文章目录
- 一、Service原理
- 1.1概述
- 1.2为什么需要service
- 1.3service
- 1.4service类型
- 1.5service组件协同
- 二、configMap原理
- 2.1概述
- 2.2命令
- 2.3类型
- 三、volume
- 2.1emptydir
- 2.2hostPath
- 2.3pv/pvc
- 2.4storageClass
- 四、调度管理
- 3.1概念
- 3.2特点
- 3.3亲和性
- 3.4容忍和污点
- 3.5固定节点调度
- 五、etcd
- 5.1概述
- 5.2相关操作
- 查看告警事件
- 5.3etcd数据库相关操作
- 增加(put)
- 查询(get)
- 删除(del)
- 更新(put覆盖)
- 查询键历史记录查询
- 监听命令
- 监听单个键
- 同时监听多个键
- 租约命令
- 添加租约
- 查看租约
- 租约续约
- 删除租约
- 多key同一租约
- 备份恢复命令
- 生成快照
- 查看快照
- 恢复快照
- 备份恢复演示
一、Service原理
1.1概述
暴漏服务的重要方式
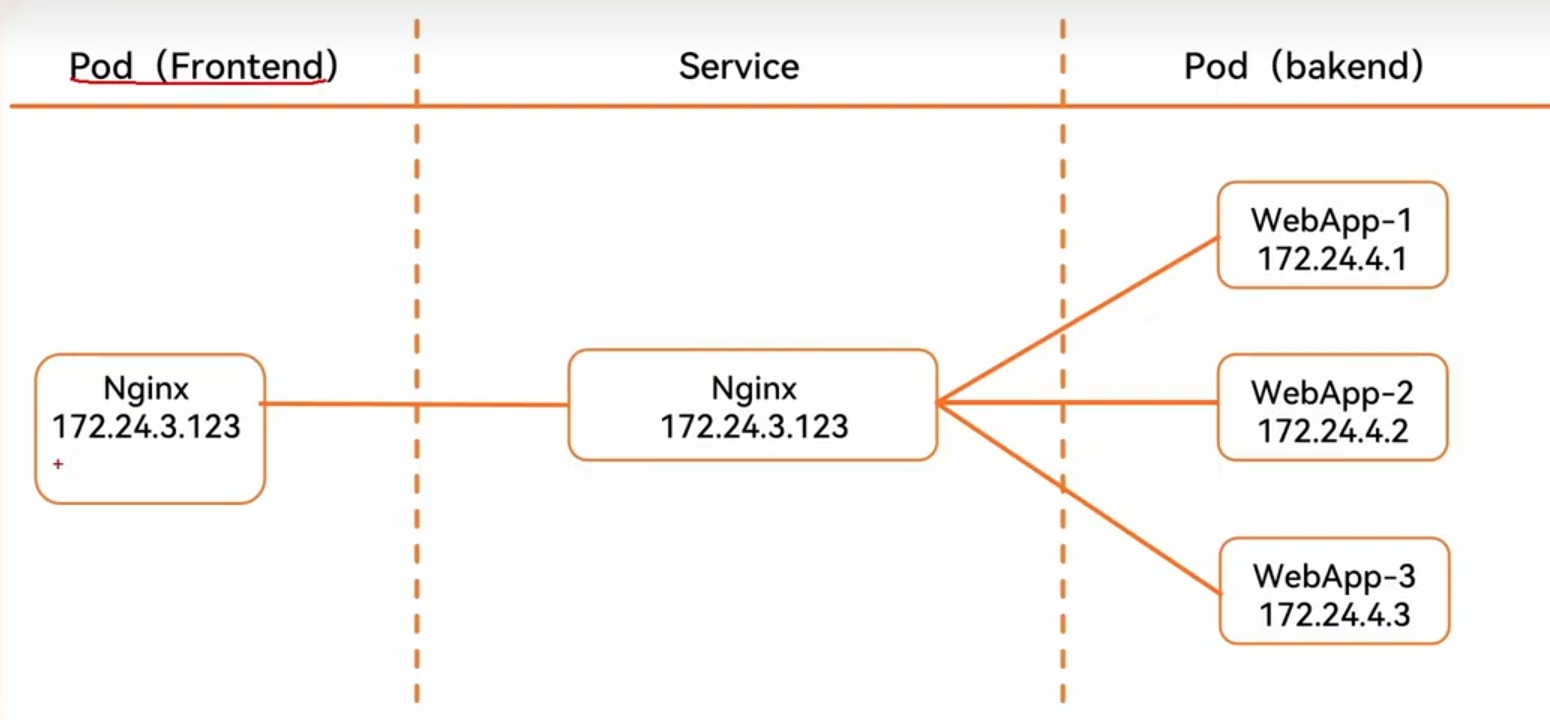
KubernetesService定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们的策略-- 通常称为微服务。这一组Pod能够被Service访问到,通常是通过’Label Selector
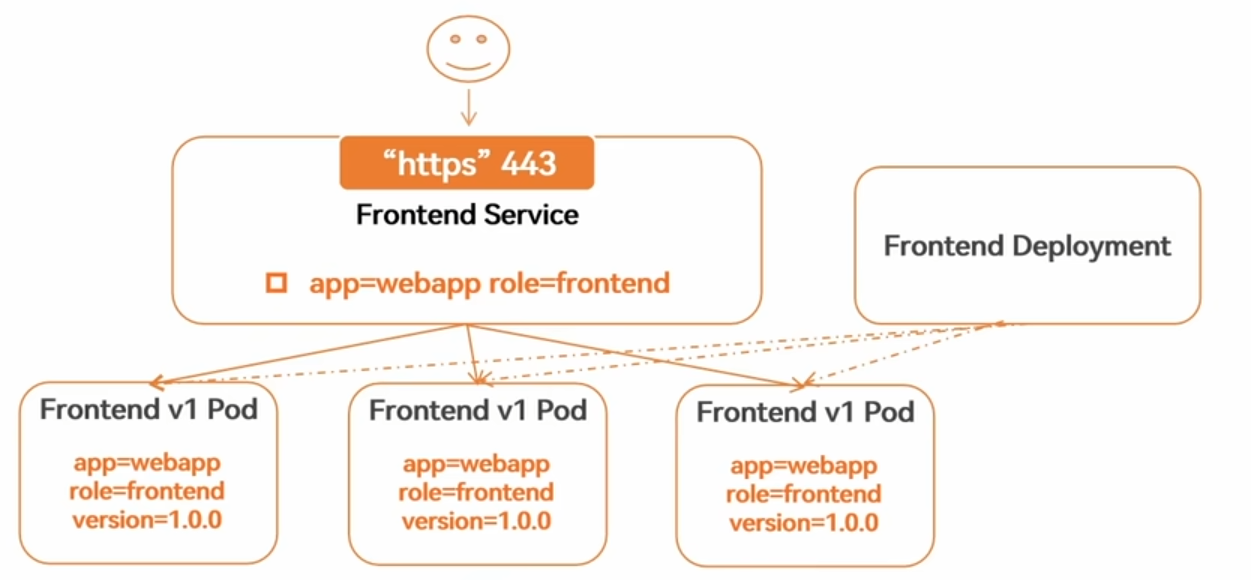
1.2为什么需要service
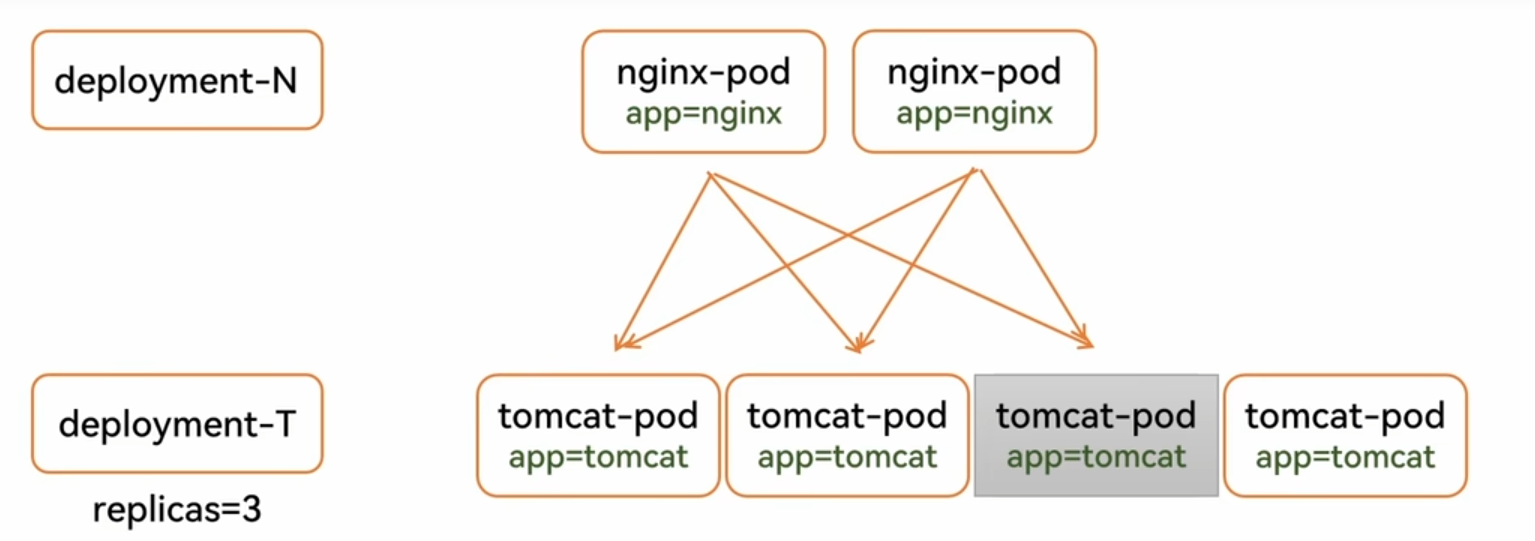
如果不用service可以实现如图的效果,部署nginx和tomcat,但是如果tomcat的pod坏了一台,deployment会创建新的Pod,但是pod的ip变化了,之前可以实现负载均衡,但是现在ip变了,负载均衡无法代理到新的pod ip上
如果我们中间加了service
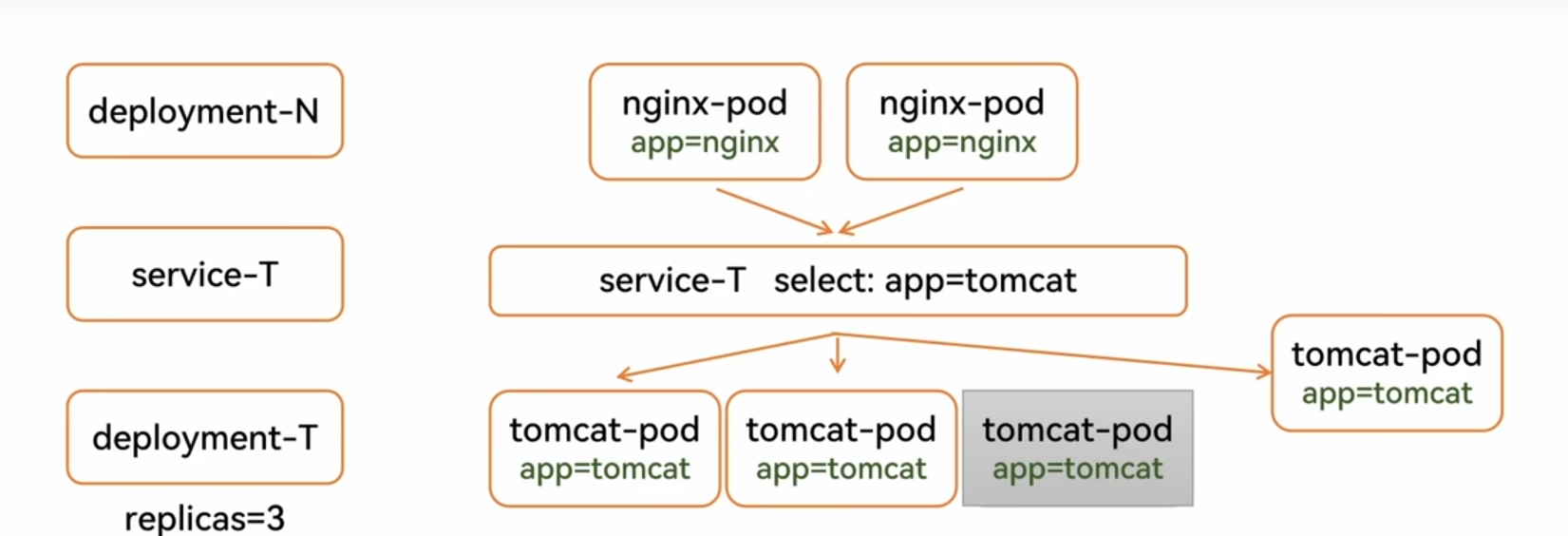
service:标签选择器和集群
不管Pod如何更新,都会被加入到负载均衡集群
1.3service

service-userspace:
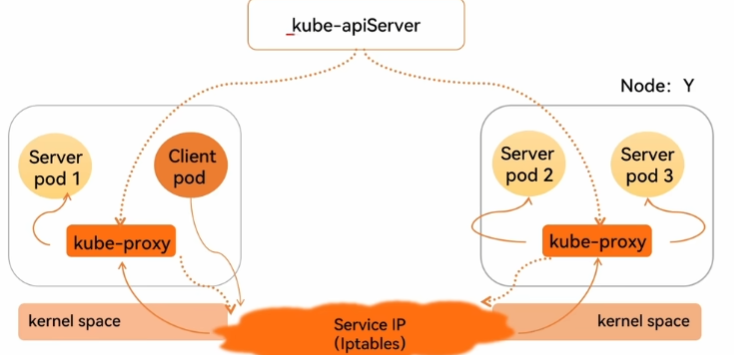
service-iptables:
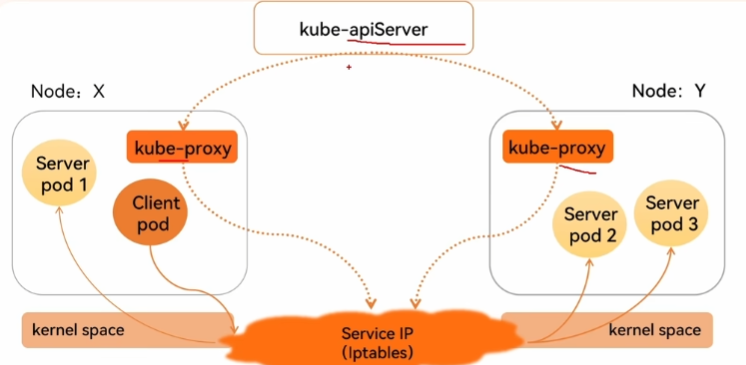
service-ipvs:
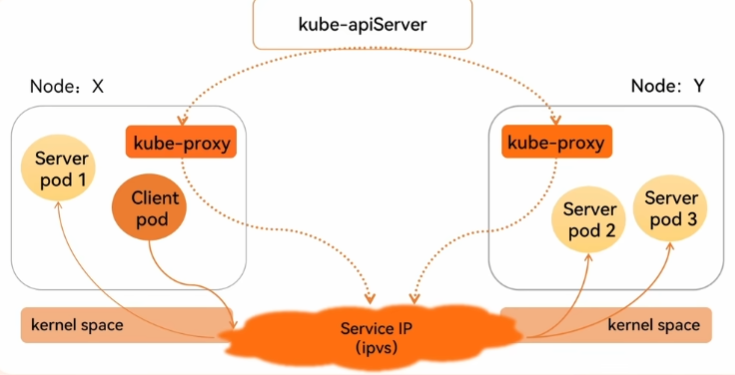
1.4service类型

