文章目录
- 🌟 第0层:极简版(30秒理解)
- 核心公式
- 生活比喻
- 📚 第1层:基础概念(5分钟理解)
- 1. 分词器基础
- 1.1 分词器的核心作用
- 1.2 主流分词算法对比
- 2. 基础实现
- 2.1 BPE实现原理
- 2.2 特殊标记处理
- 2.3 和 huggingface的Tokenizer库做对比
- 2.4 WordPiece分词器
- 2.4.1 WordPiece的工作原理
- 2.5 SentencePiece
- 2.5.1 SentencePiece的概述
- 2.5.2 SentencePiece的工作原理
- 3. 基础应用
- 3.1 选择指南
🌟 第0层:极简版(30秒理解)
一句话核心:分词器是语言模型的"词汇翻译器"——BPE是"高频字符对合并器",WordPiece是"最大似然子词分割器",SentencePiece是"语言无关编码器",优秀的分词器能使模型性能提升5-15%,训练速度提高10-20%,特别在低资源语言上效果更显著。
核心公式
最优词汇表 = argmin(α·表示效率 + β·词汇量 - γ·训练稳定性)
分词效率 = f(词汇表大小, 语言特性, 模型架构)
- 关键特性:分词直接影响模型表示能力、训练效率和泛化性能
- 优势:处理未登录词,平衡词汇量与表示能力
- 挑战:语言特性差异,特殊领域适应,长尾分布处理
生活比喻
想象图书馆编目系统:
- 传统分词:按整本书分类 → 词汇量爆炸
- BPE:按高频词组创建新类别 → 高效但可能碎片化
- SentencePiece:按字符组合创建类别 → 语言无关但可能过细
- 理想分词:既识别完整概念又处理新词 → 平衡效率与表达
💡 记住这个数字:5-15% → 10-20% → 30-50%
优秀分词器可使模型性能提升5-15%,训练速度提高10-20%,在低资源语言上效果提升30-50%
📚 第1层:基础概念(5分钟理解)
1. 分词器基础
1.1 分词器的核心作用
核心功能:
- 文本→ID转换:将原始文本映射为模型可处理的整数序列
- 未知词处理:通过子词机制处理未见词汇
- 语言表示:影响模型对语言结构的理解
- 效率优化:控制序列长度和计算复杂度
关键组件:
- 词汇表(Vocabulary):词项到ID的映射
- 分词算法:将文本拆分为词项的规则
- 特殊标记:处理特殊场景的标记
- 后处理:添加位置信息、截断和填充
1.2 主流分词算法对比
| 算法 | 代表模型 | 核心思想 | 优点 | 局限 |
|---|---|---|---|---|
| BPE | GPT系列 | 高频字符对合并 | 处理未登录词好 | 可能产生不自然分割 |
| WordPiece | BERT | 最大似然子词分割 | 适合英文任务 | 严重依赖空格 |
| SentencePiece | T5, XLNet | 无空格分词 | 语言无关 | 训练较慢 |
| Unigram LM | 部分SentencePiece | 概率模型 | 可逆转换 | 计算复杂 |
关键区别:
- BPE:贪心合并高频对
- WordPiece:基于似然选择最佳分割
- SentencePiece:不依赖空格,统一处理所有语言
2. 基础实现
在代码的同级目录新建corpus.txt文件,向里面写一个文字。
2.1 BPE实现原理
Byte-Pair Encoding(BPE)最初用于数据压缩,后来被广泛应用于自然语言处理中的子词分词任务。它通过迭代合并最频繁的字符对或子词对来构建词汇表,是GPT、RoBERTa等现代语言模型的关键分词技术。
BPE的训练过程如下:
初始化词汇表:从训练数据中提取所有唯一字符。例如,对于语料库[“dog” (8次), “log” (6次), “lot” (10次), “dot” (3次), “dogs” (4次)],初始词汇表为[“d”, “o”, “g”, “l”, “t”, “s”]。
统计字符对频率:遍历语料库,计算连续字符对的频率。例如,在"dog"中,字符对为(“d”, “o”)和(“o”, “g”)。
合并最频繁的字符对:选择频率最高的字符对,合并为新token。
更新词汇表:将新token加入词汇表,重新分词语料库,重复上述过程,直到达到目标词汇表大小。
示例:BPE训练
语料库:[“dog” (8次), “log” (6次), “lot” (10次), “dot” (3次), “dogs” (4次)]
步骤0:初始化
词汇表:[“d”, “o”, “g”, “l”, “t”, “s”]
语料库分词:
- dog: [“d”, “o”, “g”]
- log: [“l”, “o”, “g”]
- lot: [“l”, “o”, “t”]
- dot: [“d”, “o”, “t”]
- dogs: [“d”, “o”, “g”, “s”]
步骤1:统计频率
字符对:
- (“d”, “o”):15次(dog x8, dot x3, dogs x4)
- (“o”, “g”):18次(dog x8, log x6, dogs x4)
- (“l”, “o”):16次(log x6, lot x10)
- (“o”, “t”):13次(lot x10, dot x3)
- (“d”, “t”):3次(dot x3)
- (“g”, “s”):4次(dogs x4)
最高频率:(“o”, “g”)(18次)
合并为"og",新词汇表:[“d”, “o”, “g”, “l”, “t”, “s”, “og”]
步骤2:重新分词
- dog: [“d”, “og”]
- log: [“l”, “og”]
- lot: [“l”, “o”, “t”]
- dot: [“d”, “o”, “t”]
- dogs: [“d”, “og”, “s”]
继续统计新字符对频率:
- (“l”, “o”):10次(lot x10)
- (“o”, “t”):13次(lot x10, dot x3)
- (“d”, “o”):3次(dot x3)
- (“d”, “og”):12次(dog x8, dogs x4)
- (“l”, “og”):6次(log x6)
- (“og”, “s”):4次(dogs x4)
最高频率:(“o”, “t”)(13次)
合并为"ot",新词汇表:[“d”, “o”, “g”, “l”, “t”, “s”, “og”, “ot”]
步骤3:再次重新分词
- dog: [“d”, “og”]
- log: [“l”, “og”]
- lot: [“l”, “ot”]
- dot: [“d”, “ot”]
- dogs: [“d”, “og”, “s”]
继续统计新字符对频率:
- (“d”, “og”):12次(dog x8, dogs x4)
- (“l”, “og”):6次(log x6)
- (“l”, “ot”):10次(lot x10)
- (“d”, “ot”):3次(dot x3)
- (“og”, “s”):4次(dogs x4)
最高频率:(“d”, “og”)(12次)
合并为"dog",新词汇表:[“d”, “o”, “g”, “l”, “t”, “s”, “og”, “ot”, “dog”]
