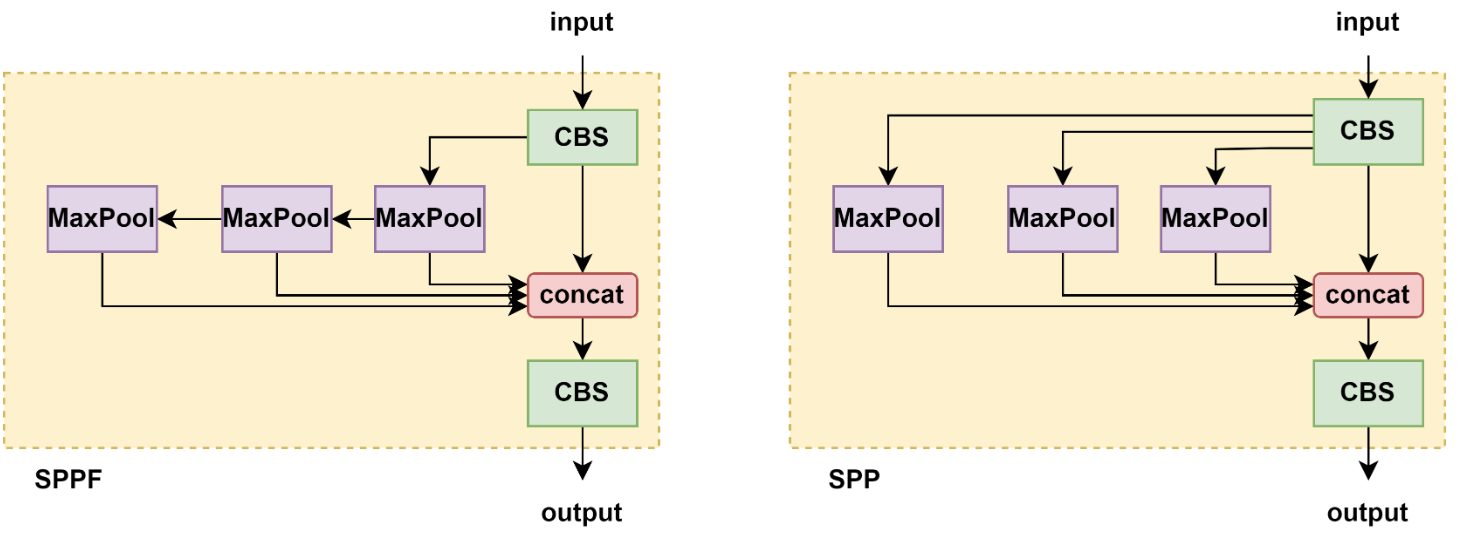
将卷积核大小变成相同,然后将并行变成了串行+并行,2个K5池化=1个K9池化,3个K5池化=1个K13池化,也就是结果相同的基础上,速度更快,计算量更小
-
对于连续堆叠 n 层,每层使用大小为 k 的核的操作(例如卷积或池化),其等效感受野大小可以通过以下公式计算:K_{等效}=1+n(k−1)
| 层数 n | 卷积核大小 k | 等效感受野 |
|---|---|---|
| 1 | 5 | 1+1×(5−1)=5 |
| 2 | 5 | 1+2×(5−1)=9 |
| 3 | 5 | 1+3×(5−1)=13 |
3.6.1 SPP 和 SPPF 区别
4、 输出头
-
灵活度较高,支持多种尺寸:
-
输入图像尺寸:通常为 640x640(或者其它尺寸,如 416x416 等)
-
输出特征图:YOLOv5 使用大、中、小三个尺寸
-
输出尺寸:
-
大目标: 通常是输入图像尺寸的 1/32
-
中目标: 通常是输入图像尺寸的 1/16
-
小目标: 通常是输入图像尺寸的 1/8
-
-
-
假设输入图像尺寸为640x640,具体的特征图尺寸如下:
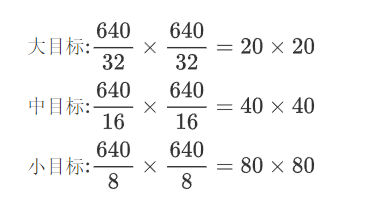
5、开源项目
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
项目链接
不同v5版本的差异表
| Model | size (pixels) | mAPval 50-95 | mAPval 50 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
-
YOLOv5的一些主要模型变体:
-
YOLOv5n:
-
这是最小的变体,适用于嵌入式设备或资源受限的环境
-
牺牲了一定的准确性以换取更快的速度
-
-
YOLOv5s:选择
-
较小的模型,适合在边缘设备上使用
-
相比于更大的模型,它提供了更好的速度,但在精度上有所降低
