目录
一、函数栈帧(Stack Frame)整理
1、核心概念
2、为什么需要函数栈帧?
3、函数栈帧的主要内容
二、理解函数栈帧能解决的核心问题
1、局部变量的生命周期与本质
2、函数调用的参数传递机制
3、函数返回值的传递
三、函数栈帧的创建和销毁解析
1、什么是栈(Stack)?
2、认识相关寄存器和汇编指令
a) 相关寄存器
b) 相关汇编指令
3、解析函数栈帧的创建和销毁
1. 预备知识
2. 函数的调用堆栈
3. 准备环境
4. 转到反汇编
5. 函数栈帧的创建
小知识:烫烫烫~
Add函数的传参
函数调用过程
6. 函数栈帧的销毁
拓展了解
一、函数栈帧(Stack Frame)整理
1、核心概念
函数栈帧(也称为活动记录)是函数被调用时,在程序的调用栈(Call Stack) 上为其分配的一块内存空间。它用于支持函数的执行和管理函数调用过程。
2、为什么需要函数栈帧?
C程序以函数为基本单位。当一个函数调用另一个函数时,需要解决以下几个关键问题,而函数栈帧正是解决这些问题的机制:
-
函数参数如何传递?
-
函数内部的局部变量如何存储?
-
函数调用结束后,如何返回到正确的位置继续执行?
-
函数的返回值如何传递给调用者?
-
函数执行前后,如何保证调用者寄存器的状态不被破坏?
3、函数栈帧的主要内容
一块函数栈帧通常包含以下几类信息:
-
函数参数与返回值:存储传递给被调用函数的参数以及函数返回时的返回值。
-
临时变量:
-
函数的非静态局部变量。
-
编译器自动生成的其他临时变量。
-
-
上下文信息:
-
调用函数的返回地址(调用指令下一条指令的地址)。
-
调用函数的栈帧基地址,用于在当前函数返回后恢复调用者的栈帧。
-
为保持函数调用前后不变而需要保存的寄存器值。
-
二、理解函数栈帧能解决的核心问题
深入理解函数栈帧的创建和销毁过程,就像是获得了C语言函数底层工作机制的“地图”,许多令人困惑的语法现象和编程难题都会变得清晰明了。具体来说,它能帮助我们彻底理解以下关键问题:
1、局部变量的生命周期与本质
-
局部变量是如何创建的?:它们并非凭空产生,而是在其所属函数的栈帧被创建时,在栈上分配了内存空间。所谓的“创建”,就是移动栈指针来预留一块足够大的内存。
-
为什么局部变量不初始化内容是随机的?:因为“创建”仅仅是在栈上分配了空间,而这片空间之前很可能被其他函数使用过,残留着之前的数据。如果不主动初始化(赋值),直接使用该内存的值,看到的自然就是不可预测的“随机值”或“垃圾值”。
2、函数调用的参数传递机制
-
函数调用时参数是如何传递的?:通常不是在被调用函数的栈帧里直接“变出”参数。而是由调用者将自己的实参(的值或地址)压入栈中(或存入约定的寄存器)。随后,被调用函数才能在自己的栈帧中找到这些参数。
-
