背景意义
研究背景与意义
随着工业自动化和智能制造的迅速发展,零件的高效识别与分割在生产线上的重要性日益凸显。传统的图像处理方法在处理复杂场景时往往面临着准确性不足和实时性差的问题,而深度学习技术的引入为这一领域带来了新的机遇。特别是基于卷积神经网络(CNN)的实例分割技术,能够对图像中的每一个目标进行精确的像素级别分割,极大地提升了零件识别的精度和效率。
本研究旨在基于改进的YOLOv11模型,构建一个高效的零件实例分割系统。YOLO(You Only Look Once)系列模型以其快速的推理速度和良好的检测精度而受到广泛关注。通过对YOLOv11进行改进,我们希望能够在保持实时性能的同时,进一步提升模型在复杂背景下的分割精度。此外,所使用的数据集包含1600张图像,涵盖了两个类别的零件实例,为模型的训练和验证提供了丰富的样本支持。
在实际应用中,零件实例分割系统不仅可以提高生产效率,还能降低人工干预的需求,减少人为错误的发生。通过对零件进行自动化识别和分割,企业能够实现更高的生产灵活性和资源利用率,进而提升整体竞争力。因此,研究基于改进YOLOv11的零件实例分割系统,不仅具有重要的学术价值,也对实际工业应用具有深远的意义。通过这一研究,我们期望为智能制造领域的图像处理技术提供新的思路和解决方案,推动行业的技术进步与创新发展。
图片效果
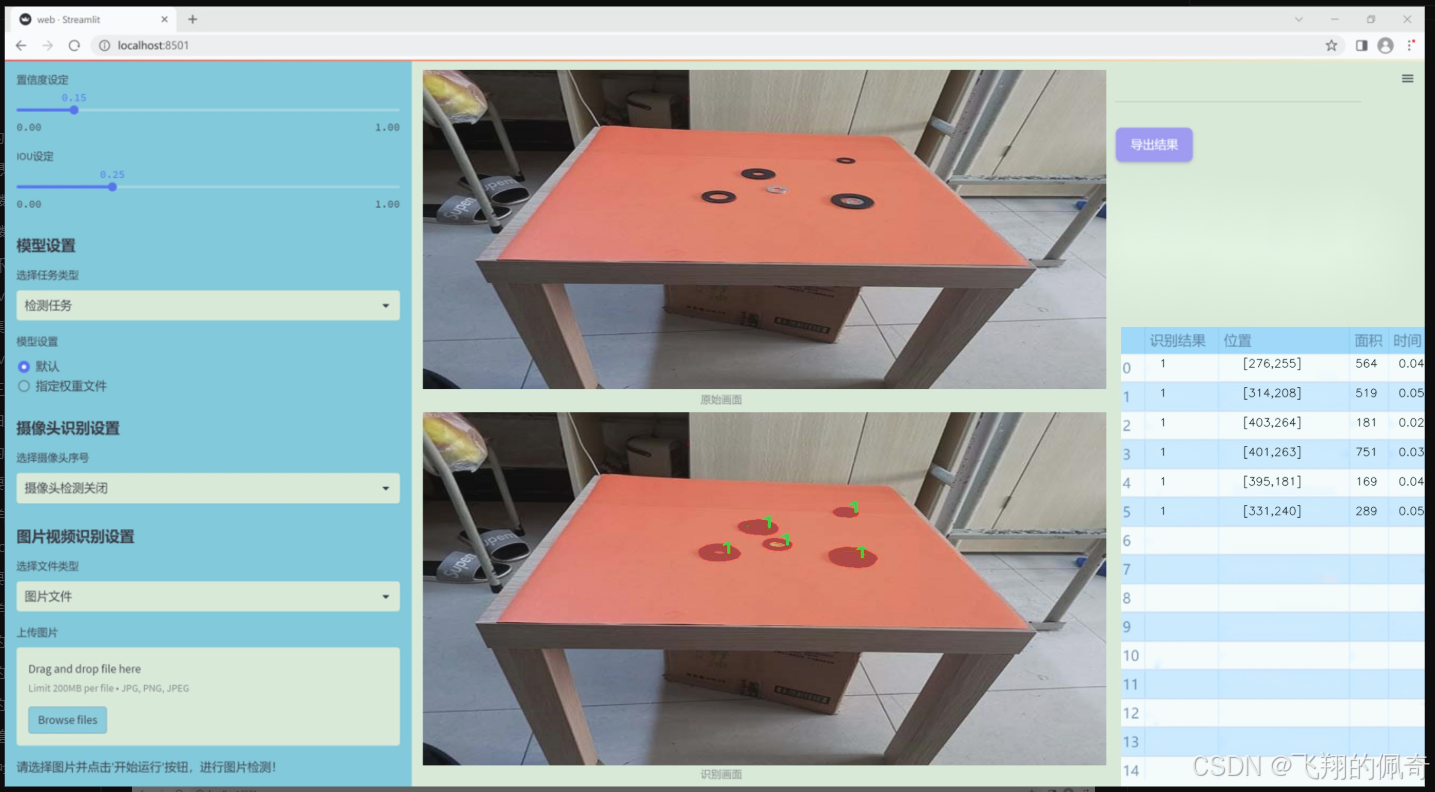
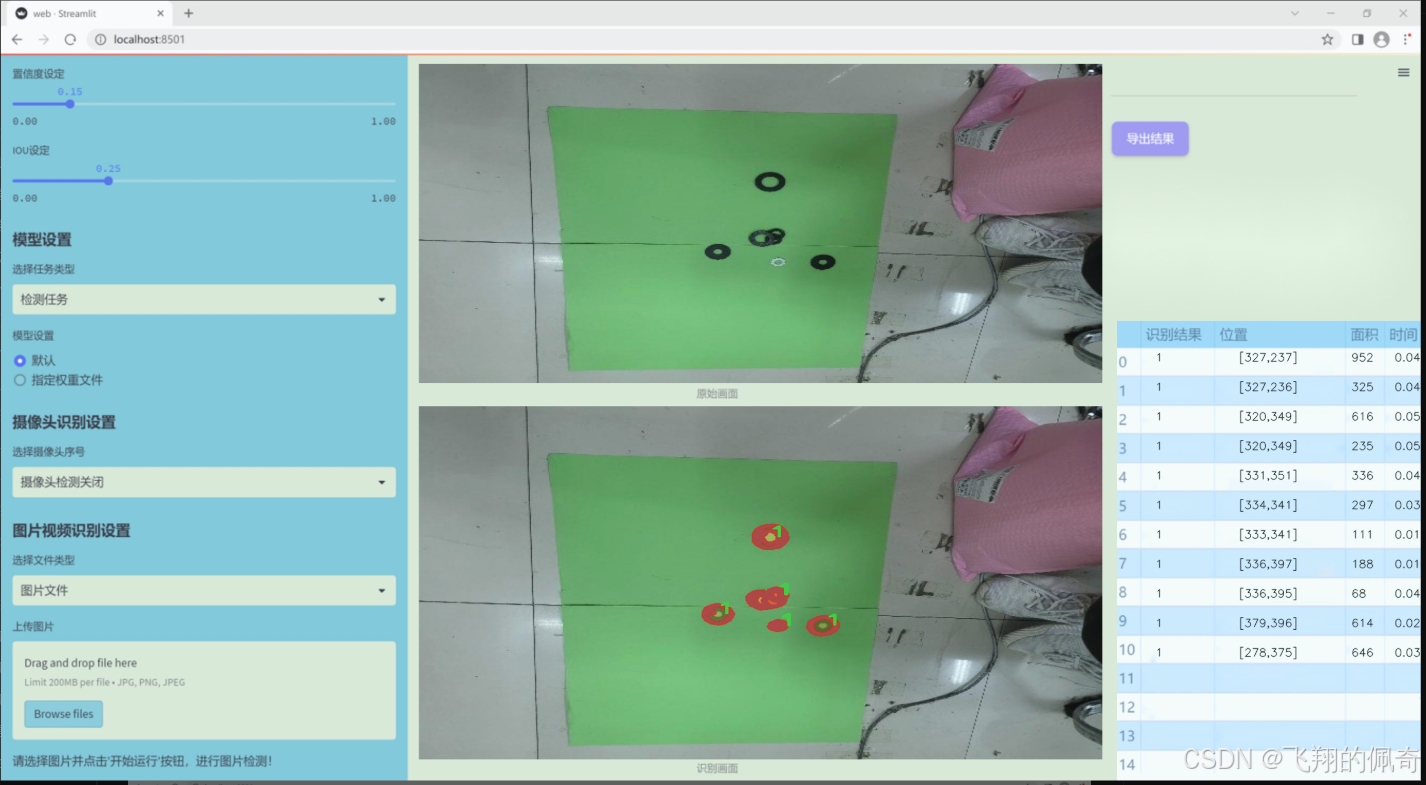
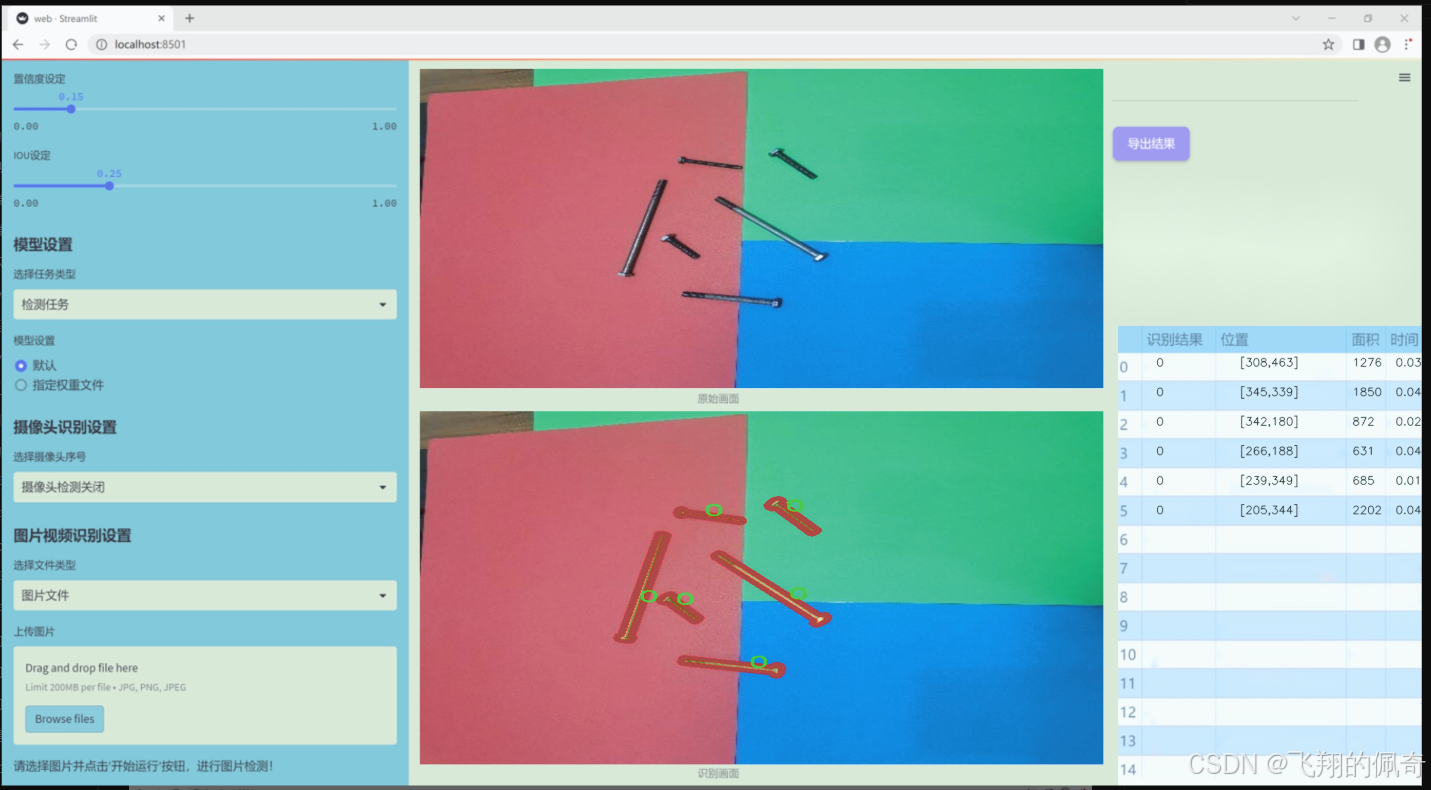
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的零件实例分割系统,特别聚焦于“2d-segnew”主题。该数据集包含了丰富的图像数据,专门设计用于训练和评估深度学习模型在零件实例分割任务中的表现。数据集中包含两个主要类别,分别标记为“0”和“1”,这两个类别的选择旨在涵盖特定的应用场景,以确保模型能够在实际应用中有效识别和分割不同类型的零件。
数据集的构建过程遵循严格的标准,确保每个类别的样本数量和质量都能满足训练需求。每个图像都经过精确标注,确保模型在学习过程中能够获得准确的反馈。这种高质量的标注不仅提升了模型的学习效率,也为后续的验证和测试提供了可靠的基础。此外,数据集中的图像多样性涵盖了不同的拍摄角度、光照条件和背景环境,以增强模型的泛化能力,使其能够在各种实际应用场景中表现出色。
