
项目背景
随着我国高速铁路运营里程突破4.5万公里,动车组日均开行超过8000列次,传统人工巡检方式已无法满足密集运行下的安全检测需求。车底关键部件如制动系统、悬挂装置、牵引电机等长期承受高强度振动和冲击,易产生疲劳裂纹、螺栓松动、部件脱落等安全隐患,亟需自动化检测手段保障运营安全。而检测系统面临极端物理挑战:动车350km/h高速通过检测区,有效检测时间仅4-5秒;车底空间狭窄且光照极差,自然光几乎无法到达;强烈气流扰动和轨道振动影响成像稳定性;检测目标尺寸差异大,从毫米级裂纹到米级部件;恶劣天气和隧道环境要求系统具备全天候作业能力。整体上,检测系统需要实现动车底部全覆盖无盲区检测,识别部件缺失、表面裂纹、异常磨损、螺栓松动等多类缺陷;检测精度达到3mm级别,召回率超过95%;实时处理能力满足不停车通过式检测;系统具备自动报警和缺陷定位功能,支持历史数据追溯分析。

针对此应用场景,目前面临的难题是突破高速运动模糊成像,实现清晰图像采集;解决车底复杂结构下的小目标精确识别;克服样本不均衡条件下的异常检测;构建高可靠性实时处理系统架构。
为解决此问题,我们采用"高速采集+智能识别+边缘计算"融合方案:部署2000fps线阵相机阵列配合同步频闪补光,冻结高速运动;基于改进YOLOv8的深度学习模型,引入可变形卷积和注意力机制增强特征提取;集成PatchCore无监督异常检测应对稀缺缺陷样本;边缘计算分布式架构实现数据就近处理,光纤汇聚保证实时性;多模态融合提升检测鲁棒性和准确率。
数据采集方案设计
在高速运动场景下的数据采集是整个系统的基础。考虑到动车运行速度可达350km/h,我们需要在轨道两侧部署线阵相机阵列,采用每米间隔布置的方式确保无盲区覆盖。相机选用10GigE接口的工业相机,帧率设定为2000fps,配合1/10000秒的快门速度来冻结高速运动。为解决车底光照不足问题,采用高频LED频闪补光系统,与相机快门同步触发,确保每帧都有充足且均匀的照明。
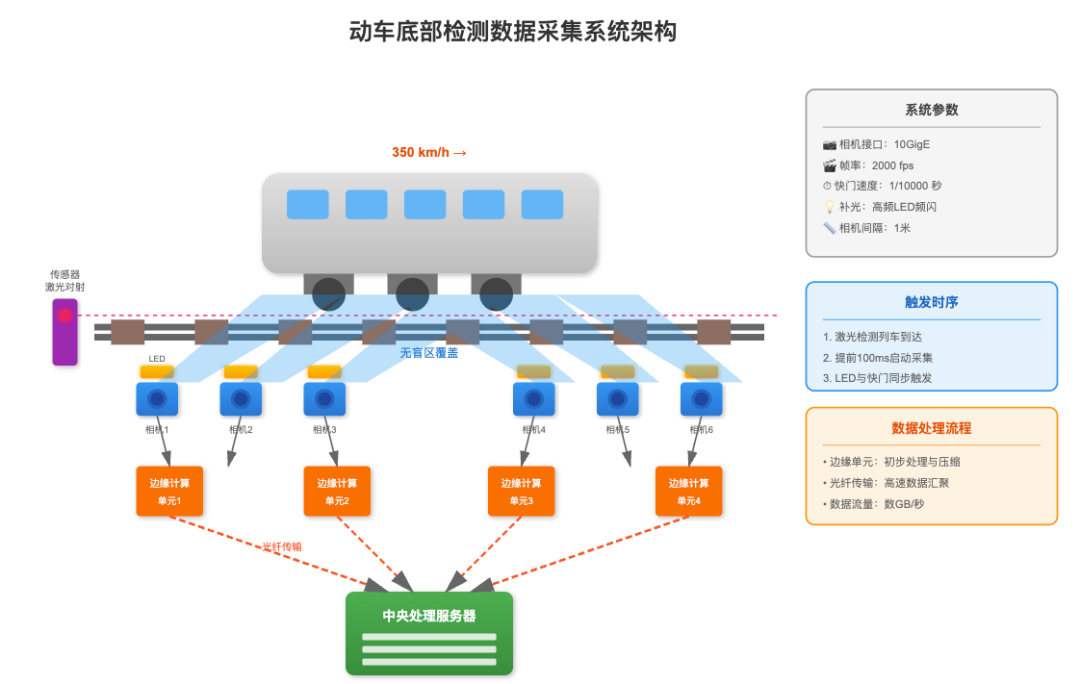