传参的顺序是怎样的?:理解栈帧可以清楚地看到,参数通常是从右向左依次压入栈中(超重要!!!)。这是为了支持像
printf这样的可变参数函数。 -
形参和实参的关系:形参其实就是函数栈帧中为参数预留的位置。在函数被调用时,实参的值会被拷贝(复制) 到形参所在的内存中。因此,形参是实参的一份副本,修改形参(在大多数情况下)不会影响实参,这解释了为何值传递是有效的。
3、函数返回值的传递
-
函数的返回值是如何带回的?:通常,返回值不会通过栈帧的主要部分传递。而是通过一个特定的寄存器(如
eax/rax)来存储并带回给调用者。如果返回值较大,可能会采用调用者预先分配空间并传入地址等其他机制。
总结而言,理解函数栈帧就是将编程语言中“函数调用”这个抽象概念,转化为CPU和内存中“分配空间、拷贝数据、跳转指令、恢复现场”等一系列具体操作的过程。这是连接高级语言语法和计算机底层逻辑的关键桥梁。让我们一同深入分析函数栈帧创建和销毁的详细过程。
三、函数栈帧的创建和销毁解析
1、什么是栈(Stack)?
栈是现代计算机程序中一个至关重要的基础概念。它支撑着函数调用、局部变量管理等核心功能,可以说没有栈,就没有我们现在看到的高级编程语言。
栈被定义为一个遵守 “后进先出”(Last In First Out, LIFO) 原则的特殊容器。
-
操作:数据可以压入(Push) 栈顶,也可以从栈顶弹出(Pop)。
-
规则:最先压入的数据最后弹出,最后压入的数据最先弹出。(类比:叠放的盘子,总是取最上面的那个,最下面的盘子是最后才能被取到的)。
在计算机系统的具体实现中:
-
栈是一块动态的内存区域。
-
压栈(Push) 使栈增大,出栈(Pop) 使栈减小。
-
在经典的操作系统(如i386, x86-64架构)中,栈的增长方向是向下的,即从高地址向低地址扩展。
-
栈顶的位置由一个名为
esp(Stack Pointer) 的专用寄存器来定位和跟踪。
2、认识相关寄存器和汇编指令
理解函数栈帧的操作需要了解一些关键的底层硬件寄存器和汇编指令。
a) 相关寄存器
| 寄存器 | 全称与用途 |
|---|---|
eax | 通用寄存器,通常用于存储临时数据和函数的返回值。 |
ebx | 通用寄存器,用于保留临时数据。 |
ebp | 栈底指针寄存器 (Base Pointer),用于定位当前函数栈帧的底部。在函数执行过程中,其值通常保持稳定,从而可以通过ebp方便地访问参数和局部变量。 |
esp | 栈顶指针寄存器 (Stack Pointer),始终指向系统栈的最顶部(下一个可用的最低地址)。push和pop操作都会直接改变esp的值。 |
eip | 指令指针寄存器 (Instruction Pointer),保存着CPU下一条要执行的指令的地址。程序的执行流程就是由eip的指向决定的。 |