-
-
YOLOv5m:
-
中等大小的模型,平衡了速度和精度
-
适用于大多数常规硬件
-
-
YOLOv5l:
-
较大的模型,提供了更高的检测精度
-
在高端硬件上可以运行良好,但速度较慢
-
-
YOLOv5x:
-
最大的模型,具有最高的精度
-
需要高性能的硬件来保证实时处理速度
-
-
-
各个模型测试速度参数:
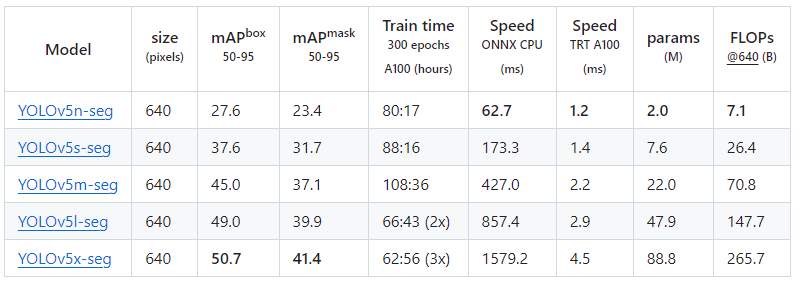
-
第四步:把下载好模型,复制一份到项目中,如下:
第五步:执行命令python detect.py --weights <weights_path> --source <source>,完成推理,结果默认保存到 runs/detect
命令参数详细说明:
detect.py:是YOLOv5提供的用于目标检测的脚本
--weights <weights_path>:指定模型权重文件的路径。例如yolov5s.pt表示使用YOLOv5s模型的预训练权重
--source <source>: 指定输入源。可以是以下类型之一:
0: 表示使用默认摄像头(通常是内置摄像头)
img.jpg: 指定图像文件作为输入
vid.mp4: 指定视频文件作为输入
screen: 使用屏幕截图作为输入源,需要注意是否所有的YOLOv5版本都支持此选项
path/: 指定一个目录,该目录下的所有支持的媒体文件都将作为输入
list.txt: 一个文本文件,其中每一行是一个输入源(可以是图像路径或视频路径)
list.streams: 类似于list.txt,但每一行是一个流媒体链接
'path/*.jpg': 使用glob模式匹配文件,此处表示所有.jpg格式的图像文件
'https://youtu.be/LNwODJXcvt4': 从YouTube URL读取视频流
'rtsp://example.com/media.mp4': 从RTSP、RTMP或HTTP流读取视频
在这里查看detect的结果
训练
-
