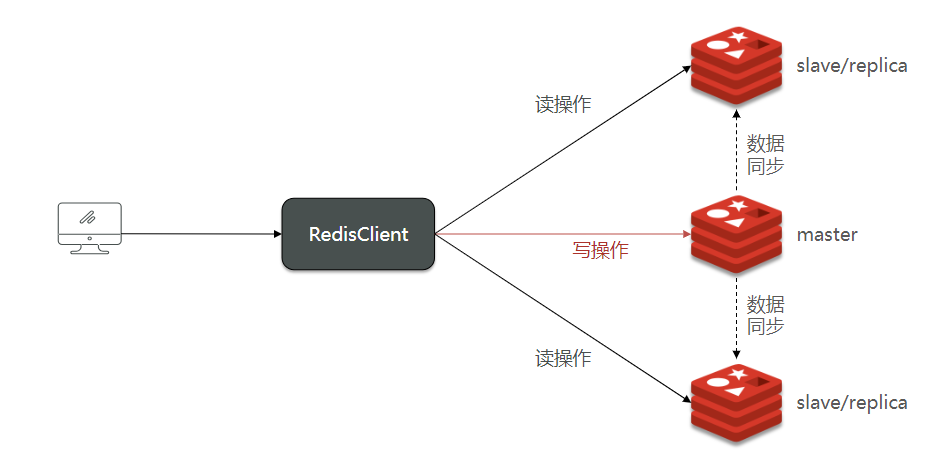
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
我们搭建的主从集群共包含三个节点,一个主节点,两个从节点。操作系统是 CentOS7.9。 这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下: IP 配置文件路径 PORT 角色 192.168.119.171 /etc/redis/7001/redis.conf 7001 master 192.168.119.171 /etc/redis/7002/redis.conf 7002 slave 192.168.119.171 /etc/redis/7003/redis.conf 7003 slave
**创建目录:**要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。我们创建三个文件夹,名字分别叫7001、7002、7003。
cd /etc/redis/
mkdir 7001 7002 7003
配置文件/etc/redis/7001/redis.conf 配置如下,这个是 master 节点的配置
bind 0.0 .0.0
protected-mode no
daemonize yes
save 3600 1
save 300 100
save 60 10000
appendonly no
replica-announce-ip 192.168 .119.171
port 7001
dir /etc/redis/7001/
配置文件/etc/redis/7002/redis.conf 配置如下,这个是 slave 节点的配置
bind 0.0 .0.0
protected-mode no
daemonize yes
save 3600 1
save 300 100
save 60 10000
appendonly no
replica-announce-ip 192.168 .119.171
port 7002
dir /etc/redis/7002/
slaveof 192.168 .119.171 7001
配置文件/etc/redis/7003/redis.conf 配置如下,这个是 slave 节点的配置
bind 0.0 .0.0
protected-mode no
daemonize yes
save 3600 1
save 300 100
save 60 10000
appendonly no
replica-announce-ip 192.168 .119.171
port 7003
dir /etc/redis/7003/
slaveof 192.168 .119.171 7001
配置说明: **持久化配置:**持久化模式改为默认的RDB模式,AOF保持关闭状态。 修改 **bind**** 参数:** bind 0.0.0.0 允许所有 IP 连接。**修改实例的声明IP:**虚拟机本身有多个IP,为了避免混乱,我们需要指定每一个实例的 IP 信息。 **修改每个实例的端口、工作目录:**修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录。 **为每个slave 节点开启主从关系:**slaveof 192.168.119.171 7001
sudo systemctl stop firewalld
sudo systemctl disable firewalld
我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
redis-server /etc/redis/7001/redis.conf
redis-server /etc/redis/7002/redis.conf
redis-server /etc/redis/7003/redis.conf
printf '%s\n ' 7001 7002 7003 | xargs -I{ } -t redis-cli -p { } shutdown
要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。 有临时和永久两种模式: 永久:修改配置文件,在redis.conf中添加一行配置:slaveof <masterip> <masterport>。 临时:使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效)。 注意:在5.0以后新增命令replicaof,与salveof效果一致。 上面已经用配置文件实现了主从关系,现在演示命令方式。
redis-cli -p 7002
slaveof 192.168 .119.171 7001
redis-cli -p 7003
slaveof 192.168 .119.171 7001
redis-cli -p 7001
info replication
role:master
connected_slaves:2
slave0:ip= 192.168 .119.171,port= 7002 ,state= online,offset= 56 ,lag= 1
