K8S官网文档:https://kubernetes.io/zh/docs/home/
Kubernetes是什么
Kubernetes 是用于自动部署、扩缩和管理容器化应用程序的开源系统。 Kubernetes 源自 ,Google 15 年生产环境的运维经验同时凝聚了社区的最佳创意和实践。简称K8s.
Kubernetes:作为开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理。
K8s核心架构
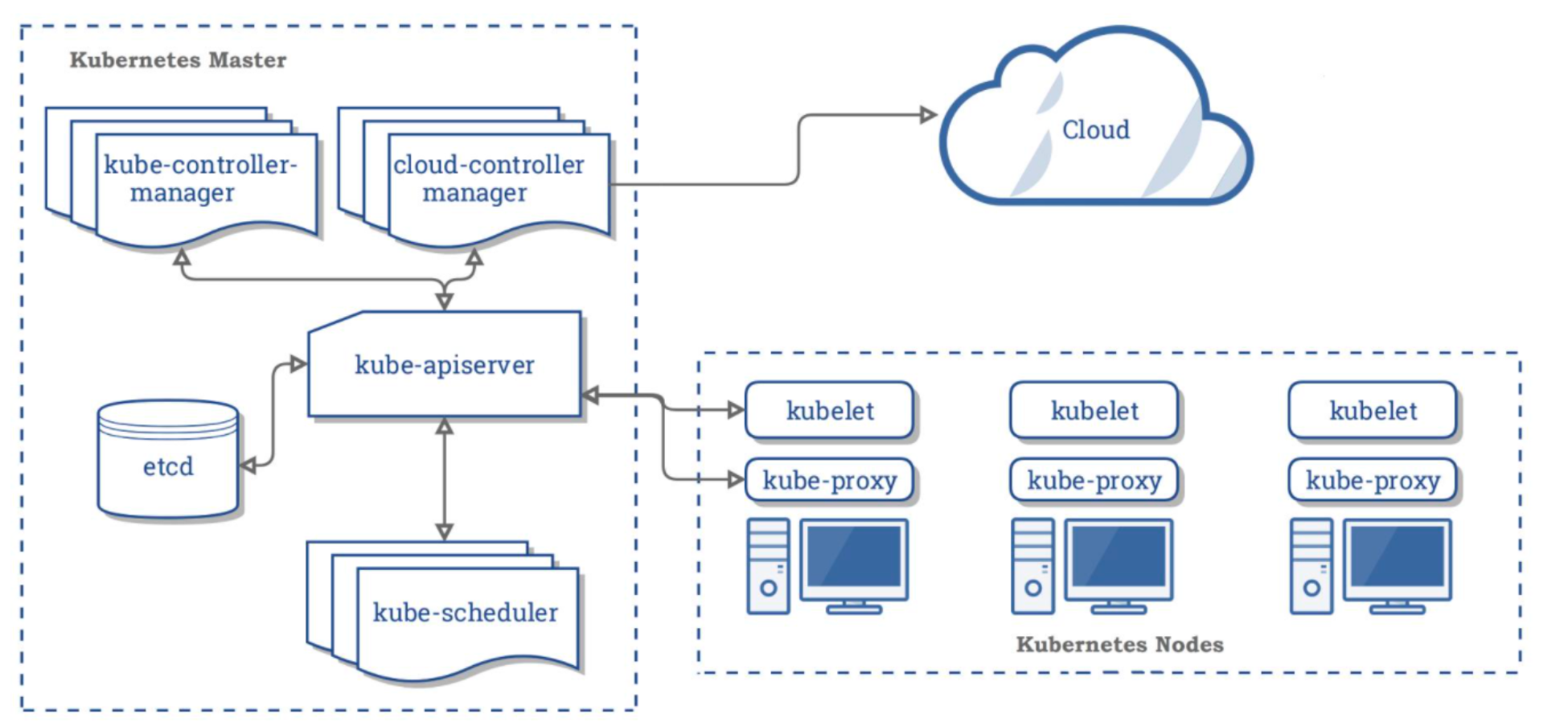
K8S 是属于Master-Worker架构,即有 Master 节点负责核心的调度、管理和运维,Worker 节点则执行用户的程序。但是在 K8S 中,主节点一般被称为Master Node ,而从节点则被称为WorkerNode 或者 Node。
所有 Master Node 和 Worker Node 组成了K8S 集群,同一个集群可能存在多个 Master Node 和 Worker Node。(不是单个主节点)。
为了实现对应的能力,不同类型的节点具有不同的组件。
Master Node组件
- kube-apiserver。K8S 的请求入口服务。API Server 负责接收 K8S 所有请求(来自 UI 界面或者 CLI 命令行工具),然后,API Server 根据用户的具体请求,去通知其他组件干活。
- Scheduler。K8S 所有 Worker Node 的调度器。当用户要部署服务时,Scheduler 会选择最合适的 Worker Node(服务器)来部署。
- Controller Manager。K8S 所有 Worker Node 的监控器。Controller Manager 有很多具体的 Controller,Node Controller、Service Controller、Volume Controller 等。Controller 负责监控和调整在 Worker Node上部署的服务的状态,比如用户要求 A 服务部署 2 个副本,那么当其中一个服务挂了的时候,Controller 会马上调整,让 Scheduler 再选择一个 Worker Node 重新部署服务。
- etcd。K8S 的存储服务。etcd 存储了 K8S 的关键配置和用户配置。K8S 中仅 API Server 才具备读写权限,其他组件必须通过 API Server 的接口才能读写数据。
Worker Node组件
- Kubelet。Worker Node 的监视器,以及与 Master Node 的通讯器。Kubelet 是 Master Node 安插在Worker Node 上的“眼线”,它会定期向 Master Node 汇报自己 Node 上运行的服务的状态,并接受来自Master Node 的指示采取调整措施。负责控制所有容器的启动停止,保证节点工作正常。
- Kube-Proxy。K8S 的网络代理。Kube-Proxy 负责 Node 在 K8S 的网络通讯、以及对外部网络流量的负载均衡。
- Container Runtime。Worker Node 的运行环境。即安装了容器化所需的软件环境确保容器化程序能够跑起来,比如 Docker Engine运行环境。