示例:BPE分词
假设最终词汇表为:[“d”, “o”, “g”, “l”, “t”, “s”, “og”, “ot”, “dog”, “log”]
分词"dogs":
- 从左到右匹配最长子词:
- "d"匹配
- "do"不匹配
- "dog"匹配
- "s"匹配
- 结果:[“dog”, “s”]
分词"logs":
- "l"匹配
- "lo"不匹配
- "log"匹配
- "s"匹配
- 结果:[“log”, “s”]
分词"dot":
- "d"匹配
- "do"不匹配
- "dot"不匹配(假设"dot"未被合并)
- "do"不匹配
- "ot"匹配
- 结果:[“d”, “ot”]
BPE通过这种方式将单词分解为有意义的子词单元,既能处理未登录词,又能保持词汇表大小在合理范围内。 这种方法在现代NLP系统中被广泛应用,因为它能有效地平衡词汇表大小和表示能力。
代码示例:
import re
from collections import defaultdict, Counterclass BPETokenizer:def __init__(self, special_tokens=None):# 修改初始化部分self.vocab = set()self.merge_rules = {}# 特殊标记字典,键为标记,值为IDself.special_tokens = special_tokens or {"[PAD]": 0,"[UNK]": 1,"[CLS]": 2,"[SEP]": 3,"[MASK]": 4}# 构建ID到token的反向映射self.id_to_token = {v: k for k, v in self.special_tokens.items()}self.token_to_id = self.special_tokens.copy()def train(self, corpus, vocab_size=10000):"""训练BPE模型"""# 对于中文,我们按字符分割words = list(corpus.replace(' ', '_')) # 用下划线表示空格word_freq = Counter()# 统计字符频率for char in words:word_freq[char] += 1# 初始化词汇表self.vocab = set(self.special_tokens.keys())self.vocab.update(word_freq.keys())# 初始化符号序列,每个字符作为一个符号symbols_list = [[char] for char in words]# BPE训练过程current_vocab_size = len(self.vocab)while current_vocab_size < vocab_size:# 统计相邻符号对的频率pair_freq = defaultdict(int)for symbols in symbols_list:for i in range(len(symbols) - 1):pair = (symbols[i], symbols[i + 1])pair_freq[pair] += 1if not pair_freq:break# 找到最频繁的符号对best_pair = max(pair_freq, key=pair_freq.get)# 检查是否已经存在这个合并规则if best_pair in self.merge_rules:breaknew_token = ''.join(best_pair)# 如果新token已存在,跳过if new_token in self.vocab:del pair_freq[best_pair]if not pair_freq:breakcontinue# 添加新token到词汇表self.vocab.add(new_token)self.merge_rules[best_pair] = new_token# 更新所有符号序列new_symbols_list = []for symbols in symbols_list:new_symbols = self._apply_merge_rule_to_symbols(symbols, best_pair, new_token)new_symbols_list.append(new_symbols)symbols_list = new_symbols_listcurrent_vocab_size += 1# 构建完整的词汇表映射self._build_vocab_mappings()def _apply_merge_rule_to_symbols(self, symbols, pair, new_token):"""将合并规则应用到符号序列"""new_symbols = []i = 0while i < len(symbols):if i < len(symbols) - 1 and symbols[i] == pair[0] and symbols[i + 1] == pair[1]:new_symbols.append(new_token)i += 2else:new_symbols.append(symbols[i])i += 1return new_symbolsdef _build_vocab_mappings(self):"""构建词汇表映射"""# 清空现有的映射self.id_to_token.clear()self.token_to_id.clear()# 先添加特殊标记for token, id in self.special_tokens.items():self.id_to_token[id] = tokenself.token_to_id[token] = id# 添加普通词汇表项sorted_vocab = sorted(self.vocab)for i, token in enumerate(sorted_vocab):token_id = i + len(self.special_tokens)self.id_to_token[token_id] = tokenself.token_to_id[token] = token_iddef tokenize(self, text):"""使用训练好的BPE模型进行分词"""# 将文本转换为初始符号序列symbols = list(text.replace(' ', '_')) # 空格用特殊符号表示# 重复应用合并规则直到无法继续合并changed = Truewhile changed:changed = Falsenew_symbols = []i = 0while i < len(symbols):if i < len(symbols) - 1:pair = (symbols[i], symbols[i + 1])if pair in self.merge_rules:new_symbols.append(self.merge_rules[pair])i += 2changed = Truecontinuenew_symbols.append(symbols[i])i += 1symbols = new_symbols# 将下划线转换回空格标记tokens = []for symbol in symbols:if symbol == '_':tokens.append('[SPACE]') # 或者其他表示空格的方式else:tokens.append(symbol)return tokensdef encode(self, text):"""将文本转换为ID序列"""tokens = self.tokenize(text)ids = []for token in tokens:if token in self.token_to_id:ids.append(self.token_to_id[token])else:ids.append(self.token_to_id.get("[UNK]", 1))return idsdef decode(self, ids):"""将ID序列转换回文本"""tokens = []for id in ids:if id in self.id_to_token:token = self.id_to_token[id]if token == '[SPACE]':tokens.append(' ')elif token not in self.special_tokens:tokens.append(token)else:# 特殊标记不添加到解码文本中passelse:tokens.append('[UNK]')return ''.join(tokens)def vocab_size(self):"""返回词汇表大小"""return len(self.vocab) + len(self.special_tokens)# 使用示例
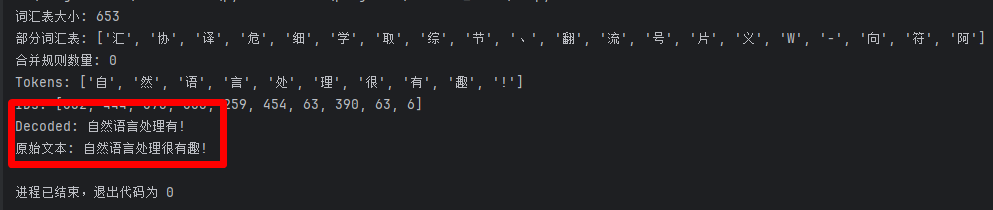
if __name__ == "__main__":# 初始化分词器tokenizer = BPETokenizer()# 训练语料with open("corpus.txt", "r", encoding="utf-8") as f:corpus = f.read()# 如果你希望保留一些基本的文本清理操作,可以添加如下代码:# with open("corpus.txt", "r", encoding="utf-8") as f:# corpus = f.read().strip() # 读取并去除首尾空白字符# 训练BPE模型tokenizer.train(corpus, vocab_size=100)print("词汇表大小:", tokenizer.vocab_size())print("部分词汇表:", list(tokenizer.vocab)[:20])print("合并规则数量:", len(tokenizer.merge_rules))# 测试分词text = "自然语言处理很有趣!"tokens = tokenizer.tokenize(text)print("Tokens:", tokens)# 测试编码ids = tokenizer.encode(text)print("IDs:", ids)# 测试解码decoded = tokenizer.decode(ids)print("Decoded:", decoded)print("原始文本:", text)
2.2 特殊标记处理
关键特殊标记:
SPECIAL_TOKENS = {"[PAD]": 0, # 填充标记"[UNK]": 1, # 未知词标记"[CLS]": 2, # 分类标记"[SEP]": 3, # 分隔标记"[MASK]": 4, # 掩码标记"[BOS]": 5, # 开始标记"[EOS]": 6, # 结束标记
}
处理策略:
- [UNK]最小化:通过足够大的词汇表减少未知词
- 位置编码兼容:确保特殊标记不影响位置信息
- 任务适配:不同任务需要不同的特殊标记组合
- 长度控制:通过截断和填充保证序列长度一致
2.3 和 huggingface的Tokenizer库做对比
安装库,执行命令:
pip install tokenizers
from tokenizers import Tokenizer, models, pre_tokenizers, trainers, processors
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents# 初始化BPE分词器
tokenizer = Tokenizer(models.BPE(unk_token="[UNK]"))# 设置预分词器(按空格和标点分割)
tokenizer.pre_tokenizer = pre_tokenizers.Sequence([pre_tokenizers.Whitespace(),pre_tokenizers.Punctuation(),pre_tokenizers.Digits(individual_digits=True)
])# 设置规范化器(可选)
tokenizer.normalizer = normalizers.Sequence([NFD(), StripAccents()])# 定义特殊标记
special_tokens = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]# 定义训练器
trainer = trainers.BpeTrainer(vocab_size=30000,min_frequency=2,special_tokens=special_tokens,
)# 训练分词器
files = ["./corpus.txt"] # 替换为你的语料文件路径
tokenizer.train(files, trainer)# 添加后处理(如添加[CLS]和[SEP])
tokenizer.post_processor = processors.TemplateProcessing(single="[CLS] $A [SEP]",pair="[CLS] $A [SEP] $B:1 [SEP]:1",special_tokens=[("[CLS]", tokenizer.token_to_id("[CLS]")),("[SEP]", tokenizer.token_to_id("[SEP]")),],
)# 启用填充和截断
from tokenizers import decoders
tokenizer.enable_padding(pad_id=0, pad_token="[PAD]")
tokenizer.enable_truncation(max_length=512)
tokenizer.decoder = decoders.BPEDecoder()# 保存和加载分词器
tokenizer.save("tokenizer.json")
tokenizer = Tokenizer.from_file("tokenizer.json")# 在现有代码的基础上增加以下内容# 使用分词器处理文本并显示详细结果
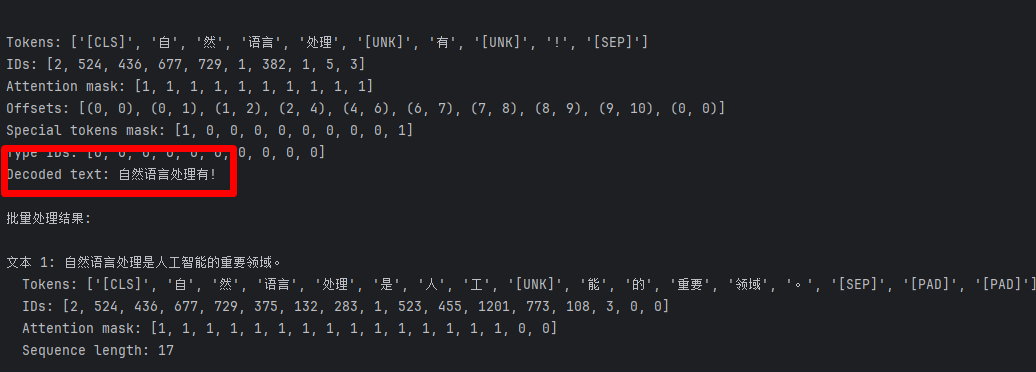
text = "自然语言处理很有趣!"