数据采集触发机制采用激光对射传感器检测列车到达,提前100毫秒启动采集系统。每个相机配置独立的边缘计算单元进行初步处理和压缩,通过光纤将数据汇总到中央处理服务器。这种分布式采集架构能够应对每秒数GB的数据流量,同时保证系统的可靠性。
数据预处理策略
原始图像的预处理采用多阶段级联优化架构。运动去模糊环节基于维纳滤波,通过PSF核估计(核大小k=v×t/p,v为速度,t为曝光时间,p为像素尺寸)实现快速复原。采用CLAHE算法(clipLimit=2.0,tileGridSize=8×8)处理局部对比度,配合双边滤波(σ_color=75,σ_space=15)保边去噪。
多视角图像配准使用SURF特征(Hessian阈值400)提取关键点,通过RANSAC剔除误匹配后计算单应性矩阵H。连续帧采用Lucas-Kanade稀疏光流实现亚像素配准,金字塔层数设为3,迭代收敛阈值ε<0.01。ROI提取基于预定义的CAD模板匹配,使用归一化互相关(NCC)定位部件区域,将4096×3072的原始图像裁剪为多个512×512的目标区域,计算复杂度降低93.75%。
模型选择与对比分析
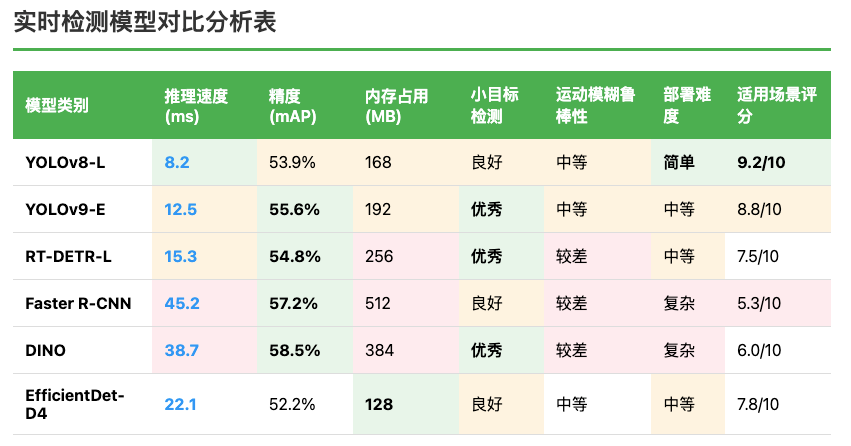
基于对比分析,YOLOv8-L在实时性、精度和部署便利性之间取得了最佳平衡。其8.2毫秒的推理速度远超实时要求,同时保持了53.9%的检测精度。相比其他模型,YOLOv8在工程化程度上更加成熟,拥有完善的部署工具链和优化方案,这对于工业应用至关重要。
算法改进方案
针对动车底部检测的特殊需求,需要对基础YOLOv8模型进行多方面改进。首先是网络架构的优化,在backbone部分引入可变形卷积(Deformable Convolution),使模型能够自适应地调整感受野形状,更好地匹配车底部件的不规则形态。在neck部分,除了原有的FPN结构,额外添加自底向上的路径聚合,形成双向特征金字塔,增强多尺度特征的语义信息传递。
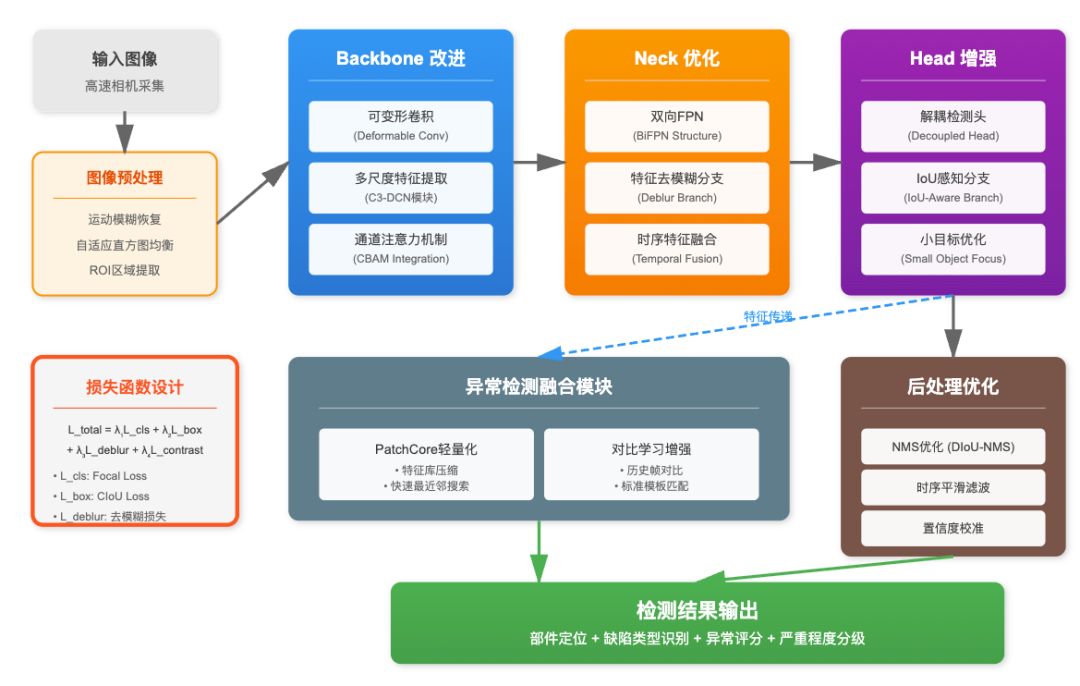
图:YOLOv8动车底部零部件检测算法改进方法
检测头去模糊分支设计
检测头的改进重点在于增强对运动模糊的鲁棒性。设计了一个轻量级的去模糊分支,与检测分支并行工作。该分支采用空洞卷积扩大感受野,其输出特征图计算如下:
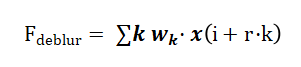
其中 r ∈ {1, 2, 4} 为空洞率
通道注意力机制通过全局平均池化和多层感知机生成通道权重:
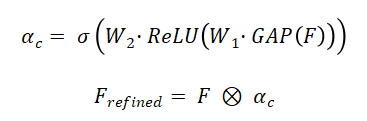
其中,σ为Sigmoid函数,W₁、W₂为可学习参数,GAP为全局平均池化,⊗表示通道级乘法。
多任务损失函数设计
总损失函数采用加权多任务学习策略:
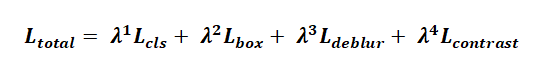
分类损失采用Focal Loss解决样本不平衡:
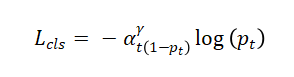
其中pt为预测概率,αt为类别权重,γ=2为聚焦参数。
定位损失使用CIoU Loss提升回归精度:
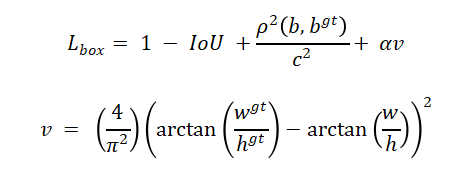
其中ρ为欧氏距离,c为最小包围框对角线长度,α为权重系数。
去模糊损失通过特征级L2约束实现:
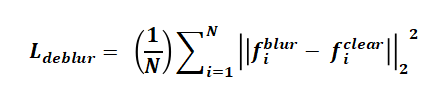
对比学习损失采用InfoNCE形式:
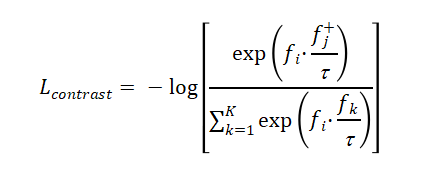
其中fj+为正样本特征,τ=0.07为温度参数。
异常检测PatchCore优化
改进的PatchCore通过知识蒸馏压缩特征库。教师模型特征FT到学生模型特征FS的蒸馏损失为:
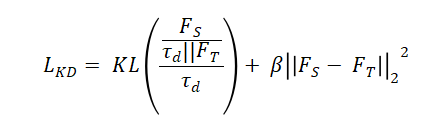
特征库采用增量式更新,新特征加入判定条件:
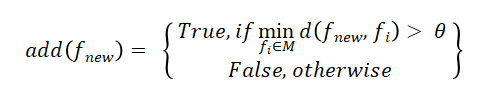
其中M为现有特征库,d(·)为余弦距离,θ=0.15为相似度阈值。
异常分数计算使用FAISS加速的k-NN搜索:
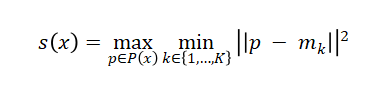
