目录
一 为什么要有主从 Redis
二 主从模式
1. 什么是主从模式?
2. 相关操作
3. 查看主从信息:
4. 断开与主节点的关系:
5. 主从结构:
6. 建立主从结构流程:
7. 全量/增量复制流程:
1. 全量复制
2. 增量复制
3. 实时复制
一 为什么要有主从 Redis
如果采用单机部署 Redis 服务,必然面临以下几种情况:
1. 单机可用的硬件资源有限。
2. 单机程序奔溃,无其他服务器代替,也就是可用性低。
所以引入了多台主机来部署 Redis 服务,比如一个主 Redis ,多个从 Redis 服务,从 Redis 只读,主 Redis 可读可写。引入更多的硬件资源,可用性也更高。
二 主从模式
1. 什么是主从模式?
顾名思义:部署多台 Redis 服务器,并选择一个为主 Redis 服务器,其他为从 Redis 服务器。
特点:
- 从节点的数据必须从主节点同步过来
- 从节点只能读,主节点可读可写
- 某个从节点挂了,不影响从其他节点读取数据和写数据
- 主节点挂了,不能写数据,从节点读的数据可能是旧的
引入主从模式在读的场景下能提高硬件资源数量和可用性,比如某个服务挂了,依旧能从其他节点读数据,但主节点挂了就不会更新新的数据了。
在写的情况下,虽然引入的多台主机,但写只在一个主服务器操作,压力并没有分摊,所以写的情况没有提高,但在常见的场景中,读的频率往往比写的频率更高。
2. 相关操作
这里在单台主机模拟多个 redis 服务。
首先让 redis 启动不同的服务:把 redis.conf 配置文件拷贝一份(/etc/redis/redis.conf),在把里面的端口号换一下,然后在底部额外添加 slaveof 主IP地址 端口号。从 Redis 节点前置工作就完成了。
下一步: Redis-server (拷贝后的配置文件) 启动从 Redis 服务。
下面来看看效果:
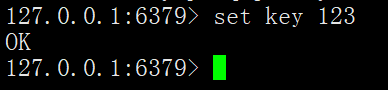