output = tokenizer.encode(text)print("Tokens:", output.tokens)
print("IDs:", output.ids)
print("Attention mask:", output.attention_mask)
print("Offsets:", output.offsets)
print("Special tokens mask:", output.special_tokens_mask)
print("Type IDs:", output.type_ids)# 增加解码功能,将ID转换回文本
decoded_text = tokenizer.decode(output.ids)
print("Decoded text:", decoded_text)# 批量处理并显示详细结果
batch = ["自然语言处理是人工智能的重要领域。", "机器学习是实现人工智能的一种方法。", "深度学习是机器学习的一个分支。"]
batch_output = tokenizer.encode_batch(batch)print("\n批量处理结果:")
for i, (text, encoding) in enumerate(zip(batch, batch_output)):print(f"\n文本 {i+1}: {text}")print(f" Tokens: {encoding.tokens}")print(f" IDs: {encoding.ids}")print(f" Attention mask: {encoding.attention_mask}")print(f" Sequence length: {len(encoding.ids)}")# 增加词汇表信息
print(f"\n词汇表大小: {tokenizer.get_vocab_size()}")
print(f"特殊标记ID:")
for token in ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]:token_id = tokenizer.token_to_id(token)if token_id is not None:print(f" {token}: {token_id}")# 增加对未知词汇的处理示例
unknown_text = "这是一个包含罕见词汇的句子:🦙"
unknown_output = tokenizer.encode(unknown_text)
print(f"\n包含未知词汇的处理结果:")
print(f"原文本: {unknown_text}")
print(f"Tokens: {unknown_output.tokens}")
print(f"IDs: {unknown_output.ids}")# 显示词汇表中的部分词汇
vocab = tokenizer.get_vocab()
print(f"\n词汇表示例 (前20个):")
for i, (token, id) in enumerate(list(vocab.items())[:20]):print(f" {token}: {id}")
2.4 WordPiece分词器
WordPiece是由Google开发的子词分词算法,作为BERT系列模型的核心分词技术,它通过最大化语言模型似然概率来决定子词合并顺序。与BPE不同,WordPiece采用基于概率的合并策略:优先合并能最大程度提升训练数据概率的字符对。其显著特征是使用##前缀标记非首子词(如"playing"→[“play”, “##ing”]),既能处理未登录词,又能保留词形信息,在跨语言任务中表现优异。
2.4.1 WordPiece的工作原理
WordPiece的训练流程基于期望最大化(EM)算法,核心步骤如下:
-
初始化词汇表:
- 从训练数据提取所有唯一字符(含标点、数字等)。
- 添加特殊标记:
[UNK](未知词)、[CLS](分类符)、[SEP](分隔符)。
-
概率驱动的合并:
- 计算合并得分:对每个字符对
(x,y),计算得分 = count(xy)count(x)×count(y)\frac{\text{count}(xy)}{\text{count}(x) \times \text{count}(y)}count(x)×count(y)count(xy)
(即合并后子词的互信息增益,值越大表示合并越能提升语言模型概率) - 选择最优合并:选取得分最高的字符对,合并为新子词(如
"e"+"r"→"er")。
- 计算合并得分:对每个字符对
-
迭代优化:
- 用新子词更新语料库分词结果
- 重新计算所有字符对得分
- 重复直到词汇表达到预设大小(BERT-base通常为30,522)
示例:WordPiece训练
语料库:["low" (10次), "lower" (8次), "slow" (6次), "flow" (5次), "lowest" (4次)]
步骤0:初始化
- 词汇表:
["l", "o", "w", "e", "r", "s", "f", "t"] - 语料库分词:
low: ["l", "o", "w"] lower: ["l", "o", "w", "e", "r"] slow: ["s", "l", "o", "w"] flow: ["f", "l", "o", "w"] lowest: ["l", "o", "w", "e", "s", "t"]
步骤1:计算合并得分
| 字符对 | count(xy) | count(x) | count(y) | 得分 = count(xy)/(count(x)×count(y)) |
|---|---|---|---|---|
| (l,o) | 33 | 33 | 33 | 33/(33×33) = 0.0303 |
| (o,w) | 33 | 33 | 33 | 0.0303 |
| (w,e) | 12 | 33 | 12 | 12/(33×12) = 0.0303 |
| (e,r) | 8 | 12 | 8 | 8/(12×8) = 0.0833 (最高) |
| (e,s) | 4 | 12 | 10 | 4/(12×10) = 0.0333 |
| (s,l) | 6 | 10 | 33 | 6/(10×33) = 0.0182 |
- 合并结果:
"e" + "r" → "er" - 新词汇表:
["l", "o", "w", "e", "r", "s", "f", "t", "er"]
步骤2:重新分词并迭代
-
更新分词:
lower: ["l", "o", "w", "er"] # "e"+"r"合并为"er" lowest: ["l", "o", "w", "e", "s", "t"] # 未受影响 -
新字符对统计:
(w, er):8次(来自"lower")(e, s):4次(来自"lowest")
-
重新计算得分:
字符对 count(xy) count(x) count(y) 得分 (e,s) 4 4 10 4/(4×10)=0.1000 (最高) (w,er) 8 33 8 8/(33×8)=0.0303 (l,o) 33 33 33 0.0303 -
合并结果:
"e" + "s" → "es" -
新词汇表:
["l", "o", "w", "e", "r", "s", "f", "t", "er", "es"]
步骤3:最终分词效果
- "lowest"分词:
["l", "o", "w", "es", "t"]→ 后续可能合并"l"+"o"→"lo","lo"+"w"→"low" - 典型词汇表示例:
["l", "o", "w", "er", "es", "low", "##er", "##es"]
示例:WordPiece分词
假设最终词汇表:["low", "##er", "##es", "s", "f", "l", "o", "w", "t"]
分词"lowest":
- 从左到右匹配:
"l"→ 匹配,但"lo"不在词汇表"low"→ 匹配(最长前缀)- 剩余
"est"→"e"不在词汇表,尝试"es"→ 匹配 - 剩余
"t"→ 匹配
- 添加##规则:
- 首子词
"low"无前缀 - 后续子词
"es"和"t"需加##(但"t"为独立字符)
- 首子词
- 结果:
["low", "##es", "t"]
分词"slower"(未登录词):
- 匹配过程:
"s"→ 匹配"sl"不匹配 → 回退到"s""l"→ 匹配"lo"不匹配 →"l""ow"不匹配 →"o"→"w""er"→ 匹配
- 结果:
["s", "l", "o", "w", "##er"]
分词"flow":
"f"→ 匹配"fl"不匹配 →"f""l"→ 匹配"lo"不匹配 →"l""ow"不匹配 →"o"→"w"- 结果:
["f", "l", "o", "w"]
关键特性
-
概率驱动合并:
优先合并高互信息的子词(如"er"在英语中作为后缀的极高概率),比BPE的频次统计更符合语言规律。 -
##标记机制:
- 首子词无前缀(
"play") - 后续子词强制加
##("##ing"),使模型明确识别词边界
- 首子词无前缀(
-
未登录词处理:
对罕见词(如"slower")自动拆解为已知子词,避免[UNK]泛滥,显著提升OOV(Out-of-Vocabulary)处理能力。
WordPiece通过概率建模实现了词形敏感的分词策略,成为BERT等模型实现跨任务迁移学习的关键基础。其设计平衡了词汇表效率与语言表达能力,尤其适合处理英语等屈折语。
代码如下:
from tokenizers import Tokenizer, models, pre_tokenizers, trainers, processors
from tokenizers import normalizers
from tokenizers.normalizers import NFD, StripAccents# 初始化BPE分词器
tokenizer = Tokenizer(models.WordPiece(unk_token="[UNK]"))# 设置预分词器(按空格和标点分割)
tokenizer.pre_tokenizer = pre_tokenizers.Sequence([pre_tokenizers.Whitespace(),pre_tokenizers.Punctuation(),pre_tokenizers.Digits(individual_digits=True)
])# 设置规范化器(可选)
tokenizer.normalizer = normalizers.Sequence([NFD(), StripAccents()])# 定义特殊标记
special_tokens = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]# 定义训练器
trainer = trainers.WordPieceTrainer(vocab_size=30000,min_frequency=2,special_tokens=special_tokens,continuing_subword_prefix="##" # 对于WordPiece风格
)# 训练分词器
files = ["./corpus.txt"] # 替换为你的语料文件路径
tokenizer.train(files, trainer)# 添加后处理(如添加[CLS]和[SEP])
tokenizer.post_processor = processors.TemplateProcessing(single="[CLS] $A [SEP]",pair="[CLS] $A [SEP] $B:1 [SEP]:1",special_tokens=[("[CLS]", tokenizer.token_to_id("[CLS]")),("[SEP]", tokenizer.token_to_id("[SEP]")),],
)# 启用填充和截断
from tokenizers import decoderstokenizer.enable_padding(pad_id=0, pad_token="[PAD]")
tokenizer.enable_truncation(max_length=512)
tokenizer.decoder = decoders.WordPiece(prefix="##")# 保存和加载分词器
tokenizer.save("tokenizer.json")
tokenizer = Tokenizer.from_file("tokenizer.json")# 使用分词器处理文本并显示详细结果
text = "自然语言处理很有趣!"