执行以下命令训练模型,结果默认保存到
runs/train
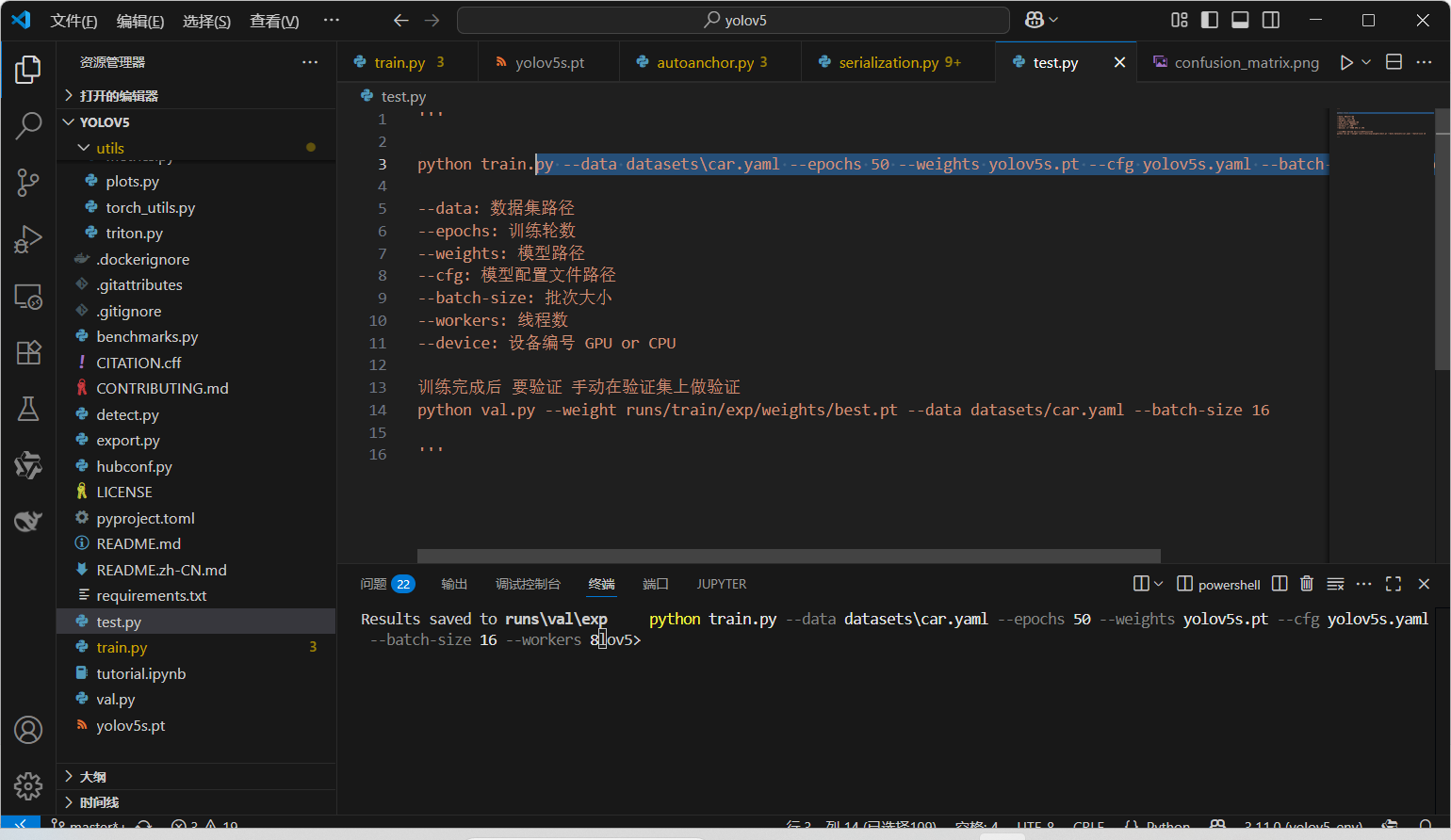
python train.py --data .\data\coco.yaml --img 640 --epochs 25 --weights .\yolov5s.pt --cfg .\models\yolov5s.yaml --batch-size 2 --device 0
-
命令参数详细说明:
-
train.py:这是一个 Python 脚本,它负责加载数据、构建模型、设置优化器、定义损失函数,并执行训练循环 -
--data coco.yaml:用来指定数据集配置文件的路径,在这个例子中,coco.yaml文件包含了训练数据集的详细信息,如训练集、验证集的路径,类别数量等,我们需要把这个coco.yaml替换成我们的数据集对应的.yaml文件路径 -
--img 640:指定样本尺寸 -
--epochs 25:用来指定训练的周期数,这里的值25表示整个训练过程将在数据集上重复 25 次 -
--weights .\yolov5s.pt:用于指定初始权重文件的路径。值yolov5s表示在 yolov5 提供的模型基础上继续训练,当路径为空字符串''时,意味着训练从零开始,没有预训练的权重 -
--cfg yolov5s.yaml:用于指定模型配置文件的路径。配置文件定义了模型的架构细节,如卷积层的数量、尺寸等,在这个例子中,yolov5s.yaml指定了YOLOv5 小型版本模型配置文件 -
--batch-size 2:用于设置每次梯度更新时使用的样本数量。批量大小越大,每次迭代所用的时间越长,但同时可能会得到更稳定的梯度,注意虚拟内存问题 -
--device 0:于指定训练过程中使用的设备,通常是 GPU 或 CPU。这个参数可以帮助你控制模型训练是在 CPU 上还是在 GPU 上进行,在这个例子中 0 表示第 0 号 GPU,如果计算机没有 GPU,参数设置为 CPU 即可,如果想让计算机自动选择可用的 GPU,把值设置为 -1 即可
