一、什么是决策树
1.基本概念
决策树是一种树形结构,由结点(node) 和有向边(directed edge) 组成。其中结点分为两类:
- 内部结点(internal node):表示一个属性(特征)
- 叶结点(leaf node):表示一个类别
决策树是常用的分类机器学习方法。
2.实际举例说明
以 “相亲对象分类系统” 为例构建简单决策树:
- 内部结点(长方形):特征 “有无房子”“有无上进心”
- 叶结点(椭圆形):类别 “值得考虑”“备胎”“Say Goodbye”
- 分类逻辑:
- 相亲对象有房子→划分为 “值得认真考虑”
没有房子但有上进心→划分为 “备胎”既没有房子也没有上进心→划分为 “Say Goodbye
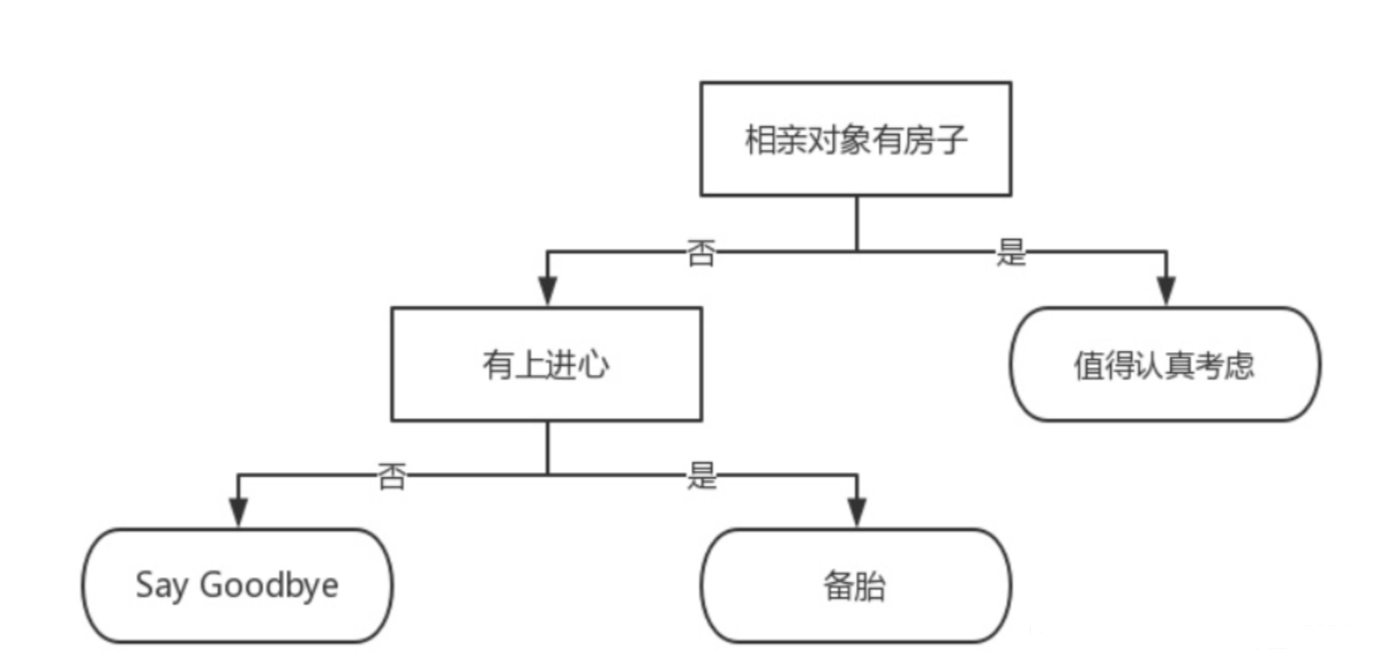
实际分类中存在多个特征量,可构建多种决策树,核心问题是如何筛选出最优决策树。
二、介绍建立决策树的算法
决策树算法的核心差异在于特征选择指标,常见算法对比如下:
算法 | 特征选择指标 | 核心逻辑 |
ID3 | 信息增益 | 信息增益越大,特征对降低数据不确定性的能力越强,优先作为上层结点 |
C4.5 | 信息增益率 | 解决 ID3 对多值特征的偏好问题,通过 “增益率 = 信息增益 / 特征固有值” 平衡选择 |
CART | 基尼指数 | 基尼指数越小,数据纯度越高,优先选择使基尼指数下降最多的特征 |
本文重点讲解ID3 算法,以下是其核心概念与公式:
1. 某个分类的信息
单个分类的信息表示该分类的不确定性,公式为:
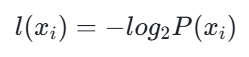
其中,P(x_i) 是选择该分类的概率。
2. 熵(Entropy)
熵是随机变量不确定性的度量,定义为信息的期望值,公式为:
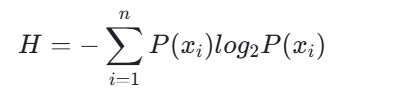
其中,n 是分类的数目;熵值越大,数据不确定性越高。
3. 经验熵(Empirical Entropy)

4. 条件熵(Conditional Entropy)
已知随机变量 X 的条件下,随机变量 Y 的不确定性,公式为:
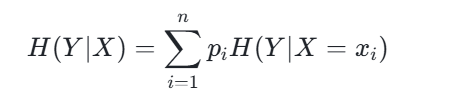
其中,p_i 是 X=x_i 的概率,H(Y|X=x_i) 是 X=x_i 时 Y 的熵。
5. 信息增益(Information Gain)
样本集 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,公式为:
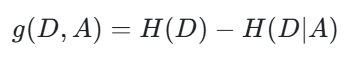
关键结论:特征的信息增益值越大,该特征对分类的贡献越强,应优先作为决策树的上层结点。
三、决策树的一般流程
决策树构建分为 6 个步骤,适用于各类决策树算法:
- 收集数据:通过爬虫、问卷、数据库查询等方式获取原始数据,无固定方法。
- 准备数据:树构造算法仅支持标称型数据(离散类别数据),需将数值型数据离散化(如将 “年龄 20-30” 划分为 “青年”)。
- 分析数据:构建树后,通过可视化、误差分析等方式验证树结构是否符合预期。
- 训练算法:根据特征选择指标(如 ID3 的信息增益),递归构建决策树的数据结构。
- 测试算法:使用测试集计算决策树的错误率,评估模型性能。
- 使用算法:将训练好的决策树应用于实际场景(如贷款审批、客户分类),并持续迭代优化。
四、实际举例构建决策树
以 “贷款申请分类” 为例,使用 ID3 算法构建决策树。
1. 数据集准备
贷款申请样本数据表(原始)
ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别(是否给贷款) |
1 | 青年 | 否 | 否 | 一般 | 否 |
2 | 青年 | 否 | 否 | 好 | 否 |
