1. 项目背景
开源大模型如LLaMA,Qwen,Baichuan等主要都是使用通用数据进行训练而来,其对于不同下游的使用场景和垂直领域的效果有待进一步提升,衍生出了微调训练相关的需求,包含预训练(pt),指令微调(sft),基于人工反馈的对齐(rlhf)等全链路。但大模型训练对于显存和算力的要求较高,同时也需要下游开发者对大模型本身的技术有一定了解,具有一定的门槛。
LLaMA-Factory项目的目标是整合主流的各种高效训练微调技术,适配市场主流开源模型,形成一个功能丰富,适配性好的训练框架。项目提供了多个高层次抽象的调用接口,包含多阶段训练,推理测试,benchmark评测,API Server等,使开发者开箱即用。同时借鉴 Stable Diffsion WebUI相关,本项目提供了基于gradio的网页版工作台,方便初学者可以迅速上手操作,开发出自己的第一个模型。
2. 本教程目标
以Meta-Llama-3-8B-Instruct 模型 和 Linux + RTX 4090 24GB环境,LoRA+sft训练阶段为例子,帮助开发者迅速浏览和实践本项目会涉及到的常见若干个功能,包括:
-
原始模型直接推理
-
自定义数据集构建
-
基于LoRA的sft指令微调
-
动态合并LoRA的推理
-
批量预测和训练效果评估
-
LoRA模型合并导出
-
一站式webui board的使用
-
API Server的启动与调用
-
大模型主流评测 benchmark
本教程大部分内容都可以通过LLaMA-Factory下的 README.md, data/README.md,examples文件夹下的示例脚本得到,遇到问题请先阅读项目原始相关资料。
关于全参训练,flash-attention加速, deepspeed,rlhf,多模态模型训练等更高阶feature的使用,后续会有额外的教程来介绍。
3. 前置准备
训练顺利运行需要包含4个必备条件:
-
机器本身的硬件和驱动支持(包含显卡驱动,网络环境等)
-
本项目及相关依赖的python库的正确安装(包含CUDA, Pytorch等)
-
目标训练模型文件的正确下载
-
训练数据集的正确构造和配置
3.1 硬件环境校验
显卡驱动和CUDA的安装,网络教程很多,不在本教程范围以内
使用以下命令做最简单的校验
nvidia-smi预期输出如图,显示GPU当前状态和配置信息

那多大的模型用什么训练方式需要多大的GPU呢,可参考 https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#hardware-requirement
新手建议是3090和4090起步,可以比较容易地训练比较主流的入门级别大模型 7B和8B版本。

3.2 CUDA和Pytorch环境校验
请参考项目的readme进行安装
https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#dependence-installation
2024年51期间系统版本有较大升级,2024-05-06 号的安装版本命令如下,请注意conda环境的激活。
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]安装后使用以下命令做简单的正确性校验
校验1
import torch
torch.cuda.current_device()
torch.cuda.get_device_name(0)
torch.__version__预期输出如图
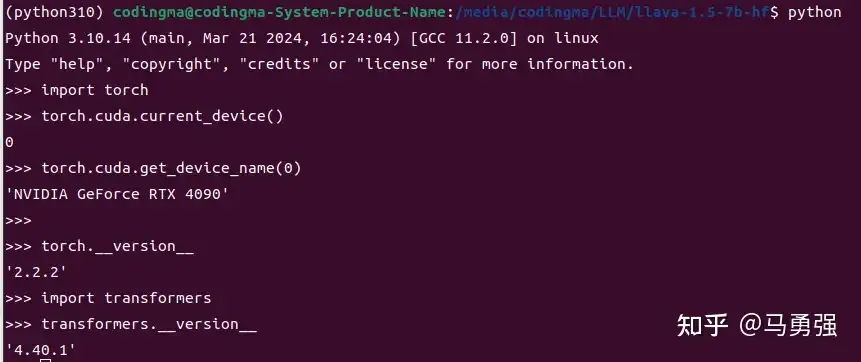
如果识别不到可用的GPU,则说明环境准备还有问题,需要先进行处理,才能往后进行。
校验2
同时对本库的基础安装做一下校验,输入以下命令获取训练相关的参数指导, 否则说明库还没有安装成功
llamafactory-cli train -h3.3 模型下载与可用性校验
项目支持通过模型名称直接从huggingface 和modelscope下载模型,但这样不容易对模型文件进行统一管理,所以这里笔者建议使用手动下载,然后后续使用时使用绝对路径来控制使用哪个模型。
以Meta-Llama-3-8B-Instruct为例,通过huggingface 下载(可能需要先提交申请通过)
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instructmodelscope 下载(适合中国大陆网络环境)
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git或者