-
-
执行过程:
-
训练过程,介绍如下:
-
Epoch:一个 epoch 指的是模型在整个训练数据集上完成一次正向传播和反向传播的过程,用于衡量训练的进度
-
Gpu_mem:表示当前GPU的内存使用情况,监控GPU内存使用情况,确保没有超过显存限制,避免出现内存溢出错误
-
box_loss:表示边界框回归损失,用于衡量预测框与真实框之间的偏差,用于优化预测框的位置,使其更加接近真实框的位置
-
obj_loss:表示对象存在性损失,用于衡量预测框是否包含对象,用于判断预测框是否真正包含了目标对象,提高模型识别目标的能力
-
cls_loss:表示分类损失,用于衡量预测框内对象的分类准确性,用于优化模型对目标对象的分类准确性,使其能够正确识别不同类别的对象
-
Instances:训练批次中检测到的目标实例数量
-
Size:表示输入到模型中的图像大小
-
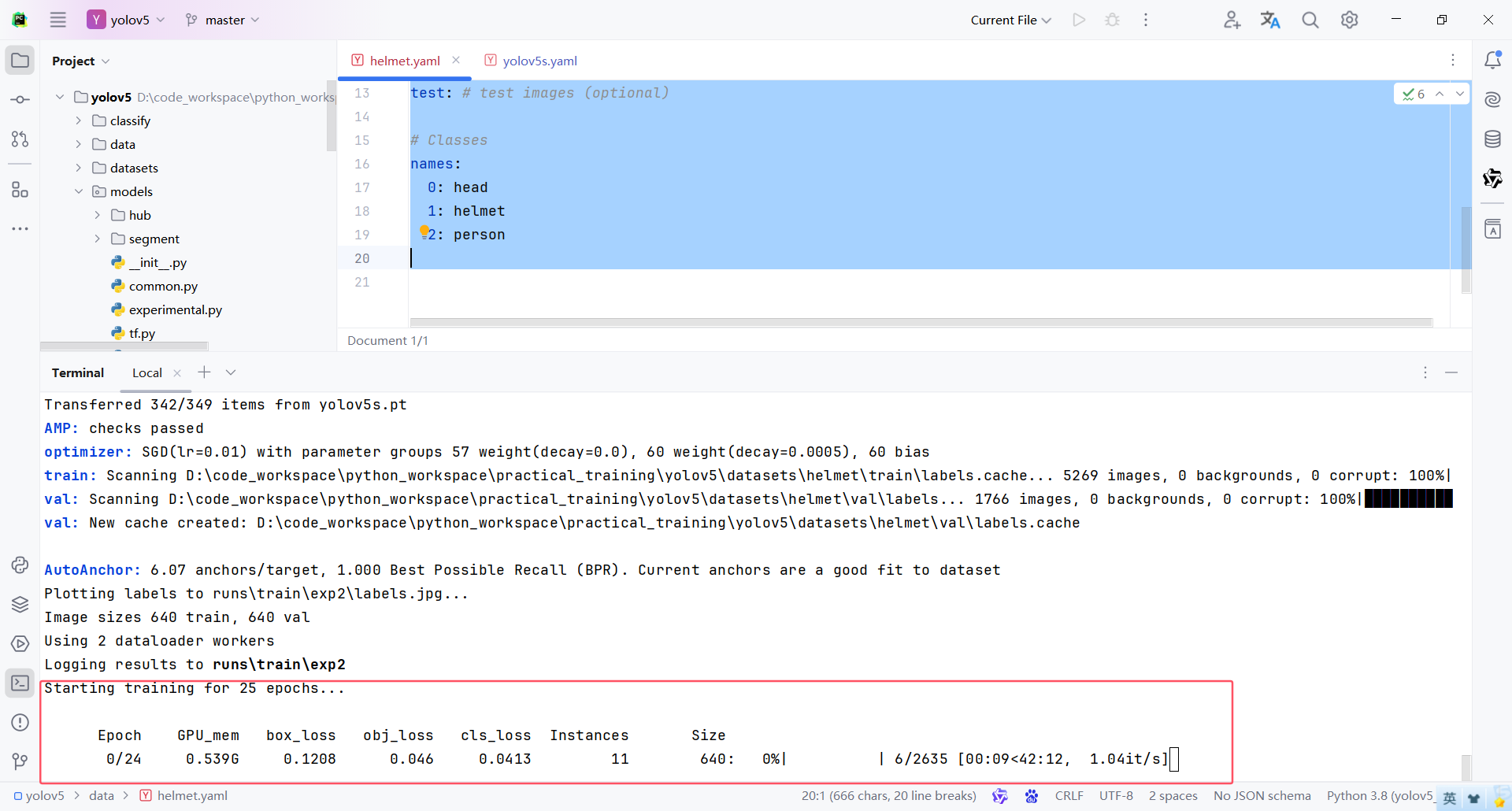
-
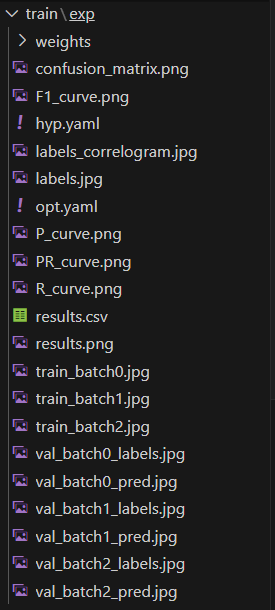
训练结果,这个文件夹中包含了很多文件,重要内容如下:
-
weights 文件夹下,有两个后缀名为
.pt的文件-
best.pt:表示在整个训练过程中性能最佳的模型权重,用于推理 -
last.pt:表示训练结束时的最后一个模型权重,用于设置下次训练基于这个基础上继续训练,但是需要修改很多参数
-
-
5.9 恢复训练
-
如果训练过程中意外停止,在训练指令后面加上
--resume参数可以恢复训练,并且不需要同时指定--weights参数。--resume会自动加载最近一次保存的检查点(包括模型权重、优化器状态等)
python train.py --weights runs/train/exp/weights/last.pt --resume
)
)



:全面解析容器化革命 | 2025 终极指南)

)
——学习笔记)


)