在训练过程中,改进YOLOv11将利用该数据集进行端到端的学习,通过不断优化模型参数,提升其在零件实例分割任务中的准确性和效率。数据集的设计理念不仅关注模型的性能提升,也考虑到实际应用中的可操作性和适应性,确保最终的系统能够在工业生产、自动化检测等领域发挥重要作用。通过对该数据集的深入分析和应用,我们期望能够推动零件实例分割技术的发展,为相关行业带来更高的智能化水平和生产效率。
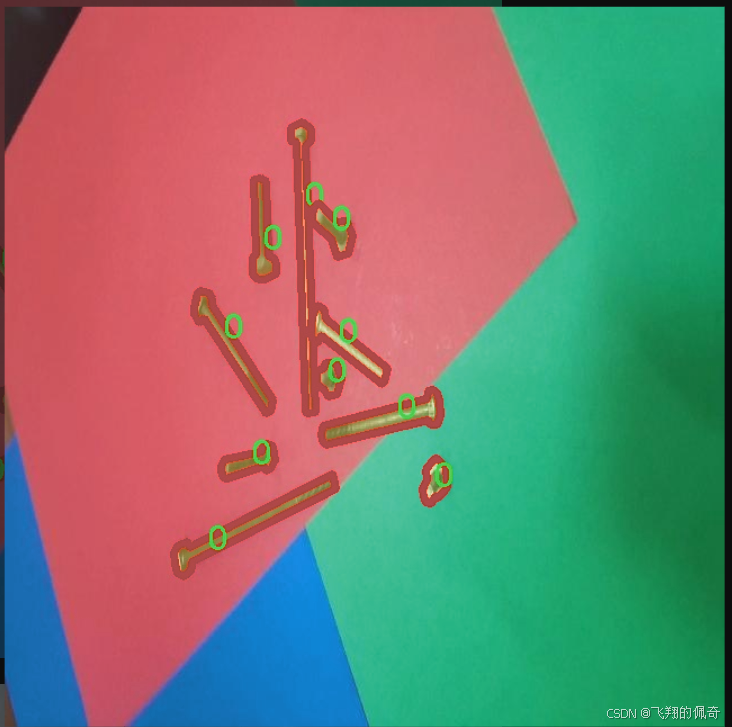




核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于控制注意力的平滑程度
# 定义平均池化层self.avgpool = nn.AdaptiveAvgPool2d(1)# 定义全连接层self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel) # 批归一化self.relu = nn.ReLU(inplace=True) # ReLU激活函数# 定义通道注意力的全连接层self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention # 设置通道注意力的计算方法# 定义滤波器注意力的计算方法if in_planes == groups and in_planes == out_planes: # 深度卷积self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 定义空间注意力的计算方法if kernel_size == 1: # 点卷积self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 定义核注意力的计算方法if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化权重def _initialize_weights(self):# 初始化卷积层和批归一化层的权重for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def