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')按网友反馈,由于网络环境等原因,文件下载后往往会存在文件不完整的很多情况,下载后需要先做一下校验,校验分为两部分,第一先检查一下文件大小和文件数量是否正确,和原始的huggingface显示的做一下肉眼对比
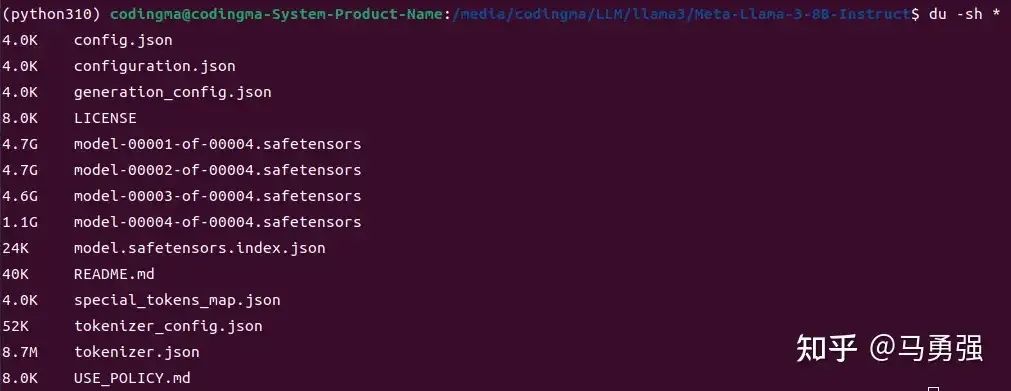
第二步是跑一下官方readme里提供的原始推理demo,验证模型文件的正确性和transformers库等软件的可用
import transformers
import torch # 切换为你下载的模型文件目录, 这里的demo是Llama-3-8B-Instruct
# 如果是其他模型,比如qwen,chatglm,请使用其对应的官方demo
model_id = "/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct" pipeline = transformers.pipeline( "text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto",
) messages = [ {"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"}, {"role": "user", "content": "Who are you?"},
] prompt = pipeline.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True
) terminators = [ pipeline.tokenizer.eos_token_id, pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
] outputs = pipeline( prompt, max_new_tokens=256, eos_token_id=terminators, do_sample=True, temperature=0.6, top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])3.4 数据集部分放到后面一起说明
4. 原始模型直接推理
在进行后续的环节之前,我们先使用推理模式,先验证一下LLaMA-Factory的推理部分是否正常。LLaMA-Factory 带了基于gradio开发的ChatBot推理页面, 帮助做模型效果的人工测试。在LLaMA-Factory 目录下执行以下命令
本脚本参数参考自 LLaMA-Factory/examples/inference/llama3.yaml at main · hiyouga/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --template llama3CUDA_VISIBLE_DEVICES=0 是指定了当前程序使用第0张卡,是指定全局变量的作用, 也可以不使用
llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --template llama3需要注意的是,本次及后续所有的程序的入口都是 llamafactory-cli, 通过不同的参数控制现在是实现什么功能,比如现在是想使用网页版本直接推理,所以第一个参数设置为webchat, 所有的可选项包括
| 动作参数枚举 | 参数说明 |
|---|---|
| version | 显示版本信息 |
| train | 命令行版本训练 |
| chat | 命令行版本推理chat |
| export | 模型合并和导出 |
| api | 启动API server,供接口调用 |
| eval | 使用mmlu等标准数据集做评测 |
| webchat | 前端版本纯推理的chat页面 |
| webui | 启动LlamaBoard前端页面,包含可视化训练,预测,chat,模型合并多个子页面 |
另外两个关键参数解释如下,后续的基本所有环节都会继续使用这两个参数
| 参数名称 | 参数说明 |
|---|---|
| model_name_or_path | 参数的名称(huggingface或者modelscope上的标准定义,如“meta-llama/Meta-Llama-3-8B-Instruct”), 或者是本地下载的绝对路径,如/media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct |
| template | 模型问答时所使用的prompt模板,不同模型不同,请参考https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file#supported-models 获取不同模型的模板定义,否则会回答结果会很奇怪或导致重复生成等现象的出现。chat 版本的模型基本都需要指定,比如Meta-Llama-3-8B-Instruct的template 就是 llama3 |
当然你也可以提前把相关的参数存在yaml文件里,比如LLaMA-Factory/examples/inference/llama3.yaml at main · hiyouga/LLaMA-Factory, 本地位置是 examples/inference/llama3.yaml ,内容如下
model_name_or_path: /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct
template: llama3这样就可以通过如下命令启动,其效果跟上面是一样的,但是更方便管理
llamafactory-cli webchat examples/inference/llama3.yaml效果如图,可通过 http://localhost:7860/ 进行访问
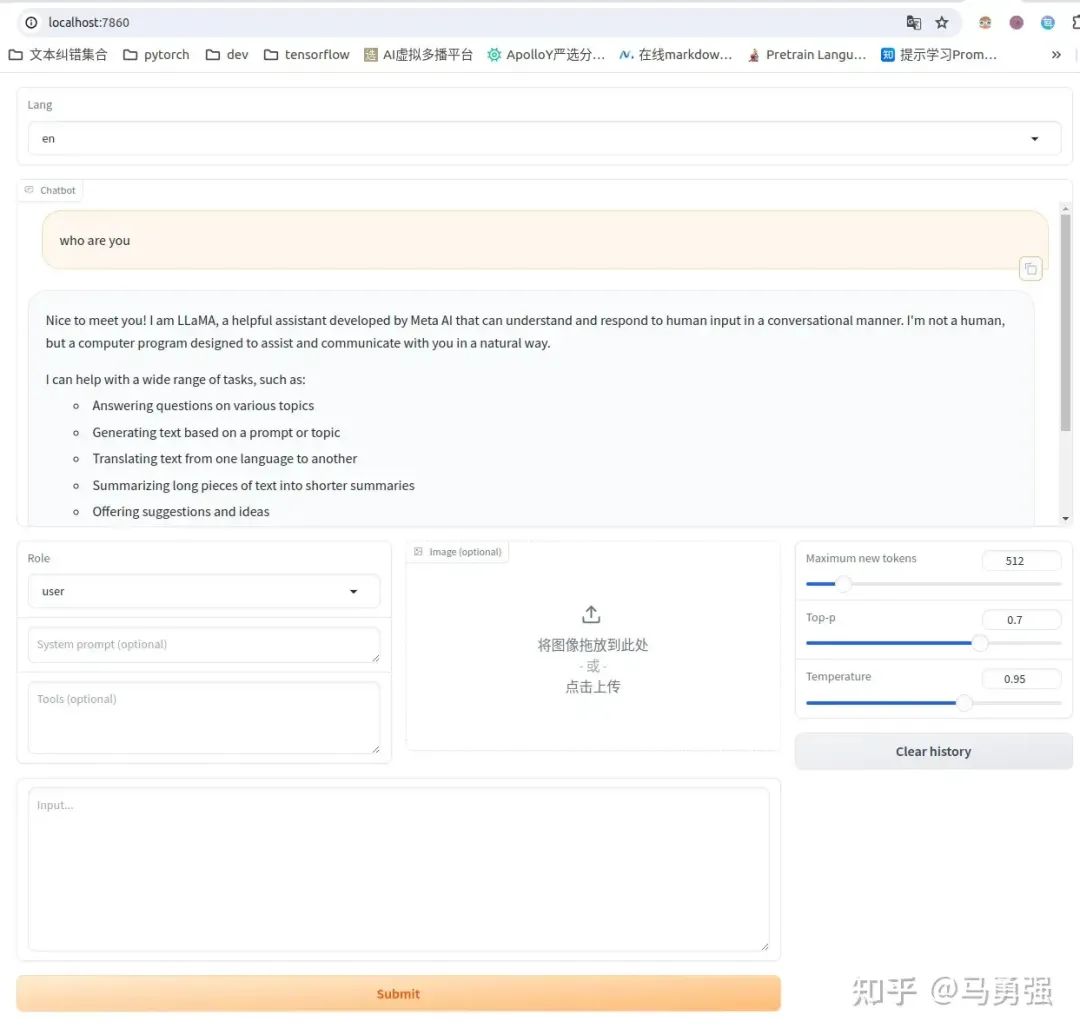
注意:这里的localhost:7860 指的是程序启动机器自身的7860端口,云上的用户可能无法通过本地的笔记本电脑直接访问,需要找云厂商获取域名和端口号的一些配置关系进行配置
比如阿里云用户需要做一下如下环境变量的配置才能正常运行gradio,然后再通过阿里云给的域名映射访问
export GRADIO_ROOT_PATH=/${JUPYTER_NAME}/proxy/7860/5. 自定义数据集构建
数据集的格式要求在不同的阶段是不同的,本教程以sft阶段的数据集需求,将以系统自带的identity数据集和将自定义的一个商品文案生成数据集为例,介绍数据集的使用。更多详情可以在https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md 中找到相关解释。
系统目前支持 alpaca 和sharegpt两种数据格式,以alpaca为例,整个数据集是一个json对象的list,具体数据格式为
[ { "instruction": "用户指令(必填)", "input": "用户输入(选填)", "output": "模型回答(必填)", "system": "系统提示词(选填)", "history": [ ["第一轮指令(选填)", "第一轮回答(选填)"], ["第二轮指令(选填)", "第二轮回答(选填)"] ] }
]例子比如单轮(alpaca_data_zh_51k.json 中的例子, 数据集在data/dataset_info.json中注册为alpaca_zh)
{ "instruction": "写一个有效的比较语句", "input": "篮球和足球", "output": "篮球和足球都是受欢迎的运动。"
}和多轮 (oaast_sft_zh.json 中的例子, 数据集在data/dataset_info.json中注册为oaast_sft_zh)
{ "instruction": "谢谢", "input": "", "output": "不用谢! 很高兴我提供的信息能够帮助到你! 如果还有什么其他问题也可以向我提问。", "history": [ [ "请你给我写一个面试准备计划,我想要去面试微软的程序员岗位", "首先,你可以去微软官网寻找招聘信息并申请面试。\n其次,您可以在社交媒体平台寻找微软公司对程序员的面试问题,并做好准备。\n最后,您可以自己对面试过程进行模拟,熟悉话题并减少紧张感。\n我希望你能面试成功。" ] ]
}所以我们训练的数据最好也转换成这种格式,然后在 data/dataset_info.json中进行注册(如果不做字段名称转换,则需要在注册的时候在 columns字段中做两个数据的映射配置)
接下来,我们使用两个具体的例子来说明数据集的使用
第一个是系统自带的identity.json数据集(已默认在data/dataset_info.json 注册为identity),对应文件已经在data目录下,我们通过操作系统的文本编辑器的替换功能,可以替换其中的NAME 和 AUTHOR ,换成我们需要的内容。
替换前
{ "instruction": "Who are you?", "input": "", "output": "I am NAME, an AI assistant developed by AUTHOR. How can I assist you today?"