ClusterIP:
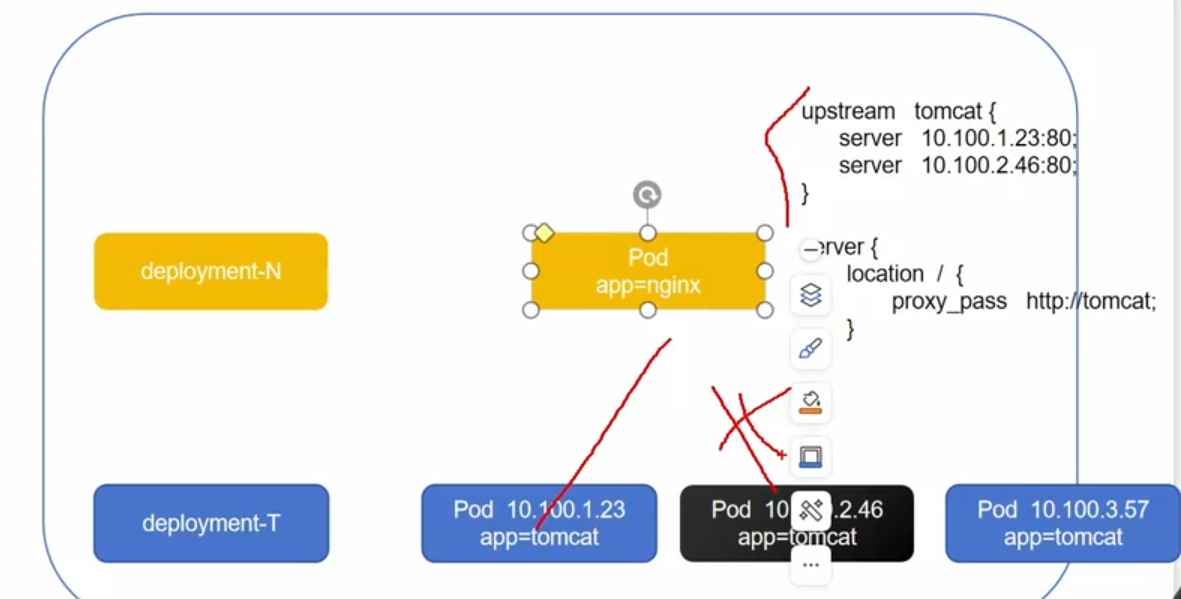
如图所示,deployment所控制的是两台机器,nginx代理的是23和46两台,现在46机器损坏,控制器会创建新的pod,但是新的pod,ip地址会发生改变,nginx无法代理,也就无法实现负载均衡
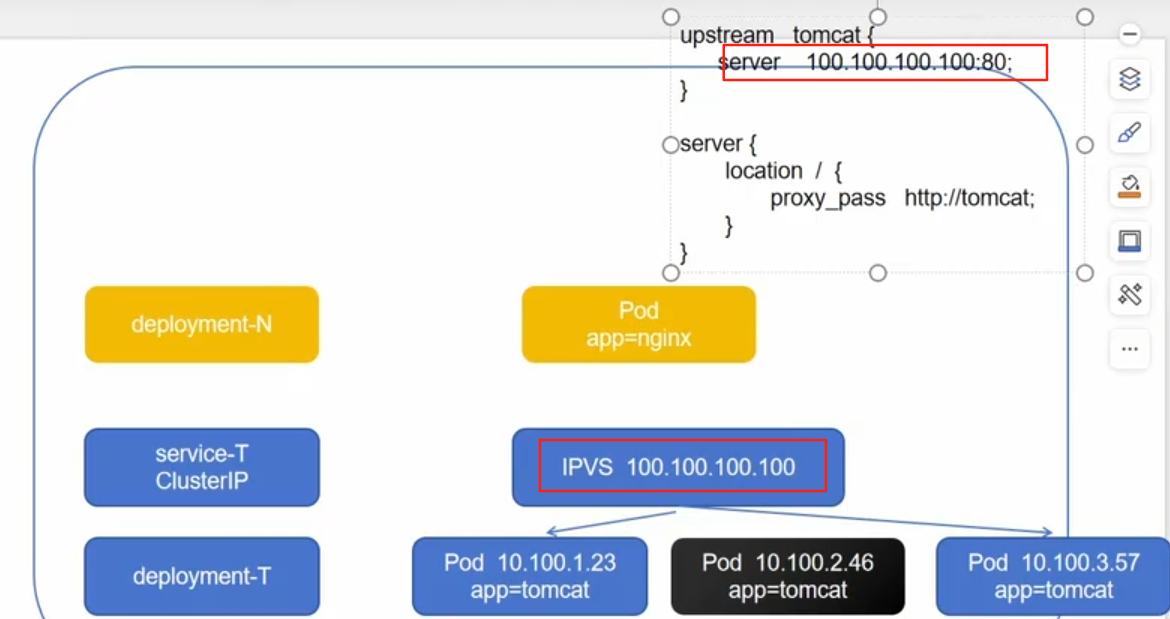
ClusterIP:提供一个集群内部的虚拟ip以供Pod访问,他只会收集满足条件的pod
NodePort:
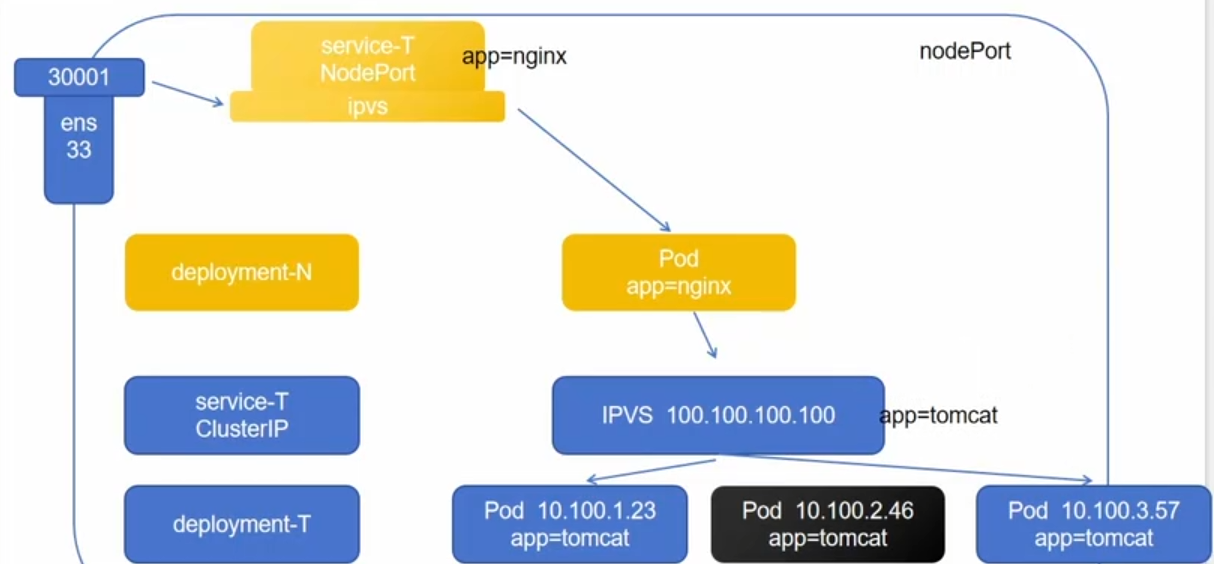
由于用户无法访问虚拟ip,所以我们引入了NodePort,他会提供一个真实的ip,供外部访问
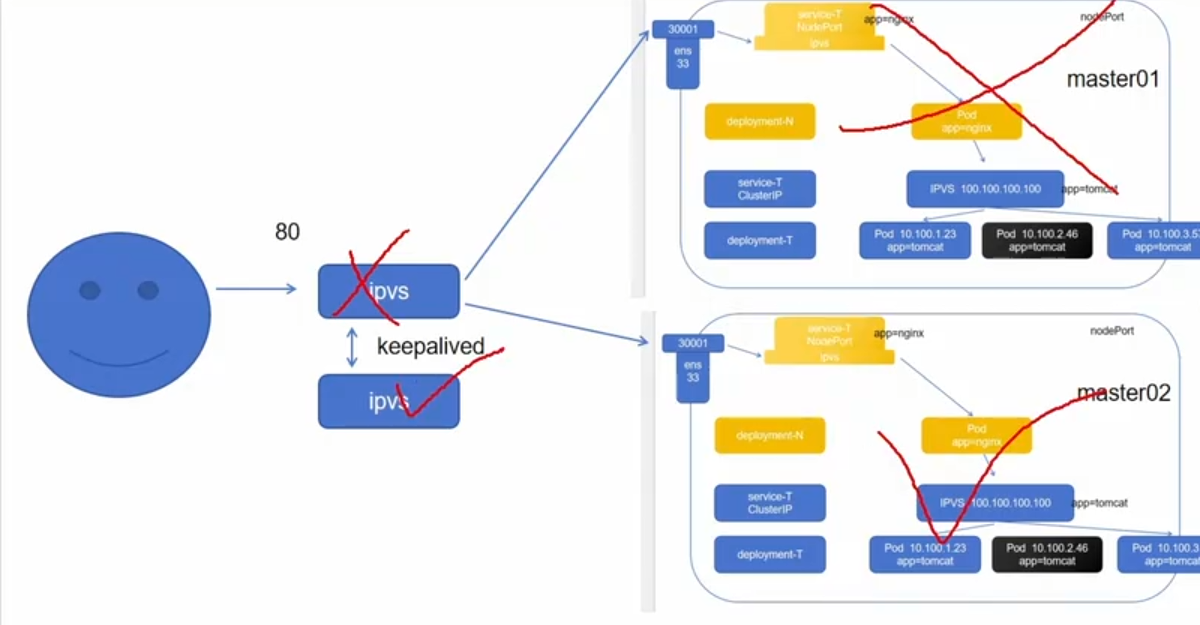
LoadBalancer:
通过外部的负载均衡器来访问
1.5service组件协同
clusterIP:
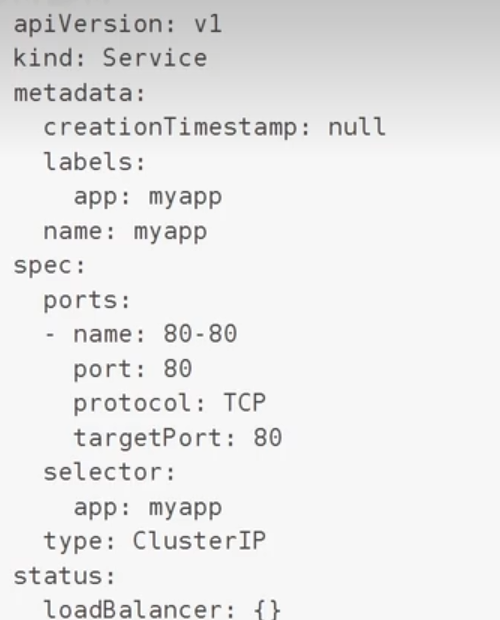
案例:


会自动生成一个资源清单:
二、configMap原理
配置信息的保存方式
2.1概述
ConfigMap 功能在 Kubernetes1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API给我们提供了向容器中注入配置信息的机制ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制等对象
2.2命令

–from-file
要求
文件内部必须是一行一对的k=v,可以在使用的时候注入至内部变成环境变量
1.txt
name-zhangsan
passwd=123
文件内部不符合要求,创建的时候依然可以变为k,val的形式,但是不会成为内部的环境变量
2.txt
今天去爬山
案例1:
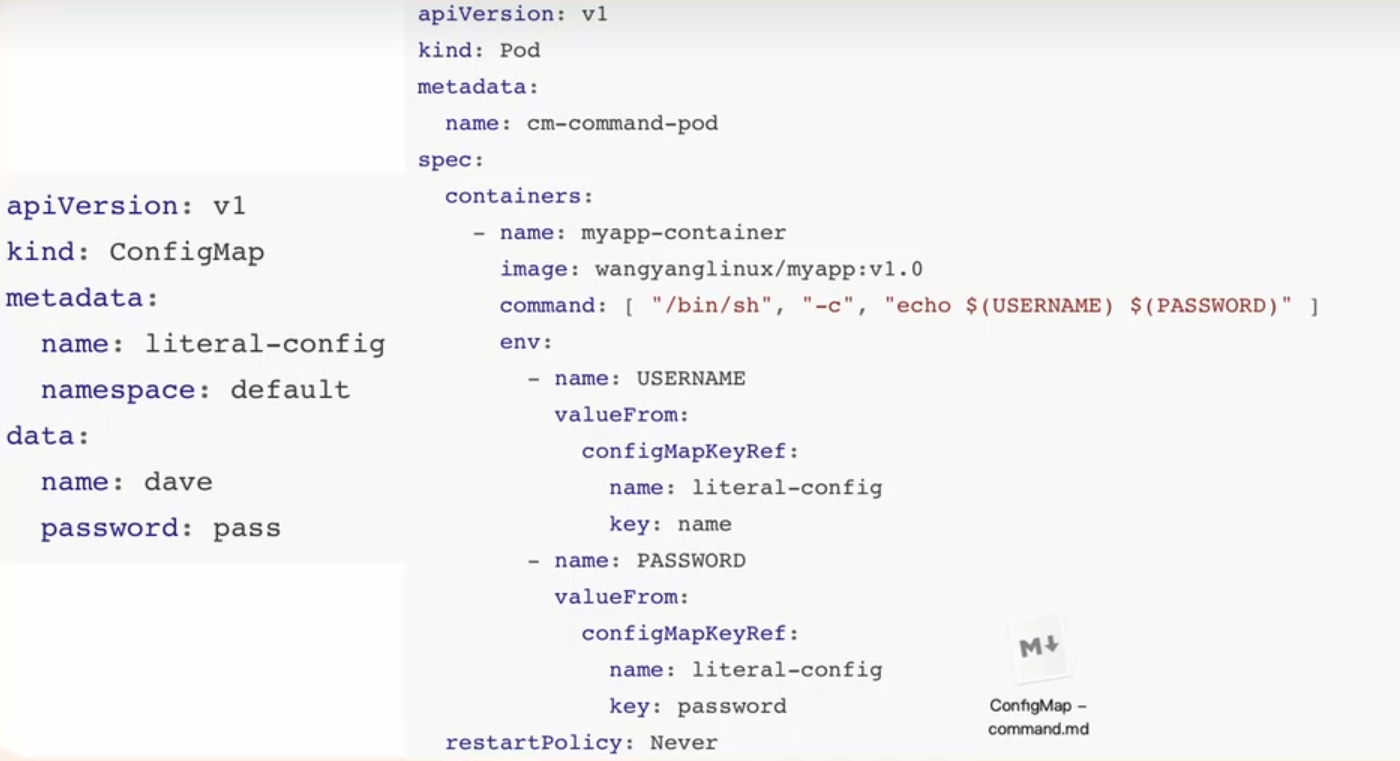
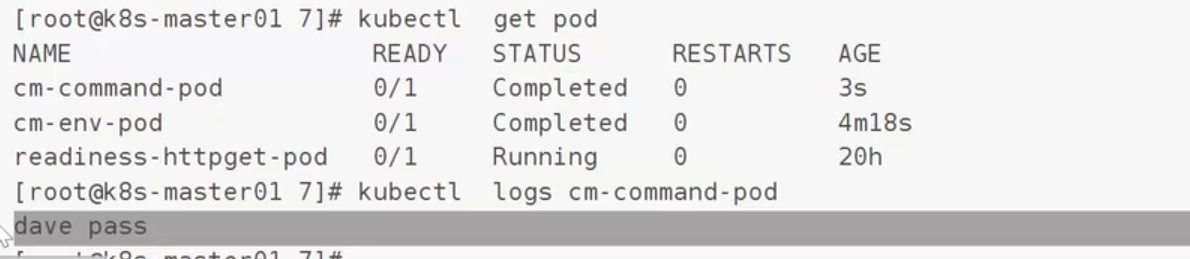
注入环境变量