output = tokenizer.encode(text)print("Tokens:", output.tokens)
print("IDs:", output.ids)
print("Attention mask:", output.attention_mask)
print("Offsets:", output.offsets)
print("Special tokens mask:", output.special_tokens_mask)
print("Type IDs:", output.type_ids)# 增加解码功能,将ID转换回文本
decoded_text = tokenizer.decode(output.ids)
print("Decoded text:", decoded_text)# 批量处理并显示详细结果
batch = ["自然语言处理是人工智能的重要领域。", "机器学习是实现人工智能的一种方法。", "深度学习是机器学习的一个分支。"]
batch_output = tokenizer.encode_batch(batch)print("\n批量处理结果:")
for i, (text, encoding) in enumerate(zip(batch, batch_output)):print(f"\n文本 {i + 1}: {text}")print(f" Tokens: {encoding.tokens}")print(f" IDs: {encoding.ids}")print(f" Attention mask: {encoding.attention_mask}")print(f" Sequence length: {len(encoding.ids)}")# 增加词汇表信息
print(f"\n词汇表大小: {tokenizer.get_vocab_size()}")
print(f"特殊标记ID:")
for token in ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"]:token_id = tokenizer.token_to_id(token)if token_id is not None:print(f" {token}: {token_id}")# 增加对未知词汇的处理示例
unknown_text = "这是一个包含罕见词汇的句子:🦙"
unknown_output = tokenizer.encode(unknown_text)
print(f"\n包含未知词汇的处理结果:")
print(f"原文本: {unknown_text}")
print(f"Tokens: {unknown_output.tokens}")
print(f"IDs: {unknown_output.ids}")# 显示词汇表中的部分词汇
vocab = tokenizer.get_vocab()
print(f"\n词汇表示例 (前20个):")
for i, (token, id) in enumerate(list(vocab.items())[:20]):print(f" {token}: {id}")运行结果:
Tokens: ['[CLS]', '自', '##然', '##语言', '##处理', '##很', '##有', '##趣', '!', '[SEP]']
IDs: [2, 526, 866, 1232, 1282, 1065, 943, 1066, 5, 3]
Attention mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Offsets: [(0, 0), (0, 1), (1, 2), (2, 4), (4, 6), (6, 7), (7, 8), (8, 9), (9, 10), (0, 0)]
Special tokens mask: [1, 0, 0, 0, 0, 0, 0, 0, 0, 1]
Type IDs: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Decoded text: 自然语言处理很有趣!批量处理结果:文本 1: 自然语言处理是人工智能的重要领域。Tokens: ['[CLS]', '自', '##然', '##语言', '##处理', '##是', '##人', '##工智能', '##的', '##重要', '##领域', '。', '[SEP]']IDs: [2, 526, 866, 1232, 1282, 695, 867, 2139, 701, 1738, 1419, 108, 3]Attention mask: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]Sequence length: 13文本 2: 机器学习是实现人工智能的一种方法。Tokens: ['[CLS]', '[UNK]', '。', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']IDs: [2, 1, 108, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0]Attention mask: [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]Sequence length: 13文本 3: 深度学习是机器学习的一个分支。Tokens: ['[CLS]', '[UNK]', '。', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']IDs: [2, 1, 108, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0]Attention mask: [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]Sequence length: 13词汇表大小: 2169
特殊标记ID:[PAD]: 0[UNK]: 1[CLS]: 2[SEP]: 3[MASK]: 4包含未知词汇的处理结果:
原文本: 这是一个包含罕见词汇的句子:🦙
Tokens: ['[CLS]', '[UNK]', ':', '[UNK]', '[SEP]']
IDs: [2, 1, 642, 1, 3]词汇表示例 (前20个):分割: 1591c: 65[PAD]: 0##度: 782best: 1400进: 592{: 89build: 1818##ard: 1762则: 180##态: 774##fix: 1422籍: 494康: 294内: 169##洞: 1141沿: 424##语言特性: 1635里: 604贪心合并高频对: 21292.5 SentencePiece
2.5.1 SentencePiece的概述
SentencePiece是由Google开发的一种无需预分词的子词分词工具,它将文本直接视为Unicode字符序列进行处理。与传统分词方法不同,SentencePiece不依赖空格或语言特定规则,能够无缝处理多语言文本、标点符号和特殊字符。它支持两种核心算法:BPE(Byte-Pair Encoding) 和 Unigram语言模型,广泛应用于T5、ALBERT等现代语言模型中。
安装库文件,执行命令:
pip install sentencepiece
2.5.2 SentencePiece的工作原理
SentencePiece的核心创新在于直接处理原始文本,无需预分词步骤。其工作流程如下:
-
原始文本预处理:
- 将空格完全替换为特殊符号
▁(U+2581,代表词界),例如"cat sat" →"▁cat▁sat"(注意:不保留原始空格)。 - 保留所有标点和Unicode字符,避免语言依赖性。
- 将空格完全替换为特殊符号
-
算法选择:
- BPE模式:与标准BPE类似,但以