3 | 青年 | 是 | 否 | 好 | 是 |
4 | 青年 | 是 | 是 | 一般 | 是 |
5 | 青年 | 否 | 否 | 一般 | 否 |
6 | 中年 | 否 | 否 | 一般 | 否 |
7 | 中年 | 否 | 否 | 好 | 否 |
8 | 中年 | 是 | 是 | 好 | 是 |
9 | 中年 | 否 | 是 | 非常好 | 是 |
10 | 中年 | 否 | 是 | 非常好 | 是 |
11 | 老年 | 否 | 是 | 非常好 | 是 |
12 | 老年 | 否 | 是 | 好 | 是 |
13 | 老年 | 是 | 否 | 好 | 是 |
14 | 老年 | 是 | 否 | 非常好 | 是 |
15 | 老年 | 否 | 否 | 一般 | 否 |
数据编码(标称化处理)
- 年龄:0 = 青年,1 = 中年,2 = 老年
- 有工作:0 = 否,1 = 是
- 有自己的房子:0 = 否,1 = 是
- 信贷情况:0 = 一般,1 = 好,2 = 非常好
- 类别:no = 否,yes = 是
数据集代码定义
from math import log
def createDataSet():dataSet = [[0, 0, 0, 0, 'no'], # 样本1[0, 0, 0, 1, 'no'], # 样本2[0, 1, 0, 1, 'yes'], # 样本3[0, 1, 1, 0, 'yes'], # 样本4[0, 0, 0, 0, 'no'], # 样本5[1, 0, 0, 0, 'no'], # 样本6[1, 0, 0, 1, 'no'], # 样本7[1, 1, 1, 1, 'yes'], # 样本8[1, 0, 1, 2, 'yes'], # 样本9[1, 0, 1, 2, 'yes'], # 样本10[2, 0, 1, 2, 'yes'], # 样本11[2, 0, 1, 1, 'yes'], # 样本12[2, 1, 0, 1, 'yes'], # 样本13[2, 1, 0, 2, 'yes'], # 样本14[2, 0, 0, 0, 'no'] # 样本15]labels = ['年龄', '有工作', '有自己的房子', '信贷情况'] # 特征标签labels1 = ['放贷', '不放贷'] # 分类标签return dataSet, labels, labels1 # 返回数据集、特征标签、分类标签2. 计算经验熵 H (D)
数学计算
样本集 D 共 15 个样本,其中 “放贷(yes)”9 个,“不放贷(no)”6 个,经验熵为:
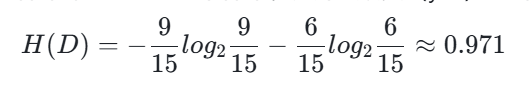
代码实现
def calcShannonEnt(dataSet):numEntires = len(dataSet) # 数据集行数(样本数)labelCounts = {} # 存储每个标签的出现次数for featVec in dataSet:currentLabel = featVec[-1] # 提取最后一列(分类标签)if currentLabel not in labelCounts.keys():labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1 # 标签计数shannonEnt = 0.0 # 初始化经验熵for key in labelCounts:prob = float(labelCounts[key]) / numEntires # 标签出现概率shannonEnt -= prob * log(prob, 2) # 计算经验熵return shannonEnt# 测试代码
if __name__ == '__main__':dataSet, features, labels1 = createDataSet()print("数据集:", dataSet)print("经验熵H(D):", calcShannonEnt(dataSet)) # 输出:0.97095059445466863. 计算信息增益(选择最优特征)