很显然主 Redis 节点写入数据立马就会同步给从 Redis 节点,但从 Redis 节点写入数据是不允许的。
3. 查看主从信息:
// 客户端执行
info replication主节点:
# Replication
// 主节点
role:master
// 挂着 2 个从节点
connected_slaves:2// 从节点 1 端口号 状态 同步数据的进度 延时
slave0:ip=127.0.0.1,port=6380,state=online,offset=2436891,lag=0
// 从节点 2
slave1:ip=127.0.0.1,port=6381,state=online,offset=2436891,lag=1// 主节点状态
master_failover_state:no-failover
// 主节点身份标识
master_replid:557ed200b79e6c6ef04630a5665b3d0db36db83c
// 备用主节点身份标识
master_replid2:0000000000000000000000000000000000000000
// 主节点最新数据的进度
master_repl_offset:2436891
// 备用主节点最新数据的进度
second_repl_offset:-1// 部分同步信息
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1369481
repl_backlog_histlen:1067411
从节点:
# Replication// 从节点
role:slave// 主节点 IP
master_host:127.0.0.1
// 主节点端口号
master_port:6379// 主节点状态
master_link_status:up
// 上一次和主节点通信的间隔 (秒)
master_last_io_seconds_ago:6
// 是否在同步数据
master_sync_in_progress:0// 读取主节点的数据但还没处理的数据
slave_read_repl_offset:1097259
// 同步主节点的实际数据
slave_repl_offset:1097259
// 优先级
slave_priority:100
// 只读
slave_read_only:1
// 节点信息是否暴露给客户端
replica_announced:1
// 从节点挂着几个从节点
connected_slaves:0// 以下和主节点一样
master_failover_state:no-failover
master_replid:557ed200b79e6c6ef04630a5665b3d0db36db83c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1097259
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:40895
repl_backlog_histlen:1056365
4. 断开与主节点的关系:
// 客户端执行
slaveof no one该方法是临时的,重启 Redis 服务还是会读取原来的配置文件相关的信息,所以可用修改配置文件重启 Redis 来持久的断开与主节点的关系。
5. 主从结构:
之前说了如果写情况比较多,主节点压力就会大,这时候可用关闭 AOF 持久化到磁盘的操作,让从节点开启,当主节点挂了则让主节点读取从节点的 AOF 文件保持最新进度的数据。
如果是一主多从,主节点每次修改数据则会同步到多个从节点上,带宽会随着从节点的数量增加,这时候可以让从节点挂着其他的从节点,不必让主节点挂所有的主节点,也就是把带宽分摊到了其他的从节点了,但同步的进度会比主节点直接打到所有从节点慢,毕竟同步会经过每个从节点到达最后的叶子从节点中间多套了几个从节点,所以根据不同的场景来决定选择不同的主从结构来适配。
总结:
- 延时小,主节点挂着所有的从节点