}替换后
{ "instruction": "Who are you?", "input": "", "output": "I am PonyBot, an AI assistant developed by LLaMA Factory. How can I assist you today?"
}第二个是一个商品文案生成数据集,原始链接为https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
原始格式如下,很明显,训练目标是输入content (也就是prompt), 输出 summary (对应response)
{ "content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤", "summary": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
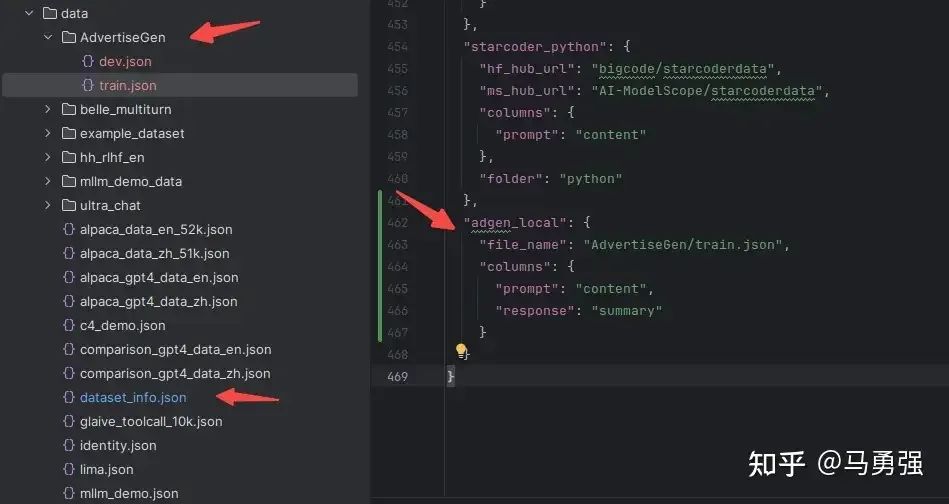
}想将该自定义数据集放到我们的系统中使用,则需要进行如下两步操作
-
复制该数据集到 data目录下
-
修改 data/dataset_info.json 新加内容完成注册, 该注册同时完成了3件事
-
自定义数据集的名称为adgen_local,后续训练的时候就使用这个名称来找到该数据集
-
指定了数据集具体文件位置
-
定义了原数据集的输入输出和我们所需要的格式之间的映射关系
6. 基于LoRA的sft指令微调
在准备好数据集之后,我们就可以开始准备训练了,我们的目标就是让原来的LLaMA3模型能够学会我们定义的“你是谁”,同时学会我们希望的商品文案的一些生成。
这里我们先使用命令行版本来做训练,从命令行更容易学习相关的原理。
本脚本参数改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/lora_single_gpu/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --output_dir ./saves/LLaMA3-8B/lora/sft \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --logging_steps 50 \ --warmup_steps 20 \ --save_steps 100 \ --eval_steps 50 \ --evaluation_strategy steps \ --load_best_model_at_end \ --learning_rate 5e-5 \ --num_train_epochs 5.0 \ --max_samples 1000 \ --val_size 0.1 \ --plot_loss \ --fp16关于参数的完整列表和解释可以通过如下命令来获取
llamafactory-cli train -h这里我对部分关键的参数做一下解释,model_name_or_path 和template 上文已解释
| 参数名称 | 参数说明 |
|---|---|
| stage | 当前训练的阶段,枚举值,有“sft”,“pt”,“rw”,"ppo"等,代表了训练的不同阶段,这里我们是有监督指令微调,所以是sft |
