1.单调栈
1.什么是单调栈
单调栈,即具有单调性的栈。
实现
#include <iostream>
#include <stack>
using namespace std;
const int N = 3e6 + 10;
int a[N], n;
void test1()
{stack<int> st; // 维护⼀个单调递增的栈for(int i = 1; i <= n; i++){// 栈⾥⾯⼤于等于 a[i] 的元素全部出栈while(st.size() && st.top() >= a[i]) st.pop();st.push(a[i]);}
}2.单调栈解决的问题
- 寻找当前元素左侧,离它最近,且比它大的元素在哪
- 寻找当前元素左侧,离它最近,且比它小的元素在哪
- 寻找当前元素右侧,离它最近,且比它大的元素在哪
- 寻找当前元素右侧,离它最近,且比它小的元素在哪
虽然是四个问题,但是原理是⼀致的。因此,只要解决⼀个,举⼀反三就可以解决剩下的几个。
3.寻找当前元素左侧,离它最近,并且比它大的元素在哪
从左往右遍历元素,构造⼀个单调递减的栈。插入当前位置的元素的时:
• 如果栈为空,则左侧不存在比当前元素大的元素;
• 如果栈非空,若栈顶元素比当前位置大则栈顶元素为目标元素;若栈顶元素比当前元素小,出栈维护单调递减栈。
注意,因为我们要找的是最终结果的位置。因此,栈里面存的是每个元素的下标。
1.1【模板】单调栈
P5788 【模板】单调栈
2.单调队列
1.什么是单调队列?
单调队列,即存储的元素要么单调递增要么单调递减的队列,这里的队列是个双端队列。
2.单调队列解决的问题
一般用于解决滑动窗口内最大值最小值问题,以及优化动态规划。
2.1 滑动窗口 /【模板】单调队列
P1886 滑动窗口 /【模板】单调队列
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<deque>
//https://www.luogu.com.cn/problem/P1886
using namespace std;
const int N = 1e6 + 10;
int n, k;
int a[N];
//单调队列
int main()
{cin >> n >> k;for (int i = 1; i <= n; ++i)cin >> a[i];//存储下标的双端队列deque<int> q;//找窗口内最小值for (int i = 1; i <= n; ++i){//单调递增的队列while (q.size() && a[i] <= a[q.back()])q.pop_back();q.push_back(i);//判断是否在窗口内,并更新队列if (q.size() && i - q.front() >= k)q.pop_front();//当窗口大小达到k时,取出窗口内的最值if (i >= k)cout << a[q.front()] << ' ';}cout << endl;q.clear();//找窗口内最大值for (int i = 1; i <= n; ++i){//单调递减的队列while (q.size() && a[i] >= a[q.back()])q.pop_back();q.push_back(i);//判断是否在窗口内,并更新队列if (q.size() && i - q.front() >= k)q.pop_front();//当窗口大小达到k时,取出窗口内的最值if (i >= k)cout << a[q.front()] << ' ';}cout << endl;return 0;