其中P(x)为测试图像的patch特征集,mk为特征库中第k个最近邻,查询复杂度从O(N)降至O(logN)。权重系数通过网格搜索确定:λ₁=1.0,λ₂=5.0,λ₃=0.5,λ₄=0.1,在验证集上取得最优性能平衡。
训练参数配置与优化策略
训练阶段策略
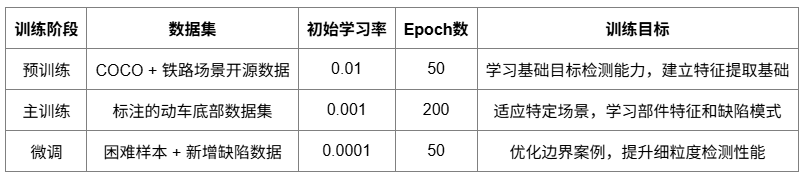
采用渐进式三阶段训练策略,逐步提升模型的检测能力和领域适应性。
数据增强策略
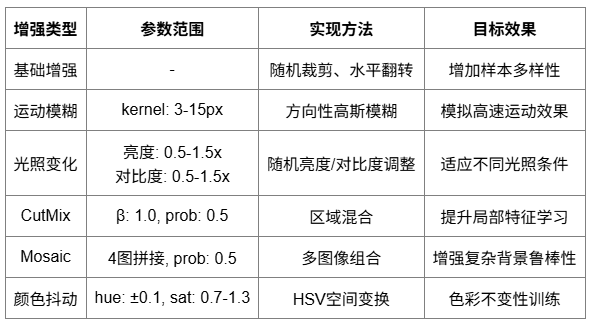
特别设计的数据增强策略,充分模拟高速运动场景下的各种挑战。
优化器配置
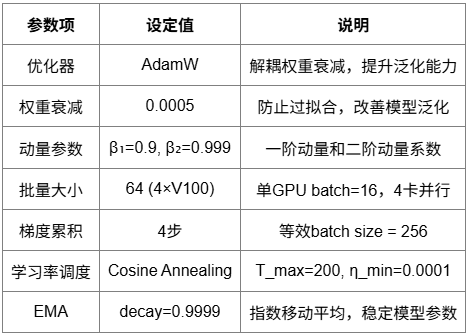
采用AdamW优化器,配合多种优化技术提升训练稳定性和收敛速度。
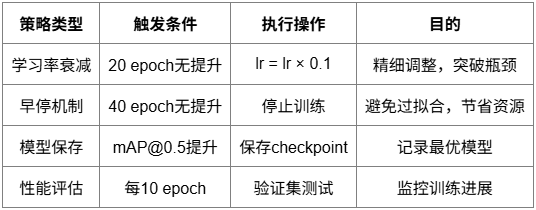
训练控制策略
采用多重控制机制确保训练效率和模型质量。
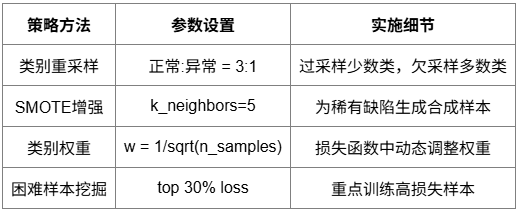
数据平衡策略
解决类别不平衡问题,确保模型对各类缺陷的检测能力。
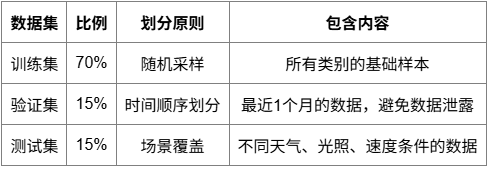
数据集划分原则
严格的数据集划分策略,确保模型评估的可靠性。
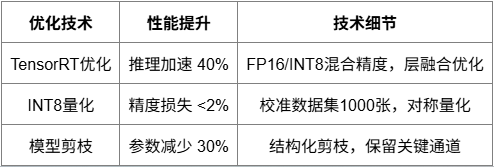
模型部署优化
通过量化和优化技术,实现高效的模型部署。
系统部署与工程化实施
模型优化与压缩策略
训练完成的YOLOv8模型需要经过系统化的优化才能满足实际部署要求。首先采用INT8量化技术,通过校准数据集计算量化参数,在保持精度损失小于2%的前提下,将模型大小压缩至原来的25%,推理速度提升约40%。对于模型剪枝,采用结构化剪枝策略,根据通道重要性评分移除冗余卷积核,剪枝率控制在30%左右,确保关键特征提取能力不受影响。
知识蒸馏作为补充优化手段,使用原始大模型作为教师网络,训练轻量级学生网络,通过软标签和特征图匹配实现性能传递。最终部署模型保持原始模型92%以上的检测精度,同时推理速度提升2.5倍。
推理加速部署架构
