前言:
上文我们讲到了进程间信号的话题【Linux系统】万字解析,进程间的信号-CSDN博客
本文我们再来认识一下:线程!
Linux线程概念
什么是线程
概念定义:
进程=内核数据结构+代码和数据(执行流)
线程=是进程内部的一个执行分支(执行流)
内核与资源角度:
进程=分配系统资源的基本实体。
线程=CUP调度的基本单位。
初步理解线程:
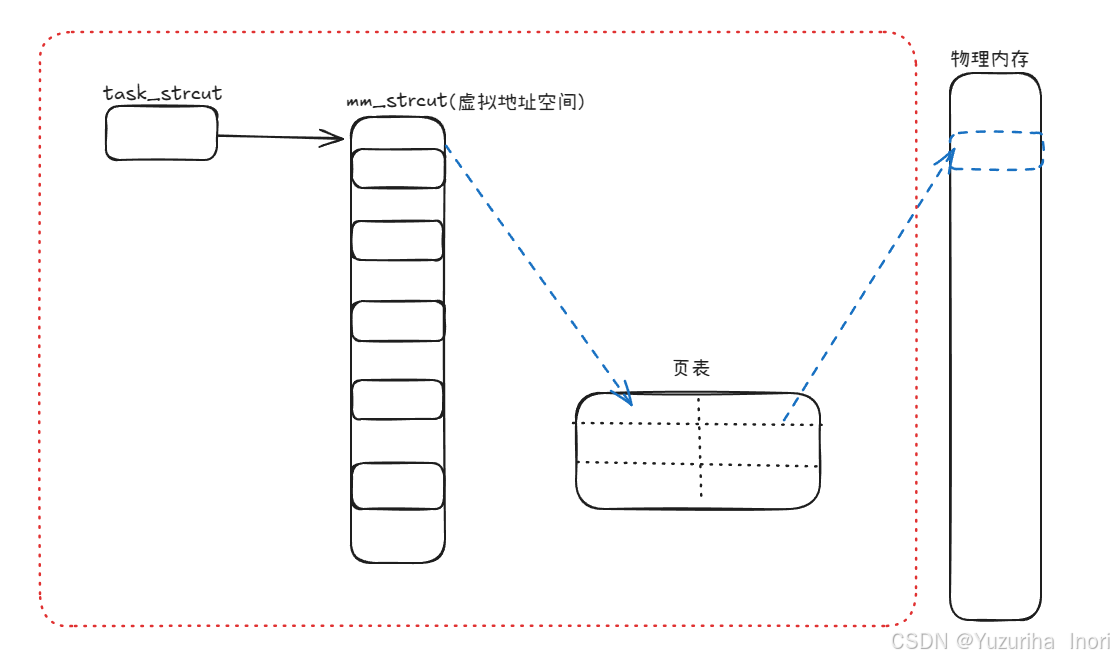
在之前我们讲过,进程=PCB(task_struct)+代码和数据,如上图所示。
而线程是什么呢?
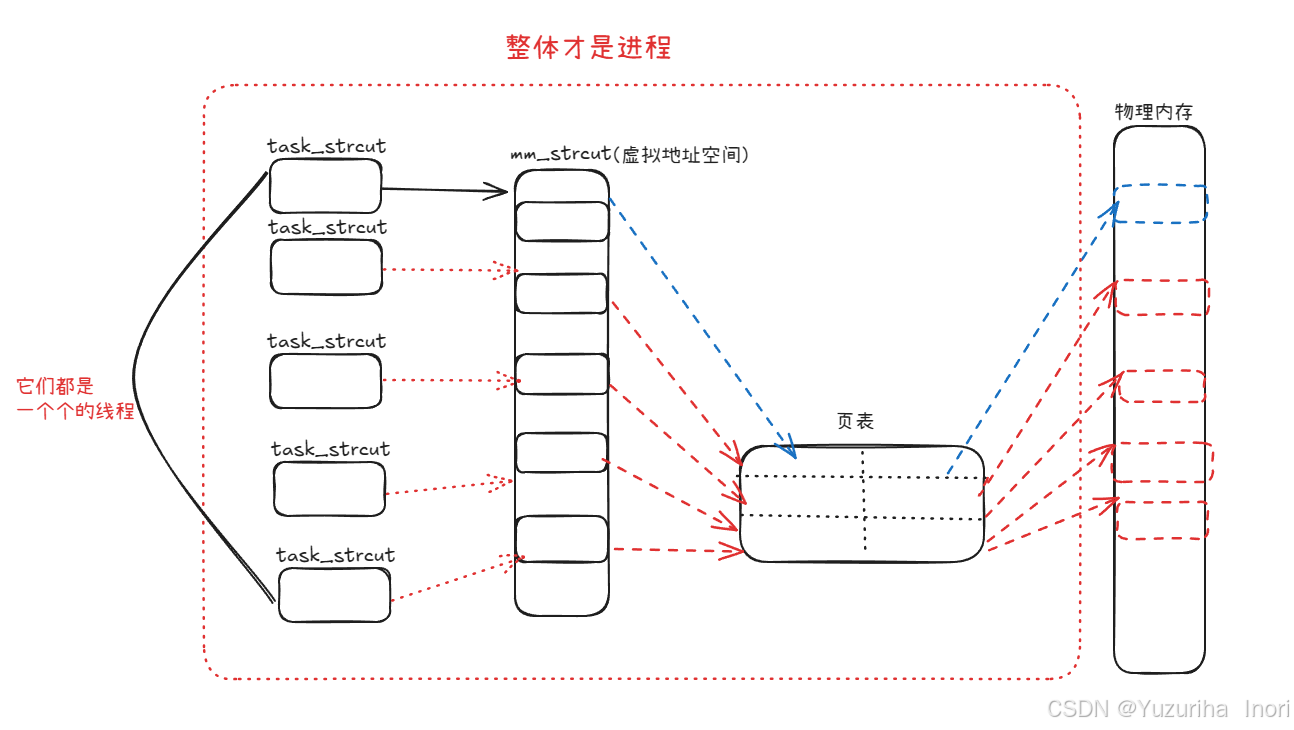
线程是进程的一个个分支!一个线程 = 一个PCB+一份自己需要执行的代码和数据!不同的线程执行进程中不同的代码,各司其职。
一个线程执行一部分代码,多个线程同时执行,让进程整体效率提升!