K8s网络模型
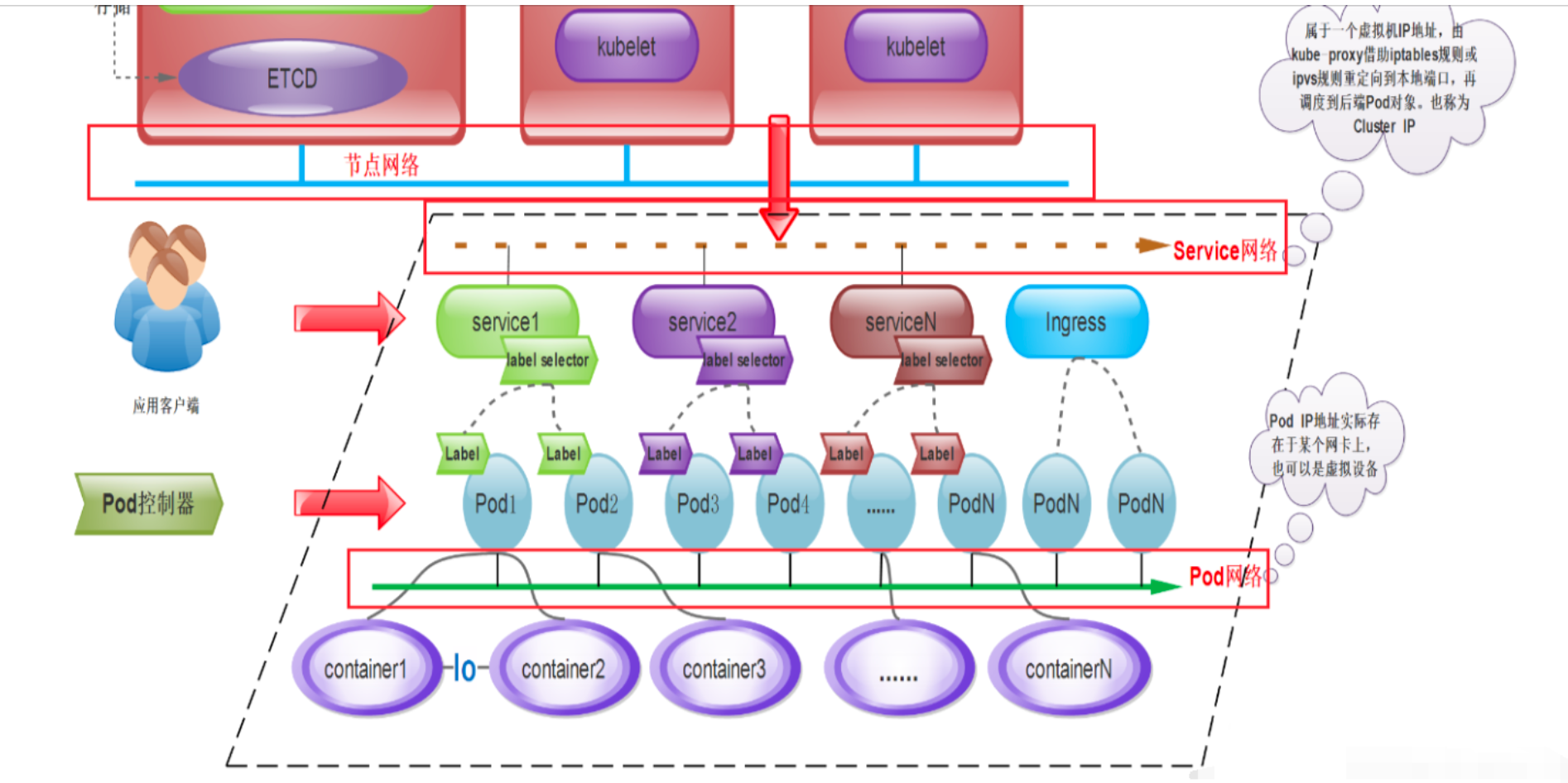
K8s内部存在4中不同的网络通信:
- 同一个Pod内容器之间的通信
- 不同Pod之间通信
- Pod和Service之间通信
- 集群外部流量和Service之间
K8S为Pod和Service资源对象分别使用了各自的专有网络,Pod网络由K8S的网络插件配置实现,而Service网络则由K8S集群指定。
K8s实战/kubectl命令使用
kubectl是apiserver的客户端工具,工作在命令行下,能够连接apiserver实现各种增删改查等操作。kubectl官方使用文档:https://kubernetes.io/zh/docs/reference/kubectl/overview/
NameSpace(命名空间)
- 将同一集群中的资源划分为相互隔离的组。
- 同一命名空间内的资命名称要唯一.
- 命名空间是用来隔离资源的,不隔离网络。
创建namespace
1. 命令方式
kubectl create namespace tuling
2. yaml方式
新建一个名为 my-namespace.yaml 的 YAML 文件
apiVersion: v1
kind: Namespace
metadata:
name: tulingmall
运行:kubectl apply -f my-namespace.yaml
删除namespace
kubectl delete namespace tuling
kubectl delete -f my-namespace.yaml
Pod
Pod是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
Pod中可以有一个或多个容器,这些容器共享存储、网络、以及怎样运行这些容器的声明。
Deployment
Deployment负责创建和更新应用程序的实例,使Pod拥有多副本,自愈,扩缩容等能力。
创建Deployment后,Kubernetes Master 将应用程序实例调度到集群中的各个节点上。如果托管实例的节点关闭或被删除,Deployment控制器会将该实例替换为群集中另一个节点上的实例。这提供了一种自我修复机制来解决机器故障维护问题。
kubectl create deployment // 可以创建一个应用部署deployment与pod
1. kubectl create deployment my-tomcat --image=tomcat:9.0.55
#my-tomcat表示pod的名称 --image表示镜像的地址
2. kubectl get deployment
#查看一下deployment的信息
3. kubectl delete deployment my-tomcat
#删除deployment
4. kubectl logs my-tomcat-6d6b57c8c8-n5gm4
#查看Pod打印的日志
5. #使用 exec 可以在Pod的容器中执行命令
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- env #使用 env 命令查看环境变量