▁为词边界标志进行字符对合并。 - Unigram模式(更常用):
- 从一个过完备的大词汇表开始(通常通过BPE或高频子串生成)
- 通过迭代剪枝优化词汇表:计算每个子词的损失影响,移除对似然值提升最小的子词
- 使用EM算法估计子词概率,最大化训练数据的似然概率
- 推理时使用Viterbi算法选择全局最优分词路径
- BPE模式:与标准BPE类似,但以
-
词汇表优化:
- 通过正则化控制子词长度,避免过短或过长的子词
- 支持用户自定义词汇表大小和字符覆盖率
示例:SentencePiece训练(Unigram模式)
语料库:["▁cat" (7次), "▁bat" (5次), "▁rat" (9次), "▁car" (4次), "▁cats" (3次)]
步骤0:初始化
- 生成初始大词汇表(通过BPE或高频子串收集):
["▁", "c", "a", "t", "b", "r", "s", "▁c", "ca", "at", "▁b", "▁r", "ar", "ra", "ts", "cats"] - 使用EM算法估计初始子词概率
步骤1:迭代剪枝
- 计算每个子词的损失影响:移除该子词后整体似然值的下降程度
- 移除低贡献子词:如
["r"]、["ts"]等对似然值影响最小的子词 - 重新估计概率:使用EM算法重新计算保留子词的概率
步骤2:最终词汇表
- 优化后的词汇表示例:
["▁", "c", "a", "t", "b", "s", "at", "ca", "▁c", "▁b", "cats"] - 子词概率(示例值):
- P(“at”) = 0.21
- P(“▁c”) = 0.14
- P(“cats”) = 0.08
- P(“a”) = 0.12
示例:SentencePiece分词
假设最终词汇表:["▁", "c", "a", "t", "b", "s", "at", "ca", "▁c", "▁b", "cats"]
对应概率:[0.2, 0.1, 0.12, 0.11, 0.09, 0.08, 0.21, 0.13, 0.14, 0.1, 0.08]
分词"▁cats":
- Viterbi路径搜索:考虑所有可能分割
- 选项1:
["▁", "c", "a", "t", "s"]→ 概率 = 0.2×0.1×0.12×0.11×0.08 = 2.11e-6 - 选项2:
["▁", "c", "a", "ts"]→ "ts"不在词汇表 - 选项3:
["▁", "c", "at", "s"]→ 概率 = 0.2×0.1×0.21×0.08 = 3.36e-4 - 选项4:
["▁", "ca", "t", "s"]→ 概率 = 0.2×0.13×0.11×0.08 = 2.29e-4 - 选项5:
["▁", "cats"]→ 概率 = 0.2×0.08 = 0.016
- 选项1:
- 选择最优路径:选项5概率最高
- 结果:
["▁", "cats"]
分词"▁car":
- Viterbi路径搜索:
- 选项1:
["▁", "c", "a", "r"]→ "r"不在词汇表 - 选项2:
["▁", "c", "ar"]→ "ar"不在词汇表 - 选项3:
["▁c", "a", "r"]→ "r"不在词汇表 - 选项4:
["▁c", "ar"]→ "ar"不在词汇表 - 选项5:
["▁", "ca", "r"]→ "r"不在词汇表
- 选项1:
- 回退到字符级:只能选择
["▁", "c", "a"]+ 未知字符"r" - 结果:
["▁", "c", "a"]+ [UNK](实际处理中会对未知字符做特殊处理)
分词"▁bat":
- Viterbi路径搜索:
- 选项1:
["▁", "b", "a", "t"]→ 概率 = 0.2×0.09×0.12×0.11 = 2.38e-4 - 选项2:
["▁", "b", "at"]→ 概率 = 0.2×0.09×0.21 = 3.78e-3 - 选项3:
["▁b", "a", "t"]→ 概率 = 0.1×0.12×0.11 = 1.32e-3 - 选项4:
["▁b", "at"]→ 概率 = 0.1×0.21 = 0.021
- 选项1:
- 选择最优路径:选项4概率最高
- 结果:
["▁b", "at"]
关键优势
- 语言无关性:无需空格分词,适用于中文、日文等无空格语言。
- 端到端训练:直接从原始字节流学习,避免预处理偏差。
- 灵活控制:通过
character_coverage参数平衡罕见字符处理能力(如中文需99.9%,英文99.95%)。
SentencePiece通过统一框架解决了多语言分词的复杂性,成为现代NLP系统中跨语言迁移学习的关键工具。 其Unigram模式尤其擅长处理形态丰富的语言(如土耳其语),而BPE模式则在资源有限场景下保持高效。
代码示例:
import sentencepiece as spm
import json# 训练SentencePiece模型
def train_sentencepiece():# SentencePiece训练spm.SentencePieceTrainer.train(input='./corpus.txt', # 训练数据文件model_prefix='spm_model', # 模型前缀vocab_size=8046, # 词汇表大小character_coverage=0.9995, # 中文建议接近1.0model_type='bpe', # 使用BPE模型user_defined_symbols=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"], # 特殊标记max_sentence_length=4096, # 最大句子长度shuffle_input_sentence=True, # 随机打乱输入句子minloglevel=1 # 减少日志输出)# 加载训练好的模型
try:train_sentencepiece()sp = spm.SentencePieceProcessor()sp.load('spm_model.model')
except Exception as e:print(f"训练模型时出错: {e}")print("请确保 corpus.txt 文件存在且包含足够的文本数据")# 创建一个简单的测试模型test_text = "自然语言处理是人工智能的重要领域。机器学习很有趣。深度学习是机器学习的一个分支。"with open('test_corpus.txt', 'w', encoding='utf-8') as f:f.write(test_text)spm.SentencePieceTrainer.train(input='test_corpus.txt',model_prefix='spm_model',vocab_size=118,character_coverage=1.0,model_type='bpe',user_defined_symbols=["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]"])sp = spm.SentencePieceProcessor()sp.load('spm_model.model')# 定义特殊标记的ID
special_tokens = {"[PAD]": sp.piece_to_id("[PAD]"),"[UNK]": sp.piece_to_id("[UNK]"),"[CLS]": sp.piece_to_id("[CLS]"),"[SEP]": sp.piece_to_id("[SEP]"),"[MASK]": sp.piece_to_id("[MASK]")
}print("SentencePiece模型信息:")
print(f"词汇表大小: {sp.get_piece_size()}")
print(f"特殊标记ID: {special_tokens}")# 使用分词器处理文本并显示详细结果
text = "自然语言处理很有趣!"