- 带宽少,主节点挂部分从节点,从节点挂剩下的从节点。
6. 建立主从结构流程:
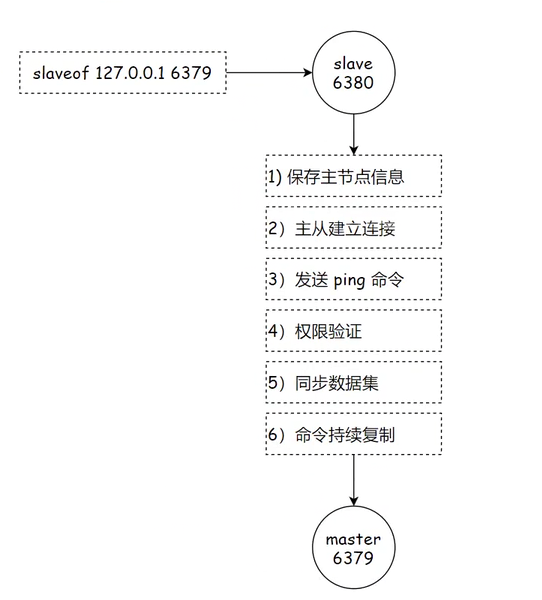
1. 首先从节点保存主节点相关的信息(IP地址,端口号)。
2. 随后发起 TCP 三次握手(验证内核发从/接收的能力)。
3. 然后检测主节点是否能正常工作(验证主节点应用层是否正确提供服务)。
4. 输入主节点的密码。
5. 以上是前置工作,完成之后就会把主节点的所有数据全量同步到从节点。
6. 后续主节点数据的变化会增量同步给从节点。
7. 全量/增量复制流程:
前置:从节点会定期自动向主节点发送 psync 命令同步最新的数据。
1. 全量复制
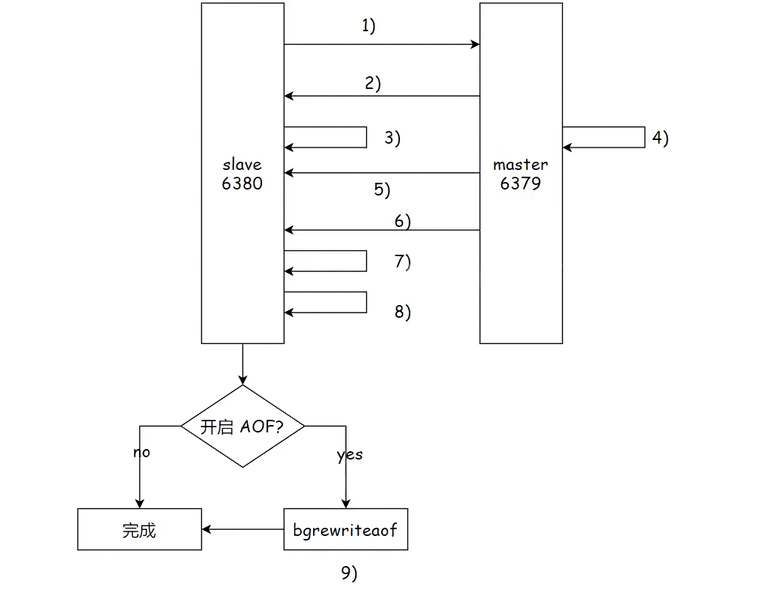
1. 第一步先向主节点发送 psync 命令,必须携带 replicationid(主节点ID) 和 offset(偏移量:数据同步进度),全量复制一般是从节点首次向主节点请求,并不知道主节点的 replicationid,偏移量也不知道,所以先获取主节点相关信息。
2. 主节点返回自己的 replicationid,并携带 全量复制的标识(可能是增量复制)。
3. 获取到主节点信息,并保存在从节点内部。
4. 主节点开始生成 RDB 文件(AOF 也行),并放入缓冲区,之前的 RDB 可能是旧的。
5. 生成后的 RDB 文件发送到从节点。
6. 这里生成和传输的过程可能有新的写数据,这些新的写数据也会同步到缓冲区并发送过去。
7. 从节点接收完成。
8. 从节点把原始数据清空,并导入收到的 RDB 文件和后续的数据。
9. 如果开启 AOF ,则更新 AOF 文件。
上述主节点会生成 RDB 文件发送给从节点,能不能不生成 RDB 文件直接把数据发送过去?
传统的 RDB 会把数据刷到磁盘,Redis 提供了一种无硬盘模式,内存中生成的 RDB 文件不刷回磁盘直接发送到从节点,少了刷盘的次数,也提高了效率。
同理从节点收到 RDB 文件也不需要刷屏,直接写入即可。
2. 增量复制
上述提到的全量复制是发生在最开始建立主从关系的时候发生全量复制的场景,如果由于网络波动,从节点向主节点获取数据,主节点无响应,从节点认为主节点挂了,可能自己提升成主节点,待后续真正的主节点恢复过来,提升后的主节点会变回原来的从节点并向主节点拉取增量数据。
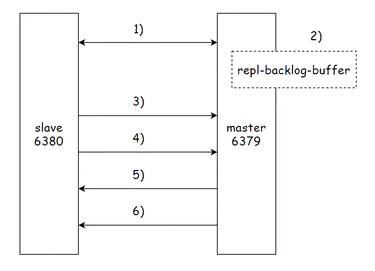
1. 当从节点发现主节点不能反馈自己,比如网络抖动等原因。
2. 主节点在断开的期间不能把数据同步给从节点,这期间可能会收到不同的读情况,主节点就会把新的数据放到积压缓冲区,也就是上面提到的 info repliaction 列出的选项。
3. 当主节点恢复过来,从节点重新和主节点建立联系.
4. 从节点这时可以向主节点 psync 进行拉取数据,首先比对 replicationid 是不是和主节点一致,不一致则全量复制,否则查看 offset 是否只缺少主节点挤压缓冲区的数据,是就增量同步,否则全量同步。
5. 主节点返回 psync 的标识(增量复制:Continue)。
6. 主节点返回挤压缓冲区内的数据个从节点,从节点并缓存,此时双方数据同步进度达到一致性。
3. 实时复制
除上述全量/增量复制会发生在刚构建主从关系和与主节点断开会发生从节点向主节点发送 psync 命令来拉取数据。
正常情况下主从已经联通了后续,主节点收到数据就会发送到从节点进行同步。
如何检测主从是否一直处于联通状态?
心跳包机制:
主节点会定期向从节点发送 ping ,从节点也会向主节点发送 ping,来标识连通性,如果超过超时的阈值则会断开。

 和 reactive() 的区别)


与固定电缆)

 详解:动态内容与 SEO 的完美结合)


算法)









![[特殊字符] GitHub 热门开源项目速览(2025/09/09)](http://pic.xiahunao.cn/[特殊字符] GitHub 热门开源项目速览(2025/09/09))