}
3.并查集
3.1并查集的概念及实现
3.1.2并查集的概念
并查集(Union Find):是一种用于维护元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素,根节点来代表整个集合。
实现并查集的时,我们⼀般让根节点自己指向自己。
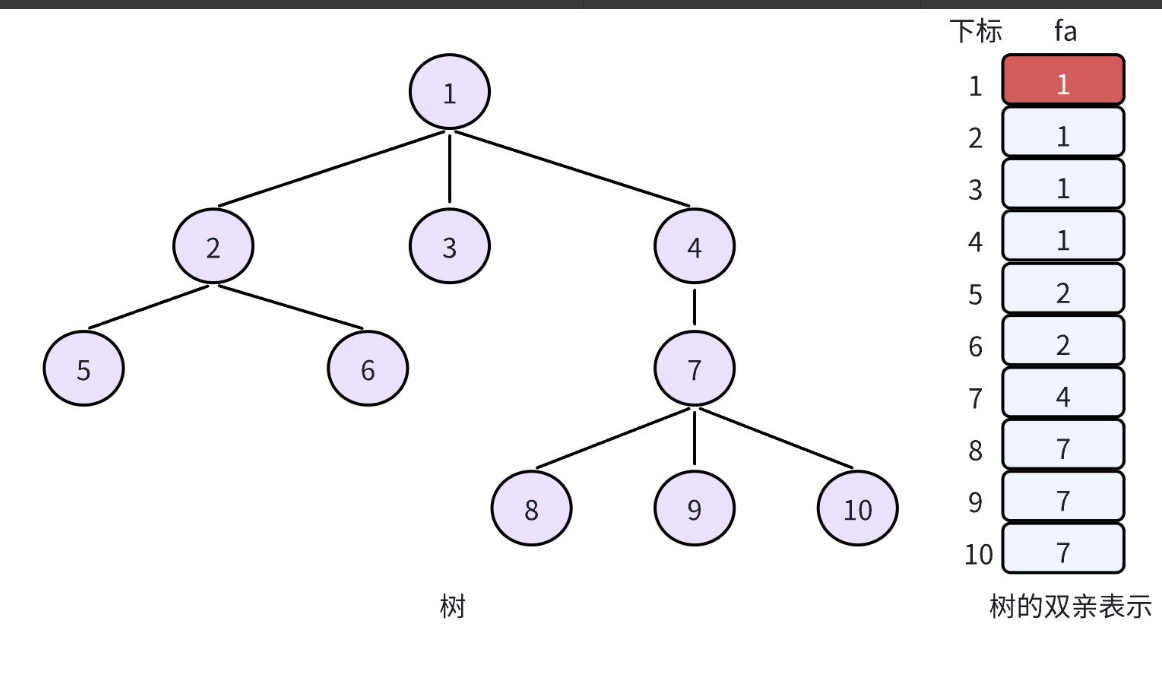
我们需要维护若干个集合
- 查询操作:查找
x属于哪一个集合 - 合并操作:将
x所在集合和y所在集合合并成一个集合 - 判断操作:判断
x和y是否在同一个集合
3.1.2并查集的实现
1.初始化:让元素自己指向自己
for(int i=1;i<=n;i++)fa[i]=i;
2.查询
// 返回父亲节点
int find(int x)
{if(fa[x] == x) return x;// 路径压缩 把被查询的节点到根节点的路径上的所有节点的⽗节点设置为根节点return fa[x] = find(fa[x]);// ⼀⾏实现return fa[x] == x ? x : fa[x] = find(fa[x]);
}3.合并
将元素 x 所在的集合与元素 y 所在的集合合并成⼀个集合:
- 让元素 x 所在树的根节点指向元素 y 所在树的根节点。
// 合并操作
void un(int x, int y) // 注意,函数名字不能⽤ union,因为它是 C++ 的关键字
{int fx = find(x);int fy = find(y);// 让元素 x 所在树的根节点指向元素 y 所在树的根节点。fa[fx] = fy;
}
4.判断
判断元素 x 和元素 y 是否在同⼀集合:
- 看看两者所在树的根节点是否相同。
// 合并操作
// 判断是否在同⼀集合
bool issame(int x, int y)
{return find(x) == find(y);
}
3.2普通并查集
P3367 【模板】并查集
3.3拓展并查集
普通的并查集只能解决各元素之间仅存在⼀种相互关系,比如《亲戚》题目中:
• a 和 b 是亲戚关系, b 和 c 是亲戚关系,这时就可以查找出 a 和 c 也存在亲戚关系。
但如果存在各元素之间存在多种相互关系,普通并查集就无法解决。比如下面的案例:
• a和 b是敌⼈关系, b和 c是敌人关系,但是 a和 c其实不是敌人关系,而是另⼀种朋友关系。
此时,就不仅仅是简单的敌⼈关系,还是出现⼀种朋友关系。
解决这类问题就需要对并查集进行扩展:将每个元素拆分成多个域,每个域代表⼀种状态或者关系。
通过维护这些域之间的关系,来处理复杂的约束条件。
下例中,若1与2是敌人且2与3是敌人那么1和3就在同一个集合中,则1与3是朋友
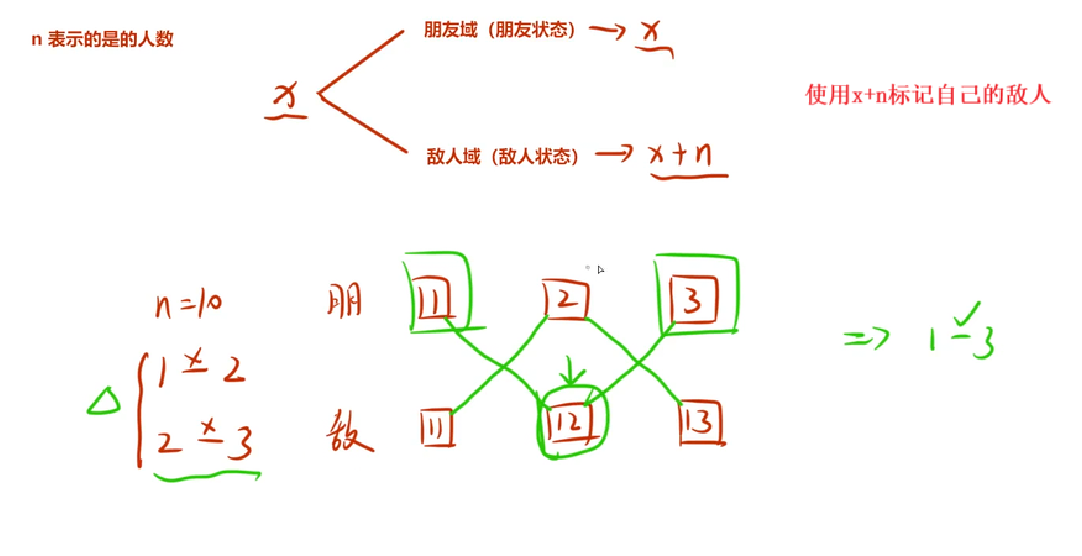
以下题为例实现:关键在于将敌人的敌人合并
P1892 [BalticOI 2003] 团伙
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
//https://www.luogu.com.cn/problem/P1892
using namespace std;
const int N = 1e3 + 10;
// 拓展并查集int n, m, p, q;
char opt;
int fa[N*2];int find(int x)