| do_train | 是否是训练模式 |
| dataset | 使用的数据集列表,所有字段都需要按上文在data_info.json里注册,多个数据集用","分隔 |
| dataset_dir | 数据集所在目录,这里是 data,也就是项目自带的data目录 |
| finetuning_type | 微调训练的类型,枚举值,有"lora",“full”,"freeze"等,这里使用lora |
| lora_target | 如果finetuning_type是lora,那训练的参数目标的定义,这个不同模型不同,请到https://github.com/hiyouga/LLaMA-Factory/tree/main?tab=readme-ov-file#supported-models 获取 不同模型的 可支持module, 比如llama3 默认是 q_proj,v_proj |
| output_dir | 训练结果保存的位置 |
| cutoff_len | 训练数据集的长度截断 |
| per_device_train_batch_size | 每个设备上的batch size,最小是1,如果GPU 显存够大,可以适当增加 |
| fp16 | 使用半精度混合精度训练 |
| max_samples | 每个数据集采样多少数据 |
| val_size | 随机从数据集中抽取多少比例的数据作为验证集 |
| 注意:精度相关的参数还有bf16 和pure_bf16,但是要注意有的老显卡,比如V100就无法支持bf16,会导致程序报错或者其他错误 |
|---|
训练过程中,系统会按照logging_steps的参数设置,定时输出训练日志,包含当前loss,训练进度等

训练完后就可以在设置的output_dir下看到如下内容,主要包含3部分
-
adapter开头的就是 LoRA保存的结果了,后续用于模型推理融合
-
training_loss 和trainer_log等记录了训练的过程指标
-
其他是训练当时各种参数的备份
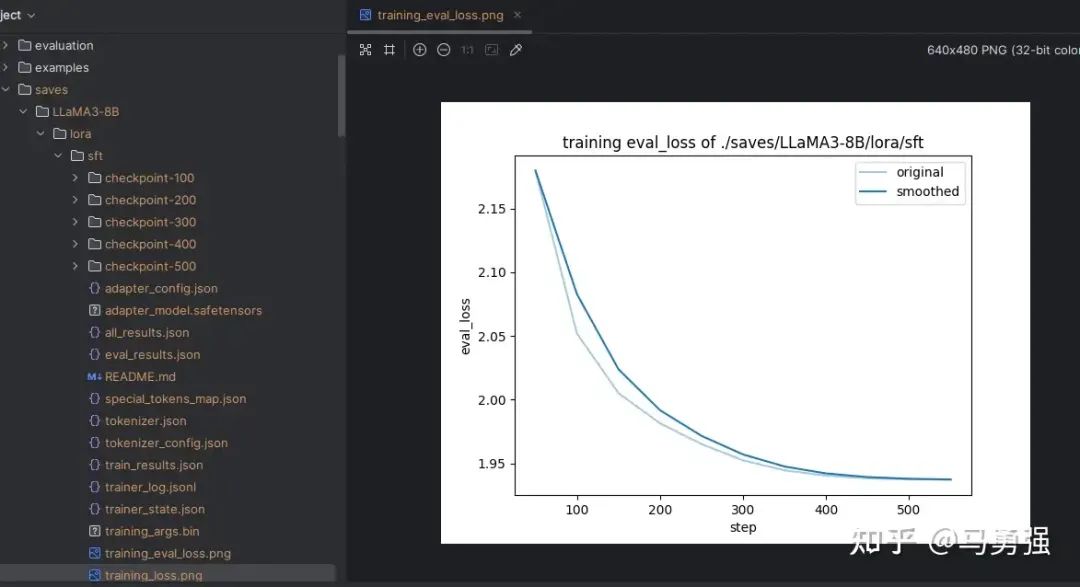
关于loss是什么等,这块不在本教程讨论内容范围之内,只需要记住loss在 正常情况下会随着训练的时间慢慢变小,最后需要下降到1以下的位置才会有一个比较好的效果,可以作为训练效果的一个中间指标。
7. 动态合并LoRA的推理
本脚本参数改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
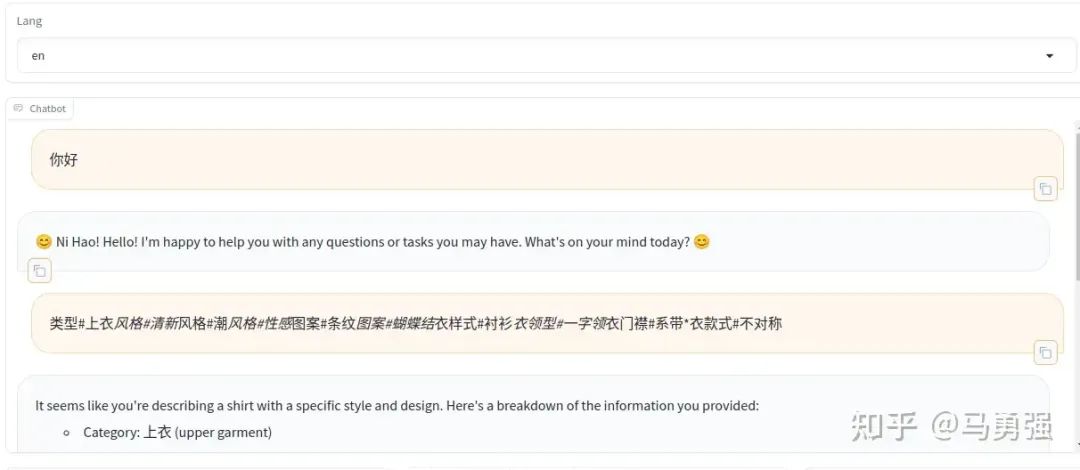
当基于LoRA的训练进程结束后,我们如果想做一下动态验证,在网页端里与新模型对话,与步骤4的原始模型直接推理相比,唯一的区别是需要通过finetuning_type参数告诉系统,我们使用了LoRA训练,然后将LoRA的模型位置通过 adapter_name_or_path参数即可。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora效果如下,可以看到,模型整个已经在学习了新的数据知识,学习了新的身份认知和商品文案生成的格式。

作为对比,如果删除LoRA相关参数,只使用原始模型重新启动测试,可以看到模型还是按照通用的一种回答。