而我们之前所讲的进程其实是:内部只有一个线程的进程!(单线程)
结论:
1.线程也采用PCB结构体来描述的
2.对资源的划分,本质是对虚拟地址的划分。也就是说,虚拟地址就是资源的代表。
3线程对进程代码的“划分”,不需要我们人为的去“划分”!因为进程所要执行的代码,其本质都是由一个个函数组成的!这本就是天然的“划分”好了的状态,所以线程对函数“划分”即可(获得函数的入口地址即可)!
4.线程其实不会对资源进行划分,进程内的大部分资源都是共享的,不存在说这个资源是线程a的谁都不可以访问!对代码的“划分”也不是真正的划分,仅仅是表示对任务的分配。一个线程负责执行一部分代码,让进程的代码同时被多个线程推进!
5.Linux的线程就是轻量级的进程(单线程进程)!
6.进程强调独占,部分共享(如进程间的通信)
线程强调共享,部分独占
补充:
windows下的线程设计,与Linux的并不相同!Linux的线程都是使用PCB结构体描述的,但是windows下的线程是采用新设计的结构体:TCB来描述的。
越复杂的代码可维护性、健壮性越不好,所以Linux在这一方面采用复用的方式,设计的更好!
分页式存储管理
进一步理解线程:内核资源的划分
物理内存管理
物理内存最小管理与分配单位:页框/页帧,大小为4KB。当然虚拟内存是与物理内存一一对应的,虚拟内存也是以4KB为基本单位进行分配(是分配噢,不是读写)。
之前我们在文件系统中也讲过:磁盘数据的分配读写(磁盘是例外),是以4KB为单位进行的。【Linux系统】详解Ext2,文件系统-CSDN博客
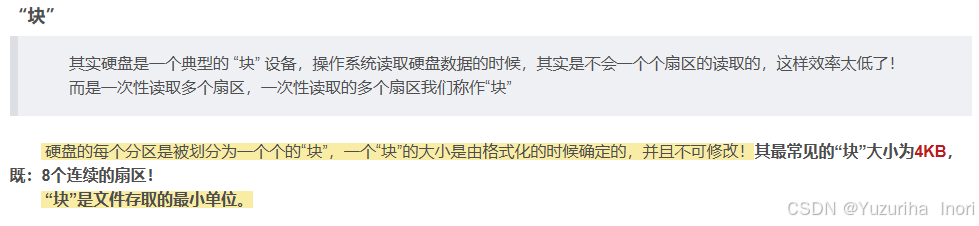
虚拟页面(4KB) ↔ 物理页框(4KB) ↔ 磁盘块(4KB)
当然不是真的划分为一个个4KB的空间,实际上是一个整体,只是OS在逻辑上进行了划分。
OS采用结构体:page,进行描述!
page描述了页框的各种信号,其中包含了页框的状态:是否被使用,是否被锁定等等。
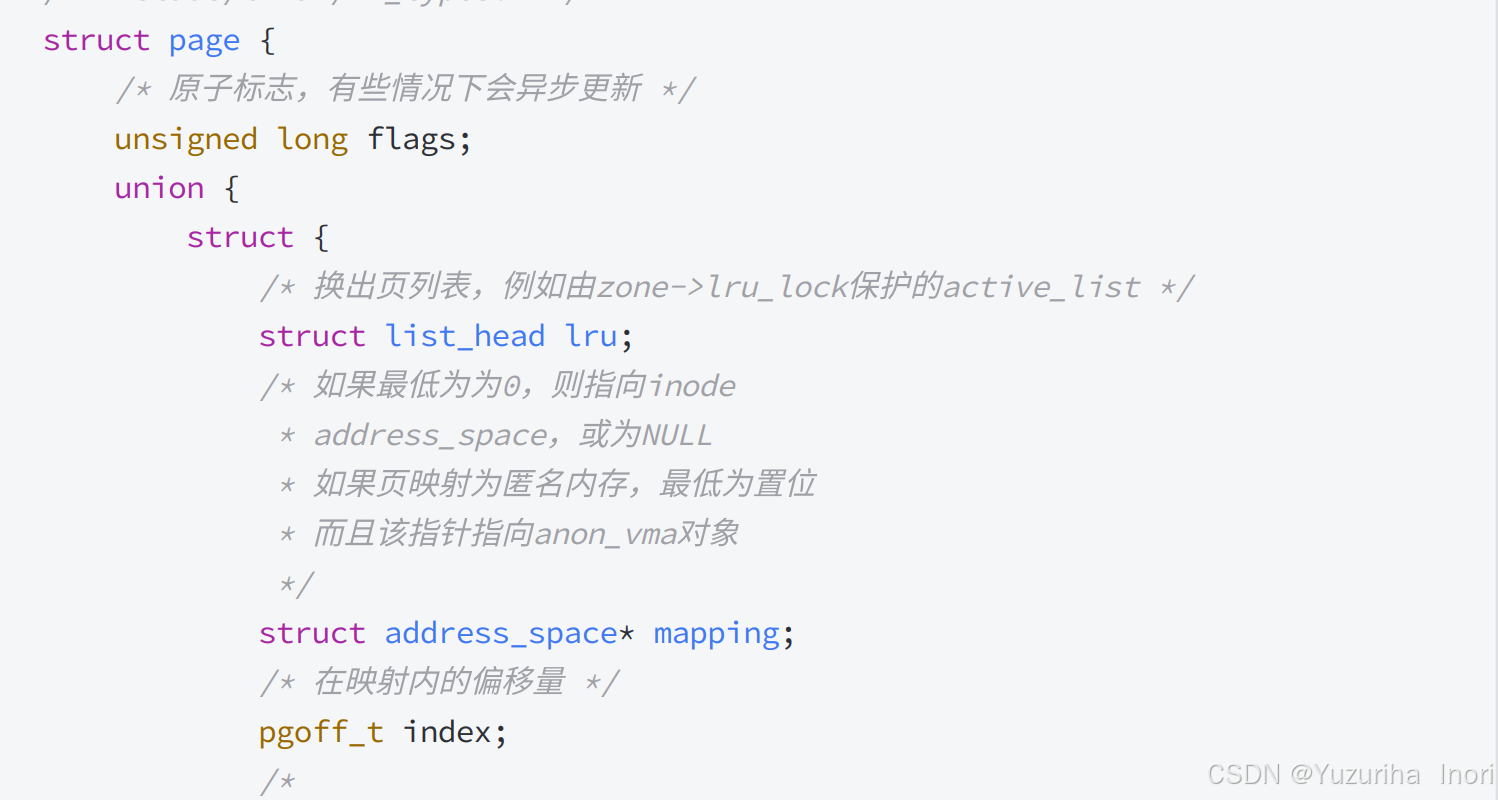
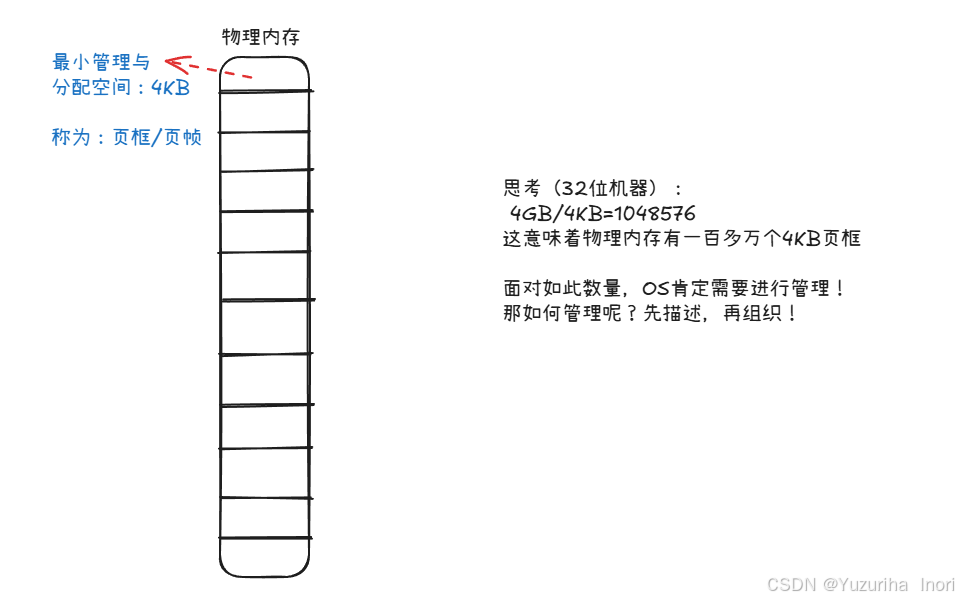
并采用数组:struct page mem[1048576],进行组织!
所以每一个page都会对应一个数组下标!而我们让数组下标 * 4KB就可以得到page的起始首物理地址了!