b) 相关汇编指令
| 汇编指令 | 功能描述 |
|---|---|
mov | 数据转移指令。例如 mov eax, ebx 将ebx的值拷贝到eax中。 |
push | 数据入栈。1. 先将esp的值减小(栈向下增长)。2. 再将数据写入新的栈顶地址。 |
pop | 数据出栈。1. 先将esp指向的数据读出来。2. 再将esp的值增加(栈收缩)。 |
sub | 减法指令。常用于减小esp的值来为函数局部变量开辟空间。例如 sub esp, 0Ch |
add | 加法指令。常用于增加esp的值来回收函数局部变量的空间。例如 add esp, 0Ch |
call | 函数调用指令。它主要做两件事: 1. 压入返回地址:将 call指令的下一条指令的地址压入栈中。2. 转入目标函数:修改 eip,开始执行被调用函数的代码。 |
jump | 跳转指令。通过直接修改eip寄存器的值,来改变程序的执行流程。 |
ret | 函数返回指令。它的作用类似于 pop eip,即将call指令压入栈的返回地址弹出,并放入eip寄存器中,从而使程序跳回到调用者函数中继续执行。 |
3、解析函数栈帧的创建和销毁
1. 预备知识
首先我们达成一些预备知识才能有效的帮助我们理解,函数栈帧的创建和销毁。
- 每一次函数调用,都要为本次函数调用开辟空间,就是函数栈帧的空间。
- 这块空间的维护是使用了2个寄存器: esp 和 ebp , ebp 记录的是栈底的地址, esp 记录的是栈顶的地址。
如图所示:
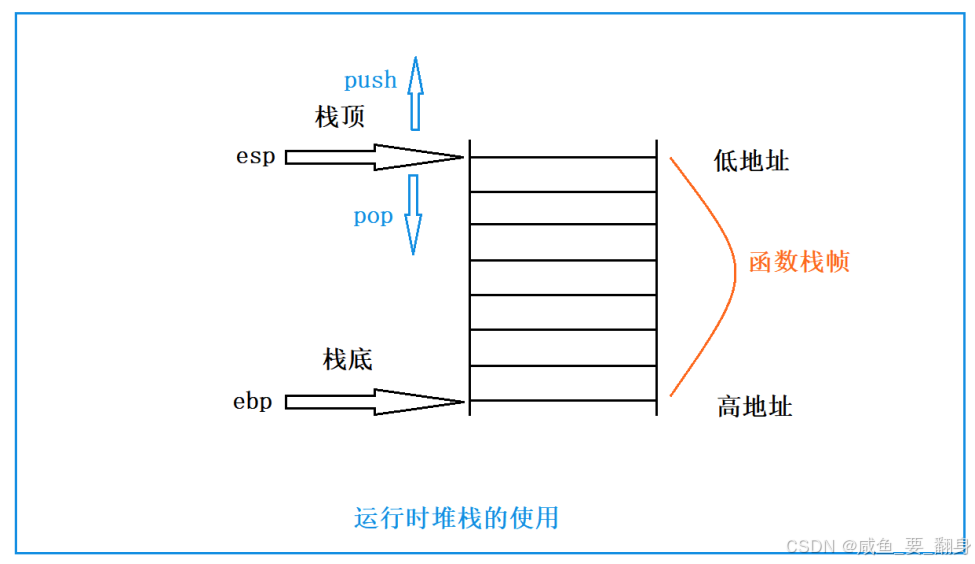
- 函数栈帧的创建和销毁过程,在不同的编译器上实现的方法大同小异,本次演示以VS2019为例。
2. 函数的调用堆栈
演示代码:
#include <stdio.h>int Add(int x, int y)
{int z = 0;z = x + y;return z;
}int main()
{int a = 3;int b = 5;int ret = 0;ret = Add(a, b);printf("%d\n", ret);return 0;
}
这段代码,如果我们在VS2019编译器上调试,调试进入Add函数后,我们就可以观察到函数的调用堆栈 (右击勾选【显示外部代码】),如下图:
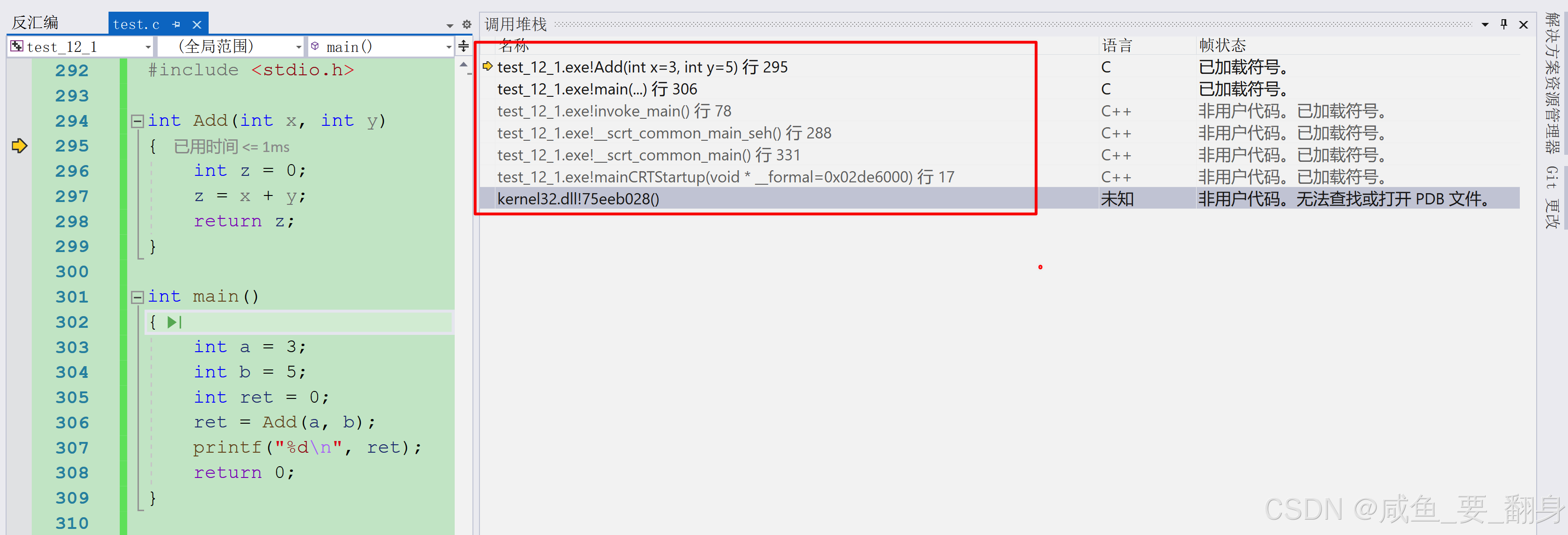
函数调用堆栈是反馈函数调用逻辑的,那我们可以清晰的观察到, main 函数调用之前,是由 invoke_main 函数来调用main函数。 在 invoke_main 函数之前的函数调用我们就暂时不考虑了。那我们可以确定, invoke_main 函数应该会有自己的栈帧, main 函数和 Add 函数也会维护自己的栈帧,每个函数栈帧都有自己的 ebp 和 esp 来维护栈帧空间。 那接下来我们从main函数的栈帧创建开始讲解:
3. 准备环境
为了让我们研究函数栈帧的过程足够清晰,不要太多干扰,我们可以关闭下面的选项,让汇编代码中排除一些编译器附加的代码,首先右击“解决方案”栏中的项目,打开如下,跟着步骤来:
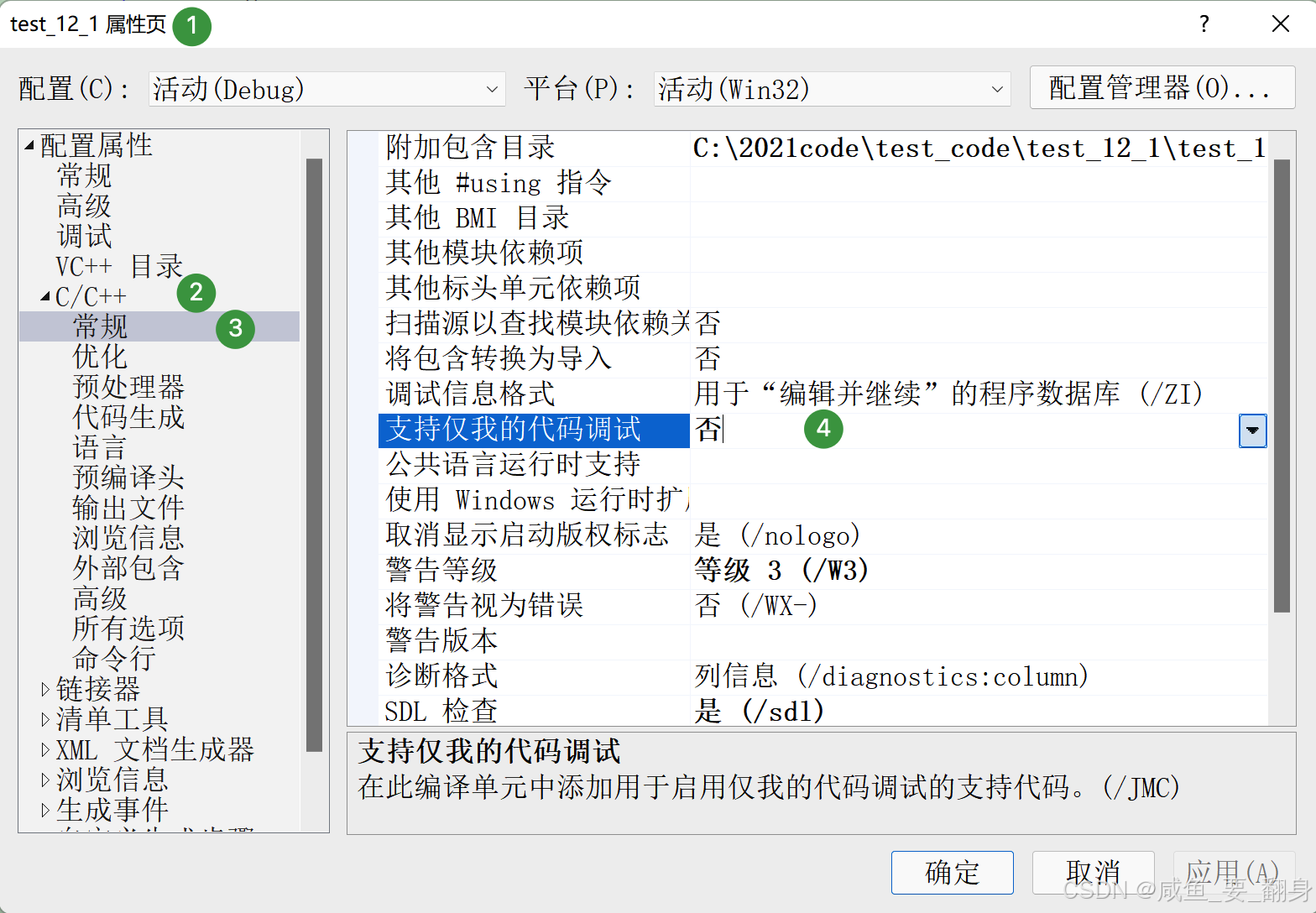
4. 转到反汇编
调试到main函数开始执行的第一行,右击鼠标找到“反汇编”选项并点击,转到反汇编。 注:VS编译器每次调试都会为程序重新分配内存,博客中的反汇编代码是一次调试代码过程中数据,每次调试略有差异。
int main()
{
//函数栈帧的创建
00BE1820 push ebp
00BE1821 mov ebp,esp
00BE1823 sub esp,0E4h
00BE1829 push ebx
00BE182A push esi
00BE182B push edi
00BE182C lea edi,[ebp-24h]
00BE182F mov ecx,9
00BE1834 mov eax,0CCCCCCCCh
00BE1839 rep stos dword ptr es:[edi]
//main函数中的核心代码int a = 3;
00BE183B mov dword ptr [ebp-8],3 int b = 5;
00BE1842 mov dword ptr [ebp-14h],5 int ret = 0;
00BE1849 mov dword ptr [ebp-20h],0 ret = Add(a, b);
00BE1850 mov eax,dword ptr [ebp-14h]
00BE1853 push eax
00BE1854 mov ecx,dword ptr [ebp-8]
00BE1857 push ecx
00BE1858 call 00BE10B4
00BE185D add esp,8
00BE1860 mov dword ptr [ebp-20h],eax printf("%d\n", ret);
00BE1863 mov eax,dword ptr [ebp-20h]
00BE1866 push eax
00BE1867 push 0BE7B30h
00BE186C call 00BE10D2
00BE1871 add esp,8 return 0;
00BE1874 xor eax,eax
}
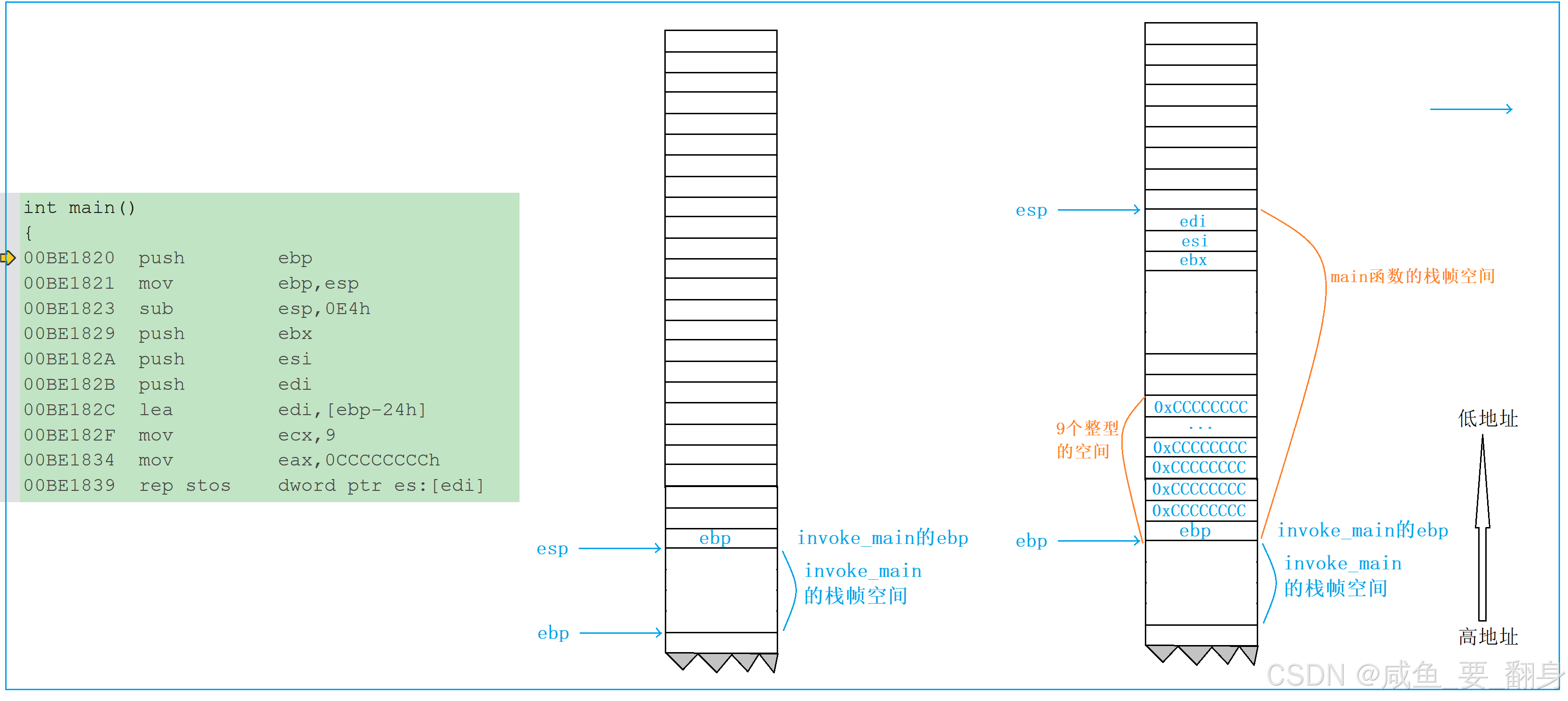
5. 函数栈帧的创建
这里看到 main 函数转化来的汇编代码如上所示。 接下来我们就一行行拆解汇编代码