如果不方便使用webui来做交互,使用命令行来做交互,同样也是可以的。
本脚本改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora效果如下

8. 批量预测和训练效果评估
当然上文中的人工交互测试,会偏感性,那有没有办法批量地预测一批数据,然后使用自动化的bleu和 rouge等常用的文本生成指标来做评估。指标计算会使用如下3个库,请先做一下pip安装
pip install jieba
pip install rouge-chinese
pip install nltk本脚本参数改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/lora_single_gpu/llama3_lora_predict.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage sft \ --do_predict \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --dataset alpaca_gpt4_zh,identity,adgen_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/predict \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_eval_batch_size 1 \ --max_samples 20 \ --predict_with_generate与训练脚本主要的参数区别如下两个
| 参数名称 | 参数说明 |
|---|---|
| do_predict | 现在是预测模式 |
| predict_with_generate | 现在用于生成文本 |
| max_samples | 每个数据集采样多少用于预测对比 |
最后会在output_dir下看到如下内容
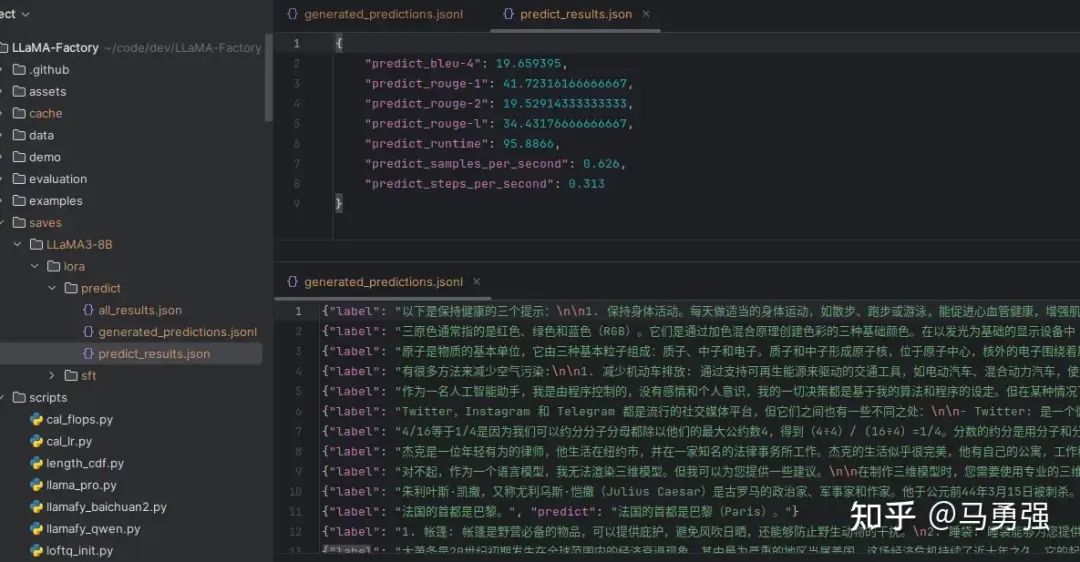
其中 generated_predictions.jsonl 文件 输出了要预测的数据集的原始label和模型predict的结果
predict_results.json给出了原始label和模型predict的结果,用自动计算的指标数据
这里给相关的指标做一下进一步的解释
| 指标 | 含义 |
|---|---|
| BLEU-4 | BLEU(Bilingual Evaluation Understudy)是一种常用的用于评估机器翻译质量的指标。BLEU-4 表示四元语法 BLEU 分数,它衡量模型生成文本与参考文本之间的 n-gram 匹配程度,其中 n=4。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_rouge-1 和 predict_rouge-2 | ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种用于评估自动摘要和文本生成模型性能的指标。ROUGE-1 表示一元 ROUGE 分数,ROUGE-2 表示二元 ROUGE 分数,分别衡量模型生成文本与参考文本之间的单个词和双词序列的匹配程度。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_rouge-l | ROUGE-L 衡量模型生成文本与参考文本之间最长公共子序列(Longest Common Subsequence)的匹配程度。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_runtime | 预测运行时间,表示模型生成一批样本所花费的总时间。单位通常为秒。 |
