1 课程内容
- 网络信息内容获取技术
- 网络信息内容预处理技术
- 网络信息内容过滤技术
- 社会网络分析技术
- 异常流量检测技术
- 对抗攻击技术
2 对抗攻击概述
2.1 对抗攻击到底是啥?
咱们先举个生活例子:
你平时看苹果能认出来 —— 红颜色、圆溜溜、带个小揪揪。但如果有人给苹果轻轻贴了个小贴纸,或者在表皮涂了一点点几乎看不出来的颜料,你可能还是知道这是苹果;可要是给电脑 “看” 这个被改动的苹果,它说不定就认错了,说这是 “西红柿”。
这种故意给数据(比如图片、文字)做微小改动,骗人工智能(AI)认错的操作,就叫对抗攻击。
关键是这改动特别 “隐蔽”:人眼几乎看不出差别,但 AI 能被绕得晕头转向。
2.2 用 “骗 AI 认熊猫” 的例子,看攻击咋操作?
咱们拿 “AI 识别图片” 来拆解,一步一步看对抗攻击是咋干活的:
正常情况:AI 认熊猫很准
假设 AI 经过训练,能较为准确地识别 “熊猫” 的图片。

攻击者动手:给图片加 “隐形干扰”
攻击者不会把熊猫改成其它动物,而是加一种人眼几乎看不见的 “噪点”(就像给图片撒了一层超细微的 “灰尘”)。
-
改动后图片:看起来还是熊猫,但像素里藏了微小变化(下图右,实际肉眼难察觉)
-
重点:这种改动特别小,你拿手机对比原始图和改动图,可能都问 “这俩不是一样吗?”