00BE1820 push ebp //把ebp寄存器中的值进行压栈,此时的ebp中存放的是invoke_main函数栈帧的ebp,esp-4
00BE1821 mov ebp,esp //move指令会把esp的值存放到ebp中,相当于产生了main函数的ebp,这个值就是invoke_main函数栈帧的esp
00BE1823 sub esp,0E4h //sub会让esp中的地址减去一个16进制数字0xe4,产生新的esp,此时的esp是main函数栈帧的esp,此时结合上一条指令的ebp和当前的esp,ebp和esp之间维护了一个块栈空间,这块栈空间就是为main函数开辟的,就是main函数的栈帧空间,这一段空间中将存储main函数中的局部变量,临时数据已经调试信息等。
00BE1829 push ebx //将寄存器ebx的值压栈,esp-4
00BE182A push esi //将寄存器esi的值压栈,esp-4
00BE182B push edi //将寄存器edi的值压栈,esp-4
//上面3条指令保存了3个寄存器的值在栈区,这3个寄存器的在函数随后执行中可能会被修改,所以先保存寄存器原来的值,以便在退出函数时恢复。//下面的代码是在初始化main函数的栈帧空间。
//1. 先把ebp-24h的地址,放在edi中
//2. 把9放在ecx中
//3. 把0xCCCCCCCC放在eax中
//4. 将从edp-0x2h到ebp这一段的内存的每个字节都初始化为0xCC
00BE182C lea edi,[ebp-24h]
00BE182F mov ecx,9
00BE1834 mov eax,0CCCCCCCCh
00BE1839 rep stos dword ptr es:[edi]上面的这段代码最后4句,等价于下面的伪代码:
edi = ebp-0x24;
ecx = 9;
eax = 0xCCCCCCCC;
for(; ecx = 0; --ecx,edi+=4)
{*(int*)edi = eax;
}
小知识:烫烫烫~
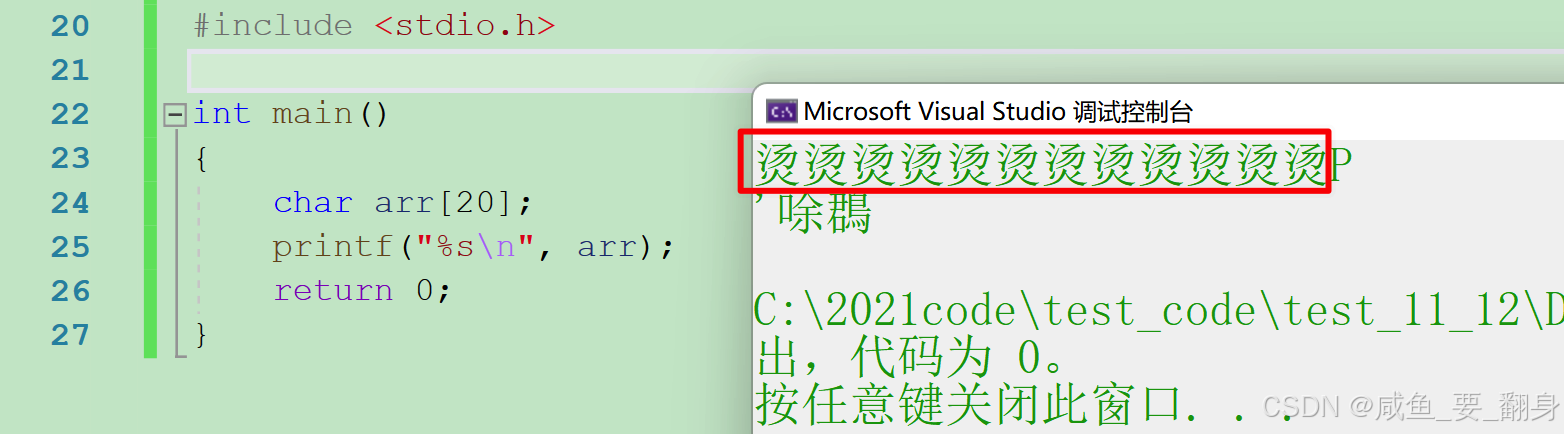
之所以上面的程序输出“烫”这么一个奇怪的字,是因为main函数调用时,在栈区开辟的空间的其中每一 个字节都被初始化为0xCC,而arr数组是一个未初始化的数组,恰好在这块空间上创建的,0xCCCC(两 个连续排列的0xCC)的汉字编码就是“烫”,所以0xCCCC被当作文本就是“烫”。接下来我们再分析main函数中的核心代码:
int a = 3;
00BE183B mov dword ptr [ebp-8],3 //将3存储到ebp-8的地址处,ebp-8的位置其实就是a变量int b = 5;