采用NVIDIA TensorRT作为核心推理引擎,充分利用GPU的并行计算能力。模型转换流程包括ONNX中间格式导出、TensorRT引擎构建和优化策略配置。启用FP16混合精度推理,配合动态批处理和多流并发机制,单张V100 GPU可达到180FPS的处理速度。
多GPU并行处理采用数据并行策略,设计智能负载均衡算法根据各GPU实时负载动态分配任务。实现了GPU故障自动切换机制,当某个GPU出现异常时,系统自动将任务重新分配到其他可用GPU,保证系统的高可用性。通过CUDA统一内存管理减少数据传输开销,使用零拷贝技术直接处理相机采集的图像数据。
实时数据流处理架构
构建基于生产者-消费者模式的流式处理框架。数据采集层使用多线程并发接收各相机数据流,通过环形缓冲区实现无锁数据交换。预处理层采用SIMD指令集加速图像增强操作,批量处理提高吞吐量。
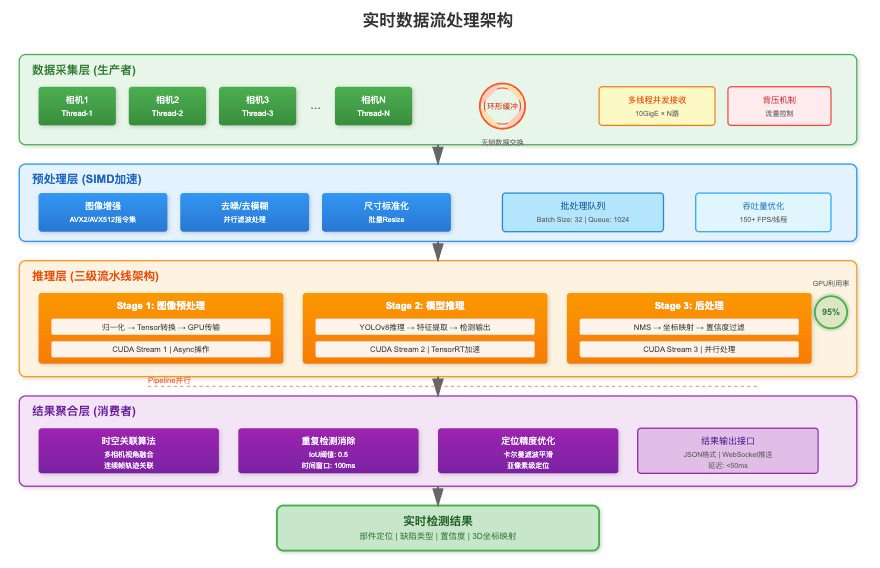
推理层实现了三级流水线架构:图像预处理、模型推理和后处理并行执行,最大化GPU利用率。结果聚合层使用时空关联算法,将多相机、多帧的检测结果进行融合,消除重复检测,提高定位精度。整个数据流采用背压机制控制处理速度,避免内存溢出。
边缘-云端协同部署
边缘计算节点部署轻量级模型进行初筛,筛选出可疑区域后将高分辨率图像上传至云端进行精细分析。边缘端使用NVIDIA Jetson AGX Xavier,运行优化后的MobileNet-YOLOv8变体,实现100FPS的初步检测。云端部署完整模型阵列,使用Kubernetes容器编排实现弹性扩缩容。
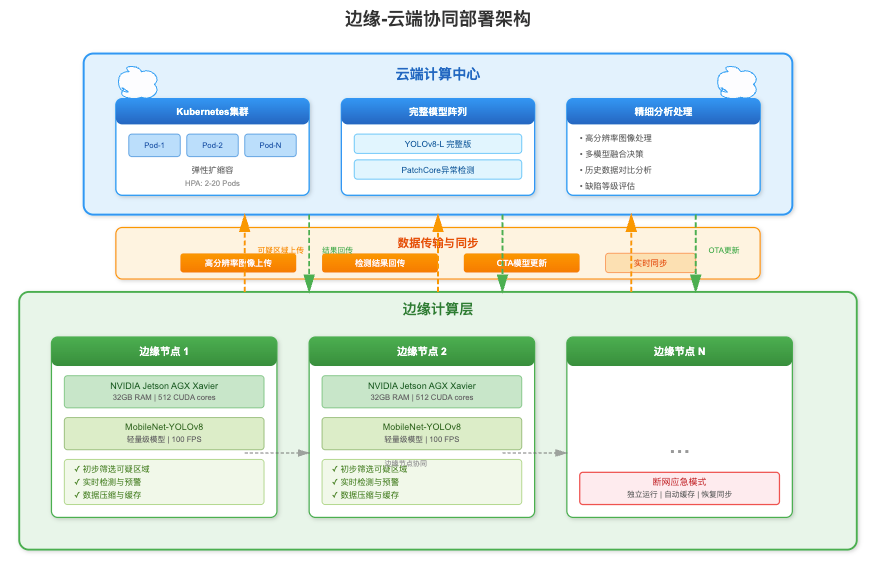
建立边缘-云端数据同步机制,检测结果实时回传,模型更新通过OTA方式推送。实现了断网应急模式,边缘端可独立完成基础检测任务,网络恢复后自动同步数据。
评估指标与测试方案
评估指标体系设计
建立多维度综合评估体系,全面衡量系统性能。检测精度指标采用COCO评估标准,包括mAP@0.5和mAP@0.5:0.95,分别评估常规检测和精细定位能力。针对不同缺陷类型分别计算AP值,重点关注关键安全缺陷的检测性能。召回率要求整体达到95%以上,其中裂纹、脱落等严重缺陷召回率需达到98%。