get_channel_attention(self, x):# 计算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 计算滤波器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 计算空间注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 计算核注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向传播x = self.avgpool(x) # 平均池化x = self.fc(x) # 全连接层x = self.bn(x) # 批归一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)
class AdaptiveDilatedConv(nn.Module):
“”“自适应膨胀卷积的封装类,作为普通卷积层的替代。”“”
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):super(AdaptiveDilatedConv, self).__init__()# 定义卷积层self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)def forward(self, x):# 前向传播return self.conv(x) # 直接调用卷积层进行计算
代码核心部分说明:
OmniAttention 类:实现了多种注意力机制,包括通道注意力、滤波器注意力、空间注意力和核注意力。通过全连接层和卷积层计算不同的注意力,并在前向传播中应用这些注意力。
AdaptiveDilatedConv 类:封装了自适应膨胀卷积的功能,允许使用不同的卷积参数进行卷积操作。
这些部分是实现自适应卷积和注意力机制的关键,能够有效地提高模型的表现。
这个程序文件 fadc.py 实现了一些深度学习中的卷积操作,特别是与可调变形卷积(Modulated Deformable Convolution)相关的功能。文件中定义了多个类和函数,主要包括 OmniAttention、FrequencySelection、AdaptiveDilatedConv 和 AdaptiveDilatedDWConv,它们都继承自 PyTorch 的 nn.Module 类。