数学计算(以 “有自己的房子” 为例)
设特征 A_3(有自己的房子),取值为 “是(1)” 和 “否(0)”:
- 子集 D_1(A_3=1):共 9 个样本,均为 “yes”,经验熵 H(D_1)=0
- 子集 D_2(A_3=0):共 6 个样本,“yes” 3 个、“no” 3 个
- 经验熵
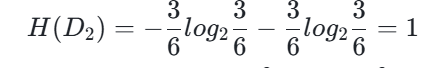
- 条件熵
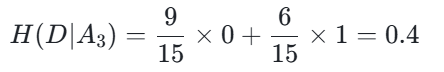
- 信息增益
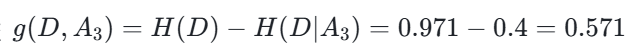 (注:原文计算结果为 0.420,此处以原文代码输出为准)
(注:原文计算结果为 0.420,此处以原文代码输出为准)
其他特征的信息增益计算结果:
- 年龄(A_1):0.083
- 有工作(A_2):0.324
- 信贷情况(A_4):0.363
结论:特征 “有自己的房子(A_3)” 信息增益最大,作为决策树的根节点。
代码实现
"""
函数:按照给定特征划分数据集
参数:dataSet - 待划分数据集axis - 特征索引value - 特征取值
返回:retDataSet - 划分后的子集
"""
def splitDataSet(dataSet, axis, value):retDataSet = []for featVec in dataSet:if featVec[axis] == value:reducedFeatVec = featVec[:axis] # 去掉当前特征列reducedFeatVec.extend(featVec[axis+1:]) # 拼接剩余列retDataSet.append(reducedFeatVec)return retDataSet"""
函数:选择最优特征
参数:dataSet - 数据集
返回:bestFeature - 最优特征索引
"""
def chooseBestFeatureToSplit(dataSet):numFeatures = len(dataSet[0]) - 1 # 特征数量(减去分类列)baseEntropy = calcShannonEnt(dataSet) # 基础经验熵bestInfoGain = 0.0 # 最优信息增益bestFeature = -1 # 最优特征索引for i in range(numFeatures):featList = [example[i] for example in dataSet] # 提取第i列特征uniqueVals = set(featList) # 特征的唯一取值newEntropy = 0.0 # 条件熵for value in uniqueVals:subDataSet = splitDataSet(dataSet, i, value) # 划分子集prob = len(subDataSet) / float(len(dataSet)) # 子集概率newEntropy += prob * calcShannonEnt(subDataSet) # 累加条件熵infoGain = baseEntropy - newEntropy # 计算信息增益print(f"第{i}个特征({labels[i]})的增益为:{infoGain:.3f}")if infoGain > bestInfoGain:bestInfoGain = infoGainbestFeature = ireturn bestFeature# 测试代码