slave1:ip= 192.168 .119.171,port= 7003 ,state= online,offset= 56 ,lag= 1
master_failover_state:no-failover
master_replid:9416e12727f8b889f6293c3eedcb9f07de1670d6
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
利用redis-cli连接7001,执行set num 123 利用redis-cli连接7002,执行get num,再执行set num 666 127.0 .0.1:7002 >"123"
127.0 .0.1:7002 >set num 666
( error) READONLY You can't write against a read only replica.
利用redis-cli连接7003,执行get num,再执行set num 888 127.0 .0.1:7003 >"123"
127.0 .0.1:7003 >set num 888
( error) READONLY You can't write against a read only replica.
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。 为了使 Redis 在系统启动时自动运行,可以创建一个 systemd 服务文件:
vi /etc/systemd/system/redismaster.service[ Unit]
Description = redismaster
After = network.target[ Service]
Type = forking
ExecStart = /usr/local/bin/redis-server /tmp/7001/redis.conf
PrivateTmp = true[ Install]
WantedBy = multi-user.target
systemctl daemon-reload
systemctl start redismaster
systemctl stop redismaster
systemctl restart redismaster
systemctl status redismaster
systemctl enable redismaster
vi /etc/systemd/system/redisslave01.service[ Unit]
Description = redisslave01
After = network.target[ Service]
Type = forking
ExecStart = /usr/local/bin/redis-server /tmp/7002/redis.conf
PrivateTmp = true[ Install]
WantedBy = multi-user.target
vi /etc/systemd/system/redisslave02.service[ Unit]
Description = redisslave02
After = network.target[ Service]
Type = forking
ExecStart = /usr/local/bin/redis-server /tmp/7003/redis.conf
PrivateTmp = true[ Install]
WantedBy = multi-user.target
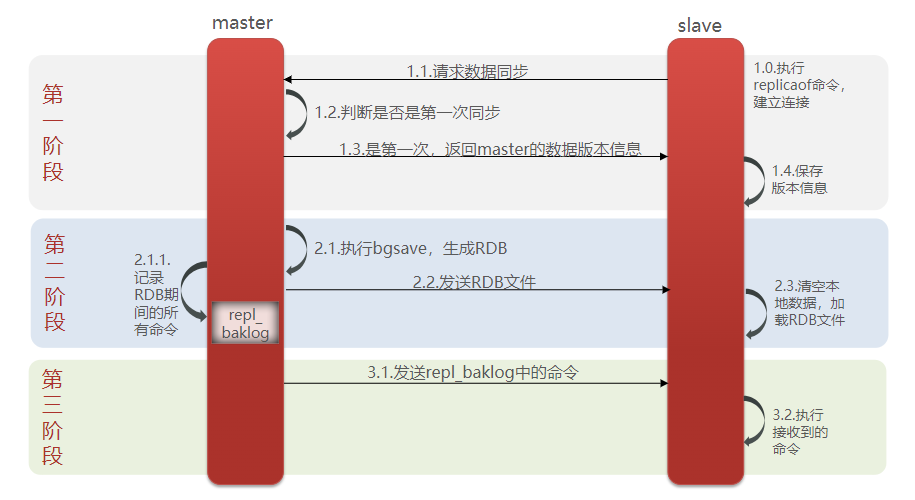
slave节点请求增量同步 master节点判断replid,发现不一致,拒绝增量同步 master将完整内存数据生成RDB,发送RDB到slave slave清空本地数据,加载master的RDB master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave slave执行接收到的命令,保持与master之间的同步
Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。 因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
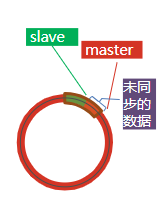
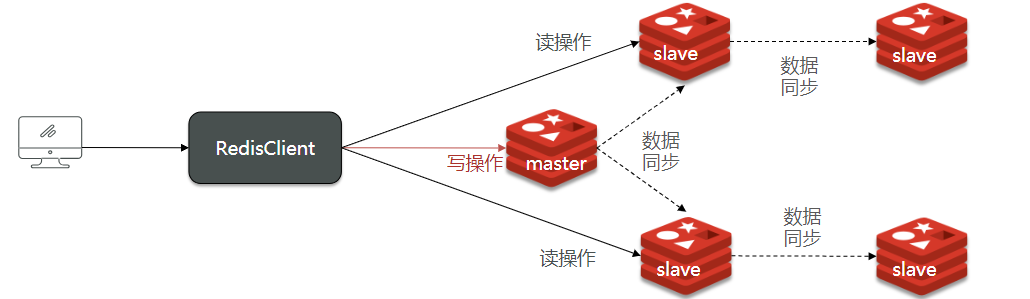
repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。 Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力








技术解析:3D重建与虚拟世界的未来)





)



![[论文梳理] 足式机器人规划控制流程 - 接触碰撞的控制 - 模型误差 - 自动驾驶车的安全合规(4个课堂讨论问题)](http://pic.xiahunao.cn/[论文梳理] 足式机器人规划控制流程 - 接触碰撞的控制 - 模型误差 - 自动驾驶车的安全合规(4个课堂讨论问题))