起始首地址+页框中的偏移量=真实的物理地址。
有了以上的梳理,我可以知道,当线程或进程申请物理内存时:
1.查数组,修改page 2.建立page与内核数据结构的映射关系
页表
重新认识页表
在此之前,我们认识页表就如图所示:一张表保存虚拟地址与物理地址映射关系。
思考一个问题:
如果一张页表将虚拟地址与物理地址的映射关系全部保存,(以32位机器为例)一个地址是4字节,那么页表中一排就要保存8字节数据。那么一共有多少地址需要我们保存呢?4GB!这也就意味着页表的大小将会来到:8字节 * 4GB = 32GB!这是不现实的!所以页表是绝不可能仅用一张表来保存映射关系的。
页表真正的保存方式:
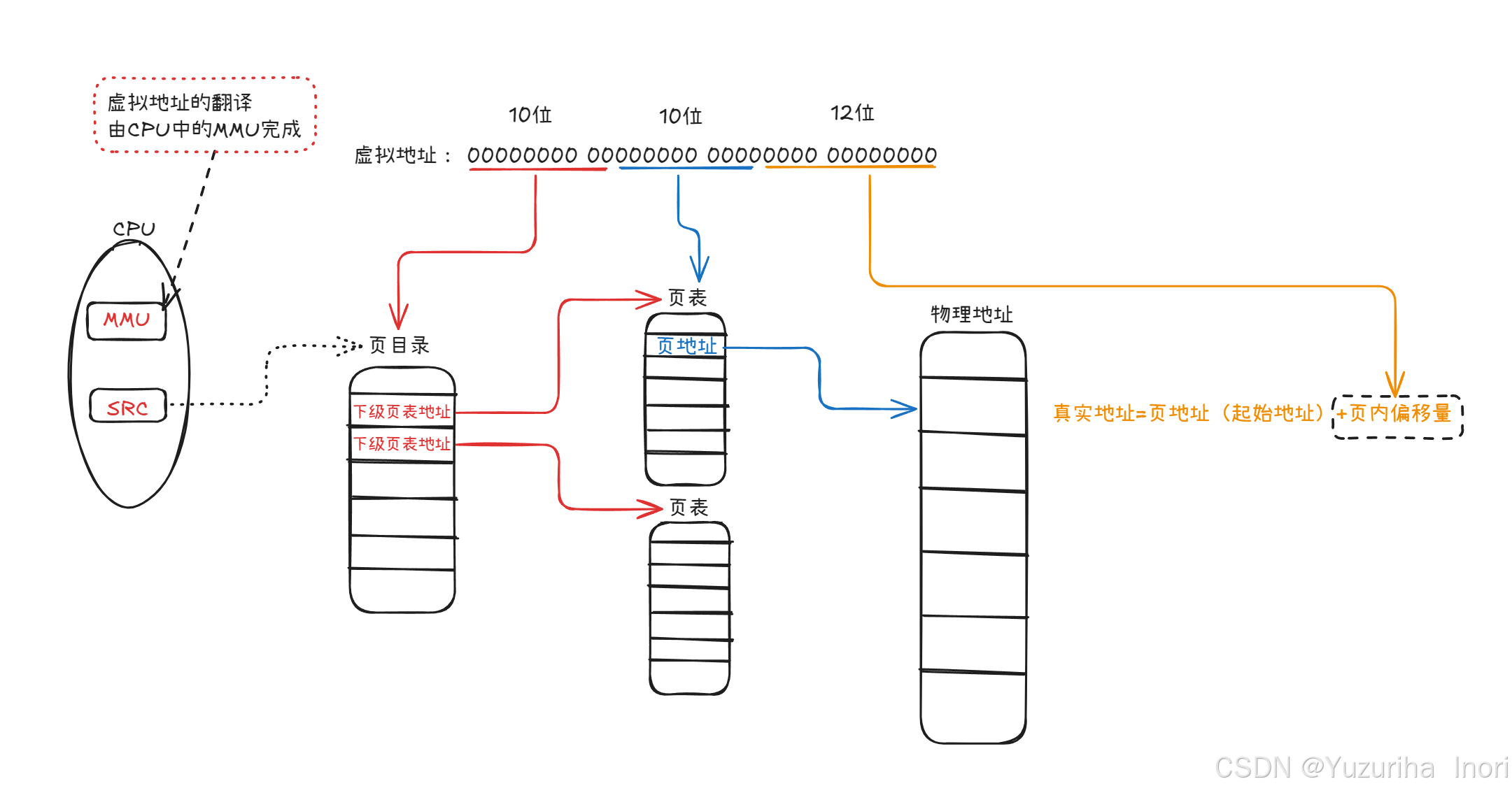
真正的页表由两部分组成:页目录、页表。
虚拟地址的转化:
首先将一个虚拟地址划分位3部分:以10位、10位、12位为3组(32位下)
前10位:表示指向页目录的地址,其中页目录中保存的是页表的地址。
中间10位:表示指向页表的地址,其中页表中保存的是页地址(起始地址)。
最后12位:表示页中的偏移量,前面的地址找到了具体的页框,最后加上偏移量,就得到了真正的物理地址了!
细节:
1.一张页目录+n张页表构成了映射体系,物理页框是映射目标。最后12位地址+页框地址=真实的物理地址。
2.虚拟地址的转化其实是有CPU中的硬件:MMU自动完成的
3.申请物理内存:查找数组,找到没有使用的page,修改page,通过page下标得到物理地址,以页框位最小单位获得到申请的内存。
4.写时拷贝,缺页中断,内存申请等等,背后都可能要重新建立新的页表与新的映射关系。
5.为什么要用最后12位,最为页内偏移量?
12位:2^12,且一个地址的存储空间为1字节,刚好为4KB(与页框大小一致,可以覆盖整个页框的偏移)
最后12位:前20位的数据是一致的,这可以保证查找到数据属于同一个4KB的页框。
深刻理解线程
1.线程进行资源的划分:本质是划分地址空间,得到一定合法范围的虚拟地址空间,本质就是,对页表的划分!
2. 线程对资源的共享:本质就是地址空间的共享,本质就是对页表条目的共享!
3.线程是轻量化进程,顾名思义:线程的开销比进程更低,尤其在线程的切换方面!
切换方面解释:
为了提高转化地址的效率,MMU引入了TLB(Translation Lookaside Buffer,缓存),其中存储最近频繁使用的映射关系!MMU做虚拟地址与物理地址的转化时,先去TLB中查询,若没有,则再去页表中查询!