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- ls / # 查看容器的根目录下面内容
kubectl exec my-tomcat-6d6b57c8c8-n5gm4 -- sh #进入Pod容器内部并执行bash命令,如果想退出容器可以使用exit命令
Service
Service是一个抽象层,它定义了一组Pod的逻辑集,并为这些Pod支持外部流量暴露、负载均衡和服务发现。
尽管每个Pod 都有一个唯一的IP地址,但是如果没有Service,这些IP不会暴露在集群外部。Service允许您的应用程序接收外部流量。Service也可以用在ServiceSpec标记type的方式暴露,type类型如下:
- ClusterIP(默认):在集群的内部IP上公开Service。这种类型使得Service只能从集群内访问。
- NodePort:使用NAT在集群中每个选定Node的相同端口上公开Service。使用 <NodeIP>:<NodePort> 从集群外部访问Service。是ClusterIP的超集。
- LoadBalancer:在当前云中创建一个外部负载均衡器(如果支持的话),并为Service分配一个固定的外部IP。是NodePort的超集。
- ExternalName:通过返回带有该名称的CNAME记录,使用任意名称(由spec中的externalName指定)公开Service。不使用代理。
Ingress
Ingress是一种 Kubernetes 资源类型,它允许在 Kubernetes 集群中暴露 HTTP 和 HTTPS 服务。通过 Ingress,您可以将流量路由到不同的服务和端点,而无需使用不同的负载均衡器。
Ingress 通常使用 Ingress Controller 实现,它是一个运行在 Kubernetes 集群中的负载均衡器,它根据Ingress 规则配置路由规则并将流量转发到相应的服务。
Ingress 和 Service区别
Ingress 和 Service都是 Kubernetes 中用于将流量路由到应用程序的机制,但它们在路由层面上有所不同:
- Service 是 Kubernetes 中抽象的应用程序服务,它公开了一个 单一的IP地址和端口,可以用于在 Kubernetes集群内部的 Pod 之间进行流量路由。
- Ingress 是一个 Kubernetes 资源对象,它提供了对集群外部流量路由的规则。Ingress 通过一个公共IP地址和端口将流量路由到一个或多个Service。
存储
Volume
Volume指的是存储卷,包含可被Pod中容器访问的数据目录。容器中的文件在磁盘上是临时存放的,当容器崩溃时文件会丢失,同时无法在多个Pod中共享文件,通过使用存储卷可以解决这两个问题。
PV & PVC
Volume 提供了非常好的数据持久化方案,不过在可管理性上还有不足。要使用Volume, Pod 必须事先知道以下信息:
- 当前的 Volume 类型并明确 Volume 已经创建好。
- 必须知道 Volume 的具体地址信息。
