文章目录
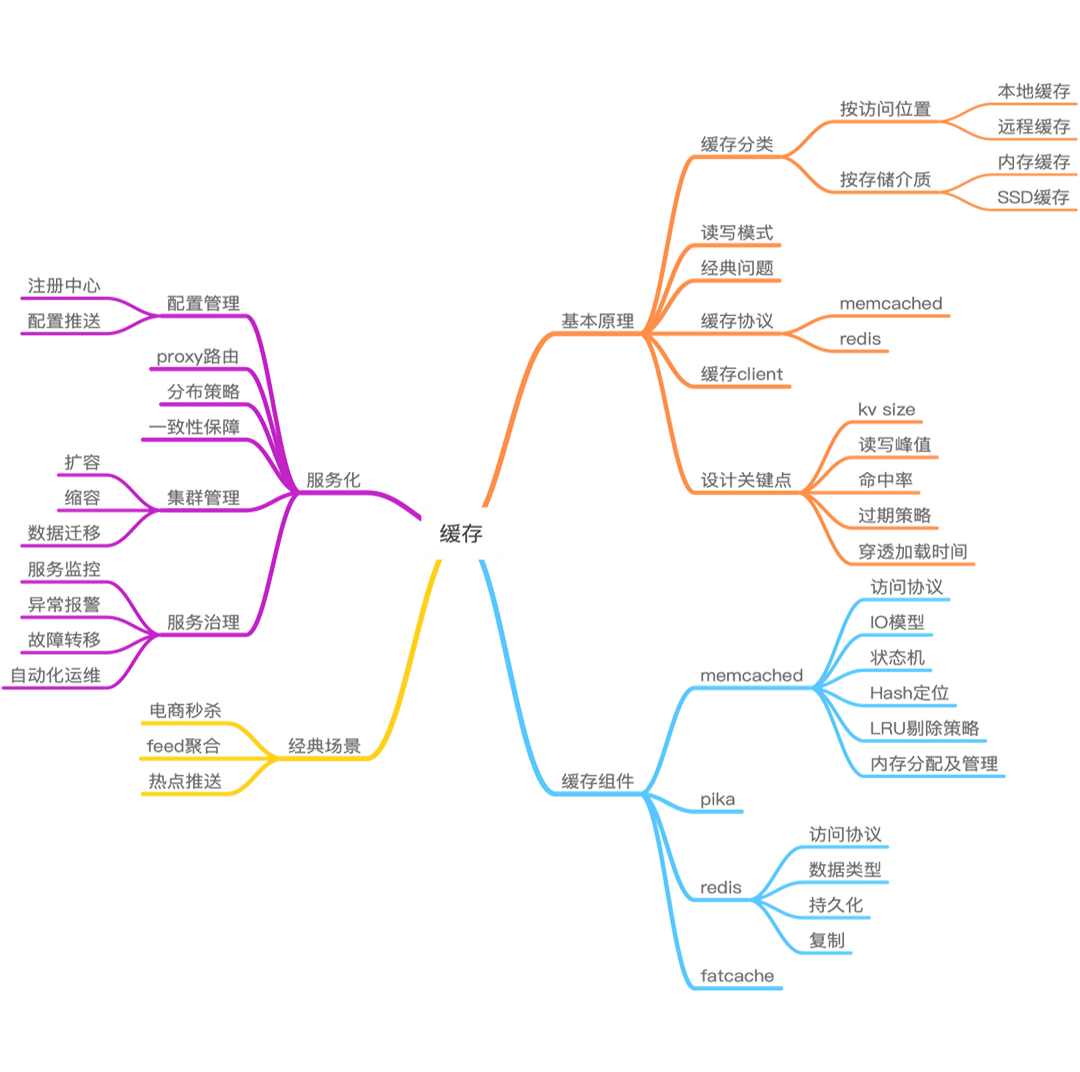
- 缓存全景图
- Pre
- 缓存读写模式概述
- 1. Cache Aside(旁路缓存)
- 工作流程
- 优缺点
- 2. Read/Write Through(读写穿透)
- 工作流程
- 优缺点
- 典型场景
- 3. Write Behind Caching(异步写回)
- 工作流程
- 优缺点
- 典型场景
- 缓存分类及常用组件
- 1. 按宿主层次分类
- 2. 按存储介质分类
- 场景对比与权衡
- 小结

缓存全景图
Pre
每日一博 - 图解5种Cache策略
架构思维:缓存层场景实战_读缓存(下)
缓存读写模式概述
在业务系统中,引入缓存主要为了降低数据库压力、提升响应性能,但也带来了数据一致性和维护成本的挑战。
根据缓存和数据库的更新策略,常见有三种读写模式:
-
Cache Aside(旁路缓存)
-
Read/Write Through(读写穿透)
-
Write Behind Caching(异步缓存写入)