实时性指标包括端到端延迟和吞吐量两个维度。系统延迟从图像采集到结果输出控制在50ms以内,满足350km/h速度下的实时检测要求。吞吐量指标要求单节点处理能力不低于150FPS,支持多路相机并发处理。引入P99延迟指标,确保99%的请求在100ms内完成。
鲁棒性评估设计了多场景测试矩阵,包括不同光照条件(强光、弱光、逆光)、天气状况(晴天、雨雪、雾霾)、运行速度(100-350km/h)的交叉组合。定义性能衰减率指标,要求极端条件下检测精度下降不超过10%。
分阶段测试方案
算法验证阶段:基于采集的历史数据构建测试集,包含10万张标注图像,覆盖20类常见缺陷。采用5折交叉验证评估模型泛化能力,通过数据增强模拟各种环境条件。设计对抗样本测试,验证模型的鲁棒性。此阶段预期mAP达到55%以上。
仿真测试阶段:搭建半实物仿真平台,使用高速摄像系统在实验室环境下模拟列车通过场景。通过可控光源和人工缺陷样本,系统化测试不同参数组合下的检测效果。构建数字孪生系统,在虚拟环境中进行极限工况测试。预期在仿真环境下系统综合性能达到设计指标的90%。
现场试运行阶段:选择2-3条运营线路进行试点部署,采用"影子模式"运行,即系统检测但不影响正常运营。收集为期3个月的运行数据,对比人工检测结果计算准确率。根据现场反馈迭代优化算法,重点解决误报和漏报问题。建立问题跟踪机制,对每个异常案例进行根因分析。
长期稳定性监测
部署自动化测试框架,每日定时运行回归测试,监控模型性能变化趋势。建立性能基准线,当指标偏离超过阈值时自动告警。实施A/B测试机制,新版本模型与现有模型并行运行对比。
设计压力测试方案,模拟高峰期多列车连续通过场景,验证系统在高负载下的稳定性。进行7×24小时连续运行测试,监控内存泄漏、性能衰减等问题。建立故障注入测试机制,模拟硬件故障、网络中断等异常情况,验证系统的容错能力。
通过季度性能评估报告跟踪系统长期表现,分析性能变化原因,持续优化系统。建立缺陷样本库动态更新机制,将新发现的缺陷类型纳入训练集,保持模型的时效性。预期系统在一年运行周期内,可用性保持99.9%以上,检测准确率稳定在95%以上。




)