{if (fa[x] == x)return x;return fa[x] = find(fa[x]);
}
// 使朋友域元素为父节点
void un(int x, int y)
{int fx = find(x), fy = find(y);fa[fy] = fx;
}
int main()
{cin >> n >> m;for (int i = 1; i <= 2 * n; ++i)fa[i] = i;while (m--){cin >> opt >> p >> q;if (opt == 'F'){un(p, q);}else{//敌人的敌人是朋友un(p, q + n);un(q, p + n);}}int res = 0;for (int i = 1; i <= n; ++i){if (fa[i] == i)res++;}cout << res << endl;return 0;
}
3.4带权并查集
1.带权并查集的概念
带权并查集在普通并查集的基础上,为每个结点增加了⼀个权值。这个权值可以表示当前结点与父结点之间的关系、距离或其他信息(注意,由于我们有路径压缩操作,所以最终这个权值表示的是当前结点相对于根结点的信息)。有了这样⼀个权值,就可以推断出集合中各个元素之间的相互关系。
2.带权并查集的实现
实现⼀个能够查询任意两点之间距离的并查集。实现带权并查集的核心是在进行 Find 和 Union 操作时,不仅要维护集合的结构,还要维护结点的权值。
基本操作:
const int N = 1e5 + 10, INF = 0x3f3f3f3f;
int n;
int fa[N], d[N];
// 初始化
void init()
{for(int i = 1; i <= n; i++){fa[i] = i;d[i] = 0; // 根据题⽬要求来初始化,这里表示到父节点距离}
}// 查询操作
int find(int x)
{if(fa[x] == x) return x;int t = find(fa[x]); // 这句代码⼀定要先执⾏,先缩短路径// 更新到根节点的距离d[x] += d[fa[x]]; // 会根据权值的意义有所改变return fa[x] = t;
}// 合并操作
// x 所在集合与 y 所在集合合并,x 与 y 之间的权值是 w
void un(int x, int y, int w)
{int fx = find(x), fy = find(y);if(fx != fy) // 不在同⼀个集合中{fa[fx] = fy;// 更新到根节点的距离d[fx] = d[y] + w - d[x]; // 会根据权值的意义有所改变}
}
4.字符串哈希
-
什么是字符串哈希:
定义⼀个把字符串映射到整数的函数 ,这就是字符串哈希。即将⼀个字符串用一个整数表示。 -
字符串哈希中的哈希函数:
在字符串哈希中,有⼀种冲突概率较小的哈希函数,将字符串映射成 p 进制数字:
hash(s)=∑i=0n−1s[i]×pn−i−1(modM)hash(s) = \sum_{i=0}^{n-1} s[i] \times p^{n-i-1} \pmod{M}hash(s)=i=0∑n−1s[i]×pn−i−1(modM) -
前缀哈希数组:
一般使用前缀和存储每个前缀的哈希值,这样的话每次就能快速求出子串的哈希了。
// 处理前缀哈希数组以及 p 的 i 次⽅数组
void init_hash()
{f[0] = 0; p[0] = 1;for(int i = 1; i <= len; i++){f[i] = f[i - 1] * P + s[i];p[i] = p[i - 1] * P;}