首先,OmniAttention 类实现了一种注意力机制,用于对输入特征图的通道、滤波器、空间和卷积核进行加权。这个类的构造函数接受多个参数,如输入和输出通道数、卷积核大小、组数、减少比例等。类中定义了多个方法,包括权重初始化、前向传播等。在前向传播中,输入特征图经过平均池化、全连接层、批归一化和激活函数处理后,生成通道注意力、滤波器注意力、空间注意力和卷积核注意力。
接下来,generate_laplacian_pyramid 函数用于生成拉普拉斯金字塔,通常用于图像处理中的多尺度分析。该函数通过逐层下采样输入张量,并计算每层的拉普拉斯差分,返回一个包含不同尺度特征的金字塔。
FrequencySelection 类实现了一种频率选择机制,允许对输入特征进行频率域的处理。它的构造函数接受多个参数,设置频率选择的方式、激活函数、空间卷积参数等。在前向传播中,输入特征通过不同的频率选择方法进行处理,最终返回加权后的特征图。
AdaptiveDilatedConv 和 AdaptiveDilatedDWConv 类则是对可调变形卷积的封装,支持自适应的膨胀卷积操作。它们的构造函数中包含了对偏移量和掩码的卷积操作,允许在卷积过程中使用注意力机制来调整权重。前向传播中,输入特征经过偏移量和掩码的计算后,使用变形卷积进行处理。
总的来说,这个文件提供了一种灵活的卷积操作实现,结合了注意力机制和频率选择,适用于图像处理和计算机视觉任务。通过这些类和函数,用户可以构建复杂的神经网络架构,以提高模型的性能和适应性。
10.4 TransNext.py
以下是保留的核心代码部分,并添加了详细的中文注释:
try:
# 尝试导入swattention模块和TransNext_cuda中的所有内容
import swattention
from ultralytics.nn.backbone.TransNeXt.TransNext_cuda import *
except ImportError as e:
# 如果导入失败(例如swattention模块不存在),则导入TransNext_native中的所有内容
from ultralytics.nn.backbone.TransNeXt.TransNext_native import *