案例2:
把环境变量作为启动参数
2.3类型

Clusterip:
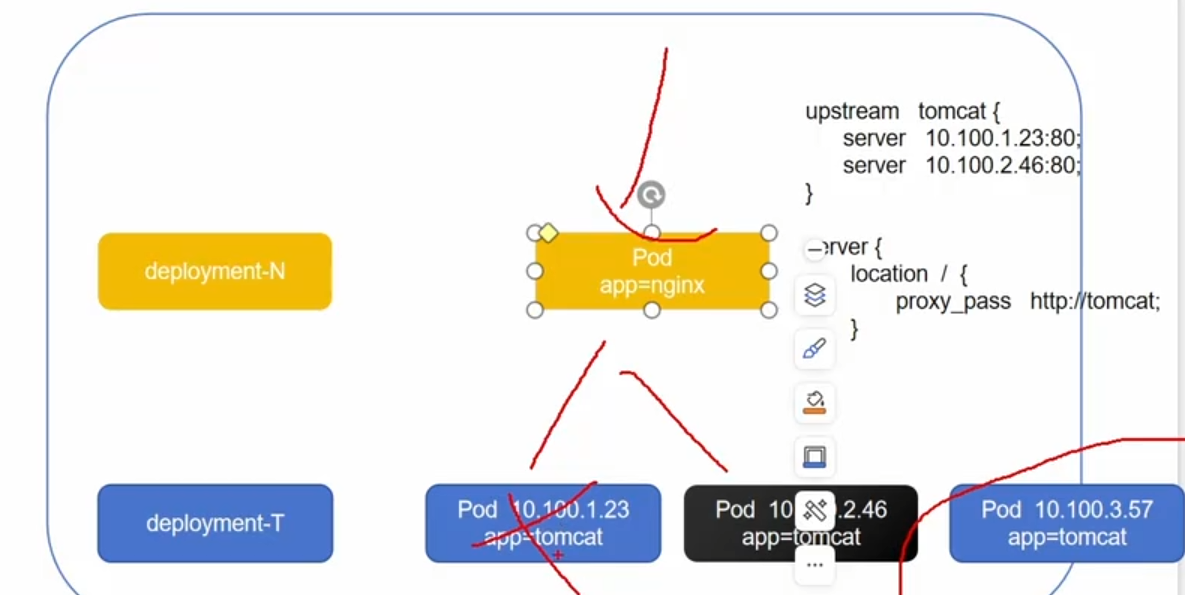
如图所示是一个简单的nginx负载均衡,他现在代理的是23和46这两台机器,如果第二台机器出现问题了,那么deployment会重建一个新的,但是这个新的机器ip地址可能会发生变化,导致nginx无法实现负载均衡
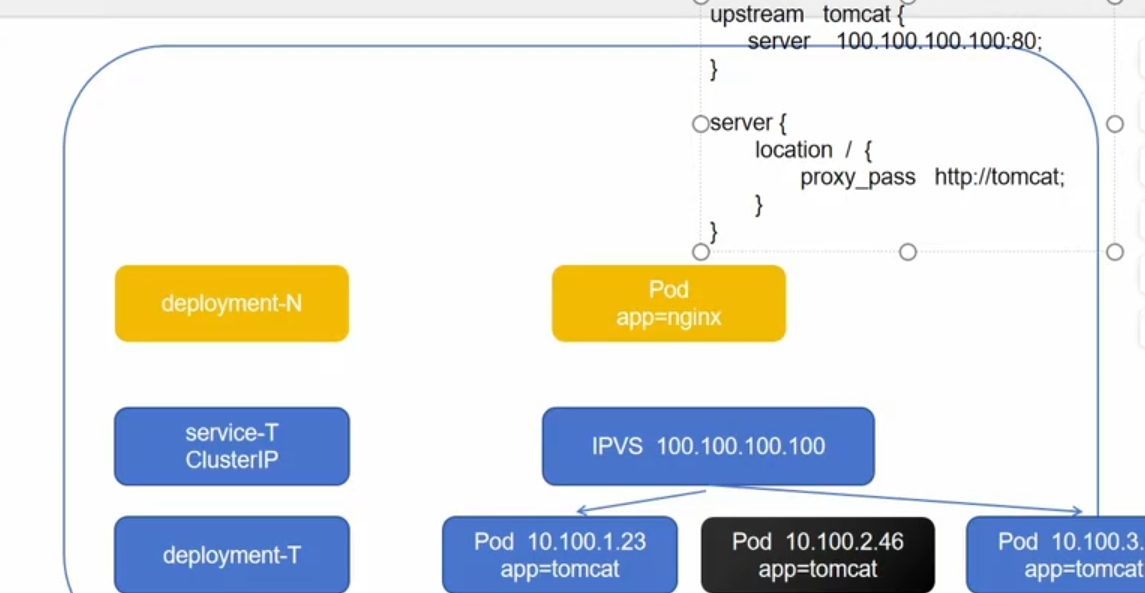
Clusterip:他会收集满足条件的pod,他会动态的更新后端Pod的状态
NodePort:
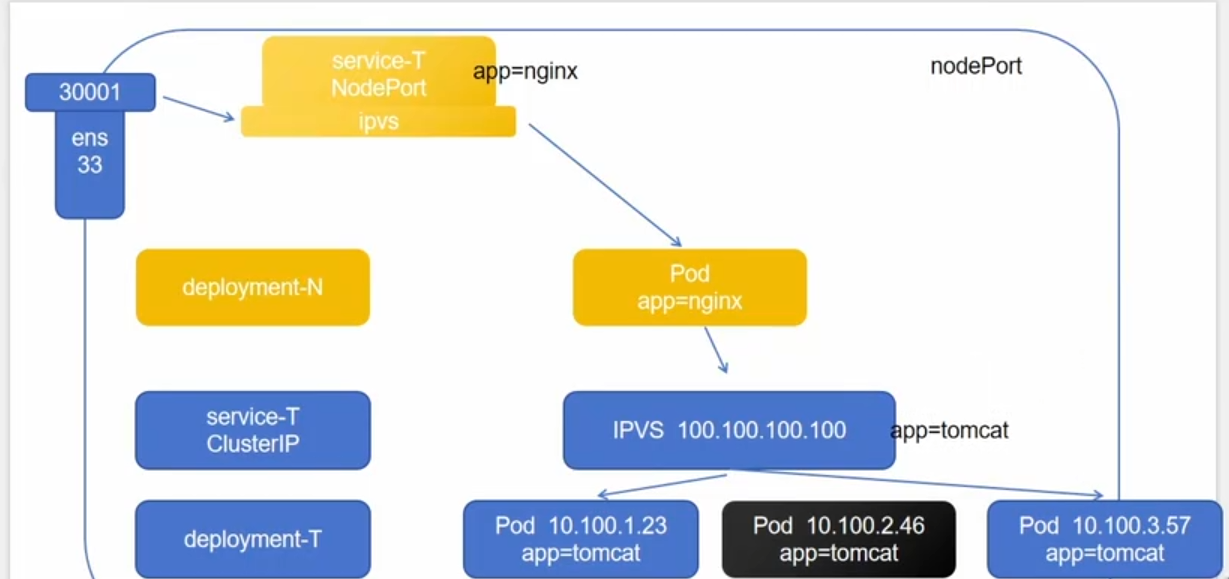
创建的真实ip就可以指向我们当前的Pod上
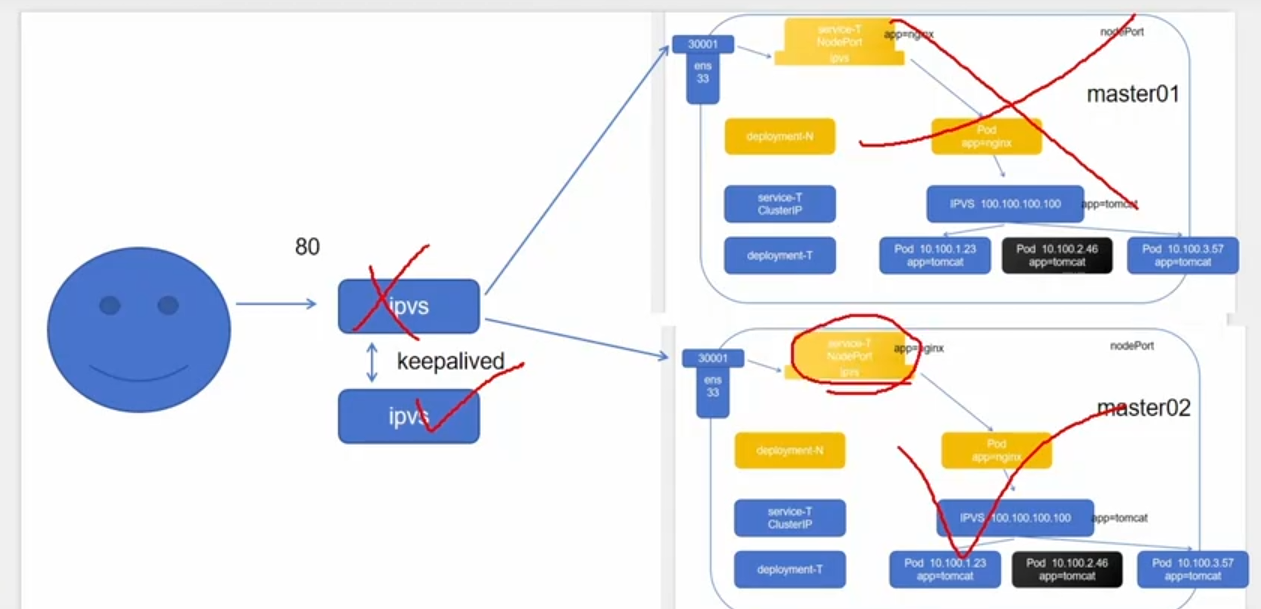
整个集群的高可用:
三、volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失–容器以干净的状态(镜像最初的状态)重新启动。其次,在Pod'中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的Volume抽象就很好的解决了这些问题
2.1emptydir
当 Pod 被分配给节点时,首先创建emptyDir'卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入emptyDir’卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除Pod 时,emptyDir中的数据将被永久删除
容器崩渍不会从节点中移除 pod,因此emptyDir 卷中的数据在容器崩溃时是安全的
emptyDir 的用法有:
》暂存空间,例如用于基于磁盘的合并排序、用作长时间计算崩溃恢复时的检查点>Web 服务器容器提供数据时,保存内容管理器容器提取的文件
案例1:
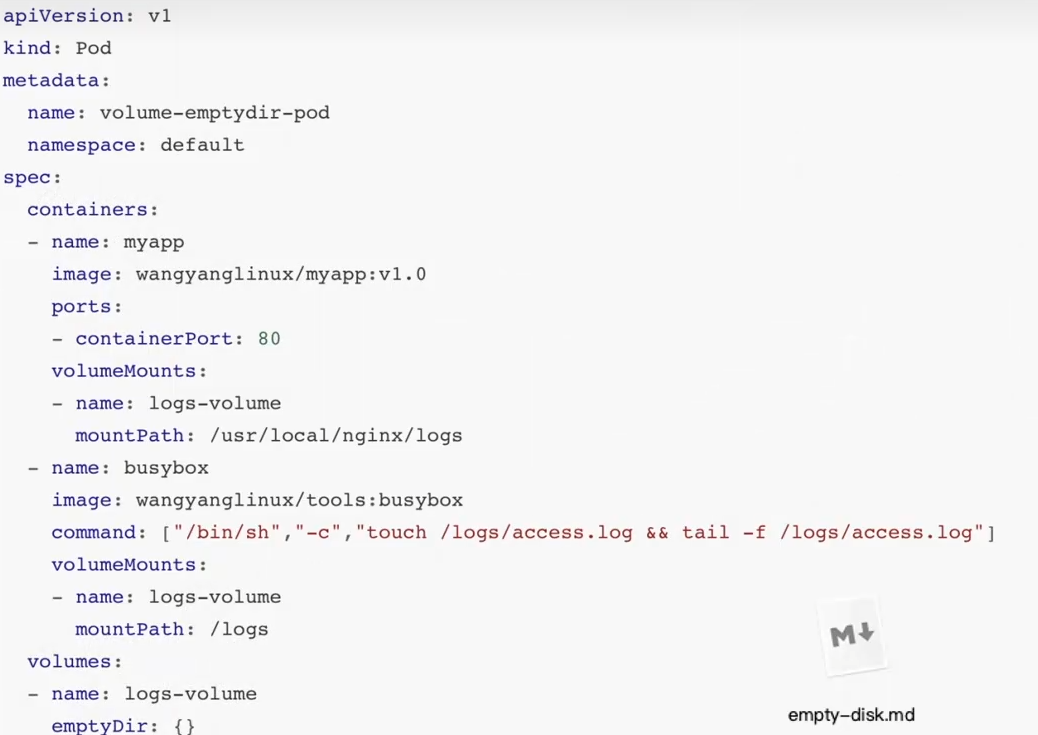
验证:访问nginx页面并
打印busybox容器日志:
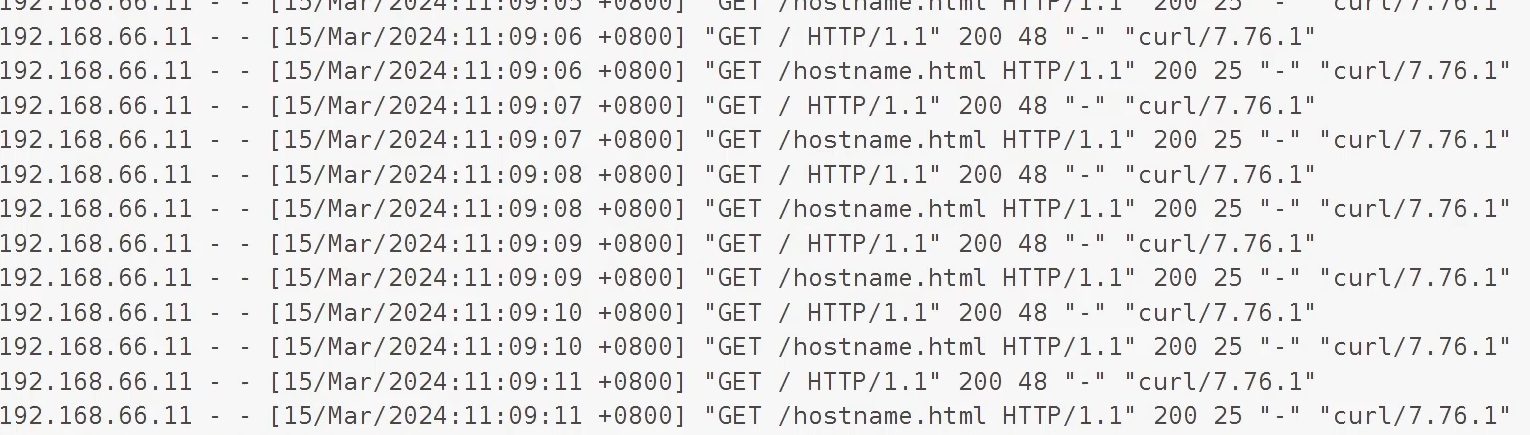
或者可以在节点上查看日志