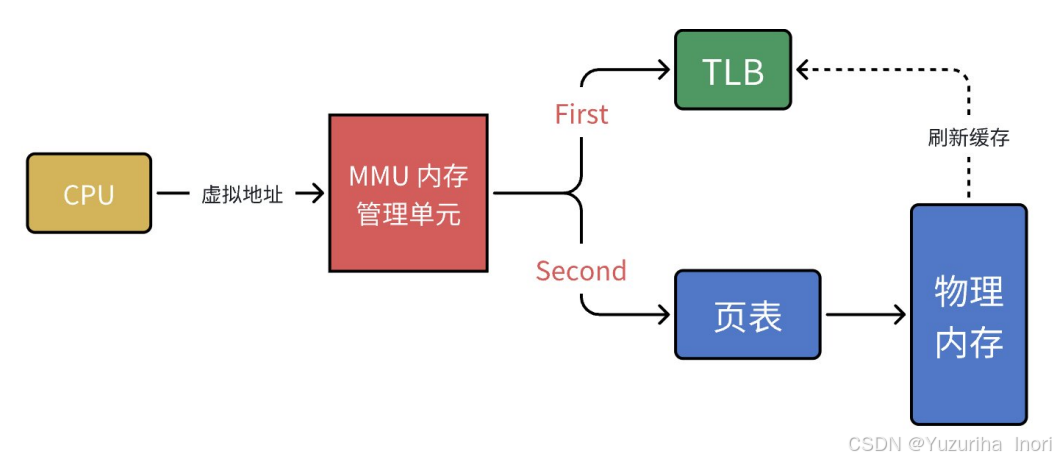
对于线程:线程不论如何切换,都是在同一个进程中的!在同一个虚拟地址空间中!
对于进程:进程一旦切换,新的进程是对应新的虚拟地址空间的!
也就是说,线程切换,虚拟地址空间不会切换,TLB正常使用!但进程切换,虚拟地址空间也切换,TLB中保存的映射关系全部报废!需要全部将其刷新!
所以这也就是为什么线程的切换开销更小!
Linux线程控制
引入pthread库
这个一个关于线程的库
首先,prhread库是Linux系统下C/C++实现的线程库!
其次,Linux系统中其实并没有真正的线程!都是轻量级进程!Linux 内核中没有独立的 “线程” 数据结构,而是通过 “轻量级进程(Lightweight Process, LWP)” 来实现线程功能!
但对于用户来说,用户需要使用线程的概念以及方法!所以为什么保证用户的正常使用,C/C++实现了pthread库,封装了LWP,来实现“线程”的概念以及方法!
所以Linux线程的实现是在用户层的,我们也将其称为:用户级线程。
注:使用pthread库,在编译器时需要加上 -l pthread选项(因为pthread库不是被默认链接的)
pthread库接口
1.线程创建
pthread_create
功能:创建线程
#include <pthread.h>int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine)(void *), void *arg);thread:输出参数,用于存储新线程的 ID(pthread_t 类型)
attr:线程属性(如栈大小、分离状态等),NULL 表示使用默认属性
start_routine:线程入口函数(函数指针),格式为 void* (*)(void*),线程启动后会执行该函数
arg:传递给 start_routine 的参数(无参数时传 NULL)返回值:0:成功;非 0:错误码演示:
#include <pthread.h> //线程库
#include <iostream>
using namespace std;void *routine(void *args)
{string name = static_cast<char *>(args);cout << "新线程:" << name << endl;while (true){}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread -1");cout << "主线程" << endl;while (true){}
}hyc@hyc-alicloud:~/linux/线程dome$ ./test
主线程
新线程:thread -1
可以看到,其实创建了线程!我们也可以通过指令:ps -aL来查看:
hyc@hyc-alicloud:~/linux/线程dome$ ps -aLPID LWP TTY TIME CMD94651 94651 pts/0 00:00:21 test94651 94652 pts/0 00:00:21 test
PID:我们可以看到PID都是一样的!这说明都属于同一个进程!
LWP:LWP不一样,这正好说明了创建了新的线程!
补充:
函数:pthread_create(创建线程),其底层其实封装了系统调用:clone(创建轻量级进程)#include <sched.h>int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...,* pid_t *parent_tid,void *tls, pid_t *child_tid */ );线程运行问题
| 创建新线程后,是先执行主线程还是先执行新线程的代码?这个是不确定的,取决于OS的调用机制! |
| CPU在调度的时候,是调度进程还是线程?线程!线程是CPU调度的基本单位! |
| 一个进程有多个线程,那么时间片如何分配?平均分配! |
| 线程运行时如果出现异常,整个进程都会被OS直接终止掉!这也就导致了多线程程序的健壮性低。 |
2.线程终止
pthread_exit
功能:终止线程
#include <pthread.h>void pthread_exit(void *retval);retval:一个 void* 类型的指针,表示线程退出的返回值return也可以终止线程,推荐使用:return
区别:在主线程中使用return,回让整个进程全部退出!但pthread_exit只会退出主线程,其他子线程照常运行注:线程中万不可用exit()退出!因为exit()是进程退出的接口!
pthread_cancel
功能:取消线程
#include <pthread.h>int pthread_cancel(pthread_t thread);线程取消后,退出结果是-1【PTHREAD_CANCELED】thread:目标线程的id(由pthread_create得到)
返回值:成功返回 0;失败返回非 0 的错误码(如 ESRCH 表示目标线程不存在)
注意:该函数只是 “请求” 取消,而非强制终止。目标线程是否以及何时终止,取决于其自身的取消配置演示:
#include <pthread.h> //线程库
#include <iostream>
using namespace std;void *routine(void *args)
{string name = static_cast<char *>(args);cout << "新线程:" << name << endl;while (true){}// 不应该看见cout << "线程取消失败!" << endl;return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread -1");// 取消线程pthread_cancel(tid);cout << "主线程" << endl;
}hyc@hyc-alicloud:~/linux/线程dome$ ./test
主线程
hyc@hyc-alicloud:~/linux/线程dome$按道理来讲,主线程也可以被取消,但并不建议这么做!
3.线程等待
pthread_join
功能:等待线程
其目的与进程的等待一致,都是为了获得线程的返回值,并回收资源!若不回收将回出现:内存泄漏!