pass
代码注释说明:
try块:
try::开始一个异常处理块,尝试执行其中的代码。
import swattention:尝试导入名为swattention的模块,如果该模块存在,则可以使用其中的功能。
from ultralytics.nn.backbone.TransNeXt.TransNext_cuda import *:尝试从ultralytics库中的TransNeXt子模块导入所有内容(通常是类和函数),这里指定了使用CUDA版本的实现。
except块:
except ImportError as e::捕获导入时可能发生的ImportError异常,as e用于获取异常信息。
from ultralytics.nn.backbone.TransNeXt.TransNext_native import *:如果swattention模块或CUDA版本的TransNext导入失败,则导入TransNext_native中的所有内容,通常是CPU版本的实现。
pass:在异常处理块中,pass语句表示不执行任何操作,继续执行后续代码。
总结:
这段代码的主要目的是根据系统环境的不同,选择合适的模块和实现进行导入,以确保代码的兼容性和可用性。
这个程序文件名为 TransNext.py,其主要功能是导入所需的模块和类。首先,程序尝试导入 swattention 模块以及 TransNext_cuda 中的所有内容。如果这一步骤成功,程序将继续执行;如果在导入过程中发生 ImportError(即找不到指定的模块),则程序会捕获这个异常,并尝试导入 TransNext_native 中的所有内容。
这种处理方式通常用于确保程序在不同的环境中都能正常运行。例如,TransNext_cuda 可能依赖于 CUDA(用于加速计算的并行计算平台和编程模型),而 TransNext_native 则可能是一个不依赖于 CUDA 的实现。通过这种方式,程序能够根据系统的支持情况选择合适的模块,从而提高了代码的兼容性和灵活性。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

)







-Eclipse插件实现)




)