00BE1842 mov dword ptr [ebp-14h],5 //将5存储到ebp-14h的地址处,ebp-14h的位置其实是b变量int ret = 0;
00BE1849 mov dword ptr [ebp-20h],0 //将0存储到ebp-20h的地址处,ebp-20h的位置其实是ret变量
//以上汇编代码表示的变量a,b,ret的创建和初始化,这就是局部的变量的创建和初始化
//其实是局部变量的创建时在局部变量所在函数的栈帧空间中创建的
//调用Add函数ret = Add(a, b);
//调用Add函数时的传参
//其实传参就是把参数push到栈帧空间中
00BE1850 mov eax,dword ptr [ebp-14h] //传递b,将ebp-14h处放的5放在eax寄存器中
00BE1853 push eax //将eax的值压栈,esp-4
00BE1854 mov ecx,dword ptr [ebp-8] //传递a,将ebp-8处放的3放在ecx寄存器中
00BE1857 push ecx //将ecx的值压栈,esp-4
//跳转调用函数
00BE1858 call 00BE10B4
00BE185D add esp,8
00BE1860 mov dword ptr [ebp-20h],eax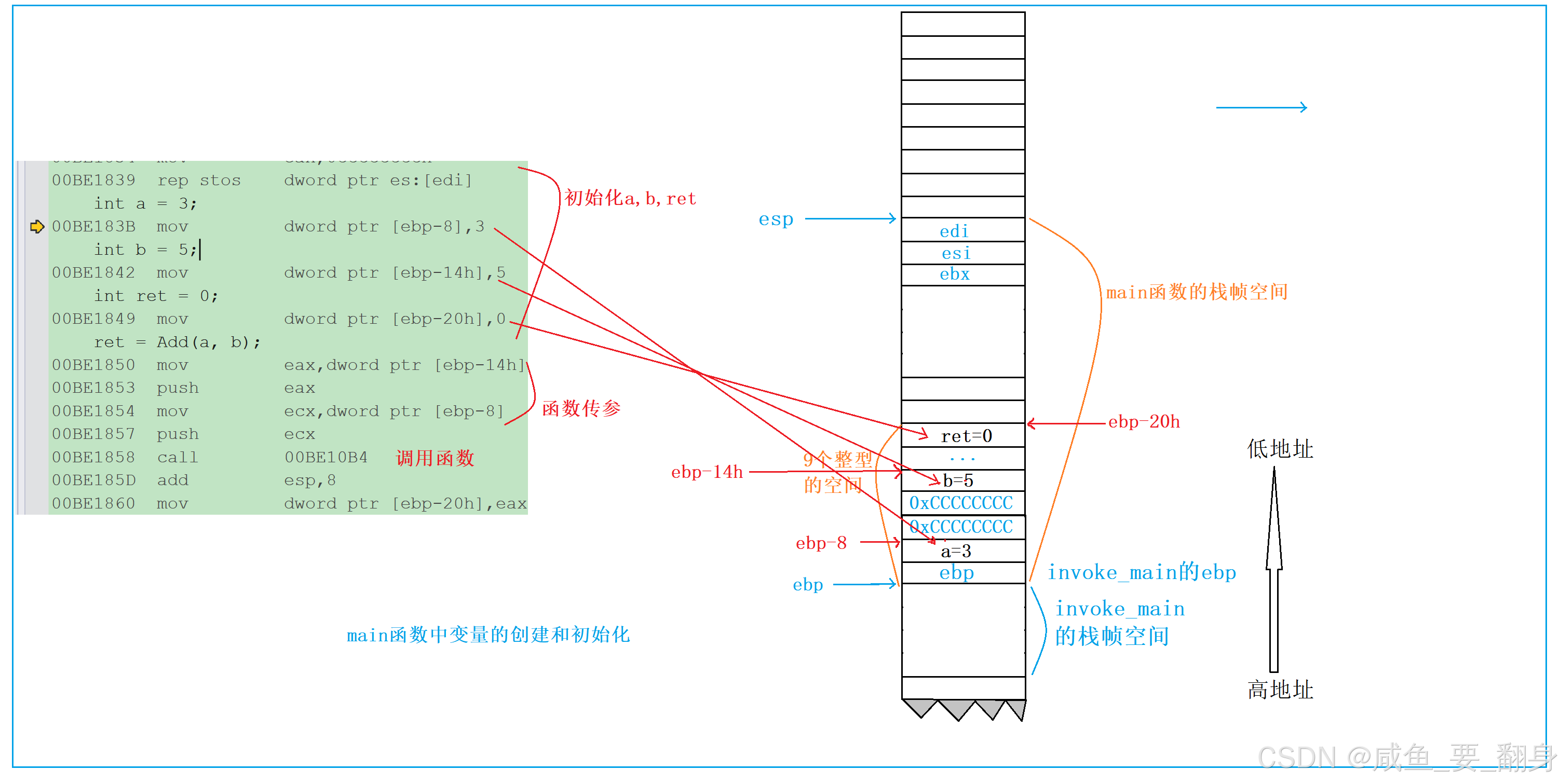
Add函数的传参
//调用Add函数ret = Add(a, b);
//调用Add函数时的传参
//其实传参就是把参数push到栈帧空间中,这里就是函数传参
00BE1850 mov eax,dword ptr [ebp-14h] //传递b,将ebp-14h处放的5放在eax寄存器
中
00BE1853 push eax //将eax的值压栈,esp-4
00BE1854 mov ecx,dword ptr [ebp-8] //传递a,将ebp-8处放的3放在ecx寄存器中
00BE1857 push ecx //将ecx的值压栈,esp-4
//跳转调用函数
00BE1858 call 00BE10B4
00BE185D add esp,8
00BE1860 mov dword ptr [ebp-20h],eax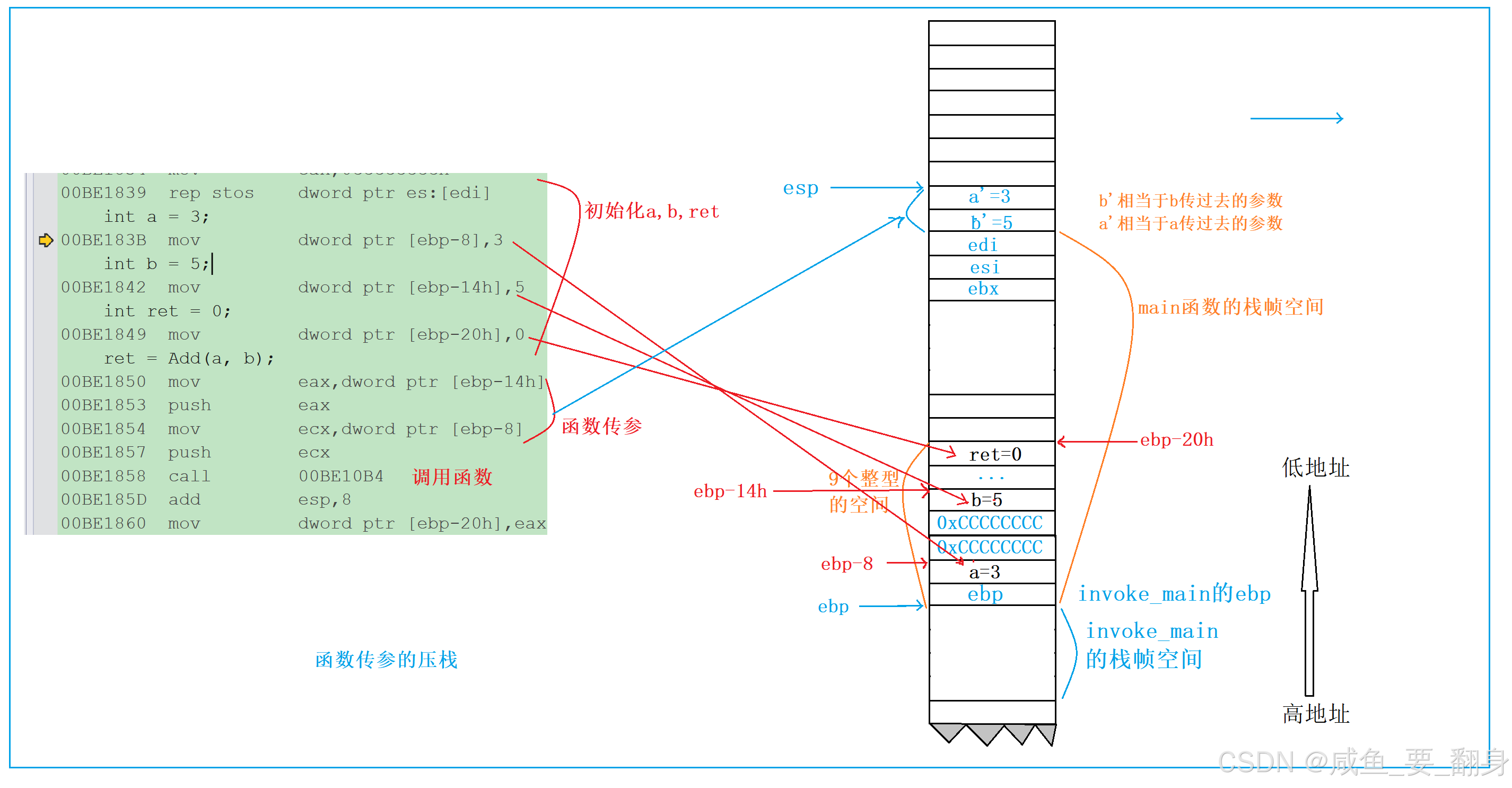
函数调用过程
//跳转调用函数
00BE1858 call 00BE10B4
00BE185D add esp,8
00BE1860 mov dword ptr [ebp-20h],eaxcall 指令是要执行函数调用逻辑的,在执行call指令之前先会把call指令的下一条指令的地址进行压栈操作,这个操作是为了解决当函数调用结束后要回到call指令的下一条指令的地方,继续往后执行。