}// 快速求得任意区间的哈希值
ULL get_hash(int l, int r)
{return f[r] - f[l - 1] * p[r - l + 1];
}
将f[i]映射成p进制数,则f[i] = f[i - 1] * P + s[i];
若要求出中间某一段的哈希值,将目标字符串、f[r]、f[l-1]表示出来找出他们之间的关系,表示如下

例子:
P3370 【模板】字符串哈希
5.Trie树
- Trie 树又叫字典树或前缀树,是⼀种能够快速插入和查询字符串的数据结构。它利用字符串的公共前缀,将字符串组织成⼀棵树形结构。
我们可以把字典树想象成⼀棵多叉树,每一条边代表⼀个字符,从根节点到某个节点的路径就代表了一个字符串。例如,要存储 “abc” 、 “abd” 、 “acde” 以及 “cd” 时,构建的字典树如下:
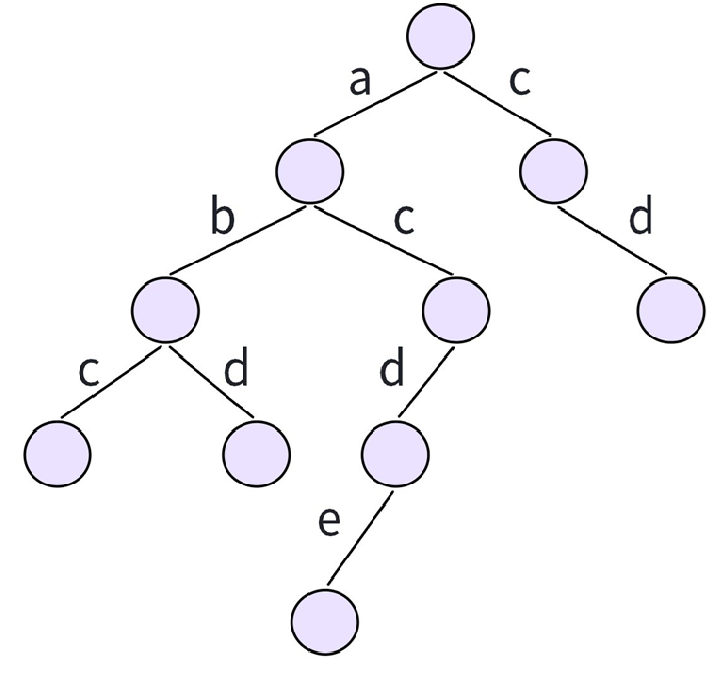
- 字典树的作用
查询某个单词是否出现过,并且出现几次;
查询有多少个单词是以某个字符串为前缀;
查询所有以某个前缀开头的单词;(这个作用可以用到输入法中,输入拼音的时候,可以提示可能的单词) - 字典树的实现
实现一个能够查询单词出现次数以及查询有多少个单词是以某个字符串为前缀的字典树,默认全是小写字母。
// 字典树 经过这个节点的字符串
int tr[N][62], p[N];
// 新插入节点的编号
int idx;
int t, n, q;
// 查询是哪个字符
int get_num(char ch)
{if (ch >= 'a' && ch <= 'z')return ch - 'a';else if (ch >= 'A' && ch <= 'Z')return ch - 'A' + 26;else return ch - '0' + 52;
}// 插入字典树
void insert(string& s)
{int cur = 0;// 从根结点开始p[cur]++;// 这个格⼦经过⼀次for (auto ch : s){int path = get_num(ch);if (tr[cur][path] == 0)tr[cur][path] = ++idx;// 迭代到下一个路径cur = tr[cur][path];p[cur]++;}e[cur]++;
}
// 查询特定前缀字符串个数
int find_pre(string& s)
{int cur = 0;for (auto ch : s){int path = get_num(ch);if (tr[cur][path] == 0)return 0;cur = tr[cur][path];}// 查询从这个格子经过的所有字符串return p[cur];
}// 查询字符串出现次数
int find(string& s)
{int cur = 0;for(auto ch : s){int path = ch - 'a';if(tree[cur][path] == 0) return 0;cur = tree[cur][path];}return e[cur];
}例子:
P8306 【模板】字典树
![[机器学习]08-基于逻辑回归模型的鸢尾花数据集分类](http://pic.xiahunao.cn/[机器学习]08-基于逻辑回归模型的鸢尾花数据集分类)















 错误,请按照以下详细步骤操作:)


