正则表达式中的元字符是具有特殊含义的字符,它们不表示字面意义,而是用于控制匹配模式。
基本元字符
. (点号)
匹配除换行符(
\n)外的任意单个字符示例:
a.b匹配 "aab", "a1b", "a b" 等
^ (脱字符)
匹配字符串的开始位置
示例:
^abc匹配以 "abc" 开头的字符串
$ (美元符)
匹配字符串的结束位置
示例:
xyz$匹配以 "xyz" 结尾的字符串
\ (反斜杠)
转义字符,使后面的字符失去特殊含义
示例:
\.匹配实际的点号而不是任意字符
字符类元字符
[] (方括号)
定义字符集合,匹配其中任意一个字符
示例:
[aeiou]匹配任意一个元音字母
[^] (否定字符类)
匹配不在方括号中的任意字符
示例:
[^0-9]匹配任意非数字字符
- (连字符)
在字符类中表示范围
示例:
[a-z]匹配任意小写字母
量词元字符
* (星号)
匹配前面的子表达式零次或多次
示例:
ab*c匹配 "ac", "abc", "abbc" 等
+ (加号)
匹配前面的子表达式一次或多次
示例:
ab+c匹配 "abc", "abbc" 但不匹配 "ac"
? (问号)
匹配前面的子表达式零次或一次
示例:
colou?r匹配 "color" 和 "colour"
{n} (花括号)
精确匹配n次
示例:
a{3}匹配 "aaa"
{n,}
至少匹配n次
示例:
a{2,}匹配 "aa", "aaa" 等
{n,m}
匹配n到m次
示例:
a{2,4}匹配 "aa", "aaa", "aaaa"
分组和选择元字符
() (圆括号)
定义子表达式或捕获组
示例:
(ab)+匹配 "ab", "abab" 等
| (竖线)
表示"或"关系
示例:
cat|dog匹配 "cat" 或 "dog"
特殊字符类元字符
\d:匹配任意数字,等价于 [0-9]
\D:匹配任意非数字,等价于 [^0-9]
\w:匹配任意单词字符(字母、数字、下划线),等价于 [a-zA-Z0-9_]
\W:匹配任意非单词字符,等价于 [^a-zA-Z0-9_]
\s:匹配任意空白字符(空格、制表符、换行符等)
\S:匹配任意非空白字符
边界匹配元字符
\b
匹配单词边界
示例:
\bcat\b匹配 "cat" 但不匹配 "category"
\B
匹配非单词边界
示例:
\Bcat\B匹配 "scattered" 中的 "cat" 但不匹配单独的 "cat"
其他元字符
\n:匹配换行符
\t:匹配制表符
\r:匹配回车符
\f:匹配换页符
\v:匹配垂直制表符
贪婪与非贪婪量词
默认情况下,量词(*, +, ?, {})是贪婪的,会尽可能多地匹配字符。在量词后加?可使其变为非贪婪(懒惰)模式:
*?:零次或多次,但尽可能少+?:一次或多次,但尽可能少??:零次或一次,但尽可能少{n,m}?:n到m次,但尽可能少
示例:<.*?> 匹配HTML标签时不会跨标签匹配
正向和负向预查
(?=...) (正向肯定预查)
匹配后面跟着特定模式的位置
示例:
Windows(?=95|98)匹配后面跟着95或98的"Windows"
(?!...) (正向否定预查)
匹配后面不跟着特定模式的位置
示例:
Windows(?!95|98)匹配后面不跟着95或98的"Windows"
(?<=...) (反向肯定预查)
匹配前面是特定模式的位置
示例:
(?<=95|98)Windows匹配前面是95或98的"Windows"
(?<!...) (反向否定预查)
匹配前面不是特定模式的位置
示例:
(?<!95|98)Windows匹配前面不是95或98的"Windows"
实例
接下来我们分析一个匹配邮箱的正则表达式,如下图:
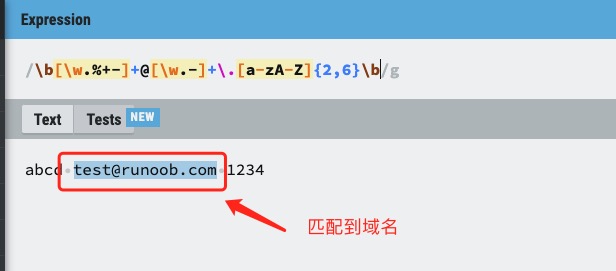
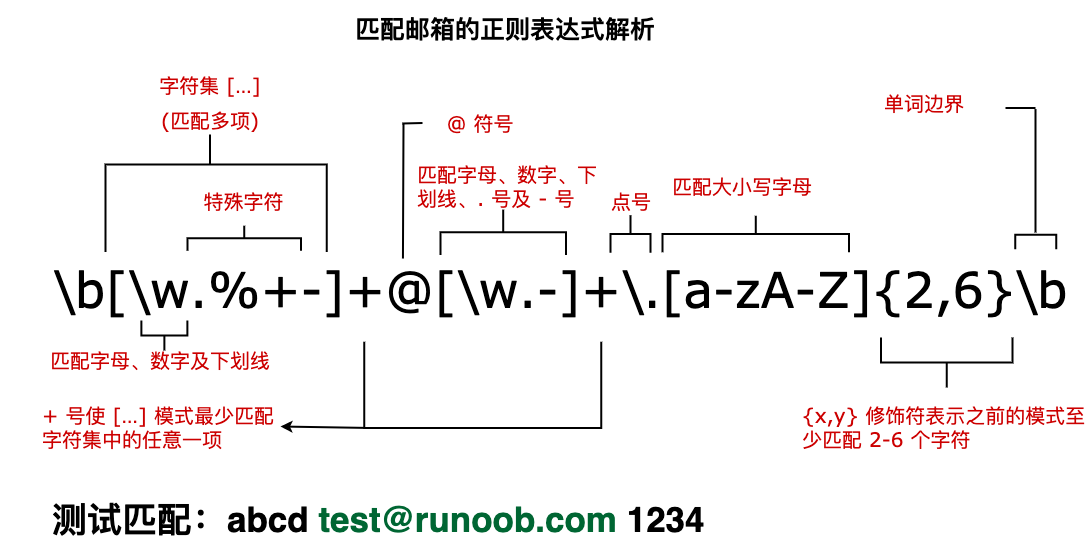
QString inputStr = "abc12.000";QRegExp regExp("[0-9.]", Qt::CaseInsensitive);QString numberStr;// 遍历字符串,提取所有匹配的字符(即数字和小数点)int pos = 0;while ((pos = regExp.indexIn(inputStr, pos)) != -1){numberStr += regExp.cap(0); // cap(0) 获取当前匹配的字符pos += regExp.matchedLength(); // 移动到下一个匹配位置}// 输出numberStr = 12.000;




-Eclipse插件实现)




)