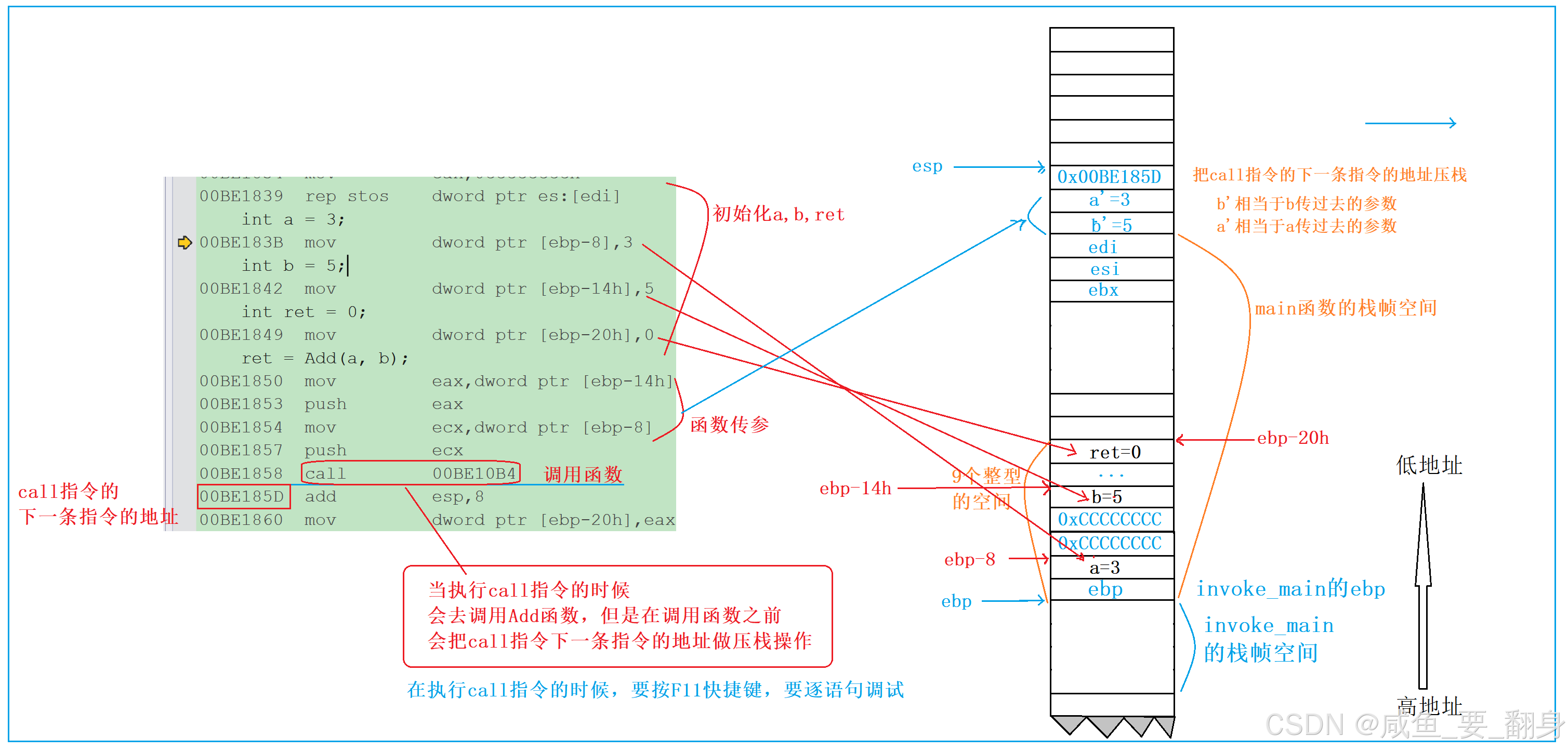
当我们跳转到Add函数,就要开始观察Add函数的反汇编代码了。
int Add(int x, int y)
{
00BE1760 push ebp //将main函数栈帧的ebp保存,esp-4
00BE1761 mov ebp,esp //将main函数的esp赋值给新的ebp,ebp现在是Add函数的ebp
00BE1763 sub esp,0CCh //给esp-0xCC,求出Add函数的esp
00BE1769 push ebx //将ebx的值压栈,esp-4
00BE176A push esi //将esi的值压栈,esp-4
00BE176B push edi //将edi的值压栈,esp-4int z = 0;
00BE176C mov dword ptr [ebp-8],0 //将0放在ebp-8的地址处,其实就是创建zz = x + y;//接下来计算的是x+y,结果保存到z中
00BE1773 mov eax,dword ptr [ebp+8] //将ebp+8地址处的数字存储到eax中
00BE1776 add eax,dword ptr [ebp+0Ch] //将ebp+12地址处的数字加到eax寄存中
00BE1779 mov dword ptr [ebp-8],eax //将eax的结果保存到ebp-8的地址处,其实就是放到z中return z;
00BE177C mov eax,dword ptr [ebp-8] //将ebp-8地址处的值放在eax中,其实就是把z的值存储到eax寄存器中,这里是想通过eax寄存器带回计算的结果,做函数的返回值。
}
00BE177F pop edi
00BE1780 pop esi
00BE1781 pop ebx
00BE1782 mov esp,ebp
00BE1784 pop ebp
00BE1785 ret 代码执行到Add函数的时候,就要开始创建Add函数的栈帧空间了。
在Add函数中创建栈帧的方法和在main函数中是相似的,在栈帧空间的大小上略有差异而已。
- 将main函数的 ebp 压栈
- 计算新的 ebp 和 esp
- 将 ebx , esi , edi 寄存器的值保存
- 计算求和,在计算求和的时候,我们是通过 ebp 中的地址进行偏移访问到了函数调用前压栈进去的参数,这就是形参访问。
- 将求出的和放在 eax 寄存器准备带回
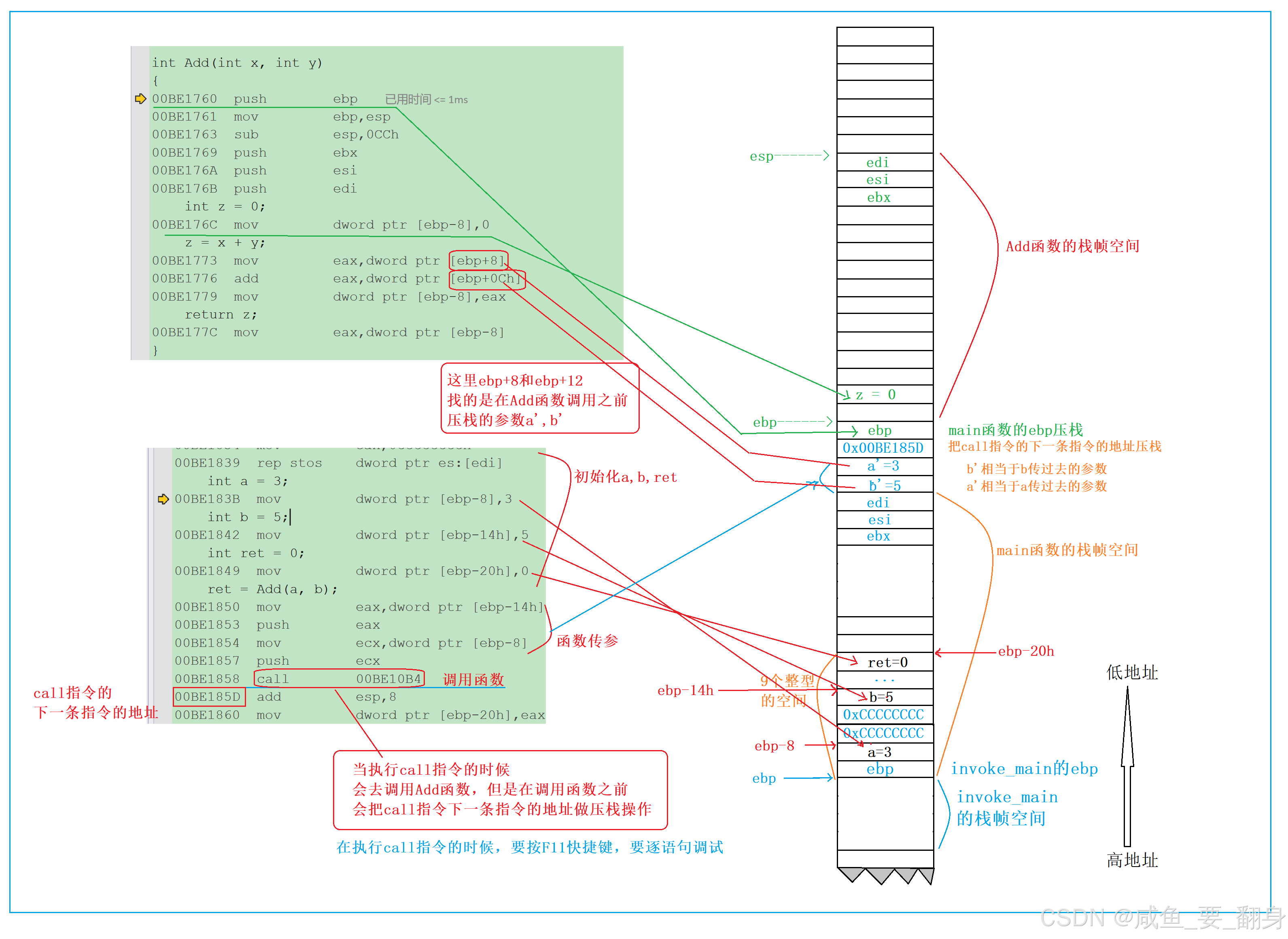
图片中的 a' 和 b' 其实就是 Add 函数的形参 x , y 。这里的分析很好的说明了函数的传参过程,以及函数在进行值传递调用的时候,形参其实是实参的一份拷贝。对形参的修改不会影响实参。