#include <pthread.h>int pthread_join(pthread_t thread, void **retval);thread:需要等待的目标线程的 ID(由 pthread_create 函数返回)
retval:二级指针(void**),用于接收目标线程的退出状态(即线程通过 pthread_exit(retval) 或 return retval 返回的值)
若不需要获取退出状态,可传入 NULL
若需要获取,则需提前定义一个 void* 指针,再将其地址传给 retval返回值:0表示等待成功,非0表示不成功!值得一提的是,此接口的等待方式的阻塞等待!
演示:
#include <pthread.h> //线程库
#include <iostream>
#include <unistd.h>
using namespace std;// 线程等待void *routine(void *agrs)
{string name = static_cast<char *>(agrs);cout << "新线程执行完方法,返回" << endl;return (void *)1;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread");// 阻塞等待void *ret;pthread_join(tid, &ret);cout << "等待成功:" << (long long)ret << endl; // long long防止在64位下进度丢失int cnt = 5;while (cnt--){cout << "主线程运行中" << endl;sleep(1);}
}hyc@hyc-alicloud:~/linux/线程dome$ ./test
新线程执行完方法,返回
等待成功:1
主线程运行中
主线程运行中
主线程运行中
主线程运行中
主线程运行中
hyc@hyc-alicloud:~/linux/线程dome$4.线程分离
pthread_detach
功能:让新线程与主线程分离,分离主线程不再阻塞等待新线程了,新线程执行完毕后会自动的回收空间
当我们不关心新线程的返回值时,可以让线程分离,这样的好处是主线程不用阻塞的等待新线程,可以执行自己的代码。
#include <pthread.h>int pthread_detach(pthread_t thread);thread 是需要分离的线程 ID(由 pthread_create 创建线程时返回)
成功返回 0;失败返回非零错误码注:即使线程分离了,分离的线程仍然都在同一个进程的地址空间中,所有的资源依旧可以访问!分离的线程,不用被主线程join,也不能被主线程join(会失败)!演示:
#include <pthread.h> //线程库
#include <iostream>
#include <unistd.h>
using namespace std;// 线程分离void *routine(void *agrs)
{int cnt = 5;while (cnt--){cout << "新线程运行" << endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread");cout << "运行主线程" << endl;// 分离pthread_detach(tid);// 等待失败!!!int ret = pthread_join(tid, nullptr);if (ret != 0)cout << "等待失败!" << endl;
}hyc@hyc-alicloud:~/linux/线程dome$ make
g++ -o test test.cc -l pthread
hyc@hyc-alicloud:~/linux/线程dome$ ./test
运行主线程
等待失败!
hyc@hyc-alicloud:~/linux/线程dome$创建多线程演示
#include <iostream>
#include <string>
#include <pthread.h>
using namespace std;// 创建多线程void *routine(void *agrs)
{string name = static_cast<char *>(agrs);cout << "创建线程:" << name << endl;return nullptr;
}int main()
{for (int i = 0; i < 5; i++){pthread_t tid;char str[10];snprintf(str, sizeof(str), "%s%d", "thread-", i);pthread_create(&tid, nullptr, routine, (void *)str);}while (true){}
}hyc@hyc-alicloud:~/linux/多线程dome$ make
g++ -o test test.cc -l pthread
hyc@hyc-alicloud:~/linux/多线程dome$ ./test
创建线程:thread-1
创建线程:thread-4
创建线程:thread-4
创建线程:thread-4
创建线程:thread-4此时,我们可以看见结果不太对,这是因为for循环的速度与新键线程的速度并不一致,导致开没有开始创建对应的线程时,str里面的内容又被刷新了!
处理办法:开辟独立的空间,避免被覆盖!
#include <iostream>
#include <string>
#include <vector>
#include <pthread.h>
using namespace std;// 创建多线程void *routine(void *agrs)
{string *name = static_cast<string *>(agrs);cout << "创建线程:" << *name << endl;return nullptr;
}int main()
{vector<pthread_t> arr;for (int i = 0; i < 5; i++){pthread_t tid;string *name = new string("thread-" + to_string(i));pthread_create(&tid, nullptr, routine, name);arr.push_back(tid);}for (int i = 0; i < 5; i++){int ret = pthread_join(arr[i], nullptr);if (ret == 0)cout << "等待成功" << endl;}
}hyc@hyc-alicloud:~/linux/多线程dome$ ./test
创建线程:thread-0
创建线程:thread-1
创建线程:thread-3
创建线程:thread-2
创建线程:thread-4
等待成功
等待成功
等待成功
等待成功
等待成功
hyc@hyc-alicloud:~/linux/多线程dome$ 线程ID与进程地址空间布局
线程ID
hyc@hyc-alicloud:~$ ps -aLPID LWP TTY TIME CMD103519 103519 pts/3 00:00:00 test103519 103520 pts/3 00:00:04 test103519 103521 pts/3 00:00:05 test103519 103522 pts/3 00:00:04 test103519 103523 pts/3 00:00:04 test103519 103524 pts/3 00:00:04 test首先,我们要区分LWP号与线程ID的区别。
LWP号是轻量级线程(LWP)的编号,但为了给用户提供线程的概念,LWP号肯定不能提供给用户,于是线程库提供了标识号:线程ID!
那这个线程ID本质是什么东西呢?接着往下看!
进程地址空间分布
Linux下的线程是由线程库提供的,而库是满足EIF文件格式,动态库会加载到物理内存空间中,然后再映射到需要的虚拟地址空间中共享区!
最后通过起始地址+偏移量的方式,就可以访问到线程库中的方法与数据了!