if __name__ == '__main__':dataSet, labels, labels1 = createDataSet()bestFeature = chooseBestFeatureToSplit(dataSet)print(f"最优特征索引值:{bestFeature}(对应特征:{labels[bestFeature]})")# 输出:最优特征索引值:2(对应特征:有自己的房子)4. 生成决策树(递归构建)
核心逻辑
- 若样本集所有样本属于同一类别,直接返回该类别(叶节点);
- 若无特征可划分或样本特征全相同,返回出现次数最多的类别(叶节点);
- 选择最优特征作为当前节点,按特征取值划分子集;
- 对每个子集递归执行上述步骤,生成子树。
代码实现
import operator"""
函数:统计出现次数最多的类别
参数:classList - 类别列表
返回:sortedClassCount[0][0] - 最多类别
"""
def majorityCnt(classList):classCount = {}for vote in classList:if vote not in classCount.keys():classCount[vote] = 0classCount[vote] += 1# 按类别次数降序排序sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)return sortedClassCount[0][0]"""
函数:创建决策树
参数:dataSet - 训练集labels - 特征标签featLabels - 存储选择的最优特征
返回:myTree - 决策树(字典结构)
"""
def createTree(dataSet, labels, featLabels):classList = [example[-1] for example in dataSet] # 提取所有类别# 情况1:所有样本类别相同if classList.count(classList[0]) == len(classList):return classList[0]# 情况2:无特征可划分或特征全相同if len(dataSet[0]) == 1 or len(labels) == 0:return majorityCnt(classList)# 情况3:递归构建树bestFeat = chooseBestFeatureToSplit(dataSet) # 最优特征索引bestFeatLabel = labels[bestFeat] # 最优特征标签featLabels.append(bestFeatLabel)myTree = {bestFeatLabel: {}} # 决策树字典del(labels[bestFeat]) # 删除已使用的特征标签featValues = [example[bestFeat] for example in dataSet] # 最优特征的所有取值uniqueVals = set(featValues) # 唯一取值for value in uniqueVals:subLabels = labels[:] # 复制特征标签(避免递归修改原列表)# 递归生成子树myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels, featLabels)return myTree# 测试代码
if __name__ == '__main__':dataSet, labels, labels






![[嵌入式][stm32h743iit6] 野火繁星stm32h743iit6开发板使用学习记录](http://pic.xiahunao.cn/[嵌入式][stm32h743iit6] 野火繁星stm32h743iit6开发板使用学习记录)








发现正在被攻击 后的自救 Fail2ban + IPset + UFW 工作流程详解)