AI “被骗”:把熊猫认成别的
当对抗图片传给 AI 后,神奇的事儿发生了:
- AI 判断:“这是长臂猿,准确率 99%”
- 原因:AI 认东西靠 “像素特征”,那些隐形噪点刚好打乱了 AI 认熊猫的 “关键线索”,让它把熊猫误判成长臂猿。
2.3 对抗攻击有啥用?(好的坏的都得说)
坏用途:搞破坏、钻漏洞
-
比如自动驾驶:有人给交通标志贴个 “隐形贴纸”(对抗攻击),让车的 AI 把 “停止 sign” 认成 “直行 sign”,可能引发事故。
-
比如人脸识别:给脸戴个特殊图案的口罩,让 AI 把 “张三” 认成 “李四”,绕过门禁。
好用途:帮 AI 变 “强壮”
现在很多 AI 工程师会主动搞对抗攻击 —— 故意制造 “骗 AI 的样本”,再用这些样本训练 AI,让 AI 学会 “识别陷阱”。就像老师故意出难题考学生,帮学生查漏补缺,最后 AI 面对真的攻击时,就不容易被骗了。
2.4 对抗攻击的主要分类
按攻击者知识:
白盒攻击:攻击者完全了解模型结构和参数,适用于基于梯度的攻击(如FGSM)。
黑盒攻击:攻击者无法访问模型内部,仅能通过查询输出生成攻击,如ZOO(Zeroth Order Optimization)
。
灰盒攻击:部分知识可用,例如知道模型类型但非具体参数。
按攻击目标:
定向攻击:强制模型输出特定错误类别(如将“猫”误判为“狗”)。
非定向攻击:仅需模型输出任何错误结果。
按实现步骤:
单步攻击:一次性生成扰动(如FGSM),速度快但效果有限。
迭代攻击:多步优化扰动(如BIM、PGD),效果更强但计算成本高。
3 对抗攻击的主要技术
对抗攻击技术可分为四大类:基于梯度的攻击、基于优化的攻击、基于决策面的攻击和其他方法。每种方法通过不同机制生成扰动。
3.1 基于梯度的攻击(Gradient-based Attacks)
这类方法利用模型的梯度信息生成扰动,通过反向传播计算损失函数对输入的导数,沿梯度方向添加噪声以最大化模型错误。优点是实现简单高效,尤其适合白盒场景。主要方法有:
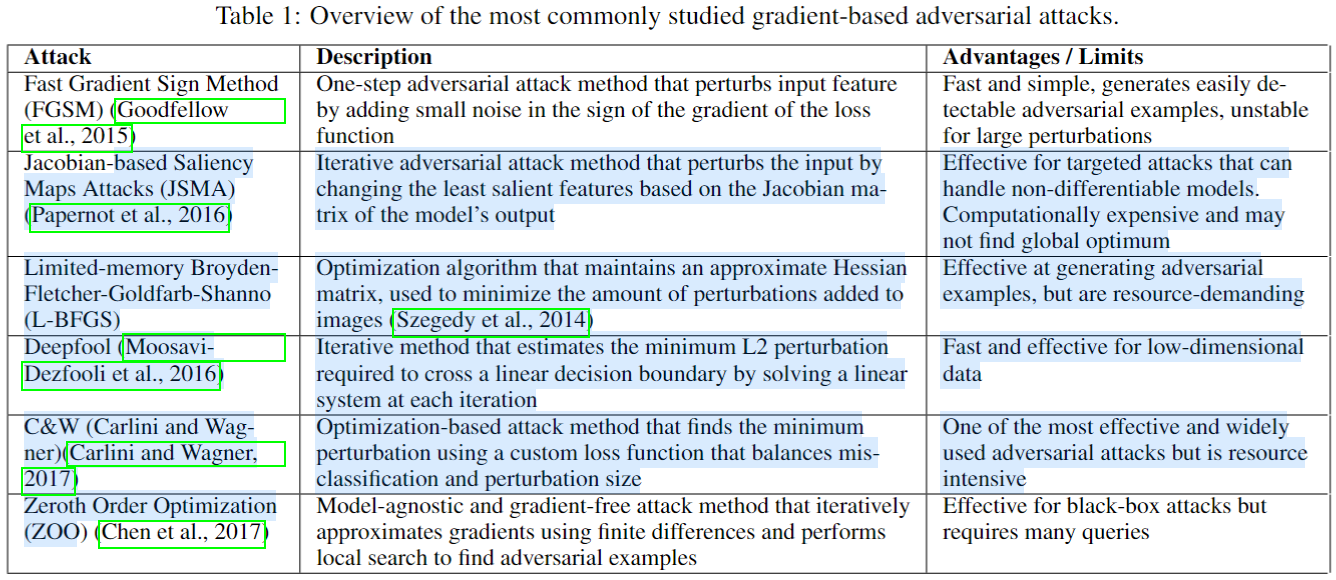
- FGSM(Fast Gradient Sign Method):单步攻击,沿梯度符号方向添加固定幅度扰动。速度快,但扰动较大易被检测。例如,在图像攻击中,通过一次梯度计算生成对抗样本 。
- BIM(Basic Iterative Method)或 I-FGSM(Iterative FGSM):FGSM的迭代版本,在多个小步中应用梯度更新,逐步优化扰动。效果比FGSM更强,但计算开销增加。
- PGD(Projected Gradient Descent):迭代攻击,在每次更新后投影扰动到允许范围内(如L∞L_∞L∞球),提高鲁棒性和攻击成功率。常被视为“最强”基准攻击 。
- MIM(Momentum Iterative Method) :在迭代中添加动量项,加速收敛并提升攻击迁移性,适合黑盒场景。
特点:基于梯度的攻击是基础,许多先进方法(如MI-FGSM)由此衍生。工具如cleverhans和advertorch支持实现。
3.2 基于优化的攻击(Optimization-based Attacks)
这类方法将攻击建模为优化问题,目标是最小化扰动大小(如L2范数)同时确保模型误分类。优点是可生成更隐蔽的对抗样本,但计算成本较高,适合高精度攻击。主要方法有:
- CW攻击(Carlini-Wagner Attack) :基于优化的经典方法,使用自定义损失函数平衡误分类和扰动大小。通过迭代最小化L2L_2L2、L0L_0L0或L∞L_∞L∞范数,生成高效且难以检测的对抗样本。是目前最广泛使用的攻击之一。
- L-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno) :优化算法,通过近似海森矩阵最小化扰动。资源密集但效果好,尤其在高维数据中。
- ZOO(Zeroth Order Optimization) :无梯度方法,使用有限差分近似梯度,适用于黑盒攻击。通过局部搜索生成对抗样本,查询次数多但模型无关。
特点:优化攻击常用于定向攻击,证据显示CW攻击在对抗训练评估中表现突出。
3.3 基于决策面的攻击(Decision-based Attacks)
这类方法直接操作模型的决策边界,通过估计最小扰动使输入跨越分类边界。优点是不依赖梯度,适用于非可微分模型。主要方法有:
- Deepfool:迭代方法,通过求解线性系统估计最小L2扰动以跨越决策超平面。速度快,适合低维数据。
- JSMA(Jacobian-based Saliency Maps Attacks) :基于模型输出的雅可比矩阵,迭代修改“最不重要”的特征(如像素),实现定向攻击。计算成本高但针对性强。
特点:决策面攻击强调隐蔽性,Deepfool常被用于评估模型鲁棒性。
3.4 其他方法
-
对抗性生成对抗网络(Adversarial GANs) :使用生成模型(如GAN)合成对抗样本,提升扰动自然性和鲁棒性。应用于图像和语音攻击。
-
Pointwise方法:未详细描述,但证据提到作为“其他”类别,可能涉及点级扰动生成。
-
物理对抗攻击:在真实世界中实现,包括:
** 基于二维样本的攻击:如贴纸或补丁干扰模型(例如,在交通标志上添加贴纸误导自动驾驶系统)。
** 基于3D实体的攻击:改变物体形状或纹理(如车辆涂装)。
** 无接触光影投射攻击:使用LED或激光投影干扰模型(如人脸识别系统)。
** 方法如EOT(Expectation Over Transformation)增强物理世界适应性。 -
NLP领域攻击:提到字符级、词级和句级攻击,通过操纵输入文本生成对抗样本,但本回答聚焦视觉主流技术。
4 总结
对抗攻击就像给 AI “下套”:用人类看不出来的小改动,打乱 AI 的判断逻辑,要么用来搞破坏,要么用来帮 AI 变得更厉害。

数据库迁移实战:Spring Boot项目完整迁移指南)



的用途)



:Transformer 架构详解(程序员视角・实战版))
:任务执行与切换)



)
)