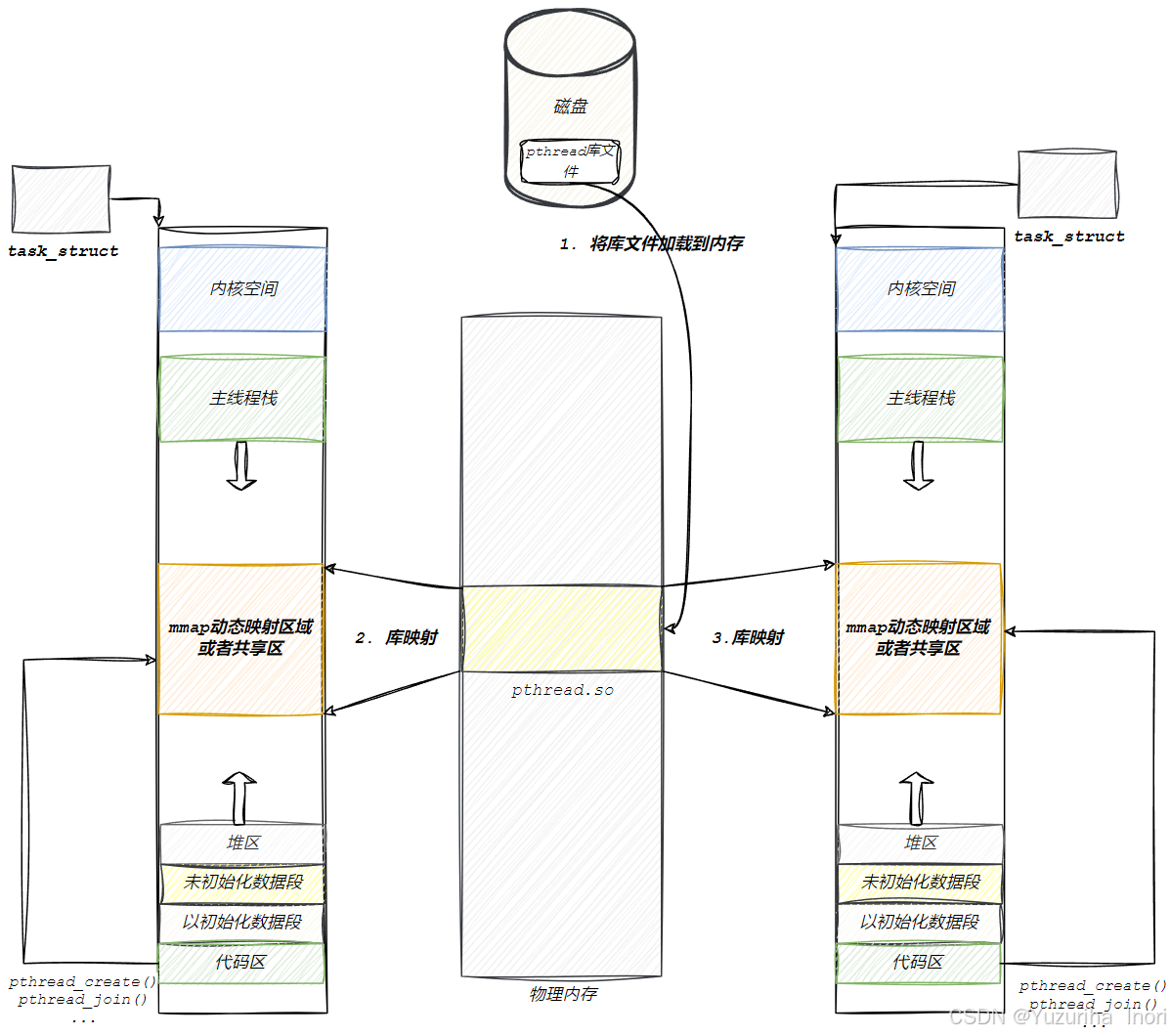
线程的概念是在pthread库中被维护的!那这也意味着库中一定有大量的被创建的线程!
库一定会管理这些线程,如何管理?先描述,再组织!
描述:
库中存在结构体,TCB用于描述线程对应属性!
strcut TCB
{线程状态线程ID线程独立的栈结构线程栈的大小.....
}注:TCB中并没有关于线程运行的属性,如:优先级、时间片、上下文等等组织:
通过数组进行组织!