| predict_samples_per_second | 每秒生成的样本数量,表示模型每秒钟能够生成的样本数量。通常用于评估模型的推理速度。 |
| predict_steps_per_second | 每秒执行的步骤数量,表示模型每秒钟能够执行的步骤数量。对于生成模型,一般指的是每秒钟执行生成操作的次数。 |
9. LoRA模型合并导出
如果想把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件的话,可以使用如下命令。合并后的模型可以自由地像使用原始的模型一样应用到其他下游环节,当然也可以递归地继续用于训练。
本脚本参数改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/merge_lora/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora \ --export_dir megred-model-path \ --export_size 2 \ --export_device cpu \ --export_legacy_format False10. 一站式webui board的使用
到这里,恭喜你完成了LLaMA-Efficent-Tuning训练框架的基础使用,那还有什么内容是没有介绍的呢?还有很多!这里介绍一个在提升交互体验上有重要作用的功能, 支持模型训练全链路的一站式WebUI board。一个好的产品离不开好的交互,Stable Diffusion的大放异彩的重要原因除了强大的内容输出效果,就是它有一个好的WebUI。这个board将训练大模型主要的链路和操作都在一个页面中进行了整合,所有参数都可以可视化地编辑和操作
通过以下命令启动
| 注意:目前webui版本只支持单机单卡,如果是多卡请使用命令行版本 |
|---|
llamafactory-cli webui如图所示,上述的多个不同的大功能模块都通过不同的tab进行了整合,提供了一站式的操作体验。
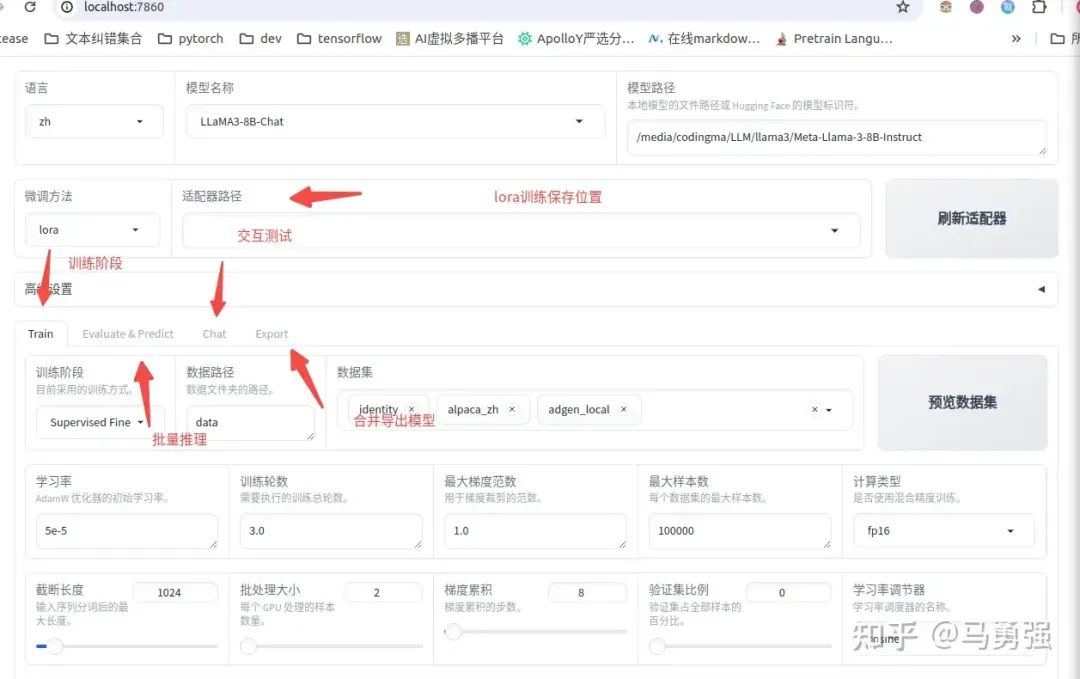
当各种参数配置好后,在train页面,可以通过预览命令功能,将训练脚本导出,用于支持多gpu训练
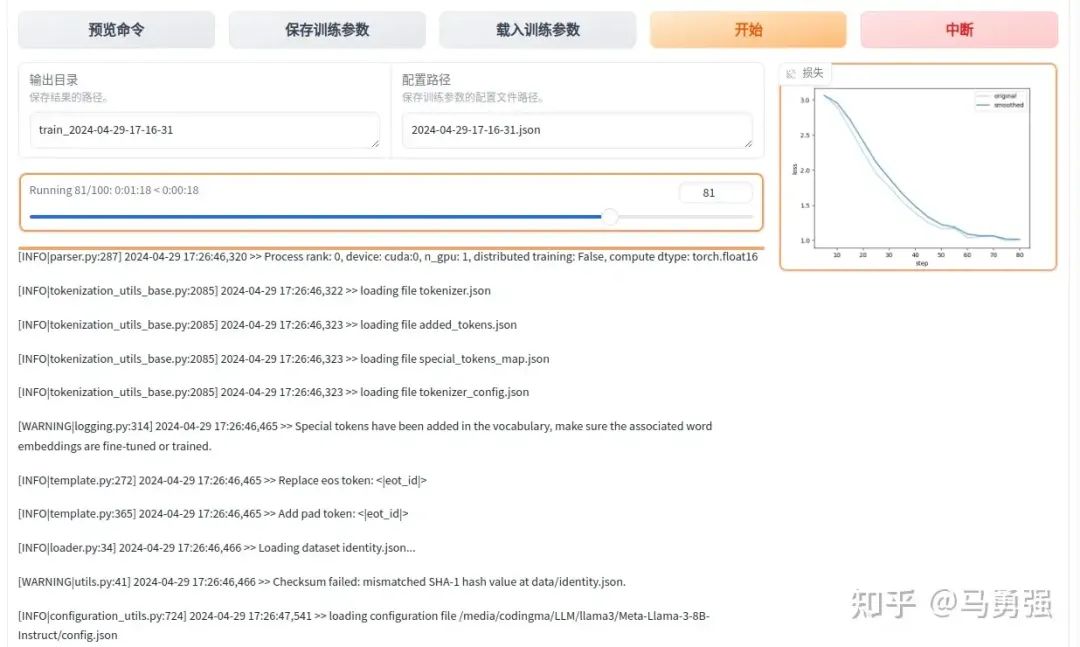
点击开始按钮, 即可开始训练,网页端和服务器端会同步输出相关的日志结果
训练完毕后, 点击“刷新适配器”,即可找到该模型历史上使用webui训练的LoRA模型文件,后续再训练或者执行chat的时候,即会将此LoRA一起加载。

11. API Server的启动与调用
训练好后,可能部分同学会想将模型的能力形成一个可访问的网络接口,通过API 来调用,接入到langchian或者其他下游业务中,项目也自带了这部分能力。
API 实现的标准是参考了OpenAI的相关接口协议,基于uvicorn服务框架进行开发, 使用如下的方式启动