下面逐一详细介绍。
1. Cache Aside(旁路缓存)
工作流程

-
写操作:
- 应用先更新数据库
- 删除 Cache 中对应的 key
- 由数据库变更日志或下游 Trigger 驱动重新计算并回写缓存
-
读操作:
- 应用先查询 Cache
- 若未命中,则加载数据库数据
- 将结果写入 Cache,并返回给调用方
写 ➔ Update DB ➔ DEL cache[key]
读 ➔ GET cache[key] ➔ Miss ➔ Query DB ➔ SET cache[key] ➔ Return
优缺点
-
优点
- 以数据库为准,强一致性风险低
- 缓存回写采用延迟(Lazy)计算,可灵活处理复杂业务
-
缺点
- 业务端需同时维护 Cache 和 DB 访问逻辑,代码复杂度高
- 触发缓存回写依赖日志或 Trigger,增加组件依赖
2. Read/Write Through(读写穿透)
工作流程
由缓存存储服务(Cache Service)统一代理读写,业务应用只与存储服务交互。
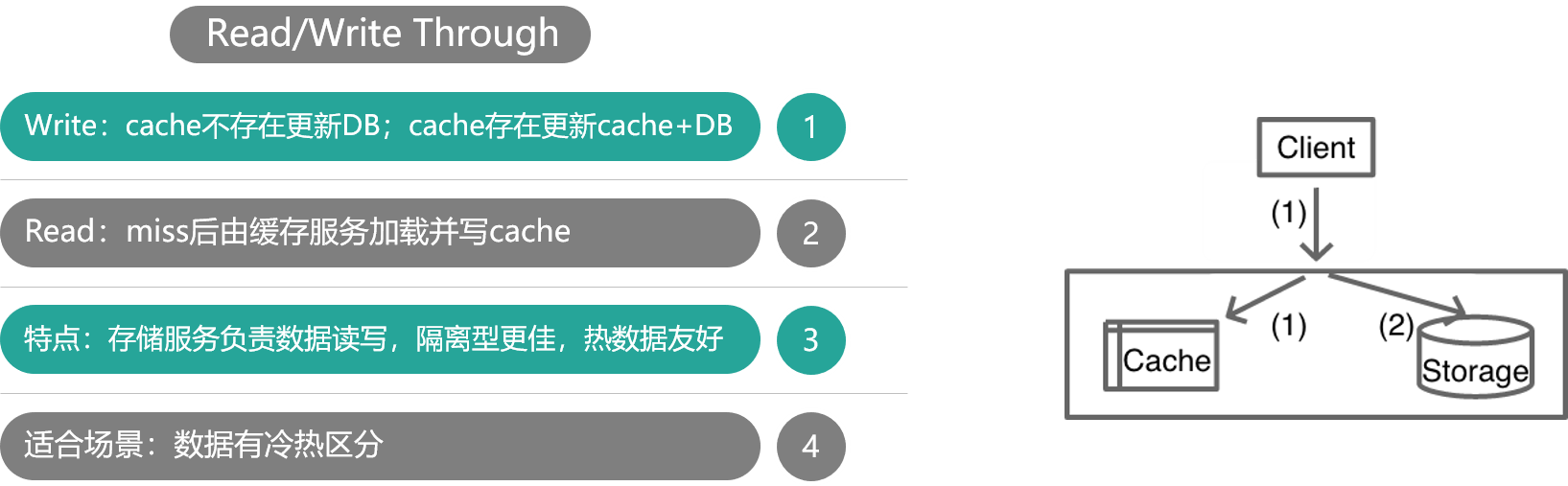
如上图,对于 Cache Aside 模式,业务应用需要同时维护 cache 和 DB 两个数据存储方,过于繁琐,于是就有了 Read/Write Through 模式。在这种模式下,业务应用只关注一个存储服务即可,业务方的读写 cache 和 DB 的操作,都由存储服务代理。存储服务收到业务应用的写请求时,会首先查 cache,如果数据在 cache 中不存在,则只更新 DB,如果数据在 cache 中存在,则先更新 cache,然后更新 DB。而存储服务收到读请求时,如果命中 cache 直接返回,否则先从 DB 加载,回种到 cache 后返回响应。
-
写操作:
- 存储服务查 Cache
- 若命中,先更新 Cache,再同步写入 DB
- 若未命中,仅更新 DB
-
读操作:
- 存储服务查 Cache
- 命中则直接返回
- 未命中则加载 DB,然后回写 Cache,再返回
写 ➔ 存储服务(GET cache) ➔ Hit: SET cache + Update DB➔ Miss: Update DB
读 ➔ 存储服务(GET cache) ➔ Miss ➔ Load DB ➔ SET cache ➔ Return
优缺点
-
优点
- 业务端代码只关注存储服务,隔离性好
- 仅为“热”数据更新缓存,内存利用率高
-
缺点
- 写路径较 Cache Aside 更同步,写延迟略高
典型场景
- 有明显“热”与“冷”数据区分的业务
3. Write Behind Caching(异步写回)
工作流程
由缓存存储服务(Cache Service)统一代理读写,业务应用只与存储服务交互。