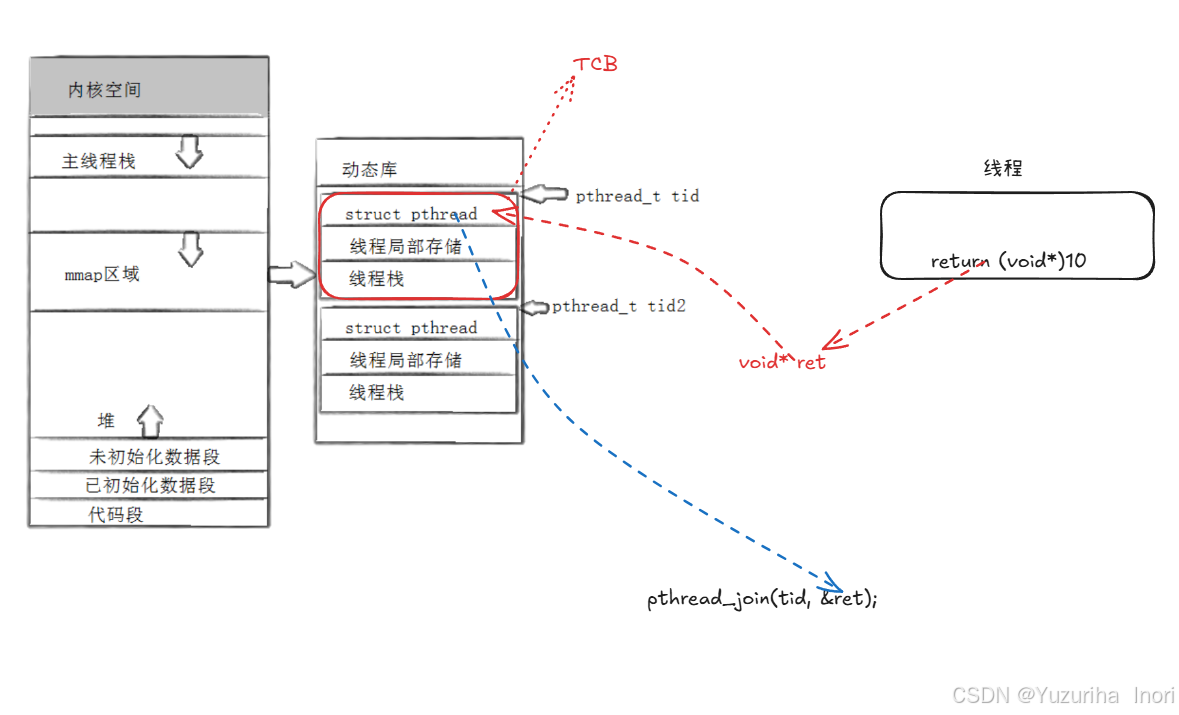
TCB分为3大部分:struct pthread、线程局部存储、线程栈。其中每一个线程都必须有对应的线程栈!因为线程栈主要用于存储代码的临时数据。注:主线程的栈空间并不在线程库中!
线程ID:线程ID其实就是对应的TCB地址!
返回值:线程返回值,其实是写入了struct pthread中的void* ret中,线程等待接口参数的变量之所以是void **,是为了拿到void *ret的数据!
线程等待:等待释放资源,就是为了释放TCB这个资源!
见一见线程ID:创建线程:thread-0
线程ID:140610093467200
线程ID:140610085074496
线程ID:140610076681792
线程ID:140610068289088
线程ID:140610059896384而strcut pthread中之所有没有关于线程执行的属性,如:时间片、优先级。是因为线程的执行工作是交给了底层的系统调用clone!由clone去执行并返回结果!
函数:pthread_create(创建线程),其底层其实封装了系统调用:clone(创建轻量级进程)#include <sched.h>int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...,* pid_t *parent_tid,void *tls, pid_t *child_tid */ );int clone(int (*fn)(void *), // 1. 子进程执行的函数void *stack, // 2. 子进程的栈指针int flags, // 3. 核心控制标志(位掩码)void *arg, // 4. 传递给fn的参数... /* 可选参数,顺序固定 */pid_t *parent_tid, // 5. 父进程中存储子进程TID的地址void *tls, // 6. 线程本地存储(TLS)结构地址pid_t *child_tid); // 7. 子进程中存储自身TID的地址
所以,调用pthread_create方法会执行两大步:
1.在库中创建线程的控制管理块,TCB
2.调用系统调用clone,在内核中创建轻量级进程,并传入执行方法,让其执行!
总结来说,用户态管理线程的逻辑信息,内核态负责实际的调度执行,两者通过系统调用协作,实现线程的创建与运行。
值得一提:Linux中线程(用户级)与内核LWP是一对一的关系!
线程栈
首先,主线程的栈与子线程的栈是不一样的!
主线程的栈大小不固定,可以向下增长!但子线程的栈是固定的,用完就完了,不会增长!
对于子线程的栈空间,原则上是线程私有的!但是其他线程想要访问还是可以访问的,没有特殊的限制。
线程局部存储
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;int num = 0;void *run1(void *args)
{while (1){cout << "修改num:" << num++ << endl;sleep(1);}
}void *run2(void *args)
{while (1){cout << "num:" << num << endl;sleep(1);}
}int main()
{pthread_t tid1, tid2;pthread_create(&tid1, nullptr, run1, nullptr);pthread_create(&tid2, nullptr, run2, nullptr);while (1){}
}hyc@hyc-alicloud:~/linux/线程局部存储$ ./test
修改num:0
num:1
修改num:1
num:2
修改num:2
num:3
修改num:3
num:4
修改num:4
num:5
修改num:5
num:6
修改num:6
num:7
修改num:7
num:8
修改num:8我们可以看到,两个线程访问了同一个全局变量,这也符合我们的预期。
下面来看看,线程局部存储的效果。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;// __thread声明线程局部存储变量
__thread int num = 0;void *run1(void *args)
{while (1){cout << "修改num:" << num++ << endl;sleep(1);}
}void *run2(void *args)
{while (1){cout << "num:" << num << endl;sleep(1);}
}int main()
{pthread_t tid1, tid2;pthread_create(&tid1, nullptr, run1, nullptr);pthread_create(&tid2, nullptr, run2, nullptr);while (1){}
}hyc@hyc-alicloud:~/linux/线程局部存储$ ./test
修改num:0
num:0
修改num:1
num:0
修改num:2
num:0
修改num:3
num:0
修改num:4
num:0
修改num:5
num:0
修改num:6
num:0由运行结果我们可以知道,线程局部存储就是为每个线程创建该变量的独立副本,不同线程之间变量互不干扰。只是名字都是一样的(理解为类似写时拷贝的效果)
作用:当我们想要使用全局变量,但又不想被其他线程干扰。这时就可以声明线程局部存储!
限制:线程局部存储只能申明内置类型、部分指针








)






)