但是 Pod 通常是由应用的开发人员维护,而 Volume 则通常是由存储系统的管理员维护。开发人员要获得上面的信息,要么询问管理员,要么自己就是管理员。这样就带来一个管理上的问题:应用开发人员和系统管理员的职责耦合在一起了。
Kubernetes 给出的解决方案是 Persistent Volume 和 Persistent Volume Claim。
- PersistentVolume(PV)是外部存储系统中的一块存储空间,由管理员创建和维护,将应用需要持久化的数据保存到指定位置。PV 具有持久性,生命周期独立于 Pod。
- Persistent Volume Claim (PVC)是对 PV 的申请 (Claim),申明需要使用的持久卷规格。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个PVC,指明存储资源的容量大小和访问模式 (比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
有了PersistentVolumeClaim,用户只需要告诉 Kubernetes 需要什么样的存储资源,而不必关心真正的空间从哪里分配、如何访问等底层细节信息。这些 Storage Provider 的底层信息交给管理员来处理。

K8S工作流程
以k8s部署nginx为例,在master节点执行一条命令要master部署一个nginx应用
(kubectl create deployment nginx --image=nginx)
Master Node动作:
- 这条命令首先发到master节点的网关api server,这是matser的唯一入口
- api server将命令请求交给controller mannager进行控制(请求转交:api server -> controller)
- controller mannager 进行应用部署解析,生成一次部署信息,并通过api server将信息存入etcd存储(存储要部署的应用: controller->etcd)
- scheduler调度器通过api server从etcd存储中,拿到要部署的应用,开始调度看哪个节点有资源适合部署(读取要部署的应用:etcd ->scheduler )
- scheduler把计算出来的调度信息通过api server再放到etcd中(保存调度信息:scheduler->etcd)
Worker Node动作:
- 每一个node节点的监控组件kubelet,随时和master保持联系(给api-server发送请求不断获取最新数据),拿到master节点存储在etcd中的部署信息(node获取Master信息)
- 假设node2的kubelet拿到部署信息,显示他自己节点要部署某某应用,kubelet就自己run一个应用在当前机器上,并随时给master汇报当前应用的状态信息(node执行相应动作)
- node和master也是通过master的api-server组件联系的
- 每一个Node机器上的kube-proxy能知道集群的所有网络,只要node访问别人或者别人访问node,node上的kube-proxy网络代理自动计算进行流量转发(流量转发)

)
)
)