本脚本改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \ --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \ --adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ --template llama3 \ --finetuning_type lora项目也支持了基于vllm 的推理后端,但是这里由于一些限制,需要提前将LoRA 模型进行merge,使用merge后的完整版模型目录或者训练前的模型原始目录都可。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \ --model_name_or_path megred-model-path \ --template llama3 \ --infer_backend vllm \ --vllm_enforce_eager服务启动后,即可按照openai 的API 进行远程访问,主要的区别就是替换 其中的base_url,指向所部署的机器url和端口号即可。
12. 进阶-大模型主流评测 benchmark
虽然大部分同学的主流需求是定制一个下游的垂直模型,但是在部分场景下,也可能有同学会使用本项目来做更高要求的模型训练,用于大模型刷榜单等,比如用于评测mmlu等任务。当然这类评测同样可以用于评估大模型二次微调之后,对于原来的通用知识的泛化能力是否有所下降。(因为一个好的微调,尽量是在具备垂直领域知识的同时,也保留了原始的通用能力)
本项目提供了mmlu,cmmlu, ceval三个常见数据集的自动评测脚本,按如下方式进行调用即可。
本脚本改编自 LLaMA-Factory/examples/lora_single_gpu/llama3_lora_eval.yaml at main · hiyouga/LLaMA-Factory
如果是chat版本的模型
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3 \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1输出如下, 具体任务的指标定义请参考mmlu,cmmlu, ceval等任务原始的相关资料, 和llama3的官方报告基本一致
Average: 63.64 STEM: 50.83
Social Sciences: 76.31 Humanities: 56.63 Other: 73.31如果是base版本的模型,template改为fewshot即可
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B \
--template fewshot \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1零基础入门AI大模型
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

)


—— 吃透泛型机制,筑牢 Java 类型安全防线)


(2))


:角色、用户及项目管理实践)





)