Write Behind Caching 模式与 Read/Write Through 模式类似,也由数据存储服务来管理 cache 和 DB 的读写。不同点是,数据更新时,Read/write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。该模式的特点是,数据存储的写性能最高,非常适合一些变更特别频繁的业务,特别是可以合并写请求的业务,比如对一些计数业务,一条 Feed 被点赞 1万 次,如果更新 1万 次 DB 代价很大,而合并成一次请求直接加 1万,则是一个非常轻量的操作。但这种模型有个显著的缺点,即数据的一致性变差,甚至在一些极端场景下可能会丢失数据。比如系统 Crash、机器宕机时,如果有数据还没保存到 DB,则会存在丢失的风险。所以这种读写模式适合变更频率特别高,但对一致性要求不太高的业务,这样写操作可以异步批量写入 DB,减小 DB 压力。
与 Read/Write Through 相似,均由存储服务管理:
-
写操作:
- 只更新 Cache
- 存储服务后台异步批量合并写 DB
-
读操作:
同 Read/Write Through 模式
写 ➔ 存储服务(SET cache) ➔ Async Batch Write → DB
读 ➔ GET cache ➔ Miss ➔ Load DB ➔ SET cache ➔ Return
优缺点
-
优点
- 写性能最高,适合超高并发、可合并请求的场景
- 如计数类业务,将多次加操作合并为一次 DB 更新
-
缺点
- 数据一致性最差,且在崩溃/宕机时可能丢失未刷盘的数据
典型场景
- 对一致性要求不高,但写入频率极高的业务
- 如热点计数、流量统计等
我们可以看到缓存的三种读写模式各有优劣,不存在最佳模式。实际上,我们也不可能设计出一个最佳的完美模式出来,如同空间换时间、访问延迟换低成本一样,高性能和强一致性从来都是有冲突的,系统设计从来就是取舍,随处需要 trade-off。
如何根据业务场景,更好的做 trade-off,从而设计出更好的服务系统。
缓存分类及常用组件
1. 按宿主层次分类
-
本地 Cache(进程内):
- 组件:Guava Cache、Ehcache(嵌入模式)
- 优势:极低延迟、零网络开销;
- 劣势:随进程重启丢失、容量受限。
-
进程间 Cache(同机独立进程):
- 组件:独立部署的 Redis/Memcached 实例(与业务进程同机)
- 优势:重启不丢数据、减少部分网络延迟;
- 劣势:本机资源竞争,运维较复杂。
-
远程 Cache(跨机部署):
- 组件:集群化的 Redis/Memcached/Pika
- 优势:容量与扩展性最佳;
- 劣势:网络延迟与带宽瓶颈。
2. 按存储介质分类
-
内存型缓存:
- 数据驻留内存,读写延迟微秒级;
- 重启或崩溃后数据丢失。
- 典型:Memcached、Redis(无 AOF/RDB 时)。
-
持久化型缓存:
- 数据写入 SSD/RocksDB 等介质,容量大一个量级;
- 重启不丢失,但读写延迟高出 1–2 个数量级。
- 典型:Pika、基于 RocksDB 的缓存方案。
场景对比与权衡
-
一致性 vs. 性能:
- Cache Aside 最强一致性,Read/Write Through 次之,Write Behind 最弱;
-
开发与运维成本:
- Cache Aside 代码最复杂,Read/Write Through 与 Write Behind 降低业务端复杂度;
-
响应延迟与吞吐:
- Write Behind 写性能最高,Read/Write Through 读写均衡,Cache Aside 读性能最佳。
根据业务特性(访问热点、更新频度、一致性需求),在三种模式与不同部署/存储选型中做权衡,才能打造符合需求的缓存架构。
小结
我们树立了三种缓存读写模式——Cache Aside、Read/Write Through、Write Behind Caching——及其适用场景;
- Cache Aside:业务先读写数据库、删除缓存,通过懒加载方式在下一次读时回填缓存,确保以数据库为准。
- Read/Write Through:所有读写请求都由缓存服务统一代理,缓存命中则读写缓存并同步数据库,未命中则回源数据库并回填缓存。
- Write Behind Caching:写操作只更新缓存,后台异步批量合并写入数据库,以最高写吞吐换取可容忍的数据一致性降低。




的性能对比研究)


考前,面试前均可用!)




 : 阿里云百炼应用问答_回答图片问题_方案1_提问时上传图片文件)