tokens = sp.encode(text, out_type=str)
ids = sp.encode(text, out_type=int)print(f"\n处理文本: {text}")
print("Tokens:", tokens)
print("IDs:", ids)# 增加解码功能,将ID转换回文本
decoded_text = sp.decode(ids)
print("Decoded text:", decoded_text)# 批量处理并显示详细结果
batch = ["自然语言处理是人工智能的重要领域。", "机器学习是实现人工智能的一种方法。", "深度学习是机器学习的一个分支。"]print("\n批量处理结果:")
for i, text in enumerate(batch):tokens = sp.encode(text, out_type=str)ids = sp.encode(text, out_type=int)print(f"\n文本 {i + 1}: {text}")print(f" Tokens: {tokens}")print(f" IDs: {ids}")print(f" Sequence length: {len(ids)}")# 增加对未知词汇的处理示例
unknown_text = "这是一个包含罕见词汇的句子:🦙"
unknown_ids = sp.encode(unknown_text, out_type=int)
unknown_tokens = sp.encode(unknown_text, out_type=str)
print(f"\n包含未知词汇的处理结果:")
print(f"原文本: {unknown_text}")
print(f"Tokens: {unknown_tokens}")
print(f"IDs: {unknown_ids}")# 显示词汇表中的部分词汇
print(f"\n词汇表示例 (前20个):")
for i in range(min(20, sp.get_piece_size())):piece = sp.id_to_piece(i)print(f" {piece}: {i}")# 保存模型信息到JSON文件(可选)
model_info = {"vocab_size": sp.get_piece_size(),"special_tokens": special_tokens,"model_prefix": "spm_model"
}with open("spm_model_info.json", "w", encoding="utf-8") as f:json.dump(model_info, f, ensure_ascii=False, indent=2)print(f"\n模型信息已保存到 spm_model_info.json")
print(f"模型文件: spm_model.model")
print(f"词汇表文件: spm_model.vocab")运行结果:
SentencePiece模型信息:
词汇表大小: 8046
特殊标记ID: {'[PAD]': 3, '[UNK]': 4, '[CLS]': 5, '[SEP]': 6, '[MASK]': 7}处理文本: 自然语言处理很有趣!
Tokens: ['▁自然语言', '处理', '很有趣', '!']
IDs: [2474, 129, 2034, 7887]
Decoded text: 自然语言处理很有趣!批量处理结果:文本 1: 自然语言处理是人工智能的重要领域。Tokens: ['▁自然语言处理是人工智能', '的重要领域', '。']IDs: [3090, 2570, 7683]Sequence length: 3文本 2: 机器学习是实现人工智能的一种方法。Tokens: ['▁', '机器', '学习', '是', '实现', '人工智能的', '一', '种', '方', '法', '。']IDs: [7415, 1571, 476, 7528, 378, 6694, 7523, 0, 7699, 7581, 7683]Sequence length: 11文本 3: 深度学习是机器学习的一个分支。Tokens: ['▁', '深度', '学习', '是', '机器', '学习', '的', '一个', '分', '支', '。']IDs: [7415, 997, 476, 7528, 1571, 476, 7462, 701, 7447, 0, 7683]Sequence length: 11包含未知词汇的处理结果:
原文本: 这是一个包含罕见词汇的句子:🦙
Tokens: ['▁这', '是', '一个', '包含', '罕', '见词汇', '的', '句', '子', ':', '🦙']
IDs: [1449, 7528, 701, 4228, 0, 1936, 7462, 7828, 7727, 7436, 0]词汇表示例 (前20个):<unk>: 0<s>: 1</s>: 2[PAD]: 3[UNK]: 4[CLS]: 5[SEP]: 6[MASK]: 7**: 8--: 9en: 10▁|: 11se: 12to: 13te: 14re: 15▁#: 16▁=: 17▁**: 18"": 19模型信息已保存到 spm_model_info.json
模型文件: spm_model.model
词汇表文件: spm_model.vocab
3. 基础应用
3.1 选择指南
| 任务/语言 | 推荐分词器 | 理由 | 词汇表示示例 |
|---|---|---|---|
| 英文NLU | WordPiece | 与BERT兼容,适合掩码任务 | [“play”, “##ing”] |
| 多语言 | SentencePiece | 语言无关,统一处理 | [“大”, “模型”] |
| 代码生成 | BPE | 处理符号和标识符好 | [“def”, “_”, “func”] |
| 低资源语言 | SentencePiece | 无需分词器 | [“த”, “மி”, “ழ்”] |
| 长文本 | BPE (大词汇表) | 减少序列长度 | [“transform”, “##ers”] |
常见误区:
| 误区 | 事实 | 解决方案 |
|---|---|---|
| “词汇表越大越好” | 过大词汇表增加计算负担 | 根据任务平衡词汇量 |
| “分词器不影响性能” | 分词直接影响模型表现 | 专门优化分词器 |
| “中文需要特殊分词” | SentencePiece统一处理 | 使用无空格分词 |
| “分词只需训练一次” | 领域变化需重新优化 | 定期评估和调整 |
| “特殊标记不重要” | 影响任务性能 | 根据任务定制 |

)

)

)

)

)







)

及常见问题解答)