6. 函数栈帧的销毁
当函数调用要结束返回的时候,前面创建的函数栈帧也开始销毁。 那具体是怎么销毁的呢?我们看一下反汇编代码。
00BE177F pop edi //在栈顶弹出一个值,存放到edi中,esp+4
00BE1780 pop esi //在栈顶弹出一个值,存放到esi中,esp+4
00BE1781 pop ebx //在栈顶弹出一个值,存放到ebx中,esp+4
00BE1782 mov esp,ebp //再将Add函数的ebp的值赋值给esp,相当于回收了Add函数的栈帧空间
00BE1784 pop ebp //弹出栈顶的值存放到ebp,栈顶此时的值恰好就是main函数的ebp,esp+4,此时恢复了main函数的栈帧维护,esp指向main函数栈帧的栈顶,ebp指向了main函数栈帧的栈底。
00BE1785 ret //ret指令的执行,首先是从栈顶弹出一个值,此时栈顶的值就是call指令下一条指令的地址,此时esp+4,然后直接跳转到call指令下一条指令的地址处,继续往下执行。回到了call指令的下一条指令的地方:
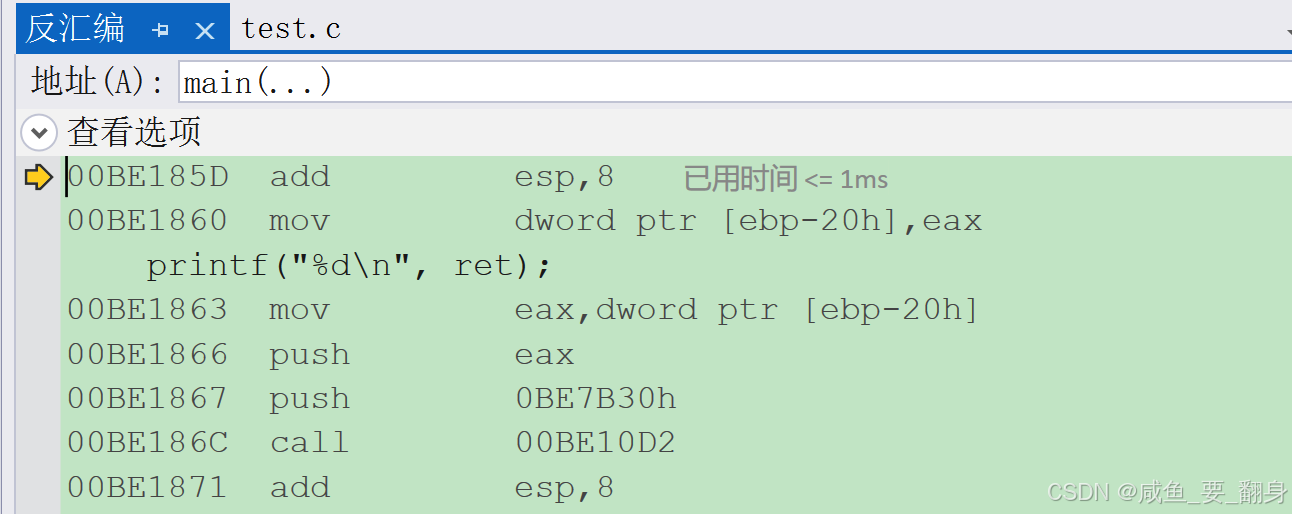
但调用完Add函数,回到main函数的时候,继续往下执行,可以看到:
00BE185D add esp,8 //esp直接+8,相当于跳过了main函数中压栈的 'a'和b'
00BE1860 mov dword ptr [ebp-20h],eax //将eax中值,存档到ebp-0x20的地址处,其实就是存储到main函数中ret变量中,而此时eax中就是Add函数中计算的x和y的和,可以看出来,本次函数的返回值是由eax寄存器带回来的。程序是在函数调用返回之后,在eax中去读取返回值的。拓展了解
其实返回对象时内置类型时,一般都是通过寄存器来带回返回值的,返回对象如果时较大的对象时,一般会在主调函数的栈帧中开辟一块空间,然后把这块空间的地址,隐式传递给被调函数,在被调函数中通过地址找到主调函数中预留的空间,将返回值直接保存到主调函数的。具体可以参考《程序员的自我修养》一书的第10章。
到这里我们给大家完整的演示了main函数栈帧的创建,Add函数栈帧的创建和销毁的过程,相信大家已经能够基本理解函数的调用过程,函数传参的方式,也能够回答开始的问题了。













![[n8n]](http://pic.xiahunao.cn/[n8n])
![[手写系列]Go手写db — — 第二版](http://pic.xiahunao.cn/[手写系列]Go手写db — — 第二版)



-记录实战教程及问题的解决方法-(day3-3)完善菜品分页查询功能)