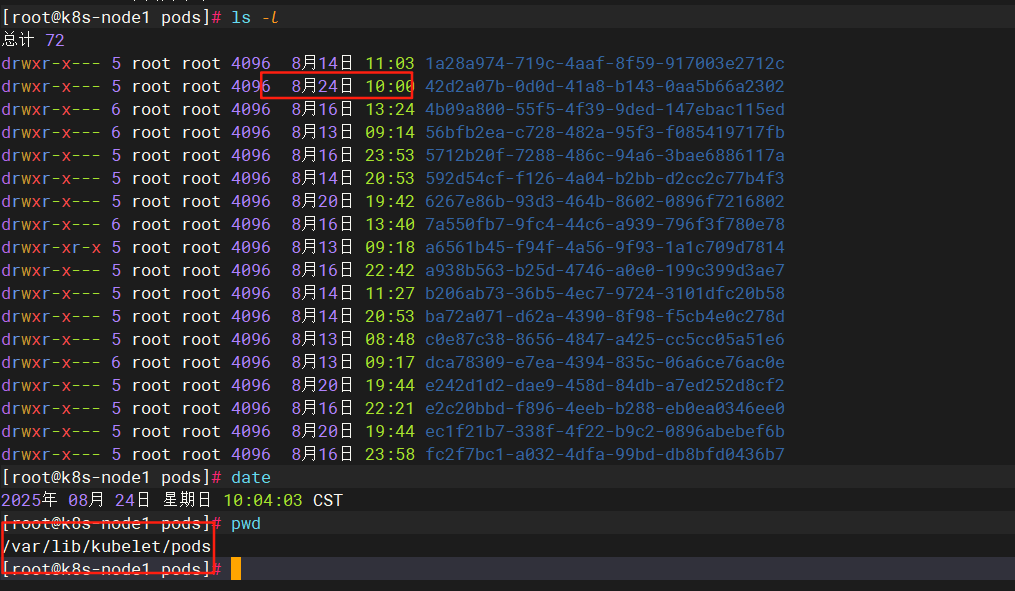
我们在日志中加入元素并查看busybox日志:确实访问一致
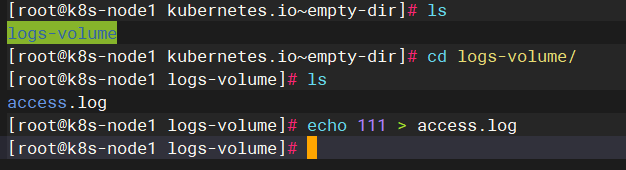

案例2:共享内存

2.2hostPath
hostPath 卷将主机节点的文件系统中的文件或目录挂载到集群中
hostPath 用途如下
》运行需要访问 Docker 内部的容器;使用/var/lib/docker'的hostPath》在容器中运行 cAdvisor;使用/dev/cgroups的hostPath允许 pod 指定给定的 hostPath 是否应该在 pod 运行之前存在,是否应该创建,以及它应该以什么形式存在 除了所需的'path属性之外,用户还可以为hostPath卷指定`type
类型:

注意:

案例:

path:/data是pod最后分配节点的跟data
必须保证节点有这个目录才会创建成功
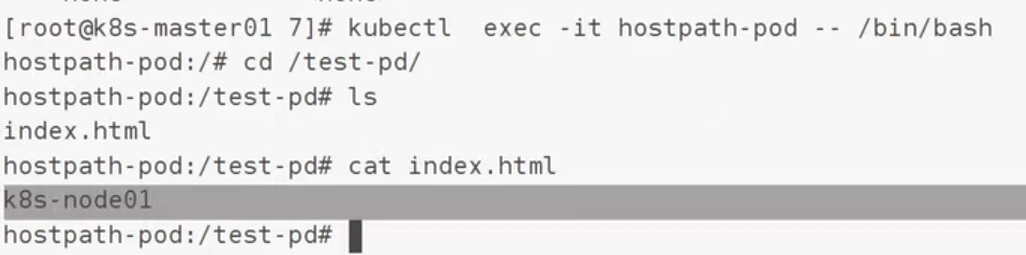
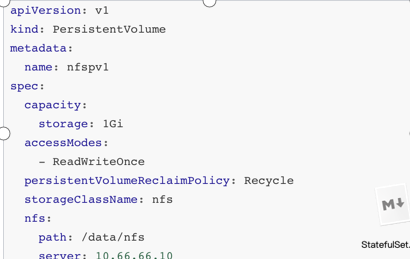
2.3pv/pvc

回收策略:

状态:

保护:

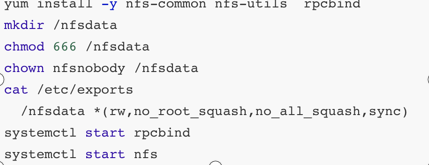
案例:
所有的几点都要安装yum install -y nfs-common nfs-utils rpcbindmkdir /nfsdata
master:创建共享目录并赋予权限
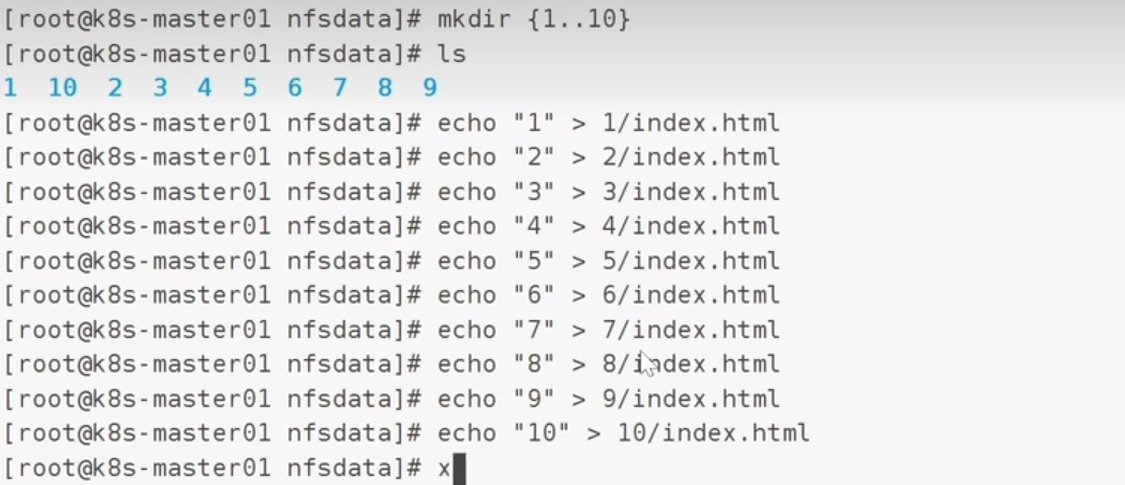
为了方便测试,可以多创建几个测试文件

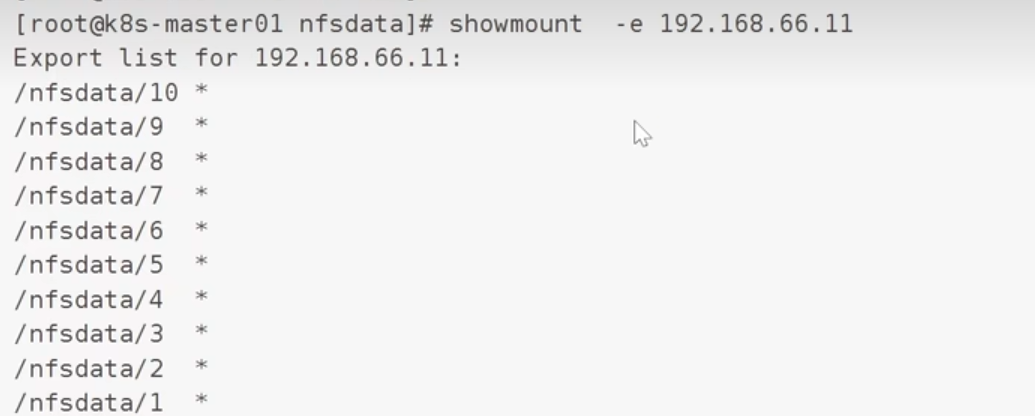
查看当前的共享结果:
验证:
node1节点上:
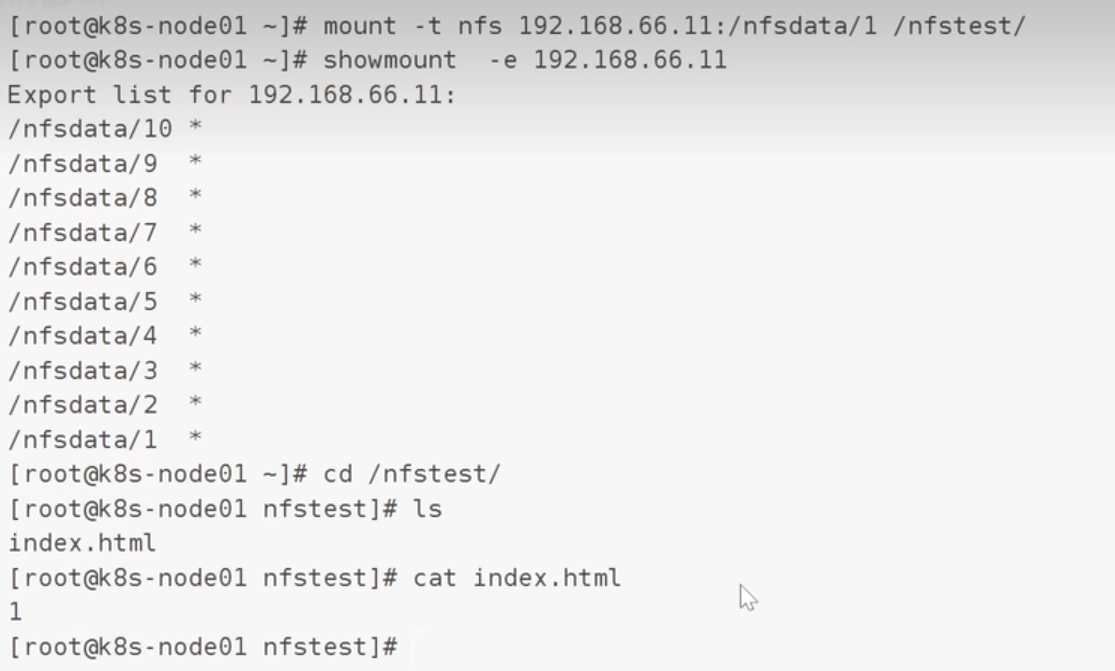
部署PV:
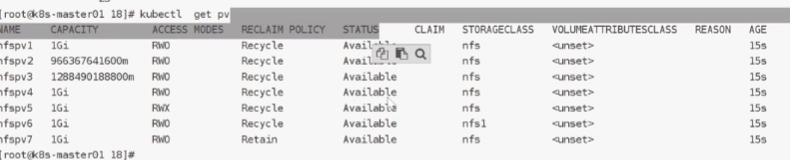
创建PVC:


改一下数量:
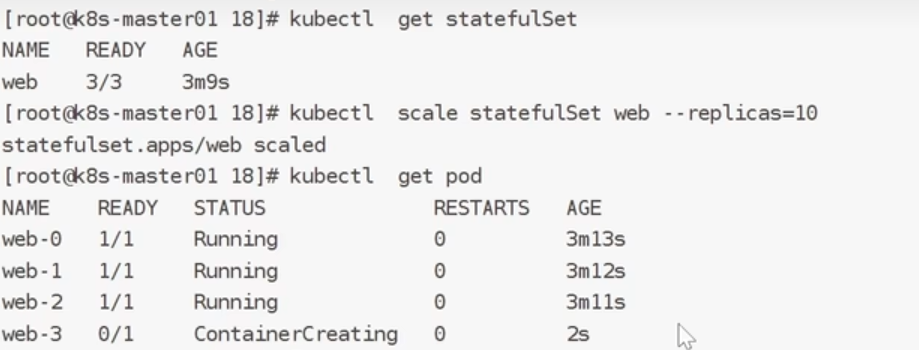
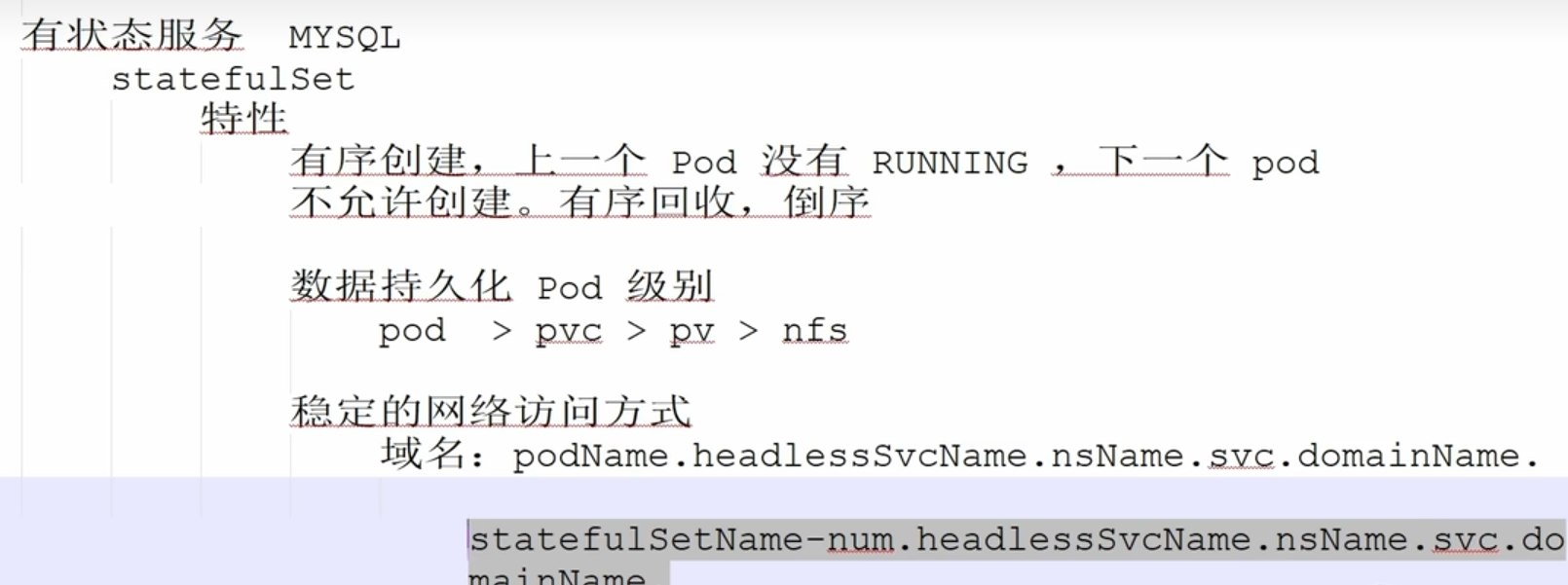
验证的stateful的特性:有序创建,有序回收
特性:
2.4storageClass
一种动态的申请存储机制
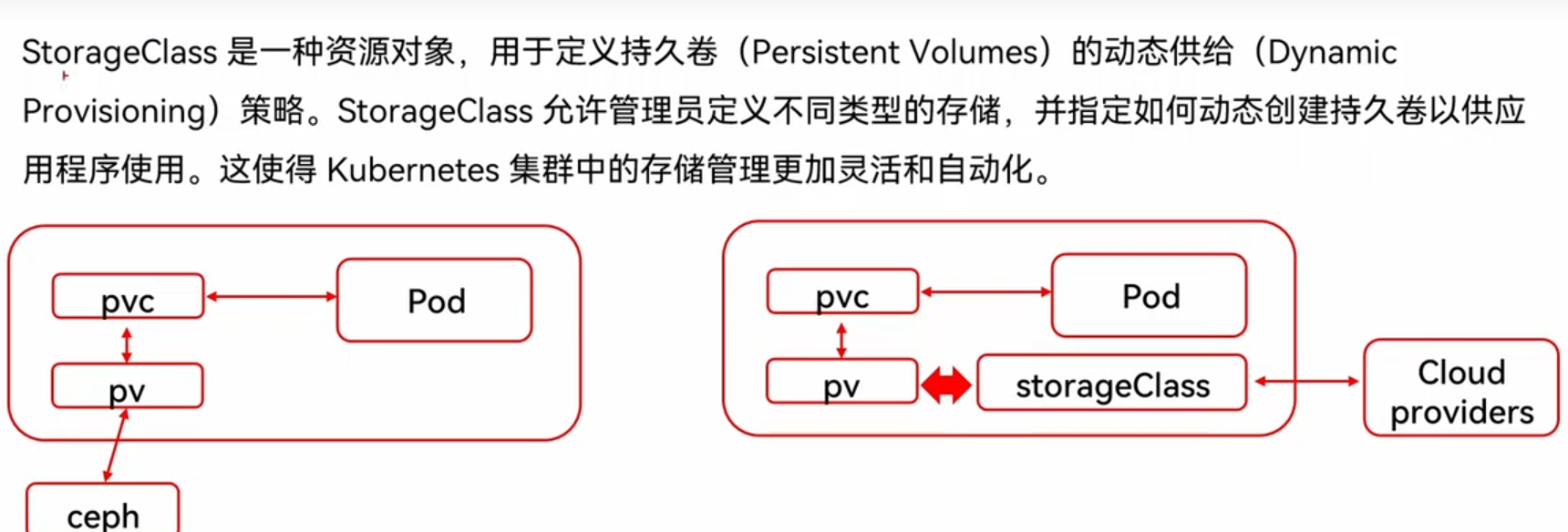
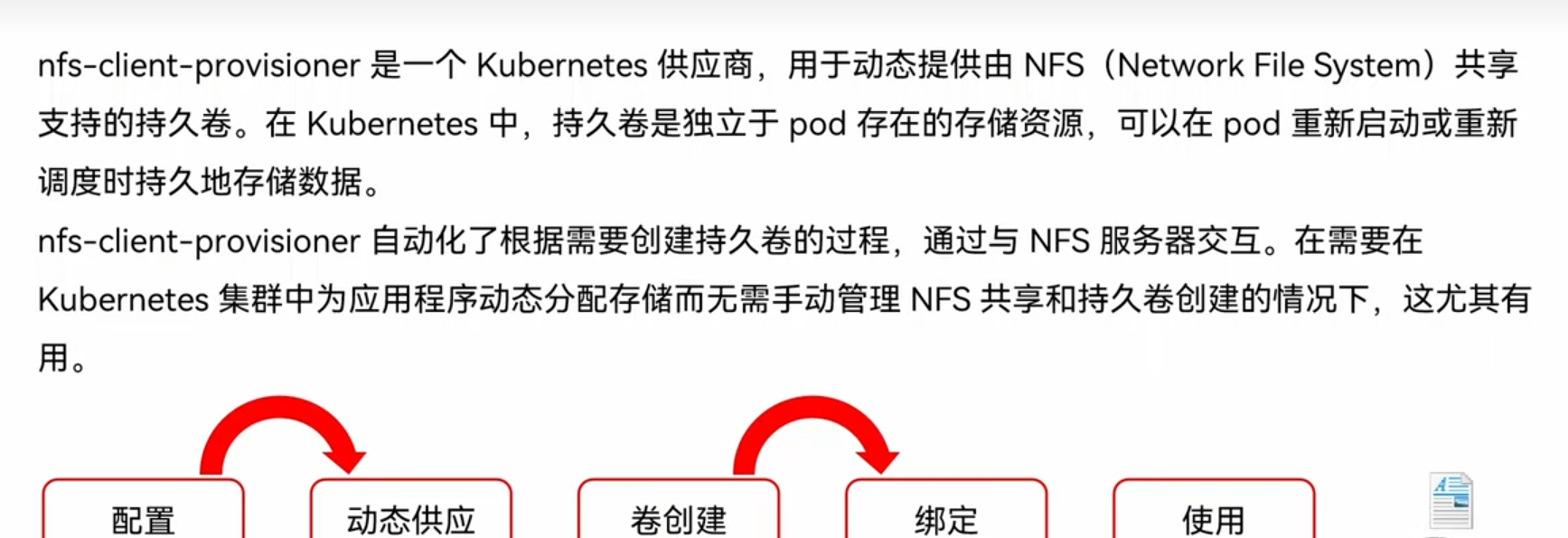
nfs-client-provisioner:
案例:
cat sa.yaml
apiVersion: v1
kind: Namespace
metadata:name: newnfs
---
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisionernamespace: newnfs
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: nfs-client-provisioner-runner
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: run-nfs-client-provisioner
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: newnfs
roleRef:kind: ClusterRolename: nfs-client-provisioner-runnerapiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: newnfs
rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: leader-locking-nfs-client-provisionernamespace: newnfs
subjects:- kind: ServiceAccountname: nfs-client-provisionernamespace: newnfs
roleRef:kind: Rolename: leader-locking-nfs-client-provisionerapiGroup: rbac.authorization.k8s.io
cat nfs.yaml
kind: Deployment
apiVersion: apps/v1
metadata:name: nfs-client-provisionernamespace: newnfs
spec:replicas: 1selector:matchLabels:app: nfs-client-provisionerstrategy:type: Recreate #设置升级策略为删除再创建(默认为滚动更新)template:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisioner #上一步创建的ServiceAccount名称containers:- name: nfs-client-provisionerimage: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0imagePullPolicy: IfNotPresentvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAME # Provisioner的名称,以后设置的storageclass要和这个保持一致value: storage-nfs- name: NFS_SERVER # NFS服务器地址,需和valumes参数中配置的保持一致value: 192.168.166.3- name: NFS_PATH # NFS服务器数据存储目录,需和volumes参数中配置的保持一致value: /data- name: ENABLE_LEADER_ELECTIONvalue: "true"volumes:- name: nfs-client-rootnfs:server: 192.168.166.3 # NFS服务器地址path: /data # NFS共享目录
执行文件:
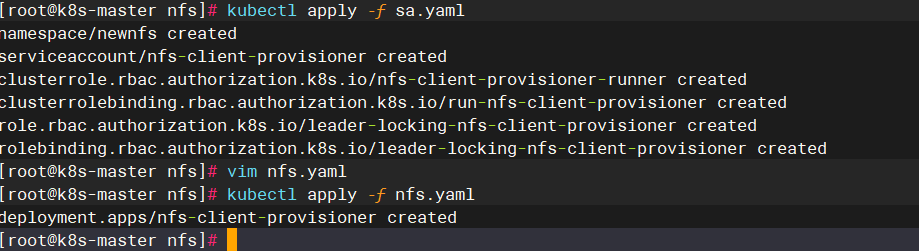

创建存储类:
在node节点上查看nfs的版本
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nfs-storageannotations:storageclass.kubernetes.io/is-default-class: "false" ## 是否设置为默认的storageclass
provisioner: storage-nfs ## 动态卷分配者名称,必须和上面创建的deploy中环境变量“PROVISIONER_NAME”变量值一致
parameters:archiveOnDelete: "true" ## 设置为"false"时删除PVC不会保留数据,"true"则保留数据
mountOptions: - hard ## 指定为硬挂载方式- nfsvers=4

注意:
需要 “隔离” 的资源(如 Pod、PVC) → 加命名空间,避免不同团队 / 业务互相影响;
需要 “全局复用” 的资源(如 StorageClass、PV) → 不加命名空间,让整个集群的资源能共用同一套配置。
创建pvc,通过storageclass动态生成pv:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:name: storage-pvcnamespace: newnfs
spec:storageClassName: nfs-storage ## 需要与上面创建的storageclass的名称一致accessModes:- ReadWriteOnceresources:requests:storage: 1Mi
编写pod绑定pvc:
apiVersion: v1
kind: Pod
metadata:name: pod-pvc1namespace: newnfs
spec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresentvolumeMounts:- name: nginx-htmlmountPath: /usr/share/nginx/htmlvolumes:- name: nginx-htmlpersistentVolumeClaim:claimName: storage-pvc
验证:


四、调度管理
3.1概念
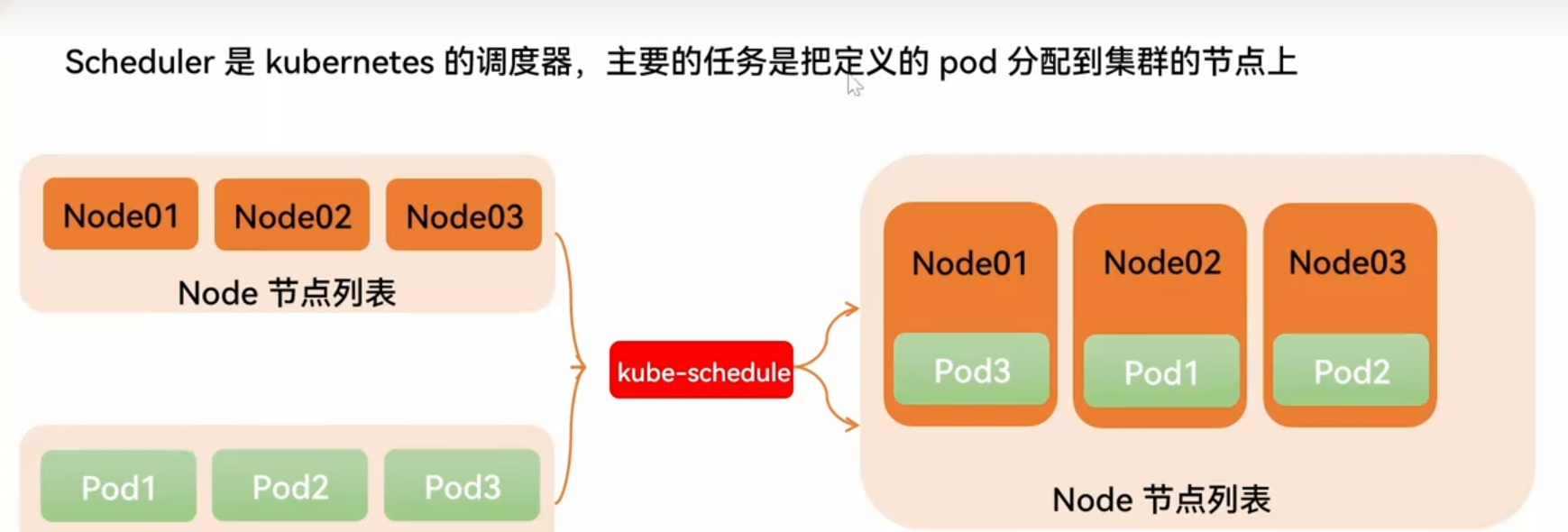

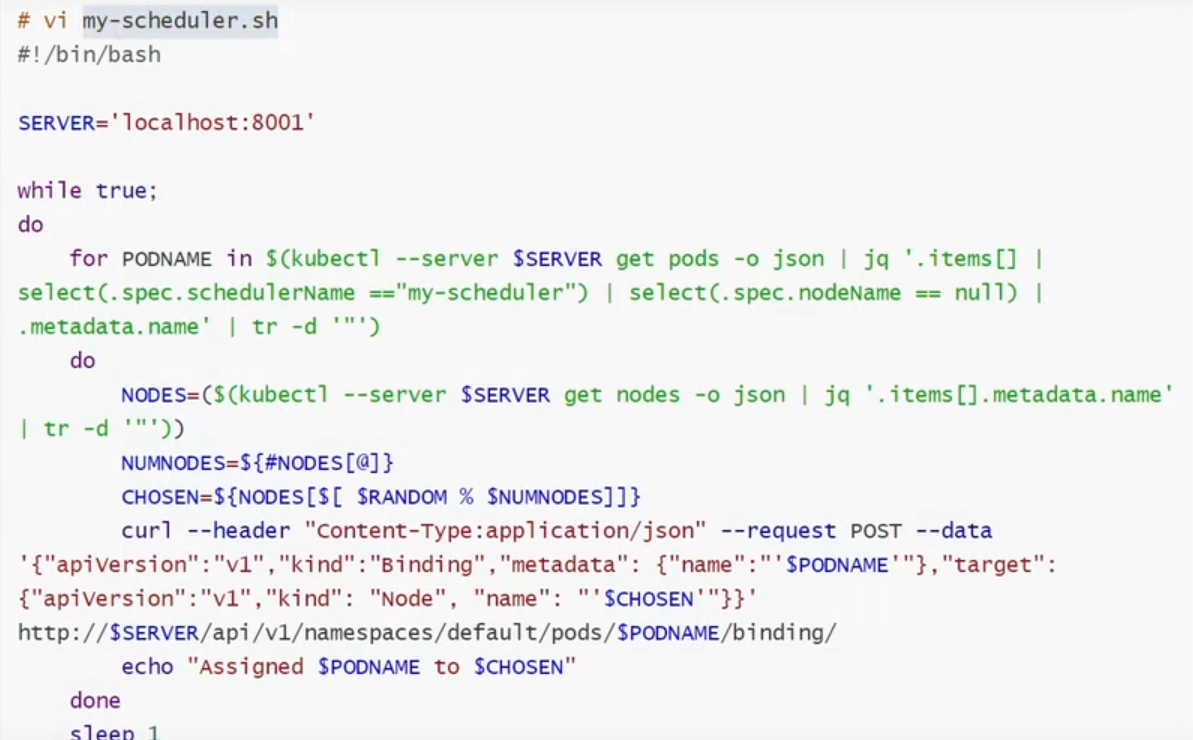
案例:自定义调度器
基于shell自定义:
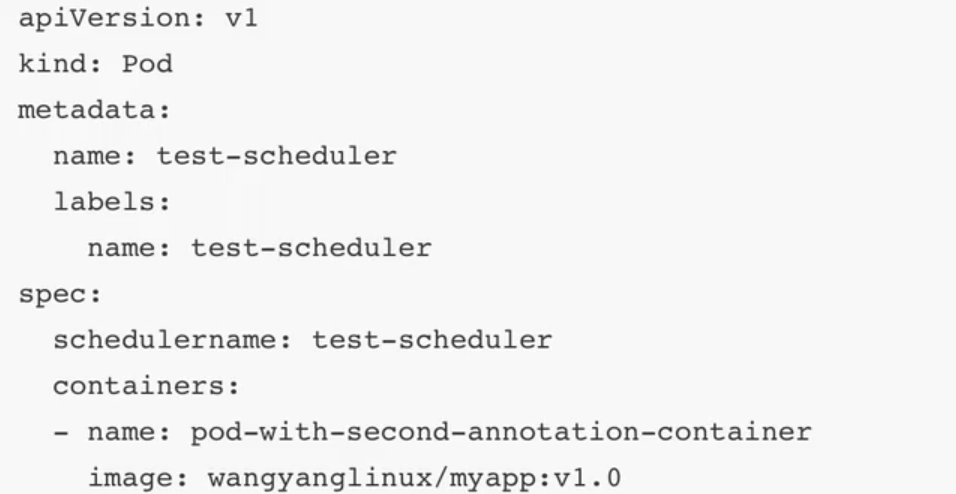
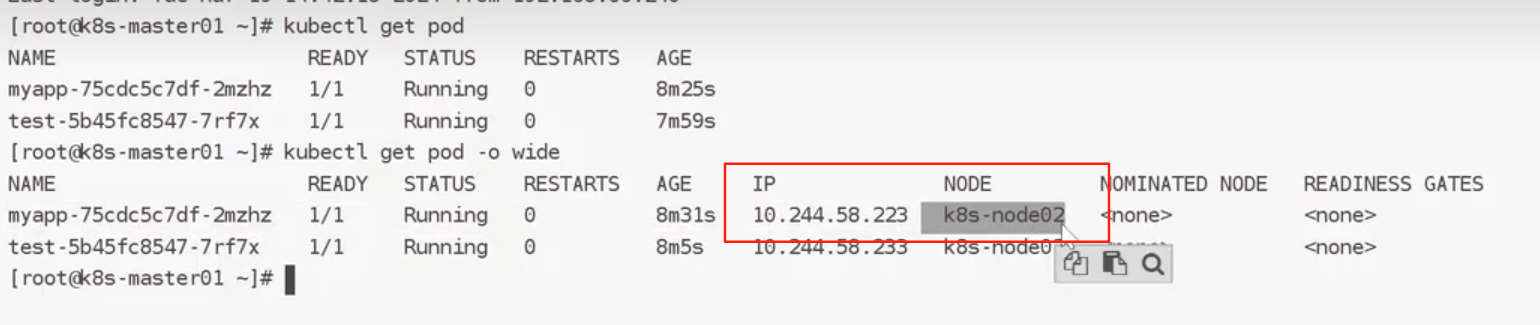
3.2特点
3.3亲和性
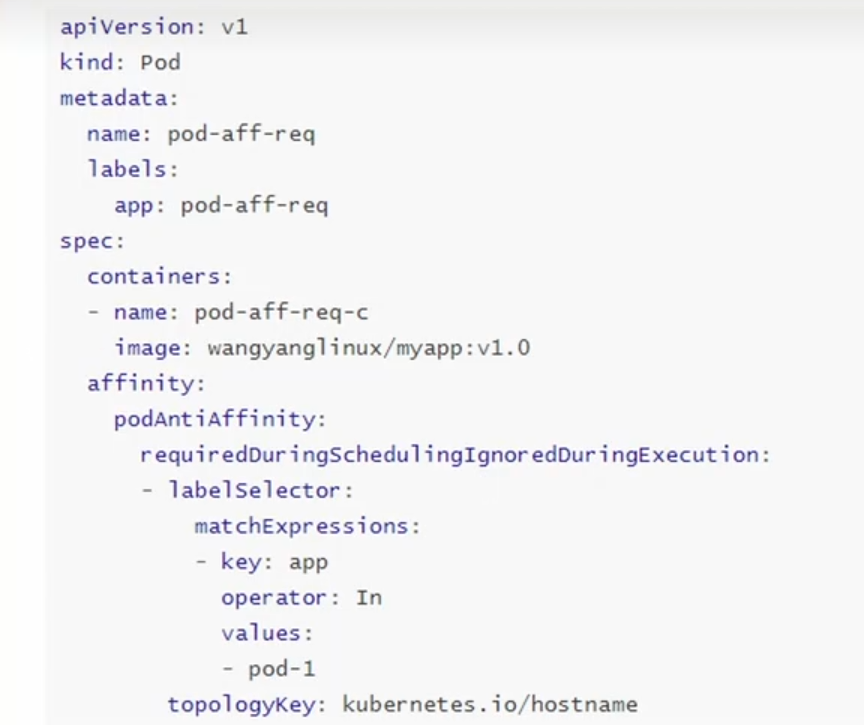
生产上为了保证应用的高可用性,需要将同一应用的不同pod分散在不同的宿主机上,以防宿主机出现宕机等情况导致pod重建,影响到业务的连续性。要想实现这样的效果,需要用到k8s自带的pod亲和性和反亲和性特性。
Pod 的亲和性与反亲和性有两种类型:
requiredDuringSchedulingIgnoredDuringExecution ##一定满足
preferredDuringSchedulingIgnoredDuringExecution ##尽量满足
**podAffinity(亲和性):**pod和pod更倾向腻在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率;
**podAntiAffinity(反亲和性):**pod和pod更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个pod随机选则一个节点,做为评判后续的pod能否到达这个pod所在的节点上的运行方式,这就称为pod亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义pod亲和性时需要有一个前提,哪些pod在同一个位置,哪些pod不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
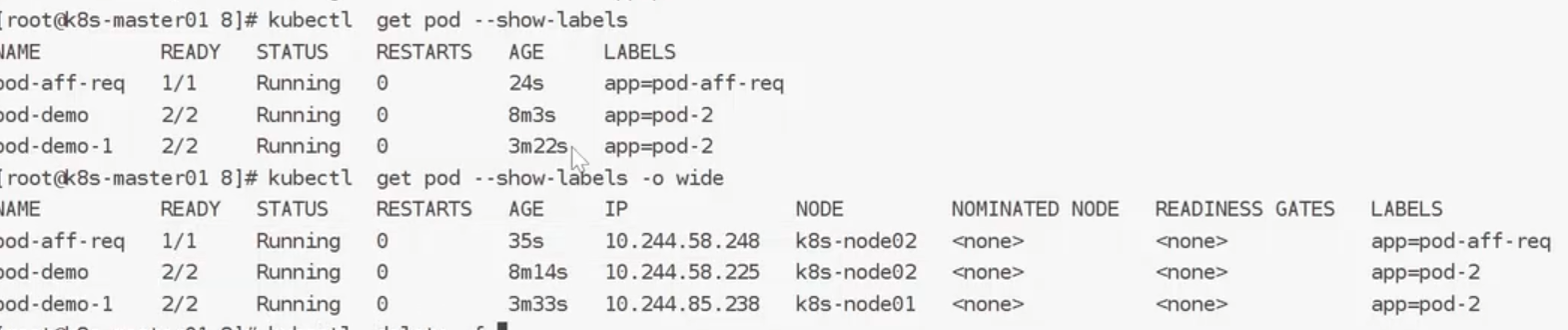
案例:软策性:
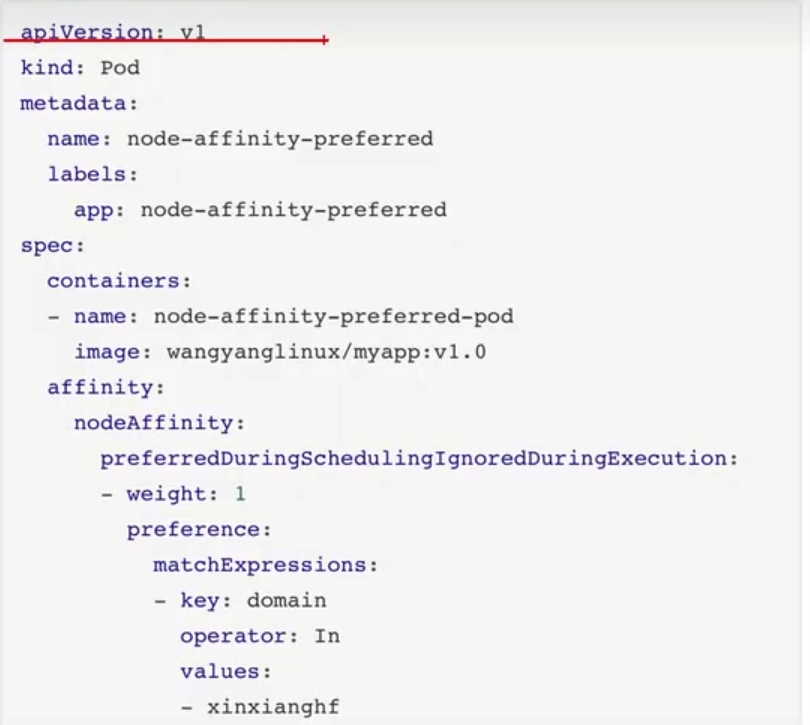

从运行结果来看,他都运行在Node2节点上,说明node2优于node1
硬策略:
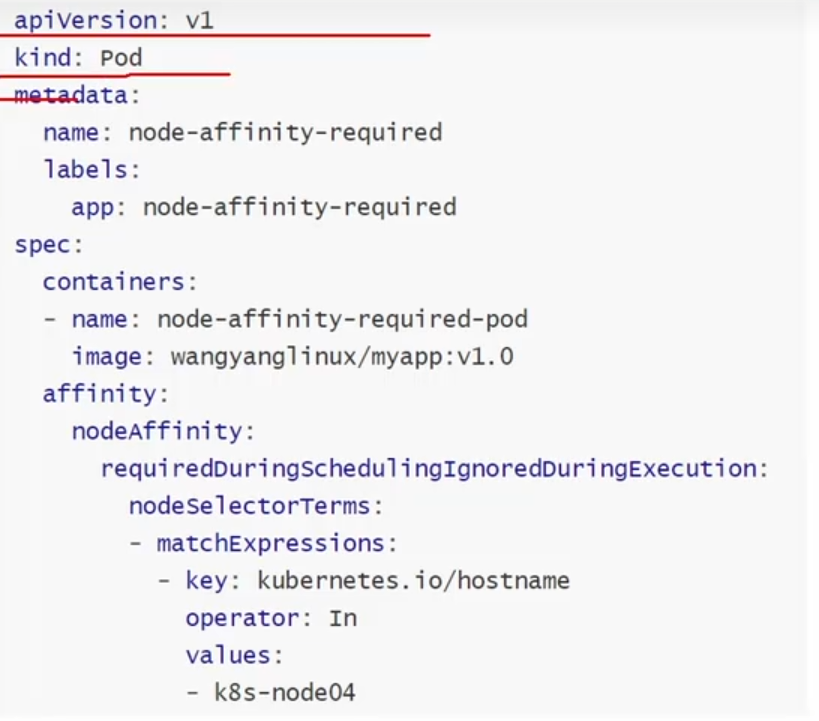
状态为pending

满足条件:

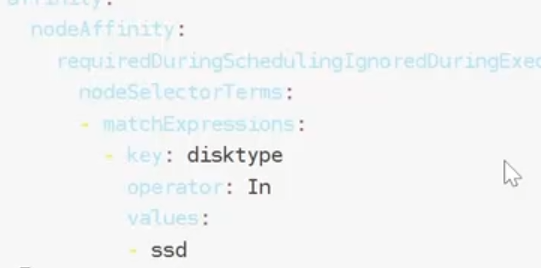
验证:满足条件

反亲和性:软策略


反亲和性:硬策略
总结:

3.4容忍和污点
污点:

污点的组成:


我们使用descibe查看详细信息
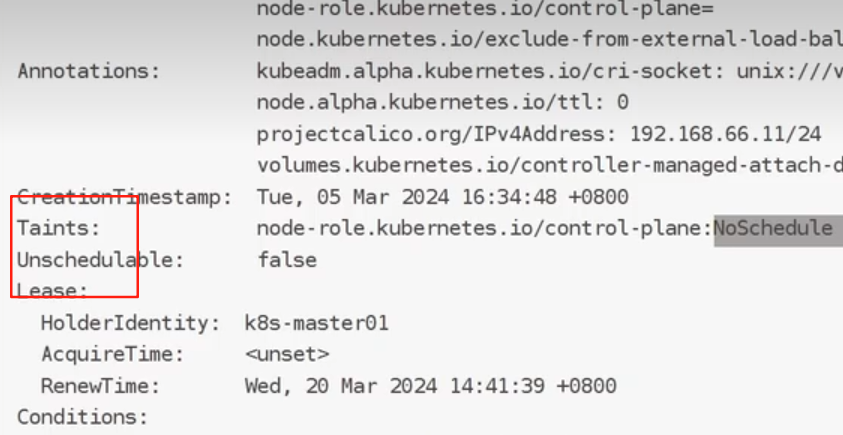
添加污点:

再次查看:
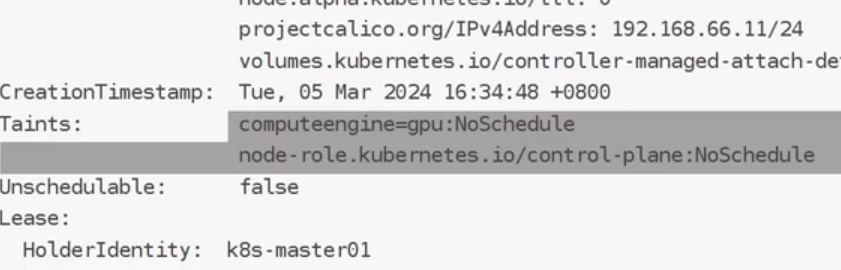
删除污点:

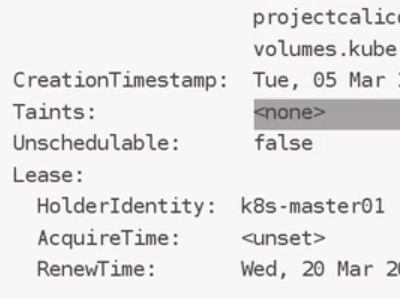
我们创建10个pod:

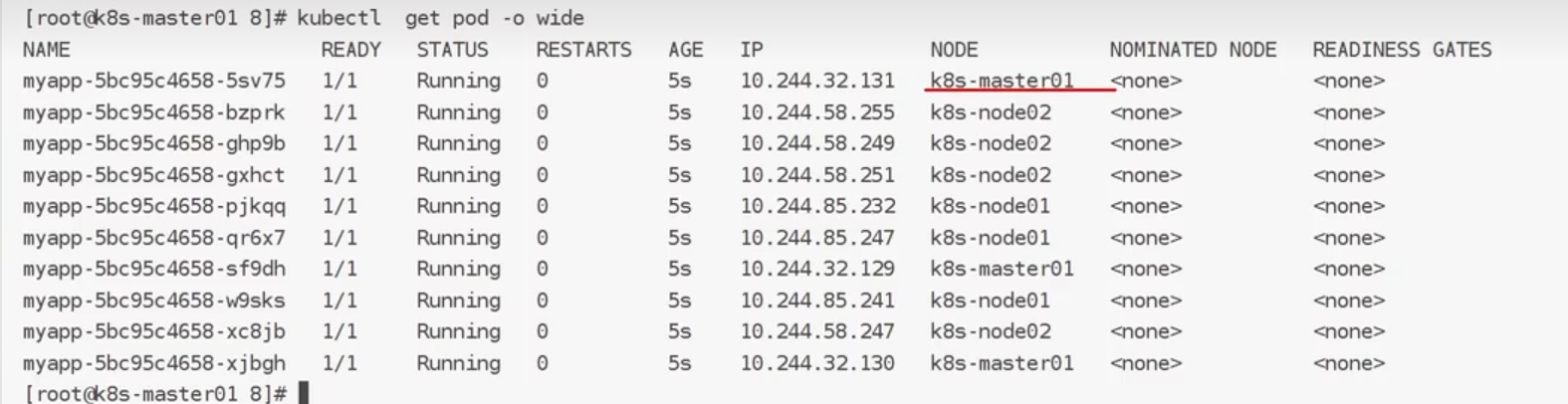
master出现节点了.所以说明不是master无法分配节点,而是它本身存在污点
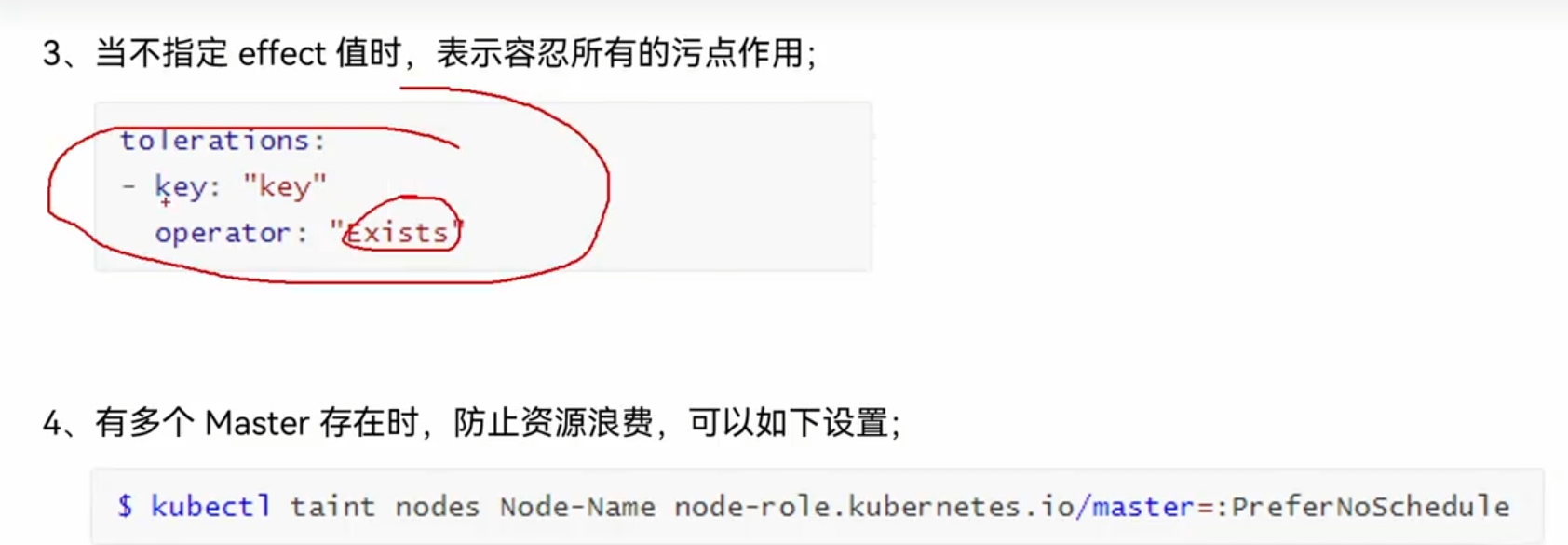
容忍:

我们先把master本身的污点加上:


设置方式:

特殊类型:

3.5固定节点调度
pod.spec.nodename将pod直接调度到指定节点上,跳过scheduler的调度策略,属于强制匹配
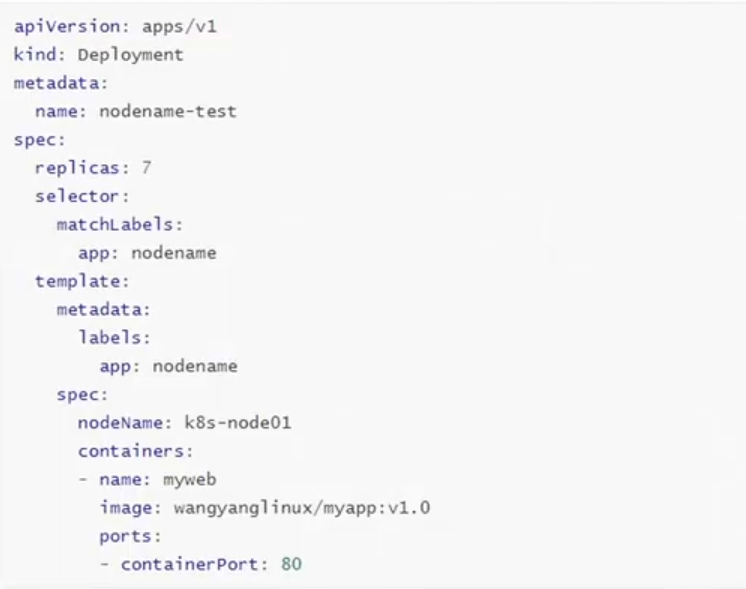
为了更方便实验,可以把nodeName改为master节点
及时设置污点,也能分配到master节点

我们也可以通过标签选择器去实现
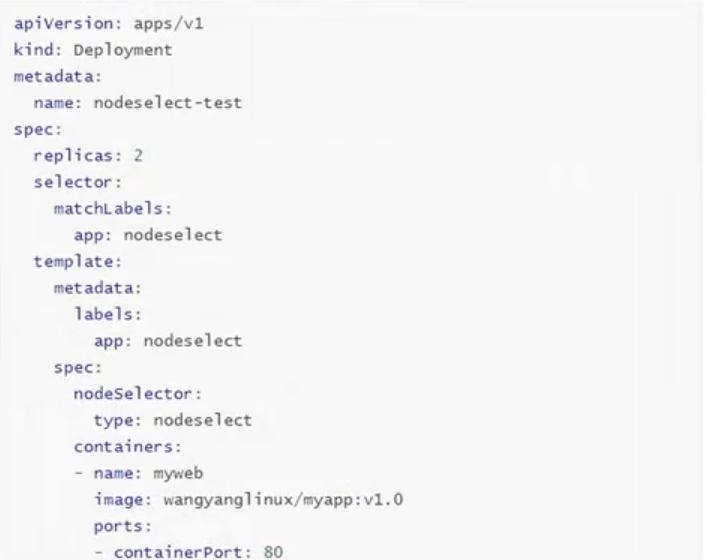
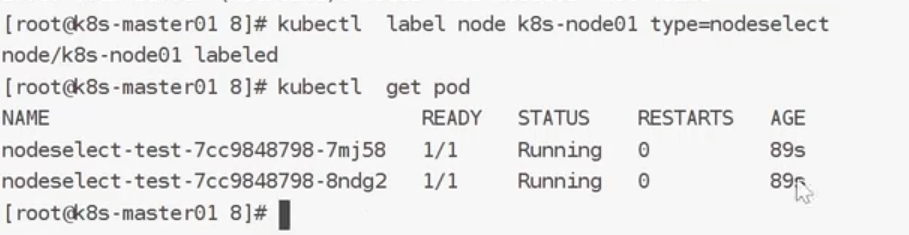
因为我们没有这个标签,所以容器处于pending状态:

现在我们添加这个标签:
五、etcd
5.1概述
etcd 是 K8s 的唯一数据存储源(Single Source of Truth),所有组件(如 API Server、Controller Manager、Scheduler、kubelet 等)的配置与状态都依赖 etcd 存储,具体包括:
集群拓扑信息:节点(Node)的注册与状态
资源对象数据:Pod、Service、Deployment、ConfigMap、Secret、Namespace 等的定义和运行状态
集群配置:如集群网络 CIDR、API Server 地址、证书信息等
状态数据:如 Pod 的运行状态(Running/Pending)、Service 的 endpoints 列表等
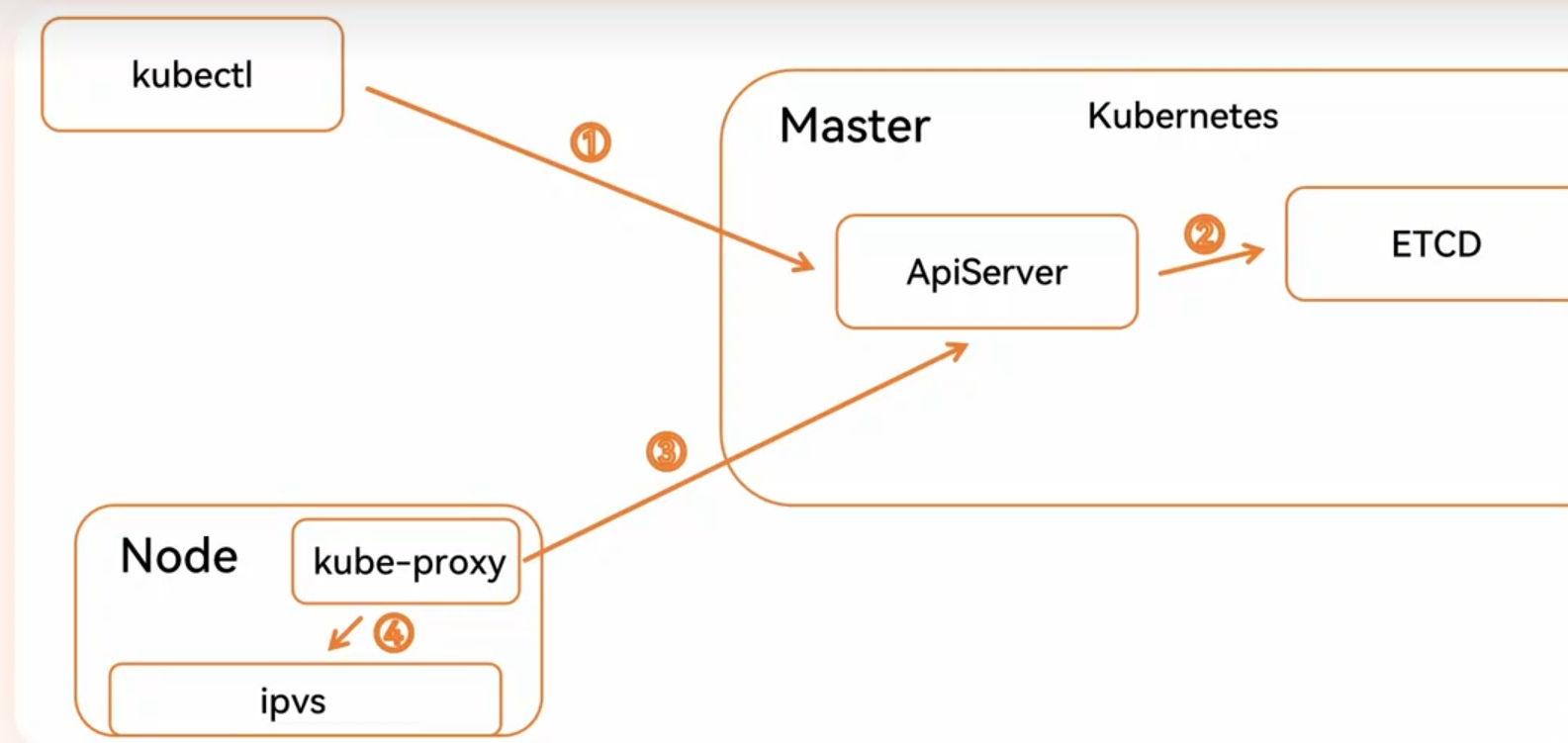
注意:K8s 中仅 API Server 有权直接读写 etcd,其他组件(如 Controller Manager、kubelet)需通过 API Server 的接口间接操作 etcd 数据,确保数据一致性和安全性。
5.2相关操作
etcdctl的tar包可以从github上获取
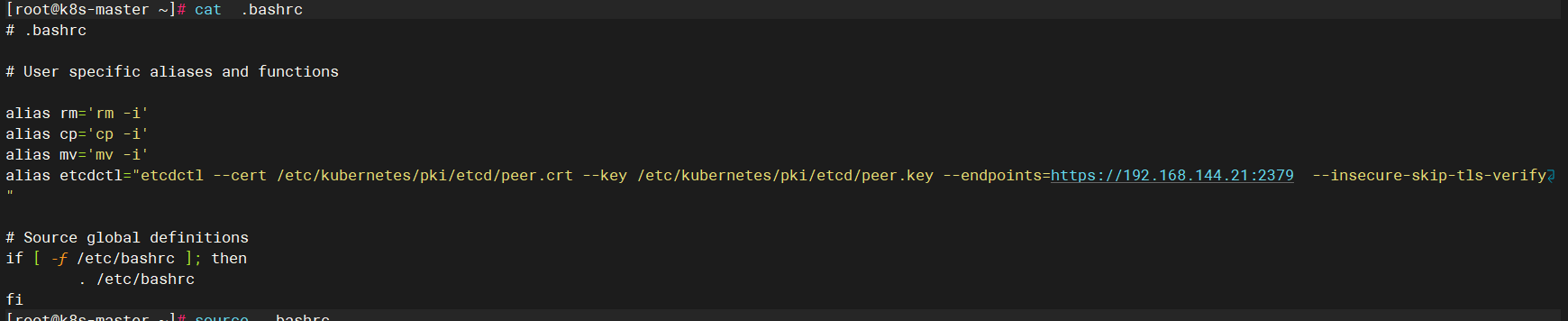
环境变量配置:
查看etcd版本:

查看etcd集群节点信息:

查看etcd集群的健康状态:

查看告警事件
如果内部出现问题,会触发告警,可以通过命令查看告警引起原因,命令如下所示:
etcdctl alarm <subcommand> [flags]
常用的子命令主要有两个:
# 查看所有告警
etcdctl alarm list
# 解除所有告警
etcdctl alarm disarm
5.3etcd数据库相关操作
增加(put)
添加一个键值,基本用法如下所示:
etcdctl put [options] <key> <value> [flags]
常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –prev-kv | 输出修改前的键值 |
注意事项:
- 其中value接受从stdin的输入内容
- 如果value是以横线-开始,将会被视为flag,如果不希望出现这种情况,可以使用两个横线代替–
- 若键已经存在,则进行更新并覆盖原有值,若不存在,则进行添加
示例
[root@tiaoban etcd]# etcdctl put name cuiliang
OK
[root@tiaoban etcd]# etcdctl put location -- -beijing
OK
[root@tiaoban etcd]# etcdctl put foo1 bar1
OK
[root@tiaoban etcd]# etcdctl put foo2 bar2
OK
[root@tiaoban etcd]# etcdctl put foo3 bar3
OK
查询(get)
查询键值,基本用法如下所示:
etcdctl get [options] <key> [range_end] [flags]
常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –hex | 以十六进制形式输出 |
| –limit number | 设置输出结果的最大值 |
| –prefix | 根据prefix进行匹配key |
| –order | 对输出结果进行排序,ASCEND 或 DESCEND |
| –sort-by | 按给定字段排序,CREATE, KEY, MODIFY, VALUE, VERSION |
| –print-value-only | 仅输出value值 |
| –from-key | 按byte进行比较,获取大于等于指定key的结果 |
| –keys-only | 仅获取keys |
示例
# 获取键值
[root@tiaoban etcd]# etcdctl get name
name
cuiliang
#查看所有的key
etcdctl get / --prefix --keys-only
# 只获取值
[root@tiaoban etcd]# etcdctl get location --print-value-only
-beijing
# 批量取从foo1到foo3的值,不包括foo3
[root@tiaoban etcd]# etcdctl get foo foo3 --print-value-only
bar1
bar2
# 批量获取前缀为foo的值
[root@tiaoban etcd]# etcdctl get --prefix foo --print-value-only
bar1
bar2
bar3
# 批量获取符合前缀的前两个值
[root@tiaoban etcd]# etcdctl get --prefix --limit=2 foo --print-value-only
bar1
bar2
# 批量获取前缀为foo的值,并排序
[root@tiaoban etcd]# etcdctl get --prefix foo --print-value-only --order DESCEND
bar3
bar2
bar1
删除(del)
删除键值,基本用法如下所示:
etcdctl del [options] <key> [range_end] [flags]
常用参数如下所示:
| 参数 | 功能描述 |
|---|---|
| –prefix | 根据prefix进行匹配删除 |
| –prev-kv | 输出删除的键值 |
| –from-key | 按byte进行比较,删除大于等于指定key的结果 |
示例
# 删除name的键值
[root@tiaoban etcd]# etcdctl del name
1
# 删除从foo1到foo3且不包含foo3的键值
[root@tiaoban etcd]# etcdctl del foo1 foo3
2
# 删除前缀为foo的所有键值
[root@tiaoban etcd]# etcdctl del --prefix foo
1
更新(put覆盖)
若键已经存在,则进行更新并覆盖原有值,若不存在,则进行添加。
查询键历史记录查询
etcd在每次键值变更时,都会记录变更信息,便于我们查看键变更记录
监听命令
watch是监听键或前缀发生改变的事件流, 主要用法如下所示:
etcdctl watch [options] [key or prefix] [range_end] [--] [exec-command arg1 arg2 ...] [flags]
示例如下所示:
# 对某个key监听操作,当key1发生改变时,会返回最新值
etcdctl watch name
# 监听key前缀
etcdctl watch name --prefix
# 监听到改变后执行相关操作
etcdctl watch name -- etcdctl get age
etcdctl watch name – etcdctl put name Kevin,如果写成,会不会变成死循环,导致无限监视,尽量避免。
示例
监听单个键
# 启动监听命令
[root@tiaoban etcd]# etcdctl watch foo#另一个控制台执行新增命令
[root@tiaoban ~]# etcdctl put foo bar
OK# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar#另一个控制台执行更新命令
[root@tiaoban ~]# etcdctl put foo bar123
OK# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar
PUT
foo
bar123#另一个控制台执行删除命令
[root@tiaoban ~]# etcdctl del foo
1# 观察控制台监听输出
[root@tiaoban etcd]# etcdctl watch foo
PUT
foo
bar
PUT
foo
bar123
DELETE
foo
同时监听多个键
# 监听前缀为foo的键
[root@tiaoban etcd]# etcdctl watch --prefix foo
# 另一个控制台执行操作
[root@tiaoban ~]# etcdctl put foo1 bar1
OK
[root@tiaoban ~]# etcdctl put foo2 bar2
OK
[root@tiaoban ~]# etcdctl del foo1
1
# 观察控制台输出
[root@tiaoban etcd]# etcdctl watch --prefix foo
PUT
foo1
bar1
PUT
foo2
bar2
DELETE
foo1# 监听指定的多个键
[root@tiaoban etcd]# etcdctl watch -i
watch name
watch location# 另一个控制台执行操作
[root@tiaoban ~]# etcdctl put name cuiliang
OK
[root@tiaoban ~]# etcdctl del name
1
[root@tiaoban ~]# etcdctl put location beijing
OK
# 观察控制台输出
[root@tiaoban etcd]# etcdctl watch -i
watch name
watch location
PUT
name
cuiliang
DELETE
namePUT
location
beijing
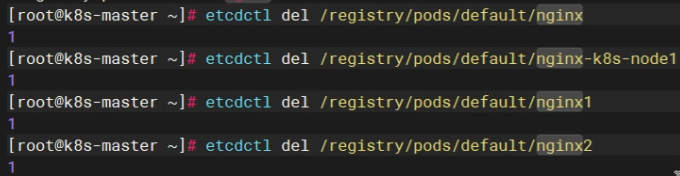
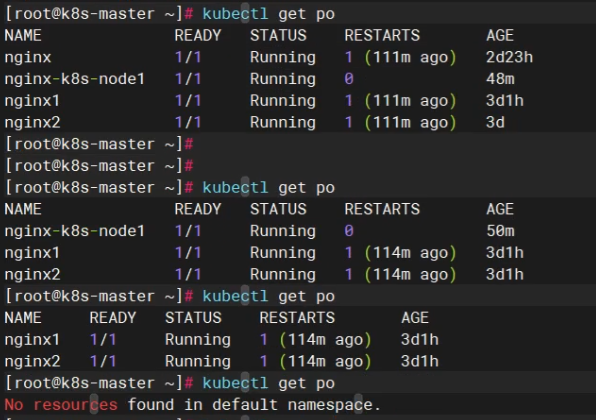
租约命令
租约具有生命周期,需要为租约授予一个TTL(time to live),将租约绑定到一个key上,则key的生命周期与租约一致,可续租,可撤销租约,类似于redis为键设置过期时间。其主要用法如下所示:
etcdctl lease <subcommand> [flags]
添加租约
主要用法如下所示:
etcdctl lease grant <ttl> [flags]
示例:
# 设置60秒后过期时间
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a2b granted with TTL(60s)
# 把foo和租约绑定,设置成60秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a29 foo bar
OK
# 租约期内查询键值
[root@tiaoban etcd]# etcdctl get foo
foo
bar
# 租约期外查询键值
[root@tiaoban etcd]# etcdctl get foo
返回为空
查看租约
查看租约信息,以便续租或查看租约是否仍然存在或已过期。
查看租约详情主要用法如下所示:
etcdctl lease timetolive <leaseID> [options] [flags]
示例:
# 添加一个50秒的租约
[root@tiaoban etcd]# etcdctl lease grant 50
lease 6e1e86f4c6512a32 granted with TTL(50s)
# 将name键绑定到6e1e86f4c6512a32租约上
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a32 name cuiliang
OK
# 查看所有租约列表
[root@tiaoban etcd]# etcdctl lease list
found 1 leases
6e1e86f4c6512a32
# 查看租约详情,remaining(6s) 剩余有效时间6秒;--keys 获取租约绑定的 key
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a32
lease 6e1e86f4c6512a32 granted with TTL(50s), remaining(6s), attached keys([name])
租约续约
通过刷新 TTL 值来保持租约的有效,使其不会过期。
主要用法如下所示:
etcdctl lease keep-alive [options] <leaseID> [flags]
示例如下所示:
# 设置60秒后过期租约
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a36 granted with TTL(60s)
# 把name和租约绑定,设置成 60 秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a36 name cuiliang
OK
# 自动定时执行续约,续约成功后每次租约为60秒
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a36
lease 6e1e86f4c6512a36 keepalived with TTL(60)
lease 6e1e86f4c6512a36 keepalived with TTL(60)
lease 6e1e86f4c6512a36 keepalived with TTL(60)
……
删除租约
通过租约 ID 撤销租约,撤销租约将删除其所有绑定的 key。
主要用法如下所示:
etcdctl lease revoke <leaseID> [flags]
示例如下所示:
# 设置600秒后过期租约
[root@tiaoban etcd]# etcdctl lease grant 600
lease 6e1e86f4c6512a39 granted with TTL(600s)
# 把foo和租约绑定,600秒后过期
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a39 foo bar
OK
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 granted with TTL(600s), remaining(556s), attached keys([foo])
# 删除租约
[root@tiaoban etcd]# etcdctl lease revoke 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 revoked
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a39
lease 6e1e86f4c6512a39 already expired
# 获取键值
[root@tiaoban etcd]# etcdctl get foo
返回为空
多key同一租约
一个租约支持绑定多个 key
# 设置60秒后过期的租约
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a3e granted with TTL(60s)
# foo1与租约绑定
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a3e foo1 bar1
OK
# foo2与租约绑定
[root@tiaoban etcd]# etcdctl put --lease=6e1e86f4c6512a3e foo2 bar2
OK
# 查看租约详情
[root@tiaoban etcd]# etcdctl lease timetolive --keys 6e1e86f4c6512a3e
lease 6e1e86f4c6512a3e granted with TTL(60s), remaining(14s), attached keys([foo1 foo2])
租约过期后,所有 key 值都会被删除,因此:
- 当租约只绑定了一个 key 时,想删除这个 key,最好的办法是撤销它的租约,而不是直接删除这个 key。
- 当租约没有绑定key时,应主动把它撤销掉,单纯删除 key 后,续约操作持续进行,会造成内存泄露。
直接删除key演示:
# 设置租约并绑定 zoo1
[root@tiaoban etcd]# etcdctl lease grant 60
lease 6e1e86f4c6512a43 granted with TTL(60s)
[root@tiaoban etcd]# etcdctl --lease=6e1e86f4c6512a43 put zoo1 val1
OK
# 续约
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a43
lease 6e1e86f4c6512a43 keepalived with TTL(60)# 此时在另一个控制台执行删除key操作:
[root@tiaoban ~]# etcdctl del zoo1
1
# 单纯删除 key 后,续约操作持续进行,会造成内存泄露
[root@tiaoban etcd]# etcdctl lease keep-alive 6e1e86f4c6512a43
lease 6e1e86f4c6512a43 keepalived with TTL(60)
lease 6e1e86f4c6512a43 keepalived with TTL(60)
lease 6e1e86f4c6512a43 keepalived with TTL(60)
...
撤销key的租约演示:
# 设置租约并绑定 zoo1
[root@tiaoban etcd]# etcdctl lease grant 50
lease 32698142c52a1717 granted with TTL(50s)
[root@tiaoban etcd]# etcdctl --lease=32698142c52a1717 put zoo1 val1
OK# 续约
[root@tiaoban etcd]# etcdctl lease keep-alive 32698142c52a1717
lease 32698142c52a1717 keepalived with TTL(50)
lease 32698142c52a1717 keepalived with TTL(50)# 另一个控制台执行:etcdctl lease revoke 32698142c52a1717# 续约撤销并退出
lease 32698142c52a1717 expired or revoked.
[root@tiaoban etcd]# etcdctl get zoo1
# 返回空
备份恢复命令
主要用于管理节点的快照,其主要用法如下所示:
etcdctl snapshot <subcommand> [flags]
生成快照
其主要用法如下所示:
etcdctl snapshot save <filename> [flags]
示例如下所示:
etcdctl snapshot save etcd-snapshot.db
查看快照
其主要用法如下所示:
etcdctl snapshot status <filename> [flags]
示例如下所示:
etcdctl snapshot status etcd-snapshot.db -w table
恢复快照
其主要用法如下所示:
etcdctl snapshot restore <filename> [options] [flags]
备份恢复演示
- 新建一个名为name的key
[root@tiaoban ~]# etcdctl put name cuiliang
OK
[root@tiaoban ~]# etcdctl get name
name
cuiliang
[root@tiaoban ~]# etcdctl endpoint status -w table
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 192.168.10.100:2379 | 2e0eda3ad6bc6e1e | 3.4.23 | 20 kB | true | false | 4 | 10 | 10 | |
| 192.168.10.11:2379 | bc34c6bd673bdf9f | 3.4.23 | 20 kB | false | false | 4 | 10 | 10 | |
| 192.168.10.12:2379 | 5d2c1bd3b22f796f | 3.4.23 | 20 kB | false | false | 4 | 10 | 10 | |
+---------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
- 生成快照,创建名为snap.db的备份文件
[root@k8s-work1 ~]# etcdctl snapshot save snap.db
{"level":"info","ts":1679220752.5883558,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"snap.db.part"}
{"level":"info","ts":"2023-03-19T18:12:32.592+0800","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1679220752.5924425,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2023-03-19T18:12:32.595+0800","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1679220752.597161,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"25 kB","took":0.008507131}
{"level":"info","ts":1679220752.5973082,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"snap.db"}
Snapshot saved at snap.db
- 查看备份文件详情
[root@k8s-work1 ~]# ls -lh snap.db
-rw------- 1 root root 25K 3月 19 18:12 snap.db
[root@k8s-work1 ~]# etcdctl snapshot status snap.db -w table
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 8f097221 | 39 | 47 | 25 kB |
+----------+----------+------------+------------+
- 把快照文件传到其他节点
[root@k8s-work1 ~]# scp snap.db 192.168.10.100:/root 100% 24KB 6.9MB/s 00:00
[root@k8s-work1 ~]# scp snap.db 192.168.10.12:/root
- 停止所有节点的etcd服务,并删除数据目录
[root@k8s-work1 ~]# rm -rf /var/lib/etcd/*
[root@k8s-work1 ~]# etcdctl snapshot restore test.db
[root@k8s-work1 ~]# cp -r default.etcd/member/ /var/lib/etcd/
[root@k8s-work1 ~]# docker ps -a | grep etcd
[root@k8s-work1 ~]# docker restart 550
[root@k8s-work1 ~]# etcdctl get s
s
1
# 其余两个节点相同操作








打造一个“智能论文生产线”,把写作流程变成自动化)










